主要来源文章,增加了一些自己的东西
We've worked with dozens of teams building LLM agents across industries. Consistently, the most successful implementations use simple, composable patterns rather than complex frameworks.
总结而言:简单优于复杂
一 Agent定义
Antropic对Agent的定义是一个由LLM驱动的智能系统,可以自己定义过程和工具使用,并且掌控自己任务的完成。
这里特别区分了workflow: LLM和tool是是被嵌入在预定的工作流里的,不是真正的Agent。
二 什么时候该用Agent,什么时候不用
在使用大语言模型(LLMs)构建应用程序时,尽可能找到最简单的解决方案,仅在必要时增加复杂性。这可能意味着根本不构建智能体系统。智能体系统通常会以延迟和成本为代价来换取更好的任务性能,你应该考虑这种权衡何时是合理的。
- 当需要处理更多复杂情况时,工作流能为定义明确的任务提供可预测性和一致性;
- 当需要大规模的灵活性和基于模型的决策时,智能体则是更好的选择;
- 对于许多应用来说,通过检索和上下文示例优化单个大语言模型调用通常就足够了。
三 如何使用框架
现在市面上有很多用于开发Agent/WorkFlow的框架(这里Antropic完全是海外视角,做了些微调):
- 代码优先的可编程 Agent 框架:LangGraph(代码级控制,状态图)
- 云厂商托管的 Agent 构建服务:阿里百炼 Agent、百度千帆 AppBuilder(云平台托管)
- 可视化低代码 Agent 构建平台:Dify、FastGPT
- 多智能体协作专用框架:AutoGen,MetaGPT
这些框架通过简化标准的底层任务(如调用大语言模型、定义和解析工具以及将调用链接在一起),使得上手变得容易。然而,它们往往会创建额外的抽象层,这可能会掩盖底层的提示和响应,使其更难调试。当简单的设置就足够时,它们还可能让人忍不住增加复杂性。
建议开发者先直接使用大语言模型(LLM)应用程序编程接口(API):许多模式只需几行代码就能实现。如果确实使用了框架,请确保你理解其底层代码。对底层代码的错误假设是客户出错的常见原因。
四 构建Block&Workflow&Agent
Building block: The augmented LLM
基础模块,有简单外挂的LLM,LLM enhanced with augmentatios such retrieval,tools and memory,claude如今具有生成query/选择合适工具/保留必要信息的能力,很多国产大模型也有。
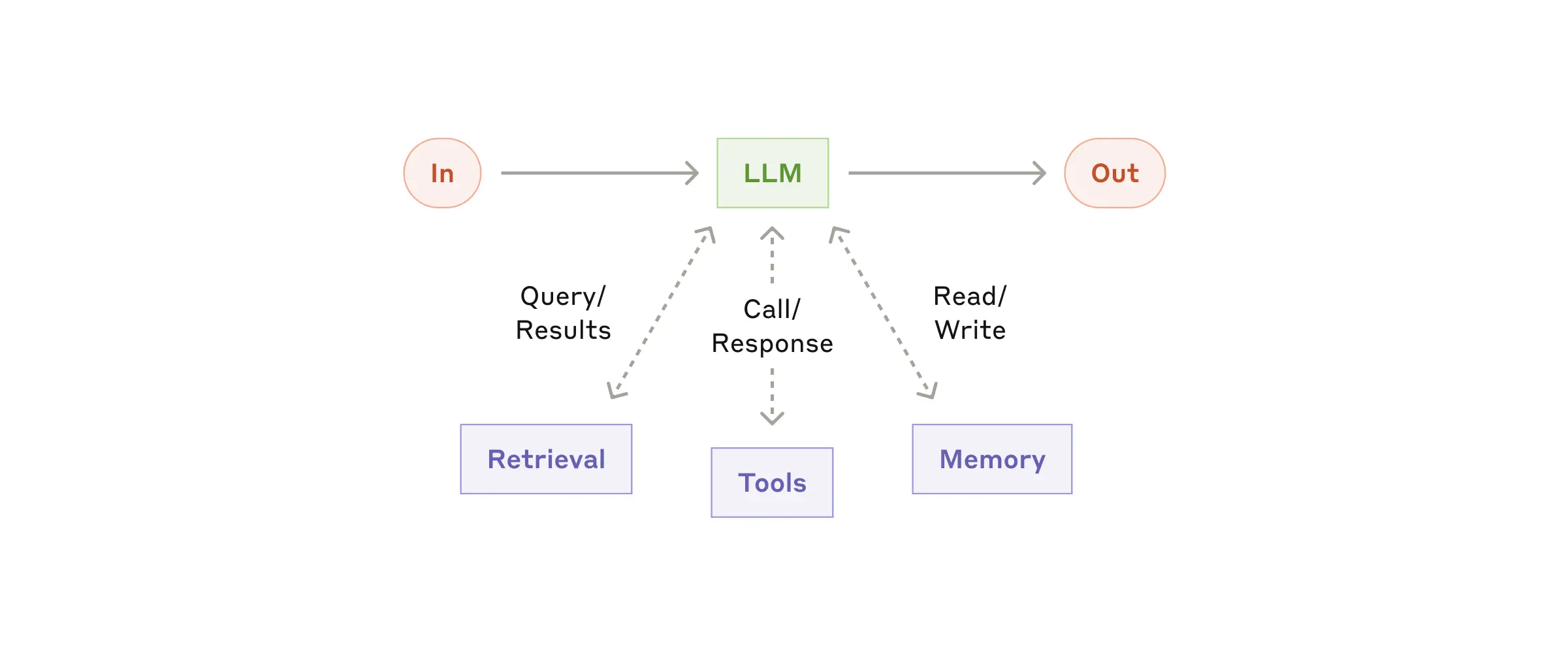
Antropic推荐关注两个方面:
- 为特定能力定制用例
- 文档&规范对大模型友好:完善且定义清晰
推荐使用MCP(Model Context Protocol)定义工具,通过 MCP 协议,开发者可快速构建适配特定场景的 LLM 应用,同时确保接口的易用性和可维护性,加速大语言模型能力的规模化落地。
Workflow
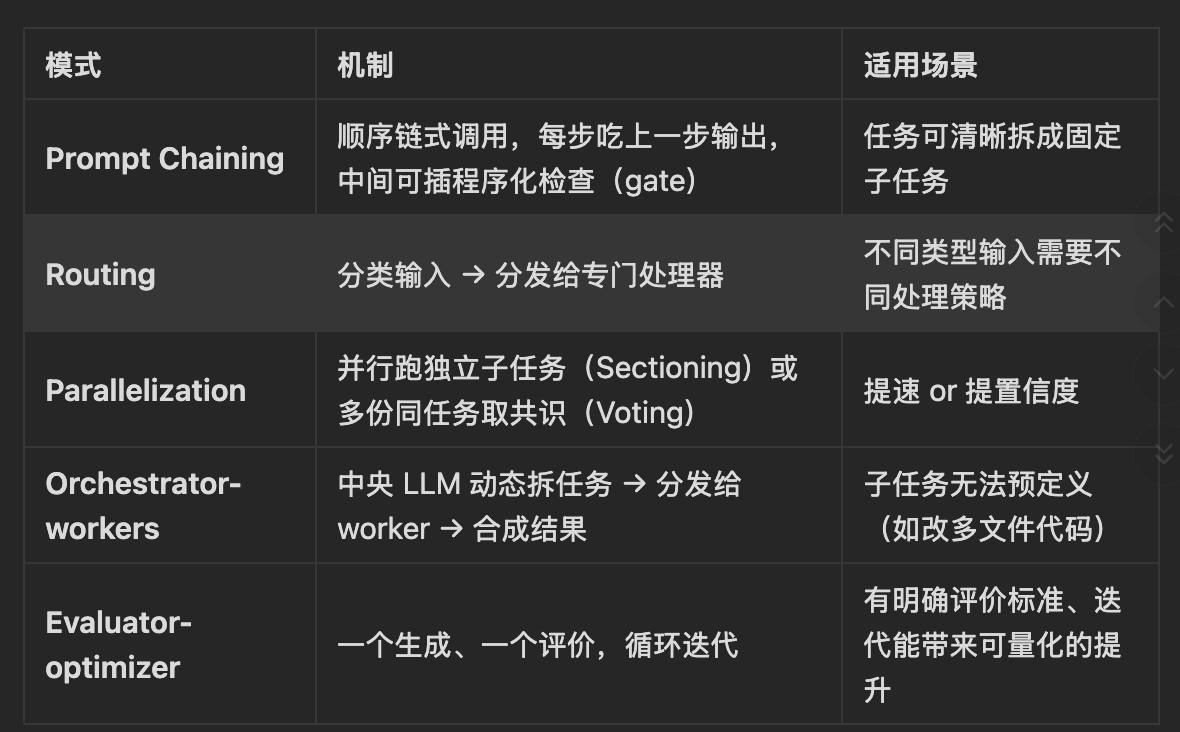
1. prompt chain
当任务可以被清晰的定义为几个固定的子任务时,为了更高的任务质量,在性能损害可以接受的条件下,可以使用workflow
如下图所示,Prompt chain 把任务分解为多阶段的小任务,每个小任务单独写prompt请求大模型,然后把大模型的返回再传递给后面的任务的大模型。为了使中间步骤可控可追溯,可以增加一些控制单元(图中的Gate)
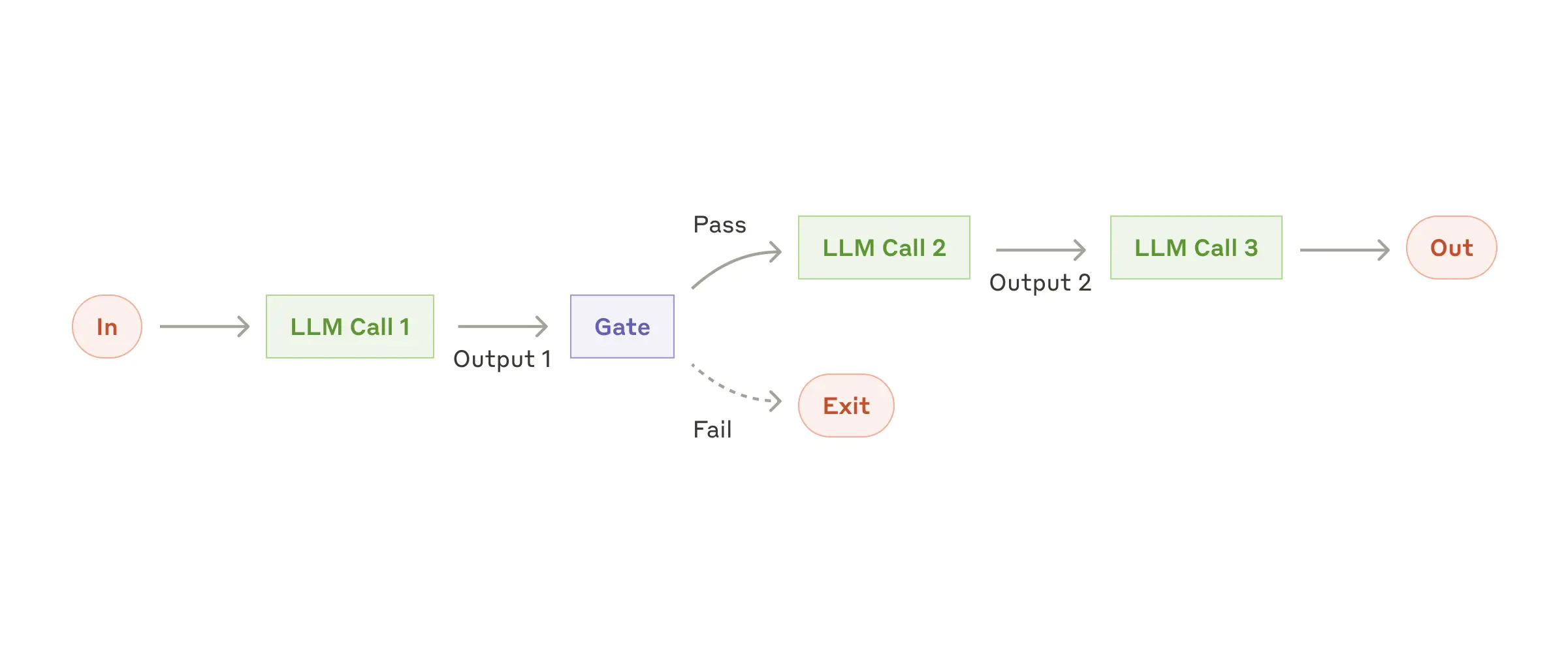
示例
- Generating Marketing copy, then translating it into a different language.
- Writing an outline of a document, checking that the outline meets certain criteria, then writing the document based on the outline.(先写大纲,Gate判断大纲是否符合要求,然后在基于大纲填充内容)
2. Routing(任务路由)
在处理复杂任务时,如果这些任务存在不同的类别,分开处理更为合适,并且分类可以由大语言模型(LLM)或更传统的分类模型/算法准确处理
任务路由本质是一个对Input的Classifier,用于决定下面的执行阶段该走那个任务,后面的任务可以工具不同需求去专门优化自己,以免不同任务间产生影响。

示例:
- 问答机器人:将不同类型的客户服务查询(一般问题、退款请求、技术支持)引导至不同的下游流程、提示和工具。
- 模型路由:将简单/常见问题路由到较小、成本效益高的模型(如Claude Haiku 4.5),将困难/不常见问题路由到更强大的模型(如Claude Sonnet 4.5),以优化性能。
3. Workflow: Parallelization
当划分的子任务可以并行化以提高速度,或者需要多个视角或尝试以获得更可靠的结果时,并行化是有效的;
对于需要多方面考虑的复杂任务,当每个方面都通过单独的大语言模型调用处理时,大语言模型通常表现更好,这样可以专注于每个特定方面。
并行话使用LLM一般有两种表现形式:
- Sectioning(分区):把任务分解为独立的子任务,单独运行
- Voting(投票制): 同一个任务,多个同时跑,得到多样话的答案
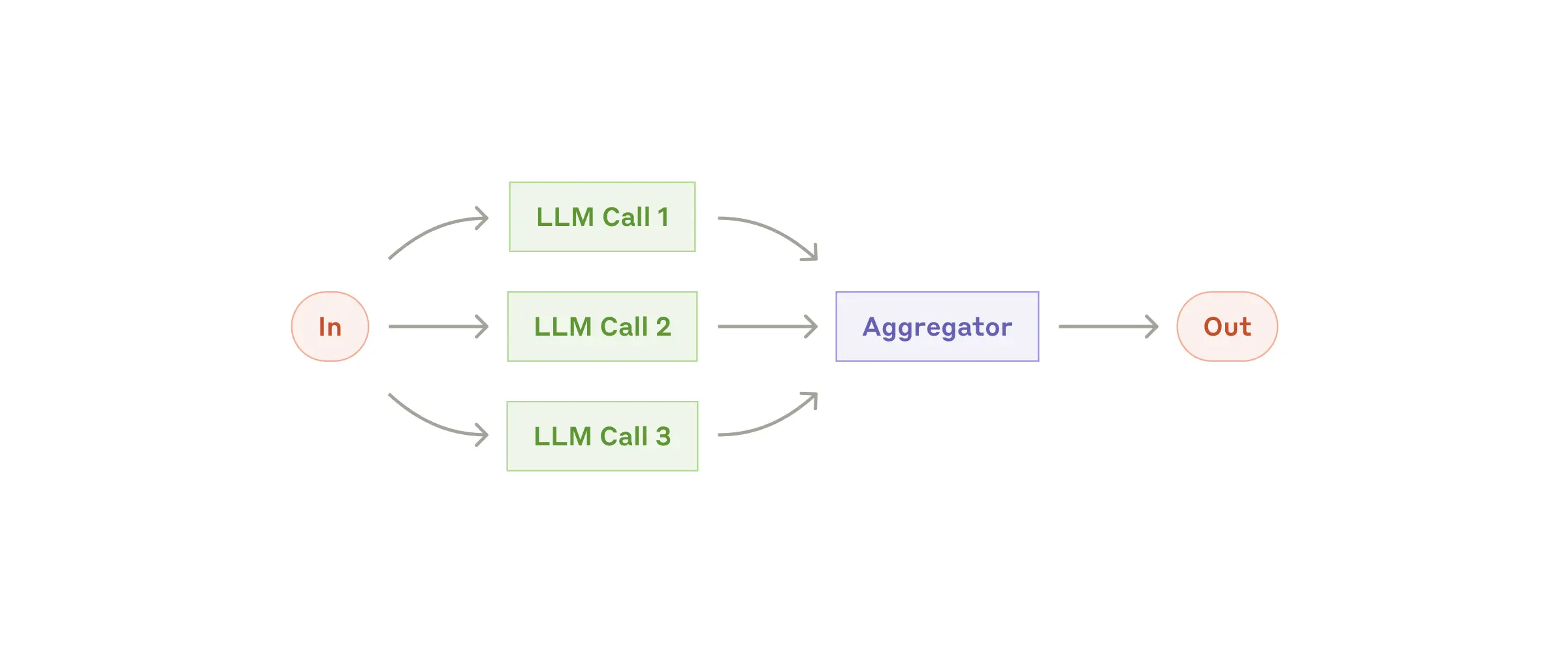
示例 :
分区:
- 实施护栏机制,其中一个模型实例处理用户查询,而另一个实例对查询进行筛选,以检查是否存在不适当的内容或请求。这通常比让同一个大语言模型调用同时处理护栏和核心响应的效果更好;
- 自动评估大语言模型的性能,其中每个大语言模型调用评估模型在给定提示下的不同性能方面。
投票:
- 审查一段代码是否存在漏洞,其中多个不同的提示对代码进行审查,如果发现问题则标记出来。
- 评估给定内容是否不适当,多个提示评估不同方面或需要不同的投票阈值,以平衡误报和漏报。
4 Workflow: Orchestrator-workers
当任务复杂到一定程度时,我们很难人工预先分解所有的子任务 ,这时候我们需要一个强大的中心LLM,分解任务,并委派给worker LLMs,然后把works的结果进行合成,与前面的Router和Parrallization最主要的区别就是任务不是预先设定的,是中心LLM基于input自主决定的。
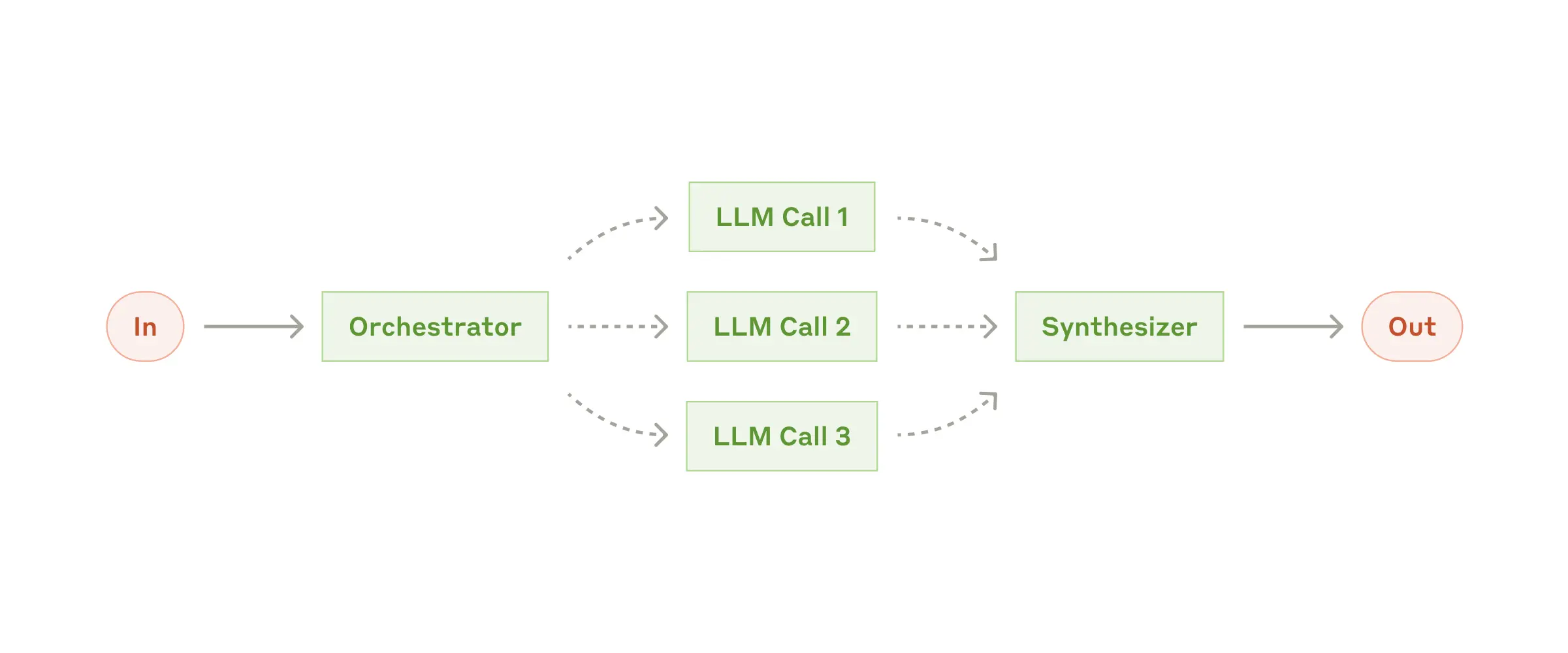
示例:
- 每次对多个文件进行复杂更改的编码产品。
- 涉及从多个来源收集和分析信息以查找可能相关信息的搜索任务。
5 Workflow: Evaluator-optimizer(评估&优化)
当评估标准(evaluation criteria)非常明确时 ,可以引入Evaluator-optimizer模式,一个LLM做输出,一个LLM做评价,然后不断迭代,
这样有两个好处,因为当有明确反馈时,大模型的输出是有明显的提升;另外,复杂的大模型自己可以充当Evaluator,就像是人类作家写作时,会不断打磨自己的作品,咬文嚼字。
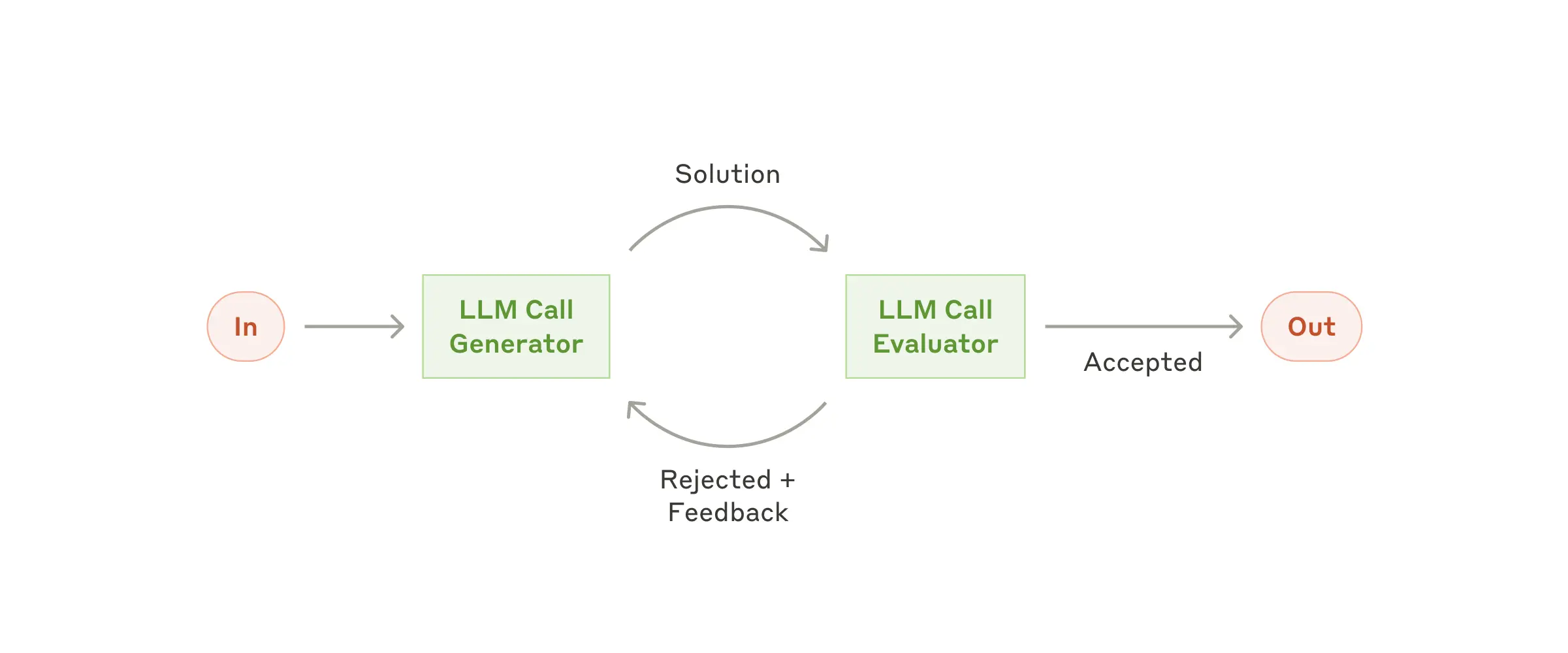
示例:
- 文学翻译中存在一些细微差别,翻译大语言模型(LLM)可能一开始无法捕捉到,但评估大语言模型(LLM)可以提供有用的批评意见。
- 复杂的搜索任务需要多轮搜索和分析才能收集全面的信息,评估者会决定是否有必要进行进一步的搜索。
6 总结
Agents
Agent模式可行的前提是大模型足够厉害,具备以下四种能力:
- 理解复杂问题(input)
- 自动推理和规划问题解决
- 可以有效有质的使用工具
- 可以自动反思,从错误中迭代纠正自己的问题
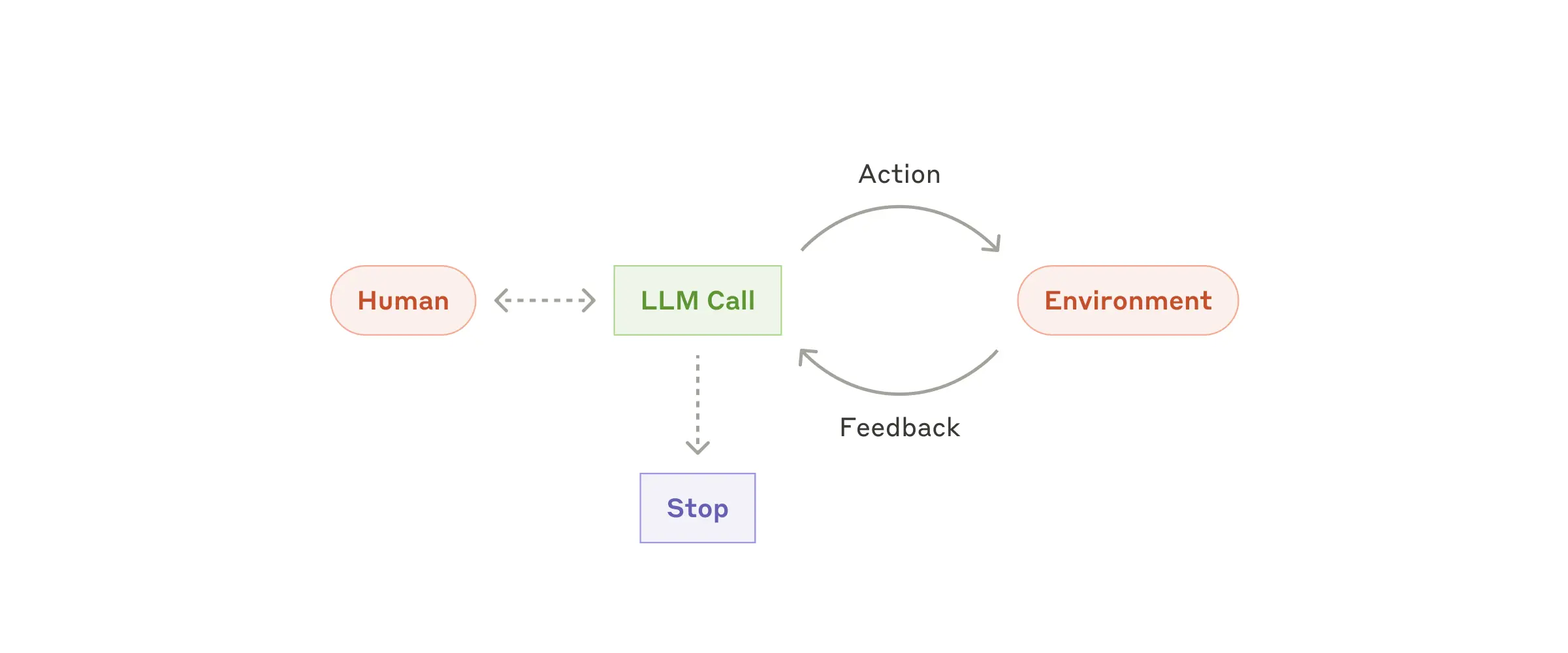
在这个前提下,当问题很难或无法预测所需的步骤数量,也无法硬编码固定路径时,可以使用Agent模式。这时大语言模型可能会进行多轮努力(当你完全交给大模型时,或者我用Trae/codex/claude code时,会发现一个任务可能会反复执行),所以我们必须一定程度上信任其决策能力(总结而言就是yes & yes)。智能体的自主性使其非常适合在可信环境中扩展任务。智能体的自主特性意味着更高的成本和错误累积的可能性。所以建议在沙盒环境中进行广泛测试,并设置适当的防护措施,所以Agent模式一般都建议单独设置一个Guardrail模块进行安全校验和兜底。
一个Agent模式的任务通常是下面这样的:
Agent的工作起始于人类用户的指令或与之进行的交互式讨论。一旦任务明确,智能体就会独立规划和执行,可能会向人类寻求更多信息或判断。在执行过程中,智能体在每一步都从环境中获取"真实情况"(如工具调用结果或代码执行情况)以评估其进展(这一点至关重要)。智能体随后可以在检查点或遇到阻碍时暂停,等待人类反馈。任务通常在完成时终止,但为了保持控制,也常设置停止条件(如最大迭代次数)
尽管上面的流程看起来很复杂,但是实际上的架构确很简单,如下图所示,就是一个强大的LLM作为核心,他可以自主判断任务分解/使用工具/是否需要迭代等一系列情况,所以这里面至关重要的就是如何设计一个工具集合和他们的文档,一个好的工具集合应该是清晰的&对大模型友好的。
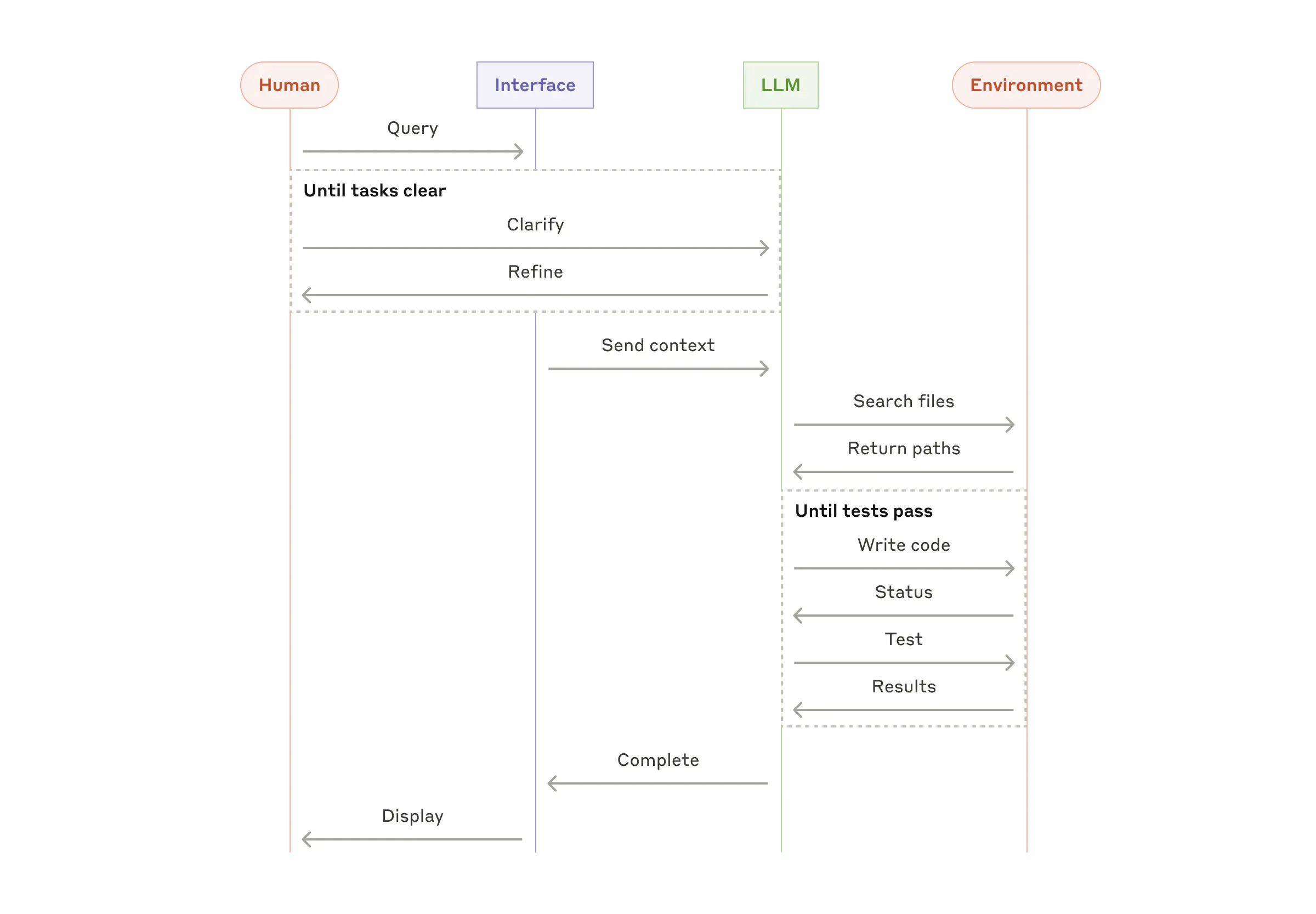
示例
- Code Agent
下面是一个Code Agent的数据流图, 具体的实践见SWE-bench
- "computer use",即Claude使用计算机来完成任务, Claude可以截图,然后操作你的电脑,目前国内的智谱也开源了对应的能力模型CogAgent
总结
简单大于复杂,所有的任务,都应该从一个简单的prompt开始,重要的是如何构建评价系统,当简单的方案不满足要求时,才引入复杂的系统!!!
下面是三条核心原则:
-
- Agent的设计应该保持简洁
-
- 显式的展示Agent的规划步骤
-
- 详尽的工具文档&系统性测试,从而构建Agent-computer interface(ACI)