
主题模型(Topic Modeling)自诞生以来,一直是自然语言处理(NLP)领域中从海量文本中挖掘潜在语义结构的核心工具。从经典的潜在狄利克雷分配(LDA)到近年来基于神经网络的各种变体,其核心目标始终是发现文本中具有统计共性的"主题"。然而,这些方法在实际应用中常常暴露出一个根本性问题:它们提取出的主题虽然在统计上连贯,却往往与分析者的具体意图相去甚远,导致结果冗余、离题,甚至毫无用处。
ArXiv URL:arxiv.org/abs/2604.12...
试想一位产品经理想从用户反馈中分析"导致用户不满的具体功能点",传统主题模型可能会返回"价格、服务、物流"等宽泛主题,甚至是一些与"不满"无关的、仅仅是高频出现的词汇组合。分析师不得不耗费大量精力进行人工筛选和二次解读,才能勉强接近最初的目标。这种"我说东,你指西"的错位,极大地限制了主题模型的实用价值。
为了解决这一痛点,来自合肥工业大学、牛津大学等机构的研究者们提出了一种全新的任务范式------以人为中心的主题建模 (Human-centric Topic Modeling, Human-TM )。其核心思想是将人类分析师的具体目标(Goal)直接整合到建模过程中,从而生成更具可解释性、多样性且紧密围绕目标的"有用"主题。为了实现这一构想,他们设计了一个名为 GCTM-OT(Goal-prompted Contrastive Topic Model with Optimal Transport)的创新模型。该模型巧妙地融合了大型语言模型(LLM)的提示工程、对比学习和最优传输理论,不仅在主题连贯性和多样性上超越了现有SOTA模型,更在与人类目标的对齐度上取得了显著提升,为构建真正"心领神会"的主题发现系统铺平了道路。
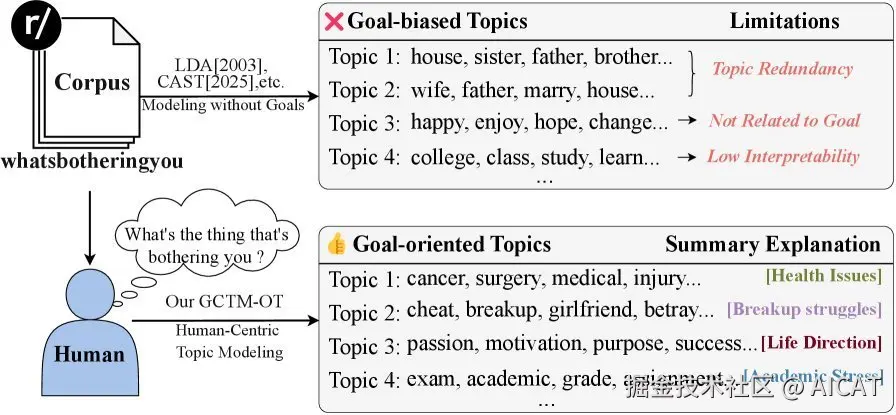
上图直观地展示了传统主题模型与 Human-TM 的核心区别。面对"什么事在困扰你?"这一人类目标,传统模型可能因词频统计而产生"房子、姐妹、父亲"或"开心、享受、希望"这类统计上相关但与"困扰"无关的主题。而 Human-TM 则能精准地识别出"分手困扰"、"健康问题"、"学业压力"等真正切题的答案。
GCTM-OT:五步协同,将人类目标注入主题发现
GCTM-OT 的整体框架设计精妙,可以看作一个五部分协同工作的系统,其最终目的是将抽象的人类目标转化为对主题学习过程的有效约束。
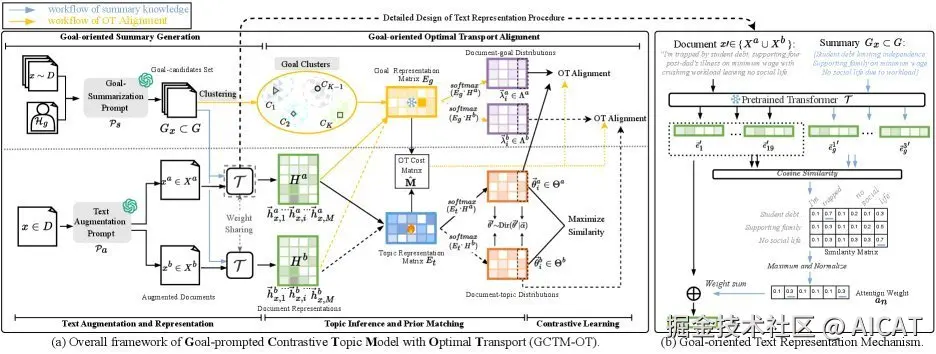
如上图所示,整个流程从左上角的"目标导向的摘要生成"开始,到右上角的"目标导向的最优传输对齐"结束,形成了一个完整的闭环,确保最终产出的主题与初始目标高度一致。
1. 目标导向的摘要生成:用 LLM 锁定"靶心"
模型的第一步,也是"目标提示"(Goal-prompted)的核心所在,是利用 LLM 从每一篇文档中提取与人类目标 H_g 相关的候选短语。研究者设计了一种目标摘要提示 (Goal-summarization Prompt, P_s),引导 LLM 阅读每篇文档,并根据给定的目标生成3到5个关键短语作为该文档的"目标候选集" G_x。

例如,如果目标是"特斯拉 Model 3 的哪些方面受到关注?",LLM 就会从一篇讨论充电体验的帖子中抽取出"充电速度"、"续航里程焦虑"等短语。如果一篇文档与目标完全无关,LLM 会将其标记为"irrelevant"并排除。通过这种方式,模型首先就将后续分析的范围牢牢锁定在与目标相关的语料上,完成了第一层过滤和聚焦。所有文档的目标候选短语最终汇集成一个语料库级别的目标集 G。
2. 文本增强与表征:构建面向目标的文档视图
为了让模型学习到更鲁棒和泛化的特征,对比学习(Contrastive Learning)通常需要对输入数据进行增强,即为同一份数据创建两个语义相似但形式不同的"视图"。传统方法如随机删除或替换词语,容易破坏文本的核心语义。
GCTM-OT 再次借助 LLM,使用一种文本增强提示 (Text Augmentation Prompt, P_a)来生成语义一致的增强文本对 (xa,xb)。更关键的一步在于如何生成面向目标 的文档表征。模型首先使用预训练的 Transformer(如 MPNet)获取文档中每个词的上下文嵌入。然后,它计算每个词的嵌入与该文档的目标候选集 G_x 中所有短语嵌入的最大余弦相似度。这个相似度得分被用作注意力权重,对所有词的嵌入进行加权求和,最终得到一个融合了目标信息的文档表征 h x。
{x}= \sum\nolimits\{n=1}^{N\{x}^{\prime}}\hat{a}\{n}\cdot\vec{e}^{\prime}\_{n} h ′_x=∑_n=1N_x′a^_n⋅e ′_n
这个过程相当于让模型在阅读文档时,对那些与"目标"更相关的词汇给予更高的关注,从而生成的文档表征 h a 和 h b 天然地偏向于分析者关心的维度。
3. 主题推断与先验匹配:塑造可解释的主题分布
得到面向目标的文档表征后,模型需要将其映射到一个 K 维的主题分布 θ 上。GCTM-OT 维护一个可训练的主题表征矩阵 E_t,其中每一行 e _tk 代表一个主题的向量。文档的主题分布通过计算其表征 h 与所有主题表征的余弦相似度,并经过 softmax 归一化得到。
θ a=softmax(cos(h a,e _t1),...,cos(h a,e _tK))
为了提升主题的可解释性,研究者还引入了先验匹配机制。他们将一批文档的主题分布 Θ 与从狄利克雷先验(Dirichlet prior)中采样的分布 Θ′ 进行匹配,通过最小化两者之间的最大均值差异(MMD)损失 L_PM,鼓励模型学习到的主题分布具有狄利克雷分布那样的稀疏、多峰特性。这有助于让每个文档聚焦于少数几个主题,从而使主题的边界更清晰。
4. 语义感知的对比学习:区分并聚合语义模式
这是模型学习的核心驱动力之一。对比学习的目标是"拉近相似的,推远不相似的"。在这里,"相似的"是一对增强文档 (xa,xb) 对应的主题分布 (θ a,θ b),它们应该被拉近。而"不相似的"则是来自不同原始文档的任意两个主题分布。
GCTM-OT 采用了一种语义感知 的策略。在计算对比损失 L_c 时,它不仅仅将同一批次内的其他所有文档都视为负样本,还会额外增加一个判断条件:只有当两个不同文档的原始表征(通过 Transformer T^ 得到)的余弦相似度低于某个阈值 δ 时,才将它们视为有效的负样本。这避免了将语义上本就相近的文档错误地推开,使得对比学习更加关注于区分真正不同的语义簇,从而有助于形成多样性更好的主题。
5. 目标导向的最优传输对齐:实现主题与目标的终极对齐
尽管前面的步骤已经将目标信息融入了文档表征,但这仍是一种间接的引导。为了实现更直接、更强力的对齐,GCTM-OT 引入了最优传输(Optimal Transport, OT)理论,这也是该模型最具创新性的部分之一。
最优传输可以通俗地理解为计算将一堆"沙子"(一个概率分布)以最小的"搬运成本"变成另一堆"沙子"(另一个概率分布)的方案。在这里,模型要做的就是以最小的代价,将学习到的文档-主题分布 θ "搬运"成一个预设的文档-目标分布 λ 。
这个"目标分布" λ 是如何构建的呢?
-
首先,模型将第一步收集到的整个语料库的目标候选集 G 进行聚类(例如使用 KMeans),得到 K 个目标簇 C_k。每个簇的中心向量 e gk 就构成了一个目标表征矩阵 {g} E_g。这相当于把零散的目标短语归纳成了 K 个核心目标方向。
-
然后,对于每个文档,其文档-目标分布 λ 通过计算其表征 h 与 K 个目标中心向量的相似度得到。
有了文档-主题分布 θ 和文档-目标分布 λ ,最优传输损失 L_OT 就开始发挥作用。它计算将 θ 变换为 λ 的最小"成本"。这里的"成本"矩阵 M^ 定义为任意一个主题 ti 和一个目标 gj 之间的语义距离(即 1−cos(e _ti,e _gj))。通过最小化这个最优传输距离,模型被强制要求学习到的主题表征 Et 必须在语义空间上与目标表征 Eg 对齐。这不仅保证了主题与目标的强相关性,也因为目标簇本身是多样化的,从而自然地促进了主题的多样性。
最终,模型的总训练目标函数由三部分构成:
L=L_c+ηL_PM+ζL_OT
其中 L_c 是对比学习损失,负责学习有区分度的语义表征; L_PM 是先验匹配损失,用于提升主题可解释性;而 L_OT 则是最优传输损失,是确保主题与人类目标对齐的关键。
实验结果:不仅做得好,而且"说得对"
研究者在三个来自 Reddit 的公开数据集(Bothering 、TeslaModel3 、AskAcademia)上对 GCTM-OT 进行了全面评估。这些数据集富含真实世界的用户生成内容,是检验模型在嘈杂环境中表现的理想选择。
全面超越的性能指标
评估分为两部分:传统的主题质量 (连贯性与多样性)和创新的目标相关性。
-
主题质量:在主题连贯性指标(如 NPMI, UCI)和多样性指标(UT)上,GCTM-OT 在绝大多数配置下都优于包括 CAST、LLM-ITL 在内的 SOTA 基线模型。这得益于其语义感知的对比学习机制和最优传输带来的多样性增益。
-
目标相关性:为了衡量模型是否真的实现了"以人为中心",研究者提出了三个新颖的评价指标:
-
目标相似度 (Goal Similarity, GS): 衡量生成的主题与一组"黄金标准"目标候选词的平均最大相似度。
-
目标相关主题率 (Goal-relevant Topic Rate, GTR): 计算生成的主题中,与目标足够相关(相似度超过阈值)的比例。
-
目标覆盖率 (Goal Coverage Rate, GCR): 衡量所有"黄金标准"目标候选词中,有多大比例被生成的主题所覆盖。
-
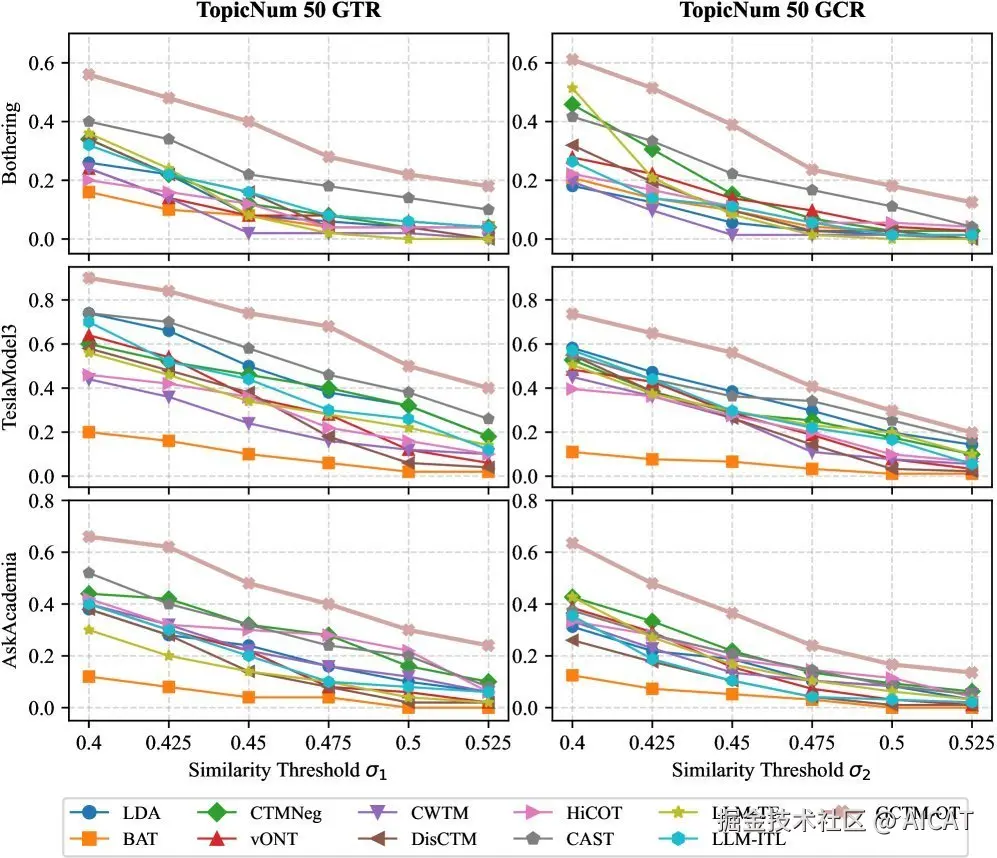
实验结果令人信服。如上图所示,在衡量目标对齐度的关键指标 GTR 和 GCR 上,GCTM-OT 相比其他所有模型都表现出压倒性的优势。这直接证明了通过目标提示和最优传输对齐,模型确实学会了生成与用户意图高度一致的主题。
直观可感的案例分析
除了冰冷的数字,定性分析更能体现 GCTM-OT 的价值。在 Bothering 数据集上,当目标是"什么事在困扰你?"时,GCTM-OT 能够生成诸如"分手困扰"、"健康问题"、"财务压力"等高度概括且切题的主题。更重要的是,它还能为每个主题自动生成一个可读的短语摘要(例如为"分手困扰"主题生成"breakup struggle"),这是通过寻找与该主题向量最接近的目标簇候选词实现的。相比之下,传统模型如 LDA 生成的主题关键词则显得杂乱无章,缺乏明确指向。
总结与启示
GCTM-OT 的提出,标志着主题建模领域一次重要的范式转移。它不再满足于对文本进行无监督的、纯粹统计意义上的模式发现,而是开创性地将人类的分析意图作为核心输入,构建了一个以人为中心的主题建模(Human-TM)框架。
通过巧妙地融合 LLM 提示工程、对比学习和最优传输理论,GCTM-OT 成功地解决了传统主题模型"答非所问"的顽疾。它不仅在技术上实现了创新------特别是利用最优传输来直接对齐主题空间和目标空间------更在应用层面上极大地提升了主题模型的实用价值。分析师不再需要从大量无关结果中"淘金",而是可以直接获得针对其特定问题的高度相关的洞察。
这项工作为未来的信息抽取和知识发现指明了一个重要方向:让人类专家的领域知识和分析目标更深入地参与到模型的学习过程中,而不是仅仅停留在后处理阶段。正如论文所展望的,未来可以进一步探索层次化的 Human-TM,从而能够根据人类目标生成结构化的主题层级,为复杂文本的深度分析提供更强大的工具。