一、引言
我们在Flink的日常开发中,经常会发现代码里写了七八个算子(如 map、filter、flatMap),但在 Flink Web UI 上看到的 Task 却只有两三个。这种"合并"现象的幕后推手,就是 Flink 的核心优化机制------算子链(Operator Chain),理解它能帮助我们写出更高效的 Flink 作业。
二、什么是算子链(Operator Chain)?
在讨论算子链之前,需要先理清 Flink 中几个核心抽象之间的关系:
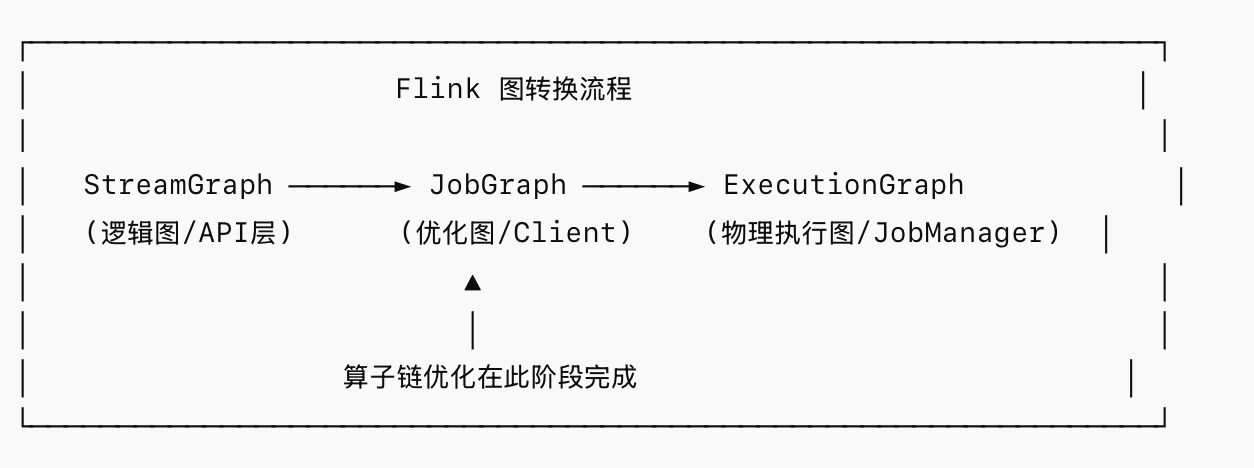
在 Flink 中,数据流是由一系列算子(Operator)组成的。默认情况下,Flink 会尽可能地将多个连续的算子链接(Chain)在一起,形成一个 Task,这个 Task 会被调度到一个 SubTask(即一个线程)中执行,算子链的本质是将多个算子融合在一个线程中串行执行。
假设我们有如下 Flink 作业:
env.addSource(kafkaSource) // parallelism = 2
.map(new MyMap()) // parallelism = 2
.filter(new MyFilter()) // parallelism = 2
.keyBy(...)
.process(new MyProcess()) // parallelism = 4
.addSink(sinkFunction); // parallelism = 4StreamGraph(Chain 之前 --- 逻辑视图):

JobGraph(Chain 之后 --- 优化视图):
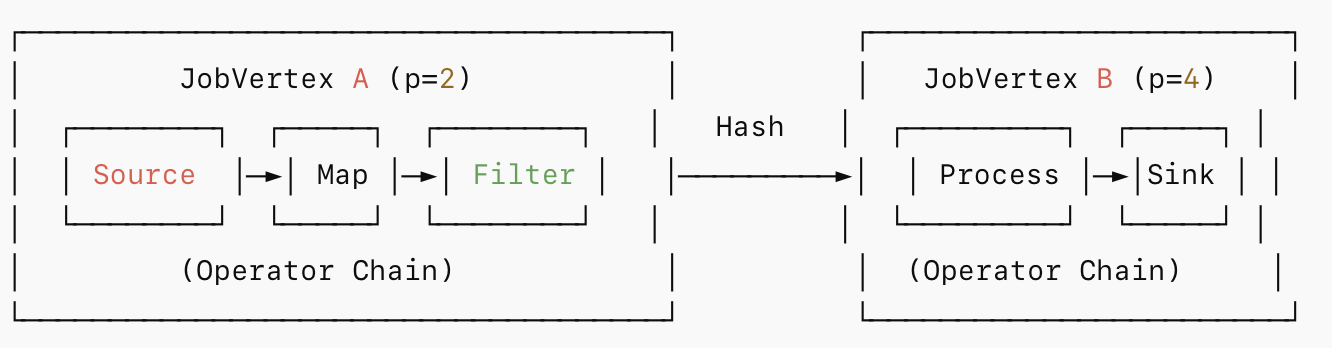
Source → Map → Filter:三者并行度都是 2,连接方式是 Forward → 可以 chain。
Filter → Process:Filter 并行度 2,Process 并行度 4,且经过 keyBy(Hash 分区)→不能 chain。
Process → Sink:并行度都是 4,Forward 连接 →可以 chain。
数据在算子链内与算子链之间的传递区别示意如下:

三、算子链的优缺点分析
算子链是 Flink 高吞吐、低延迟的关键保障,其优势在于:
- 降低序列化开销:Chain 内部数据通过 Java 对象引用直接传递,完全省去序列化/反序列化
- 减少线程切换:多个算子合并在一个线程中执行,避免线程上下文切换
- 减少网络 I/O:不需要经过 Network Buffer 和 TCP 传输
- 降低延迟:数据从上游算子到下游算子是同步方法调用,几乎零延迟
- 减少 Task 数量:更少的 Task 意味着更少的线程、更少的 Checkpoint barrier 对齐开销
然而,有些场景下使用算子链反而会成为瓶颈需要"拆链",算子链在使用过程需要关注以下问题点:
- 资源耦合:Chain 中的所有算子共享一个线程,如果其中一个算子特别慢(如调用外部服务),会阻塞整条链
- 反压传播更直接:链尾的慢速会立即影响链头,因为它们在同一线程(没有 buffer 缓冲)
- 监控粒度降低:在 Flink Web UI 中,chain 后的算子显示为一个 Task,难以逐个观察各算子的指标(如处理时间、watermark 等)
- 调试困难:日志中 chain 内的算子共享同一个 Task 标识,排查问题时可能不够直观
- 负载不均衡:如果 chain 中某个算子计算量远大于其他算子,无法单独扩缩容
四、算子链的形成条件
Flink 并不会无脑将所有算子连在一起,必须同时满足以下条件:
- 上下游算子并行度一致(Parallelism 相同)。
- 下游算子的入度为 1(即单数据源,不能是 Join 或 CoProcess)。
- 上下游算子在同一个 SlotSharingGroup 中(默认都在 "default" 组)。
- 上下游算子之间的数据传输策略是 FORWARD(不能是 Keyed、Rebalance、Broadcast 等)。
- 算子没有被显式禁用链化(
disableChaining())。 - 执行环境允许链化(没有全局
env.disableOperatorChaining())。
五、算子链配置
-
全局配置
flink-conf.yaml
pipeline.operator-chaining: true # 默认为 true
//java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.disableOperatorChaining(); // 全局禁用算子链,一般不建议全局禁用,除非用于调试目的。 -
算子级配置
// 1. startNewChain():从当前算子开始一条新的链(切断与上游的chain)
dataStream
.map(new MyMap())
.startNewChain() // Map 成为新链的头
.filter(new MyFilter());// 2. disableChaining():当前算子不参与任何chain(前后都切断)
dataStream
.map(new MyMap())
.disableChaining() // Map 独立成为一个Task
.filter(new MyFilter());// 3. slotSharingGroup():设置不同的SlotSharingGroup(间接阻止chain)
dataStream
.map(new MyMap()).slotSharingGroup("group-a")
.filter(new MyFilter()).slotSharingGroup("group-b");
// Map 和 Filter 不在同一个 SlotSharingGroup → 无法 chain
六、最佳实践与调优原则
算子链选择与调优总体原则如下:
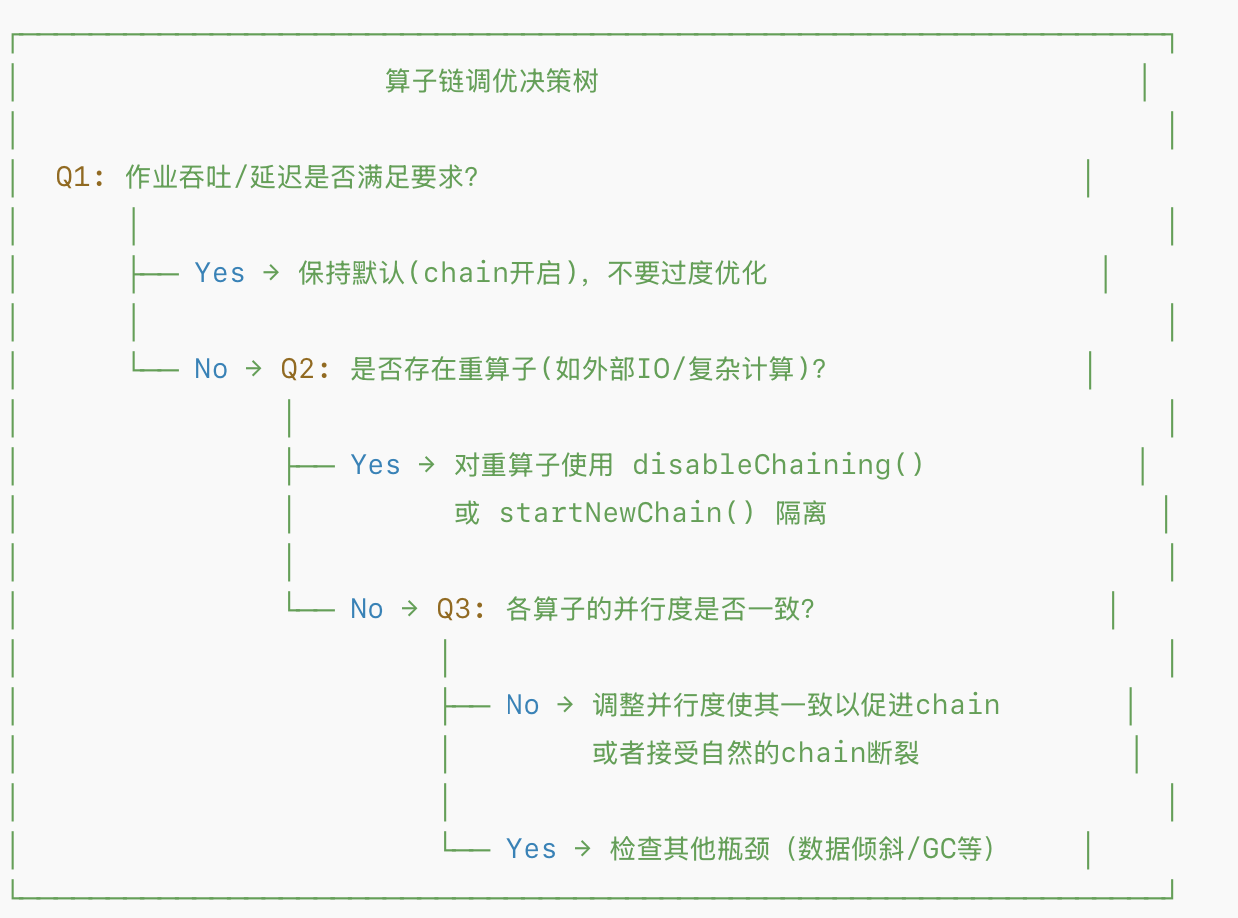
- 场景1:轻量级 ETL 管道 --- 保持默认 Chain,所有算子都是 CPU 轻量操作,chain 在一起可以最大化吞吐。
- 场景2:存在重 I/O 算子 --- 隔离慢算子,如果chain在一起会拖慢整条链,隔离后可以独立调整其并行度。
- 场景3:调试/性能分析 --- 临时禁用 Chain,禁用后每个算子都是独立 Task,在 Flink Web UI 中可以看到每个算子的性能指标;性能分析完成后请务必恢复默认设置,否则生产性能将受严重影响。
- 场景4:精细化资源管理 --- 使用 SlotSharingGroup(慎用)
七、总结展望
算子链是 Flink 中一个"默认就很好"的优化机制。在大多数场景下,你不需要做任何干预。只有当你需要隔离慢算子、精细化资源管理或调试排查时,才需要手动控制它。记住一个原则:不要过早优化,也不要无意识地破坏优化。