目录
[一、POSIX 线程库](#一、POSIX 线程库)
[1. 什么是 pthread](#1. 什么是 pthread)
[2. 为什么不是标准库](#2. 为什么不是标准库)
[1. pthread_create](#1. pthread_create)
[2. 代码示例](#2. 代码示例)
[三、线程 ID 与 LWP](#三、线程 ID 与 LWP)
[1. pthread_self](#1. pthread_self)
[2. 什么是 LWP](#2. 什么是 LWP)
[3. Linux 如何看待线程](#3. Linux 如何看待线程)
[1. 线程退出](#1. 线程退出)
[2. 线程等待](#2. 线程等待)
[3. 线程分离](#3. 线程分离)
[1. pthread_t](#1. pthread_t)
[2. TCB](#2. TCB)
[3. 线程栈](#3. 线程栈)
[4. 线程局部存储](#4. 线程局部存储)
[5. 线程栈、TCB 与 TLS 的关系](#5. 线程栈、TCB 与 TLS 的关系)
[6. pthread_create 时到底发生了什么](#6. pthread_create 时到底发生了什么)
[1. 为什么封装](#1. 为什么封装)
[2. 设计一个 Thread 类](#2. 设计一个 Thread 类)
一、POSIX 线程库
在上一篇文章中,我们从内核层面深入剖析了线程的核心要素------地址空间与页表。现在,让我们将这些底层原理转化为实际的代码实现
在 Linux 环境下,我们无法直接通过 C 语言的关键字来创建一个执行流,而是必须依赖一个强大的中介:POSIX 线程库
1. 什么是 pthread
pthread 全称为 POSIX Threads,是 IEEE 定义的一套关于线程的 API 标准
-
标准而非实现 :POSIX 只是定义了一套接口规范(函数名、参数、返回值),而 Linux 上的具体实现叫做 NPTL
-
用户态库:虽然线程在内核里对应的是 task_struct,但我们平时调用的 pthread_create 等函数,其实都实现在一个名为 libpthread.so 的动态库中
简单来说,pthread 是连接需求与"内核的执行流之间的那座桥梁
2. 为什么不是标准库
当你在代码里 #include <pthread.h>,编译时却发现编译器报错 "undefined reference to pthread_create"。这是因为 pthread 并不是 C 语言标准委员会定义的标准库
(1) 历史原因
C 语言(C89/C99)诞生的年代,计算机大多是单核处理器为主。因此,早期的C语言标准在设计时,完全没有考虑多线程并发的需求,语言本身缺乏原生的线程支持
直到 2011 年,C11 标准才正式引入了 threads.h,和 <thread> 。然而这些新标准的线程实现往往只是对现有系统线程 API 的封装。特别是在Linux系统下,其底层实现都高度依赖于pthread 库
(2) 系统强相关
线程的本质是 CPU 调度,这和操作系统的内核架构紧密耦合
-
C 标准库旨在提供跨平台的通用逻辑(如字符串处理、IO 缓冲)
-
线程库则需要深入操作系统内部,去调用 clone() 等系统调用。因此,它被设计为一个原生库
正因为它是一个外部的动态库,在使用 gcc 编译时,必须手动加上 -lpthread 选项
二、线程创建
在 Linux 编程中,创建一个新线程的唯一入口就是 pthread_create 函数
1. pthread_create
cpp
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);参数拆解
这个函数的参数设计非常考究,体现了 C 语言对"通用性"的极致追求:
-
thread(输出型参数) : 指向 pthread_t 类型变量的指针。当函数成功返回时,它会被写入新线程的 ID
-
attr: 用于设置线程属性(如栈大小、优先级、分离状态等)。大多数场景下,我们传入 NULL,表示使用默认属性
-
start_routine : 这是一个函数指针。它代表了新线程要执行的任务
-
其格式是:void* func_name(void* arg)
-
这就像是进程里的 main 函数,新线程一旦诞生,就会跳到这里开始运行
-
-
arg: 传递给 start_routine 的参数。因为它是 void* 类型,你可以传递任何类型:一个整数、一个字符串,甚至是一个复杂的结构体
返回值
与大多数 Linux 系统调用(成功返回 0,失败返回 -1 并设置 errno)不同,pthread 系列函数:
-
成功返回 0
-
失败返回错误码。 它不设置全局的 errno,因为 errno 在多线程环境下如果不进行特殊处理,会产生竞态条件
2. 代码示例
cpp
// 线程执行的任务
void* thread_run(void* arg) {
const char* name = (const char*)arg;
while (1) {
printf("我是新线程[%s], PID: %d\n", name, getpid());
sleep(1);
}
}
int main() {
pthread_t tid;
// 创建线程
pthread_create(&tid, NULL, thread_run, (void*)"New Thread");
// 主线程继续执行
while (1) {
printf("我是主线程, PID: %d, 我创建的线程ID是: %lu\n", getpid(), tid);
sleep(1);
}
return 0;
}运行结果分析:
-
PID 相同:你会发现主线程和新线程打印出来的 getpid() 是完全一样的。这印证了我们上一篇的结论:它们属于同一个进程,共享同一套地址空间
-
并发执行:屏幕上会交替出现两个线程的打印,说明它们在不同的执行流中并行运作
三、线程 ID 与 LWP
虽然我们在代码中通过 pthread_create 获取了 pthread_t 类型的 ID,但这个 ID 在内核层面可能无法被识别
Linux 底层实际上维护着两套相互关联却又截然不同的身份标识系统
1. pthread_self
cpp
#include <pthread.h>
// 获取线程ID
pthread_t pthread_self(void);新线程获取线程 ID 可以通过 pthread_self 函数,该函数返回一个 pthread_t 类型的变量,用于标识调用线程的 ID。这个 ID 是 pthread 库为每个线程分配的进程内唯一标识符,由 pthread 库自身维护
需要注意的是,由于每个进程拥有独立的内存空间,这个 ID 的作用范围仅限于进程内部,操作系统内核并不识别该标识。实际上,pthread 库是通过内核系统调用(如 clone)来创建线程的,内核会为每个线程分配一个系统全局唯一的 ID 来标识线程
2. 什么是 LWP
虽然我们在用户态叫它 "线程",但在内核调度器看来用户态所谓的 "线程",就是一个轻量级进程
-
LWP :全称 Lightweight Process
-
唯一性:每一个线程(包括主线程)在内核中都有一个唯一的 LWP 编号
-
调度单位 :CPU 调度的基本单位不是 PID,而是 LWP
观察 LWP:ps 命令
运行我们上一节写的那个多线程程序,然后打开另一个终端,输入:
bash
ps -aL | head -n 1 && ps -aL | grep a.out我们可以看到这样的输出

解析:
-
PID 相同:这两个条目的 PID 都是 3334741,说明它们属于同一个进程。
-
LWP 不同:两个执行流的 LWP 分别是 3334741 和 3334742
-
主线程特征 :你会发现,主线程的 LWP 等于 PID
3. Linux 如何看待线程
早期的操作系统可能会区分进程调度和线程调度,但 Linux 采取了极其高效的做法:统而治之
在内核中,进程和线程均由 task_struct 结构体表示。内核的调度机制会依据既定算法,从任务队列中选取合适的 LWP 分配给 CPU 执行
-
TGID :这是 task_struct 里的一个字段。对于同一进程的所有线程,它们的 TGID 都等于主线程的 PID。我们平时调用 getpid(),其实拿到的就是这个 TGID
-
内核逻辑:
-
如果一个任务独占一个地址空间,它就是传统意义上的进程
-
如果多个任务共享一个地址空间(相同的 mm_struct),它们就是同一进程下的多线程
-
结论: Linux 并没有真正的原生线程 ,它只有通过共享资源实现的轻量级进程。这种设计让内核的调度逻辑保持了惊人的简洁和高效
四、线程终止与等待
线程作为 "轻量级进程",其生命周期管理与进程如出一辙。进程通过 exit 和 waitpid 实现生命周期控制,而线程则对应使用 pthread_exit 和 pthread_join 来完成类似功能
1. 线程退出
一个线程要结束自己的使命,通常有三种方式。这里我们要特别注意:绝对不能在线程里调用 exit(),因为那是给进程准备的。一旦调用,整个进程(包括所有线程)都会瞬间暴毙
(1) 函数 return
这就像 main 函数执行结束一样,线程函数执行完毕并返回一个指针
- 注意:主线程 return 相当于调用 exit,会导致整个进程退出;而普通线程 return 只代表该线程结束
(2) pthread_exit()
cpp
void pthread_exit(void *retval);-
这相当于进程中的 exit()
-
作用:谁调用,谁退出。retval 是退出码,可以被其他线程拿到
(3) pthread_cancel()
cpp
int pthread_cancel(pthread_t thread);-
这相当于进程中的 kill 信号
-
作用:一个线程请求取消另一个线程。被取消的线程其退出码通常是常数 PTHREAD_CANCELED(在 Linux 中通常是 -1)
2. 线程等待
在进程中,如果子进程退出了,父进程不读取其状态,子进程就会变成僵尸进程。线程也有这样的问题
cpp
int pthread_join(pthread_t thread, void **retval);-
类比:这就是线程版的 waitpid
-
功能:
-
阻塞等待:调用线程会挂起,直到目标线程退出
-
资源回收:回收线程在用户态库中残留的资源(如线程描述符、栈空间)
-
获取返回值:通过 retval 拿到线程退出时传出的指针
-
为什么需要等待?
既然线程共享地址空间,为什么它们退出后不能自动把资源还给系统?
-
获取结果:创建线程往往是为了让它去干活,主线程需要知道活儿干得怎么样了(返回值)
-
防止资源泄露 : 虽然线程的大部分资源随着进程结束而销毁,但在进程运行期间,已退出的线程如果不被 join,它在线程库内部占用的部分私有栈空间等是不会释放的
如果程序不断创建新线程而不等待,最终会导致无法创建更多线程,甚至内存溢出
关于参数 retval
pthread_join 的第二个参数为什么要传二级指针?
本质原因:线程退出的返回值是一个 void*(一级指针)。如果我们想在主线程里修改一个 void* 变量的值来获取结果,根据 C 语言的传参规则,我们必须传递这个变量的地址,即 void**
进程与线程对比
| 进程 | 线程 | |
|---|---|---|
| 正常退出 | exit(status) | pthread_exit(void *retval) 或 return |
| 外部终止 | kill(pid, sig) | pthread_cancel(tid) |
| 等待函数 | wait / waitpid | pthread_join |
| 等待特性 | 可阻塞也可非阻塞 | 必须阻塞(直到目标退出) |
| 清理后果 | 释放 PCB、页表、内存 | 释放库维护的描述符、用户态栈 |
3. 线程分离
线程分离是一种状态。一旦线程被设置为分离状态,它在退出时会自动释放所有资源,不需要也不允许其他线程来 join 它
cpp
int pthread_detach(pthread_t thread);(1) 使用方式
-
主线程分离子线程:主线程在创建完子线程后,直接调用 pthread_detach
-
线程自我救赎:子线程可以在自己的执行函数里调用 pthread_detach(pthread_self()),实现自我管理
(2) 概念
-
可结合(Joinable):线程处于可结合状态时,其资源(如线程ID、栈空间等)不会被系统自动回收。其他线程可以通过调用 pthread_join 函数来等待该线程结束并获取其返回值
-
已分离(Detached):线程处于已分离状态时,其资源会在线程终止时由系统自动回收。其他线程无法通过 pthread_join 等待该线程
类比守护式线程
在进程层面上,我们有守护进程,它们脱离终端,在后台运行。分离线程 在逻辑上非常类似于守护式线程
-
后台运行:它们通常执行的是周期性的、辅助性的任务,比如心跳检测、日志刷盘、垃圾回收
-
无需等待:主线程不需要停下来等它们的结果,主逻辑忙主逻辑的,分离线程忙它自己的
虽然它是守护式,但它不会永生, 很多人误以为分离线程可以脱离进程独立存在。**这是错误的。**线程分离只是脱离了主线程的 join 约束。如果进程(主线程)执行结束退出了,地址空间被销毁,所有的分离线程都会瞬间强制关停
六、线程与地址空间
为了确保每个线程能够独立执行函数调用并存储局部变量,线程库(pthread)在进程地址空间中划分了专属的内存区域
1. pthread_t
在 Linux 中,pthread_t 的类型通常是 unsigned long。当你打印它时,会看到一个巨大的数字
本质上: pthread_t 实际上是一个内存地址 。它指向进程地址空间中 共享区(Library Mapping Area) 的一块内存。这块内存里存放着该线程的控制信息结构------TCB (Thread Control Block)
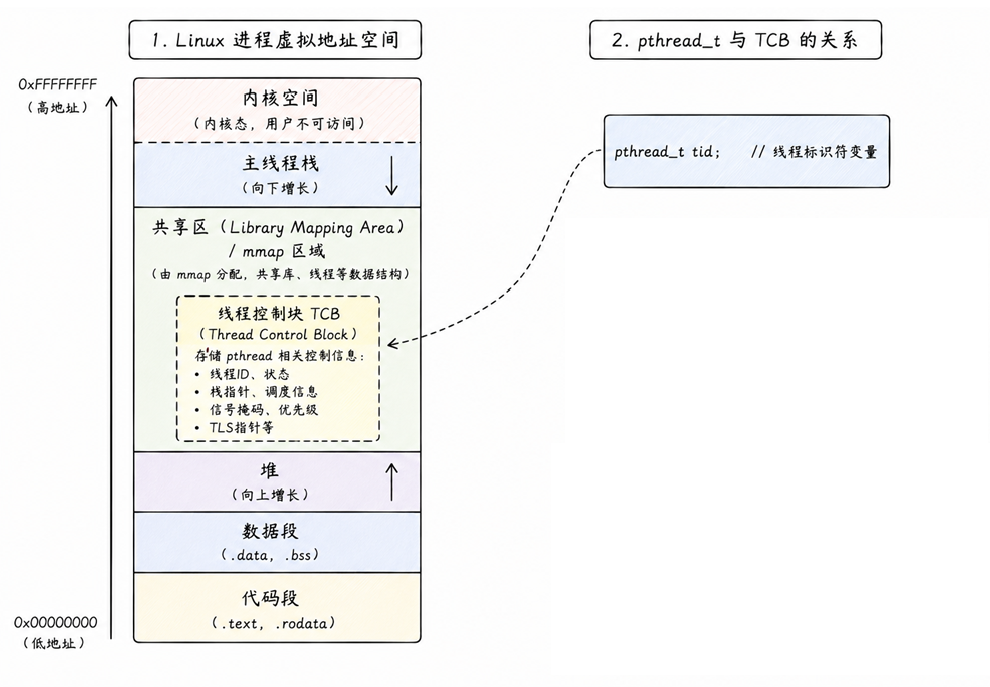
2. TCB
在内核里,线程对应的是 PCB;但在用户态线程库里,线程对应的是 TCB
在 Linux 的 glibc 源码中,这个 TCB 结构体的名字叫 struct pthread。它是线程库管理线程的核心
-
源码路径(以 glibc-2.x 为例):nptl/descr.h
-
核心内容:

3. 线程栈
我们要纠正一个常见的误区:新线程的栈并不在进程原本的栈区里
-
进程主栈:位于地址空间的最顶部,供主线程使用。它会随着调用深度的增加动态向下增长
-
新线程栈 :当你调用 pthread_create 时,线程库会利用 mmap 系统调用,在堆(Heap)和栈(Stack)之间的共享区里申请一块匿名内存
为什么每个线程都有独立的局部变量?
-
物理隔离:每个线程在创建时,线程库都会分配一块固定大小(默认通常是 8MB)的内存作为它的私有栈
-
寄存器隔离 :当 CPU 调度到某个线程时,CPU 的 栈指针寄存器(如 %rsp) 会立即指向该线程专属的栈地址
-
互不干扰:线程 A 在自己的栈里压栈,线程 B 在自己的栈里出栈。虽然它们在一个地址空间里,但各自拥有独立的栈空间,局部变量自然也是相互隔离的
线程栈与进程栈
虽然都叫栈,但它们有着本质的区别:
| 进程主栈 | 线程栈 | |
|---|---|---|
| 位置 | 地址空间顶部(高地址) | 共享区(mmap 映射区域) |
| 大小 | 动态增长,很大(通常上限是 8MB,但可扩充) | 固定大小(创建时确定,默认 8MB) |
| 管理者 | 操作系统内核直接管理 | 动态库负责申请和释放 |
| 溢出风险 | 相对较难溢出 | 容易溢出 |
深度思考:线程栈是绝对私有的吗?
答案是:逻辑上私有,物理上共享
-
由于所有线程共享同一个页表(地址空间),这意味着线程 A 理论上有权限读写线程 B 的栈空间
-
如果你把线程 A 的一个局部变量地址通过全局变量传给线程 B,线程 B 是可以修改它的
结论: 线程栈的私有靠的是约定俗成。每个线程只动自己 %rsp 指向的那块地盘。如果你强行跨界,系统不会像进程那样报段错误,但你的代码逻辑会变得极其混乱且危险
4. 线程局部存储
线程局部存储是一种允许每个线程拥有自己独立数据副本的机制。在多线程编程中,当多个线程需要访问相同的全局或静态变量时,TLS 可以确保每个线程操作的是自己的数据副本,从而避免数据竞争和同步问题
cpp
__thread int g_val = 100; // 每个线程都会拥有一份独立的 g_val实现机制:
-
编译器会在目标文件中开辟一个特殊的段(.tdata 或 .tbss)
-
当新线程创建时,线程库会把这些段的内容拷贝到该线程独有的内存区域(就在 TCB 附近)
-
访问方式 :通过 CPU 的段寄存器(x86 上的 FS 或 GS)作为基址,加上偏移量来访问
5. 线程栈、TCB 与 TLS 的关系
当你调用 pthread_create 时,线程库并不是简单地申请一个栈,而是通过 mmap 申请了一大块内存区域。这块区域被划分成了三个部分:
-
线程栈:占据了这块内存的绝大部分空间
-
TLS:紧随其后,存储 __thread 变量
-
TCB:通常位于这块内存的末尾(高地址处)
关系: pthread_t 的值,本质上就是这块内存区域中 struct pthread**(TCB)的起始地址**。这就是为什么通过 pthread_t 就能控制线程的一切
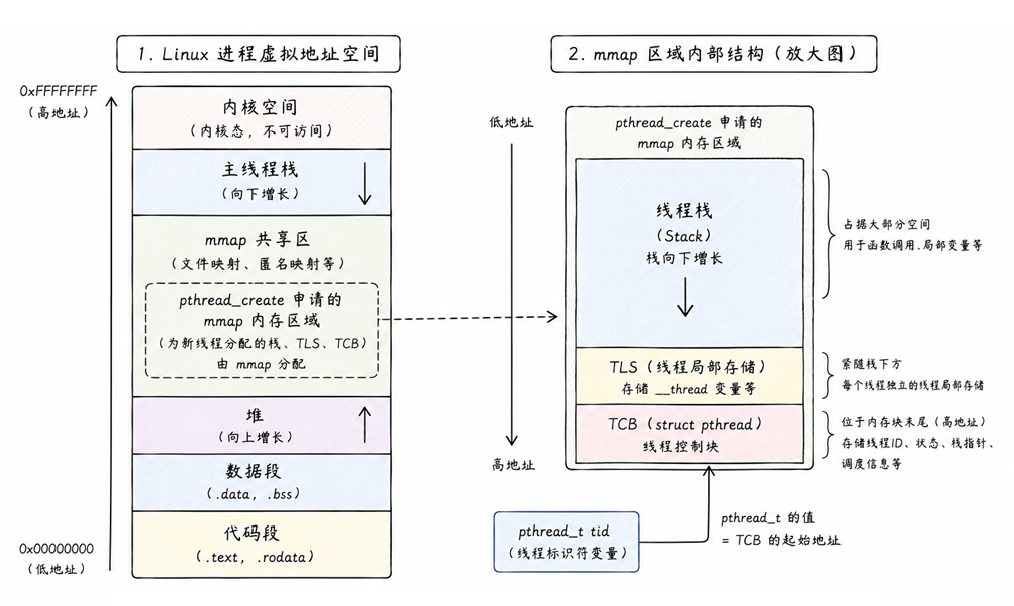
为什么 pthread_self 能瞬间拿到对象?
这是一个非常精妙的设计。如果线程想知道自己的线程 ID,调用 pthread_self 几乎是零延迟的
原理: 在 x86_64 架构下,Linux 内核会利用 CPU 的 FS 寄存器
-
在线程切换时,内核会将 FS 寄存器的值指向当前线程的 TCB 地址
-
pthread_self 的实现代码大概长这样(伪汇编):
bash
movq %fs:0, %rax ; 直接从 FS 寄存器指向的内存偏移量 0 处读取 TCB 地址
ret因为不需要陷入内核,也不需要查表,仅仅是一条普通的 CPU 指令,所以它快得惊人
6. pthread_create 时到底发生了什么
调用 pthread_create 函数时,整体执行流程如下
-
内存空间申请:线程库通过 mmap 在进程共享地址空间中,申请一块大小充足的内存区域,默认包含 8MB 内存以及 TCB、TLS 所需空间
-
线程控制块初始化:在内存末端初始化 struct pthread(TCB),填充线程属性
-
存储初始化:为当前线程分配并初始化 TLS 线程本地存储空间
-
发起系统调用:调用底层 clone 系统调用,进入内核执行创建逻辑
-
创建一个新的 task_struct
-
让新任务的栈指针(RSP)指向刚才 mmap 出来的栈空间
-
设置新任务的 FS 寄存器指向 TCB
-
-
完成线程创建:
-
内核里产生了一个新的 LWP,开始由调度器支配
-
用户态 pthread_create 函数将 TCB 结构地址回写到传入的线程指针参数中,最终返回 0,表示创建成功
-
七、线程封装
经过前面的底层拆解,你已经掌握了线程从内存布局到内核调度。但在实际的工业级开发中,我们很少直接在业务代码里裸写 pthread_create
原因很简单:原生 C 接口过于生硬,不符合面向对象的高效开发直觉。最后一节,我们聊聊如何通过封装,把生涩的线程库变成优雅的 C++ 工具
1. 为什么封装
直接使用 pthread 原生 API 有几个非常痛的槽点:
-
类型不安全:void* 传参像黑盒,必须手动强转,容易出错
-
代码耦合:线程的逻辑和主逻辑混在一起,难以维护
-
this 指针:在 C++ 成员函数里调用 pthread_create 非常麻烦,因为成员函数带有一个隐藏的 this 指针,而 pthread 需要的是一个纯粹的函数地址
-
资源管理:如果不小心忘了 join 或 detach,就会产生我们前面聊过的僵尸线程
2. 设计一个 Thread 类
我们要利用 RAII 的思想,将线程的声明周期与对象的生命周期绑定
核心难点:静态代理
由于 pthread_create 要求的回调函数格式必须是 void* func(void*),而 C++ 类成员函数其实是 void* func(Thread* const this, void*)
解决方案:定义一个静态成员函数作为中间人,通过传参把 this 指针递进去
cpp
#include <iostream>
#include <string>
#include <pthread.h>
#include <functional>
class Thread
{
public:
// 定义一个回调类型,方便用户传入 lambda 或函数
using func_t = std::function<void(void*)>;
Thread(func_t func, void* arg, std::string name)
: _func(func), _arg(arg), _name(name), _tid(0), _is_running(false)
{}
// 静态成员函数:解决 this 指针问题
static void* thread_routine(void* arg)
{
Thread* self = static_cast<Thread*>(arg); // 拿到当前对象的指针
self->_func(self->_arg); // 执行真正的业务逻辑
return nullptr;
}
// 启动线程
void start()
{
int n = pthread_create(&_tid, nullptr, thread_routine, this);
if (n == 0)
_is_running = true;
}
// 等待线程
void join()
{
if (_is_running) {
pthread_join(_tid, nullptr);
_is_running = false;
}
}
std::string name() { return _name; }
pthread_t tid() { return _tid; }
private:
pthread_t _tid;
std::string _name;
bool _is_running;
func_t _func; // 用户要执行的任务
void* _arg; // 任务参数
};经过封装后,在 main 函数中调用变得极其自然流畅:
cpp
void my_task(void* arg) {
std::string msg = (char*)arg;
for(int i = 0; i < 5; ++i) {
std::cout << "线程正在运行: " << msg << std::endl;
sleep(1);
}
}
int main() {
Thread t1(my_task, (void*)"Data-01", "Thread-1");
t1.start();
std::cout << "创建了线程: " << t1.name() << " , ID: "
<< t1.tid() << std::endl;
t1.join();
return 0;
}总结
综上所述,从 POSIX 线程库到 pthread_create,从 pthread_t 到 LWP,再到线程栈与地址空间布局,我们逐步建立起了对 Linux 线程机制的整体认知。虽然在线程接口层面看起来只是简单地创建了一个执行流,但其背后实际上仍然依赖于内核中的 task_struct、调度器以及共享地址空间体系
与此同时,我们也进一步理解了:线程之所以被称为轻量级进程,并不是因为它不需要管理,而是因为多个线程共享了同一套进程资源,从而避免了进程级别的大量内存与页表开销
但共享带来高效的同时,也意味着风险。当多个线程同时访问同一份资源时,执行顺序的不确定性很容易导致数据不一致、竞争条件甚至程序崩溃。也正因如此,现代多线程编程中最核心的问题,往往已经不再是"如何创建线程",而是:
如何让多个线程安全、有序地协同工作
在下一篇中,我们将正式进入线程同步与互斥机制,深入理解互斥锁、线程竞争、临界区以及线程安全背后的真正原理。
