文章目录
- [1. Redis 为什么出现?](#1. Redis 为什么出现?)
-
- [1.1 数据库性能瓶颈](#1.1 数据库性能瓶颈)
- [1.2 为什么需要缓存](#1.2 为什么需要缓存)
- [1.3 Redis 与 MySQL](#1.3 Redis 与 MySQL)
- [2. Redis 基础概念](#2. Redis 基础概念)
- [3. Redis 安装与配置](#3. Redis 安装与配置)
- 结语
1. Redis 为什么出现?
在互联网系统发展的早期,大部分系统通常只依赖关系型数据库,例如MySQL 来完成数据存储。当系统访问量较低时,数据库能够轻松支撑业务需求。 但随着用户规模增长,一个问题逐渐暴露:数据库扛不住高并发请求。尤其是在电商、社交平台、新闻门户等高访问场景下,大量重复查询会给数据库带来巨大压力。Redis 出现的核心原因,就是解决数据库性能瓶颈问题。
1.1 数据库性能瓶颈
关系型数据库(如 MySQL)虽
然功能强大,但它并不是为极致高并发场景而设计的。在互联网业务快速增长后,数据库通常会遇到三个核心瓶颈。
- 磁盘 IO 性能限制
MySQL 的数据通常存储在磁盘中。即使使用B+ 树索引和Buffer Pool缓存池,本质上仍然依赖磁盘IO。而磁盘读取速度远低于内存。
| 存储介质 | 访问速度 |
|---|---|
| CPU Cache | 纳秒级 |
| 内存(RAM) | 微秒级 |
| SSD | 毫秒级 |
| 机械硬盘 | 更慢 |
因此,当请求量增长时,磁盘 IO 很容易成为数据库性能瓶颈。例如某个热门博客页面,一天可能被访问几十万次。但数据实际上几乎不变。如果每次都查询数据库,本质上是在重复消耗数据库资源。
-
高并发导致数据库压力激增
数据库连接数是有限的,当瞬间涌入大量请求时,容易出现:连接池耗尽、查询阻塞、响应变慢、数据库宕机。例如电商秒杀场景,如果几十万人同时抢购商品,请求全部直接访问 MySQL,数据库可能瞬间被压垮。
-
热点数据被重复查询
在很多系统中存在大量高频访问、低变化的数据。例如用户信息、商品详情、排行榜。这些数据读远远大于写,于是工程师想到:能不能把经常访问的数据放到更快的位置?于是缓存思想(Cache) 诞生了。
1.2 为什么需要缓存
缓存(Cache)的核心思想就是将热点数据存储到访问速度更快的介质中,减少数据库访问压力。
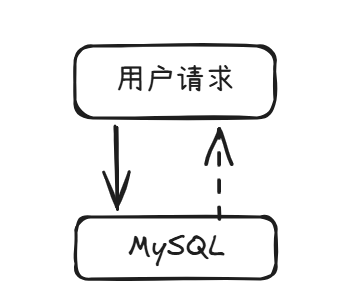
如果没有缓存,用户每次发起请求,系统都会直接查询数据库:
引入缓存后,系统会先在缓存中查询,如果缓存未命中,才会查数据库,并把结果写到缓存中,第二次查询就可以命中缓存了。
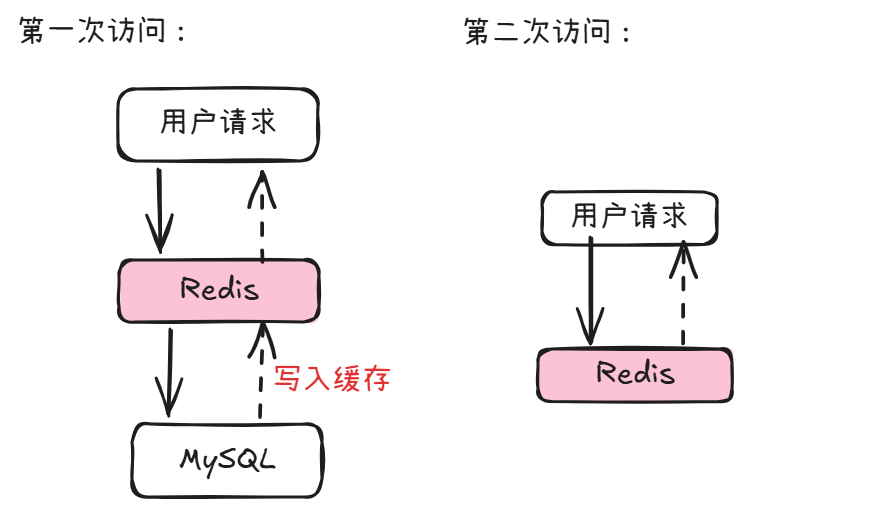
例如某商品详情,原本:
10万请求 → MySQL引入 Redis 后:
99999 请求 → Redis
1 次 → MySQL数据库压力骤降。
因此 Redis 本质上是一个高性能缓存系统。
1.3 Redis 与 MySQL
很多初学者容易误解:
"既然 Redis 这么快,为什么不用 Redis 替代 MySQL?"
原因在于两者解决的问题不同。
- MySQL 属于关系型数据库,能够维持数据持久化、支持事务并且强一致,适合用户订单、支付记录等复杂的核心业务数据查询。
例如:
sql
SELECT *
FROM orders
WHERE amount > 100
ORDER BY create_time DESC;而这类复杂查询,Redis 并不擅长。
- Redis 属于内存型 Key-Value 数据库,它基于内存,所以查询速度快,性能高,并发高,并且支持丰富的数据结构。适合处理会话管理、排行榜、实时统计等业务。
例如:
bash
INCR article:view:1 # 统计文章阅读量Redis 与 Mysql 两者不是竞争关系,而是合作关系。Mysql负责"存",而Redis 负责"快"。
在现代互联网系统中,"Redis + Mysql"是基本的标配架构。
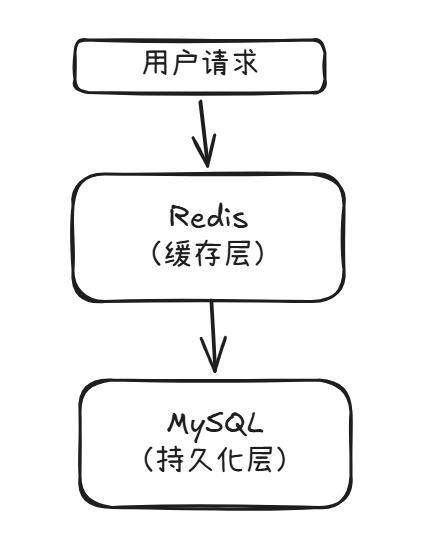
QL 架构.png]]
2. Redis 基础概念
2.1 Redis 是什么
Redis(Remote Dictionary Server )是一个基于内存 的高性能 Key-Value 数据库 ,属于 NoSQL(Not Only SQL) 数据库的一种。与传统关系型数据库(如 MySQL)不同:
Redis 不以"表结构"存储数据,而是采用 Key-Value(键值对) 的形式组织数据。
例如:
SET username "zhangsan"
GET username其中key 是username,value是"zhangsan"。
Redis 的 value 并不仅仅是字符串,它支持多种丰富的数据结构:
- String(字符串)
- Hash(哈希)
- List(列表)
- Set(集合)
- ZSet(有序集合)
- Bitmap
- HyperLogLog
- GEO
- Stream
因此:
Redis 并不仅仅是一个缓存工具,更是一个高性能的数据存储中间件。
2.2 Redis 的核心特点
Redis 核心特点主要有:高性能、数据结构丰富、单线程、i/o多路复用、数据持久化和高可用。
高性能
Redis 最大的特点就是:快。官方测试中:Redis 单机每秒可处理十万级以上请求(QPS)。
之所以性能优秀,主要原因包括:
- 基于内存
- 高效数据结构
- 单线程避免锁竞争
- I/O 多路复用
后面会重点讲 Redis 为什么这么快。
丰富的数据结构
相比传统 Key-Value 存储系统,Redis 提供了非常丰富的数据类型。
| 数据结构 | 典型场景 |
|---|---|
| String | 缓存、计数器 |
| Hash | 用户对象 |
| List | 消息队列 |
| Set | 点赞、共同好友 |
| ZSet | 排行榜 |
这意味着 Redis 不只是缓存,还能模拟很多中间件能力。
例如
-
排行榜:
ZADD score_rank 100 tom
ZADD score_rank 95 jack -
点赞系统:
SADD article:1:likes user001
-
阅读量统计:
INCR article:view:1
因此 Redis 在很多业务场景下既是缓存,也是业务组件。
单线程模型
Redis 在执行命令时 核心命令处理采用单线程模型。 也就是说同一时间只有一个线程执行命令。很多初学者会疑惑:"单线程为什么还能这么快?" 实际上Redis 的瓶颈通常不是 CPU,而是网络 IO。 采用单线程反而避免了上下文切换、锁竞争和线程同步,从而减少性能损耗。
例如:
在多线程环境中,多个线程同时修改共享资源,需要加锁:
线程 A
线程 B
线程 C
↓
加锁而 Redis:
请求队列
↓
单线程执行天然避免线程安全问题。
不过需要注意Redis 并不完全是单线程。在 Redis 6 之后命令执行仍然是单线程,但网络 IO 已支持多线程。
也就是说:
多线程处理网络请求
↓
单线程执行命令因此:
面试中"Redis 是单线程吗?"
更准确回答应该是:
Redis 核心命令执行是单线程,但 Redis 6 后网络 IO 已支持多线程。
I/O 多路复用
Redis 能够高并发处理海量连接,一个重要原因是 I/O 多路复用机制。 简单来说Redis 不会为每个客户端连接都创建一个线程。
否则:
10000 个连接
↓
10000 个线程线程切换成本会非常高。
Redis 的做法是一个线程同时监听多个连接。 当某个连接准备好数据时,再去处理它。
整体模型:
多个 Socket
↓
I/O 多路复用器
↓
Redis 单线程处理命令持久化机制
Redis 虽然是内存数据库,但并不意味着断电数据一定丢失 。 Redis 支持 ==RDB 快照 ==和 AOF日志,用于数据恢复。这一部分后面详细展开。
高可用机制
单机 Redis 存在风险:
Redis 挂了
↓
系统缓存失效
↓
数据库被打爆因此 Redis 提供:主从复制(Replication)实现数据备份。
哨兵(Sentinel)实现故障自动转移。
集群(Cluster)实现横向扩容。
保证了高可用 + 高并发。
2.3 Redis 为什么快(重点)
Redis 性能强大的原因,本质上可以归结为:内存 + 单线程 + I/O 多路复用 + 高效数据结构
基于内存
Redis 的数据存储在:内存(RAM) ,而不是磁盘,因此访问速度极快。
相比 MySQL:
MySQL:
磁盘 → 数据
Redis:
内存 → 数据内存访问速度远高于磁盘。
这是 Redis 高性能的根本原因。
单线程避免线程切换
Redis 使用单线程执行命令,避免了
- 锁竞争
- 上下文切换
- CPU 调度开销
提高了执行效率。
I/O 多路复用
Redis 通过 epoll + Reactor 模型 ,实现单线程管理海量连接。做到少线程+高并发,因此Redis 可以做到又简单又快。
3. Redis 安装与配置
在学习 Redis 数据结构之前,我们需要先搭建 Redis 环境,并能够成功连接、执行基础命令。本文以 Linux 虚拟机(CentOS) 为例进行安装。
3.1 Redis 安装
安装编译环境
Redis 采用 C 语言编写,因此需要先安装 GCC 编译工具:
bash
yum install gcc -y安装完成后,可以执行:
bash
gcc -v验证是否安装成功。
下载 Redis
进入安装目录:
bash
cd /usr/local下载 Redis 压缩包(以 Redis 7.4.1 为例):
bash
wget https://download.redis.io/releases/redis-7.4.1.tar.gz解压:
bash
tar -zxvf redis-7.4.1.tar.gz为了后续操作方便,可以重命名:
bash
mv redis-7.4.1 redis目录结构如下:
text
/usr/local/redis编译安装
进入 Redis 目录:
bash
cd redis执行编译:
bash
make安装:
bash
make install安装完成后,可执行:
bash
redis-server -v查看 Redis 是否安装成功。
3.2 Redis 配置
Redis 的核心配置文件为:
text
redis.conf通常需要修改以下配置。
远程访问
默认情况下 Redis 只允许本机访问。
找到:
text
bind 127.0.0.1将其注释掉:
text
# bind 127.0.0.1关闭保护模式
找到:
text
protected-mode yes修改为:
text
protected-mode no否则远程连接可能失败。
后台运行 Redis
找到:
text
daemonize no修改为:
text
daemonize yes这样 Redis 会以守护进程方式运行。
3.3 启动 Redis
启动服务:
bash
./redis-server ./redis.conf查看 Redis 进程:
bash
ps -ef | grep redis如果出现 Redis 进程,则说明启动成功。
3.4 连接 Redis
进入 Redis 客户端:
bash
./redis-cli测试连接:
bash
ping如果返回:
text
PONG说明 Redis 已成功运行。
至此,Redis 环境已经安装完成,接下来开始学习 Redis 最核心的内容:数据类型与底层结构。
结语
本文主要介绍了:
- Redis 为什么出现
- Redis 与 MySQL 的关系
- Redis 的核心特点
- Redis 为什么快
- Redis 的安装与基础配置
至此,我们已经完成 Redis 入门准备。下一篇将进入 Redis 最核心的部分:数据类型与底层实现。