接下来正式开始上手 LangGraph 编程学习,下面我准备了三个实战案例。
第一个案例,是把之前说到的业务示例,完整转换成 LangGraph 代码,搞懂 LangGraph 里图示工作流的编码逻辑,学会怎么定义状态、创建图结构、往图里添加节点和添加边,完成 LangGraph 基础图示编程入门。
第二个案例,实现一套可联网搜索的智能代理系统,真正对接智能应用开发场景。
第三个案例,会对之前学过的链式 RAG 系统做升级改造,把传统链式 RAG 重构为图示化 RAG 系统,让工作流逻辑变得更加复杂、灵活,后续写代码时会具体拆解实现逻辑。
介绍完三个案例规划后,我们本篇从第一个案例开始实操讲解,选用生活中通俗易懂的智能快递配送系统,来讲解 LangGraph 基础图示编程的完整实现逻辑。
编码前的版本说明
LangGraph 放弃了对 Python 3.9 的支持,所有 LangChain 包现在都需要 Python 3.10 或更高版本。使用 python --version 查看 Python 版本。如低于 3.9,需要重装。
【案例一】智能快递配送系统
Graph API 编码思路
想要搭建这套图示快递配送系统,本质就是把现实中的快递配送流程,用 LangGraph 代码进行建模。图的核心组成包含状态、节点、边,最后还要对图进行编译,编译提供了对图形结构的一些基本检查(没有孤立节点等)
对应到编码逻辑:
-
首先要定义整张图的全局状态 ;
-
其次定义节点 ,节点就对应快递配送里的各个站点,并且 LangGraph 中节点本质就是 Python 函数,有多少个站点就要定义多少个函数;
-
接着需要创建图结构 ,把定义好的节点添加进图中,相当于把各个配送站点归属到同一家快递公司体系下,才能纳入整体调度;
-
然后添加边 ,边的作用是定义节点之间的流转流程,规划快递运输路径;
-
最后一步是编译图 。
这里用生活化的例子解释LangGraph 编译 的含义:创建图和节点相当于自己搭建好了一家快递公司,而编译就等同于公司注册审核 。官方会校验公司资质、架构是否合规,对应到 LangGraph 中,编译会对图结构做基础检查 ,比如检测是否存在孤立节点。所谓孤立节点,就是已经定义好了站点节点,但没有通过任何边和其他节点产生关联,相当于建了一个无人对接的揽收站,没有入站也没有出站流转,属于多余无效节点,编译阶段会自动检测出这类问题。
同时要区分:
LangGraph 所谓的一些 "编译" 与传统意义上的语言编译完全不同,LangGraph 编译本质是在运行时动态构建和验证一个复杂的图,而非翻译代码。
C++ 的编译是 "完整编译" 或 "静态编译" 的典范。它追求在程序运行之前,就将所有代码 "解译" 完毕,生成一个独立、高效、可直接被操作系统调用的 "成品"。它比 Java 的编译更彻底(直接到机器码,而非中间码),也更底层(紧密绑定操作系统和 CPU 架构)。
"编译" 对比表格:
| 特性 | LangGraph 的编译 | Java 的编译 | C++ 的编译 |
|---|---|---|---|
| 本质 | 配置组装与验证 | 语言翻译与转换(到中间码) | 语言翻译与转换(到本地机器码) |
| 发生阶段 | 应用程序运行时(初始化阶段) | 应用程序开发时(构建阶段) | 应用程序开发时(构建阶段) |
| 主要目的 | 1. 构建可执行的工作流对象2. 进行结构验证 | 1. 将高级语言转为低级语言(字节码)2. 进行语法和深度语义检查 | 1. 将高级语言转为特定平台的本地机器码2. 进行彻底的语法、语义检查与优化3. 链接所有模块,生成完整的可执行文件 |
整体梳理 LangGraph 标准编码步骤:第一步定义全局状态;第二步定义各个节点函数;第三步创建图结构,把节点、边全部纳入图中;第四步编译图,完成结构校验;最后编写代码测试、执行整张工作流。后续代码编写,会严格按照这套流程落地。
正式编码前,不能直接上手写代码,要先梳理业务、画出流程图,先在脑海或草稿上画出人能看懂的业务图示,理清整体工作流,再对照图示逐行编码。
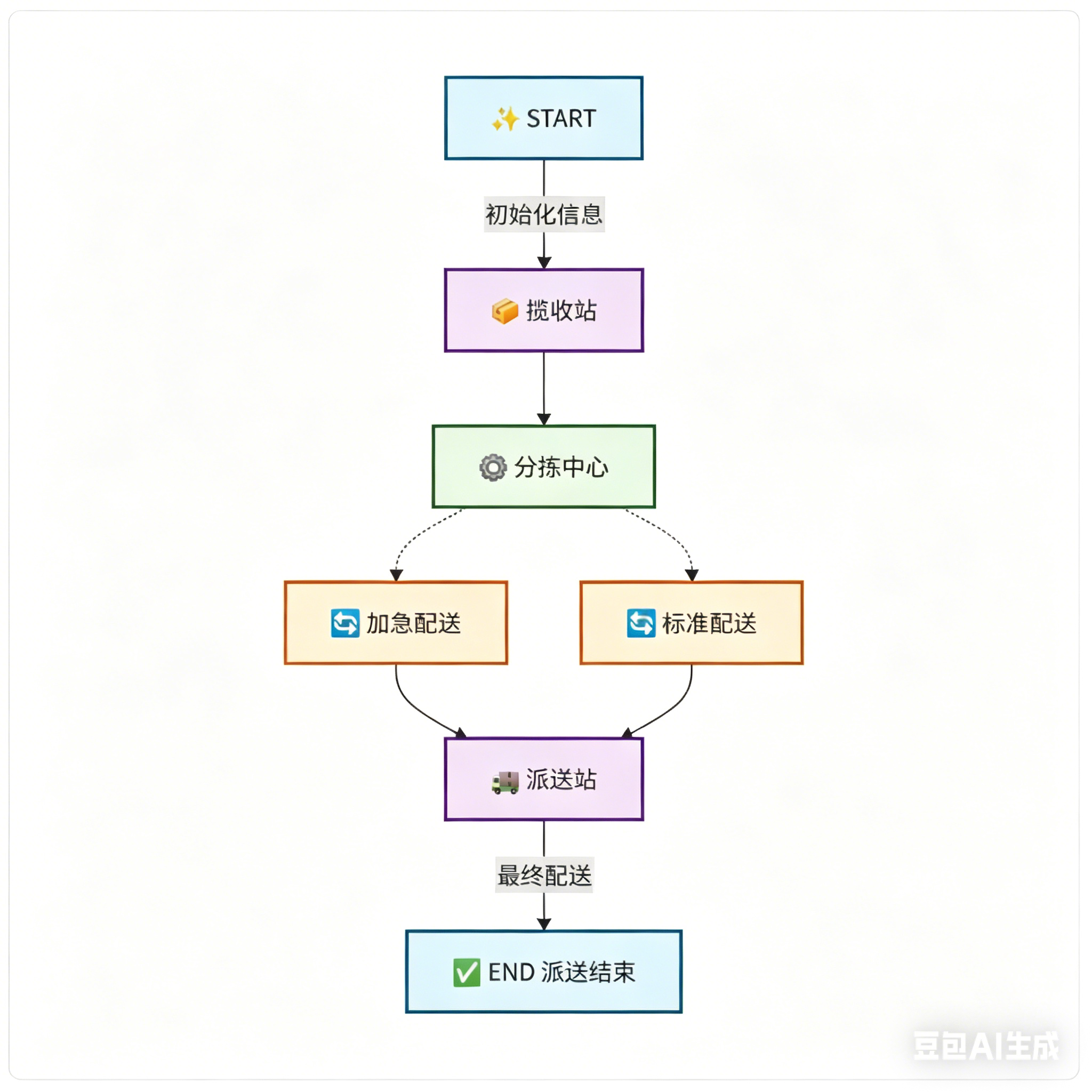
以智能快递配送系统为例,完整工作流逻辑为:从起始节点 开始,用户把包裹交到揽收站 ,再进入当地分拣中心 ;分拣中心会根据包裹目的地,分流到北京、上海等不同目标城市分拣中心;根据包裹状态信息,判断配送是加急还是标准,进行分流;到达目标区域后进入配送站 ,最后送达用户手中,走到结束节点。
从流程图中可以区分两种边:固定边 和条件边。固定边就是 A 节点固定流向 B 节点,路径不会改变;条件边则是根据设定条件,自动分流到不同节点。同时可以提前梳理出编码需要用到的所有节点:揽收站、分拣中心、加急配送、标准配送、派送站,再加上系统内置的开始、结束特殊节点,编码时只需对应定义业务函数、规划好固定边和条件边即可。
为了让案例更贴合实际,还可以增加业务复杂度:按配送方式拆分出空运加急配送 和陆运标准配送两个节点。分拣中心可以根据包裹是否加急的状态,通过条件边自动分流,加急走空运、普通走陆运,两种配送方式最终都统一进入派送站。
为了方便新手入门,对完整流程图做了精简保留核心逻辑:保留揽收站、分拣中心、加急配送、标准配送、派送站五大业务节点,搭配系统自带的起始、结束节点;无分支直线流转的都是固定边,有判断分支的都是条件边。后续编码核心工作,就是定义好全局状态、编写对应节点函数、创建图并挂载节点与边,最后编译校验、运行测试,完成整套 LangGraph 图示工作流的搭建。
代码实现
步骤 1:定义 State,设置快递的 "包裹信息"
定义图时要做的第一件事是定义图的状态。状态 将是图中所有 节点 和 边 的输入,可以是 TypedDict 或 Pydantic 模型(Pydantic 的性能不如 TypedDict)。如下所示:
python
from typing import TypedDict, Annotated # 导入 TypedDict(定义字典结构)和 Annotated(给类型附加元数据)
from operator import add # 导入 add 函数(作为元数据标记,提示合并时使用加法操作)
# 定义包裹状态的数据结构
class PackageState(TypedDict):
# ========== 包裹基本信息 ==========
package_id: str
# ^^^^^^^^^ 字段含义:包裹的唯一标识ID
# 类型:str(Python 原生字符串类型)
# 示例值:"PKG_20240101_001"
origin: str
# ^^^^^^^ 字段含义:始发站/发货地
# 类型:str(Python 原生字符串类型)
# 示例值:"北京分拨中心"
destination: str
# ^^^^^^^^^^^ 字段含义:目的地/收货地
# 类型:str(Python 原生字符串类型)
# 示例值:"上海分拨中心"
# ========== 配送状态 ==========
status: str
# ^^^^^^ 字段含义:当前配送状态
# 类型:str(Python 原生字符串类型)
# 可选值:"待揽收"、"运输中"、"派送中"、"已签收"
history: Annotated[list[str], operator.add]
# ^^^^^^^ 字段含义:包裹的流转历史记录(按时间顺序记录每个节点)
# 真实类型:list[str](字符串列表,Python 3.9+ 原生类型注解)
# 元数据:add(从 operator 模块导入,提示合并时应使用列表拼接)
# 存储格式:["时间戳 状态描述", "2024-01-01 10:00:00 已揽收", ...]
total_distance: Annotated[int, operator.add]
# ^^^^^^^^^^^^^^ 字段含义:包裹已行驶的总里程(单位:公里)
# 真实类型:int(整数,Python 原生类型)
# 元数据:add(从 operator 模块导入,提示合并时应使用数值累加)
# 示例值:1250(表示1250公里)
# ========== 配送详情 ==========
priority: str
# ^^^^^^^^ 字段含义:配送优先级
# 类型:str(Python 原生字符串类型)
# 可选值:"普通"、"加急"【知识点】State 更新机制:Reducers
在快递案例中,我们借助 Annotated 类型,给流转历史 history 和 总里程 total_distance 额外配置了状态更新元数据 ,指定对应的规则函数 operator.add,用来控制这两个字段该怎么更新。
也就是说:状态想自动合理更新,关键就靠 Reducers 更新规则 。我们用 Annotated 给 history 和 total_distance 加了一层元数据,绑定了 operator.add 这个规则,用来规定字段的更新方式。
它的作用非常简单:告诉系统,当新数据进来时,不要把旧数据覆盖掉,而是把新数据追加、累加在后面。
比如:
- 历史记录:每到一个新站点,就把新站点追加到列表里,而不是把之前的记录删掉。
- 总里程:每走一段路,就把新里程累加到总里程里,而不是直接替换成新数字。
有了这个规则,整个快递流程里的状态才能被一步步正确更新,而不会被覆盖丢失。
python
# 覆盖更新: 每次新状态替换旧状态
status: str
# 追加更新: 新的流转记录添加到历史列表
history: Annotated[list[str], add]
# 数值累加: 里程数累加
total_distance: Annotated[int, add]步骤 2:定义 StateGraph 图,成立快递公司
StateGraph 是一个有状态图计算框架,它基于有向图(Directed Graph) 模型构建,专门设计用于处理多步骤、有状态的工作流程。
StateGraph 用来将复杂的工作流程可视化、模块化,让开发者能够像设计快递配送网络一样设计软件系统。通过这种思维方式,即使是复杂的多步骤 AI 应用也变得清晰可控。
我们需要使用 langgraph.graph.state.StateGraph 来定义。StateGraph 仅是一个构建器类,可以使用 State 来构建。如下所示:
当然了,这个步骤也可以放在节点定义之后
python
from langgraph.graph import StateGraph
# 2. 成立快递公司
delivery = StateGraph(PackageState)注意,这里仅是构建出 StateGraph,还无法直接用于执行。
步骤 3:定义 Nodes,创建配送站点
接着我们可以定义各个配送站点(节点)。在 LangGraph 中,节点 就是一个 Python 函数(同步或异步)。注意
- 节点 接收 状态 作为参数。
- 节点 不需要返回整个 状态 模式,只需一个更新。
如下所示:
python
# 3. 定义各个配送站点
def receive_package(state: PackageState):
"""揽收站"""
return {
"status": "已揽收", # 更新状态字段
"history": [f"在{state['origin']}揽收"] # 更新历史记录,reducer会自动将这条记录拼接到现有历史后面
}
def sort_package(state: PackageState):
"""分拣中心: 根据目的地分拣"""
destination = state["destination"] # 获取目的地信息
if "北京" in destination:
next_station = "北京分拣中心"
elif "上海" in destination:
next_station = "上海分拣中心"
else:
next_station = "其他地区分拣中心"
return {
"status": "已分拣", # 更新状态字段
"history": [f"分拣至{next_station}"] # 更新历史记录,reducer会自动将这条记录拼接到现有历史后面
}
def final_delivery(state: PackageState):
"""派送站"""
return {
"status": "已签收", # 更新状态字段
"history": [f"已送达{state['destination']}"] # 更新历史记录,reducer会自动将这条记录拼接到现有历史后面
}步骤 4:添加 Nodes,建设配送站点
接下来,我们需要将各节点,组织进图中,即添加节点到 StateGraph 中。可以使用 add_node() 将新节点添加到 StateGraph。add_node() 方法常用参数说明:
表格
| 参数名 | 类型 | 描述 |
|---|---|---|
node |
字符串或 StateNode 对象 |
作用:指定节点要运行的函数或可执行对象使用方式:- 如果传入字符串,该字符串将作为节点名称,此时会使用 action 参数作为实际的执行函数- 如果传入 StateNode 对象,则直接使用该对象定义 |
action |
StateNode 对象或 None(默认值) |
作用:定义与节点关联的动作(执行逻辑)使用方式:- 当 node 参数是字符串时,action 会作为该节点的实际执行函数- 当 node 参数已经是 StateNode 对象时,action 通常为 None |
...... |
代码如下所示:
python
# 4. 添加配送站点
delivery.add_node("揽收站", receive_package)
delivery.add_node("分拣中心", sort_package)
delivery.add_node("派送站", final_delivery)步骤 5:添加 Edges,规划运输路线
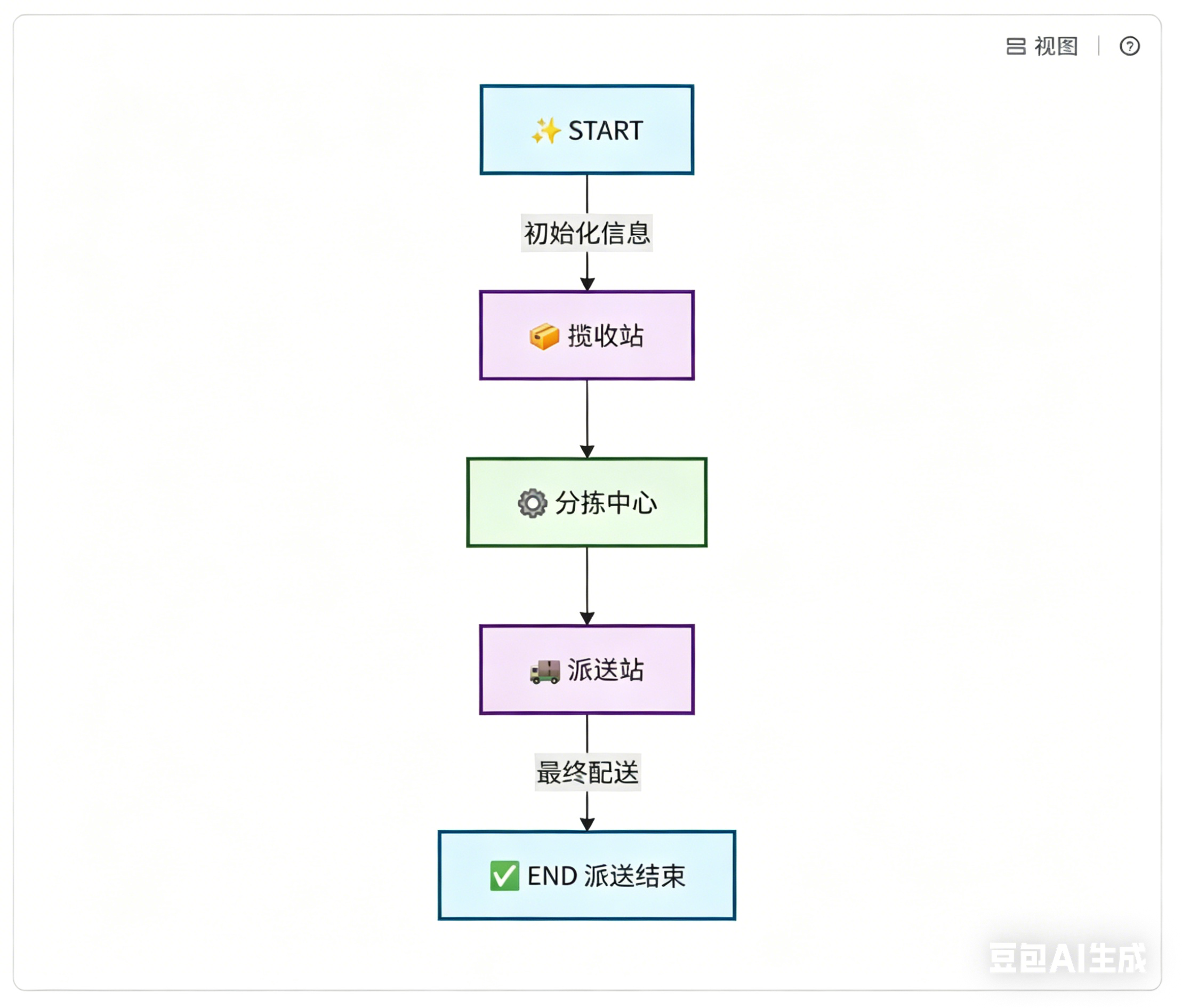
各节点(站点)准备好后,则需要为快递运输规划路线。如:
实际上,这就是为 图 定义 边。边有几种关键类型:
- 普通边 / 固定边(
Normal Edges):直接从一个节点转到下一个节点。 - 条件边(
Conditional Edges):调用函数来确定下一步要转到哪个节点。
例如,设置最简单运输路线:快递由揽收站接收,下一站固定为分拣中心,最后到派送中进行派送。这就是固定边,如下图所示:
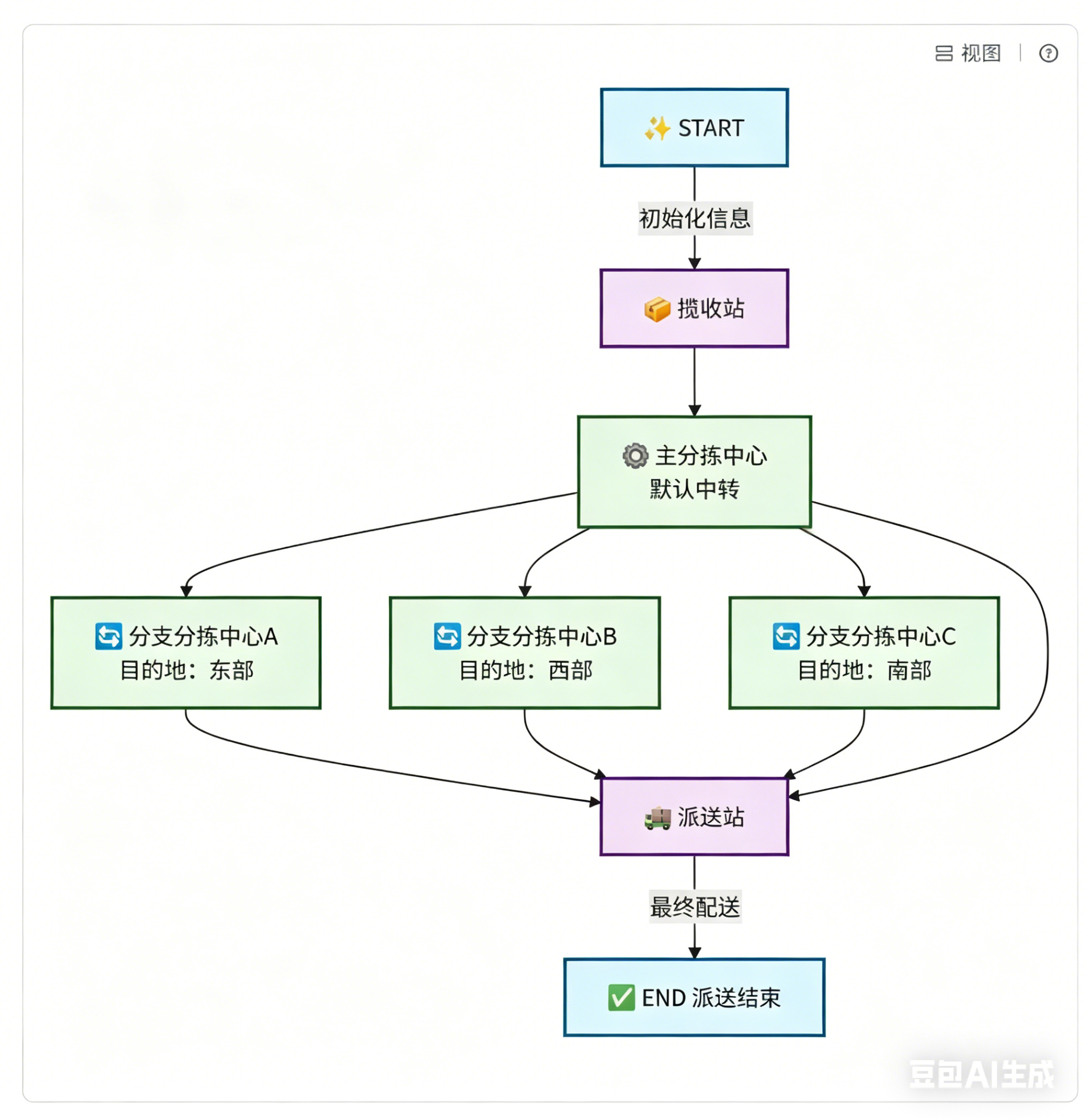
再例如,我们可以根据以下条件,判断快递如何运输:
- 包裹是加急件 → 走空运线路
- 包裹不是加急件 → 走标准线路
这就是条件边,如下图所示:
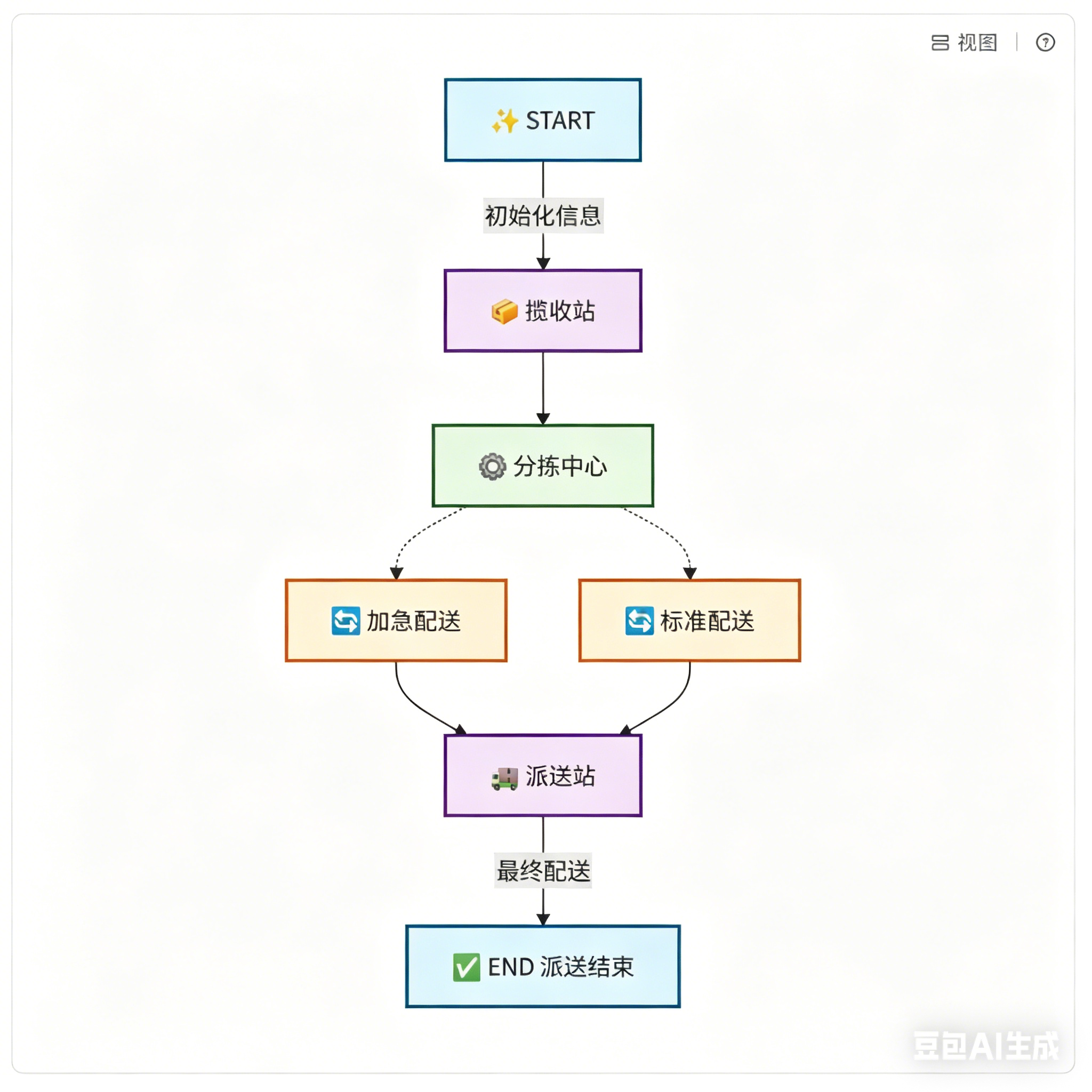
要说明的是,在 LangGraph 中:
START节点:是一个特殊节点,表示将用户输入发送到图形的节点。引用此节点的主要目的是确定应该首先调用哪些节点。END节点:是一个表示终端节点的特殊节点。当想要指示哪些边在完成后没有后续动作时,将引用此节点。- 条件入口点(Conditional Entry Point):调用一个函数来确定在用户输入到达时首先调用哪个节点。
代码实现
1)使用 add_edge() 向图中添加从开始节点(或起始节点列表)到结束节点的固定边。add_edge() 方法常用参数说明:
表格
| 参数名 | 类型 | 描述 |
|---|---|---|
start_key |
字符串 或 字符串列表 | 边的起始节点的键。 |
end_key |
字符串 | 边的结束节点的键。 |
2)使用 add_conditional_edges() 向图中添加 从起始节点到任意数量的目标节点 的条件边。add_conditional_edges() 方法常用参数说明:
表格
| 参数名 | 类型 | 描述 |
|---|---|---|
source |
字符串 | 起始节点。退出此节点时,将运行此条件边。 |
path |
Callable 或 Runnable |
决定下一个节点或多个节点的方法。如果没有指定 path_map 应返回一个或多个节点。如果返回 "END",图将停止执行。 |
path_map |
字典 或 字符串列表 或 None |
【可选】将路径映射到节点名。如省略,path 返回的路径应为节点名。 |
接下来实现下图对应的代码:
对应代码如下:
python
# 新增节点:定义不同配送方式的处理逻辑
def standard_delivery(state: PackageState):
"""
标准配送节点
作用:
- 处理普通优先级的包裹
- 采用陆运方式,速度较慢但成本低
更新内容:
- status: 更新为"运输中"(标准运输状态)
- history: 添加"标准陆运"记录,标记运输方式
- total_distance: 增加500公里里程
"""
return {
"status": "运输中",
"history": ["标准陆运"],
"total_distance": 500
}
def express_delivery(state: PackageState):
"""
加急配送节点
作用:
- 处理加急优先级的包裹
- 采用空运方式,速度快但成本高
更新内容:
- status: 更新为"加急运输"(加急运输状态)
- history: 添加"空运加急"记录,标记运输方式
- total_distance: 增加800公里里程
"""
return {
"status": "加急运输",
"history": ["空运加急"],
"total_distance": 800
}
# ========== 4. 构建配送工作流图 ==========
# 将各个节点注册到工作流图中
delivery.add_node("揽收站", receive_package) # 注册揽收节点
delivery.add_node("分拣中心", sort_package) # 注册分拣节点
delivery.add_node("标准配送", standard_delivery) # 注册标准配送节点
delivery.add_node("加急配送", express_delivery) # 注册加急配送节点
delivery.add_node("派送站", final_delivery) # 注册派送节点
# ========== 5. 设计配送路线 ==========
# 定义节点之间的连接关系(边)
# 起点 -> 揽收站
delivery.add_edge(START, "揽收站")
# 揽收站 -> 分拣中心
delivery.add_edge("揽收站", "分拣中心")
def select_delivery(state: PackageState):
"""
智能路由决策函数
作用:
- 在分拣完成后,根据包裹的优先级决定使用哪种配送方式
- 这是一个条件路由函数,根据 state 中的 priority 字段进行判断
返回值:
- "加急配送":如果 priority 为"加急"
- "标准配送":其他情况(包括"普通")
业务流程:
分拣中心 → 判断优先级 → 选择配送方式
"""
if state["priority"] == "加急":
return "加急配送"
else:
return "标准配送"
# 添加条件边:从分拣中心出发,根据 select_delivery 函数的返回值决定下一个节点
delivery.add_conditional_edges(
"分拣中心", # source: 起始节点。从这个节点执行完后,会调用条件函数
select_delivery, # path: 条件函数,根据当前状态返回下一个节点的名称
["加急配送", "标准配送"] # path_map: 条件函数可能返回的节点列表(用于验证和IDE提示)
)
# 两条配送路线都汇合到派送站
delivery.add_edge("标准配送", "派送站") # 标准配送完成后去派送站
delivery.add_edge("加急配送", "派送站") # 加急配送完成后去派送站
# 派送站完成后结束流程
delivery.add_edge("派送站", END)
# ========== 完整流程说明 ==========
"""
配送工作流执行流程:
START(开始)
↓
揽收站(receive_package)
→ 状态:已揽收
→ 记录:在XX地揽收
↓
分拣中心(sort_package)
→ 状态:已分拣
→ 记录:分拣至XX分拣中心
→ 决策:根据 priority 字段判断走哪条路
↓
├─ priority="加急" ─→ 加急配送(express_delivery)
│ → 状态:加急运输
│ → 记录:空运加急
│ → 里程:+800公里
│ ↓
└─ priority="普通" ─→ 标准配送(standard_delivery)
→ 状态:运输中
→ 记录:标准陆运
→ 里程:+500公里
↓
派送站(final_delivery)
→ 状态:已签收
→ 记录:已送达XX地
↓
END(结束)
关键特性:
1. Reducer 自动合并:多次添加的 history 会自动拼接,total_distance 会自动累加
2. 条件路由:根据包裹优先级动态选择配送方式
3. 状态累积:每个节点的更新都会被保留并传递到后续节点
"""也可以将决策返回映射到路由,如下所示:
python
# 智能路由:根据优先级选择配送方式
def select_delivery(state: PackageState):
"""智能路由决策 - 根据包裹特性选择路线"""
if state["priority"] == "加急":
return "备注加急"
else:
return "无备注"
delivery.add_conditional_edges(
"分拣中心", # source: 起始节点。退出此节点时,将运行此条件边。
select_delivery, # path: 确定下一个或多个节点的可调用对象。
{
"备注加急": "加急配送",
"无备注": "标准配送"
}
)步骤 6:StateGraph 图编译,从公司创建到运行
在步骤 2 中,我们仅是构建出 StateGraph,还无法直接用于执行。LangGraph 要求:必须先编译图,然后才能使用它。编译提供了对图结构的一些基本检查,这会验证:
- 从
START到所有节点的可达性 - 从所有节点到
END的可达性 - 没有孤立节点或死循环
使用 compile() 方法即可编译图。该方法将 StateGraph 编译为 CompiledStateGraph 对象。编译后的图实现了 Runnable 接口,可以异步调用、流式传输、批处理和运行。
代码如下:
python
# 7. 编译系统
delivery_system = delivery.compile()到这里,核心代码已编写完成。接下来进行测试,代码如下:
python
# 8. 测试配送
test_packages = [
{
"package_id": "P001",
"origin": "北京",
"destination": "上海",
"priority": "普通",
"history": [],
"total_distance": 0
},
{
"package_id": "P002",
"origin": "广州",
"destination": "乌鲁木齐",
"priority": "加急",
"history": [],
"total_distance": 0
}
]
for package in test_packages:
print(f"\n配送包裹: {package['package_id']}")
result = delivery_system.invoke(package)
print("最终状态:", result["status"])
print("配送历史:", result["history"])
print("总里程:", result["total_distance"])注意,默认情况下,图将具有相同的输入和输出结构。对于 invoke() 方法,支持单个输入,它的输入可以是字典或任何其他类型,默认返回最新的 State。打印结果如下:
python
配送包裹: P001
最终状态: 已签收
配送历史: ['在北京揽收', '分拣至上海分拣中心', '标准陆运', '已送达上海']
总里程: 500
配送包裹: P002
最终状态: 已签收
配送历史: ['在广州揽收', '分拣至其他地区分拣中心', '空运加急', '已送达乌鲁木齐']
总里程: 800到此,我们已经构建出了一个图式的智能快递配送系统,来理解 LangGraph 图的基本能力与用法!核心概念回顾:
- State = 包裹信息卡(记录所有状态)
- Nodes = 配送站点(执行具体操作)
- Edges = 运输路线(控制流转顺序)
- Reducers = 信息更新规则(如何记录变更)
- 编译 = 从路线图到运营系统的转换