目录
[1. 用户态与内核态的隔离](#1. 用户态与内核态的隔离)
[2. 系统调用:用户态访问内核的唯一合法入口](#2. 系统调用:用户态访问内核的唯一合法入口)
[3. glibc:系统调用的用户态封装](#3. glibc:系统调用的用户态封装)
[4. 异常触发:从用户态到内核态的切换机制](#4. 异常触发:从用户态到内核态的切换机制)
本文章内容均来自本人的个人笔记为个人学习总结,禁止他人转载 ,参考自B站课程:码农论坛《C++环境高级编程》,以及韦东山《嵌入式linux应用开发》。由于当时方便记笔记,笔记中少部分图片(仅涉及部分代码以及相关运行结果展示,不涉及重要笔记、资料等)来源于原课程视频截图,版权归原作者"码农论坛","韦东山"及相关权利人所有。
本笔记无任何商业用途(除开csdn官方操作),仅供个人学习交流。感谢原up主的课程分享!
一、为什么文件这么重要?
- 对linux来说,socket函数和文件操作没有区别。
- 在网络传输的过程中,可以使用文件i/o函数。
总之,在linux中,一切皆文件。
先看几个演示:
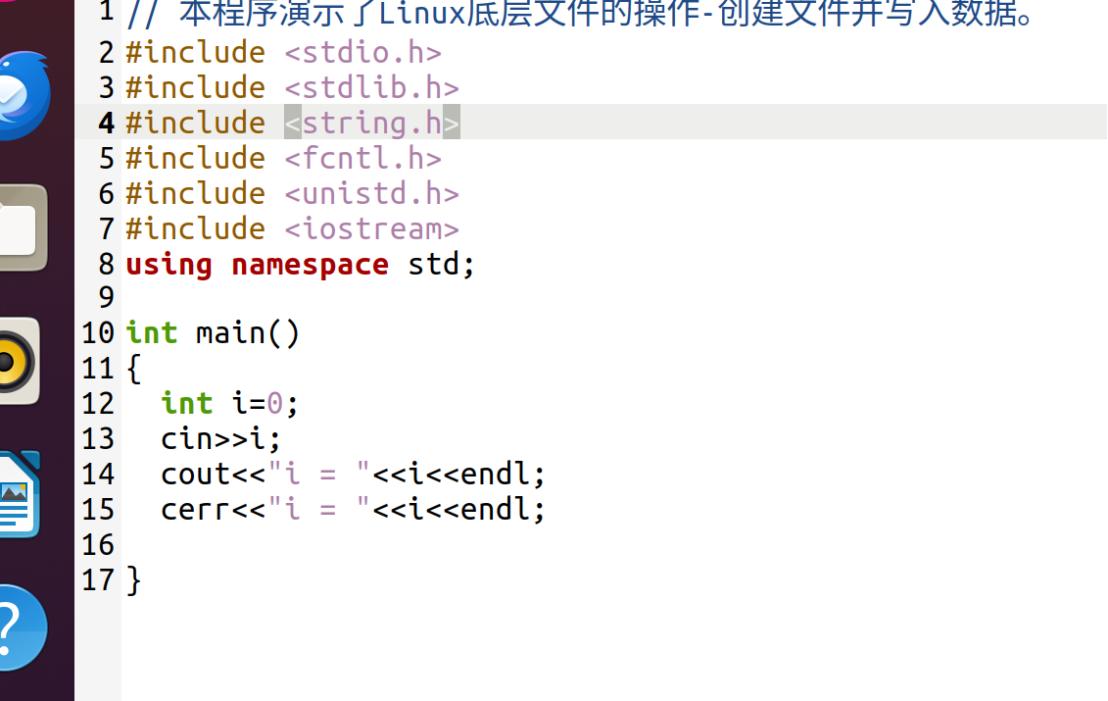
先看两个简单的演示代码:
创建文件并写入数据:
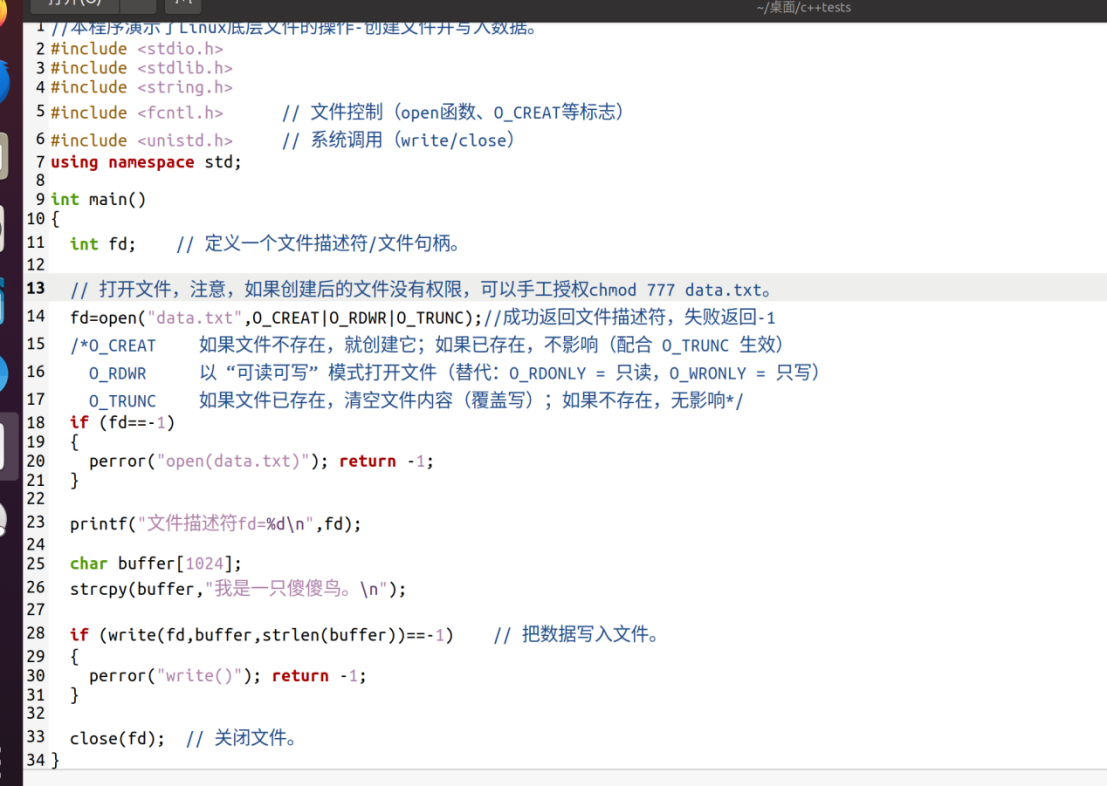
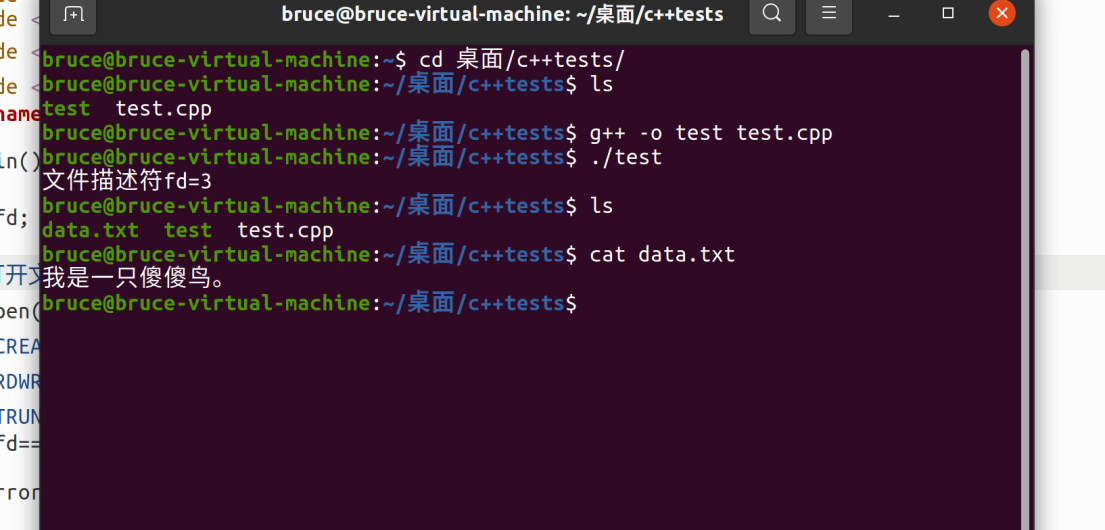
编译运行:
再演示:读取文件
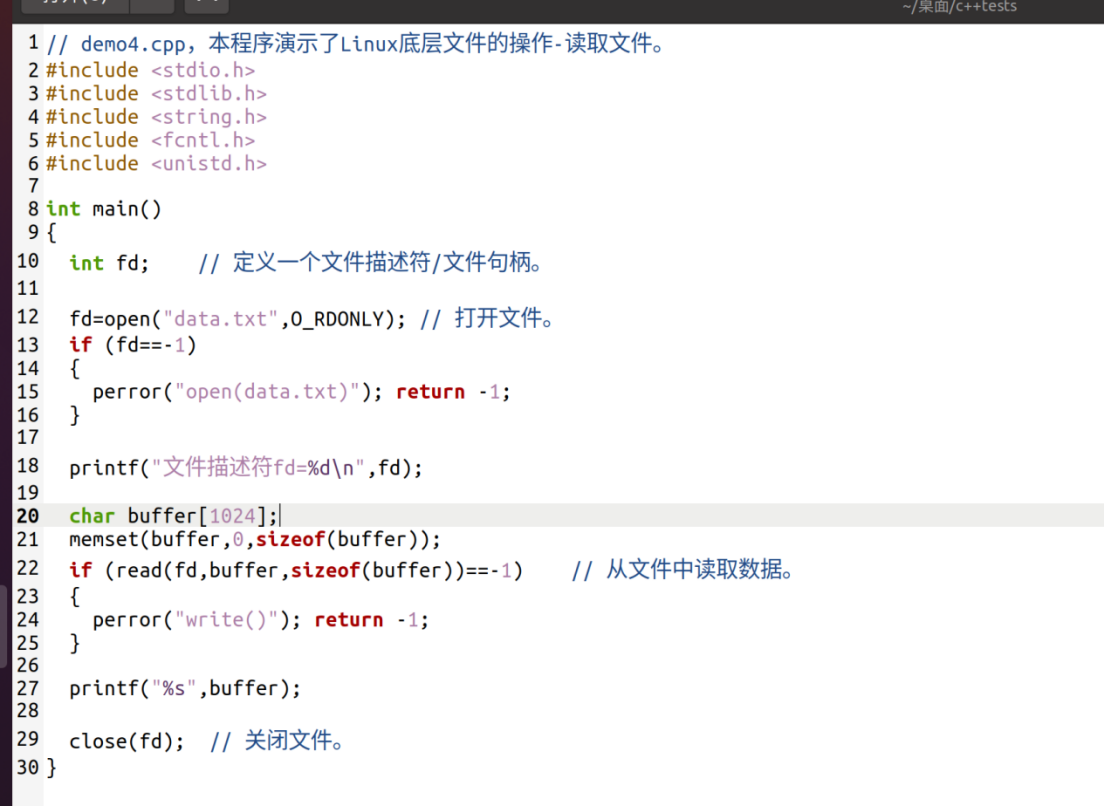
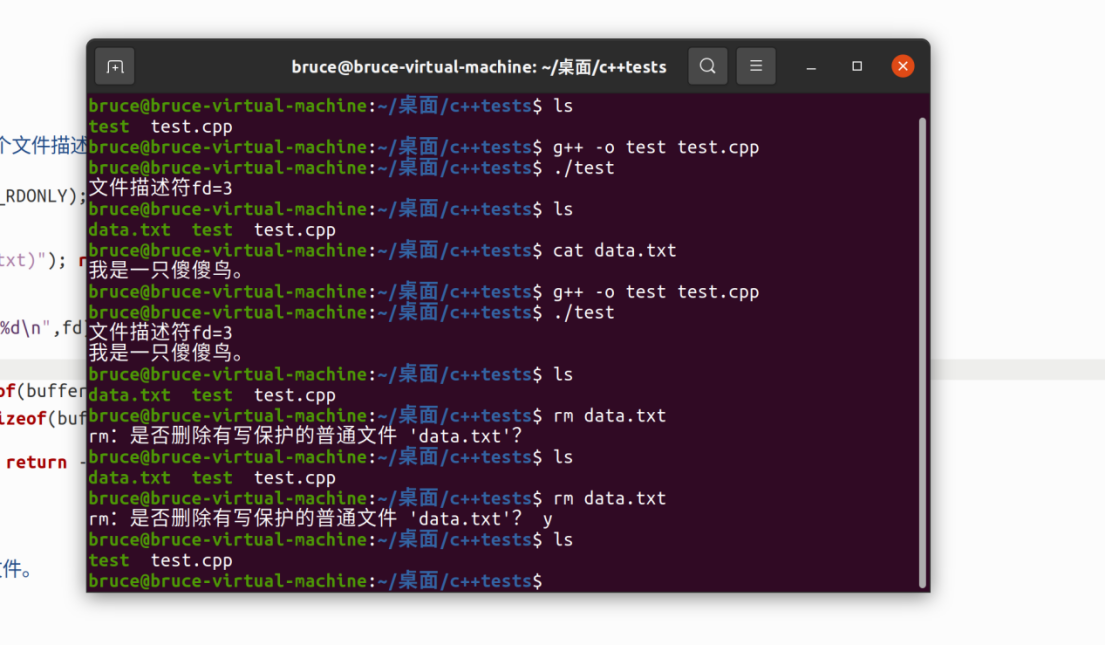
在/porc/进程id/fd目录中,存放了每个进程打开的fd(文件描述符,又叫文件句柄)
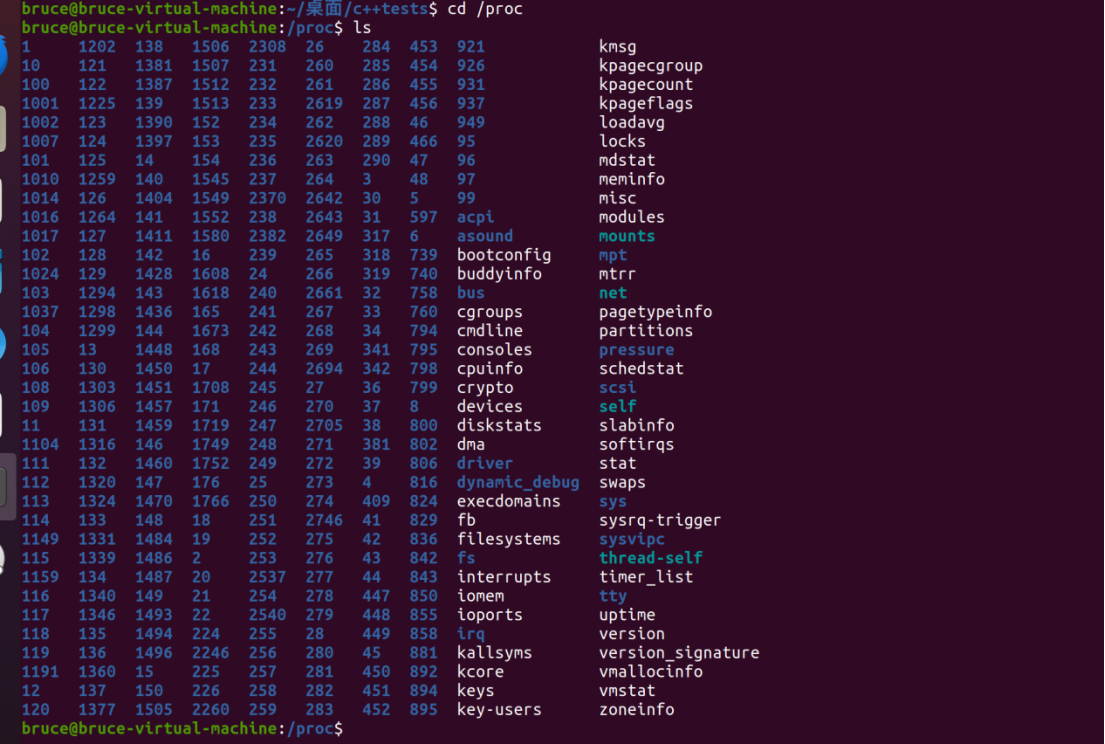
这些数字都是系统的进程,全部的进程在这里:
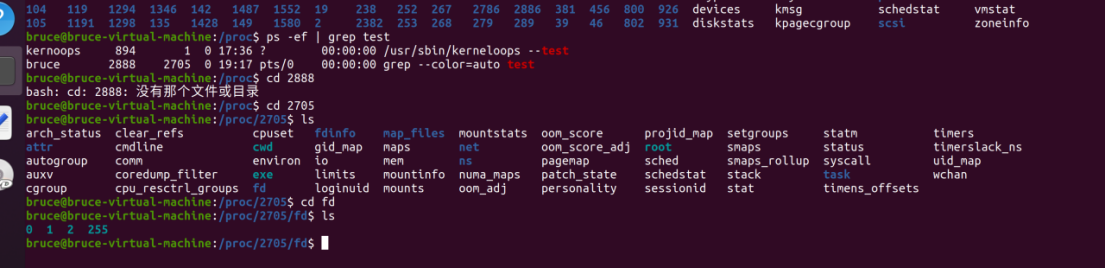
用ps命令查看与test有关的进程:
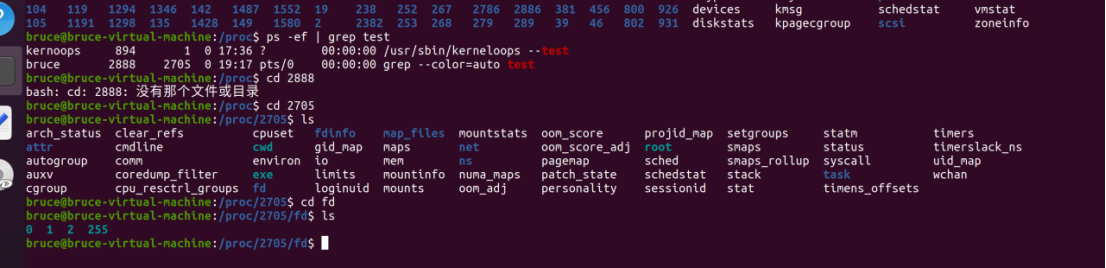
就可以进入fd目录,查看具体的文件描述符了!
但是这是shell的。
修改test(demo3):

编译运行:

此时程序还在运行
回到另一个窗口,查看test进程:

显示0,1,2,3
我们只打开了一个文件是3,那012是哪来的???
原因;
Linux 进程默认打开 3 个文件描述符:
0:标准输入(对应设备:键盘,C++ 中对应 cin)
1:标准输出(对应设备:显示器,C++ 中对应 cout)
2:标准错误(对应设备:显示器,C++ 中对应 cerr)
所以在c++中才可以使用这些进行输入输出操作
演示:linux缺省进程打开的3个文件描述符
先补充一下close命令:
close(fd)是 Linux 系统调用,作用是释放指定的文件描述符,让进程和对应的文件 / 设备断开关联
简单说:close(fd) 就是 "关掉" 进程对某个文件 / 网络连接的访问权限,把 fd 这个 "编号车位" 空出来。
|------------------------------------------------------------------------|---------------|--------------|----------------------|
| fd 值 | 名称 | 对应设备 | C++ 标准 IO 绑定 |
| 0 | 标准输入 (stdin) | 键盘 | cin |
| 1 | 标准输出 (stdout) | 显示器 | cout |
| 2 | 标准错误 (stderr) | 显示器 | cerr |
| 核心关联 :C++ 的cin/cout/cerr本质是对底层 fd=0/1/2 的封装,fd 被关闭,上层 IO 就会失效。 | | | |
cin/cout 绑定 "标准输入 / 输出通道" 是 C++ 标准规定的通用逻辑,Windows 也不例外;区别只在于:Linux 用「整数文件描述符(fd)」表示这个通道,Windows 用「句柄(HANDLE)」表示,但绑定关系本身是通用的。
Windows:
// 1. 获取标准输入/输出句柄(替代Linux的fd=0/1)
HANDLE hStdin = GetStdHandle(STD_INPUT_HANDLE);
HANDLE hStdout = GetStdHandle(STD_OUTPUT_HANDLE);
// 2. 关闭标准输入/输出句柄(替代Linux的close(0)/close(1))
CloseHandle(hStdin);
CloseHandle(hStdout);
|------------|-------------------------|--------------------------|
| 特性 | Linux | Windows |
| IO 管理方式 | 整数文件描述符(fd) | 句柄(HANDLE,结构体指针) |
| 标准 IO 标识 | fd=0 (输入)/1 (输出)/2 (错误) | STD_INPUT_HANDLE 等宏(非整数) |
| 关闭 IO 的函数 | close(fd) | CloseHandle(HANDLE) |
| 核心头文件 | unistd.h/fcntl.h | windows.h |
正式演示:
编译运行:
没有任何问题。
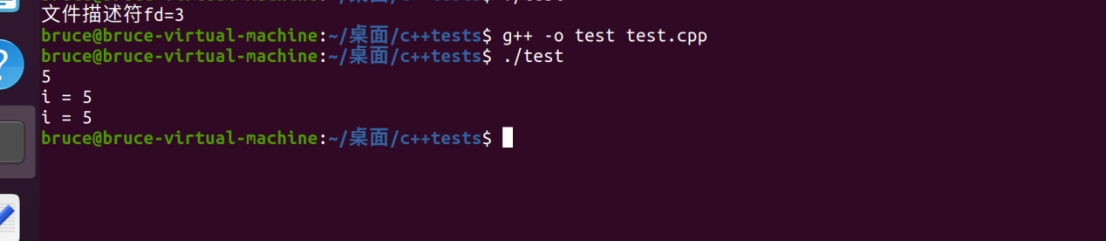
若关闭标准输入:


直接显示0,根本没有机会让我们输入。
若也关闭标准输出:
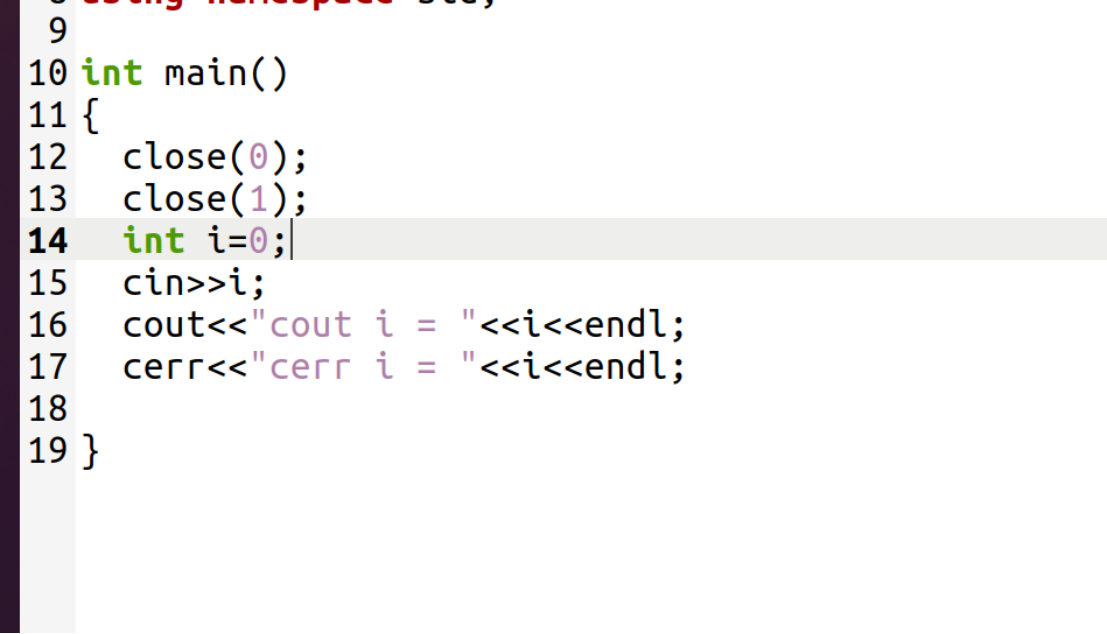

只显示了标准错误
同理,把标准错误都关掉(close(2)),这几行代码都不会显示!
综上!!!
"Linux 一切皆文件描述符"+"C++ 标准 IO 绑定 fd"
把这几个都关了,并sleep(100s),查看进程:
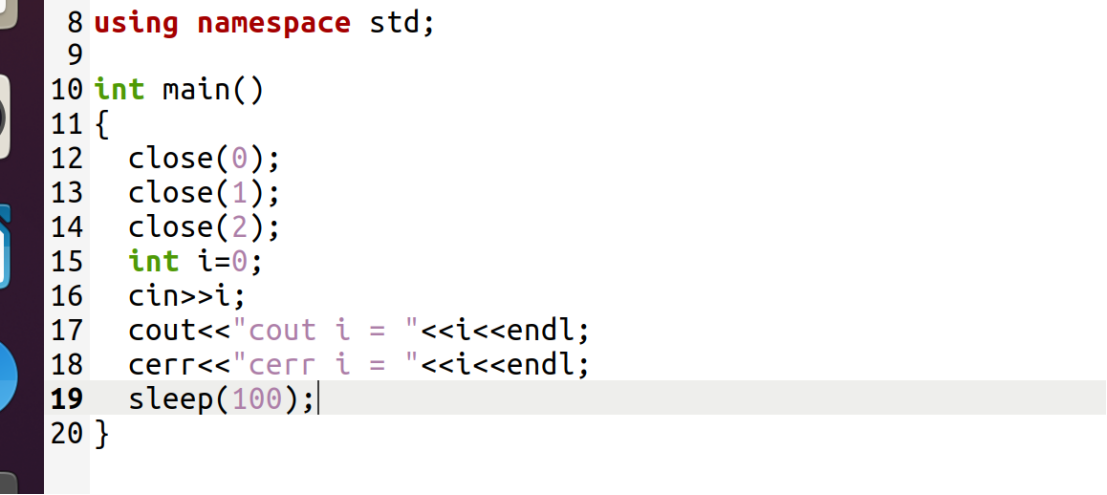
补充:进程的正确看法
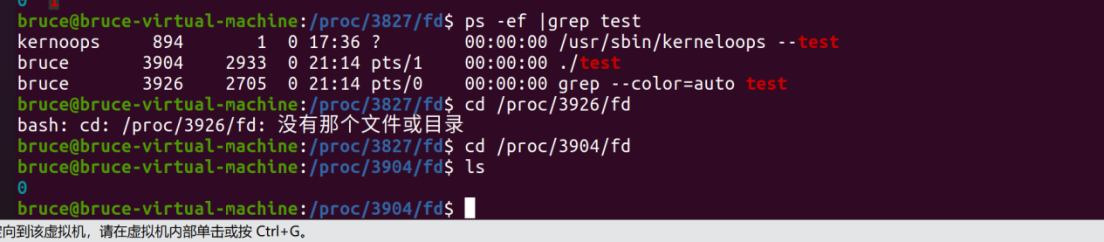
示例:

第 1 行:vi demo3.cpp
这是你用 vi 编辑器打开 demo3.cpp 源码的进程,不是运行的程序。
第 2 行(你要找的):./demo3
命令列是 ./demo3 → 这就是你编译后正在运行的可执行程序,也就是真正的 demo3 进程,PID=7979。
它运行在 pts/2 终端,说明你是在第二个终端窗口里执行的 ./demo3。
第 3 行:grep --color=auto demo3
这是你当前执行的 ps -ef | grep demo3 命令里的 grep 子进程,它只是在搜索包含 "demo3" 的进程,不是你写的程序。
它会把自己也搜出来,因为命令里包含 "demo3" 这几个字。
为什么是7979而不是7076 ???
7979 是 ./demo3 这个程序的进程 ID(PID),也就是你要找的目标进程。
7076 是它的父进程 ID(PPID),也就是启动它的那个 shell(终端)进程,不是 demo3 本身。
接下来编译运行,查看进程:


显示:啥也没有!
文件描述符的分配规则:找到最小的,没有被占用的文件描述符:
现在关闭了0,1,2,加上一个socket(套接字),注意加上头文件sys/socket.h
之后打开文件会发生啥?

编译运行:

查看进程:

执行ls,显示0 1(这里忘了执行截图)如上
详细解释为什么是0 1,而不是3 4:
之前打开文件,文件描述符是3,现在关闭了012:
详解步骤:
步骤 1:初始状态(进程启动)
系统默认分配 3 个 fd:0(stdin)、1(stdout)、2(stderr) --> 这 3 个编号都被占用。
步骤 2:执行 close(0); close(1); close(2);
手动释放了 0、1、2 这 3 个编号 --> 现在 0、1、2 都是"空车位",3、4、5... 也都是空的。
步骤 3:执行 fd=open("data.txt",...)
内核开始找"最小的空编号":
先看 0 --> 空的 --> 直接分配给文件 --> fd=0。
此时占用的 fd:0(文件),1、2、3... 仍空。
步骤 4:执行 sockfd=socket(...)
内核继续找"最小的空编号":
先看 0 --> 已被文件占用 --> 跳过;
再看 1 --> 空的 --> 分配给 Socket --> sockfd=1。
此时占用的 fd:0(文件)、1(Socket),2、3... 仍空。
步骤 5:执行 ls /proc/3776/fd
看到的就是当前被占用的 fd:0、1 --> 完全符合「找最小未占用」的规则。
把socket注释掉,再编译运行,查看进程:
显示0!!!!
系统默认分配 3 个 fd:0(stdin)、1(stdout)、2(stderr) --> 这 3 个编号都被占用。
执行 close(0); close(1); close(2);
手动释放了 0、1、2 这 3 个编号 --> 现在 0、1、2 都是「空车位」,3、4、5... 也都是空的。
执行 fd=open("data.txt",...)
内核开始找"最小的空编号":
先看 0 --> 空的 --> 直接分配给文件 --> fd=0。
由此说明:文件描述符的分配规则:找到最小的,没有被占用的文件描述符。

运行完毕,上述两个程序连printf的内容都没有输出!
说明::
C 语言的标准输入输出也是绑定文件描述符的,而且和 C++ 的逻辑完全一致。
在linux是绑定fd,在windows是绑定句柄!
C 语言的标准输入输出也是绑定文件描述符的,而且和 C++ 的逻辑完全一致。
在linux是绑定fd,在windows是绑定句柄!
|-------------------|------------|-------------------------|--------------|
| C 语言标准 IO | 含义 | 绑定的 Linux 文件描述符 | 对应设备 |
| stdin | 标准输入 | 0 | 键盘 |
| stdout | 标准输出 | 1 | 显示器 |
| stderr | 标准错误 | 2 | 显示器 |
|-------------------|--------------------|------------------------------------|
| C 语言标准 IO | Linux 底层实现 | Windows 底层实现 |
| stdin | 绑定 fd=0 | 绑定 GetStdHandle(STD_INPUT_HANDLE) |
| stdout | 绑定 fd=1 | 绑定 GetStdHandle(STD_OUTPUT_HANDLE) |
| stderr | 绑定 fd=2 | 绑定 GetStdHandle(STD_ERROR_HANDLE) |
接下来创建一个socket:
编译运行:

查看进程,进入目录并ls:

说明,socket本质就是文件的操作。
解释:统一的 I/O 操作
在网络传输数据的过程中,可以直接使用文件的 I/O 函数(如read()/write())来收发数据,对socket函数也是如此:
来到之前的网络编程客户端(在我上一篇博客)程序:
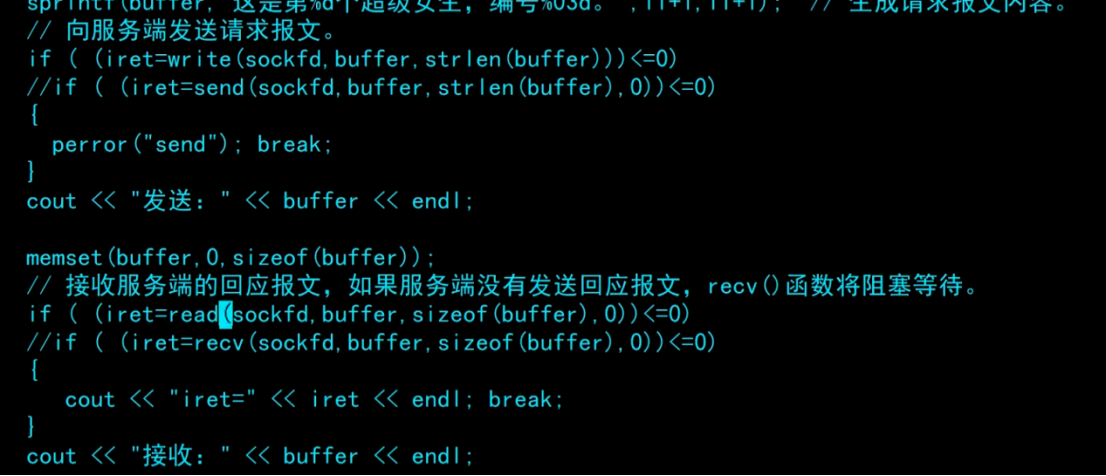
在服务端程序的send和recv都可以改成文件操作的write和read,效果是一样的:
编译运行服务端程序,再编译运行客户端,效果一样:
同样类比:
C/C++ 标准库的文件操作(比如 C 的 fopen/fread/fwrite、C++ 的 fstream)本质上都是对底层文件描述符(fd)的封装------ 上层的「文件指针(FILE*)」「流对象(fstream)」最终都会绑定到内核的文件描述符,所有读写操作最终都会通过 fd 与内核交互。
简单说:fd 是 Linux 内核给文件的 "底层身份证",C/C++ 的文件操作只是给这个身份证套了一层 "易用的上层接口"。
这里就不演示了,大家自己测试一下。
总结一下:
核心设计思想:一切皆文件
对 Linux 而言,socket 操作与普通文件操作没有本质区别:
普通文件、网络 socket、管道、设备等,在 Linux 内核中都被抽象为「文件」,统一用 ** 文件描述符(fd)** 来管理。
这是 Linux "一切皆文件" 设计哲学的直接体现。
统一的 I/O 操作
在网络传输数据的过程中,可以直接使用文件的 I/O 函数(如read()/write())来收发数据:
对文件:read(fd, buf, count) / write(fd, buf, count)
对 socket:read(sockfd, buf, count) / write(sockfd, buf, count)
接口完全一致,上层代码无需关心底层是文件还是网络连接。
文件描述符(fd)的本质
文件描述符是 Linux 分配给文件或 socket 的整数标识:
它是进程与内核之间的 "凭证",进程通过 fd 来访问对应的资源(文件、网络、设备等)。
分配规则:内核会选择当前最小的未被占用的整数作为新的 fd。
进程启动时默认占用:0(标准输入)、1(标准输出)、2(标准错误)。
✨ 一句话总结
Linux 把网络 socket 和普通文件统一抽象为「文件」,用 ** 文件描述符(fd)** 来标识,并用同一套read/write接口完成 I/O,这就是 "一切皆文件" 的核心魅力。
但注意区分: 不是 "所有东西",而是:进程能访问的几乎所有 I/O 资源,本质都是用文件描述符(fd)来表示。
文件描述符只是进程视角的 "句柄 / 编号",不是硬件本身,也不是内核对象本身。
相当于:
你手里的门卡编号,不是门本身,也不是房间。
哪些东西会被分配 fd?
几乎所有I/O 资源(所有能 "进数据" 和 "出数据" 的东西)都会用 fd 表示:
普通文件
目录(某些打开方式)
管道(pipe)
有名管道(fifo)
socket(TCP/UDP/ 原始套接字)
终端设备(/dev/tty、/dev/pts/0)
键盘、显示器
声卡、显卡(部分设备)
大部分设备文件(/dev/xxx)
哪些东西不是文件描述符?
进程本身(PID 不是 fd)
线程
内存地址
信号
锁
内核对象本身(inode、file 结构体)
管道、socket 是内核对象,fd 只是指向它的编号
最经典的一句 Linux 设计哲学
Everything is a file, not everything is a file descriptor.
一切皆文件(抽象)
不是一切皆文件描述符(整数编号)
对应你代码里的
open() 打开文件 → I/O 资源
socket()/accept() 网络 → I/O 资源
close() 关闭 I/O 资源
所有 I/O 资源,Linux 都用 fd 来代表示。
二、文件内部的io调用机制
总的来说,是一下几点:
1. 用户态与内核态的隔离
Linux 将虚拟地址空间划分为用户空间和内核空间,两者通过硬件内存保护机制(MMU)严格隔离。用户进程运行在用户态,无法直接访问内核数据或代码,这是操作系统安全与稳定性的基石。
2. 系统调用:用户态访问内核的唯一合法入口
当应用程序需要执行文件读写、进程创建、网络通信等特权操作时,必须通过系统调用向内核请求服务。系统调用是内核暴露给用户空间的唯一编程接口。
3. glibc:系统调用的用户态封装
系统调用的原始形式(如 syscall 指令直接传递系统调用号)使用不便,glibc(GNU C Library) 提供了符合 POSIX 标准的封装函数(如 open、read、write)。这些封装函数负责:
将用户参数整理为内核期望的格式
设置系统调用号
触发异常进入内核态
处理返回值并设置 errno
补充:
glibc(GNU C Library)是 Linux 系统的核心库,为操作系统和应用程序提供了关键的 API 支持,包括 ISO C11、POSIX.1-2008、BSD 等标准接口。这些接口涵盖了文件操作(如 open、read、write)、内存管理(如 malloc)、线程支持(如 pthread_create)、动态加载(如 dlopen)等功能。
4. 异常触发:从用户态到内核态的切换机制
glibc 封装的系统调用函数内部,最终通过一条软中断指令(x86 上是 syscall,ARM 上是 svc)触发 CPU 异常。CPU 响应异常后:
硬件自动切换到内核模式
根据异常向量表跳转到内核的系统调用分发例程
内核根据系统调用号查表,调用对应的内核函数(如 sys_open、sys_read)
完成后通过特定指令返回用户态,恢复进程上下文
一句话总结
用户程序 → glibc 封装函数 → syscall/svc 触发异常 → CPU 切换特权级 → 内核系统调用分发器 → 内核函数执行 → 结果返回用户态。
这个是完整流程(图片来源于韦东山)
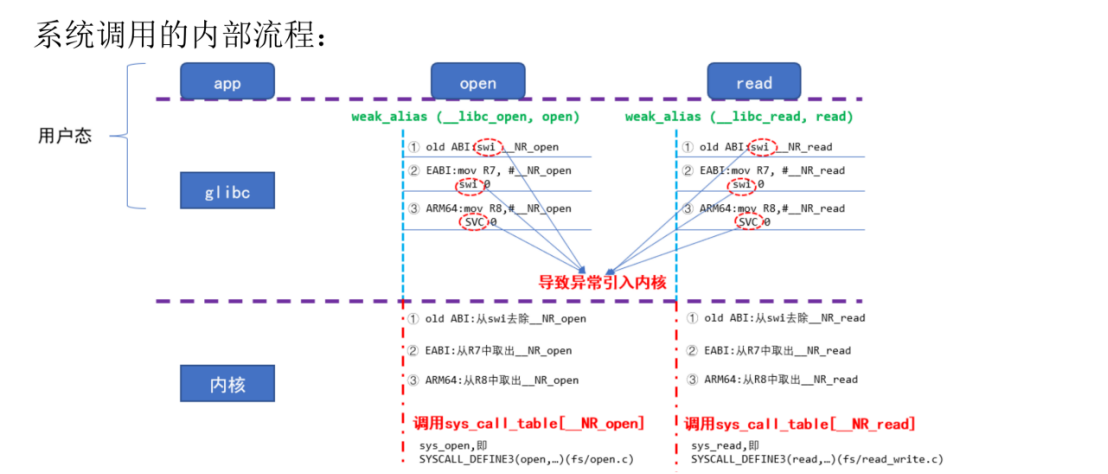
完整链路示例:
用户态 内核态
─────── ──────
app 调用 open/read
│
▼
glibc 封装函数
│
▼
设置系统调用号到寄存器
│
▼
触发异常(swi/svc)──────────► CPU切换特权级
│
▼
异常处理入口
│
▼
从寄存器取出系统调用号
│
▼
查 sys_call_table
│
▼
执行对应内核函数
sys_open / sys_read
逐层详解
第一层:APP 调用
// 示例代码
int fd = open("1.txt", O_RDWR);
int len = read(fd, buf, 1024);
这些都是 POSIX 标准函数,你直接调用,不用关心底层。
第二层:glibc 封装
// glibc 内部(简化示意)
int open(const char *pathname, int flags, mode_t mode)
{
// ... 参数整理 ...
// 调用真正的系统调用
return _libc_open(pathname, flags, mode);
}
图中的 weak_alias 是 glibc 的一个机制:
weak_alias(_libc_open, open)
意思是:open 这个符号,默认指向 _libc_open。用户如果自己定义了一个 open 函数,可以覆盖它。这是 glibc 为了灵活性做的设计,你可以暂时不管它,知道 open 最终调用的是 _libc_open 就行。
第三层:设置系统调用号 + 触发异常
这是最关键的一步。_libc_open 内部做的事情:
Assembly:
; ARM EABI 方式(如 i.MX6ULL 的 Cortex-A7)
mov r7, #NR_open ; 把 open 的系统调用号放进 r7 寄存器
swi 0 ; 触发软件中断,CPU 进入内核态
不同 ARM 架构传参方式不同:
|----------------------|-----------|--------------|
| 架构 | 传参寄存器 | 触发指令 |
| old ABI(老 ARM) | swi 指令编码里 | swi #NR_open |
| EABI(ARMv7,i.MX6ULL) | r7 | swi |
| ARM64(新板子) | r8 | svc |
old ABI:系统调用号藏在 swi 指令本身
EABI:系统调用号在 r7 寄存器里
ARM64:系统调用号在 r8 寄存器里,触发指令叫 svc 而不是 swi
第四层:异常处理入口(进入内核)
swi(或 svc)触发后,CPU 硬件自动做:
切换到内核模式(特权级)
跳转到异常向量表里预定的入口地址
内核的异常处理代码开始执行
第五层:取出系统调用号,查表分发
内核异常处理代码做的事:
// 内核里的逻辑(简化)
if (是 swi/svc 异常) {
// 从寄存器取出系统调用号
int nr = r7; // EABI 方式
// 查系统调用表,执行对应函数
sys_call_tablenr(参数...);
}
图中的 sys_call_table 是一个函数指针数组,每个系统调用号对应一个数组下标,指向内核里的实现函数:
sys_call_tableNR_open → sys_open
sys_call_tableNR_read → sys_read
sys_call_tableNR_write → sys_write
...
第六层:内核函数执行
// 内核源码 fs/open.c
SYSCALL_DEFINE3(open, const char __user *, pathname, int, flags, umode_t, mode)
{
// 拷贝用户空间路径名到内核空间
// 分配文件描述符
// 调用 VFS 层打开文件
// 返回 fd
}
// 内核源码 fs/read_write.c
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
// 根据 fd 找到文件结构体
// 调用 VFS 层读取数据
// 把数据拷贝到用户空间
// 返回读取字节数
}
SYSCALL_DEFINE3 是一个宏,3 表示这个系统调用有 3 个参数。展开后就是定义了 sys_open 和 sys_read 函数。

完整链路:
我的代码:
open("1.txt", O_RDWR)
│
▼
glibc:
_libc_open("1.txt", O_RDWR, 0)
│
▼
汇编:
mov r7, #NR_open
swi ← 触发异常,进入内核
│
▼
内核异常处理:
从 r7 取出 NR_open
│
▼
查表:
sys_call_tableNR_open
│
▼
内核函数:
sys_open() ← 真正干活的地方
│
▼
返回:
fd = 3 → 回到用户态,你的代码拿到 fd
几个缩写的解释:
|---------|------------------------------|-------------------------------|
| 缩写 | 全称 | 含义 |
| ABI | Application Binary Interface | 应用程序二进制接口,定义函数调用时参数怎么传、寄存器怎么用 |
| EABI | Embedded ABI | 嵌入式 ARM 的标准 ABI |
| swi | Software Interrupt | ARMv7 的软中断指令,用于触发系统调用 |
| svc | Supervisor Call | ARM64 的系统调用指令,和 swi 作用一样,换个名字 |
| NR_open | Number of open | open 系统调用的编号(每个系统调用都有一个唯一编号) |
一句话总结(记):
app → glibc 封装 → 触发异常 → 内核系统调用分发 → 内核函数干活 → 返回结果
接下来测试:
一个最简单的程序:

编译,后台运行,查看进程:
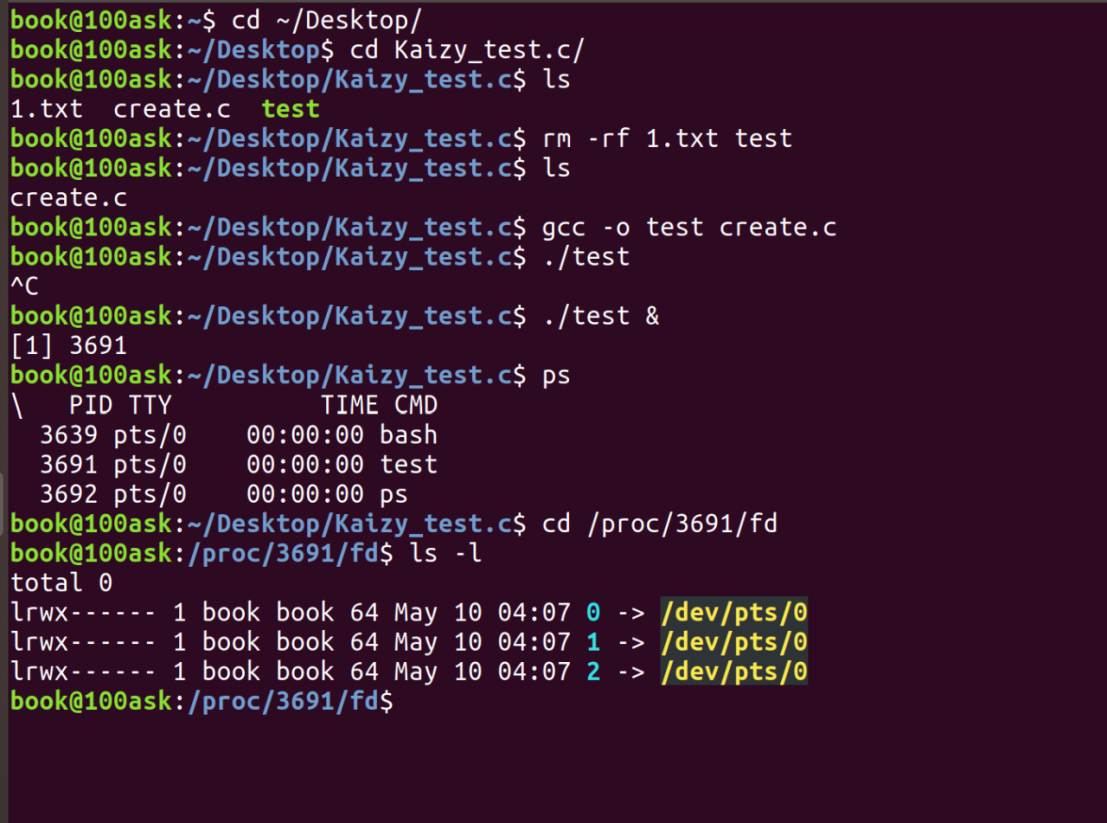
这里0,1,2:
这三个数字是 Linux 为每个进程默认打开的标准文件描述符。它们在你启动程序时由系统自动分配,分别负责输入、输出和报错。
就是我们熟知的:
0 → 标准输入 (stdin)
程序读取数据的地方。它指向 /dev/pts/0,也就是你敲命令的终端窗口。如果程序等着你键盘打字输入,就是从这个通道读取的。
1 → 标准输出 (stdout)
程序打印结果的地方。同样指向你的终端,所以你用 printf 或 std::cout 输出的内容会显示在屏幕上。
2 → 标准错误 (stderr)
程序输出错误信息的地方。也指向终端,所以错误信息默认也会打印在屏幕上。之所以和标准输出分开,是为了能单独把错误信息重定向到文件里去。
因为程序是在终端前台或者后台 (&) 启动的,系统会自动把它的输入、输出都"连接"到这个终端设备上,所以你看到它们都指向 /dev/pts/0。
若在代码里再打开一个文件:
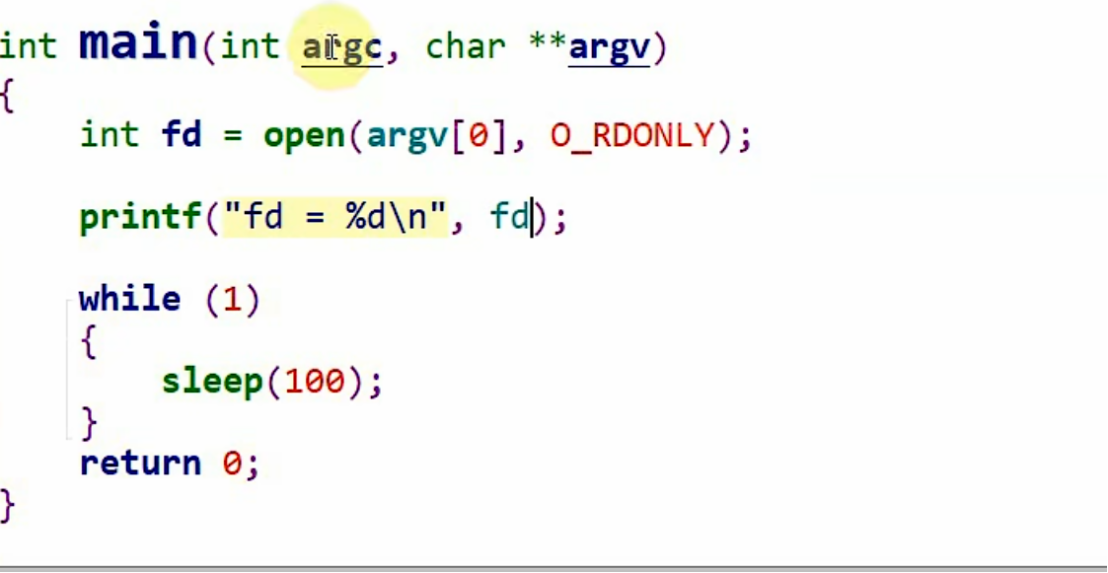
重新查看进程:

可见多了一个文件句柄,也不需要解释。
再修改代码:
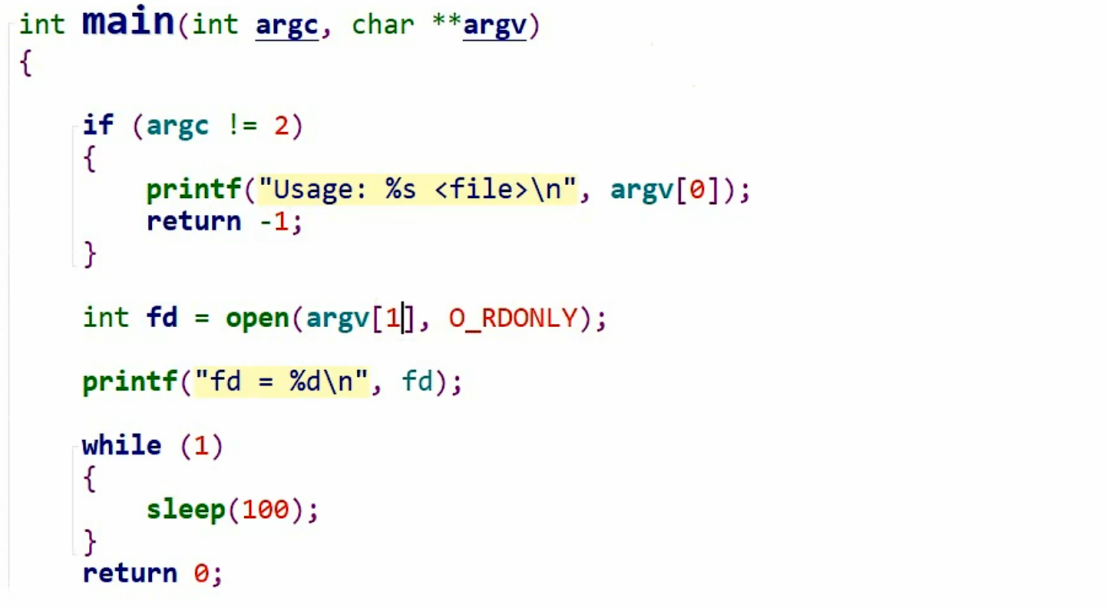
编译运行,分别打开两个文件(运行文件和源文件)(来源于韦东山):
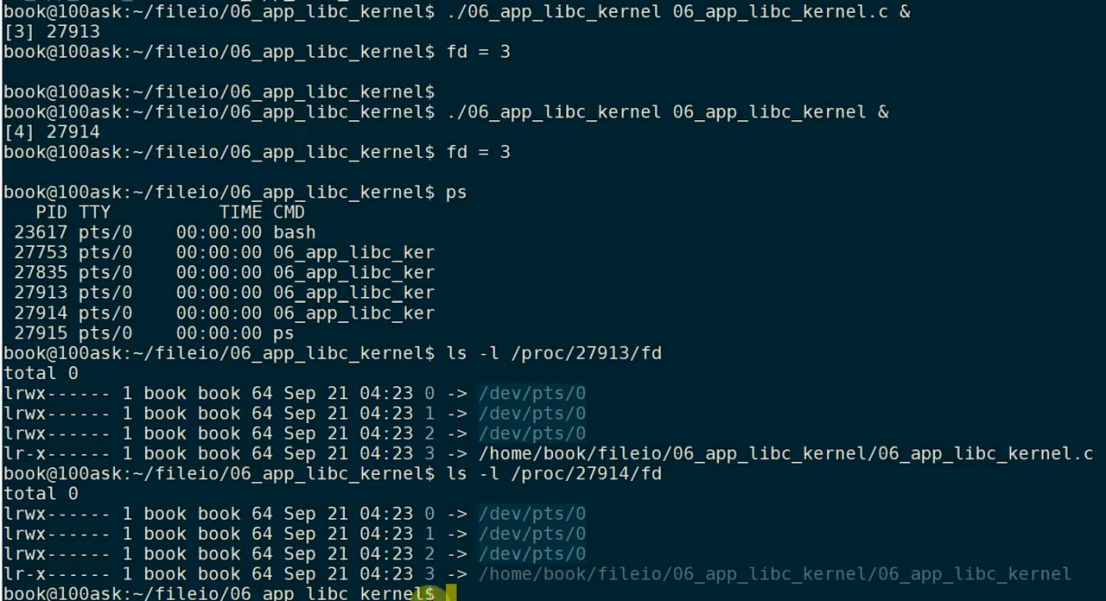
每个进程的文件句柄3,都对应着本进程打开的新文件。
说明:每个进程,都有自己的文件句柄空间。
一般来讲,想要打开fd=3,的文件,实际上是说打开某个进程fd=3的文件。
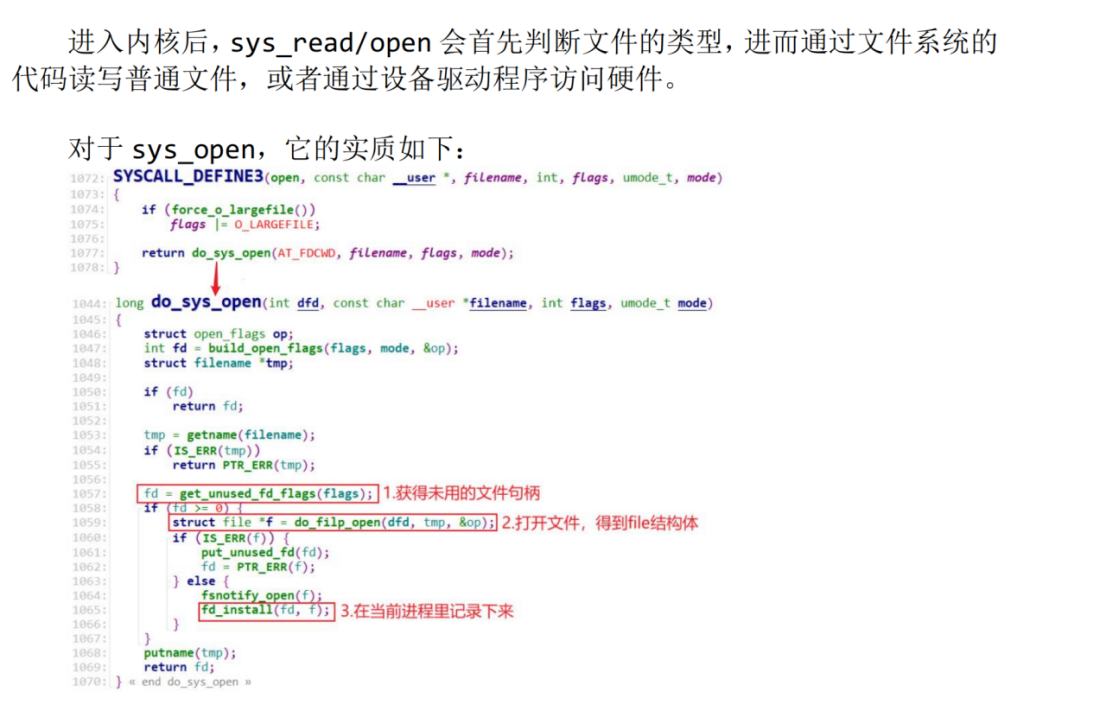
提取的代码:
cpp
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_flags op;
int fd = build_open_flags(flags, mode, &op);
struct filename *tmp;
if (fd)
{
return fd;
}
tmp = getname(filename);
if (IS_ERR(tmp))
{
return PTR_ERR(tmp);
}
fd = get_unused_fd_flags(flags); // ① 获得未用的文件句柄(描述符)
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op); // ② 打开文件,得到 file 结构体
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f); // ③ 在当前进程里记录下来(绑定 fd 和 file)
}
}
putname(tmp);
return fd;
}这个file结构体非常的复杂:
其中有一个重要的变量:
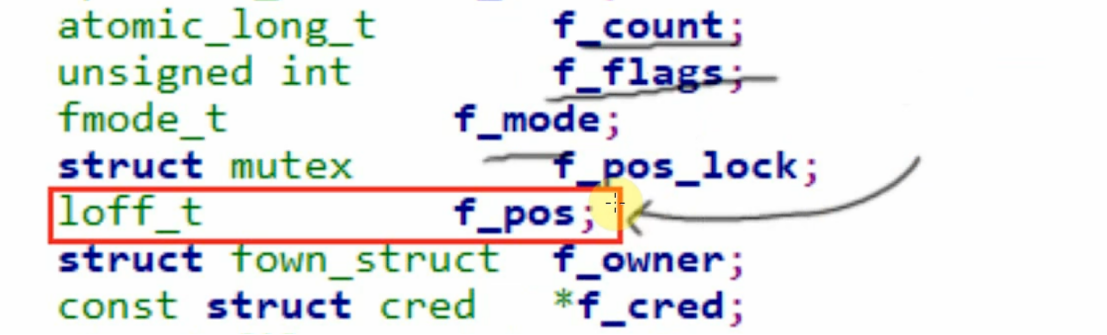
f_pos 是 struct file 结构体中的一个字段,用来记录当前文件操作的读写位置(文件偏移量)。
通俗理解
它就像一个书签,标记着"下次读/写从这个位置开始"。你之前问过 write 那张图里 POS 的自动更新,那个 POS 在内核里就是 f_pos 在管理。
它在 file 结构体里的样子
struct file {
// ...
loff_t f_pos; // loff_t 是 long long 类型,即 64 位有符号整数
// ...
};
它是怎么工作的
- 打开文件时
fd = open("1.txt", O_RDONLY);
内核创建 struct file,f_pos 初始值 = 0(从文件开头开始)。
- 读/写时自动更新
read(fd, buf, 100); // 读了 100 字节,内核自动把 f_pos += 100
read(fd, buf, 100); // 接着从 100 的位置继续读,读完 f_pos = 200
write(fd, buf, 50); // 从 200 的位置写,写完 f_pos = 250
每一次 read 或 write 成功后,内核都会把实际读写的字节数加到 f_pos 上。
- 手动改位置用 lseek
lseek(fd, 0, SEEK_SET); // 把 f_pos 设回 0,回到文件开头
lseek(fd, 100, SEEK_CUR); // f_pos 往后跳 100 字节
- 打开时加特殊标志也会影响它
fd = open("1.txt", O_RDWR | O_APPEND); // 每次写之前 f_pos 自动跳到文件末尾
fd = open("1.txt", O_RDWR | O_TRUNC); // 清空文件,f_pos 从 0 开始
一个细节:为什么 f_pos 要单独加锁(f_pos_lock)
在多线程场景下:
// 线程 A 和 B 同时用同一个 fd 读写
lseek(fd, 100, SEEK_SET); // A 线程想从 100 开始读
lseek(fd, 200, SEEK_SET); // B 线程同时把 f_pos 改成了 200
f_pos_lock 就是为了防止这种竞争,保证 lseek + read/write 是一个原子操作。
总结:f_pos 就是你文件操作的"当前位置指针",内核用它来跟踪每次读写到哪了,保证顺序读写的连贯性。
流程:(图片来源于韦东山)
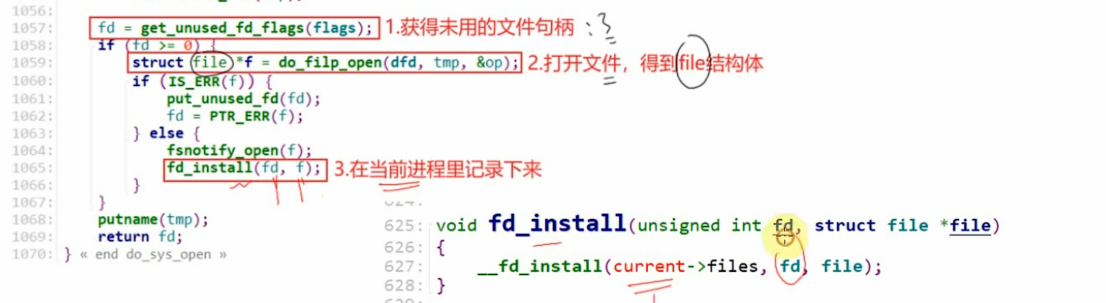
- fd_install 的实现
void fd_install(unsigned int fd, struct file *file)
{
__fd_install(current->files, fd, file);
}
拆解:
|-------------------|-------------------------------------------------------------------------------------------|
| 代码 | 含义 |
| current | 指向当前进程 的 task_struct(Linux 内核用 current 宏获取当前正在运行的进程) |
| current->files | 当前进程的文件描述符表 (struct files_struct),这个表记录了该进程打开的所有文件 |
| __fd_install(...) | 把 struct file * 存到 current->files 这个表里,索引用 fd,即 current->files->fd_arrayfd = file |
用人话说
fd_install 就是往当前进程的"文件打开记录本"里写一行:
文件描述符 fd=3 → 指向内核里的 struct file(代表"1.txt"这个已打开的文件)
这样以后你用 read(3, buf, 100) 时,内核根据 fd=3 就能立刻找到对应的 struct file,知道要读哪个文件、当前读到哪了(f_pos)、用什么权限打开的(f_mode)。
为什么必须绑定到 current->files?
因为文件描述符是进程私有的。每个进程有自己的 files_struct 表:
|------------|-------------------------------|
| 进程 | fd=3 指向 |
| 你的 test 进程 | 1.txt 的 struct file |
| 另一个进程 | 可能是 config.json,也可能根本没打开 fd=3 |
总结(图片来源于韦东山):
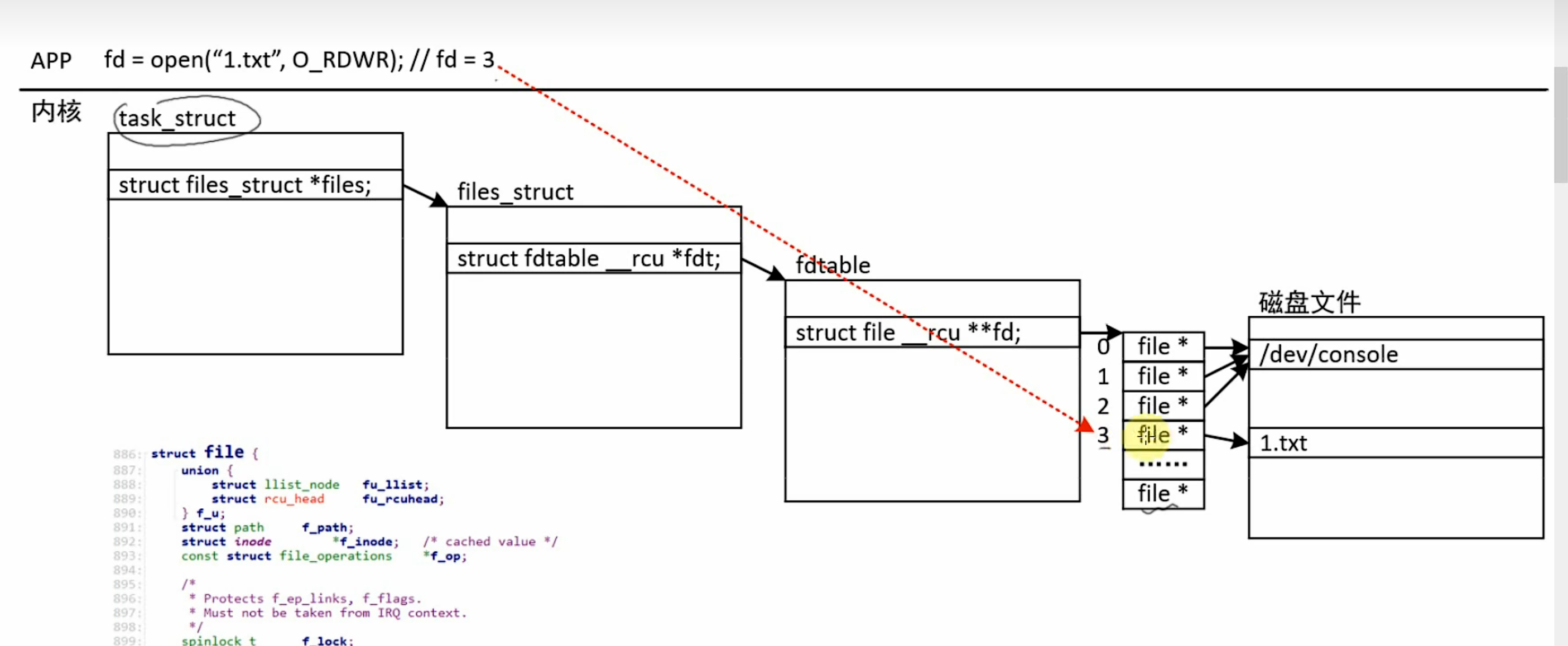
进程 task_struct
└── files (struct files_struct *)
└── fd_array\[\]
├── 0 → struct file (指向 /dev/pts/0) ← 标准输入
├── 1 → struct file (指向 /dev/pts/0) ← 标准输出
├── 2 → struct file (指向 /dev/pts/0) ← 标准错误
└── 3 → struct file (指向 1.txt) ← 你刚 open 的
│
├── f_pos = 0
├── f_mode = O_RDWR
└── ...
task_struct 是 Linux 内核中代表一个进程 的核心数据结构,用 C 语言的结构体实现。它常被称为进程控制块(PCB)。
简单来说,内核不认"进程名",只认 task_struct 。操作系统通过它来管理和调度进程,一个 task_struct 就是一个进程的"档案袋"。
这个结构体非常庞大,包含了一个进程的所有关键信息:
进程身份信息:进程ID (PID)、父进程ID (PPID)、所属用户等。
内存管理信息 :进程的代码段、数据段、堆栈在内存的哪里,即内存描述符 mm_struct。
文件系统信息 :就是我们之前讨论的 files_struct,记录进程打开了哪些文件。
调度信息:进程的优先级、时间片、运行状态等,用于 CPU 调度。
信号信息:哪些信号被阻塞、哪些信号在等待处理等。
current 是内核中的一个宏 ,在任何内核代码中,都可以通过 current 直接获取当前正在执行的进程的 task_struct。所以之前 fd_install 函数里,就是通过 current->files,找到当前进程的文件描述符表,然后把 struct file 指针存进去的。
fd_install 就是在这个 fd_array\[\] 里填上新的一格。
内部结构->从 current 到 struct file 的完整路径:
current ← 当前进程的 task_struct
└── files ← struct files_struct *(文件描述符管理器)
└── fdt ← struct fdtable *(文件描述符表指针,真正的表本体)
└── fd\[\] ← struct file * 数组(文件描述符数组)
├── 0 → struct file (stdin)
├── 1 → struct file (stdout)
├── 2 → struct file (stderr)
└── 3 → struct file (你刚 open 的文件)
fdtable 是一个可以动态扩容的结构。当一个进程打开的文件超过初始容量时,内核会分配一个更大的 fd\[\] 数组,然后让 fdt 指向新的表。files_struct 本身不用动,只换 fdt 指针就行。
调用链:
current->files // struct files_struct *
current->files->fdt // struct fdtable *
current->files->fdt->fd // struct file ** 即 fd 数组
__fd_install(current->files, fd, file) 内部实际做的是:
current->files->fdt->fdfd = file;
把 struct file * 存进这个数组的对应位置。