这篇文章讲什么
有个任务看起来像目标检测,但实际上是一道几何题 + 一道指派问题。
本文复盘一个完整的图像理解管道设计过程。核心不是"怎么绕过某系统"------而是四个更通用的决策:
- 什么时候 DL 不是最优解(强结构 × 低泛用场景,经典 CV 反而更稳)
- 特征域选择(像素域 vs 边缘域,选错域直接跪)
- 无监督特征提取 + 匹配(PCA + 代价矩阵 + Hungarian)
- 管道可观测性(怎么记日志、画图、统计,才能科学地调参而不是凭感觉)
技术栈:OpenCV + InSPyReNet + PCA + Hungarian。验证码是一个好的案例,因为它的目标函数干净、约束明确、评测标准清晰。
起因:公司同事用龙虾时提需求------有些需要登录的自动化抓取总卡在登录验证码上,想远程飞书帮忙自动登录。看来直接 prompt 并没解决。于是有了这个task。
本文所有测试均在 Geetest 公开 demo 页面完成,技术交流为目的,不提供开箱即用的绕过工具。
问题分解
目标:自动通过两类图像验证------Slider(滑动拼图)和 BigImage(图标方向匹配)。
先给结论:
makefile
Slider: Canny + 模板匹配,~300 行代码。核心决策:换域不换方法。
BigImage: InSPyReNet 抠图 + PCA 主轴 + Hungarian 指派,跨 DL/线性代数/组合优化。很多人第一反应是 pip install ultralytics 然后标数据。但这两个题的结构太强了------固定规则、固定映射、已知类数------检测类模型不是最优方案,详见 §2.1 分析。我没有实际训 YOLO,以下基于问题结构的推理------如果读者跑过对比实验,很欢迎补充数据。
一、Slider --- 像素域 → 边缘域,一个特征工程决策
Slider 的目标很简单:算出拖动距离 dx。直觉上拿到拼图块直接在背景图上滑窗匹配:
python
result = cv2.matchTemplate(bg_gray, piece_gray, cv2.TM_CCOEFF_NORMED)跪了。 piece 和缺口从同一张图上切下来,像素值高度相关,匹配峰到处都是。
关键决策:换域。 从像素域切到边缘域,同一个 matchTemplate:
python
bg_edges = cv2.Canny(bg_gray, 100, 200)
piece_edges = cv2.Canny(piece_gray, 100, 200)
res = cv2.matchTemplate(bg_edges, piece_edges, cv2.TM_CCOEFF_NORMED)
_, max_val, _, max_loc = cv2.minMaxLoc(res)
if max_val > 0.15:
dx = max_loc[0] - piece_x_start - piece_offset_x # piece_offset_x: 拼图在canvas里的起始x,业务校准量
ini
像素域: [0x4A, 0x4B, 0x4C, ...] ← 缺口和周围几乎一样,匹配峰乱窜
边缘域: [ 0, 255, 0, ...] ← 缺口边界 = 梯度极值,信号干净Canny(100, 200) 是常用的经验值,在 Geetest demo 图上跑了几十张没翻车,就没细调。后来补了 50 次 Slider 测试来验证 max_val > 0.15 这个阈值:
ini
Slider max_val 分布 (N=50):
min=0.211 median=0.436 max=0.658
全部 > 0.15: 100%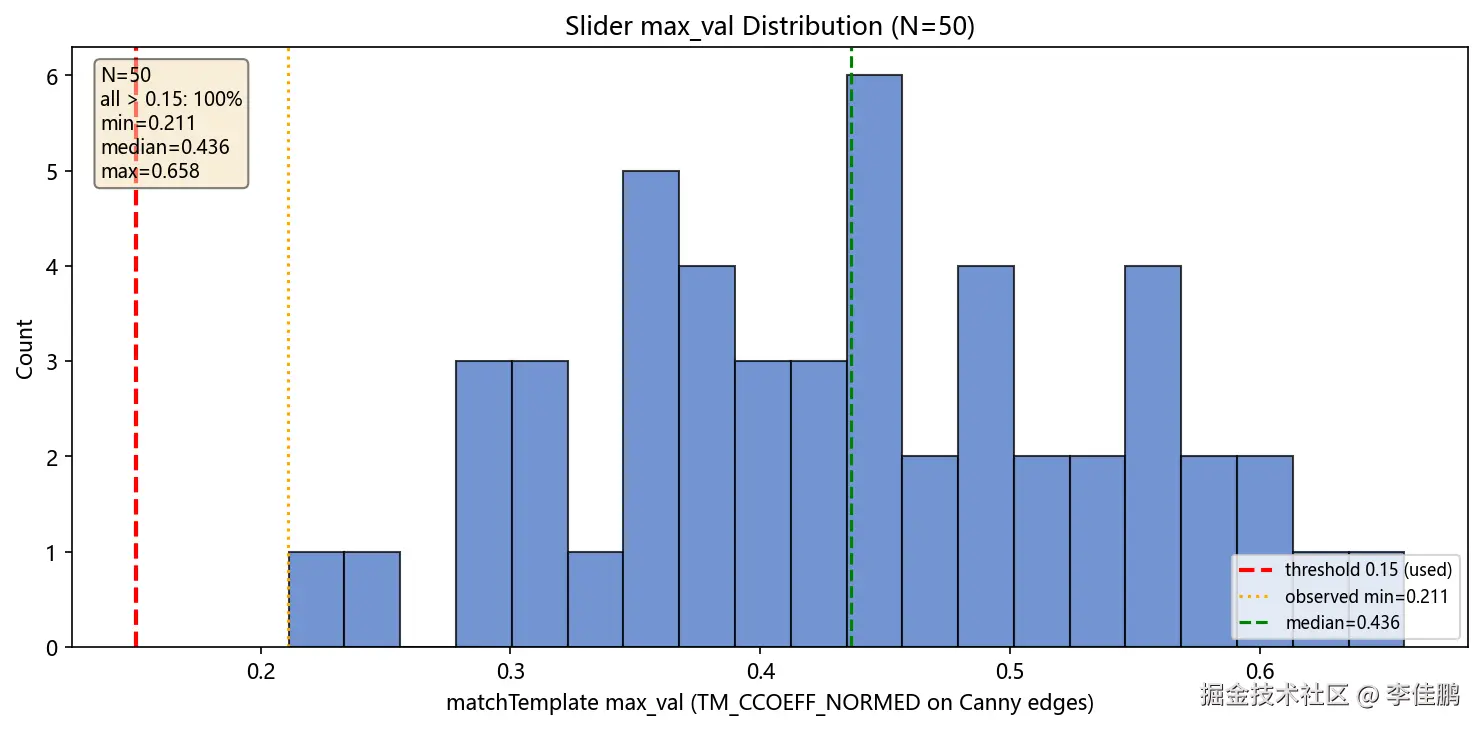
0.15 非常保守------观测到的最小值是 0.211,中位数 0.436。也就是说这个阈值其实可以提到 0.20 甚至 0.25,不会漏掉任何正确匹配,但能更激进地拒绝低置信度结果。不过对 Geetest demo 来说没必要------Canny 边缘在这个图集上太干净了,模板匹配几乎没有歧义。
当背景太花模板匹配失败时,兜底方案是轮廓启发式------实际测试中一次都没触发过,说明 Canny 这条主线在这个图集上完全够了。
Slider 的本质教训就一条: 表征决定上限。同一个匹配算法,像素域和边缘域准确率天差地别。这是"特征工程"最干净的案例。
二、BigImage --- 思路演变:从 WPS 抠图到匈牙利指派
这个题的解法不是一步到位的。思路经历了几次转向。
2.0 思考过程
第一步:解决"往哪点"。 灵感来自 WPS 的抠图工具------有一次用 WPS 给文档去背景,发现它把图标抠得干干净净。立刻想到:验证码的图标不也一样吗?抠出来 → 取质心 → 点击坐标就有了。这一步解决得很快。
第二步:解决"箭头方向"。 提示条上的箭头是标准几何形状,方向的 pattern 很明显------二值化 → 找轮廓 → 看凸包朝向。基础的 CV 技术就够了,没有卡住。
第三步:两个终极难题合在一起。 图标的方向怎么判断?每张图的三个图案各不相同------乌龟、飞机、蝴蝶......形态差异大到没法用一个简单几何规则覆盖,难道最终还是得上 DL?背景的干扰图标又怎么排除?想了很久,发现这两个问题可以合并:
- 一共 8 个固定方向 ,随机取 3 个
- 下面图的 3 个图标方向顺序可以跟提示条不一样,但一定有解
- 背景就算混入第 4、第 5 个干扰图标,本质上也只是候选池变大了
- 最难的情况:3 个里有 1 个箭头方向反了(比如提示是 ↑,图标方向反了 180° 变成 ↓),再加上 1 个没反转的------比如上下上这种 pattern
第四步:从暴力到建模。 假设给 3 次 attempt(这也合理),暴力枚举可以应付简单情况。但遇到上下上 + 背景干扰(4~5 个候选),暴力就炸了。这时候意识到这个问题的结构------这是指派问题。 提示方向是需求方,图标方向是供给方,要求总角度误差最小。代价矩阵 + Hungarian,一次性解完。而且它天然容忍背景干扰------多出来的候选在匹配时自然被淘汰,不需要单独做"排除干扰图标"这一步。
最终方案: 50 次测试,48 次成功(96%)。不是 100%,但成本极低、速度极快。失败的 2 次都是 icons_lt_arrows------InSPyReNet 抠图后只找到 2 个连通域,第 3 个图标没抠出来。这在预期之内,3 次 attempt 足以覆盖。
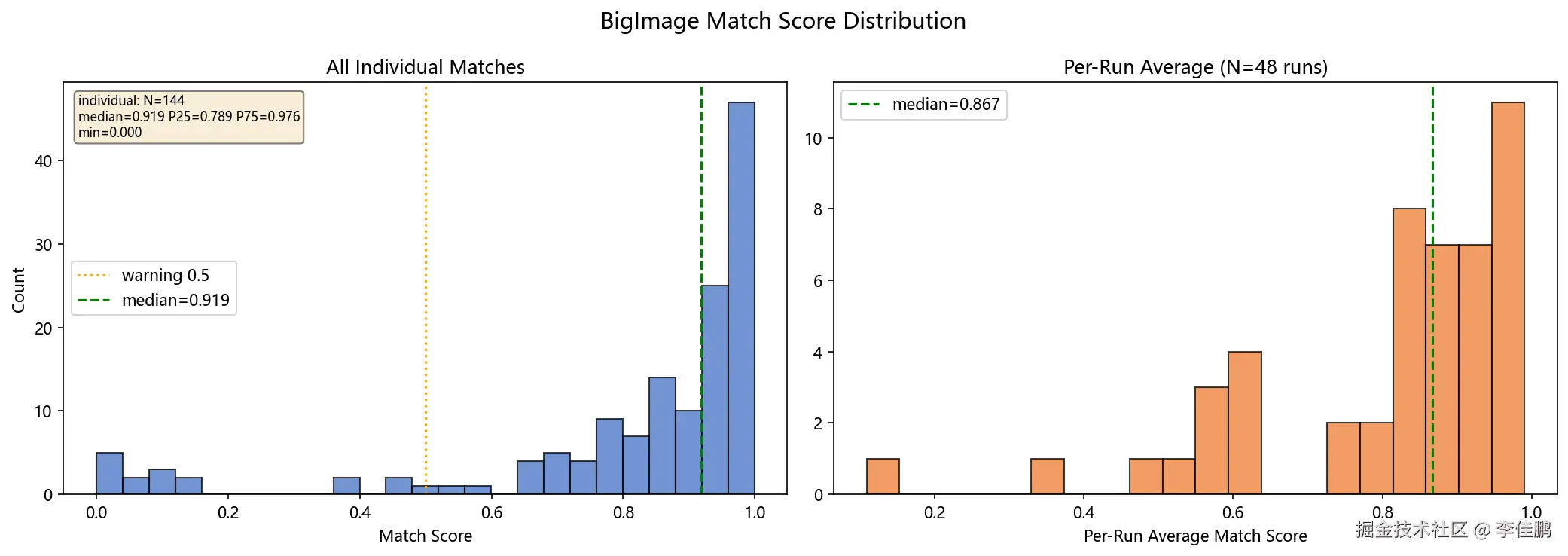
2.0.1 批量测试数据(N=50)
ini
BigImage 50 次测试:
OK: 48 (96%) | Fail: 2 (icons_lt_arrows)
匹配分数分布 (144 个独立匹配):
median=0.919 P25=0.789 P75=0.976 min=0.000
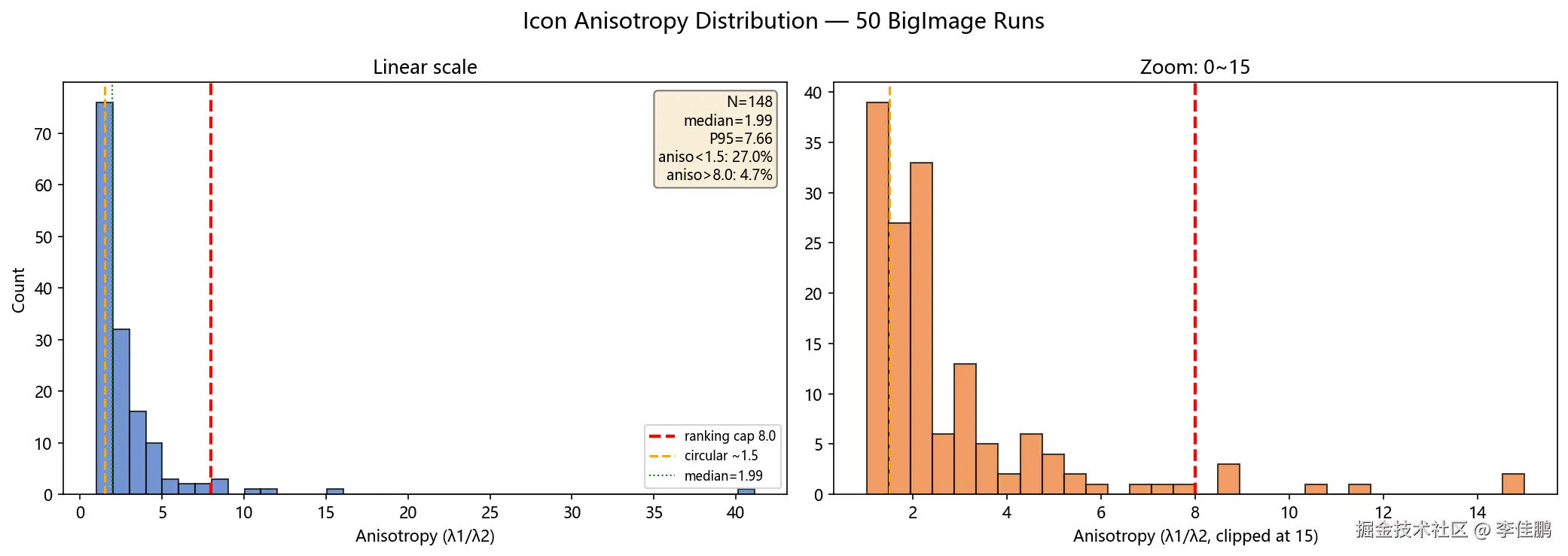
各向异性分布 (图标候选池):
median=1.99 P95=7.66 max=41.12
aniso<1.5 (近圆形): 27.0% | aniso>8.0 (极端值): 4.7%匹配分数中位数 0.919 说明匈牙利指派在大多数 case 上很稳。但 min=0.000 提醒我们:个别匹配可能完全失败(PCA 主轴刚好和正确方向差 90°,或者在近圆形图标上直接乱飘)。
27% 的图标 aniso < 1.5 意味着这些几乎圆形的图标 PCA 方向不可靠------它们靠的是 Hungarian 全局优化的"同伴压力"被捎带配对,而不是自己方向对。
makefile
输入: 提示条(含 3 个箭头方向) + 大图(含若干图标+可能干扰)
输出: 按提示顺序依次点击对应图标
管道: Tip方向识别 → 图标抠图+PCA → 代价矩阵+Hungarian指派2.1 为什么不上 YOLO
老实说我没训 YOLO。事后复盘,不上 DL 的理由是三个:
makefile
问题一: 标注成本
├─ 一个站点 3 个箭头 + 8 个方向 = 24 类
└─ 图标风格跨站点不同 → 泛化要加数据
问题二: 推理成本 --- GPU 服务器,500 次验证/天 → 利用率 < 3%
问题三(最关键的): 这是强结构问题
├─ 类数固定(8 方向)
├─ 图标是刚性变换(旋转+平移,几乎无缩放)
└─ 对强结构问题,经典 CV 精度 ≥ DL,复杂度低一个数量级但说实话,当时没做这么系统的对比分析。就是直觉:这题的结构太强了,强到不需要 DL。 以下基于问题结构的推理,欢迎打脸。
2.2 Stage 1 --- 提示条方向提取
scss
BGR → gray → GaussianBlur(3,3) → Otsu(正反各一次) → findContours → 凸包直径求方向 → 极性修正核心 trick:Otsu 正反各做一次。 有些箭头白底黑框,有些黑底白框。THRESH_BINARY_INV + OTSU 和 THRESH_BINARY + OTSU 各跑一次,取连通域更多的那个。这不是一开始就想到的------Geetest demo 的提示条就是反色渲染,第一次跑 Otsu 正向后一个轮廓都提不出来,加了反向才过。
方向向量用凸包最远两点(hull_diameter)算------比 PCA 主轴更适合箭头,因为箭头凸包是细长的,最远两点恰好就是箭尾到箭头。
极性修正: 凸包给轴线,不区分头尾。解决------在轮廓 ROI 上做 Canny(34, 100),比较向量前后半平面的边缘密度。箭头尖端 Canny 响应多,尾部少。如果后半平面边缘 > 前半平面 × 1.06,翻转:
python
if nb > nf * 1.06 or (nb > nf and (nb - nf) > max(6, int(0.05 * tot))):
v = -v # 翻转这里有两层:1.06 是相对比例阈值,max(6, 0.05*tot) 是绝对差值兜底------箭头特别小的时候(tot < 100),比例容易波动,需要绝对差值防止误翻。几次调试后拍的值,不是推导出来的。
48 张提示条 144 个箭头中,56.9% 被翻转------说明凸包直径给的方向约一半是反的,极性修正不是可有可无。
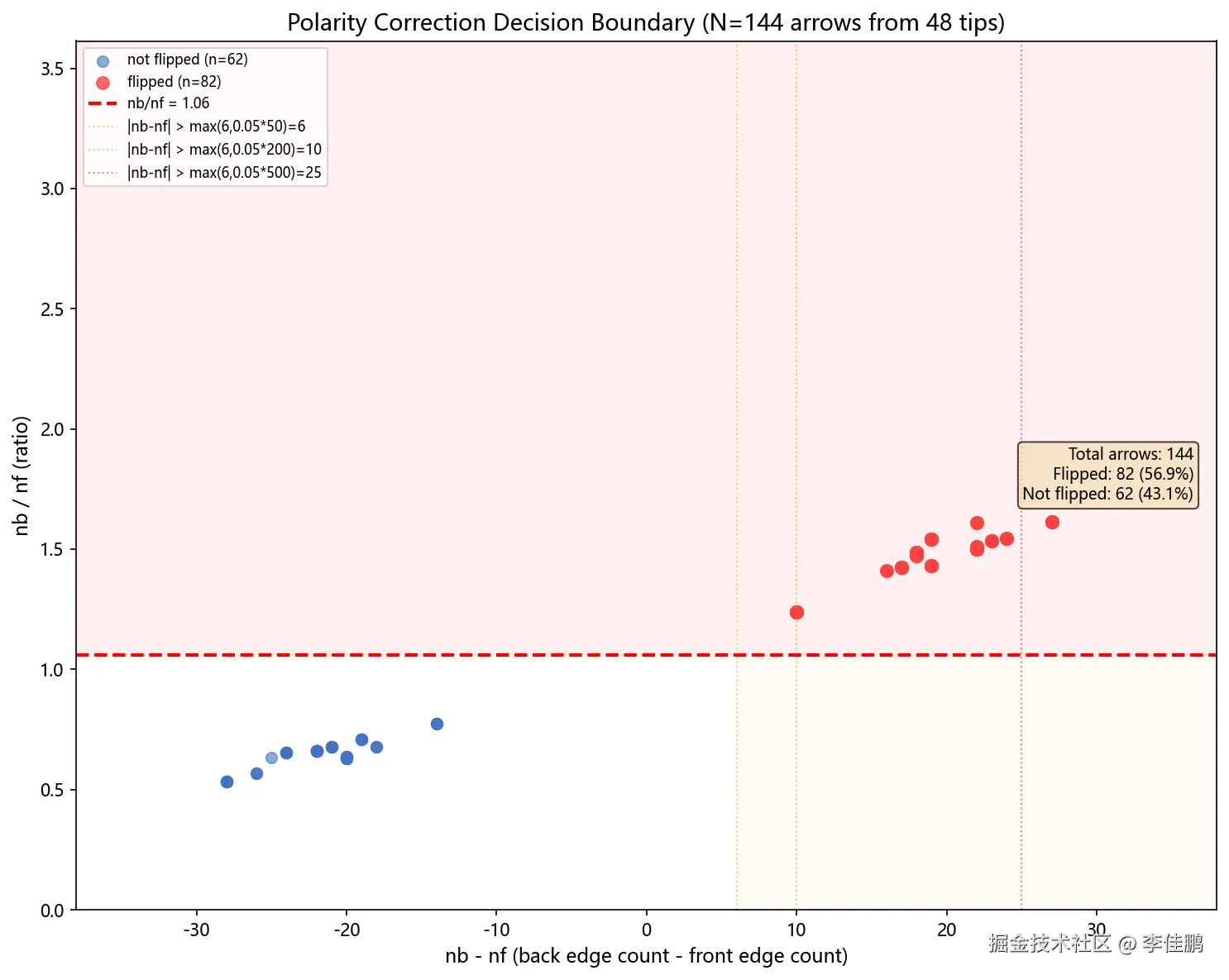
2.3 Stage 2 --- 图标抠图 + PCA 方向提取
抠图的灵感来自 WPS。 有一次用 WPS 给文档去背景,发现它把图标从背景里分离得干干净净。验证码的图标本质上就是"前景图标 + 杂乱背景",跟 WPS 的场景一模一样。试了一下 transparent_background(底层是 InSPyReNet),效果超出预期------不需要标注,预训练模型拿来即用。
python
from transparent_background import Remover
rem = Remover(mode="fast")
saliency = rem.process(rgb, type="map") # 只要显著性图
mask = (saliency > 32).astype(np.uint8) * 255模型做了进程内缓存------同一次脚本里的第 2 次及后续尝试不会重新初始化模型。验证码失败后的同页重试,CV 冷启动成本明显下降。
抠图后连通域分析。这里踩过一个最隐蔽的坑:InSPyReNet 有时把一个图标切成多块碎片。 图标边缘渐变过渡时,显著图在图标中间断开,连通域把一块图标算成两三个独立候选 → PCA 主轴全乱 → Hungarian 匹配一塌糊涂。排查了很久------因为不是每次都出现,跟图标边缘对比度有关。解决方案:对质心距离 < 15px 的邻近连通域画粗线桥接,再重新做连通域分析:
python
for (i, j) in close_pairs:
if dist(centroids[i], centroids[j]) < 15:
cv2.line(mask, p1, p2, 255, thickness=thick)最典型的触发 case 还记得:一张绿叶背景的大图,里面有个绿乌龟图标,乌龟旁边是叶子阴影形成的纯黑地带。InSPyReNet 把纯黑区域判为背景,显著图在乌龟身上断开------原本一个图标被切成了两块。起初以为是 saliency map 的阈值(_MASK_ALPHA_THRESHOLD=32)太敏感,调了几次发现降阈值会让更多背景噪声进来。意识到根因不在阈值,而在连通域分析阶段------InSPyReNet 的输出本身就有这种边缘模糊导致的断裂。于是直接在连通域之间画粗线桥接(质心距离 < 15px),再重新做一次连通域分析。简单但有效。
每个连通域提取三个特征:
python
icon = {
"center": (cx, cy),
"pca_ang": pca_angle_from_cov(mask), # PCA 主轴角 0~180°
"aniso": anisotropy(mask), # 特征值比 λ1/λ2
"area": area,
}PCA 计算用了 np.cov + np.linalg.eigh,没调 sklearn------对于每个 mask 几百到几千像素的数据,numpy 原生完全够用,还少一个依赖。
候选排序规则:
python
def rank_key(item):
return min(aniso, 8.0), area # aniso 截断在 8.0,防极端值主导排序为什么截断 aniso 在 8.0? 各向异性越高主轴越稳定,应该排前面。但如果候选是超窄一条线(aniso 可能到几十),它反而不是图标------是噪声。min(aniso, 8.0) 让"足够细长"和"极其细长"在排序时平等,避免噪声排在真图标前面。
候选池大小也不机械取 icon_pool_max:
python
def match_pool_cap(expect_n, icon_pool_max):
base = max(expect_n + 4, expect_n * 2) # buffer,防假阳性挤掉真目标
return max(expect_n, min(icon_pool_max, base))2.4 Stage 3 --- 匈牙利全局指派:两个难题一起解
提示条给了 3 个方向,图里有 N 个候选图标。问题有两个:
- 图标方向可能反了------PCA 给的是无向轴(0-180°),同一个轴可以对应两个相反的方向。提示要求 ↑,图标 PCA 可能指向 ↓(差 180°,但在 0-180° 的周期里看起来是一样的)。
- 背景有干扰------抠图可能多抠出第 4、第 5 个候选(背景里的装饰元素)。
关键洞察:这两个问题可以用同一个机制解。
为什么: 8 个固定方向(每 45° 一个),随机取 3 个。题目一定有解------下面图的 3 个图标就是按提示出现的。背景干扰只是让候选池从 3 变成 N(N ≥ 3)。如果能把 N 个候选和 3 个提示做全局最优匹配,多余的候选自然落选。
最难的情况举例:提示是 ↑ ↓ ↑。图里 3 个图标,其中 1 个方向反了 180°(本来是 ↑,PCA 主轴指向 ↓),其他的对。这时候逐对贪心匹配会出错------某个 ↑ 提示可能被错误配对到那个反了的图标上。但如果做全局优化,"总和最小的角度误差"自然会把重担分给最合适的配对。
旧版: 全排列枚举所有 (图标排列 × 方向正反组合) → O(n! × 2^n),候选 > 6 直接爆炸。
新版: 代价矩阵 + 线性分配。因为 PCA 轴是无向的(周期 180°),枚举一个全局偏移 delta ∈ {0, 90} 就够了------0° 和 90° 覆盖了"图标整体是按 0°, 45°, 90°... 基准放的"两种可能。
python
from scipy.optimize import linear_sum_assignment
m = len(arrow_dirs)
n = len(icons)
for delta in [0, 90]: # 全局旋转二义性:图标可能整体偏了 0° 或 90°
target_axes = [(d*45 + delta) % 180 for d in arrow_dirs]
cost = np.zeros((m, n))
for k in range(m):
for j in range(n):
diff = abs(target_axes[k] - icons[j]["pca_ang"]) % 180
cost[k, j] = min(diff, 180 - diff) # 周期 180°
row_ind, col_ind = linear_sum_assignment(cost)
total_cost = cost[row_ind, col_ind].sum()
# 取 delta ∈ {0, 90} 中总代价更小的
ini
Cost Matrix (m=3, n=5):
icon0 icon1 icon2 icon3 icon4
tip0 [ 45 5 30 80 70 ] → 选 icon1 (差 5°)
tip1 [ 10 60 15 75 20 ] → 选 icon0 (差 10°)
tip2 [ 80 20 5 10 45 ] → 选 icon3 (差 10°)
总代价: 25
O(n!) → O(n³)。同目标函数。同全局最优。上图是示意。下面是 50 次测试中三张典型 Cost Matrix:高置信、中等、低置信。
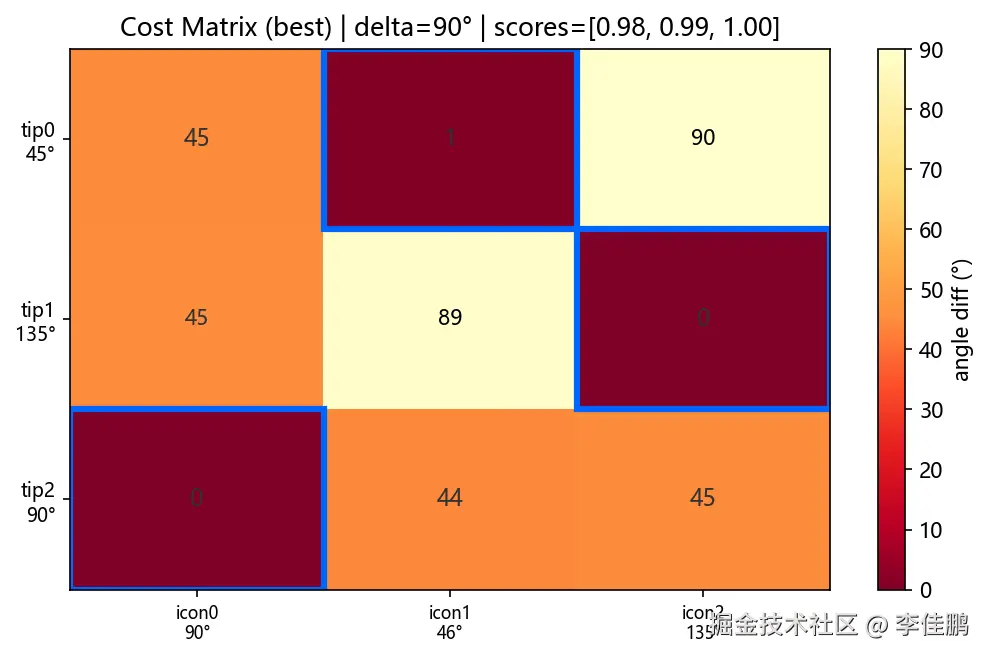
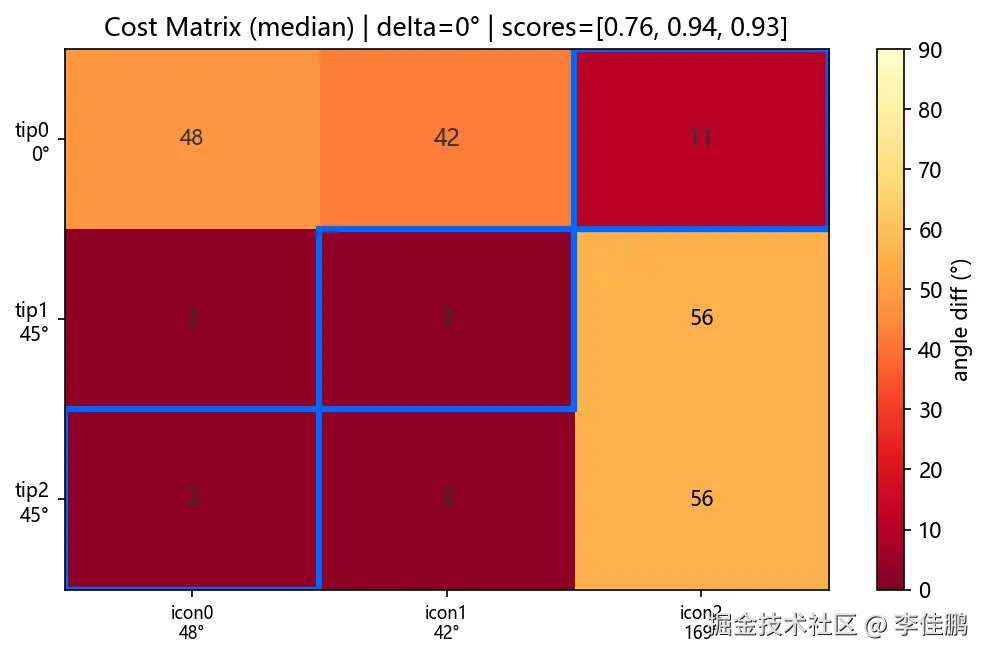
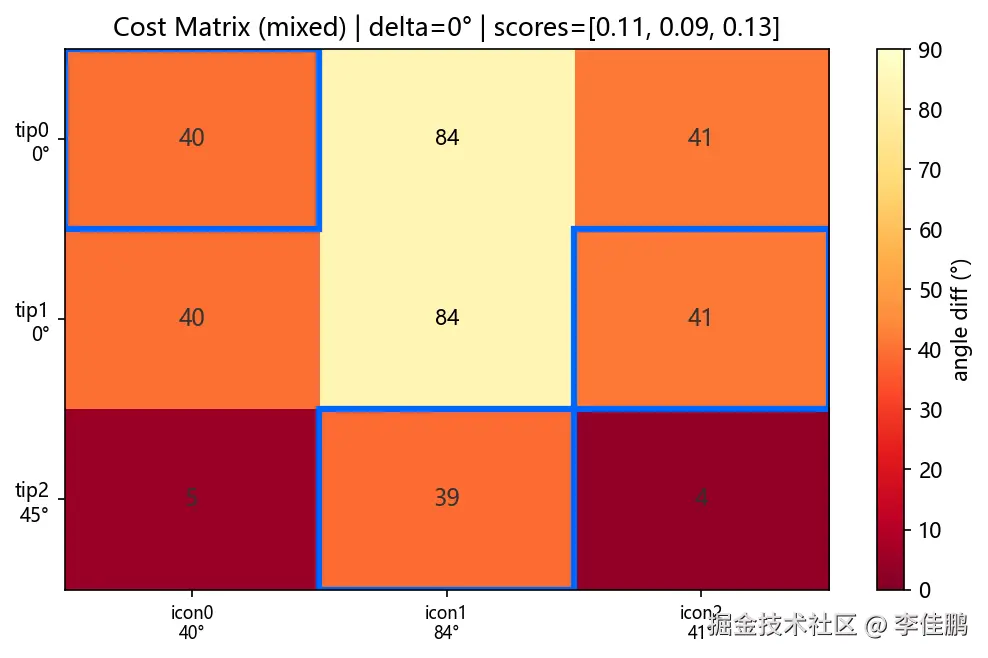 这个转换的价值不在性能------在于把两个难题(方向歧义 + 背景干扰)装进了同一个数学框架。 前者是"遍历所有情况 + 人工处理每种 corner case",后者是"建代价矩阵 → 最小权匹配出来就知道哪个候选不属于任何提示"。这种"把多个问题合并建模"的意识,比会调 API 值钱得多。
这个转换的价值不在性能------在于把两个难题(方向歧义 + 背景干扰)装进了同一个数学框架。 前者是"遍历所有情况 + 人工处理每种 corner case",后者是"建代价矩阵 → 最小权匹配出来就知道哪个候选不属于任何提示"。这种"把多个问题合并建模"的意识,比会调 API 值钱得多。
当然不是 100%------极端情况下(两个图标 PCA 方向非常接近 + 都反了),匹配可能出错。50 次测试 96% 成功率,成本极低、速度极快。
三、让管道可观测
算法写完了,跑几次看着 OK。到这里大部分人(包括一开始的我)就停了。
但真正有价值的工作不是"跑通一次"------是让管道的行为可测量、可复现、可调试。 以下是补上的一层。
3.1 单次运行的决策日志
每次运行产出一个结构化结果,不只是"过了/没过"。原版只存了 center 和 bbox,以下是补全后的版本------加上 pca_ang、aniso、area,后面的统计分析才跑得起来:
python
@dataclass
class CVPipelineOK:
tip: TipStepOut # arrow_dirs
big: BigStepOut # icons: 候选列表 + pool_count
match: MatchStepOut # centers, match_scores, match_icon_idx, match_modes
def to_jsonable(self):
return {
"arrow_dirs": self.tip.arrow_dirs,
"pool_count": self.big.pool_count,
"icons": [{"center": ic["center"], "pca_ang": ic["pca_ang"],
"aniso": ic["aniso"], "area": ic["area"]}
for ic in self.big.icons],
"click_centers": self.match.centers,
"match_scores": self.match.match_scores,
"match_icon_idx": self.match.match_icon_idx,
"match_modes": self.match.match_modes,
}关键字段:match_scores(每个匹配的角度差换算分数)、match_modes(delta=0 还是 90)、pool_count(候选图标数)。这些是后续统计的基础。
3.2 Cost Matrix 可视化
匈牙利匹配的核心是代价矩阵。画出来,一眼看出这次匹配置信度:
python
import matplotlib.pyplot as plt
import seaborn as sns
def plot_cost_matrix(arrow_dirs, icons, delta, save_path=None):
m, n = len(arrow_dirs), len(icons)
targets = [(d*45 + delta) % 180 for d in arrow_dirs]
cost = np.zeros((m, n))
for i in range(m):
for j in range(n):
diff = abs(targets[i] - icons[j]["pca_ang"]) % 180
cost[i, j] = min(diff, 180 - diff)
fig, ax = plt.subplots(figsize=(max(6, n*0.8), max(4, m*0.8)))
sns.heatmap(cost, annot=True, fmt=".0f", cmap="YlOrRd_r",
xticklabels=[f"icon{j}\n{icons[j]['pca_ang']:.0f}°" for j in range(n)],
yticklabels=[f"tip{i}\n{targets[i]:.0f}°" for i in range(m)],
vmin=0, vmax=90, ax=ax)
ax.set_title(f"Cost Matrix (delta={delta}°)")
# 标 Hungarian 选中的格子
row_ind, col_ind = linear_sum_assignment(cost)
for r, c in zip(row_ind, col_ind):
ax.add_patch(plt.Rectangle((c, r), 1, 1, fill=False,
edgecolor='blue', lw=2))
return fig跑一批真实 case 之后翻这些热力图,你会发现:
- 好的 case: 选中格子基本深色(低成本),每行只有一个明显低点
- 坏的 case: 一行全是浅色(高成本)→ 这个提示没有对应图标,候选池漏了真目标
- 歧义 case: 一行有两个差不多的深色格子 → 匹配不稳,但概率上还有救
3.3 批量运行的统计视图
跑 N 次,收集所有 to_jsonable() 到 JSONL。然后:
python
def compute_run_stats(jsonl_path):
records = [json.loads(line) for line in open(jsonl_path)]
success = sum(1 for r in records if r.get("ok")) / len(records)
all_scores = [s for r in records if r.get("ok")
for s in r["match_scores"]]
pool_sizes = [r["pool_count"] for r in records if r.get("ok")]
return {
"total_runs": len(records),
"success_rate": success,
"match_score_p50_p90": (np.percentile(all_scores, 50),
np.percentile(all_scores, 90)),
"pool_size_p50_p95": (np.percentile(pool_sizes, 50),
np.percentile(pool_sizes, 95)),
"failure_stages": Counter(
r["stage"] for r in records if not r.get("ok")
),
}几个基于本次 50 次测试得到的参考值:
| 指标 | 实测值 | 如果跑偏了 |
|---|---|---|
| 匹配分数中位数 | 0.919 | < 0.7 → 检查 PCA 方向提取或候选池质量 |
| 候选池 P95 | 3(刚好等于箭头数) | > 6 → 抠图混入大量背景噪声 |
| 失败阶段 | icons_lt_arrows=4% | no_arrows 高 → Otsu失效;icons_lt_arrows 高 → 抠图太激进 |
| aniso < 1.5 比例 | 27% | > 50% → 图标池里圆形太多,匹配靠运气 |
3.4 各向异性分布:一个无监督信号质量指标
aniso 是本文最有意思的特征------不需要标注数据就能判断信号质量。
python
def plot_aniso_distribution(all_icons_aniso, save_path=None):
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].hist(all_icons_aniso, bins=40, edgecolor='black', alpha=0.7)
axes[0].axvline(x=8.0, color='red', linestyle='--', label='截断阈值 8.0')
axes[0].axvline(x=1.5, color='orange', linestyle='--', label='圆形边界 ~1.5')
axes[0].set_xlabel("Anisotropy (λ1/λ2)")
axes[0].legend()
axes[1].hist(all_icons_aniso, bins=40, edgecolor='black', alpha=0.7)
axes[1].set_yscale('log')
axes[1].set_xlabel("Anisotropy (λ1/λ2)")
fig.suptitle("Icon Anisotropy Distribution")
return fig解读:
- aniso ≈ 1.0~1.5: 图标接近圆形。PCA 主轴不可靠,方向几乎是随机的。占 27%。
- aniso ≈ 2.0~8.0: 有明显长轴方向(箭头、手指、飞机)。PCA 主轴可靠。占 ~68%。
- aniso > 8.0: 占 4.7%,其中 > 20 的极大概率不是图标,是背景细线或边缘残留。
27% 近圆形是一个值得关注的数字。 这些图标在匹配时靠的不是自己的方向,而是 Hungarian 全局优化的"同伴压力"------另外两个图标方向对,这一个就被捎带对了。如果哪天验证码厂商故意放三个圆形图标......但这就是代价,任何基于 PCA 的方案都会在圆形上翻车。不需要看任何一张图片,光看分布就能定位问题。 这就是"数据驱动调参"。
3.5 失败模式:不只是"没过"
makefile
失败阶段分类:
no_arrows → 提示条一个箭头都没提出来 → Otsu 失效
icons_lt_arrows → 候选图标不够 → 抠图太激进 or 碎片化
verify_timeout → CV 跑通了但点完没过 → 点击坐标不准 or 风控
new_challenge_spawned → 题面被换了 → 正常,同页重试
try_again_feedback → 服务端明确拒绝 → 特征被识别本次 50 次测试只触发了 icons_lt_arrows(2 次),其余类型为系统设计预留------未来换站点、换验证码厂商时可能触发。
一个月后回来看统计数据,不需要重新翻截图,直接看失败分布就知道哪里要修。
四、管道复盘:每个决策对应的技能
| 环节 | 做了什么 | 对应技能 | 一句话 |
|---|---|---|---|
| 1.1 | 像素→边缘,换域匹配 | 特征工程 | 同一算法,换表征准确率天差地别 |
| 2.1 | 评估 YOLO 后否决 | 方法论选择 | SOTA 不是默认答案,强结构场景经典方法可达同等精度 |
| 2.2 | Otsu 正反各一次 + 极性修正 | 信号处理 | 二值化 + 方向歧义消除的完整链路 |
| 2.3 | PCA + aniso 排序,min(aniso,8.0) 截断 | 无监督特征选择 | 不靠标注,用数据内在结构筛选 + 防极端值 |
| 2.4 | 方向歧义+背景干扰 → 代价矩阵+Hungarian | 运筹/指派问题 + 多问题合并建模 | 两个难题装进一个框架,Code → Math |
| 3.1~3.5 | 结构化日志 + 批量统计 + 分布可视化 | 管道可观测性 | 从"我感觉"到"数据说" |
五、护城河:把问题抽象成数学的能力
攻击方收益 ≤ 攻击方成本 → 防线有效
攻击方收益 > 攻击方成本 → 防线失守这个模型不止适用于验证码。任何风控/反欺诈场景都可以用它来思考:垃圾注册(短信成本 vs 变现价值)、爬取(IP 池成本 vs 数据价值)等等。核心洞察:你不需要让攻击变得不可能,只需要让攻击成本高于收益。
但我真正想说的是另一个角度------在这个 vibe coding 越来越普及的时代,不管是安全工程师还是普通用户,把问题抽象成数学问题的能力才是护城河。
普通用户反复问 AI,得到的答案只会是"上 YOLO"或"上 ResNet",最后一定放弃------因为他们没有判断力去分辨这个建议对不对。安全工程师也一样------如果只会调 API 而不会建模,vibe 用户追上来的速度会比你想象的快。真正挡得住的是:能把一个看起来像目标检测的问题,拆成几何题 + 指派问题的人。
验证码的终点不是"更强的题",而是"人类可过但机器困难"的帕累托前沿。这个前沿永远在移动------每个公开方案推高前沿,但前沿不会消失,因为防御方多一个自由度:他们可以改题面结构,攻击方只能适应。
第一次在掘金发文,也请多多指教!