等待组和屏障是两种用于协调多组执行任务(比如协程)的同步机制。我们通常使用等待组来等待一组任务全部完成。而屏障则用于在某个节点上同步多个执行过程。
Go 语言中的等待组
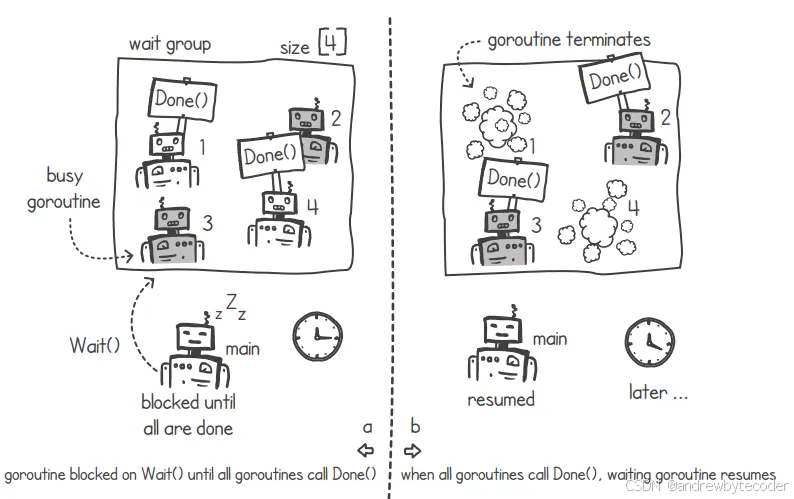
通过使用等待组,我们可以让一个协程等待着一组并发任务的全部完成。可以把等待组想象成一位项目经理,他负责管理分配给不同工作者的任务。当所有任务都完成后,这位"项目经理"就会通知我们。
使用等待组来等待任务完成
我们先设定等待组的大小,然后使用 wait()和 Done()这两个函数来控制等待过程。在这种模式下,通常有多个协程需要同时完成各自的任务。我们可以创建一个等待组,并将其大小设置为与需要完成的任务数量相等。主线程会将任务分配给新创建的协程们,而在调用 wait()函数后,主线程的执行会被暂停。当某个协程完成任务后,它会调用等待组上的 Done()函数。当所有协程都完成了各自的任务后,主线程才能继续执行。此时,主线程可以确认所有的任务都已经完成。
Go 语言的 sync 包中包含了 waitGroup 的实现。该实现包含了三个函数。
- Done() - 将等待组成员数量减 1
- Wait() - 一直等待,直到等待组的成员数量变为 0 个
- Add(delta int) - 将等待组中的成员数量增加 delta 个
go
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
func doWork(id int, wg *sync.WaitGroup) {
i := rand.Intn(5)
// 随机生成等待时间
time.Sleep(time.Duration(i) * time.Second)
fmt.Println(id, "Done working after", i, "seconds")
wg.Done()
}
func main() {
wg := sync.WaitGroup{}
// 用于等待4个个协程结束
wg.Add(4)
for i := 1; i <= 4; i++ {
go doWork(i, &wg)
}
wg.Wait()
fmt.Println("All complete")
}所有的协程在经过不同时间的等待后都会完成执行。它们会调用 waitgroup 的 Done()方法,这样主协程就能继续执行了,最终我们就能看到如下的输出结果:
go
4 Done working after 0 seconds
1 Done working after 0 seconds
3 Done working after 3 seconds
2 Done working after 3 seconds
All complete
Process finished with the exit code 0使用信号量创建等待组
现在,让我们来看看如何自行实现等待组的功能,而不是使用 Go 语言中预先提供的实现方式。我们可以基于前一章中实现的信号量机制,来创建一个简单的等待组。
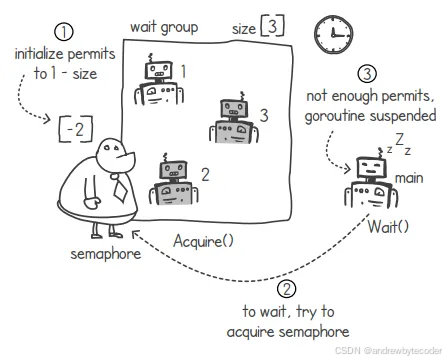
我们可以在 wait() 函数中加入相应的逻辑,从而调用信号量的 Acquire() 函数。当可用许可数量等于或少于 0 时,Acquire() 函数的执行会暂停对应的 goroutine。我们可以采用一种技巧:将信号量的许可数量初始化为 1-n,这样就能实现一个大小为 n 的等待组。这样一来,wait() 函数就会一直阻塞,直到许可数量从 1-n 增加到 1 为止。下图展示了一个大小为 3 的等待组的示例。对于大小为 3 的等待组来说,我们可以使用许可数量为-2 的信号量。
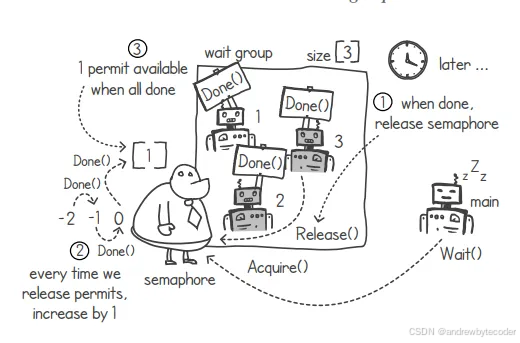
每当有一个协程对等待组调用 Done() 函数时,我们就可以对信号量执行 Release() 操作。这样,信号量上的可用许可数量就会增加 1。当所有的协程都完成自己的任务并调用 Done() 后,信号量上的许可数量将变为 1。这一过程如下图所示。
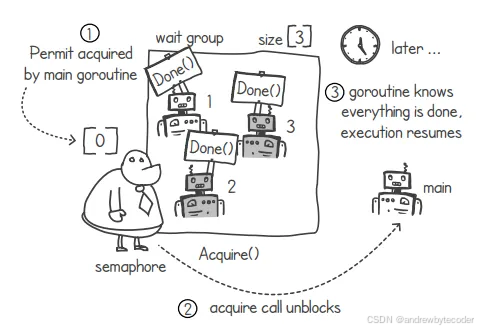
当许可数量大于 0 时,Acquire()函数就能正常执行,从而解除对相关 goroutine 的阻塞状态。在下图中,主 goroutine 获取到了许可,此时许可数量又回到了 0。这样一来,主 goroutine 就可以继续执行了,同时它也知道所有的 goroutine 都已经完成了各自的任务。
信号量实现
go
package main
import (
"sync"
)
type Semaphore struct {
permits int
cond *sync.Cond
}
func NewSemaphore(n int) *Semaphore {
return &Semaphore{
permits: n,
cond: sync.NewCond(&sync.Mutex{}),
}
}
func (rw *Semaphore) Acquire() {
rw.cond.L.Lock()
for rw.permits <= 0 {
rw.cond.Wait()
}
rw.permits--
rw.cond.L.Unlock()
}
func (rw *Semaphore) Release() {
rw.cond.L.Lock()
rw.permits++
rw.cond.Signal()
rw.cond.L.Unlock()
}
go
package main
type WaitGrp struct {
sema *Semaphore
}
func NewWaitGrp(size int) *WaitGrp {
return &WaitGrp{sema: NewSemaphore(1 - size)}
}
func (wg *WaitGrp) Wait() {
wg.sema.Acquire()
}
func (wg *WaitGrp) Done() {
wg.sema.Release()
}
go
package main
import (
"fmt"
)
func doWork(id int, wg *WaitGrp) {
fmt.Println(id, "Done working ")
wg.Done()
}
func main() {
wg := NewWaitGrp(4)
for i := 1; i <= 4; i++ {
go doWork(i, wg)
}
wg.Wait()
fmt.Println("All complete")
}在等待中调整等待组的大小
我们使用信号量来实现等待组时,存在一定的局限性:我们必须在一开始就指定等待组的大小。这意味着,在创建等待组之后,就无法再更改其大小了。为了更好地理解这一限制,我们来看一个需要在创建后调整等待组大小的应用场景。
假设我们正在使用多个协程来编写一个用于搜索文件名的程序。该程序会从指定的输入目录开始,递归地查找对应的文件名。我们需要让程序能够接收输入目录和文件名作为两个输入参数。程序的输出应包含包含完整路径的匹配结果列表。
使用多个协程可以帮助我们更快地找到文件,尤其是在需要搜索多个驱动器中的文件时。我们可以为搜索过程中遇到的每个目录分别创建一个协程。
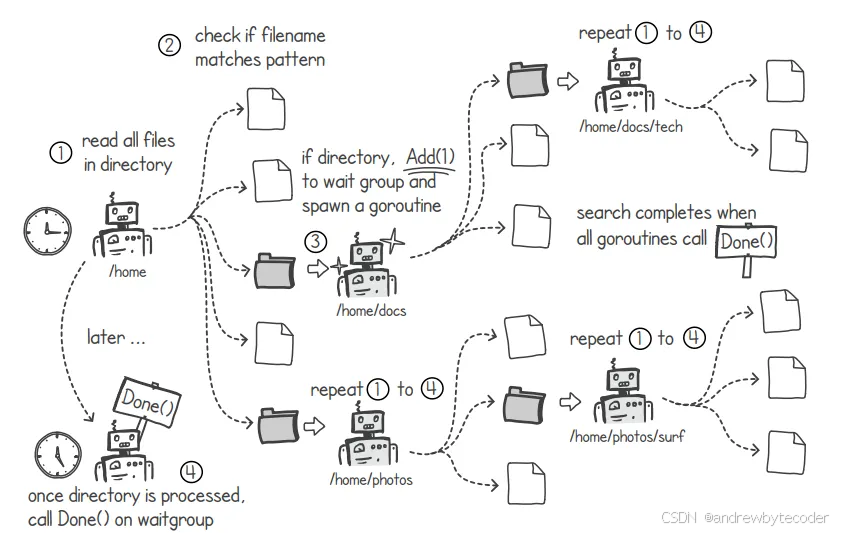
其思路是让一个协程去查找与输入字符串匹配的文件。如果该协程遇到某个目录,它会将全局等待组的计数加 1,然后创建一个新的协程来对该目录执行相同的搜索操作。当所有的协程都调用等待组的 Done()方法时,搜索过程就结束了。这意味着我们已经遍历了第一个输入目录中的所有子目录。下面的代码实现了这种递归搜索功能。
go
package main
import (
"fmt"
"os"
"path/filepath"
"strings"
"sync"
)
func fileSearch(dir string, filename string, wg *sync.WaitGroup) {
files, _ := os.ReadDir(dir)
for _, file := range files {
fpath := filepath.Join(dir, file.Name())
if strings.Contains(file.Name(), filename) {
fmt.Println(fpath)
}
if file.IsDir() {
wg.Add(1)
go fileSearch(fpath, filename, wg)
}
}
wg.Done()
}
func main() {
wg := sync.WaitGroup{}
wg.Add(1)
go fileSearch(os.Args[1], os.Args[2], &wg)
wg.Wait()
}现在,我们只需要一个 main() 函数即可。该函数负责创建一个等待组,将计数值加 1,然后启动一个 goroutine 来调用 filesearch() 函数。main() 函数只需等待等待组中的计数值变为 0,表示搜索任务已完成。如下所示:在代码中,我们使用命令行参数来指定搜索目录以及需要匹配的文件名。
构建更灵活的等待组机制
文件搜索程序让我们看到了使用 Go 内置的 waitgroup 与自行实现 semaphore waitgroup 相比所带来的优势。由于无法提前确定会创建多少个 goroutine,我们不得不在运行过程中动态调整 waitgroup 的大小。此外,自行实现的 semaphore waitgroup 有一个局限性:同一时间只能有一个 goroutine 等待在 waitgroup 中。如果有多个 goroutine 调用 wait()函数,那么只有其中一个 goroutine 能够继续执行,因为计数器只会增加一次而已。
让信号量的值变为 1。我们能否调整实现方式,使其能够与 Go 语言内置的 waitgroup 功能相兼容呢?
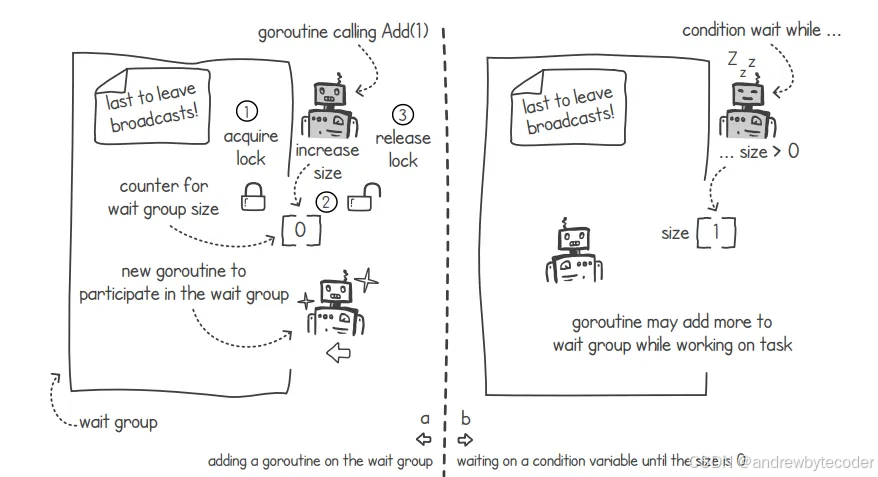
我们可以利用条件变量来实现更完善的等待组功能。下图展示了如何利用条件变量来实现 Add(delta)和 wait()这两个函数。Add()函数的作用仅仅是增加等待组的成员数量。我们可以用互斥锁来保护这个变量,从而避免在多个 goroutine 同时尝试修改它的情况。而 wait()函数的实现则依赖于条件变量:当等待组的成员数量大于 0 时,等待操作就会持续进行下去。
go
package listing6_7
import (
"sync"
)
type WaitGrp struct {
groupSize int
cond *sync.Cond
}
func NewWaitGrp() *WaitGrp {
return &WaitGrp{
cond: sync.NewCond(&sync.Mutex{}),
}
}
func (wg *WaitGrp) Add(delta int) {
wg.cond.L.Lock()
wg.groupSize += delta
wg.cond.L.Unlock()
}
func (wg *WaitGrp) Wait() {
wg.cond.L.Lock()
for wg.groupSize > 0 {
wg.cond.Wait()
}
wg.cond.L.Unlock()
}
func (wg *WaitGrp) Done() {
wg.cond.L.Lock()
wg.groupSize--
if wg.groupSize == 0 {
wg.cond.Broadcast()
}
wg.cond.L.Unlock()
}要编写"Add (delta)"函数,我们需要先获取与条件变量相关的互斥锁,然后将增量值加到 groupsize 变量上,最后释放互斥锁。在"Done()"操作中,我们同样需要使用互斥锁来保护 groupsize 变量,即先锁定它,操作完成后再解锁。此外,当 groupsize 的值大于 0 时,我们还需要进入等待状态。上述逻辑如下所示。
当某个协程希望表明自己已经完成任务时,它会调用 Done()函数。此时,在 waitgroup 的 Done()函数中,我们可以将群组中的协程数量减 1。此外,还需要设置相应的逻辑,以便最后一个调用 Done()函数的协程能够通知那些仍处于等待状态的协程。该协程能够判断出自己是最后一个完成任务的协程,因为在其调用 Done()函数后,群组中的协程数量就会变为 0。
下图的左侧展示了 goroutine 如何获取互斥锁、将组内成员数量减 1,然后再释放互斥锁。图的右侧显示,当组内成员数量变为 0 时,该 goroutine 会意识到自己是最后一个活跃的 goroutine,于是它会通过条件变量发出信号,让所有处于暂停状态的 goroutine 重新开始执行。这样一来,就可以确认 waitgroup 所承担的任务已经全部完成。我们选择使用广播方式来发送信号,而不是普通的通知方式,因为可能有多个 goroutine 因为调用 wait()函数而处于暂停状态。
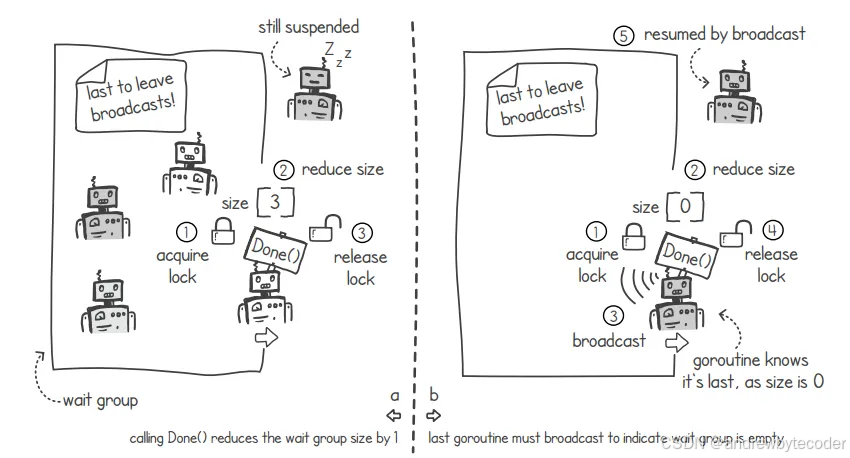
与往常一样,我们使用互斥锁来保护"groupsize"变量。之后,我们将该变量的值减 1。最后,我们检查自己是否是等待组中最后一个 goroutine------如果"groupsize"的值为 0,那么我们就对条件变量执行"Broadcast()"操作,从而让所有被挂起的 goroutine 恢复执行。
这种新的实现方式满足了我们最初的要求。我们可以在创建等待组之后调整其大小,同时也可以解除多个因调用 wait()函数而处于等待状态的 goroutine 的阻塞状态。
内存屏障
等待组在任务完成后用于实现同步非常有效。但要是我们需要在开始执行任务之前先协调各个协程的运行呢?有时候,我们还需要让不同的协程在代码中的不同时间点上同时执行。此时,屏障功能就能派上用场了------它可以帮助我们在代码的特定位置,让多个协程同步执行。
我们可以用一个简单的例子来帮助理解"等待组"和"障碍物"的概念。比如,私人飞机只有在所有乘客都到达登机口后才会起飞。这就相当于一个"内存屏障"------所有人都必须等到所有乘客都聚集到这个"内存屏障"处(即机场登机口)之后,才能继续登机。只有当所有人都到齐后,乘客们才能登上飞机。
对于同一趟航班来说,飞行员必须等待多项任务完成之后才能起飞。这些任务包括加油、装载行李以及让乘客登机等。用我们的比喻来说,这就相当于"waitgroup"阶段------飞行员需要等待所有并行进行的任务都完成后,飞机才能起飞。
要理解程序中的各种限制因素,可以想象这样一种情况:有多个协程在同时处理同一计算任务的不同部分。在这些协程开始执行之前,它们都必须等待输入数据的准备就绪。一旦数据准备完毕,它们又需要等待下一个执行时机,以便将各自的计算结果汇总起来。只要还有需要处理的输入数据,这个过程就会不断重复。下 + 图很好地诠释了这一概念。
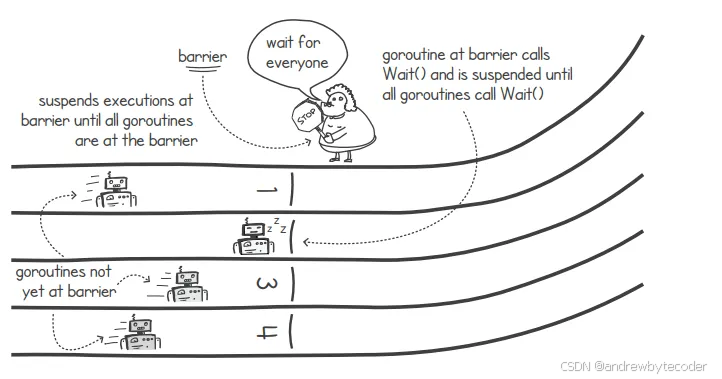
在考虑各种限制因素时,我们可以把协程看作处于两种状态之一:要么正在执行任务,要么处于暂停状态,等待其他协程完成处理。例如,某个协程可以先进行一些计算操作,然后再进入等待状态。
通过调用 wait() 函数,可以让其他协程完成它们的计算。该 wait() 函数会暂停当前协程的执行,直到所有参与此"屏障"机制的协程都调用 wait() 函数之后才会继续执行。此时,屏障机制会解除对所有被暂停的协程的约束,这样它们就能重新开始执行了。
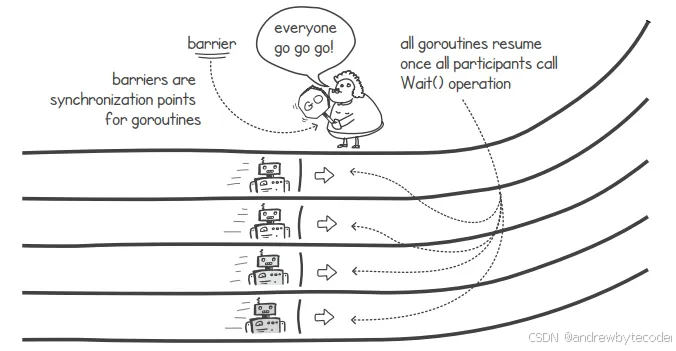
屏障与等待组的不同之处在于:它将等待组的"Done()"操作和"wait()"操作合并为一个原子性调用。另一个区别是,根据实现方式的不同,屏障可以被多次重复使用。
定义:可以重复使用的屏障有时被称为"循环式屏障"。
在 Go 语言中实现屏障机制
Go 语言并没有内置实现屏障功能的组件,因此如果我们想使用屏障功能,就必须自己来实现它。与使用等待组的方式类似,我们也可以利用条件变量来实现屏障功能。
首先,我们需要知道将要使用这个屏障的线程数量。在实现中,我们将这个数值称为"屏障大小"。通过了解这个数值,我们就能判断是否有足够的线程已经到达了屏障处。
在实现屏障机制时,我们只需关注 wait() 函数的调用即可。下图展示了调用该函数的两种情况。第一种情况是:有一个 goroutine 调用了该函数,但此时并非所有 goroutine 都处于屏障处(见图 6.l0 的左侧)。在这种情况下,调用 wait() 函数会使得等待计数器增加,从而让我们知道当前有多少 goroutine 正在等待屏障被释放。当等待的 goroutine 数量少于屏障的容量时,系统会通过让该 goroutine 等待条件变量来使其暂停执行。
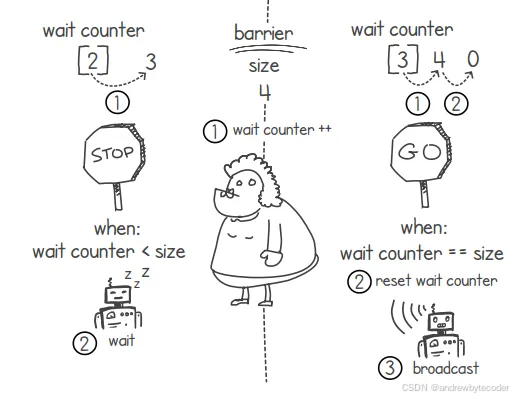
当等待计数器的值达到阈值时,我们需要将计数器重置为 0,并通过条件变量进行广播,从而唤醒所有处于暂停状态的协程。这样一来,那些正在等待的协程就能恢复执行了。
下面代码中,我们实现了与"屏障"相关的结构体类型以及用于创建屏障的 NewBarrier 函数。该结构体包含了屏障的大小、一个等待计数器,以及一个对条件变量的引用。在构造函数中,我们将等待计数器初始化为 0,同时创建一个新的条件变量,并将屏障的大小设置为函数参数所指定的值。
go
package main
import "sync"
type Barrier struct {
size int
waitCount int
cond *sync.Cond
}
func NewBarrier(size int) *Barrier {
condVar := sync.NewCond(&sync.Mutex{})
return &Barrier{size, 0, condVar}
}
func (b *Barrier) Wait() {
// 使用互斥锁来保护waitCount变量的访问
b.cond.L.Lock()
b.waitCount += 1
// 如果waitCount达到了阈值,就重置waitCount的值,并通过条件变量进行广播通知。
if b.waitCount == b.size {
b.waitCount = 0
b.cond.Broadcast()
} else {
// 如果waitCount尚未达到阈值,那么就继续等待,同时持有条件变量。
b.cond.Wait()
}
b.cond.L.Unlock()
}我们可以通过让两个协程分别执行不同时长的工作来测试这种"屏障"机制。下面代码中,有一个 workandwait()函数:该函数会先执行一段时间的工作,之后进入等待状态。与往常一样,我们使用 time.sleep()函数来模拟工作的过程。当协程从"屏障"状态中解除阻塞后,它会再次开始执行相同时长的工作。在每个阶段,该函数都会打印出自协程启动以来的时间,单位为秒。
go
package main
import (
"fmt"
"time"
)
// 执行到地方了,多个协程同时等待,直到所有的服务都执行完成
func workAndWait(name string, timeToWork int, barrier *Barrier) {
start := time.Now()
for {
fmt.Println(time.Since(start), name, "is running")
time.Sleep(time.Duration(timeToWork) * time.Second)
fmt.Println(time.Since(start), name, "is waiting on barrier")
barrier.Wait()
}
}
func main() {
barrier := NewBarrier(2)
go workAndWait("Red", 4, barrier)
go workAndWait("Blue", 10, barrier)
time.Sleep(100 * time.Second)
}现在,我们可以启动两个使用 workAndwait() 函数的 goroutine,这两个 goroutine 所需要的工作时间各不相同。这样一来,完成工作较快的 goroutine 会被"屏障"暂停执行,它必须等待较慢的 goroutine 完成后才能继续执行。在主函数中,我们创建了一个"屏障",并启动了两个 goroutine,同时将对该"屏障"的引用传递给这两个 goroutine。我们将这两个 goroutine 分别命名为"Red"和"Blue",给它们分别设定 4 秒和 10 秒的工作时间。
当我们同时运行代码段时,程序会运行 100 秒后结束,此时主 goroutine 也会终止。正如预期的那样,那个运行速度较快的 goroutine 被称为"Red",它很快就能完成任务,然后等待另一个运行速度较慢的 goroutine------"Blue"完成其任务。后者需要 10 秒才能完成任务。从输出的时间戳中可以看出这一情况。
go
0s Red is running
0s Blue is running
4.0010853s Red is waiting on barrier
10.0008419s Blue is waiting on barrier
10.0008419s Blue is running
10.0008419s Red is running
14.0016971s Red is waiting on barrier
20.0020384s Blue is waiting on barrier
20.0020384s Blue is running
20.0020384s Red is running
24.002994s Red is waiting on barrier
30.0025444s Blue is waiting on barrier
30.0025444s Blue is running
30.0025444s Red is running
34.0034109s Red is waiting on barrier
40.0032668s Blue is waiting on barrier
40.0032668s Blue is running
40.0032668s Red is running
44.0033899s Red is waiting on barrier
50.0034345s Blue is waiting on barrier
50.0034345s Blue is running
50.0034345s Red is running
54.0039966s Red is waiting on barrier
1m0.0042804s Blue is waiting on barrier
1m0.0042804s Blue is running
1m0.0042804s Red is running
1m4.0045925s Red is waiting on barrier
1m10.0053304s Blue is waiting on barrier
1m10.0053304s Blue is running
1m10.0053304s Red is running
1m14.0063314s Red is waiting on barrier
1m20.0062591s Blue is waiting on barrier
1m20.0062591s Blue is running
1m20.0062591s Red is running
1m27.6673365s Red is waiting on barrier
1m30.00735s Blue is waiting on barrier
1m30.00735s Blue is running
1m30.0074903s Red is running
1m34.0084202s Red is waiting on barrier
Process finished with the exit code 0使用屏障机制进行并行矩阵乘法运算
矩阵乘法是线性代数中的基本运算,被广泛应用于各个计算机科学领域。在图论、人工智能和计算机图形学等众多领域中,都有大量算法需要使用矩阵乘法来实现。不过,进行这种线性代数运算需要耗费相当多的时间。
使用这种简单的迭代方法来计算两个 n×n 矩阵的乘积时,其时间复杂度为 O(n³)。这意味着,计算所需的时间会随着矩阵尺寸 n 的增大而呈立方级增长。例如,如果计算一个 n×n 矩阵的乘积需要 10 秒的话,那么当矩阵尺寸变为 2n×2n 时,计算时间将会增加到 100 秒。
计算两个 100×100 矩阵的乘积时,所需时间为几秒而已。而当矩阵的大小变为 200×200 时,计算相同运算结果所需的时间则增加到 80 秒。由此可见,当输入数据的规模翻倍时,计算所需时间也会增加 23 倍。
更快速的矩阵乘法算法
有一些矩阵乘法算法的运行时间复杂度低于 O(n³)。1969 年,德国数学家沃尔克·斯特拉森提出了一种更快的算法。不过,这种算法的优越性只有在矩阵规模非常大时才能体现出来。对于较小的矩阵来说,简单的乘法算法显然更为适用。
其他一些较新的算法,其运行时间复杂度更低。不过,这些算法在实际应用中并不被采用,因为只有当矩阵的输入规模大到惊人时,这些算法才能体现出其优势------而实际上,这样的输入规模已经超出了现代计算机内存的存储能力。这类算法属于"银河算法"这一类别,它们能在那些因规模过大而无法在现实中应用的场景中,发挥出优于其他算法的性能。
我们该如何利用并行计算技术,构建出矩阵乘法算法的并行版本,从而加快运算速度呢?首先,让我们先回顾一下矩阵乘法的原理。为简化实现过程,本节中我们只考虑方阵(n×n 矩阵)。例如,在计算矩阵 A 与矩阵 B 的乘积时,第一个元素(第 0 行、第 0 列)的值,其实就是 A 的第 0 行与 B 的第 0 列相乘的结果。下图展示了一个 3×3 矩阵乘法的示例。要计算第二个元素(第 0 行、第 1 列),则需要将 A 的第 0 行与 B 的第 1 列相乘,依此类推。
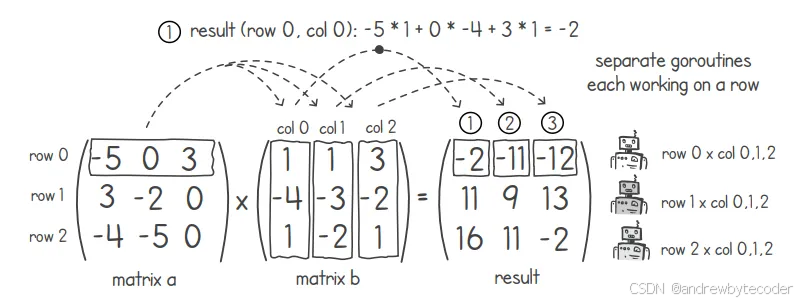
下面的代码展示了一个能够在单条 goroutine 中完成这种乘法运算的函数。该函数使用了三个嵌套循环:首先遍历行数,然后再遍历列数;最后,在最内层的循环中,将对应的元素相乘并求和。
go
func matrixMultiply(matrixA, matrixB, result *[matrixSize][matrixSize]int) {
for row := 0; row < matrixSize; row++ {
for col := 0; col < matrixSize; col++ {
sum := 0
for i := 0; i < matrixSize; i++ {
sum += matrixA[row][i] * matrixB[i][col]
}
result[row][col] = sum
}
}
}让我们的算法能够被多个处理器并行处理的一种方法是将矩阵乘法操作拆分成多个部分,然后让每个部分由一个协程来负责计算。上图展示了如何通过为每一行分配一个协程的方式来分别计算出每行的结果。对于一个 n×n 大小的矩阵来说,我们可以创建 n 个协程,每个协程负责计算其中一行的结果。
为了让矩阵乘法运算更贴近实际应用场景,我们可以让运算过程分为三个步骤,然后重复这三个步骤,从而模拟出一种需要长时间才能完成的计算过程。
- 加载矩阵 A 和 B 的输入数据。
- 使用每个行对应一个协程的方式,同时计算 A × B 的结果。
- 将结果输出到控制台上。
在第一步中,即加载输入矩阵时,我们可以直接使用随机整数来生成这些矩阵。而在实际应用中,我们需要从某个来源获取这些输入数据,比如通过网络连接或从文件中读取。下面的代码展示了一个可用于用随机整数填充矩阵的函数。
go
const matrixSize = 3
func generateRandMatrix(matrix *[matrixSize][matrixSize]int) {
for row := 0; row < matrixSize; row++ {
for col := 0; col < matrixSize; col++ {
matrix[row][col] = rand.Intn(10) - 5
}
}
}为了计算并行乘法运算(步骤 2),我们需要一个能够对结果矩阵中每一行进行乘法计算的函数。具体来说,我们可以让多个协程分别执行这个函数,每个协程负责处理矩阵中的一行数据。当所有协程完成对矩阵中所有行的计算后,我们就可以将最终的结果矩阵输出到控制台上了(步骤 3)。
如果我们需要多次执行步骤 1 到步骤 3,那么就需要有一种机制来协调这些步骤的顺序。例如,我们不能在加载输入矩阵之前就进行乘法运算。同样,也应在所有的 goroutine 完成对所有行的计算之后,才能输出最终结果。
这就是我们在前一节中的"屏障机制"发挥作用的地方。利用这种机制,我们可以确保各个步骤能够有序地进行同步处理,避免在某个步骤尚未完成时就开始下一个步骤。下图展示了实现这一目标的办法。从图中可以看出,对于 3×3 的矩阵来说,我们可以使用大小为 4 的屏障机制(即总行数加 1)。这个数值正好对应于我们的 Go 程序中所有协程的总数,当然,这里还包括了 main()协程在内。
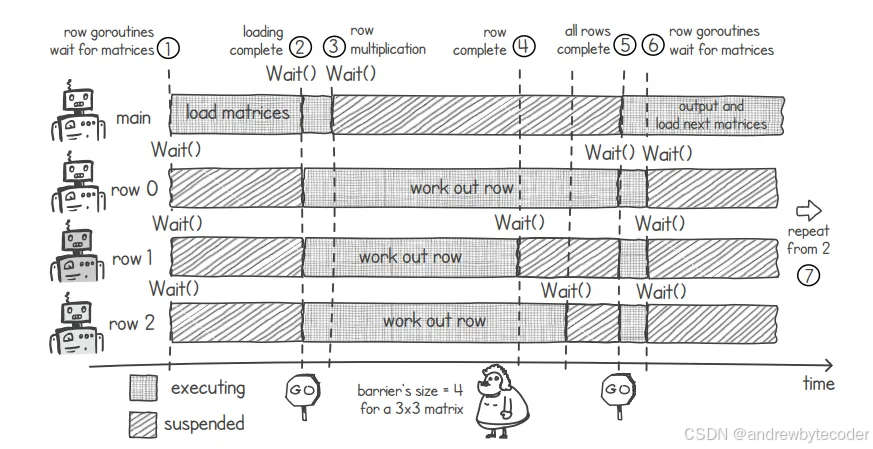
- 最初,主 goroutine 负责加载输入矩阵,而各个处理行的 goroutine 则需在屏障处等待。在我们的应用程序中。
- 加载完成后,main()协程会调用最终的 wait()操作,从而释放所有的协程。
- 现在轮到主 goroutine 等待其他 goroutines 完成它们的乘法运算了。
- 当一个协程计算完自己负责的那行数据后的结果后,它会再次调用屏障上的
wait()函数。 - 当所有的协程都执行完毕,并在屏障上调用
wait()函数后,所有协程都将解除阻塞状态。此时,main()协程将会输出处理结果,并加载下一个输入矩阵。 - 每行中的协程都会通过调用屏障上的
wait()函数来等待,直到主线程的加载任务完成为止。 - 只要还有矩阵需要相乘,就持续重复步骤 2 的操作。
如下代码展示了如何实现单行乘法运算。该函数接受两个输入矩阵、一个用于存放结果矩阵的容器、一个标志位,以及表示需要计算哪一行的参数。它不会遍历所有行,而是只处理作为参数传入的那一行。其实现方式与列表 6.14 相同,只不过没有外部循环结构而已。在并行性方面,根据可用处理器的数量,Go 的运行时系统能够合理分配计算任务,让各个 CPU 核心都能高效地处理相应的计算任务。理想情况下,每个执行乘法计算的 goroutine 都能拥有独立的 CPU 核心来运行。
go
package main
import (
"fmt"
"math/rand"
"sync"
)
type Barrier struct {
size int
waitCount int
cond *sync.Cond
}
func NewBarrier(size int) *Barrier {
condVar := sync.NewCond(&sync.Mutex{})
return &Barrier{size, 0, condVar}
}
func (b *Barrier) Wait() {
b.cond.L.Lock()
b.waitCount += 1
if b.waitCount == b.size {
b.waitCount = 0
b.cond.Broadcast()
} else {
b.cond.Wait()
}
b.cond.L.Unlock()
}
const matrixSize = 3
func generateRandMatrix(matrix *[matrixSize][matrixSize]int) {
for row := 0; row < matrixSize; row++ {
for col := 0; col < matrixSize; col++ {
matrix[row][col] = rand.Intn(10) - 5
}
}
}
func rowMultiply(matrixA, matrixB, result *[matrixSize][matrixSize]int, row int, barrier *Barrier) {
for {
barrier.Wait()
for col := 0; col < matrixSize; col++ {
sum := 0
for i := 0; i < matrixSize; i++ {
sum += matrixA[row][i] * matrixB[i][col]
}
result[row][col] = sum
}
barrier.Wait()
}
}
func main() {
var matrixA, matrixB, result [matrixSize][matrixSize]int
barrier := NewBarrier(matrixSize + 1)
for row := 0; row < matrixSize; row++ {
go rowMultiply(&matrixA, &matrixB, &result, row, barrier)
}
for i := 0; i < 4; i++ {
generateRandMatrix(&matrixA)
generateRandMatrix(&matrixB)
barrier.Wait()
barrier.Wait()
for i := 0; i < matrixSize; i++ {
fmt.Println(matrixA[i], matrixB[i], result[i])
}
fmt.Println()
}
}正如我们在矩阵乘法示例中看到的那样,屏障是一种非常有用的并发控制工具,它能够帮助我们在代码的特定节点处同步各个执行过程。这种"先加载数据、等待处理完成后再获取结果"的处理方式,正是屏障的典型应用场景。不过,这种机制在那些创建新线程的成本较高的情况下尤为有用,比如在使用内核级线程时。通过使用这种机制,就可以节省每次数据加载时创建新线程所花费的时间。
在 Go 语言中,创建协程的成本很低且效率很高。因此,在这种场景下使用同步原语并不会带来显著的性能提升。通常,更简单的做法是先加载所需处理的任务,创建相应的协程,然后使用等待组来等待这些协程完成,最后再收集处理结果。不过,在需要同步大量协程的情况下,使用同步原语仍然可能带来一定的性能优势。