MultiAgent之OpenClaw:QuantClaw的简介、安装和使用方法、案例应用之详细攻略
目录
[T1、通过 Clawhub 安装(推荐)](#T1、通过 Clawhub 安装(推荐))
[T2、从 OpenClaw 源码仓库](#T2、从 OpenClaw 源码仓库)
[2)配置检测器与 judge 模型](#2)配置检测器与 judge 模型)
[3)启动 OpenClaw 后查看 Dashboard](#3)启动 OpenClaw 后查看 Dashboard)
[4)taskTypes 配置方式](#4)taskTypes 配置方式)
[5)targets 配置方式](#5)targets 配置方式)
[6)modelPricing 覆盖与成本统计](#6)modelPricing 覆盖与成本统计)
[7)loadModelDetector 后端](#7)loadModelDetector 后端)
[1)作为 OpenClaw 的动态精度路由插件](#1)作为 OpenClaw 的动态精度路由插件)
QuantClaw 的 简介
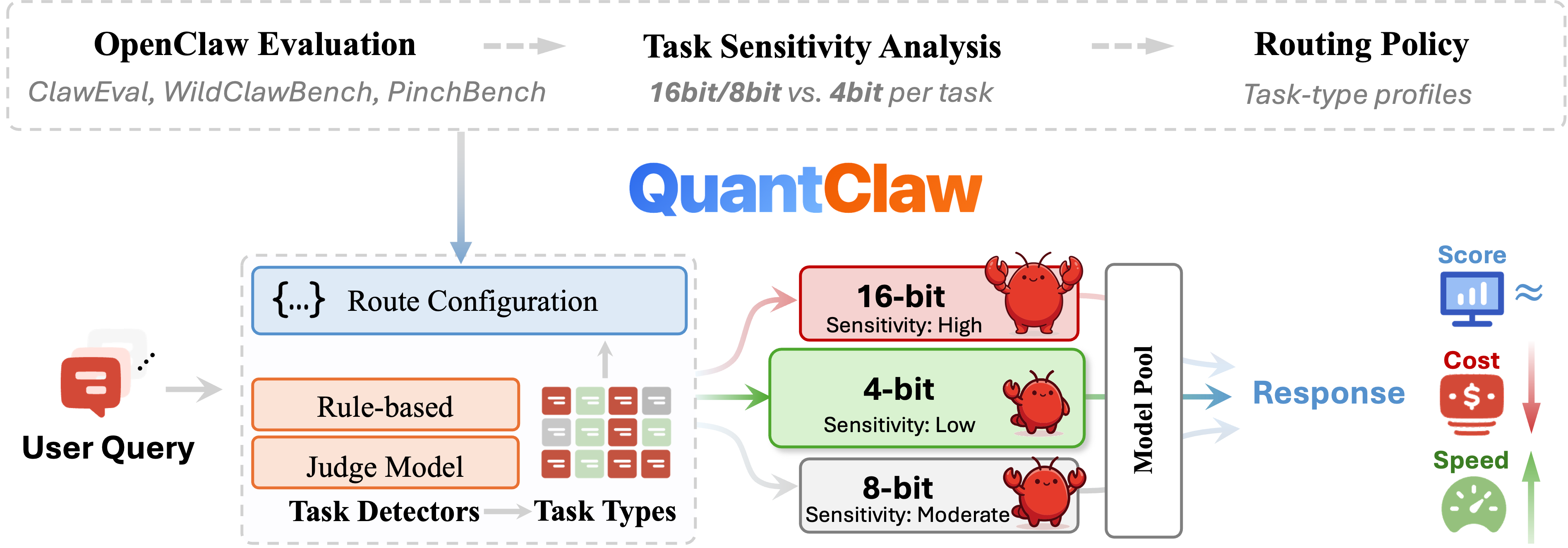
QuantClaw 是一个面向 OpenClaw 的即插即用任务类型路由量化插件,会把每个请求分类到对应任务类型,再映射到 4bit、8bit 或 16bit 精度层,最后路由到合适的目标模型,从而在不要求用户手动选精度的前提下平衡质量、延迟与成本。
QuantClaw 的定位不是单纯的"量化工具",而是 OpenClaw 的任务类型精度路由插件。它的核心思路是:先识别请求属于哪类任务,再根据任务特性自动分配合适的模型精度,尽量把"该用高精度的任务"送到高精度模型,把"能接受低精度的任务"送到低精度模型。仓库说明中强调,它是"plug-and-play task-type routing quantization plugin for OpenClaw",也就是安装后即可接入 OpenClaw 运行。
README 进一步说明,QuantClaw 的设计并不是凭经验随意分配精度,而是建立在对 OpenClaw 工作负载的量化研究之上;官方评估覆盖 24 种任务类型、104 个任务、6 个模型、9B 到 744B 的不同规模。在 Claw-Eval(release v0.0.0)中,仓库给出了 BF16/FP8 与 NVFP4 的对比结果,用于说明不同模型在不同精度下的表现差异。
Github地址 :https://github.com/SparkEngineAI/QuantClaw-plugin
1、 特点
|--------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 自动适配与智能路由 | 仓库把核心能力概括为 Automatic Adaptation / 自动适配 和 Intelligent Routing / 智能路由。具体来说,系统会优先使用规则分类器;如果规则匹配失败,再交给 judge 模型处理。最终每个请求会被映射到 4bit、8bit 或 16bit 的目标模型。 |
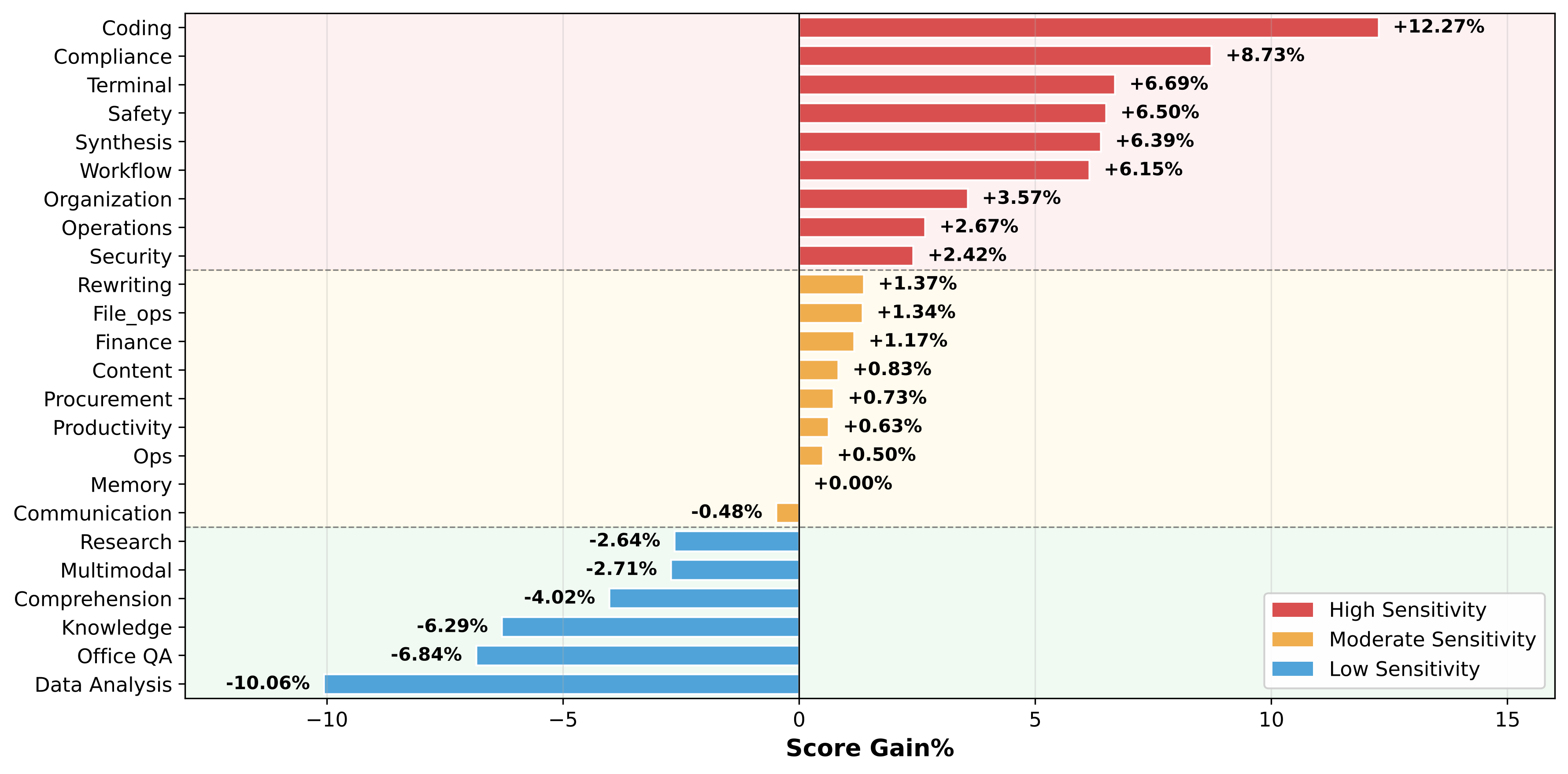
| 面向任务类型,而不是只看模型本身 | README 明确列出了任务敏感性差异:像 coding、safety、复杂 workflow 这类高敏感任务更适合高精度;而 research、multimodal、comprehension、knowledge lookup、office QA、data analysis 等任务通常可以容忍更低精度。也就是说,QuantClaw 的核心不是"统一降精度",而是"按任务决定精度"。 |
| 完全可定制 | 仓库在"Configuration Notes / 配置说明"里写得很清楚:你可以自定义 task type 的 id、description、precision、keywords、patterns,也可以为不同精度层分别配置 provider、model、endpoint、api key、pricing。这意味着它不仅能自动跑,也能被深度调参,适合不同部署环境。 |
| 内置可观测性 | 仓库说明支持追踪 路由、token、成本、会话和实时配置变更,并提供 Dashboard 页面查看统计数据,地址是 http://127.0.0.1:18789/plugins/quantclaw/stats。这表示它不只是做决策,还提供运行可视化与成本统计能力。 |
| 支持热更新 | README 里写到,~/.openclaw/quantclaw.json 修改后会触发 hot reload。这对线上使用很实用:你调整任务分类、目标模型或定价后,不必重新大改部署流程。 |
QuantClaw 的 安装和使用方法
1、安装
1)前提条件
仓库明确说明:前提是已经安装 OpenClaw。QuantClaw 是 OpenClaw 的插件,所以需要先有 OpenClaw 运行环境。
2)安装方式
README 给了三种安装路线:
T1、 通过 Clawhub 安装(推荐)
openclaw plugins install clawhub:@sparkengineai/quantclawT2、 从 OpenClaw 源码仓库
如果你是从 OpenClaw 源码仓库运行、且 openclaw CLI 不在 PATH 中,可以:
cd /path/to/openclaw
node openclaw.mjs plugins install @sparkengineai/quantclawT3、 直接从源码安装:
git clone https://github.com/SparkEngineAI/QuantClaw-plugin.git ./quantclaw
openclaw plugins install ./quantclaw如果 openclaw CLI 不在 PATH 中,则在 OpenClaw 目录下用 node openclaw.mjs plugins install /path/to/quantclaw 安装。
2、使用方法
1 )创建或初始化运行时配置
QuantClaw 会从下面这个路径读取运行时配置:
~/.openclaw/quantclaw.json如果文件不存在,启用插件并启动 OpenClaw 后会自动生成默认配置;如果你是直接基于仓库使用,也可以先复制示例文件:
cp config.example.json ~/.openclaw/quantclaw.json仓库特别强调,这个配置文件是插件运行的核心入口。
2 )配置检测器与 judge 模型
README 的示例配置中,quant 区块里会开启插件并配置两个检测器:
{
"quant": {
"enabled": true,
"detectors": ["ruleDetector", "loadModelDetector"],
"judge": {
"endpoint": "http://127.0.0.1:8000",
"model": "BAAI/bge-m3",
"providerType": "openai-compatible",
"apiKey": "",
"cacheTtlMs": 300000
}
}
}这表示 QuantClaw 的路由流程是:先走 ruleDetector,再走 loadModelDetector,judge 模型可以通过一个 OpenAI-compatible 接口提供服务。
3 )启动 OpenClaw 后查看 Dashboard
安装和配置后,启动 OpenClaw,再打开:
http://127.0.0.1:18789/plugins/quantclaw/stats仓库把这一步作为查看插件统计和路由状态的入口。
4 )taskTypes 配置方式
仓库给了一个 taskTypes 示例。每个任务类型可以写:
id
precision
description
keywords
patterns示例里,coding 被映射到 16bit,并通过描述、关键词和正则模式来识别,比如 code、debug、Python、CUDA、编程、代码 等关键词,以及类似 "fix the bug in this repository" 的模式。默认任务类型是 standard。
5 )targets 配置方式
仓库给出的 targets 示例展示了不同精度层如何绑定不同模型与价格。比如:
4bit 目标:provider: quantclaw-4bit,model: glm-4.7-flash-int4-autoround
16bit 目标:provider: quantclaw-16bit,model: glm-4.7-flash
每个目标都可以配置 endpoint、apiKey、displayName 和 pricing。这说明 QuantClaw 不只是路由"精度层",还负责把精度层和具体推理后端对应起来。
6 )modelPricing 覆盖与成本统计
README 还给出 modelPricing 示例,用于模型级价格覆盖。若某个精度层已经配置了 target-level pricing,就优先使用该层定价;如果没有,再回退到 modelPricing 做成本统计。也就是说,成本计算逻辑是分层的,便于统一管理。
7 )loadModelDetector 后端
loadModelDetector 支持两种方式:
一种是本地 embedding router,通过 OpenAI-compatible API 暴露服务;另一种是直接接入普通的 OpenAI-compatible LLM judge。仓库给了构建和启动本地 router 的命令:
python router/embedding_task_router.py --model-name BAAI/bge-m3 --device cuda --config-path ~/.openclaw/quantclaw.json --output-dir ./embedding_router_index-bge-m3 build --print-summary
python router/embedding_task_router_server.py --model-name BAAI/bge-m3 --device cuda --output-dir ./embedding_router_index-bge-m3 --port 8012如果没有 GPU,把 --device cuda 改成 --device cpu 即可;如果不想运行本地 embedding router,也可以把 quant.judge.endpoint 直接指向任意 OpenAI-compatible LLM 服务。
QuantClaw 的 案例应用
1)作为 OpenClaw 的动态精度路由插件
QuantClaw 最明确的应用,就是在 OpenClaw 中充当 动态精度路由层。它根据任务类型把请求分配到不同精度模型,因此适合需要在 质量、延迟和成本 三者之间做权衡的部署场景。这个"按需选精度"的思路,是仓库最核心的实际用途。
2)面向高敏感任务与低敏感任务的差异化部署
README 直接举出了适合高精度和低精度的任务类别,可作为典型落地场景:
高敏感任务:coding、safety、复杂 workflow。
低敏感任务:research、multimodal、comprehension、knowledge lookup、office QA、data analysis。
这说明 QuantClaw 的实际应用方式是:把"重要、复杂、易出错"的请求送到更高精度,把"可容忍误差"的请求送到更便宜、更快的精度层。
3)代码类任务的路由示例
仓库中的 taskTypes 示例把 coding 任务显式设为 16bit,并用"代码审查、bug 分析、实现、调试、异步行为、Web 开发"等描述来识别。这个例子本身就是一个很典型的使用案例:当系统识别到请求属于代码/调试类任务时,优先路由到高精度模型。
4)多后端、多模型精度层的统一管理
targets 示例中同时展示了 4bit 和 16bit 两个层级,以及不同 provider、model、endpoint 和 pricing 的组合。这表明 QuantClaw 适合用于多模型混部环境:你可以把不同精度的推理后端统一纳入一个路由插件管理,而不是在应用层手工切换模型。
5)用于成本观测和运维分析
仓库明确提到会追踪路由、token、成本、会话和实时配置变化,并提供统计 Dashboard。实际应用上,这意味着它不仅能做"自动分配",还适合做 成本治理、路由效果分析、配置调优 这些运维场景。