目录
一、上节课复习:MySQL到底是个啥玩意儿
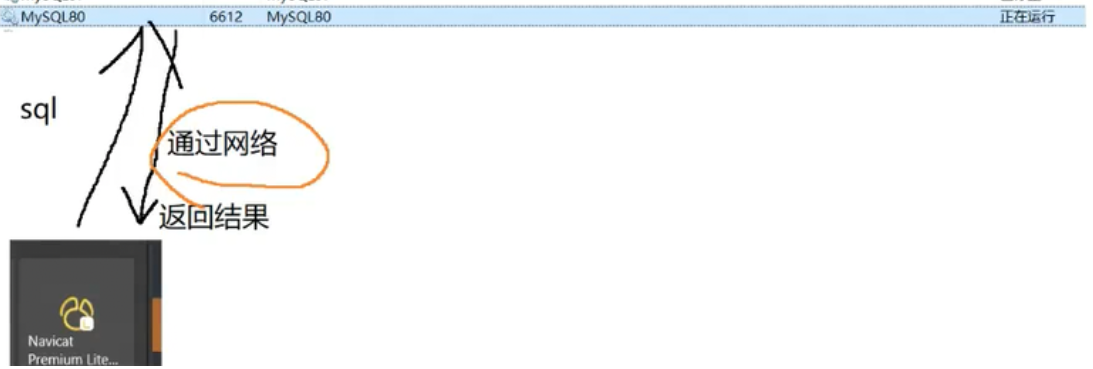
首先,++mysql是一个客户端-服务器结构的程序++。这意味着我们通过Navicat这样的客户端,通过网络发送SQL请求给MySQL服务器,服务器处理完再通过网络返回结果。客户端和服务器可以在同一台机器,也可以在不同机器。
基本操作就是经典的++增删改查++:
-
insert
-
delete
-
update
-
select
然后重点来了------++数据库约束++。计算机圈子里流传了一句话:"人是不靠谱的",数据库的数据通常非常重要,必须保证准确性,程序的约束就是其中一种。
常见的约束有这些:
-
NOT NULL非空约束
-
DEFAULT默认约束
-
UNIQUE唯一约束
-
PRIMARY KEY主键约束
-
FOREIGN KEY外键约束
-
CHECK检查
++主键的坑,你踩过吗?++
一个表中只能有一个主键,通常主键使用整数来表示。最常用的是++自增主键++:
create table student (id int primary key auto_increment, name varchar(20));但是!这里有个巨坑------++自增主键仅限于单节点的MySQL服务器场景使用++。如果是多节点的情况,比如大公司数据量级非常庞大,靠一个服务器存储不现实,搞了20个MySQL服务器构成的集群,这时候自增主键就可能会重复!因为各个节点的自增是独立的,AB之间的自增主键是会出现重复的。
业界流传了很多分布式情况下唯一的id生成算法,比如雪花算法。核心思想是把++时间戳+主机的标识+随机的数字++,然后通过hash算法映射成整数。虽然hash算法存在冲突概率,但工程上选择好的hash算法可以让这个概率变得极低(工程上忽略不计)。
二、外键约束:父表和子表的爱恨情仇
外键约束涉及到两个表的关系。比如学生表(studentId, name, classId)和班级表(classId, name)。班级表是父表,学生表是子表。
设定外键约束时,需要明确当前表的哪个列和另外一个表的哪个列建立关联关系:
create table class (classId int primary key auto_increment, name varchar(20));
create table student (studentId int primary key auto_increment, name varchar(20), classId int, foreign key (classId) REFERENCES class(classId));
++父约束子,子也在约束父------这就是外键的精髓!++
当你往student表插入数据时,会先触发一次针对class表的查询,查到结果了才能插入,没有查到就会报错:
insert into student values(1, '张三', 1), (2, '李四', 2), (3, '王五', 3);
-- 如果class表里没有classId=3,这里就会报错修改时同样会触发查询:
update student set classId = 100 where studentId = 3; -- 也会报错更狠的是删除和修改父表时,也会去查询子表,看子表是否有数据使用,有的话就失败,没有才能正常进行:
delete from class where classId = 2; -- 会报错实战场景:电商网站的商品下架
我这里可以提一个很经典的场景:淘宝这样的电商网站,商品表goods(id, name, price...),订单表order(id, time, goodsId)。订单表的goodsId应该是出自于商品表。
如果商品下架了,delete能删除吗?++如果用外键约束,是不能直接delete的,会报错!++
那怎么办?++逻辑删除!++ 不是使用delete,而是通过update把is_online字段改成0。返回商品列表的时候,select ... where is_online = 1。
这就像是学习数据结构中的顺序表里的"逻辑删除"------不需要把usedSize那个位置的元素干掉,只是把标志位改成0。虽然意味着数据库的内容越来越多,空间浪费就浪费了,毕竟硬盘不值钱,这不是主要矛盾。
如果不加外键约束就会报错,核心问题在于++"索引"++。子表中插入数据,就会涉及到自动在父表中进行查询。索引相当于在表中搞了一个特殊的数据结构,相当于"目录",可以加快查询的速度。默认是顺序遍历O(N)比较低效,被标记为主键的列会自动创建索引。如果引用的是其他列,也可以给其他的列手动创建索引:
create table class(classId int unique, name varchar(20));
create table student(studentId int, name varchar(20), classId int, FOREIGN key (classId) REFERENCES class(classId));unique这样也可以起到一个自动创建索引的效果。
三、check约束
check (表达式) 是用来做条件判断的,后续插入修改数据,都会自动代入条件,条件成立才能够进行插入修改。
create table student (id int, name varchar(20), gender varchar(10));
insert into student values (1, '张三', '武装直升机'), (2, '李四', '沃尔玛购物袋');
select * from student; -- 可以明显看到这样插入的性别非常不合理,但也可以插入然后加上check约束:
drop table student;
create table student (id int, name varchar(20), gender varchar(10), check (gender = '男' or gender = '女'));
insert into student values (1, '张三', '武装直升机'), (2, '李四', '沃尔玛购物袋');
select * from student; -- 这样就会报错了!!!!!!!!!!!!!!!!!!!!!!!!!!再比如:
create table score(id int, score int check (score >= 0 and score <= 100));
insert into score values(1, 101); -- 像这种约束也能起作用++但是!++ check是从mysql 8.0.16这个版本开始支持的。当前很多公司用的是5.7版本,也有老项目用更早的。组件的升级,对于很多公司来说是不愿意做的。之前check虽然不会报错,但是实际没有生效------纯属摆设!
希望这篇笔记能帮到正在学MySQL的兄弟们,少走点弯路,少踩点坑!有问题评论区交流,一起加油!