引言:封装清晰的 SQL 为什么可能变慢?
在复杂业务系统中,开发者常用 CTE(Common Table Expression,公共表表达式)或子查询封装业务逻辑。这样能提升可读性,但也可能让过滤条件远离数据源,导致执行计划产生较大的中间结果集。
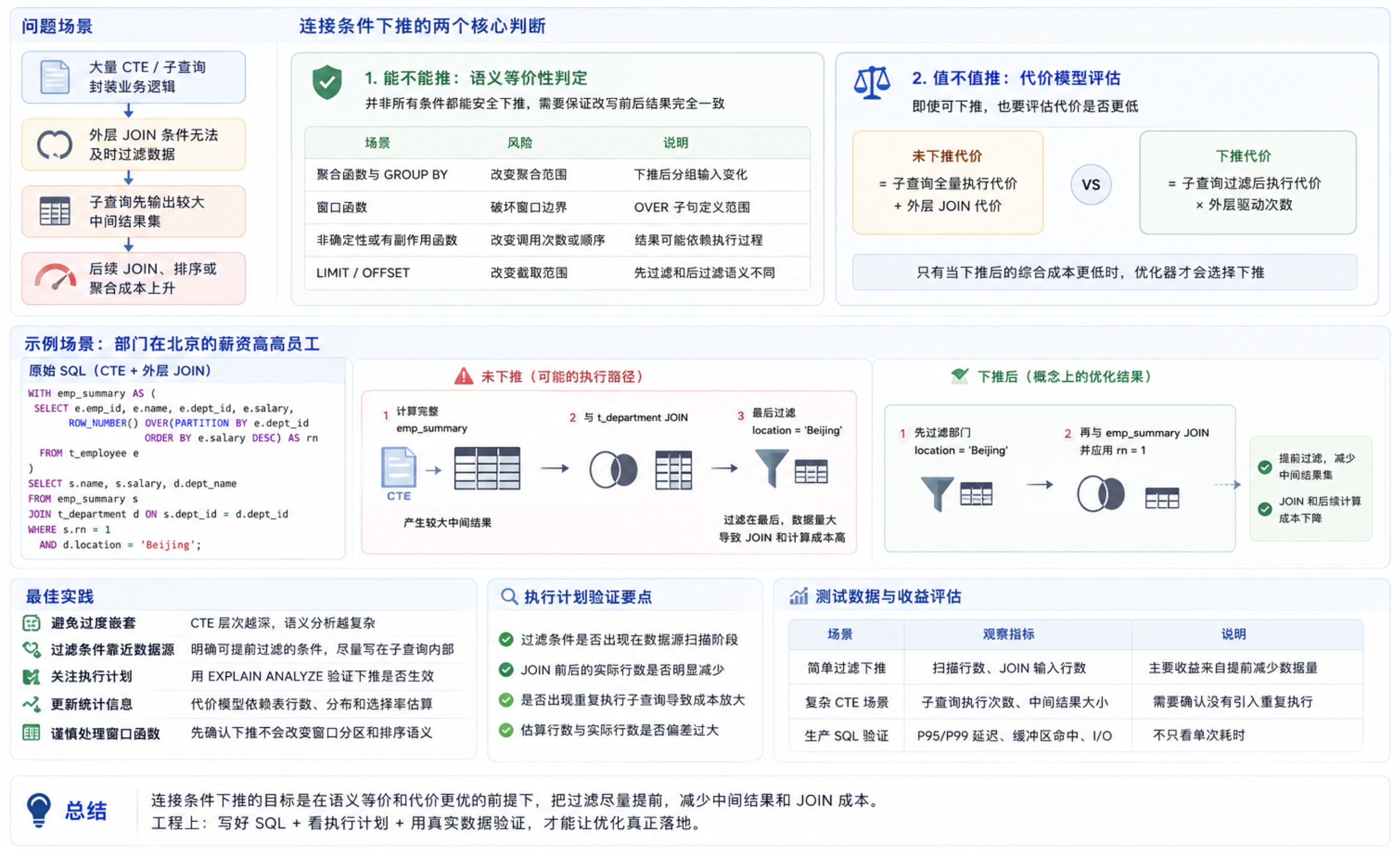
典型问题如下:
text
大量 CTE / 子查询封装业务逻辑
-> 外层 JOIN 条件无法及时过滤数据
-> 子查询先输出较大中间结果集
-> 后续 JOIN、排序或聚合成本上升"连接条件下推(Join Condition Pushdown)"的目标,是在保证语义等价的前提下,把可以提前执行的连接或过滤条件推到更靠近数据源的位置。这个优化并不只是移动一段 WHERE 条件,还需要同时判断"能不能推"和"值不值推"。
一、连接条件下推的两个核心判断
1.1 能不能推:语义等价性判定
并非所有 JOIN 条件都能安全下推。优化器需要确认改写前后的结果完全一致,尤其要谨慎处理以下场景:
| 场景 | 风险 | 说明 |
|---|---|---|
聚合函数与 GROUP BY |
可能改变聚合范围 | 下推后分组输入发生变化 |
| 窗口函数 | 可能破坏窗口边界 | OVER 子句定义了计算范围 |
| 非确定性或有副作用函数 | 可能改变调用次数或顺序 | 结果可能依赖执行过程 |
LIMIT / OFFSET |
可能改变截取范围 | 先过滤和后过滤语义不同 |
优化器通常需要分析查询树,识别聚合、窗口、函数、限制子句等节点,只对语义安全的条件进行下推。
1.2 值不值推:代价模型评估
即使语义上可以下推,也不代表一定更快。例如外层驱动表很大时,下推可能导致内侧子查询被重复执行,反而增加成本。
可以用下面的简化模型理解:
text
未下推代价 = 子查询全量执行代价 + 外层 JOIN 代价
下推代价 = 子查询过滤后执行代价 x 外层驱动次数只有当下推后的综合成本更低时,优化器才应选择该计划。因此,准确的统计信息对该类优化非常关键。
二、代码示例
2.1 场景构造
sql
CREATE TABLE t_employee (
emp_id INT PRIMARY KEY,
name VARCHAR(50),
dept_id INT,
salary DECIMAL(10,2)
);
CREATE TABLE t_department (
dept_id INT PRIMARY KEY,
dept_name VARCHAR(50),
location VARCHAR(50)
);2.2 CTE + 外层 JOIN
sql
WITH emp_summary AS (
SELECT
e.emp_id,
e.name,
e.dept_id,
e.salary,
ROW_NUMBER() OVER(PARTITION BY e.dept_id ORDER BY e.salary DESC) AS rn
FROM t_employee e
)
SELECT
s.name,
s.salary,
d.dept_name
FROM emp_summary s
JOIN t_department d ON s.dept_id = d.dept_id
WHERE s.rn = 1
AND d.location = 'Beijing';如果优化器不能识别可下推条件,执行路径可能是:
- 先计算完整的
emp_summary; - 再与
t_department做 JOIN; - 最后应用
d.location = 'Beijing'过滤。
当中间结果较大时,这种路径会放大 JOIN 和窗口计算后的处理成本。
2.3 概念上的下推结果
语义安全且代价合适时,优化器可以把部门过滤提前:
sql
WITH emp_summary AS (
SELECT
e.emp_id,
e.name,
e.dept_id,
e.salary,
ROW_NUMBER() OVER(PARTITION BY e.dept_id ORDER BY e.salary DESC) AS rn
FROM t_employee e
)
SELECT s.name, s.salary, d.dept_name
FROM emp_summary s
JOIN (
SELECT *
FROM t_department
WHERE location = 'Beijing'
) d ON s.dept_id = d.dept_id
WHERE s.rn = 1;这只是概念化写法,实际是否改写以及改写到哪个位置,需要以执行计划为准。
三、最佳实践
3.1 写出更容易优化的 SQL
| 建议 | 说明 |
|---|---|
| 避免过度嵌套 | CTE 层次越深,语义分析越复杂 |
| 过滤条件靠近数据源 | 明确可以提前过滤的条件,尽量写在子查询内部 |
| 关注执行计划 | 用 EXPLAIN ANALYZE 验证过滤条件是否提前生效 |
| 更新统计信息 | 代价模型依赖表行数、分布和选择率估算 |
| 谨慎处理窗口函数 | 先确认下推不会改变窗口分区和排序语义 |
3.2 执行计划验证
sql
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
WITH emp_summary AS (
SELECT e.emp_id, e.name, e.dept_id, e.salary,
ROW_NUMBER() OVER(PARTITION BY e.dept_id ORDER BY e.salary DESC) AS rn
FROM t_employee e
)
SELECT s.name, s.salary, d.dept_name
FROM emp_summary s
JOIN t_department d ON s.dept_id = d.dept_id
WHERE s.rn = 1
AND d.location = 'Beijing';重点观察:
location = 'Beijing'是否出现在部门表扫描或索引扫描阶段;- JOIN 前后的实际行数是否明显减少;
- 是否出现重复执行子查询导致的成本放大;
- 估算行数与实际行数是否偏差过大。
四、测试数据应如何表达
连接条件下推在合适场景下可能带来明显收益,但提升幅度与数据分布、索引、统计信息、并发负载和版本实现有关。建议在文章或技术方案中使用如下表达:
| 场景 | 观察指标 | 说明 |
|---|---|---|
| 简单过滤下推 | 扫描行数、JOIN 输入行数 | 主要收益来自提前减少数据量 |
| 复杂 CTE 场景 | 子查询执行次数、中间结果大小 | 需要确认没有引入重复执行 |
| 生产 SQL 验证 | P95/P99 延迟、缓冲区命中、I/O | 不只看单次耗时 |
如果需要给出性能数据,应注明测试环境、数据规模、索引、统计信息状态和 SQL 版本,避免把单一测试结果写成普遍结论。
总结
CTE 和子查询能提升 SQL 可读性,但也可能让过滤条件远离数据源。连接条件下推的价值在于:在语义等价和代价更优的前提下,把过滤尽量提前,减少中间结果和 JOIN 成本。
工程上不应盲目依赖优化器,也不必完全回避 CTE。更稳妥的做法是:把明确可提前过滤的条件写近数据源,用执行计划验证下推效果,并用真实数据规模评估收益。