为什么现在必须用 KRaft?
以前搭建 Kafka,还得先装个 Zookeeper,维护两套系统,不仅麻烦,ZK 还经常成为性能瓶颈。
现在(2026年),Kafka 3.8 版本已经非常成熟了。KRaft 模式直接用 Kafka 自己的节点来管理元数据,不再依赖外部组件。对于新搭建的集群,建议直接使用 KRaft 模式,架构更轻,运维压力小一半。
Kafka核心架构与原理
1. 高吞吐的秘诀
- 顺序写磁盘 (Sequential I/O):Kafka 将消息追加写入日志文件末尾。操作系统对顺序写有深度优化,其速度甚至超过随机内存读写。
- 零拷贝 (Zero-Copy) :利用 Linux 的
sendfile()系统调用,数据可以直接从内核空间的 Page Cache 传输到网卡缓冲区,跳过了用户空间。这减少了 2 次上下文切换和 1 次数据拷贝,极大地降低了 CPU 消耗和 I/O 延迟。 - 页缓存 (Page Cache):Kafka 重度依赖操作系统的 Page Cache。只要内存足够,读写操作基本都在内存中完成,无需频繁触及物理磁盘。
- 批量处理与压缩:生产者会将多条消息打包成一个批次(Batch)发送,并可选用 Snappy、LZ4 等压缩算法,有效减少网络传输开销。
2. 分区与并行处理
- Topic 与 Partition:Topic 是消息的逻辑分类,而 Partition 是其物理存储单元。一个 Topic 可以有多个 Partition,分布在不同的 Broker 上,这是 Kafka 实现水平扩展和高并发的基础。
- 并行度:分区数决定了 Topic 的最大消费并行度。生产者通过指定 Key 来决定消息路由到哪个分区,从而保证相同 Key 的消息在同一个分区内,实现局部有序。
3. 元数据管理:从 Zookeeper 到 KRaft
- Zookeeper 模式 (旧):依赖外部 Zookeeper 集群来管理 Broker 状态、Topic 元数据等。架构复杂,且 ZK 本身可能成为性能瓶颈。
- KRaft 模式 (新,主流):Kafka 2.8+ 引入,3.x 版本成熟。KRaft (Kafka Raft) 是 Kafka 自研的基于 Raft 协议的元数据管理模块,完全去除了 Zookeeper 依赖。Kafka 节点自身通过选举产生 Controller,负责集群管理,架构更简洁,扩展性更强。
高可用与可靠性保障
1. 副本机制 (Replication)
- Leader/Follower:每个 Partition 有多个副本,其中一个为 Leader,负责所有读写请求;其余为 Follower,只负责从 Leader 同步数据。
- ISR (In-Sync Replicas):这是一个动态的副本集合,包含 Leader 和所有与 Leader 同步延迟在阈值内的 Follower。只有 ISR 中的副本才有资格被选举为新的 Leader。
- 生产配置 :推荐设置
replication.factor=3和min.insync.replicas=2,确保即使一个副本宕机,数据依然安全。
2. 生产者可靠性 (acks)
生产者的 acks 参数决定了消息写入的可靠性级别:
acks=0:发后即忘,速度最快,但可能丢消息。适用于日志采集等不重要的场景。acks=1:只要 Leader 写入成功就返回。如果 Leader 宕机且 Follower 未同步,会丢失消息。acks=all(或-1):Leader 和所有 ISR 中的 Follower 都写入成功才返回。这是最可靠的模式,配合min.insync.replicas使用,可以确保消息绝不丢失。
3. 消费者可靠性 (Offset)
- 自动提交 vs. 手动提交 :默认自动提交位移可能导致消息丢失(读取后未处理完就提交了)或重复消费。生产环境建议关闭自动提交 ,在业务逻辑处理成功后再手动提交 Offset。
- 幂等性:消费者端需要实现幂等逻辑,以应对网络抖动等原因导致的消息重复投递。
环境规划
准备三台机器,搭建一个高可用的集群。这里要注意:KRaft 模式下,节点既可以是 Broker(存数据),也可以是 Controller(管元数据)。 为了高可用,通常把这三个节点配置成"混合模式"(即:既干活又管事)。
| 主机名 | 推测 IP 地址 | Node ID | 角色 |
|---|---|---|---|
| test-111 | 192.168.174.111 | 1 | Broker + Controller |
| test-112 | 192.168.174.112 | 2 | Broker + Controller |
| test-113 | 192.168.174.113 | 3 | Broker + Controller |
一、基础环境准备(所有节点执行)
1. 配置 Hosts 解析
在三台服务器上分别执行,确保节点间可以通过主机名通信:
cat >> /etc/hosts << EOF
192.168.174.111 test-111
192.168.174.112 test-112
192.168.174.113 test-113
EOF2. 安装 JDK 与 Kafka
建议安装 JDK 11 或 17(Kafka 3.8 推荐),并下载 Kafka 3.8.0:
# 1. 安装 JDK (以 OpenJDK 11 为例)
yum install -y java-11-openjdk-devel
# 2. 下载并解压 Kafka 3.8.0
cd /opt
wget https://mirrors.huaweicloud.com/apache/kafka/3.8.0/kafka_2.12-3.8.0.tgz
tar -zxvf kafka_2.12-3.8.0.tgz
mv kafka_2.12-3.8.0 /usr/local/kafka
# 3. 创建数据目录
mkdir -p /data/kafka-logs
chmod 777 /data/kafka-logs二、配置 KRaft 集群
1. 生成集群 ID
仅在 test-111 上执行一次,生成唯一的集群标识符:
/usr/local/kafka/bin/kafka-storage.sh random-uuid
2. 修改配置文件
KRaft 模式使用 config/kraft/server.properties。你需要分别在三个节点上修改该文件,注意 node.id 和 advertised.listeners 的区别。
节点 1 (test-111) 配置:
vim /usr/local/kafka/config/kraft/server.properties
# 1. 角色定义:同时作为 Broker 和 Controller
process.roles=broker,controller
# 2. 节点 ID (三台机器必须不同)
node.id=1
# 3. 监听器配置
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
# 4. 对外广播地址 (修改为当前主机名)
advertised.listeners=PLAINTEXT://test-111:9092
# 5. 控制器选举配置 (列出所有节点)
controller.quorum.voters=1@test-111:9093,2@test-112:9093,3@test-113:9093
controller.listener.names=CONTROLLER
# 6. 数据存储路径
log.dirs=/data/kafka-logs
# 7. 安全协议映射
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
inter.broker.listener.name=PLAINTEXT节点 2 (test-112) 配置:
修改点:node.id=2 和 advertised.listeners
process.roles=broker,controller
node.id=2
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
advertised.listeners=PLAINTEXT://test-112:9092
controller.quorum.voters=1@test-111:9093,2@test-112:9093,3@test-113:9093
log.dirs=/data/kafka-logs
# ...其他配置同上节点 3 (test-113) 配置:
修改点:node.id=3 和 advertised.listeners
process.roles=broker,controller
node.id=3
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
advertised.listeners=PLAINTEXT://test-113:9092
controller.quorum.voters=1@test-111:9093,2@test-112:9093,3@test-113:9093
log.dirs=/data/kafka-logs
# ...其他配置同上三、格式化与启动
1. 格式化存储目录
在所有三个节点上分别执行(使用第一步生成的 UUID):
/usr/local/kafka/bin/kafka-storage.sh format -t RqGufrkOSVCsJ8fL8w8riw -c /usr/local/kafka/config/kraft/server.properties四、创建 Systemd 服务
vim /usr/lib/systemd/system/kafka.service
[Unit]
Description=Apache Kafka Server (KRaft)
After=network.target
[Service]
Type=simple
User=root
Environment="JAVA_HOME=/usr/lib/jvm/java-11-openjdk"
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/kraft/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target启动服务:
systemctl daemon-reload
systemctl start kafka
systemctl enable kafka
配置环境变量:
cat > /etc/profile.d/kafka.sh << "EOF"
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
EOF
source /etc/profile验证集群状态
在任意节点查看集群元数据状态:
kafka-metadata-quorum.sh --bootstrap-server test-111:9092 describe --status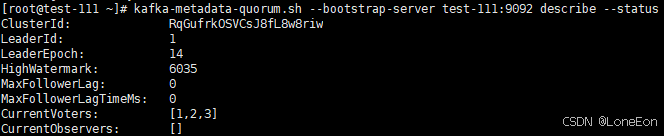
KRaft 模式确实比老版本清爽很多,少了 ZK 的干扰,排查问题也更直接。只要 kafka-metadata-quorum.sh 检查通过,这个集群就可以放心投入业务使用了