对抗数据系统熵增:分层解耦驱动的数据仓库建模方法论与实践指南

版本:V1.0
摘要
本文基于某A公司数据仓库建设的深度实践,针对数据仓库建设中普遍存在的"质量差、效率低、成本高、反复重造"四大共性痛点,提出了一套以"分层解耦+场景适配"为核心的新数据建模方法论。通过明确界定明细层(DWD)与集市层(ADS/DWS)的定位差异,采用"领域驱动3NF建模+场景化维度建模"的双轨设计策略,有效解决了传统数据仓库体系中"复用性与易用性冲突""短期需求与长期发展矛盾"等核心问题。本文不仅阐述了方法论的理论基础,更提供了从概念模型抽象、用例驱动关联关系提取、到治理体系建设的完整落地路径,旨在为数据仓库从业者提供一套可操作、可度量、可持续演进的实践指南。
一、引言:数据建模是数据仓库的核心基石
1.1 为什么数据仓库需要独立的建模方法论
在数字化转型的浪潮中,数据仓库已成为企业数据驱动决策的核心基础设施。然而,大量企业在数据仓库建设过程中陷入了一个共同的困境:初期建设时数据模型清晰、结构合理,但随着业务需求的不断增长和数据量的持续膨胀,数据系统逐渐变得混乱不堪------表与表之间的依赖关系错综复杂、数据冗余严重、查询性能急剧下降、维护成本居高不下。最终,企业不得不投入大量资源进行全局性的数据重建,但重建后的系统往往在短期内再次陷入同样的困境。
这一现象的本质,是数据系统在面对持续变化的业务需求时,缺乏一套科学的建模方法论来维持系统的有序性。数据仓库不是业务数据库的简单复制,也不是数据表的随意堆砌,它需要一套独立于OLTP系统的建模理论和方法。
1.2 OLTP与OLAP的本质差异
数据仓库建设的首要前提是深刻理解事务处理(OLTP)与分析处理(OLAP)之间的本质差异。这两种系统在应用场景、实时性要求、数据特征和建模逻辑上存在根本性的不同:
| 对比维度 | OLTP(联机事务处理) | OLAP(联机分析处理) |
|---|---|---|
| 核心定位 | 面向应用、事务驱动(增删查改) | 面向主题、决策驱动(复杂分析、报表) |
| 实时性要求 | 高(毫秒级响应) | 低(分钟/小时级即可) |
| 数据特征 | 仅存储当前数据,更新频繁 | 存储历史+当前数据,相对稳定 |
| 查询模式 | 简单查询为主,单条或小批量记录操作 | 复杂查询为主,大量数据聚合分析 |
| 建模逻辑 | 以业务流程为参考(如订单流、用户流) | 以业务主题为参考(如经营分析、风控主题) |
| 数据一致性 | 强一致性(ACID) | 最终一致性(允许短暂延迟) |
| 并发模式 | 高并发短事务 | 低并发长事务 |
理解这些差异的意义在于:许多企业在建设数据仓库时,直接照搬OLTP系统的数据库设计思路,将业务库的表结构原封不动地复制到数据仓库中。这种做法看似省事,实则埋下了巨大的隐患------OLTP系统的设计目标是支撑高并发的日常事务操作,其表结构高度规范化(通常满足3NF甚至BCNF),这导致在进行复杂分析时需要大量的表关联(JOIN),查询性能极差。
1.3 数据仓库的四大核心支撑场景
数据仓库的价值不仅体现在存储数据,更体现在为不同类型的决策场景提供高质量的数据支撑。根据实践经验,数据仓库的核心场景可归纳为以下四类:
(1)经营决策场景
这是数据仓库最传统也最核心的应用场景。通过构建指标仪表盘、经营分析报告等数据产品,为管理层提供企业运营的全景视图。典型需求包括:
- 核心经营指标(GMV、营收、利润、用户增长等)的实时监控与趋势分析
- 各业务线、各区域的业绩对比与贡献度分析
- 预算执行情况的跟踪与偏差分析
(2)运营决策场景
面向运营团队的数据消费场景,强调对用户群体的精细化洞察和运营效果的量化评估。典型需求包括:
- 用户标签体系构建与人群细分
- 运营活动效果复盘(如转化率、留存率、ROI分析)
- 用户行为路径分析与漏斗转化优化
(3)模型决策场景
为算法模型和风控模型提供训练数据和特征工程支持。这类场景对数据的质量、完整性和时效性要求极高。典型需求包括:
- 风控模型的特征数据准备与样本构建
- 推荐系统/搜索算法的训练数据供给
- 机器学习模型的在线特征服务
(4)程序决策场景
将数据分析结果直接回流至业务系统,实现自动化的程序决策。这是数据价值闭环的关键环节。典型需求包括:
- 风险拦截规则引擎的数据支撑
- 自动化营销触达(如精准推送、个性化优惠)
- 业务系统的实时决策参数供给
这四大场景构成了从"数据→洞察→决策→行动"的完整闭环,数据仓库的建设必须围绕这些场景的需求展开,而非单纯追求技术层面的完美。
1.4 数据系统的"熵增危机"
热力学第二定律告诉我们:在一个封闭系统中,熵(混乱度)必然持续增加。数据系统同样面临这一规律------如果没有有效的治理机制,数据系统的混乱度会随着时间的推移不断加剧,最终导致系统崩溃。
熵增的典型表现:
| 熵增指标 | 具体表现 | 危害程度 |
|---|---|---|
| 反向依赖占比 | 下层模型依赖上层模型的数据 | 🔴 严重------破坏分层架构 |
| 跨层依赖占比 | 跳过中间层直接依赖非相邻层 | 🔴 严重------增加耦合度 |
| 资产重复率 | 相同或相似的数据在多处冗余存储 | 🟠 高------浪费存储、口径不一致 |
| 域内内聚度低 | 同一业务域内的表之间关联松散 | 🟠 高------难以理解和维护 |
| 跨域耦合度高 | 不同业务域之间的表过度关联 | 🟠 高------变更影响范围大 |
| 枢纽节点过多 | 某些表被过多其他表依赖 | 🟡 中------单点故障风险 |
| ODS穿透 | 直接从ODS层取数,绕过DWD层 | 🔴 严重------丧失数据治理能力 |
| 不合理跨域依赖 | 非必要的跨业务域数据依赖 | 🟠 高------增加系统复杂度 |
熵增的直接后果:
- 数据质量下降:数据口径不一致、数据重复计算、数据链路断裂等问题频发
- 查询效率降低:表关联复杂、数据冗余导致查询性能急剧下降
- 存储成本飙升:重复存储、无效表未清理导致存储资源浪费
- 维护成本增加:系统复杂度上升导致新人上手困难、变更风险增大
- 决策效率弱化:数据不可信、查询慢直接影响了业务决策的时效性和准确性
某A公司在过去曾通过多次全局重造(2018-2019年治理计划、2020-2021年资产重建)来对抗熵增,但实践表明:全局重造成本高昂(通常需要数月甚至数年的时间)、风险巨大(容易引入新的数据问题)、且效果难以持久(熵增趋势很快再次显现)。因此,必须从方法论层面找到一种可持续的、低成本的熵增控制机制。
二、旧方法论的困境:从"既要又要"到目标冲突
2.1 传统OneData分层建模的核心假设
传统的数据仓库分层建模方法(如阿里巴巴的OneData方法论)试图通过统一的数据规范来解决数据仓库建设中的各种问题。其核心假设是:通过建立一套标准化的分层体系(ODS→DWD→DWS→ADS),每一层都有明确的职责定位,就可以同时满足"短期需求效率"和"长期可持续发展"两个目标。
这一假设在理论上看似完美,但在实践中却暴露出了严重的结构性问题。
2.2 困境一:场景适配不足
旧方法论的一个根本缺陷是:它以"数据本身特征"为分层依据,而没有充分考虑不同消费场景的差异化需求。
具体表现:
- 明细宽表的归属模糊:一张包含大量字段的明细宽表,应该放在DWD层还是DWS层?旧方法论没有给出明确的答案。如果放在DWD层,违背了DWD层"精简、规范"的设计原则;如果放在DWS层,那么DWS层的定位又变得模糊------它到底是聚合层还是明细层?
- 责任边界不清:当一张表同时被多个团队使用时,谁来负责它的治理?数仓团队认为这是业务团队的需求,应该由业务团队负责;业务团队认为这是数仓团队建设的公共表,应该由数仓团队负责。
- 消费场景未区分:自助分析场景需要的是"易理解、易使用"的数据模型,而程序化消费场景需要的是"高性能、高稳定"的数据模型。旧方法论将这两种场景混为一谈,导致模型设计无法兼顾。
2.3 困境二:人才要求过高
旧方法论对数据仓库工程师的能力要求极高,要求公共层工程师同时掌握两种截然不同的建模方法:
- 3NF建模(规范化建模):关注业务本质的表达,强调减少数据冗余、保证数据一致性
- 星型建模(维度建模):关注分析效率的提升,强调减少表关联、提升查询性能
这两种建模方法在设计理念、技术要求和评价标准上存在根本性的差异。要求一个工程师同时精通这两种方法,并且在实践中灵活切换,是不现实的。其结果是:公共层建设往往变成"四不像"------既没有达到3NF的规范化水平,也没有达到星型模型的分析效率。
能力要求与人才供给的矛盾:
| 所需能力 | 传统要求 | 市场供给 | 矛盾程度 |
|---|---|---|---|
| 3NF规范化建模能力 | 精通 | 较少 | 🔴 高 |
| 维度建模能力 | 精通 | 中等 | 🟠 中高 |
| 业务理解能力 | 深入 | 稀缺 | 🔴 高 |
| SQL性能优化能力 | 熟练 | 中等 | 🟡 中 |
| 数据治理能力 | 熟练 | 稀缺 | 🔴 高 |
2.4 困境三:分层目标冲突(典型案例深度剖析)
以某A公司实际发生的一个典型案例来说明旧方法论的目标冲突问题。
需求背景: 业务分析团队需要一张"用户交易状态汇总表",用于日常的经营分析和报表制作。
旧方法论下的两种方案:
| 维度 | 方案A(数仓视角------复用导向) | 方案B(经分视角------易用导向) |
|---|---|---|
| 设计方案 | 复用现有的DWD明细表和DWS聚合表,通过JOIN获取所需数据 | 新建一张宽表,将所有需要的字段整合到一张表中 |
| SQL复杂度 | 需要多表JOIN,SQL编写复杂 | 直接SELECT,SQL简单直观 |
| 查询性能 | 多表JOIN导致查询较慢 | 单表查询,性能优秀 |
| 数据冗余 | 无冗余,复用现有表 | 存在冗余,新增宽表 |
| 研发效率 | 高(无需新建表) | 低(需要新建表并开发ETL) |
| 维护成本 | 低(依赖关系清晰) | 高(新增表需要维护) |
| 业务友好度 | 差(需要理解多表关系) | 优(一张表搞定) |
冲突的本质:
经分同学的核心诉求是"语义清晰、SQL编写简单、查询快",而数仓同学的核心诉求是"研发效率高、模型可复用"。这两种诉求在旧方法论的框架下是无法同时满足的。
根因分析:
问题的根源在于:数仓团队用"中间层复用逻辑"来建设集市层,忽略了集市层的核心价值是快速响应分析需求。在旧方法论中,DWS层被定位为"轻度聚合层",既要承担数据聚合的职责,又要承担数据消费的职责。这种"既要又要"的定位,导致了目标的内在冲突。
最终决策:
某A公司最终采用了方案B(新建宽表),但这一决策暴露了旧体系中"分层定位模糊"的致命问题。更重要的是,如果每次遇到类似需求都新建宽表,数据仓库将迅速膨胀,治理成本将呈指数级增长。
三、新方法论的核心设计:分层解耦与场景适配
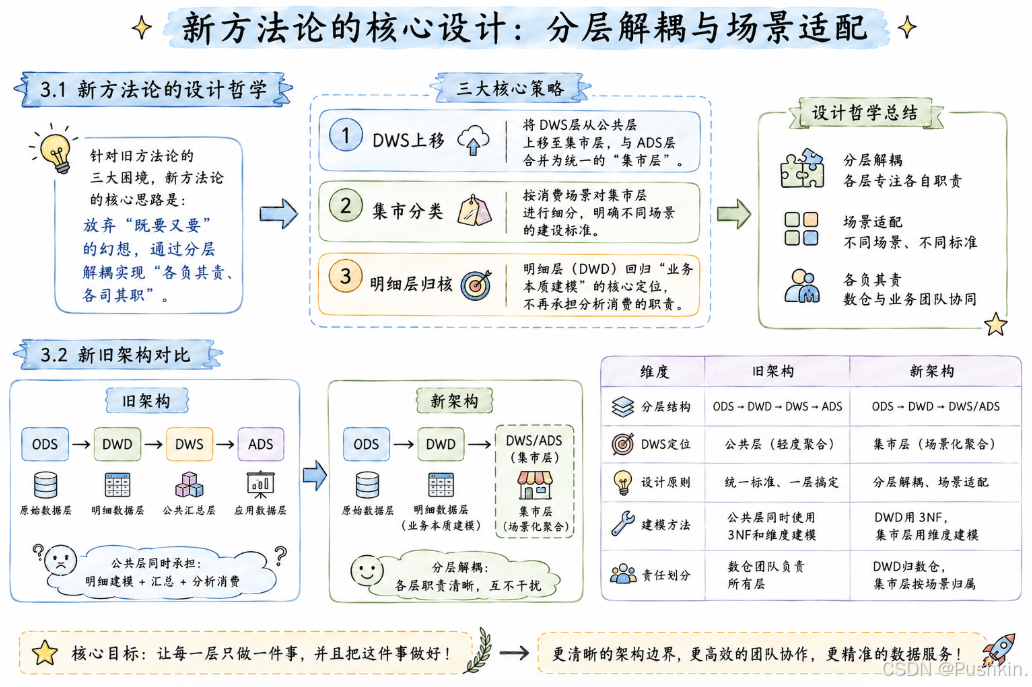
3.1 新方法论的设计哲学
针对旧方法论的三大困境,新方法论的核心思路是:放弃"既要又要"的幻想,通过分层解耦实现"各负其责、各司其职"。
具体而言,新方法论包含三个核心策略:
- DWS上移:将DWS层从公共层上移至集市层,与ADS层合并为统一的"集市层"
- 集市分类:按消费场景对集市层进行细分,明确不同场景的建设标准
- 明细层归核:明细层(DWD)回归"业务本质建模"的核心定位,不再承担分析消费的职责
3.2 新旧架构对比
| 维度 | 旧架构 | 新架构 |
|---|---|---|
| 分层结构 | ODS→DWD→DWS→ADS | ODS→DWD→DWS/ADS |
| DWS定位 | 公共层(轻度聚合) | 集市层(场景化聚合) |
| 设计原则 | 统一标准、一层搞定 | 分层解耦、场景适配 |
| 建模方法 | 公共层同时使用3NF和维度建模 | DWD用3NF,集市层用维度建模 |
| 责任划分 | 数仓团队负责所有层 | DWD归数仓,集市层按场景归属 |
3.3 分层调整策略详解
| 层级 | 定位调整 | 建模方法 | 核心目标 | 负责人 |
|---|---|---|---|---|
| 明细层(DWD) | 仅保留业务本质建模,不再承担分析消费职责 | 领域驱动3NF规范化建模 | 稳定、可扩展、表达业务语义 | 数仓团队 |
| 集市层(DWS/ADS) | DWS上移至集市层,按场景分类建设 | 维度建模(星型/雪花模型) | 分析易用、查询性能高、响应快 | 数仓团队+业务团队 |
关键变化解读:
-
DWD层的"减法":DWD层不再试图满足所有消费场景的需求,而是专注于做好一件事------准确、完整地表达业务本质。这降低了DWD层的复杂度,提高了其稳定性和可扩展性。
-
集市层的"加法":集市层承担了场景化消费的所有职责,包括轻度聚合(原DWS层职责)和高度聚合(原ADS层职责)。这使得集市层可以根据具体场景灵活设计,不再受限于公共层的统一标准。
-
责任边界的"清晰化":DWD层由数仓团队统一建设和维护,确保数据的一致性和准确性;集市层可以根据消费场景的不同,由数仓团队或业务团队分别建设,提高响应速度。
3.4 两层建模方法的差异对比
| 维度 | 明细层(DWD) | 集市层(DWS/ADS) |
|---|---|---|
| 设计目标 | 业务语义清晰、冗余少、可复用 | 分析需求响应快、查询性能高 |
| 建模方法 | 3NF规范化(减少冗余) | 星型/雪花模型(减少JOIN) |
| 表结构特征 | 表数量多、单表字段少、关联关系清晰 | 表数量少、单表字段多、宽表为主 |
| 变更频率 | 低(业务本质相对稳定) | 高(分析需求变化频繁) |
| 生命周期 | 长(通常3年以上) | 短(通常6个月-2年) |
| 质量评价标准 | 规范性、完整性、一致性 | 易用性、性能、覆盖率 |
| 缺点 | 直接分析性能低(需多表JOIN) | 易冗余,需配套治理机制 |
3.5 逻辑模型与物理模型的双层设计
新方法论强调逻辑模型与物理模型的分离,这是对抗熵增的关键设计:
集市层的双层设计:
- 逻辑模型:聚焦"易理解、易使用",面向业务用户。逻辑模型的设计原则是语义清晰、结构简洁,让业务用户能够用最少的学习成本理解数据结构。
- 物理模型:聚焦"查询性能、计存成本",面向技术实现。物理模型的设计原则是性能最优、成本可控,通过分区策略、索引设计、数据压缩等手段提升查询效率。
明细层的设计原则:
- 统一聚焦"稳定性、可扩展性、业务本质表达能力",逻辑模型与物理模型保持高度一致。
双层设计的价值:
通过逻辑模型与物理模型的分离,集市层可以在不改变逻辑模型的前提下,根据性能需求灵活调整物理模型。例如,同一张逻辑表可以根据查询模式的不同,在物理层拆分为多张不同粒度的表,从而实现性能与成本的平衡。
四、明细层建模实践:领域驱动的3NF落地
4.1 为什么明细层必须采用3NF建模
明细层是数据资产的"地基",其质量直接决定了上层数据消费的可靠性和灵活性。采用3NF(第三范式)建模的核心原因是:
- 稳定性:3NF建模以业务本质为依据,业务本质相对稳定,不会因为分析需求的变化而频繁变更
- 可扩展性:3NF建模将业务实体拆分为独立的表,新增业务维度时只需新增表或字段,不会影响现有结构
- 一致性:3NF建模消除了数据冗余,从源头上避免了数据不一致的问题
- 复用性:3NF建模的表结构清晰、关联关系明确,可以被多种分析场景复用
3NF建模的核心原则:
- 1NF(第一范式):每个字段都是不可再分的基本数据项
- 2NF(第二范式):在1NF基础上,消除部分函数依赖(非主键字段必须完全依赖于主键)
- 3NF(第三范式):在2NF基础上,消除传递函数依赖(非主键字段之间不能存在依赖关系)
4.2 概念模型→逻辑模型→物理模型的三层递进
建模必须遵循"概念→逻辑→物理"的三层递进原则,这是保证数据模型质量的关键。
第一层:概念模型(Conceptual Model)
概念模型是建模的起点,它从业务视角出发,提炼出业务的核心实体、属性及其关联关系。概念模型的特点是与具体技术实现无关,完全用业务语言描述。
概念模型的构成要素:
- 实体(Entity):业务中的核心对象,如"卖家""商品""报价""订单"
- 属性(Attribute):实体的特征描述,如"报价金额""币种""生效时间"
- 关系(Relationship):实体之间的关联,如"一个SKU对应多个报价"
第二层:逻辑模型(Logical Model)
逻辑模型将概念模型转化为程序可识别的结构,如Java Class、SQL表结构等。逻辑模型仍然独立于具体的数据库产品,但已经具备了技术实现的雏形。
逻辑模型的构成要素:
- 表结构:表名、字段名、字段类型、主键、外键
- 关联关系:表之间的JOIN关系、外键约束
- 业务规则:数据校验规则、默认值、约束条件
第三层:物理模型(Physical Model)
物理模型适配具体数据库的物理存储特性,如Hive、MySQL、ClickHouse等的分区策略、索引设计、存储格式等。
物理模型的构成要素:
- 存储格式:Parquet、ORC、Avro等
- 分区策略:按天/月/年分区
- 索引设计:B-Tree索引、Bitmap索引等
- 压缩算法:Snappy、ZSTD、LZ4等
三层递进的价值:
通过三层递进的建模方法,可以确保数据模型在每一层都有明确的关注点,避免将业务逻辑、技术实现和性能优化混为一谈。这也是对抗熵增的重要手段------每一层的变化都控制在自己的范围内,不会引发全局性的混乱。
4.3 概念模型抽象方法:31法则
为确保对业务的理解深度,某A公司提出了"31法则"------每个业务名词必须满足以下三个条件:
| 要素 | 要求 | 示例 |
|---|---|---|
| 1个名词(命名) | 用简洁的名词命名业务实体 | "商品" |
| 1句话(定义) | 用一句话精确定义该实体的本质 | "可供交易的物体" |
| 1段话(解释) | 用一段话详细说明该实体的范围、特征和业务规则 | "包含实物商品(如手机、服装)、虚拟商品(如会员权益、优惠券),是交易的核心载体。每个商品有唯一的SKU编码,关联价格、库存、分类等属性。" |
31法则的验证标准:
- 如果一个业务名词无法用一句话精确定义,说明对该实体的理解还不够深入
- 如果一个业务名词无法用一段话详细解释,说明对该实体的业务规则还不够清晰
- 如果多个业务名词的定义存在重叠或模糊,说明实体划分不够合理
31法则的实际应用案例:
| 名词 | 一句话定义 | 一段话解释 |
|---|---|---|
| 商品 | 可供交易的物体 | 包含实物商品(如手机、服装)、虚拟商品(如会员权益、优惠券),是交易的核心载体。每个商品有唯一的SKU编码,关联价格、库存、分类等属性。 |
| 报价 | 针对特定市场的商品价格设定 | 由卖家发布,关联SKU与市场,包含金额、币种、生效时间等属性。一个SKU在不同市场可以有多个不同的报价,报价的变更不影响历史交易记录。 |
| 订单 | 买家与卖家之间的交易契约 | 包含订单号、买家ID、卖家ID、商品列表、支付金额、订单状态等核心信息。订单状态流转遵循严格的业务规则(如创建→支付→发货→完成/取消)。 |
| 用户 | 使用平台服务的个体或组织 | 分为个人用户和企业用户,包含注册信息、身份认证、联系方式等属性。用户ID是全局唯一的标识符,贯穿整个数据体系。 |
4.4 用例驱动的关联关系抽象方法
在明确了业务实体之后,下一步是提取实体之间的关联关系。某A公司采用"用例驱动"的方法,通过分析业务用例中的名词、动词和量词,抽象出实体之间的关联关系。
用例驱动三步法:
| 步骤 | 提取对象 | 转化规则 | 示例 |
|---|---|---|---|
| 第一步 | 名词 | 提炼为实体 | "卖家""商品""SKU""报价""市场""币种" |
| 第二步 | 动词/状语 | 提炼为关联关系 | "发布"表示"卖家→报价"的拥有关系 |
| 第三步 | 量词 | 确定关系基数 | "一个SKU有多个报价"→SKU与报价是1:N关系 |
完整案例:俄罗斯卖家报价场景
原始用例描述:
"俄罗斯的卖家为商品SKU发布属于俄罗斯市场的、币种为卢布、金额为300的报价"
第一步:提取名词(实体)
- 卖家(Seller)
- 商品(Product)
- SKU(Stock Keeping Unit)
- 报价(Quotation)
- 市场(Market)
- 币种(Currency)
- 金额(Amount)
第二步:提取动词/状语(关联关系)
- "发布":表示"卖家→报价"的拥有关系(Seller has Quotation)
- "属于":表示"报价→市场"的归属关系(Quotation belongs to Market)
- "为商品SKU":表示"报价→SKU"的关联关系(Quotation references SKU)
第三步:提取量词(关系基数)
- "一个SKU有多个报价":SKU与报价是1:N关系
- "一个报价发布到一个市场":报价与市场是N:1关系
- "一个卖家有多个报价":卖家与报价是1:N关系
最终抽象出的关联网络:
卖家(1) ──发布──→ 报价(N) ──归属──→ 市场(1)
│
└──关联──→ SKU(1)关键设计原则:
所有业务逻辑(如"大权益未激活""风控拦截规则"等)均放在代码层(Java/SQL)实现,而非嵌入表结构中。这一原则确保了表结构的稳定性和可扩展性------业务规则的变化不需要修改表结构,只需修改代码逻辑即可。
4.5 概念模型验证清单
在完成概念模型设计后,建议通过以下清单进行验证:
| 验证项 | 检查内容 | 通过标准 |
|---|---|---|
| 31法则完整性 | 每个实体是否都有命名、定义和解释 | 全部满足 |
| 实体独立性 | 实体之间是否存在职责重叠 | 无重叠 |
| 关系完整性 | 所有业务用例中的关联关系是否都已抽象 | 全部覆盖 |
| 基数准确性 | 关系基数(1:1、1:N、N:M)是否正确 | 经业务确认 |
| 可扩展性 | 新增业务场景时是否需要修改现有结构 | 无需修改或仅需扩展 |
| 业务可理解性 | 业务人员是否能理解概念模型 | 业务评审通过 |
五、集市层建模实践:场景化的维度建模
5.1 集市层的定位与职责
集市层(DWS/ADS)是新方法论中变化最大的部分。其核心定位是:面向场景消费,提供易理解、易使用、高性能的数据模型。
集市层的三大核心职责:
- 数据聚合:根据分析场景的需求,对DWD层明细数据进行不同粒度的聚合
- 语义封装:将复杂的业务逻辑封装为直观的字段和表,降低业务用户的使用门槛
- 性能优化:通过宽表设计、预聚合、数据压缩等手段提升查询性能
5.2 集市层的场景分类
集市层应按消费场景进行细分,不同场景的建模策略存在显著差异:
| 场景类型 | 典型需求 | 建模策略 | 数据粒度 | 更新频率 |
|---|---|---|---|---|
| 经营分析集市 | 经营报表、指标仪表盘 | 星型模型(事实表+维度表) | 日/月粒度 | T+1 |
| 用户运营集市 | 用户标签、人群圈选 | 宽表设计(用户维度+行为特征) | 用户粒度 | T+1/实时 |
| 风控分析集市 | 风控特征、风险评分 | 特征宽表(用户/订单维度) | 事件粒度 | 实时/T+1 |
| 算法训练集市 | 模型训练样本、特征数据 | 样本宽表(正负样本+特征) | 样本粒度 | 周期性 |
5.3 星型模型设计要点
星型模型是集市层最常用的建模方法,其核心结构包括:
┌─────────────┐
│ 维度表A │
└──────┬──────┘
│
┌──────┴──────┐
│ │
┌─────────────┐ ┌───┴────┐ ┌────┴────┐
│ 维度表B │ │ 事实表 │ │ 维度表C │
└──────┬──────┘ └───┬────┘ └────┬────┘
│ │ │
└────────────┴────────────┘事实表设计要点:
- 粒度定义:明确事实表的粒度(如"每笔交易一行"或"每个用户每天一行"),粒度一旦确定不可随意变更
- 度量字段:只包含可聚合的数值型字段(如金额、数量),不可聚合的字段应放在维度表中
- 外键设计 :所有维度关联均通过外键实现,外键字段命名应保持一致(如
user_id、product_id)
维度表设计要点:
- 维度属性:包含所有用于过滤、分组、排序的描述性字段
- 缓慢变化维(SCD):对于维度属性会变化的场景,需设计SCD策略(Type 1覆盖、Type 2新增记录、Type 3新增字段)
- 维度层级:对于存在层级关系的维度(如"省→市→区"),应设计层级字段以支持上卷和下钻分析
5.4 宽表设计的权衡
宽表是集市层最常用的物理模型,其核心优势是减少JOIN操作、提升查询性能。但宽表设计需要权衡以下因素:
| 权衡维度 | 宽表优势 | 宽表劣势 | 应对策略 |
|---|---|---|---|
| 查询性能 | 单表查询,无需JOIN | --- | --- |
| 存储成本 | --- | 字段冗余导致存储增加 | 采用列式存储+压缩算法 |
| 维护成本 | --- | 字段变更影响大 | 建立字段变更审批机制 |
| 语义清晰度 | 字段集中,一目了然 | 字段过多时难以理解 | 建立数据字典和字段说明 |
| 更新效率 | --- | 全表更新成本高 | 采用增量更新+分区策略 |
宽表设计的最佳实践:
- 明确粒度:宽表的粒度必须明确且唯一,避免"一张表包含多种粒度"
- 字段分组:将字段按业务含义分组(如"用户属性""订单属性""支付属性"),提高可读性
- 控制字段数量:单表字段数建议控制在200以内,超过时考虑拆分为多张表
- 命名规范 :字段命名应遵循统一规范(如
user_age、order_amount、pay_time)
六、治理体系:对抗熵增的长效机制
6.1 治理体系的设计原则
新方法论的核心不是"消灭熵增"(这是不可能的),而是"控制增速度",使数据系统的混乱度在可接受的范围内缓慢增长。治理体系的设计遵循以下三大原则:
| 原则 | 核心思想 | 实施方式 |
|---|---|---|
| 架构约束 | 通过分层规范限制混乱度的增长 | 禁止反向依赖、跨层穿透、ODS直连 |
| 分而治之 | 将全局治理拆分为局部治理 | 按业务域划分治理范围,独立治理 |
| 少量人肉干预 | 在关键节点设置人工审核 | 核心模型变更需经架构评审 |
6.2 熵增控制的架构约束
通过严格的分层规范,限制数据模型之间的依赖关系,从而控制熵增速度:
| 约束规则 | 具体内容 | 违反后果 | enforcement方式 |
|---|---|---|---|
| 禁止反向依赖 | 下层模型不得依赖上层模型 | 分层架构崩溃 | 自动化检测+CI拦截 |
| 禁止跨层穿透 | 不得跳过中间层直接依赖非相邻层 | 增加耦合度 | 依赖关系扫描 |
| 禁止ODS直连 | 不得直接从ODS层取数,必须经过DWD层 | 丧失数据治理能力 | 权限控制+审计 |
| 禁止跨域直连 | 跨业务域的数据依赖必须通过枢纽表 | 增加系统复杂度 | 架构评审 |
| 禁止循环依赖 | 表与表之间不得形成循环依赖 | 数据链路断裂 | 依赖图检测 |
自动化检测机制:
数据模型变更
│
▼
[依赖关系扫描] ──→ 检测反向依赖、跨层依赖、循环依赖
│
▼
[熵增指标计算] ──→ 计算资产重复率、域内聚度、跨域耦合度
│
▼
[阈值判断] ──→ 超过阈值则拦截发布
│
▼
[人工评审] ──→ 特殊情况需经架构委员会评审6.3 局部治理策略
与全局重造不同,新方法论强调"局部治理"------仅在必要时对单个业务域进行小范围重构,而非全链路推倒重来。
局部治理的触发条件:
| 触发条件 | 判断标准 | 治理方式 |
|---|---|---|
| 域内熵增超标 | 域内资产重复率>30% | 域内表合并与清理 |
| 跨域依赖过多 | 跨域依赖占比>20% | 跨域依赖梳理与优化 |
| 性能严重下降 | 核心查询响应时间>阈值 | 物理模型优化(分区、索引) |
| 业务重大变更 | 业务流程发生根本性变化 | 概念模型重构 |
局部治理的实施步骤:
- 现状评估:通过熵增指标量化当前域的混乱程度
- 影响分析:评估治理对上下游的影响范围
- 方案设计:设计治理方案(表合并、字段调整、依赖优化)
- 灰度验证:在小范围内验证治理效果
- 全量切换:确认无误后进行全量切换
- 效果跟踪:持续跟踪治理后的熵增指标变化
6.4 组织配套:权责清晰的治理体系
技术架构的落地离不开组织体系的支撑。新方法论强调将治理职责嵌入到日常生产流程中,而非单独设立"治理团队"。
| 角色 | 职责 | 考核指标 |
|---|---|---|
| 域负责人 | 负责单个业务域的数据模型设计与治理 | 域内熵增指标、模型复用率 |
| 质量负责人 | 负责数据质量监控与问题排查 | 数据质量事件数、问题响应时间 |
| 成本负责人 | 负责存储成本与计算成本的管控 | 存储成本增长率、无效资产清理率 |
| 架构评审委员 | 负责核心模型变更的架构评审 | 评审通过率、架构规范执行率 |
治理流程嵌入生产流程:
需求评审 ──→ 模型设计 ──→ 架构评审 ──→ 开发实现 ──→ 质量测试 ──→ 发布上线 ──→ 持续监控
│ │ │
└── 域负责人确认 └── 架构委员评审 └── 质量负责人验收6.5 治理效果度量
治理效果必须通过可量化的指标来衡量,而非主观判断。核心度量指标包括:
| 指标类别 | 具体指标 | 计算方式 | 目标值 |
|---|---|---|---|
| 熵增控制 | 反向依赖占比 | 反向依赖数/总依赖数 | <5% |
| 熵增控制 | 跨层依赖占比 | 跨层依赖数/总依赖数 | <10% |
| 资产质量 | 资产重复率 | 重复表数/总表数 | <15% |
| 资产质量 | 域内内聚度 | 域内依赖数/总依赖数 | >70% |
| 治理效率 | 治理成本降低比例 | (旧治理成本-新治理成本)/旧治理成本 | >60% |
| 资产价值 | 数据资产复用率 | 被复用表数/总表数 | >40% |
某A公司的实践表明,通过新方法论的治理体系,治理成本可降低60%以上,数据资产复用率可提升40%以上。
七、落地路径:从理论到实践的完整指南
7.1 实施路线图
新方法论的落地不是一蹴而就的,需要分阶段、分步骤推进。建议的实施路线图如下:
第一阶段:基础建设(1-2个月)
- 建立分层规范文档,明确DWD与集市层的定位差异
- 搭建依赖关系扫描工具,实现反向依赖、跨层依赖的自动检测
- 制定31法则模板,用于概念模型的标准化描述
- 选择1-2个业务域作为试点,验证新方法论的可行性
第二阶段:试点验证(2-3个月)
- 在试点域内完成概念模型抽象(31法则)
- 完成DWD层的3NF建模
- 完成集市层的维度建模(星型模型/宽表)
- 验证新方法论在查询性能、开发效率、维护成本方面的效果
第三阶段:全面推广(3-6个月)
- 将试点经验总结为标准化方法论文档
- 组织全员培训,确保所有数据工程师理解新方法论
- 逐步将其他业务域迁移至新架构
- 建立熵增指标的产品化监测体系
第四阶段:持续优化(长期)
- 持续监控熵增指标,及时发现和解决问题
- 定期回顾和更新建模规范,适应业务变化
- 推动数据建模从"经验驱动"向"数据驱动"升级
7.2 常见陷阱与应对策略
| 陷阱 | 表现 | 后果 | 应对策略 |
|---|---|---|---|
| 分层定位模糊 | DWD层包含大量分析字段,集市层又建了大量规范表 | 两层职责混淆,失去解耦意义 | 严格执行分层规范,定期审计 |
| 过度设计 | 概念模型过于复杂,实体划分过细 | 开发效率低,维护成本高 | 遵循"够用就好"原则,避免过度抽象 |
| 忽视治理 | 只关注建模,不关注治理体系建设 | 新系统很快再次熵增 | 治理体系与建模同步建设 |
| 一刀切迁移 | 试图一次性将所有旧模型迁移至新架构 | 迁移风险大、周期长、易失败 | 分域逐步迁移,优先迁移高价值域 |
| 缺乏培训 | 团队成员不理解新方法论的核心思想 | 落地变形,回到老路 | 全员培训+实战演练+持续辅导 |
7.3 工具链建设建议
新方法论的落地离不开工具链的支撑。建议建设以下工具:
| 工具类别 | 功能 | 建设优先级 |
|---|---|---|
| 依赖关系扫描工具 | 自动检测表之间的依赖关系,识别反向依赖、跨层依赖 | 🔴 最高 |
| 熵增指标监控平台 | 实时计算和展示熵增指标,支持阈值告警 | 🔴 最高 |
| 概念模型管理工具 | 管理31法则文档,支持概念模型的版本控制 | 🟠 高 |
| 数据字典工具 | 管理表结构、字段说明、业务含义 | 🟠 高 |
| 模型评审流程工具 | 支持模型变更的在线评审和审批 | 🟡 中 |
| 数据质量监控工具 | 监控数据质量指标,自动发现数据异常 | 🟠 高 |
八、总结与展望
8.1 核心结论
通过对某A公司数据仓库建模实践的总结,本文得出以下核心结论:
-
复杂数据系统必然熵增:这是数据系统的客观规律,无法通过技术手段完全消除。我们能做的是通过合理的架构设计控制熵增速度,使系统在可接受的范围内持续演进。
-
分层解耦是控制熵增的核心手段:通过明确DWD层与集市层的定位差异,采用"领域驱动3NF建模+场景化维度建模"的双轨设计,可以有效平衡"有序性"与"高效性"之间的矛盾。
-
明细层聚焦业务本质,集市层聚焦场景消费:这是新方法论的核心原则。DWD层必须回归"业务本质建模"的核心定位,集市层必须承担"场景化消费"的全部职责。两层的定位不可混淆。
-
概念模型是建模的源头:没有清晰的概念模型,就没有合理的数据模型。31法则是验证业务理解深度的有效工具,每个数据工程师都应该掌握。
-
治理体系必须与建模同步建设:没有治理体系支撑的建模方法论,最终都会回到熵增的老路。治理体系的核心是"架构约束+分而治之+少量人肉干预"。
8.2 方法论适用性分析
新方法论并非适用于所有场景,其适用性取决于企业的实际情况:
| 适用场景 | 不适用场景 |
|---|---|
| 数据仓库规模较大(表数量>1000) | 数据仓库规模较小(表数量<100) |
| 业务场景复杂多变 | 业务场景简单稳定 |
| 数据团队规模较大(>10人) | 数据团队规模较小(<3人) |
| 存在明显的熵增问题 | 数据系统运行良好,无明显问题 |
| 有多团队协同的数据消费场景 | 单一团队消费数据的场景 |
8.3 未来展望
数据仓库建模方法论的演进是一个持续的过程。未来,以下几个方向值得重点关注:
-
熵增指标的产品化监测:将熵增指标的计算和监控产品化,实现自动化的熵增预警和治理建议。
-
数据建模的智能化辅助:利用AI技术辅助概念模型抽象、关联关系提取、模型质量评估等建模环节,降低建模门槛。
-
实时数据仓库的建模挑战:随着实时分析需求的不断增长,实时数据仓库的建模方法论将成为新的研究热点。
-
数据湖仓一体架构下的建模演进:在数据湖仓一体架构下,传统的分层建模方法需要进行适应性调整。
-
数据治理的自动化与智能化:从"人工治理"向"自动治理"演进,通过规则引擎和AI技术实现自动化的数据治理。
附录:关键术语表
| 术语 | 英文 | 定义 |
|---|---|---|
| OLTP | Online Transaction Processing | 联机事务处理系统,面向应用、事务驱动 |
| OLAP | Online Analytical Processing | 联机分析处理系统,面向主题、决策驱动 |
| 3NF | Third Normal Form | 第三范式,关系数据库规范化的标准 |
| DWD | Data Warehouse Detail | 数据仓库明细层,存储业务过程明细数据 |
| DWS | Data Warehouse Summary | 数据仓库汇总层,存储轻度聚合数据 |
| ADS | Application Data Store | 应用数据层,存储高度聚合的应用数据 |
| ODS | Operational Data Store | 操作数据存储层,存储原始业务数据 |
| 星型模型 | Star Schema | 由事实表和维度表组成的数据模型 |
| 雪花模型 | Snowflake Schema | 维度表进一步规范化的星型模型变体 |
| 熵增 | Entropy Increase | 系统混乱度持续增加的趋势 |
| 31法则 | 3-1 Rule | 每个业务名词需满足"1个命名+1句话定义+1段话解释" |
| SCD | Slowly Changing Dimension | 缓慢变化维,处理维度属性随时间变化的策略 |
版权声明:本文基于某A公司数据仓库建设实践总结而成,仅供学习交流使用。文中涉及的具体数据和案例已做脱敏处理。