机器学习概述
文章目录
-
- 机器学习概述
- [1. 机器学习概述](#1. 机器学习概述)
- [2. 机器学习的分类](#2. 机器学习的分类)
- [3. 机器学习术语与概念](#3. 机器学习术语与概念)
- [4. 机器学习常见算法](#4. 机器学习常见算法)
-
- 有监督学习-线性回归
- 有监督学习-逻辑回归
- 有监督学习-KNN
- 有监督学习-朴素贝叶斯
- 有监督学习-SVM
- 有监督学习-决策树
- 无监督学习-聚类算法
- [无监督学习- k-means](#无监督学习- k-means)
- [无监督学习- k-medoids](#无监督学习- k-medoids)
- [无监督学习- 层次聚类](#无监督学习- 层次聚类)
- [无监督学习- DBSCAN](#无监督学习- DBSCAN)
前言
本章内容包括对机器学习基础,发展历程,应用场景,开发流程和经典学习算法分类等概念,并开始系统机器学习的第一步,掌握其涉及的基本概念和术语,并对各个经典机器学习算法进行系统学习。
1. 机器学习概述
机器学习概念
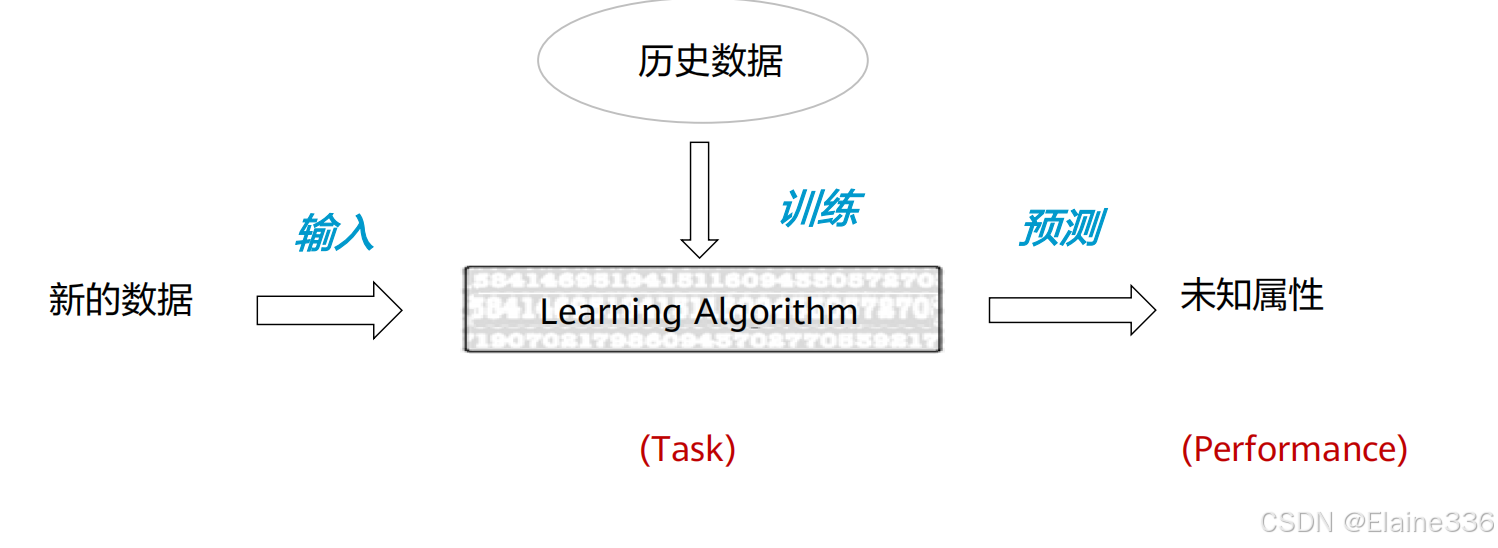
机器学习概述
- 人工智能、机器学习、深度学习关系
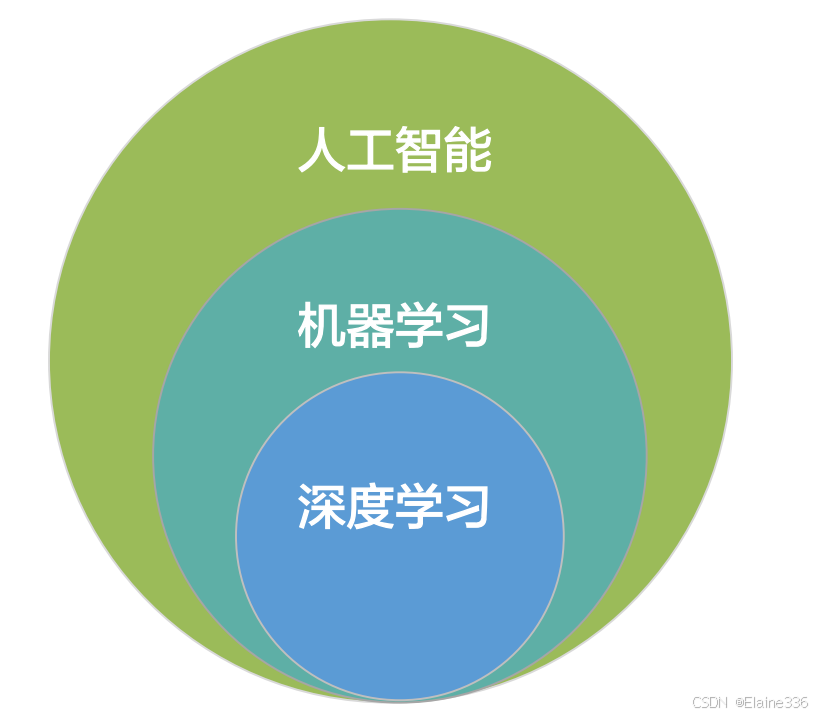
机器学习概述

机器学习概述
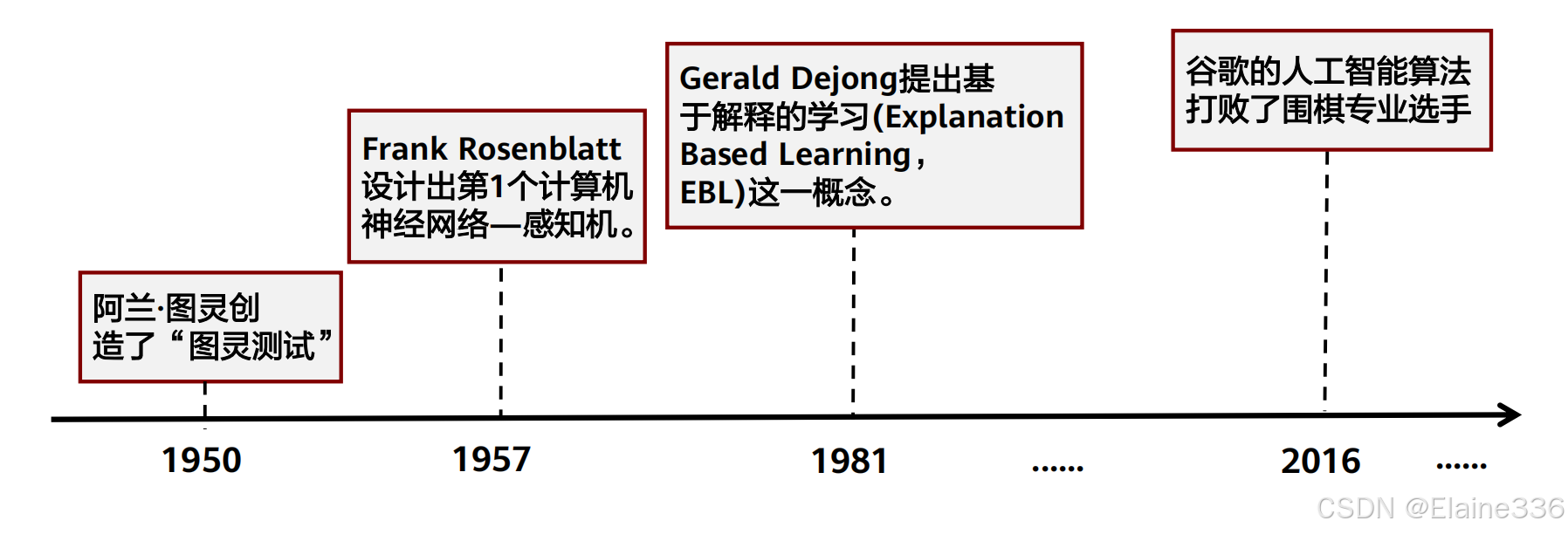
- 机器学习的发展史
机器学习概述 - 机器学习应用场景
- 属性预测,价值评估,客户分层,异常检测,疾病检测,风险管理,个性化推荐,垃圾信息识别,智能排序,等级评分,流失预警,文本识别,图像识别,量化交易分析,用户画像,路径优化,店铺选址,资源优化,作诗作歌词,恶意软件识别,精准营销,智能投顾,搜索优化,诈骗检测,关联匹配等等。
2. 机器学习的分类
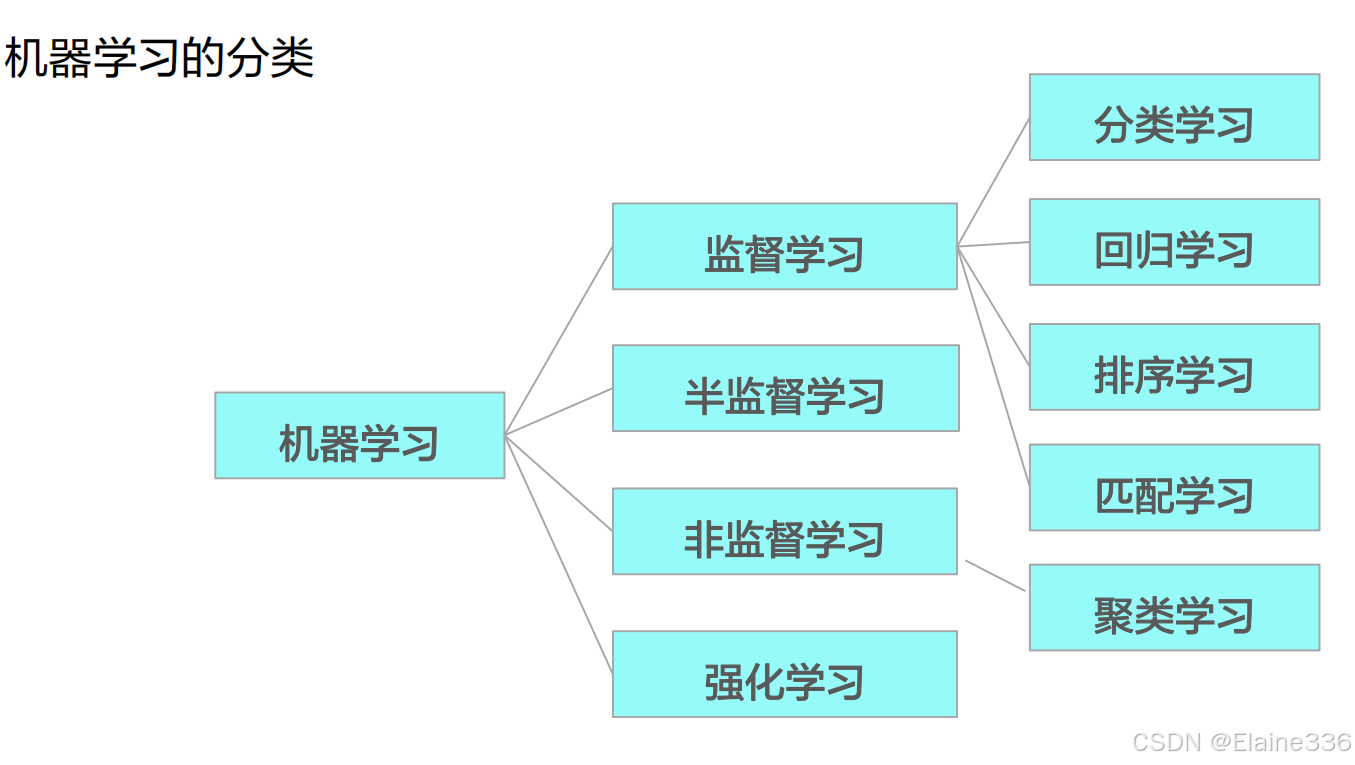
机器学习的分类
- 如下两图,有什么相同与不同之处?
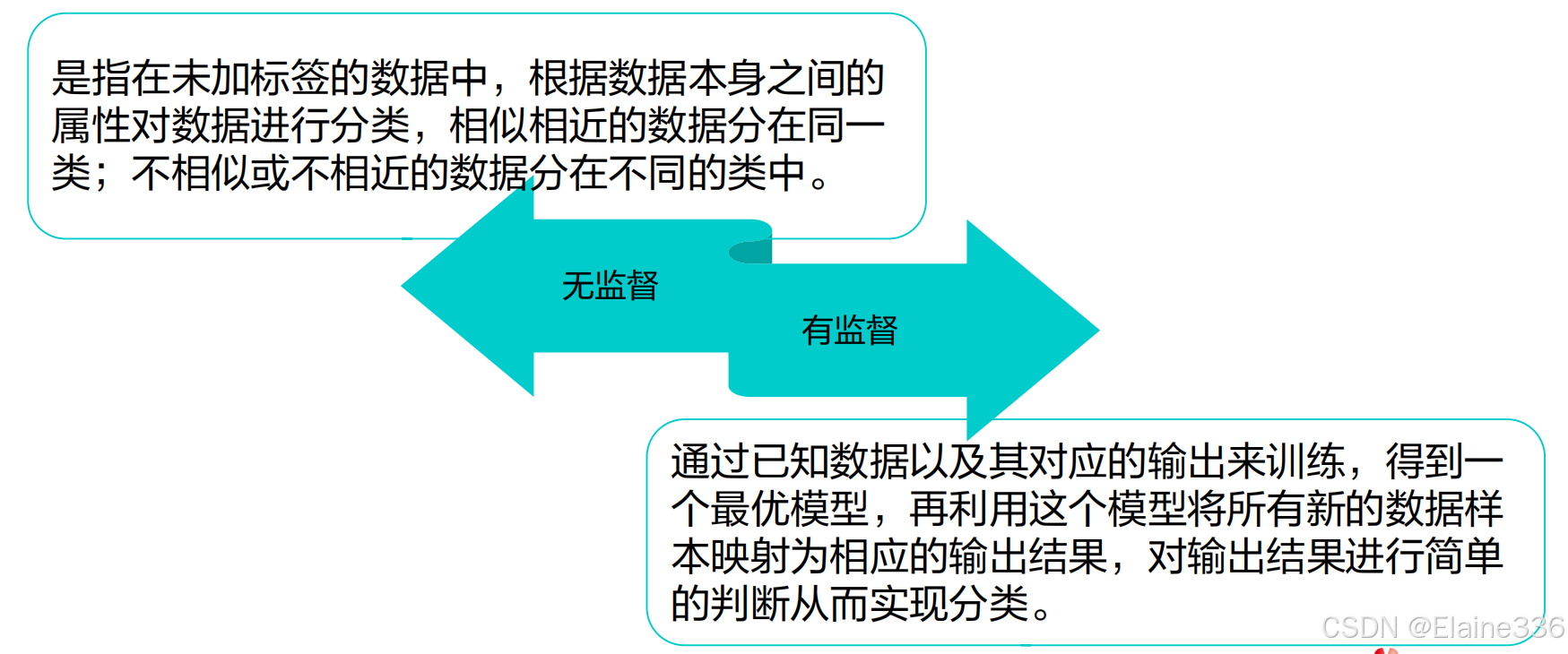 机器学习的分类
机器学习的分类 - 强化学习训练过程
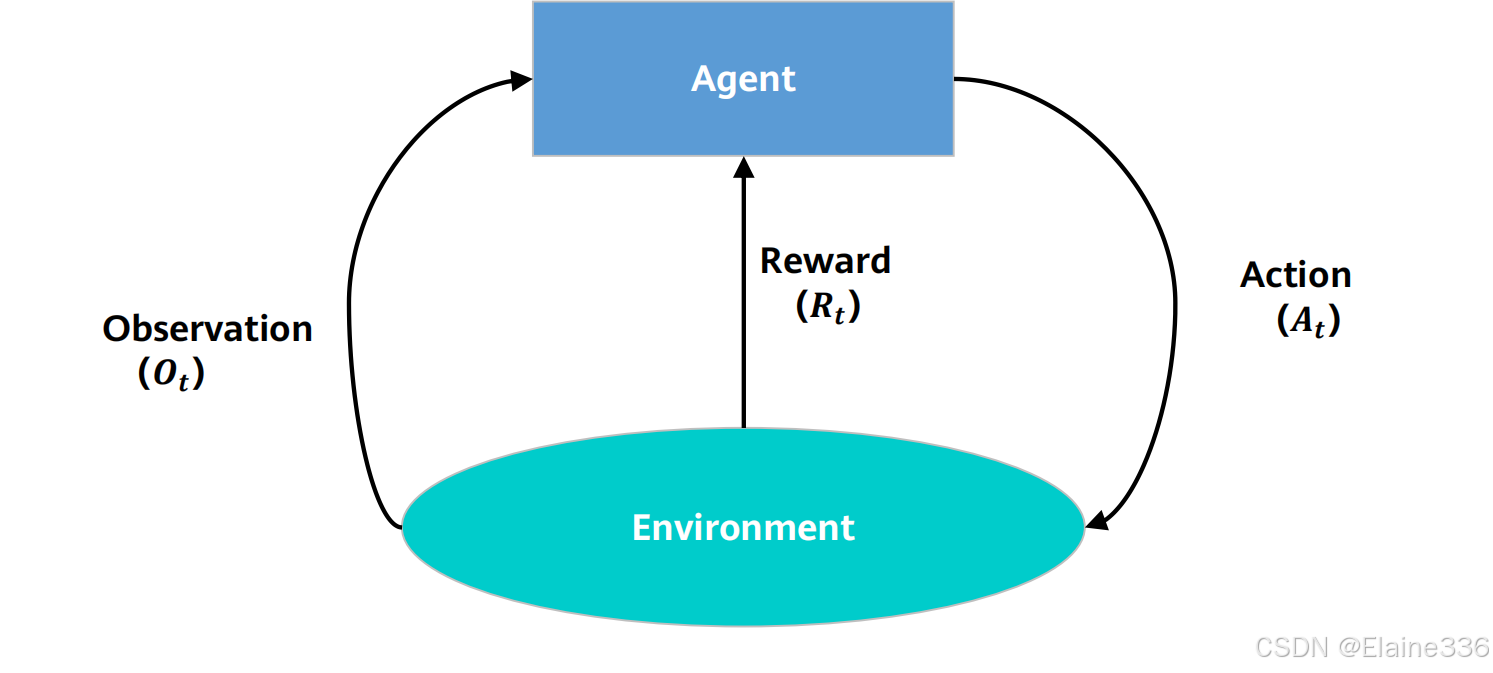
机器学习的分类
3. 机器学习术语与概念
机器学习的整体流程
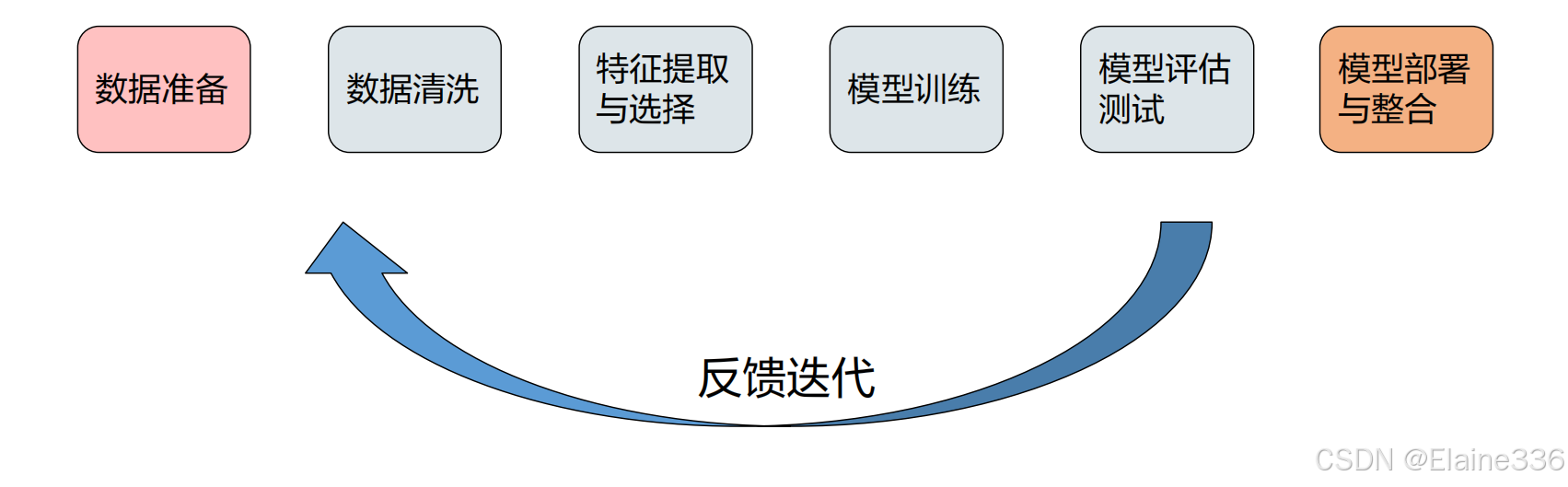
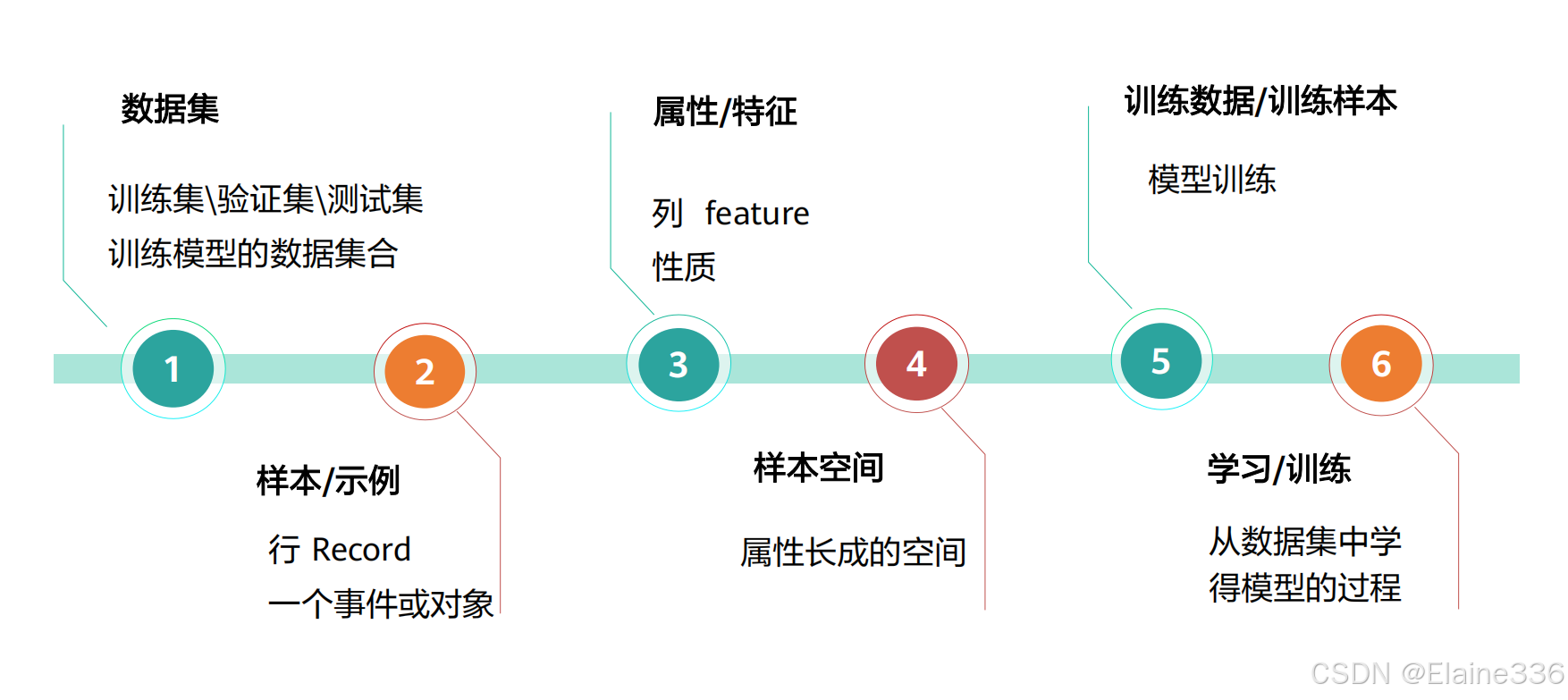
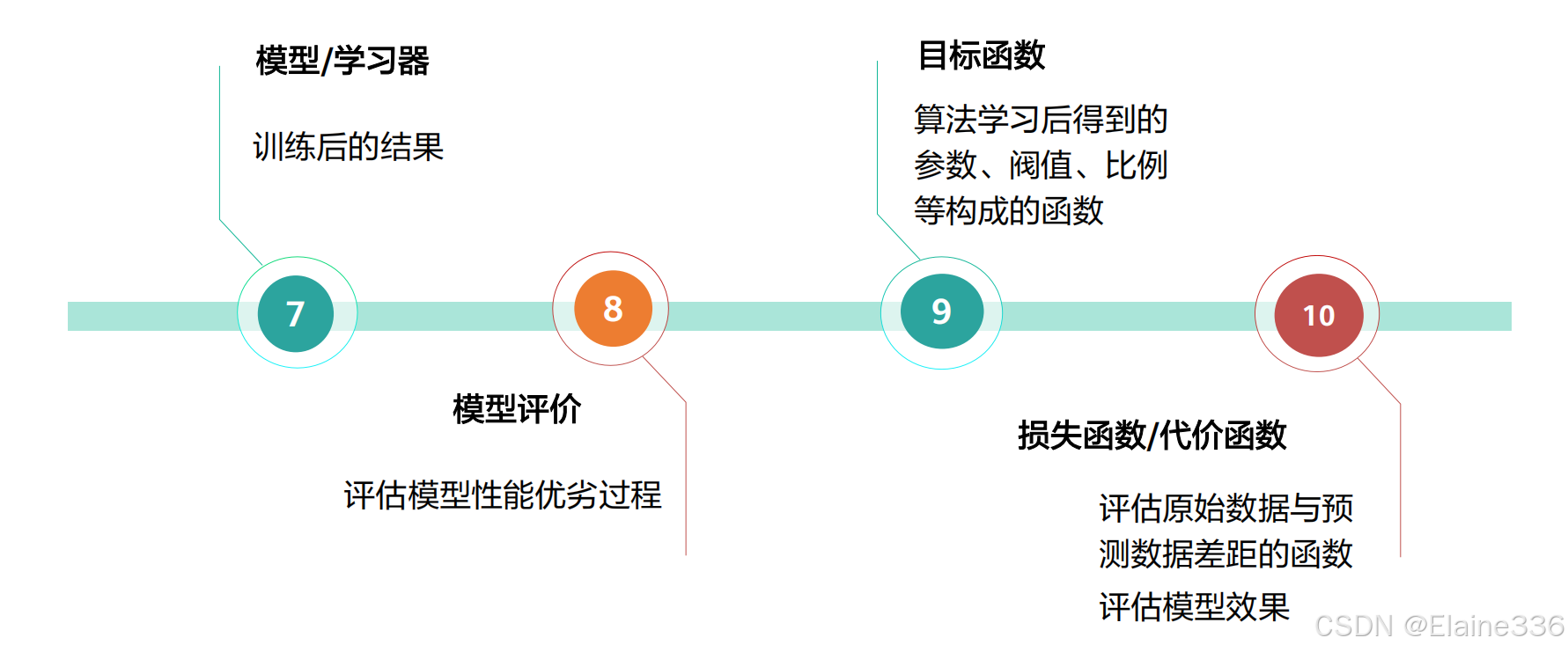
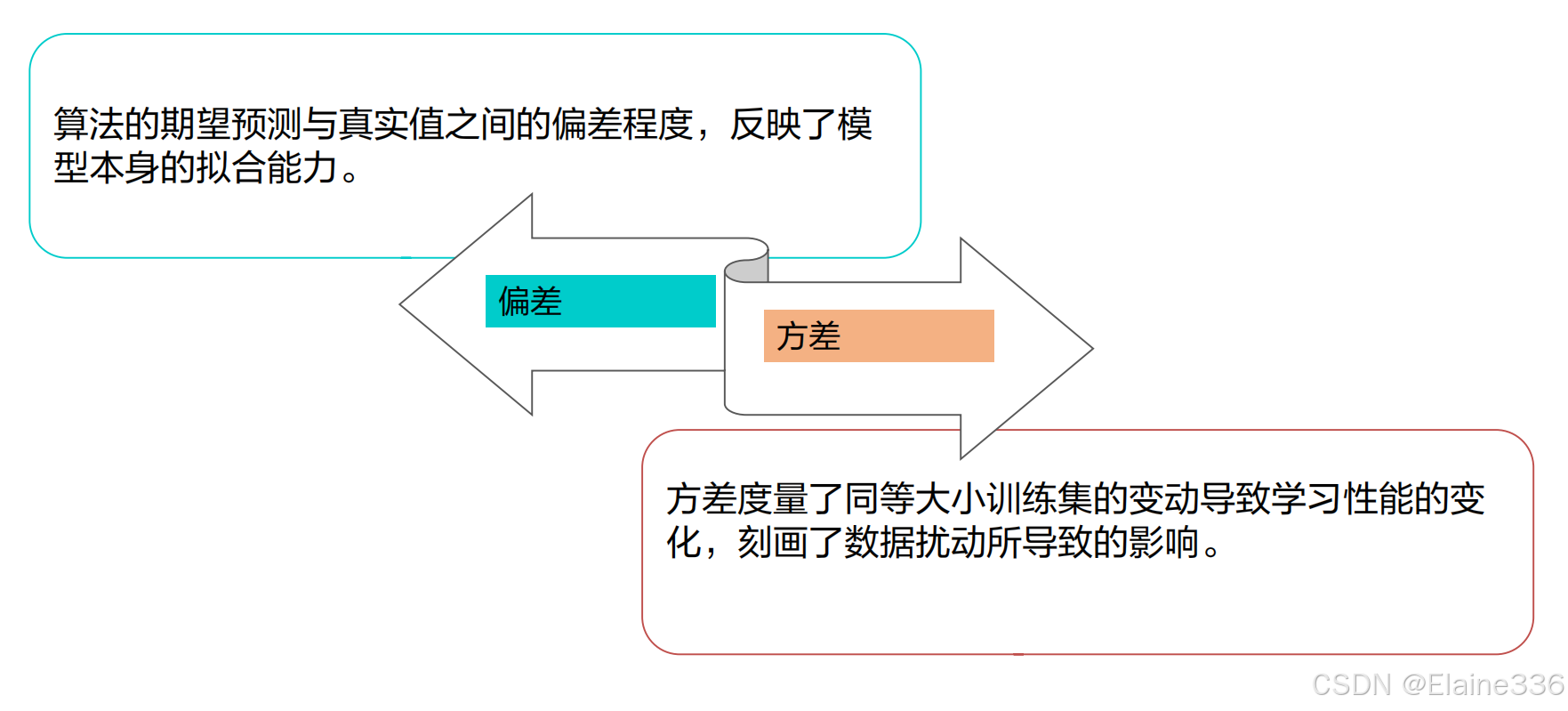
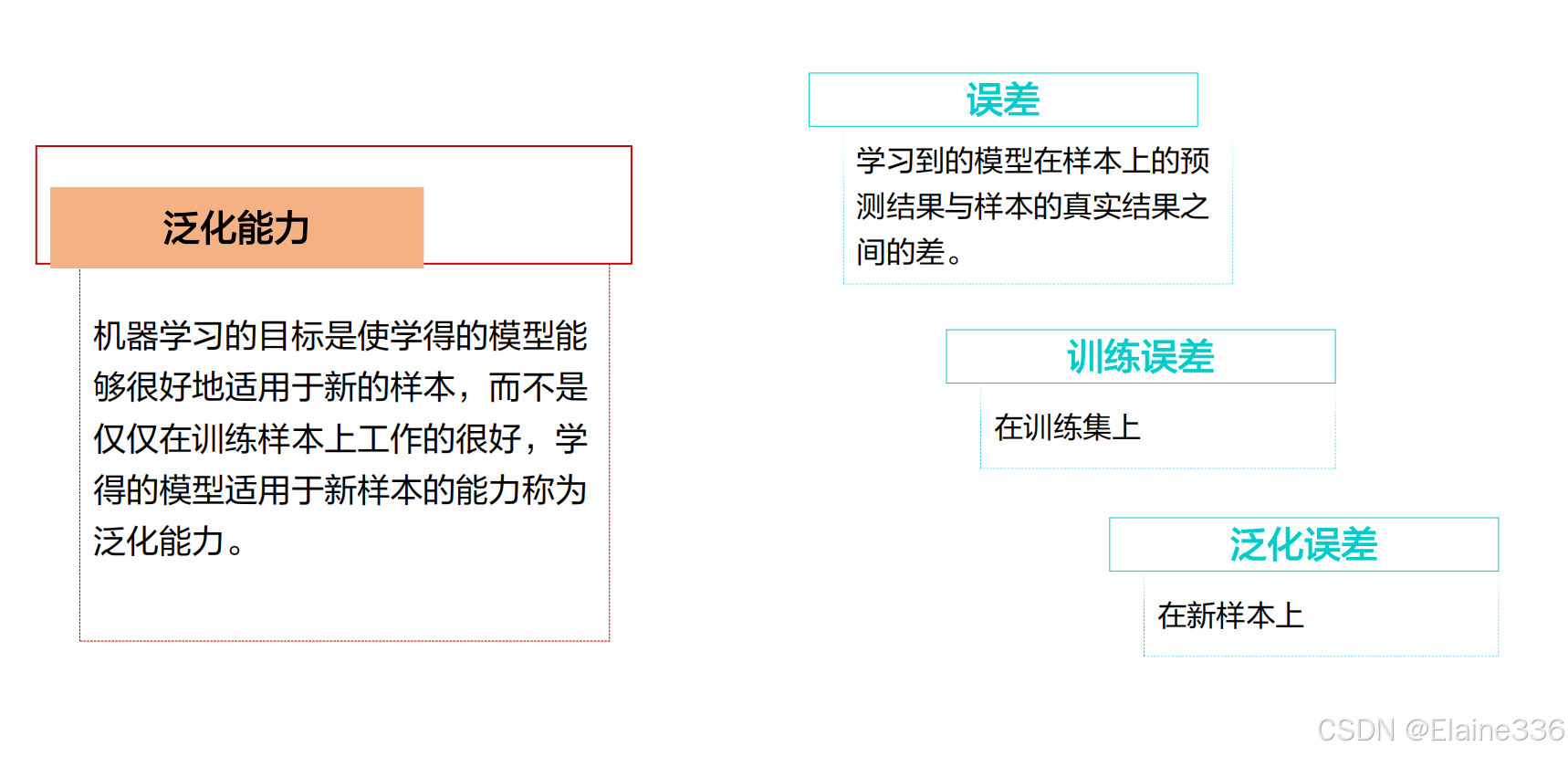
机器学习术语与概念
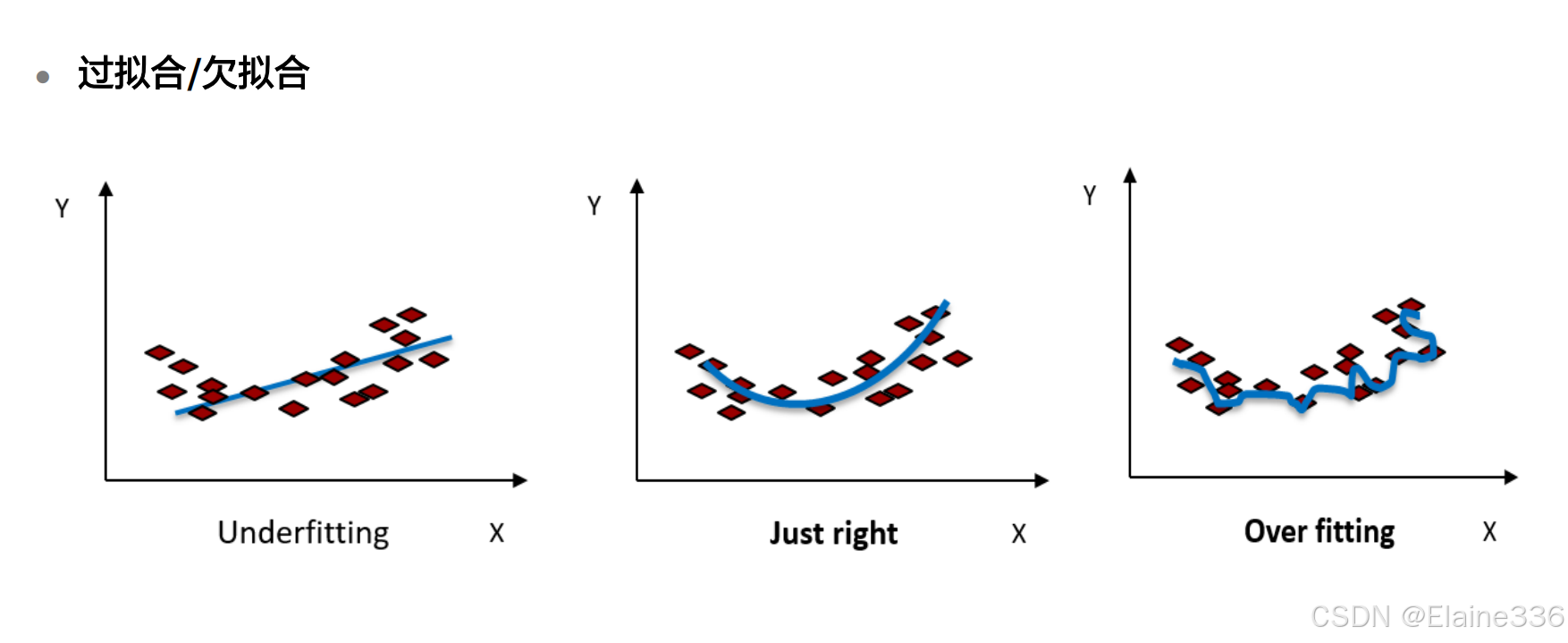
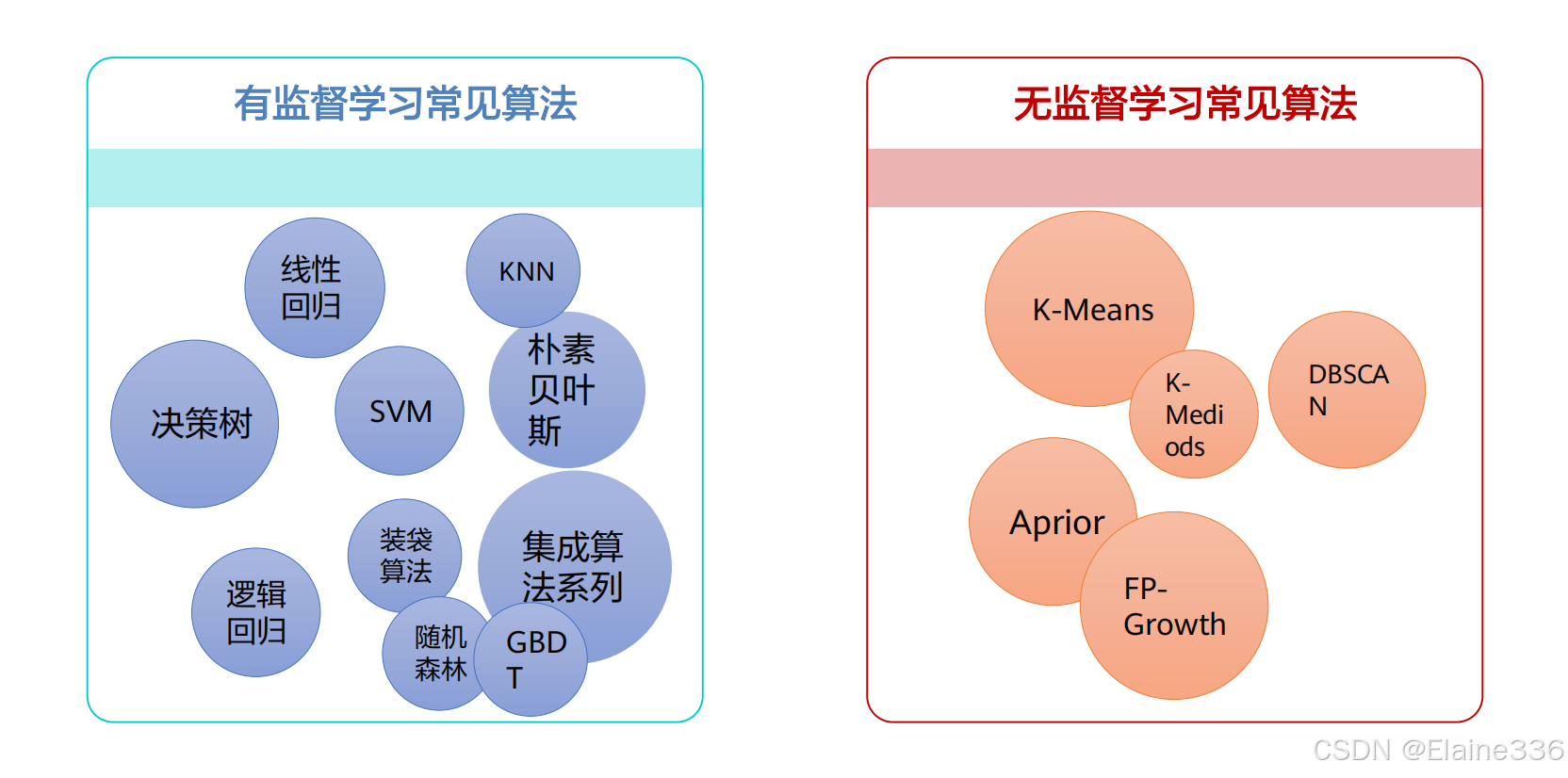
4. 机器学习常见算法
有监督学习-线性回归
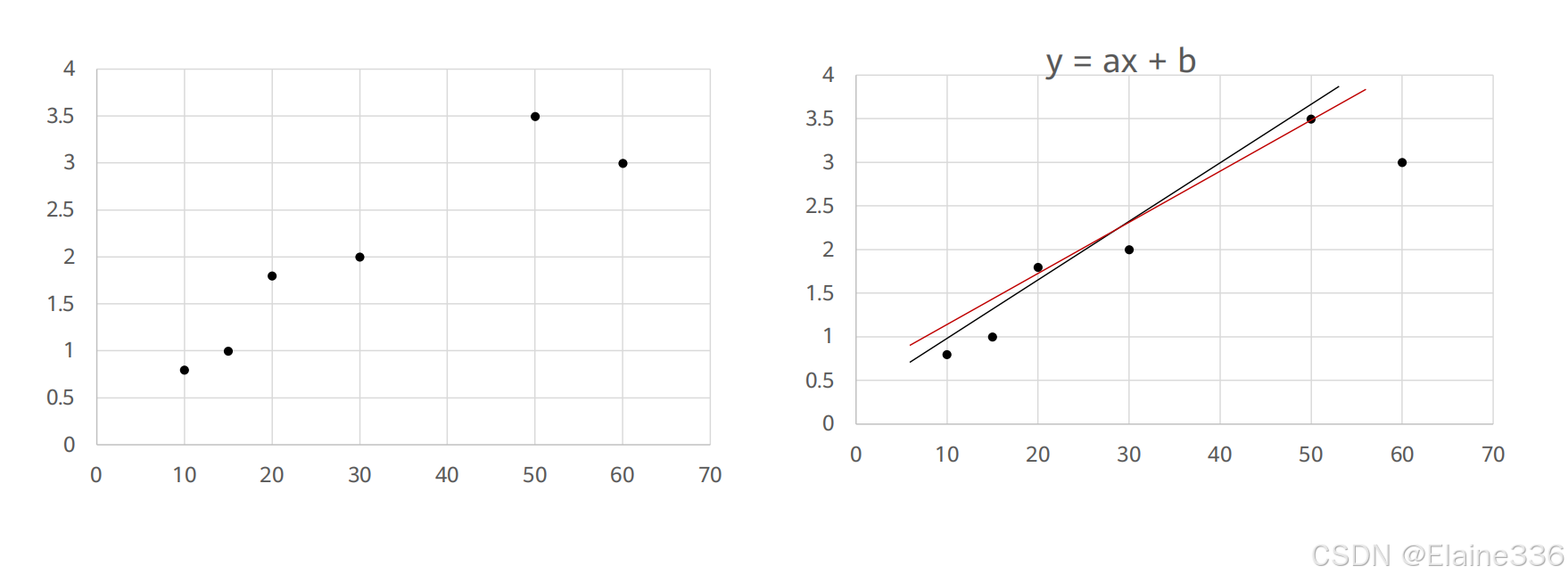
- 试图找到一条最合适的线来拟合下图(左)中所有的数据点?
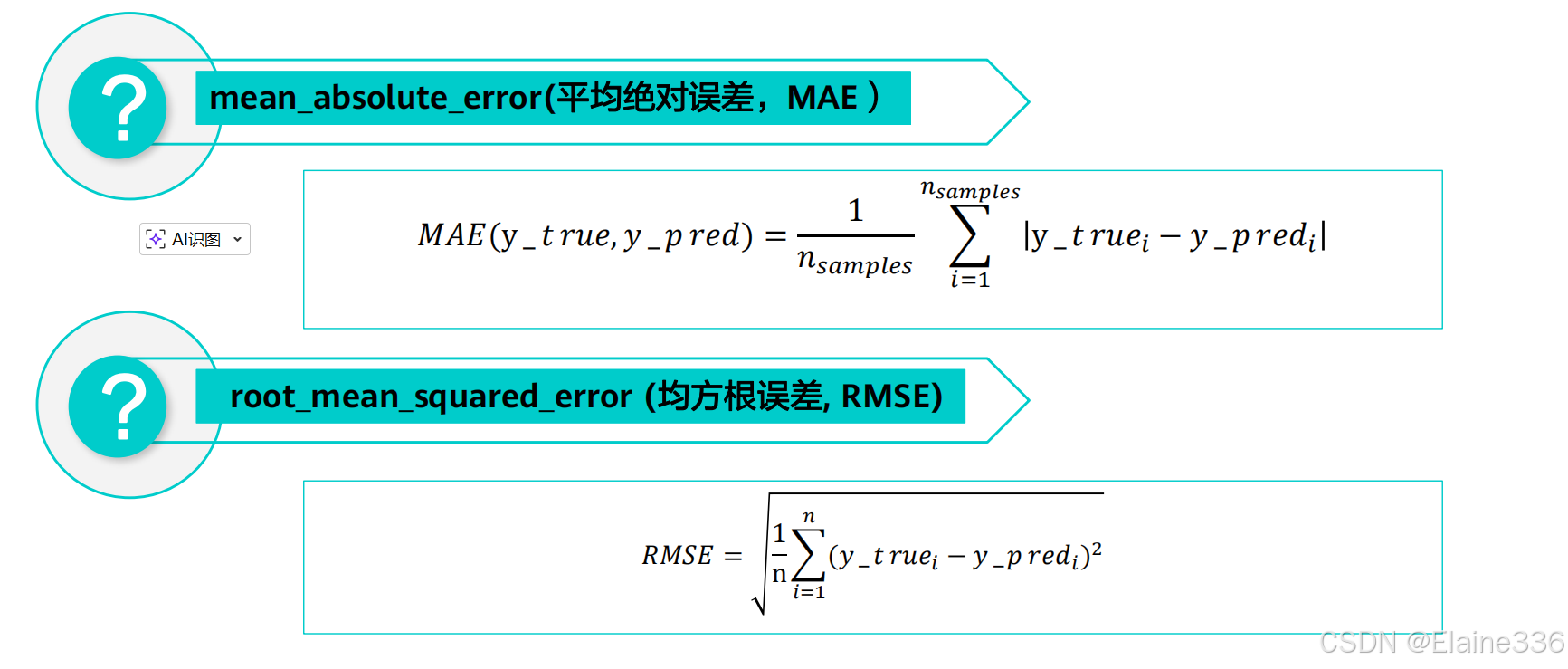
有监督学习-线性回归 - 线性回归的模型评估方法
有监督学习-逻辑回归
- 线性回归模型通常是处理因变量是连续变量的问题,如果因变量是定性变量,线性回归模型就不再适用了,需采用逻辑回归模型解决。
-
- 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,它实际上是属于一种分类方法。
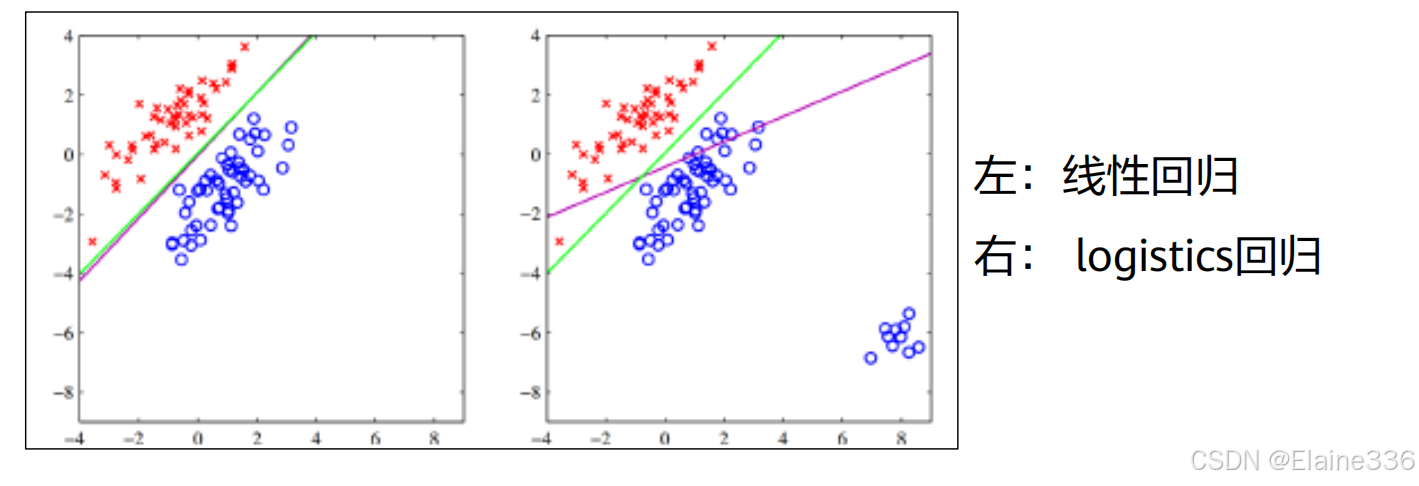
- 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,它实际上是属于一种分类方法。
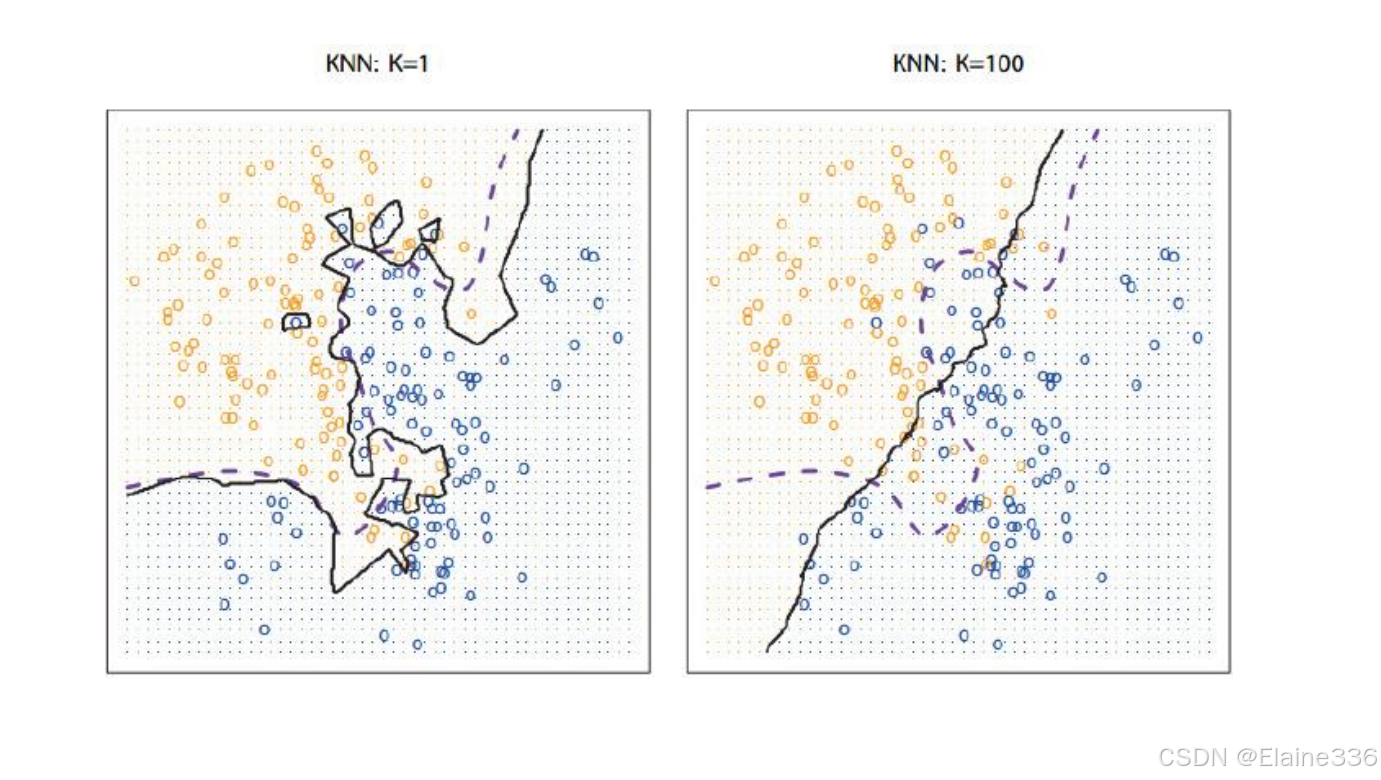
有监督学习-KNN
- KNN(K-Nearest Neighbors)即K近邻算法,是一种基本的分类与回归方法。其核心思想是给定训练数据集,对新输入实例,在训练数据集中找到与它最邻近的K个实例,根据这K个实例类别进行预测。用于分类时,多数表决决定类别;用于回归时,取均值作为预测值。
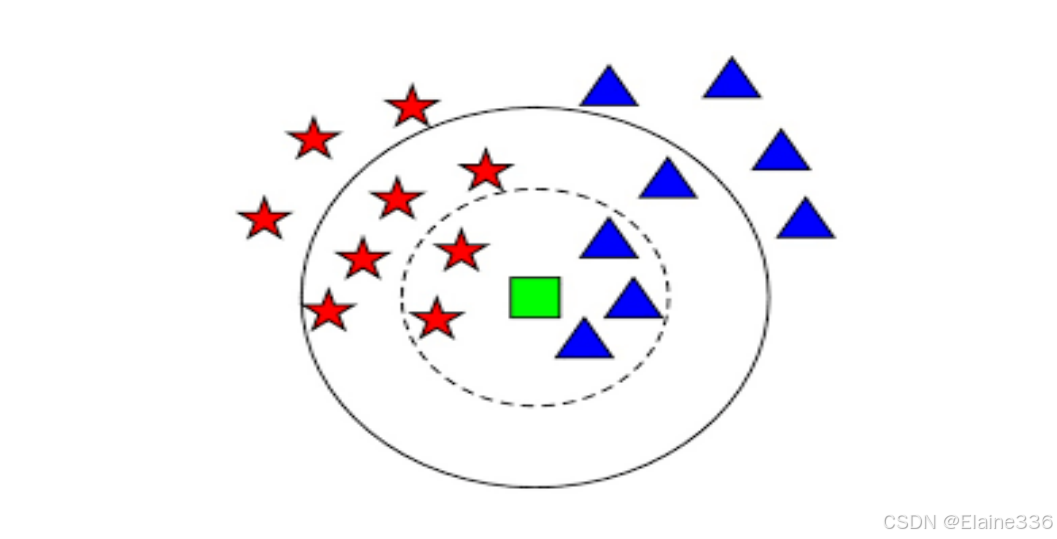
- 1.K预设值取多少
- 2.如何定义距离
- 3.分类决策规则
有监督学习-朴素贝叶斯
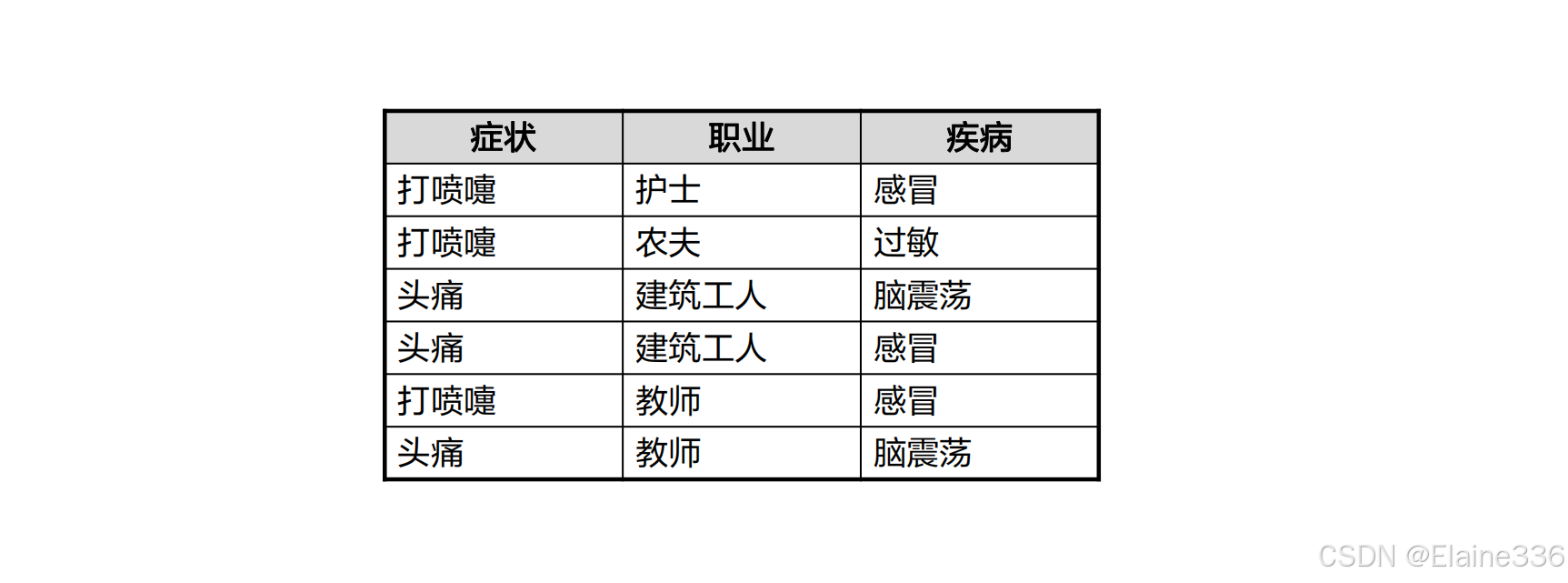
- 病人分类:又来了第七个病人,是打喷嚏的建筑工人。请问他患上感冒的概率有多大?
有监督学习-朴素贝叶斯 - 朴素贝叶斯算法(Naive Bayes):朴素贝叶斯是一种简单的多类分类算法,基于贝叶斯定理,并假设特征之间是独立的。给定样本特征𝑋,样本属于类别𝐻的概率是:
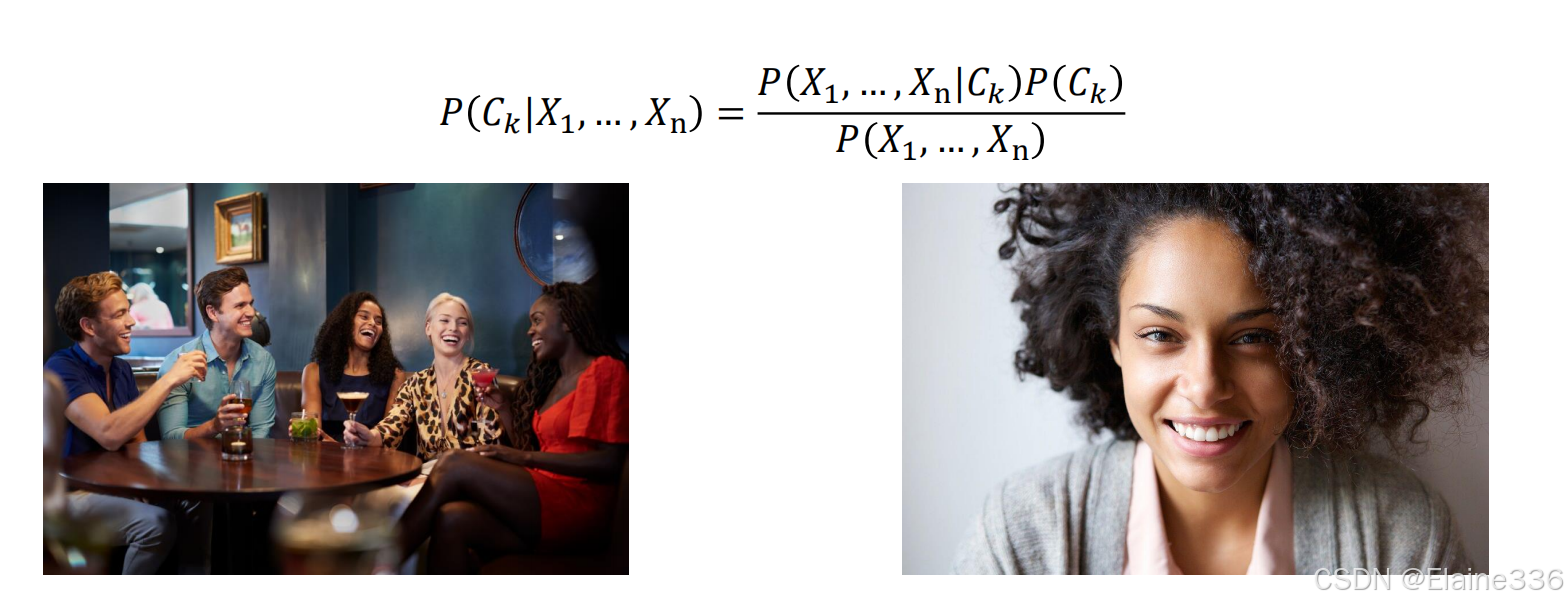
有监督学习-SVM
- 在线性不可分的情况下,得到非线性SVM主要有两个步骤:
- 支持向量机通过某种事先选择的非线性映射(核函数)将输入变量映射到一个高维特征空间。
- 在这个空间中构造最优分类超平面。
有监督学习-决策树
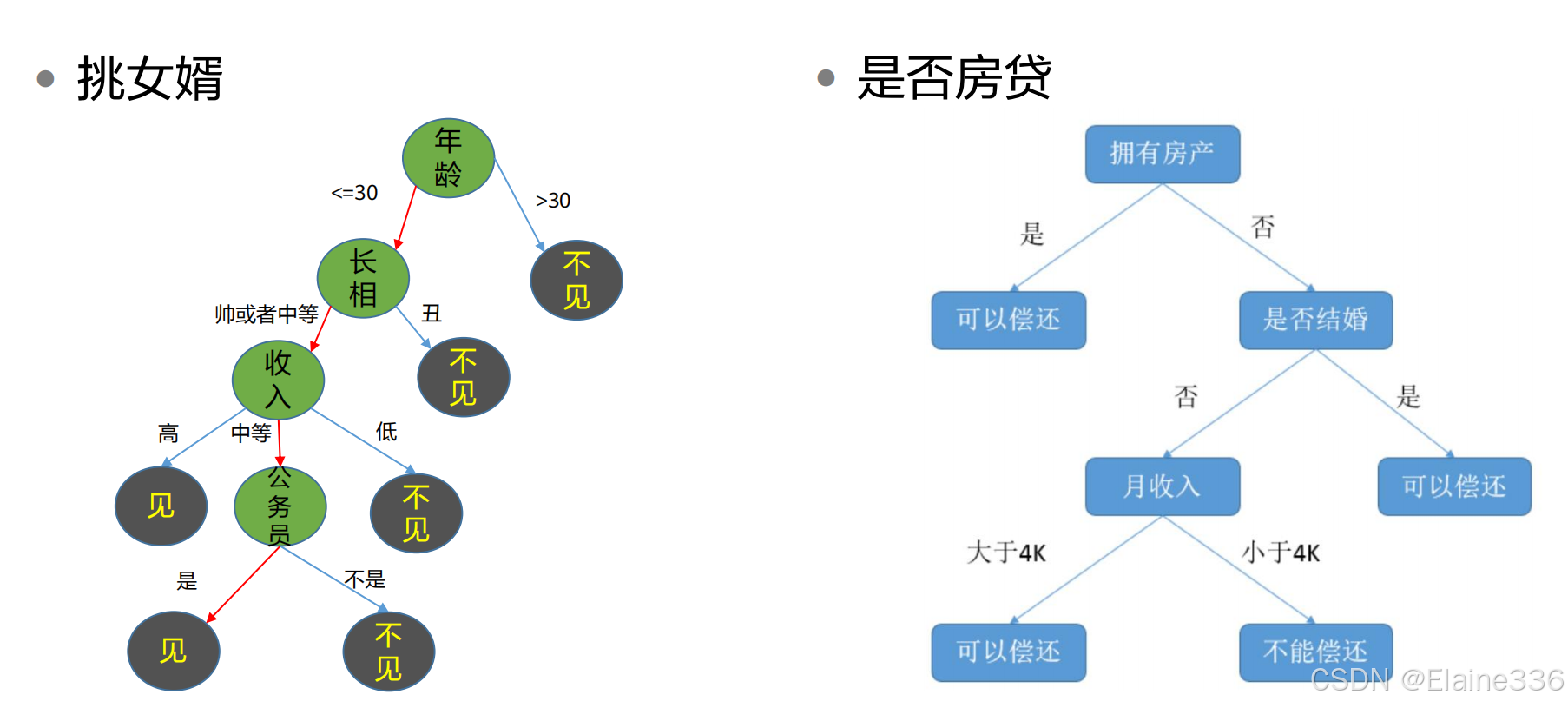
无监督学习-聚类算法

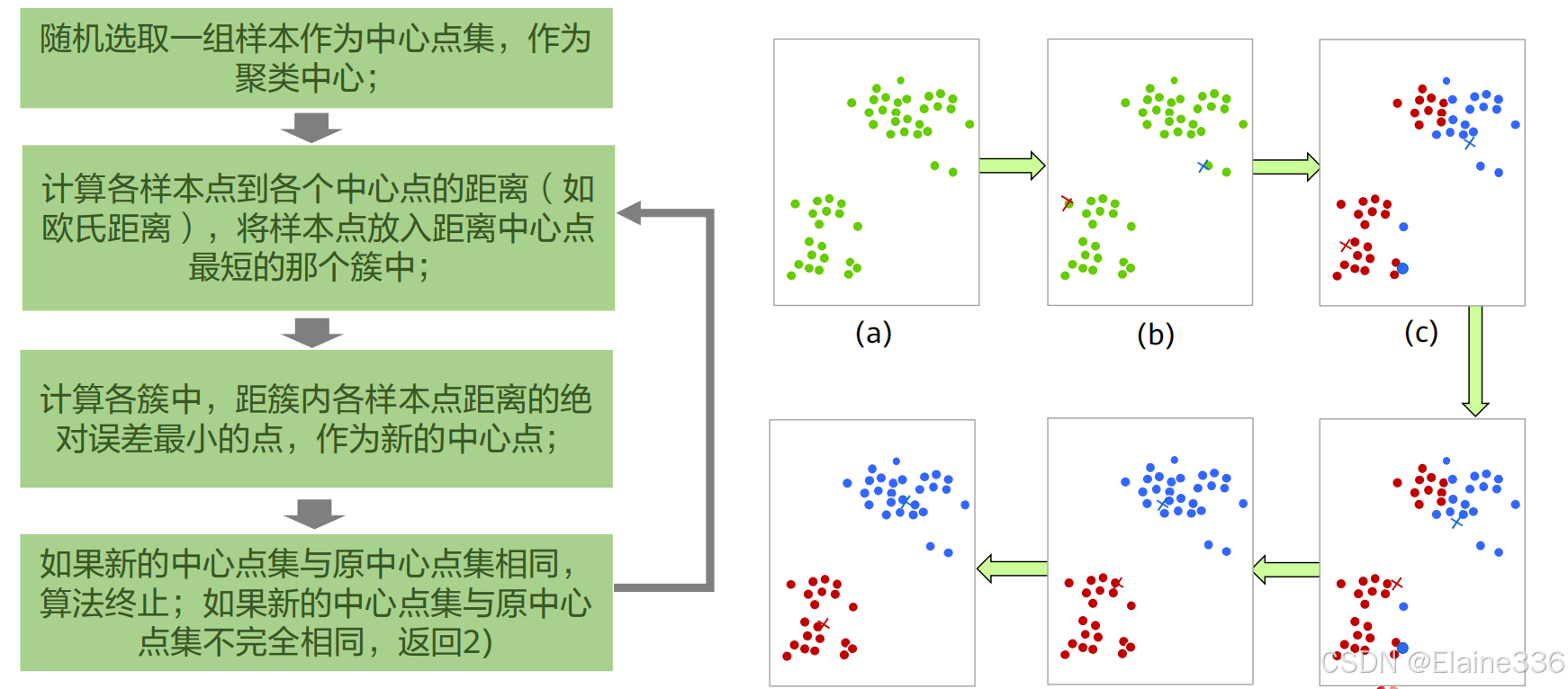
无监督学习- k-means

无监督学习- k-medoids
- K-Mediods是基于原型的另一种聚类算法,也是对K-Means算法的一种改进。
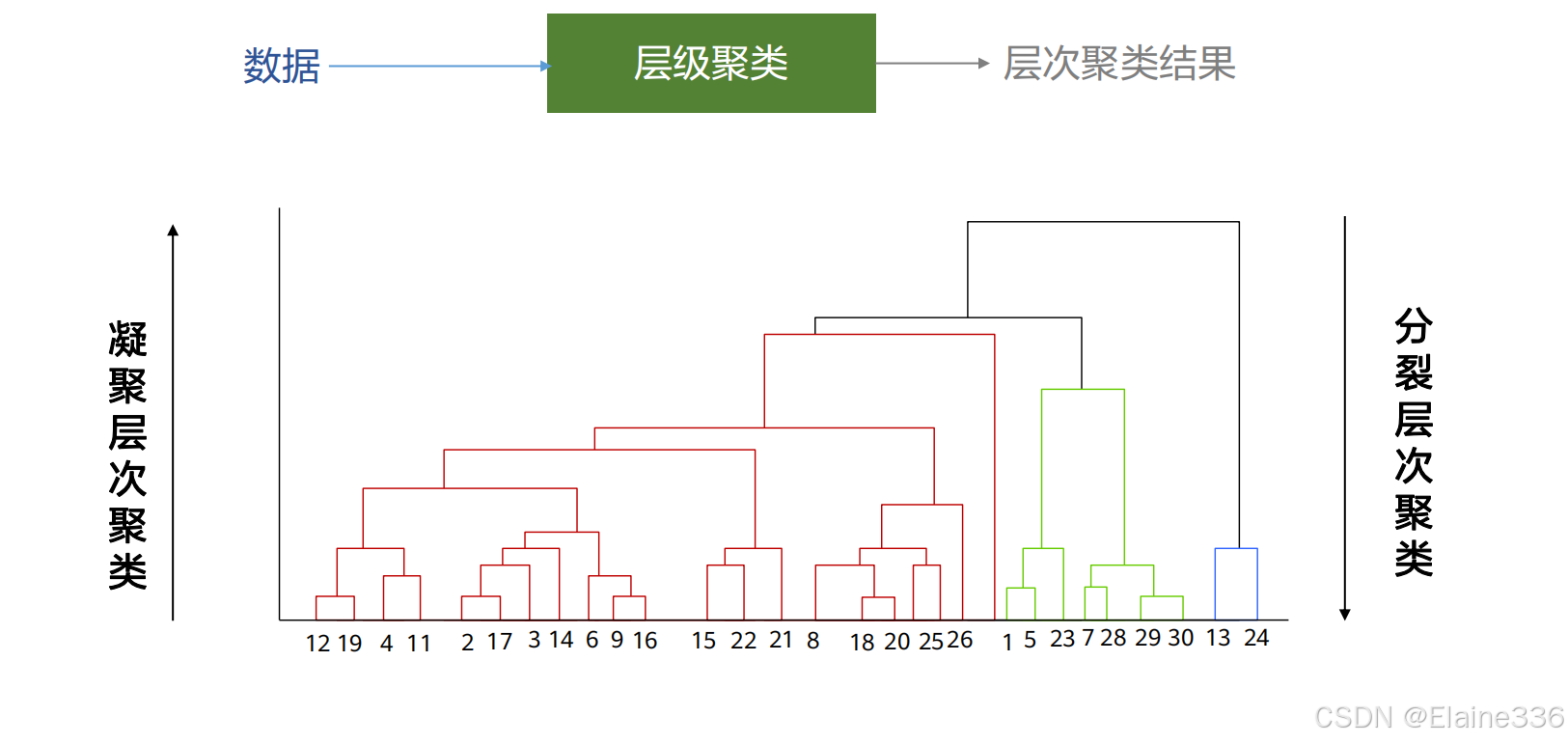
无监督学习- 层次聚类
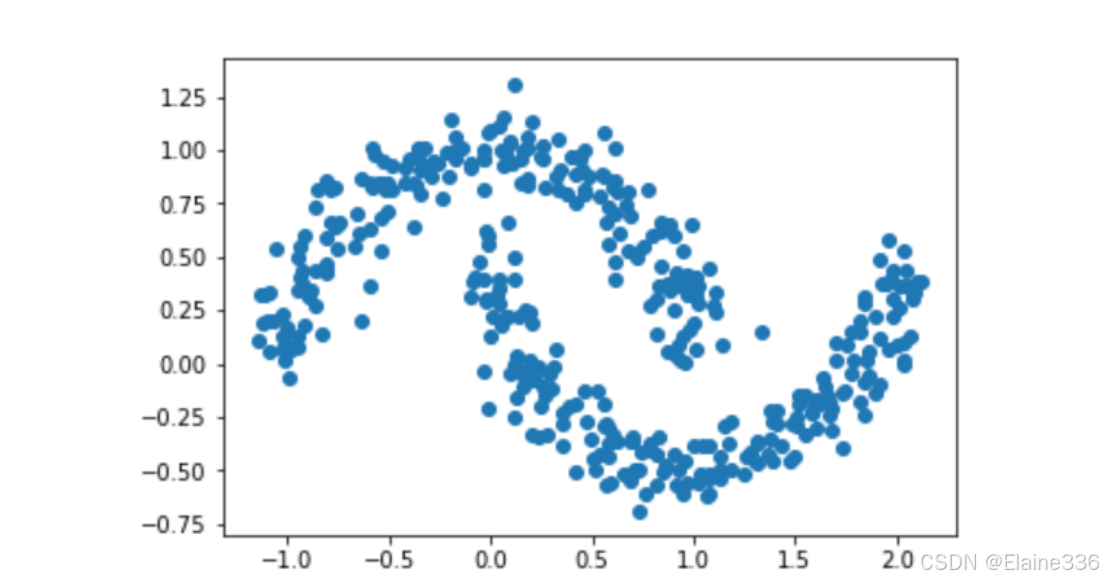
无监督学习- DBSCAN
- 密度聚类的思想不同于K-Means,它是通过聚类的簇是否紧密相连来判断样本点是否属于一个簇,代表性的算法就是DBSCAN,它基于一组邻域参数来判断某处样本是否是紧密。
- 文章内容均引用华为云HCCDA-AI内容:若有侵权,联系即删