其实作为干了这么多年的研发和运维的人来说,现在都已经到 2026 年了,云原生(Cloud-Native)架构的话基本可以说是到处都是了。也就是说,现在我每天碰得最多的底层东西,早就不是以前那种一台台的物理服务器了。往往仅仅只是 Kubernetes(K8s)集群里面那几百上千个不停变来变去的 Pod。
那么在这种情况下面,数据库的计算和存储分开弄,还有那个存储资源随时需要随时挂载,其实已经变成大家都在干的事儿了,想不跟着走也不行。
但是呢,我们平时把以前老架构下的数据库往云原生环境里面搬的时候,经常就会碰到个问题。什么问题呢?就是很多以前用物理机时候留下来的老习惯,搞得人特别难受。
举个例子,我们在弄数据库存储那个逻辑层面隔开的东西------其实也就是表空间的时候。老一套的流程走下来,往往还是得让管理员自己登到服务器上去。接着还得靠手工去敲底层的操作系统命令,建个目录啊,再给分配个权限什么的,这样才能把底层用的盘给准备好。
这事儿如果放在现在那种自动化程度非常高的 CI/CD(持续集成与持续交付)流水线里面的话,真的非常耽误事。那么要是碰到系统需要自动扩容或者缩容的时候,这种情况往往就会变成每次都卡住的地方。
最近这段时间,我们这边正好在把核心业务往金仓数据库kingbase上面迁,接着要做一些云原生环境的适配工作。在这个过程里头呢,我就顺便好好琢磨了一下它底层引擎里面的一个挺有用的功能:自动创建表空间目录。
这功能看着好像挺一般的,但是在我们实际干活的时候,其实帮了大忙了。也就是说,它把云原生里面存储对接最容易出差错的那部分直接给跑通了。
所以这篇文章就不说那些干巴巴的纯理论了。我打算直接从平时敲代码验证,还有咱们工程实际操作的角度,跟大家捋一捋怎么用好这个特性。接着看看怎么在容器化的环境底下,把那种声明式的存储分配给搞定,然后再进一步去搭一个花钱少但是又好用的冷热数据分层架构。
文章目录
-
- [一、 告别繁琐的 Shell 脚本:特性机制与底层逻辑解析](#一、 告别繁琐的 Shell 脚本:特性机制与底层逻辑解析)
- [二、 容器化进阶:彻底打通 K8s PV/PVC 的声明式链路](#二、 容器化进阶:彻底打通 K8s PV/PVC 的声明式链路)
-
- [1. 基础设施层的声明式挂载 (K8s YAML 实战)](#1. 基础设施层的声明式挂载 (K8s YAML 实战))
- [2. 数据库内部的逻辑切割阶段 (SQL 实战)](#2. 数据库内部的逻辑切割阶段 (SQL 实战))
- [三、 降本增效核心:构建基于表空间的冷热数据分层(Tiered Storage)架构](#三、 降本增效核心:构建基于表空间的冷热数据分层(Tiered Storage)架构)
-
- [1. 异构存储介质的挂载设计](#1. 异构存储介质的挂载设计)
- [2. 分层表空间的初始化定义 (SQL)](#2. 分层表空间的初始化定义 (SQL))
- [3. 表分区规划与动态降冷策略](#3. 表分区规划与动态降冷策略)
- [四、 开发者实战避坑指南:不可忽视的架构边界校验](#四、 开发者实战避坑指南:不可忽视的架构边界校验)
-
- [1. 分布式存储的底层 I/O 性能屏障](#1. 分布式存储的底层 I/O 性能屏障)
- [2. 避免目录结构的非标准化命名陷阱](#2. 避免目录结构的非标准化命名陷阱)
- [3. 表空间的自动化容量水位监控预警](#3. 表空间的自动化容量水位监控预警)
- [五、 总结](#五、 总结)
一、 告别繁琐的 Shell 脚本:特性机制与底层逻辑解析
在深入实战之前,我们有必要先理清传统表空间管理为什么会成为自动化运维的阻碍。
表空间是关系型数据库中将逻辑数据对象(如表、索引)映射到物理存储设备上的重要桥梁。在传统的运维工作流中,创建一个新的业务表空间,我们需要经历以下极其繁琐且割裂的步骤,且一旦权限配置存在微小偏差(例如非数据库服务运行用户属主),就会导致后续的建库或建表指令直接崩溃:
bash
# 传统手工模式(流程繁琐,极易因权限或拼写错误导致自动化中断)
$ su - root
$ mkdir -p /data/new_storage_disk/finance_data
$ chown -R kingbase:kingbase /data/new_storage_disk/finance_data
$ su - kingbase
$ ksql -c "CREATE TABLESPACE finance_spc LOCATION '/data/new_storage_disk/finance_data';"其实为了把前面说的那种特别别扭的割裂问题给解决掉,kingbase 就在它内部引擎的 SQL 解析还有执行那个层面,搞了个小动作。也就是说,它把这个系统调用的活儿直接给接管过来了。这里面有个很关键的核心参数,名字叫 auto_createtblspcdir。通常来说,系统默认它是开着的,也就是处于 on 的情况。那么靠着这个参数的话,数据库引擎在跑 SQL 语句的那个阶段,自己就能去判断了。接着,它就会自动把底层操作系统的目录结构给你建出来,用不着咱们再手工去弄。
咱们平时在干活的时候,可以直接在数据库的命令行里头敲两下试试。看看这个特性用起来到底方不方便:
sql
-- 验证自动化目录构建参数是否处于开启状态
SHOW auto_createtblspcdir;
-- 预期输出: on
-- 此时,即便底层物理路径 /data/new_storage_disk/log_data 完全不存在
-- 直接执行以下 DDL 语句,引擎也会自动代为创建目录并赋予正确权限
CREATE TABLESPACE log_spc LOCATION '/data/new_storage_disk/log_data';底层安全与运行逻辑剖析:
那么当上面那条 CREATE TABLESPACE 的语句跑起来的时候,到底会发生啥呢?其实 kingbase 引擎会自己去认出那个绝对路径 ,接着把它提取出来。要是引擎跑到文件系统里一看,发现这个路径根本就不存在的话。它就会去调用系统底层的那个 mkdir 接口,一层一层地去把目录给建好。那它是用谁的身份去建呢?其实用的就是当前运行数据库服务的那个 OS 用户的身份。这个用户的话,往往仅仅只是一个权限被限制住的服务账号而已。
那么官方这么去设计代码,到底好在哪儿呢?其实主要有这么两块:
- 把多租户环境下面那种权限乱套的问题给彻底去掉了 :因为现在目录都是引擎自己去建的。也就是说,这个目录的属主(Owner)生下来肯定就是对的。咱们以前手工搞运维的情况,经常会有那种用
root用户去建了目录,结果转头就忘了敲chown改权限。像这种低级失误的话,现在就不会再发生了。 - 死死守住了安全隔离这道坎 :它在系统里往往是强行要求的,就是你指定的必须是个绝对路径。这个事儿放到容器环境里的话,那是极其关键的。要是用了相对路径出了事,是非常麻烦的。为什么会这样呢?其实原因在于,相对路径经常会搞得数据错写到容器的临时层(OverlayFS)里面去,这后果很难收场。接着呢,引擎还定了个规矩,就是这个新路径绝对不能放在现存的那个核心
data目录下面。而且去敲这行命令的人,必须得是超级用户的情况才可以。也就是说,这就从底层的物理层面,还有人员的权限层面,直接上了个双保险,把最核心的元数据给保护起来了。这样就能防着出现一种非常极端的情况。也就是说,万一有哪个单独业务的表空间数据突然涨得特别多,它也不至于一下子把整个数据库实例的那个系统盘都给彻底撑爆了。
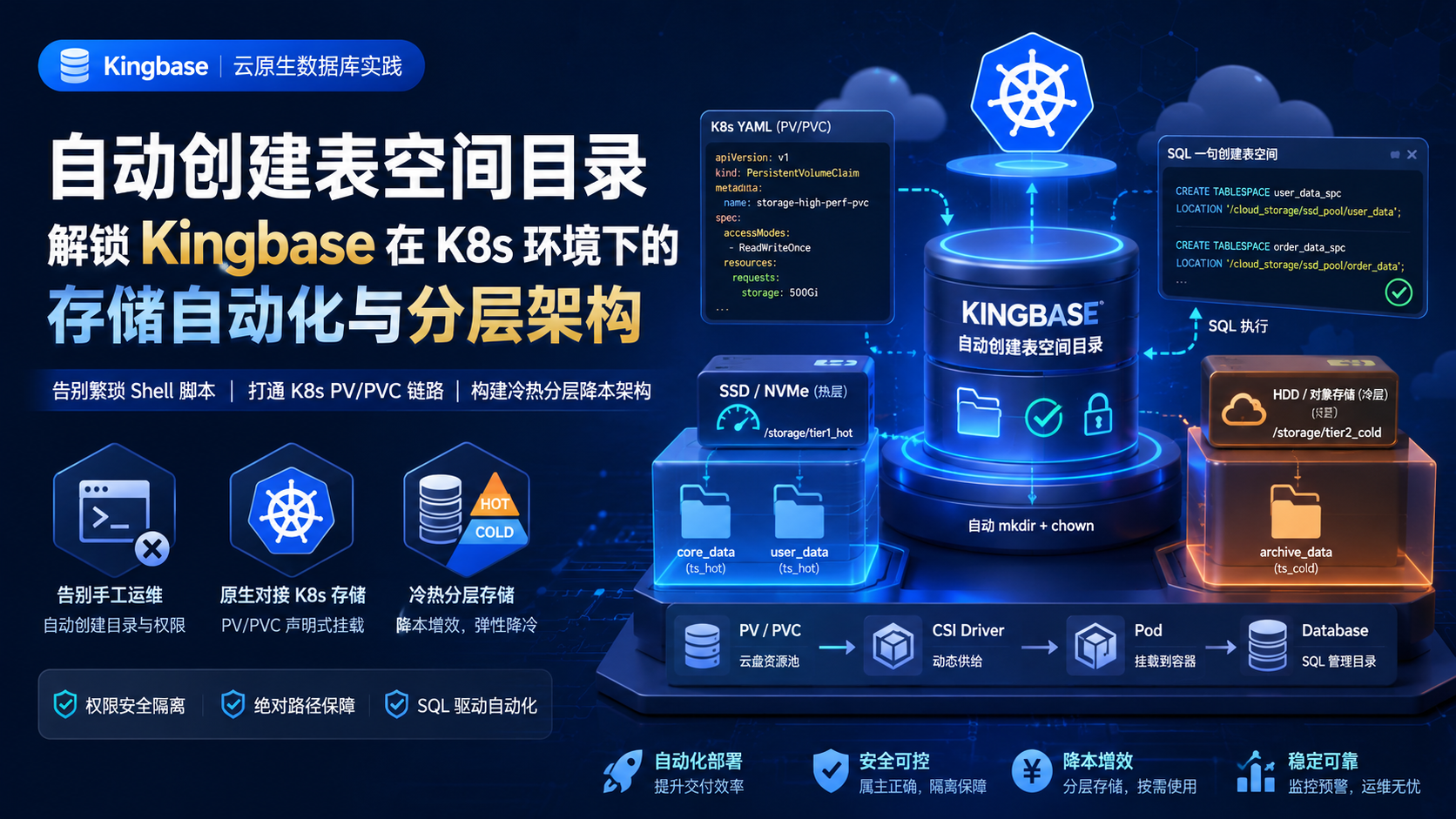
二、 容器化进阶:彻底打通 K8s PV/PVC 的声明式链路
在 2026 年的技术语境下,我们在大规模集群中很少再去直接操作裸磁盘或 LVM 逻辑卷。在 Kubernetes 生态中,存储资源是被抽象为 PV(Persistent Volume,持久卷)和 PVC(Persistent Volume Claim,持久卷声明)的。K8s 通过 CSI(Container Storage Interface,容器存储接口)驱动,动态地从云厂商的块存储池或分布式文件系统中划拨资源并挂载到 Pod 内。
如果没有"自动创建目录"这一数据库内部特性,容器编排将面临尴尬的局面:当 K8s 将一块 500GB 的企业级云盘挂载到 Pod 的 /var/lib/kingbase/storage 时,它提供的是一个空荡荡的根目录。如果研发团队想在这个大盘上划分出"用户中心表空间"、"交易流水表空间"等多个子目录,就必须编写复杂的 K8s InitContainer(初始化容器)脚本,或者借助庞大的自定义 Operator 来预处理这些目录。这不仅让 K8s 的 YAML 清单变得冗长难懂,也增加了 Pod 启动的耗时与故障率。
结合kingbase的自动化特性,整个云原生存储对接链路迎来了史诗级的简化。
1. 基础设施层的声明式挂载 (K8s YAML 实战)
基础设施团队只需关注宏观存储资源的分配,通过 K8s 标准声明划拨高速云盘,并将其挂载到容器的统一数据池挂载点:
yaml
# K8s PVC 声明文件:向云平台申请 500G 高性能 SSD 块存储
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: storage-high-perf-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Gi
storageClassName: ebs-ssd-premium
---
# StatefulSet / Pod 的局部配置片段:将其挂载到容器内部
volumeMounts:
- mountPath: /cloud_storage/ssd_pool # 空白的大容量挂载点
name: storage-volume2. 数据库内部的逻辑切割阶段 (SQL 实战)
其实当那个数据库的 Pod 被成功拉起来之后的情况。也就是说,咱们应用层上面那些用来做自动化发布的脚本(像是 Liquibase、Flyway 或者是咱们自己弄的那种 DevOps 平台)。这时候的话,它们往往仅仅只需要直接去下发那些标准的 SQL 语句就行了。那么在这中间,根本就用不着操作系统层级里的管理员再去人工插手了。接着系统自己就能把底层的目录给切开,然后把业务该归给谁就划给谁,这些它自动就跑完了:
sql
-- 将挂载的 500G 空白云盘逻辑划分为两个独立业务的表空间
-- kingbase会自动在 /cloud_storage/ssd_pool 下创建 user_data 和 order_data 目录
CREATE TABLESPACE user_data_spc LOCATION '/cloud_storage/ssd_pool/user_data';
CREATE TABLESPACE order_data_spc LOCATION '/cloud_storage/ssd_pool/order_data';
-- 通过金仓专属的系统字典视图,验证表空间是否成功映射到了物理路径
SELECT spcname, sys_tablespace_location(oid)
FROM sys_tablespace
WHERE spcname IN ('user_data_spc', 'order_data_spc');像这样的一种大家一起配合干活的模式。也就是说,外面其实是 K8s 负责管盘,它主要是搞那种比较大块的宏观资源调度。接着里面呢,是数据库它自身负责管目录,也就是在微观的地方自己去把数据给隔离开。那么这两种情况合在一起的话,就把底层的基础设施和咱们上面跑的业务逻辑给彻彻底底地拆开了,谁也不影响谁。通常来说,咱们平时如果要去衡量一个数据库产品,看看它到底是不是真的有那种云原生体验的话。这往往仅仅只是看它有没有做到上面说的那样,其实这就已经是个非常关键的地方了。
三、 降本增效核心:构建基于表空间的冷热数据分层(Tiered Storage)架构
自动化部署只是云原生带来的基础红利。在海量数据的企业级应用中,如何利用灵动的表空间机制实现云上的"降本增效"(FinOps),才是更高阶的架构设计。
在电商、金融等场景下,数据价值随时间呈断崖式衰减。例如,最近三个月的交易流水是"热数据",面临极高的并发读写,必须依赖高 IOPS 的 NVMe SSD 甚至内存级存储设备;而三年前的归档记录则是"冷数据",往往只在监管审计时偶尔查询,如果依然将其存放在昂贵的 SSD 上,将产生极其巨大的浪费。
利用自动表空间特性的极简扩展能力,我们可以非常丝滑地在云环境中构建起动态的存储分层架构,让不同生命周期的数据落在不同成本的介质上。
1. 异构存储介质的挂载设计
在 K8s 编排层面,我们为数据库实例同时分配并挂载两块不同成本与性能特性的卷:
- Tier 1 (热层,极速响应) :选用企业级极速云盘,提供极低的读写延迟,挂载于 Pod 路径
/storage/tier1_hot。 - Tier 2 (冷层,海量廉价) :选用大容量 SATA HDD 云盘,或者通过文件网关挂载兼容 S3 协议的对象存储卷,挂载于 Pod 路径
/storage/tier2_cold。
2. 分层表空间的初始化定义 (SQL)
架构师可以通过 DDL 快速将上述底层介质映射为数据库内部的冷热资源池:
sql
-- 1. 创建热数据表空间(引擎自动在高性能 SSD 挂载点下构建目录结构)
CREATE TABLESPACE ts_hot LOCATION '/storage/tier1_hot/core_data';
-- 2. 创建冷数据表空间(引擎自动在低成本、高容量的挂载点下构建目录结构)
CREATE TABLESPACE ts_cold LOCATION '/storage/tier2_cold/archive_data';3. 表分区规划与动态降冷策略
其实结合数据库里面的那个分区表(Partitioning)机制的话,也就是说,我们可以把数据的时间属性,跟底层的物理存储层直接给它绑定到一起。那么这里我们接着就拿一张上亿数据量级别的交易流水表 sys_transactions 来举个例子看看:
sql
-- 创建基于时间范围的分区表,默认主表逻辑驻留在热表空间
CREATE TABLE sys_transactions (
tx_id BIGINT,
tx_time TIMESTAMP NOT NULL,
amount NUMERIC(10,2),
details VARCHAR(500)
) PARTITION BY RANGE (tx_time) TABLESPACE ts_hot;
-- 新增当年(高频访问)的热数据分区,显式指定在热数据表空间
CREATE TABLE tx_2026 PARTITION OF sys_transactions
FOR VALUES FROM ('2026-01-01') TO ('2027-01-01')
TABLESPACE ts_hot;
-- 对于历史遗留数据,初始化时可直接将其分区创建在低成本冷表空间
CREATE TABLE tx_2024 PARTITION OF sys_transactions
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01')
TABLESPACE ts_cold;数据生命周期流转(数据降冷):
那么随着业务时间慢慢往后推移的话,2026 年那种经常被查的热数据,到了 2027 年的时候其实也就变成没什么人看的冷数据了。遇到这种情况的话,运维那边的兄弟其实根本不需要去折腾什么复杂的外部 ETL(也就是数据抽取转换)工具。接着就是,大家也完全不用去忍受那种停机维护的痛苦。
通常来说,你只要用系统里的定时任务去跑一条最普通的 DDL 语句就行了。跑完之后会怎么样呢?kingbase 的底层引擎就会自己去干活,很安全而且不出错地,把 2026 年那个分区的物理文件给搬个家。也就是说,直接从很贵的那种 SSD 目录里头,挪到便宜的 HDD 或者是对象存储的目录里面去:
sql
-- 一键降冷:将 2026 年的分区平滑迁移至冷数据层,瞬间释放 SSD 存储空间
ALTER TABLE tx_2026 SET TABLESPACE ts_cold;其实像这种搞法,也就是完全靠着数据库自己内部引擎来实现的分层机制,主要往往仅仅只是用 SQL 来驱动的。也就是说,就算在咱们企业层级里的实际项目里,开发人员连一行上层的业务代码都不用去重新写。那么带来的好处是什么呢?好处就是那种海量数据存下来的整体硬盘花销,会被直接砍掉很大一截。通常来说的话,这种不用改代码就能省钱的套路,刚好满足了现在大家想要一点点抠机器成本的实际需要。
四、 开发者实战避坑指南:不可忽视的架构边界校验
尽管 auto_createtblspcdir 特性带来了极致的部署体验,但作为对系统稳定性负责的开发者,我们不能盲目迷信自动化。在生产级 K8s 环境中应用该特性时,必须关注以下几个工程边界问题:
1. 分布式存储的底层 I/O 性能屏障
当我们把表空间(尤其是归档表空间)指向一个通过网络协议挂载的文件系统或对象存储网关时,虽然kingbase的自动创建功能可以顺畅地完成 mkdir 操作,但这类存储的 I/O 延迟与锁机制支持程度可能极其薄弱。
某些廉价的网络文件系统在处理强制刷盘同步指令时存在性能瓶颈。因此,在将真实业务表放入这些网络挂载路径之前,必须在操作系统侧进行严苛的基准测试。
bash
# 使用 fio 验证新挂载存储路径的 8K 随机写 IOPS(模拟数据库核心操作场景)
fio --name=randwrite --ioengine=libaio --iodepth=64 \
--rw=randwrite --bs=8k --direct=1 --size=5G \
--numjobs=4 --runtime=60 --group_reporting \
--filename=/storage/tier2_cold/test_io.dat避坑法则: 无论目录创建多么丝滑,如果上述基准测试中随机写的延时超过业务容忍的毫秒级阈值,请绝对不要将包含核心索引、或是存在更新(UPDATE/DELETE)操作的分区放置于该冷表空间,否则极易引发数据库整体的进程阻塞。
2. 避免目录结构的非标准化命名陷阱
尽管官方文档明确指出引擎能够处理包含大小写混合的复杂文件夹命名映射,但在微服务与多云混合部署的当下,不同底层的操作系统(甚至是不同的容器镜像底座)对大小写敏感度的处理策略存在差异。
最佳实践: 强烈建议在定义 LOCATION 的绝对路径时,摒弃任何大写字母、空格或特殊符号,始终遵循纯小写、下划线分隔的严谨 POSIX 标准路径命名风格。
sql
-- 推荐的标准化、高兼容性命名范例
CREATE TABLESPACE safe_spc LOCATION '/storage/cloud_pool/finance_archive_data';这能有效避免未来在执行底层物理热备工具(如全量物理备份与恢复)时,因路径解析歧义导致的不可控恢复失败。
3. 表空间的自动化容量水位监控预警
动态挂载与自动化构建并不能让我们彻底变成"甩手掌柜"。把部分文件系统结构的控制权交给 SQL 层面后,我们必须在监控侧(如 Prometheus + Grafana 体系)建立更加敏锐的探针。除了在 K8s 侧监控 PVC 的总体使用率外,还需要在kingbase内部配置实时视图,监控各个业务线逻辑表空间的膨胀速度:
sql
-- 创建专属监控视图:实时跟踪各业务表空间的物理容量水位及挂载物理路径
CREATE OR REPLACE VIEW v_sys_tablespace_monitor AS
SELECT
spcname AS "Tablespace_Name",
sys_size_pretty(sys_tablespace_size(spcname)) AS "Used_Size_Human_Readable",
sys_tablespace_location(oid) AS "Physical_Mount_Path"
FROM
sys_tablespace
WHERE
spcname NOT LIKE 'sys_%'; -- 排除系统自带的核心表空间
-- 自动化巡检或监控采集节点可定期执行
SELECT * FROM v_sys_tablespace_monitor ORDER BY sys_tablespace_size(spcname) DESC;一旦某个特定业务分配的自定义表空间容量逼近告警阈值,系统便能及时通知 K8s 管理员对底层存储卷进行扩容,或者触发数据的降冷清洗动作,确保自动化带来的便利不会反噬系统稳定性。
五、 总结
其实大家现在都在折腾,就是从以前那种老旧的 IT 架构,全面往 Cloud-Native 环境上面搬。在这么一个情况下面的话,我们平时去评价一个底层的软件到底行不行,往往仅仅只是看官方给的那些理论并发跑分,其实用处是不太大的。那真正要看什么呢?也就是说,我们得看看这东西放到现在的云环境里面到底好不好使。它自己能不能比较聪明地把自己给管好,还有一点挺关键的,就是咱们开发人员平时用起来觉得舒不舒服。
我们拿电科金仓数据库来说。它在这个引擎内部自己带了一个功能,也就是说它可以自己去把表空间的物理目录给建出来,接着还能顺带把这个目录的权限给管起来。大家也知道,以前老牌的关系型数据库,那个底层的逻辑结构往往搞得特别重。那么把它放到现在这种追求轻量级的容器化环境里,本来是非常别扭的,中间差了挺大的一截。但是有了这个内置功能的话,这个问题其实就给顺理成章地抹平了。
你想想以前的情况,要弄这些往往还得靠专门的物理机管理员。他们得登上去敲一大串非常啰嗦的 Shell 脚本,这活儿干起来简直就跟老式的手工小作坊一样。那么现在是个啥情况呢?其实只要在上面敲几行声明式的 SQL 语句就行了。接着系统自己就会去调度那些跨介质的存储资源。这样弄下来的话,不光是咱们研发兄弟们干活不用那么累了,那个系统该隔离的安全边界,反而被管得更扎实了。
通常来说,咱们这些干技术的人,还是得多花点心思去搞明白。接着呢,尽量去用好底层软件本来就自带的这些机制。当然了,要是咱们平时对 K8s 里面存储是怎么编排的,还有最近大家经常提的那个 FinOps (云财务运营)是怎么一回事,能多懂一点的话,那就更好了。把这些东西凑在一块儿理解透了。也就是说,就算以后业务那边的需求天天变来变去的,咱们也是不怕的。我们总归能搭出一套现代化的数据存储系统来。这个系统的话,既能扛得住平时海量高并发的情况,又能帮公司把花钱的成本给死死压住,其实这才是咱们干活的最终目的。