上一篇创建环境和代码框架基础可以见《ROS2+Gazebo+VLA占位服务:纯仿真环境下的具身智能闭环实现》(https://blog.csdn.net/weixin_55221858/article/details/156659624),本次把占位服务替换为VLM服务,读者有能力的话也可以自己训练能直接输出动作的VLA模型,实现真正的VLA端到端服务。
系统概述
本系统是一个分布式具身智能控制系统,采用"大脑-小脑"分层架构,实现视觉语言模型推理与实时机器人控制的分离。
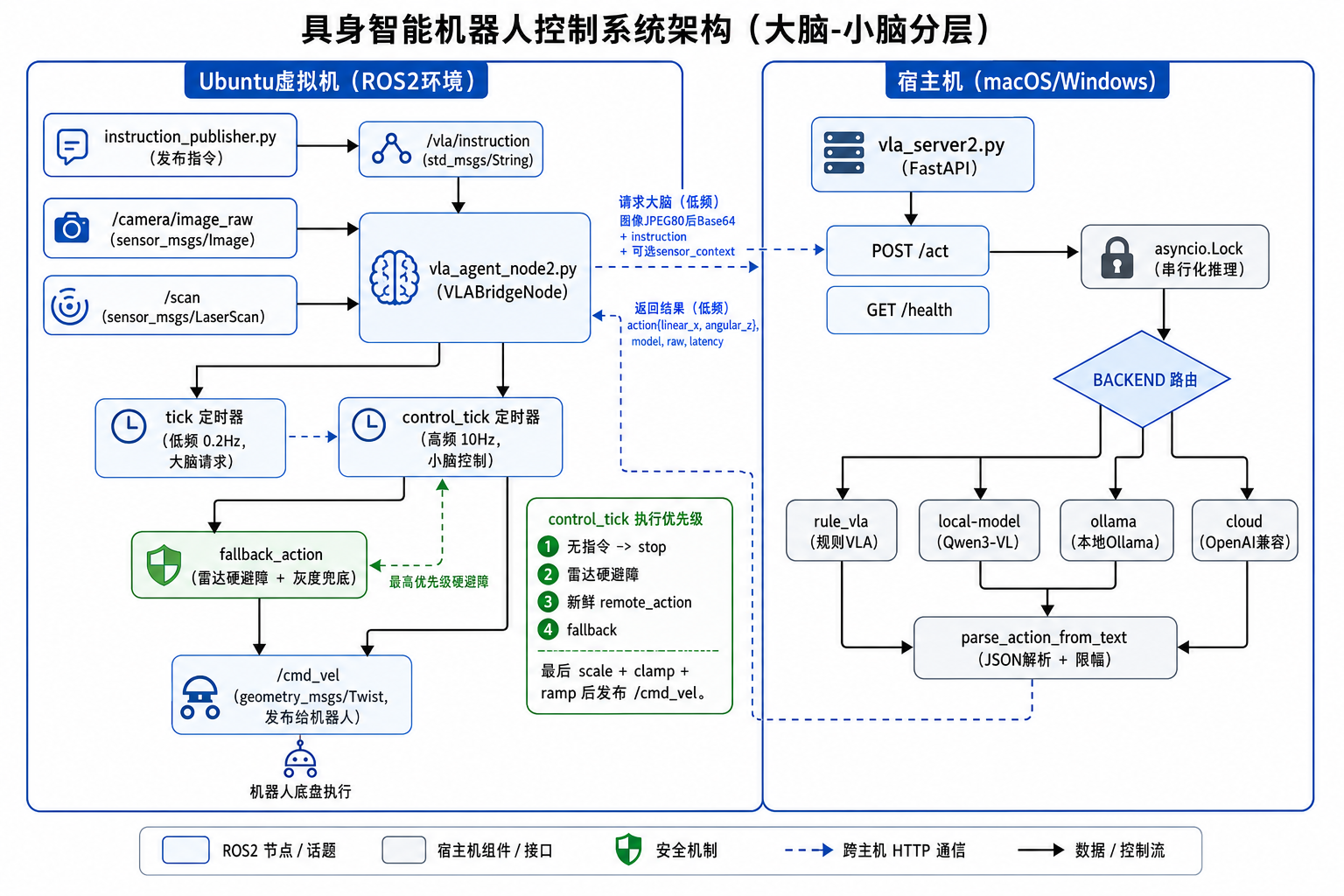
运行环境
-
宿主机 (macOS/Windows): 运行VLM/VLA推理服务器
-
Ubuntu虚拟机: 运行ROS2节点和机器人控制
控制流程
1. 指令发布流程
instruction_publisher.py
↓ 发布String消息
/vla/instruction 话题
↓ 订阅
vla_agent_node2.py (on_instruction回调)
↓ 更新 latest_instruction2. 推理请求流程
vla_agent_node2.py (tick定时器)
↓ 检查: 有指令? 有图像? 请求未进行中?
↓ 图像编码为Base64
↓ 构造请求 payload
↓ HTTP POST 到 vla_server2.py
↓ 解析响应,缓存 remote_action3. 运动控制流程
vla_agent_node2.py (control_tick定时器)
↓ 优先级判断:
│
├─ 无指令? → 发布停止 (0,0)
│
├─ 雷达硬避障? → 使用本地避障动作
│
├─ 大脑动作新鲜? → 使用 remote_action
│
└─ 否则 → 使用 fallback_action (慢速前进)
↓
scale + clamp + ramp (加速度平滑)
↓
发布 Twist 到 /cmd_vel安全机制设计
1. 多层安全保护
最高优先级: 雷达硬避障
↓ 永远不被大脑覆盖
↓ 前方距离 < obstacle_dist (默认0.4m)
↓ 立即转向,选择更安全的方向
次优先级: 大脑指令
↓ 需要满足:
│ - remote_action 不为 None
│ - 动作年龄 < remote_fresh_s
│ - 雷达未触发硬避障
最低优先级: 本地fallback
↓ 默认慢速前进 (0.15 m/s)
↓ 灰度图像简单避障2. 容错机制
-
请求失败退避: 失败后1秒内不重试
-
动作新鲜度检查: 过期动作自动丢弃
-
单飞机制: 防止并发请求堆积
-
图像过期检查: 超过8秒的图像不使用
3. 运动平滑
# 速度限幅
lin = clamp(lin, -max_lin, max_lin)
ang = clamp(ang, -max_ang, max_ang)
# 加速度限制 (ramp)
step = accel * dt
lin = clamp(lin, last_lin - step, last_lin + step)通信协议
1. ROS2话题
| 话题名 | 消息类型 | 方向 | 说明 |
|---|---|---|---|
/camera/image_raw |
sensor_msgs/Image |
订阅 | 相机原始图像 |
/vla/instruction |
std_msgs/String |
订阅 | 控制指令文本 |
/scan |
sensor_msgs/LaserScan |
订阅 | 激光雷达数据 |
/cmd_vel |
geometry_msgs/Twist |
发布 | 运动速度指令 |
2. HTTP API
-
端点 :
POST /act -
超时: 可配置 (默认25秒)
-
重试: 失败后退避1秒
3. 数据格式
图像传输:
-
ROS Image → OpenCV Mat → JPEG编码 → Base64字符串
-
JPEG质量: 80 (平衡大小和质量)
动作输出:
{
"linear_x": 0.5, // 线速度 (m/s), 范围 [-5.5, 5.5]
"angular_z": -0.2 // 角速度 (rad/s), 范围 [-2.5, 2.5]
}性能优化
1. 频率分离设计
-
大脑请求: 0.2Hz (5秒/次) - 低频,减少计算负载
-
小脑控制: 10Hz (100ms/次) - 高频,保证实时性
2. 异步解耦
-
大脑和小脑独立运行
-
大脑失败不影响小脑避障
-
动作缓存机制减少等待
3. 资源管理
-
图像编码压缩 (JPEG 80%质量)
-
传感器数据摘要 (减少传输量)
-
请求超时控制
扩展性设计
1. 推理后端扩展
-
支持多种VLM模型
-
可配置的推理参数
-
环境变量和命令行配置
2. 传感器融合
-
支持激光雷达数据
-
可扩展其他传感器
-
传感器上下文传递给VLM
3. 控制策略扩展
-
可调整的安全阈值
-
可配置的控制频率
-
可修改的运动限制
调试与监控
1. 日志输出
-
图像MD5校验
-
动作解析结果
-
延迟统计
-
优先级决策日志
2. 健康检查
GET /health返回服务器状态和后端信息。
启动VLM服务
vla_server2.py参考如下,可切换云端/本地/ollama模型,算力不足建议用云端模型避免程序卡顿或崩溃,如果不打算消耗token或算力足够可以用本地模型,模型参数如温度、超时等、提示词和是否接受激光雷达传感器的数据可以根据需要调整。云端模型需要填自己的Base URL和API KEY,本地模型/ollama模型以实际路径和名称为准,如果是直接加载其他本地模型可能需要改函数,甚至自行做个本地服务API服务,然后在代码将其当作云端模型调用
python
import hashlib
import os
import re
import json
import time
import base64
import tempfile
import asyncio
import argparse
from pathlib import Path
from typing import Any, Dict, Optional, Tuple
import cv2
import numpy as np
import requests
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
import uvicorn
id=1
# =============== 可选:本地 Transformers Qwen3-VL ===============
LOCAL_VLM_AVAILABLE = False
try:
import torch
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
LOCAL_VLM_AVAILABLE = True
except Exception:
LOCAL_VLM_AVAILABLE = False
# -------------------- 配置 --------------------
BACKEND = os.getenv("VLA_BACKEND", "cloud").strip().lower()
# BACKEND: "rule" | "local-model" | "ollama" | "cloud"
# local-model 配置
LOCAL_MODEL_DIR = os.getenv("LOCAL_MODEL_DIR", r"../model/Qwen3-VL-2B-Instruct")
LOCAL_MAX_NEW_TOKENS = int(os.getenv("LOCAL_MAX_NEW_TOKENS", "64"))#128
LOCAL_TOP_P = float(os.getenv("LOCAL_TOP_P", "0.9"))#0.8 # 仅选择累计概率80%的token
LOCAL_TEMPERATURE = float(os.getenv("LOCAL_TEMPERATURE", "0.7"))#0.2 极低温度,压缩概率分布
# ollama 配置
OLLAMA_URL = os.getenv("OLLAMA_URL", "http://127.0.0.1:11434").rstrip("/")
OLLAMA_MODEL = os.getenv("OLLAMA_MODEL", "qwen2.5vl") # 需要是支持图像输入的模型
OLLAMA_TIMEOUT_S = float(os.getenv("OLLAMA_TIMEOUT_S", "20"))
# cloud 配置(兼容 OpenAI 风格的 Chat Completions 接口)
CLOUD_BASE_URL = os.getenv(
"CLOUD_BASE_URL",
os.getenv("MIMO_BASE_URL", ""),
).rstrip("/")
CLOUD_API_KEY = os.getenv(
"CLOUD_API_KEY",
os.getenv("MIMO_API_KEY", ""),
)
CLOUD_MODEL = os.getenv(
"CLOUD_MODEL", os.getenv("MIMO_MODEL", "mimo-v2.5")
)
CLOUD_TIMEOUT_S = float(os.getenv("CLOUD_TIMEOUT_S", "30"))
CLOUD_MAX_TOKENS = int(os.getenv("CLOUD_MAX_TOKENS", "1024"))
CLOUD_TEMPERATURE = float(os.getenv("CLOUD_TEMPERATURE", "0.2"))
# 速度/安全限制:Twist 范围(可按需要调)
MAX_LIN = float(os.getenv("VLA_MAX_LIN", "5.5"))
MAX_ANG = float(os.getenv("VLA_MAX_ANG", "2.5"))
# -------------------- FastAPI --------------------
app = FastAPI(title="VLA Server (rule/local-model/ollama/cloud)")
class ActRequest(BaseModel):
instruction: str
image_b64: str
timestamp: Optional[float] = None
# 可选:由ROS侧上报的传感器摘要(如激光雷达压缩信息),用于增强决策输入
sensor_context: Optional[Dict[str, Any]] = None
def clamp(x: float, lo: float, hi: float) -> float:
return max(lo, min(hi, x))
def decode_image_b64_to_bgr(image_b64: str) -> np.ndarray:
raw = base64.b64decode(image_b64.encode("utf-8"))
buf = np.frombuffer(raw, dtype=np.uint8)
img = cv2.imdecode(buf, cv2.IMREAD_COLOR)
if img is None:
raise ValueError("cv2.imdecode failed")
return img
# -------------------- 1) rule 后端 --------------------
def rule_vla(instruction: str, image_bgr: np.ndarray) -> Dict[str, Any]:
t = (instruction or "").lower()
if "stop" in t or "halt" in t:
return {"linear_x": 0.0, "angular_z": 0.0}
if "left" in t:
return {"linear_x": 0.0, "angular_z": +0.8}
if "right" in t:
return {"linear_x": 0.0, "angular_z": -0.8}
if "back" in t:
return {"linear_x": -0.15, "angular_z": 0.0}
# 简单"明暗避障"
gray = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY)
center = gray[
gray.shape[0] // 3 : 2 * gray.shape[0] // 3,
gray.shape[1] // 3 : 2 * gray.shape[1] // 3,
]
mean_intensity = float(np.mean(center))
if mean_intensity < 60:
return {"linear_x": 0.0, "angular_z": 0.9}
return {"linear_x": 0.20, "angular_z": 0.0}
# -------------------- VLM 输出 -> action 解析 --------------------
_JSON_RE = re.compile(r"\{[\s\S]*\}")
def parse_action_from_text(text: str) -> Optional[Dict[str, float]]:
"""
期望模型输出 JSON:
{"linear_x": 0.1, "angular_z": -0.2}
容错:从文本里抓第一个 {...} 解析。失败返回 None。
"""
if not text:
return None
m = _JSON_RE.search(text)
if not m:
return None
try:
obj = json.loads(m.group(0))
lin = float(obj.get("linear_x", 0.0))
ang = float(obj.get("angular_z", 0.0))
# 限幅,避免模型发疯
lin = clamp(lin, -MAX_LIN, MAX_LIN)
ang = clamp(ang, -MAX_ANG, MAX_ANG)
return {"linear_x": lin, "angular_z": ang}
except (json.JSONDecodeError, ValueError, TypeError):
return None
def build_action_prompt(instruction: str, sensor_context: Optional[Dict[str, Any]] = None) -> str:
# 强制 JSON-only 输出:这是把"VLM 文本"变成"动作"的关键
# return (
# "You are a robot control policy. "
# "Given the user's instruction and the image, output ONLY a JSON object.\n"
# "JSON schema:\n"
# '{ "linear_x": number, "angular_z": number }\n'
# f"Constraints: linear_x in [-{MAX_LIN}, {MAX_LIN}], angular_z in [-{MAX_ANG}, {MAX_ANG}].\n"
# "No extra text.\n"
# f"Instruction: {instruction}\n"
# )
# 通用机器人视觉控制,核心转弯/退后避障
return (
"You are a robot motion control policy for a differential-drive robot.\n"
"Given a front-view camera image and the user instruction, output ONLY ONE JSON object:\n"
'{"linear_x":<number>,"angular_z":<number>}\n\n'
"### PRIMARY GOAL (highest priority)\n"
"- Treat a WHITE CYLINDER (bright white circular/oval pillar) as the TARGET.\n"
"- If the target is visible: approach it safely.\n"
"- When the target is very close (it touches the bottom edge OR occupies a large area in the lower center), STOP.\n\n"
"### Target detection rules (use IMAGE cues)\n"
"- Target is a bright white cylinder: a white circular/oval blob with smooth boundary.\n"
"- Estimate horizontal error by target position:\n"
" * target left of center -> turn left (angular_z > 0)\n"
" * target right of center -> turn right (angular_z < 0)\n"
" * target near center -> go straight (angular_z ~= 0)\n"
"- Estimate closeness by size/vertical position:\n"
" * small and high in image -> far\n"
" * large and low in image -> close\n"
" * touches bottom edge / very large in lower center -> reached\n\n"
"### Target pursuit control (MUST follow if target visible)\n"
f"- Output ranges: linear_x in [-{MAX_LIN}, {MAX_LIN}], angular_z in [-{MAX_ANG}, {MAX_ANG}]\n"
"- If target reached (very close): linear_x=0.0 and angular_z=0.0\n"
"- Else if target visible but not centered:\n"
" * far: linear_x in [2.0,3.0], angular_z in [+0.8,+1.6] (if target left) or [-1.6,-0.8] (if target right)\n"
" * close: linear_x in [0.8,1.6], angular_z in [+0.6,+1.2] or [-1.2,-0.6]\n"
"- Else if target visible and centered:\n"
" * far: linear_x in [3.0,4.5], angular_z=0.0\n"
" * close: linear_x in [1.0,2.0], angular_z=0.0\n\n"
"### SAFETY OVERRIDE\n"
"- If a wall/obstacle touches the bottom edge in the center and blocks motion, avoid collision even if target visible.\n"
"- If collision imminent: set linear_x=0.0 and turn in place with angular_z in [+1.2,+1.8] or [-1.8,-1.2].\n\n"
"### Fallback navigation (use ONLY if target NOT visible)\n"
"### Distance & Geometry Rules (CRITICAL)\n"
"- Objects that appear LOWER in the image are CLOSER to the robot.\n"
"- Larger image area (higher pixel coverage) usually means the object is CLOSER.\n"
"- If walls/objects touch the bottom edge, treat as CENTER_CLOSE.\n"
"- If large regions enter from the bottom corners, treat as CENTER_CLOSE (near a corner).\n\n"
"### Step 1: Decide the scene category from the IMAGE (must choose ONE)\n"
"A) CENTER_CLOSE: obstacle/wall touches the bottom edge or occupies the lower half\n"
"B) CENTER_FAR: obstacle exists in the center but still has distance (can steer around)\n"
"C) LEFT_MORE_OPEN: left side is more open than right side\n"
"D) RIGHT_MORE_OPEN: right side is more open than left side\n"
"E) CLEAR: center and both sides look open (safe to go forward)\n"
"F) UNCERTAIN: cannot judge (blur/dark/ambiguous)\n\n"
"### Step 2: Map category to motion (must follow exactly)\n"
"- CENTER_CLOSE: choose ONE of:\n"
" * turn in place: linear_x=0.0 and angular_z in [+1.2,+1.8] or [-1.2,-1.8]\n"
" * or back up: linear_x in [-0.6,-1.2] and angular_z in [-0.6,+0.6]\n"
"- CENTER_FAR: DO NOT STOP. steer around while moving forward:\n"
" * linear_x in [1.6,2.8], angular_z in [+0.6,+1.2] OR [-1.2,-0.6]\n"
"- LEFT_MORE_OPEN: linear_x in [2.0,3.2], angular_z in [+0.6,+1.4]\n"
"- RIGHT_MORE_OPEN: linear_x in [2.0,3.2], angular_z in [-1.4,-0.6]\n"
"- CLEAR: linear_x in [3.0,4.5], angular_z=0.0\n"
"- UNCERTAIN: move slowly and search (do not output 0,0):\n"
" * linear_x in [0.8,1.6], angular_z in [-0.6,+0.6]\n\n"
"### Instruction following (apply after safety)\n"
"- If instruction says STOP/HALT, output linear_x=0.0 and angular_z=0.0.\n\n"
"### Strict output requirement\n"
"Output ONLY a single valid JSON object, no extra text.\n\n"
f"### User instruction\n{instruction}\n"
)
if sensor_context:
sensor_block = json.dumps(sensor_context, ensure_ascii=False, separators=(",", ":"))
# 可选上下文以 JSON 字符串形式附加到提示词,便于模型做"视觉+传感器"联合判断
return (
prompt
+ "\n### SENSOR CONTEXT (optional)\n"
+ "Use instruction, image, and this sensor context jointly for action planning.\n"
+ f"{sensor_block}\n"
)
return prompt
# -------------------- 2) local-model 后端 --------------------
def get_device() -> "torch.device":
# 宿主机 macOS:优先 MPS;Linux VM 通常没有 MPS
if torch.backends.mps.is_available():
return torch.device("mps")
if torch.cuda.is_available():
return torch.device("cuda")
return torch.device("cpu")
def local_model_infer(prompt: str, image_bytes: bytes) -> str:
"""
用 temp 文件喂给 Qwen3-VL 的 processor(原代码使用 image_path)
"""
suffix = ".jpg"
tmp_dir = Path(tempfile.gettempdir()) / "vla_upload"
tmp_dir.mkdir(parents=True, exist_ok=True)
tmp_path = tmp_dir / f"vla_{int(time.time()*1000)}{suffix}"
tmp_path.write_bytes(image_bytes)
try:
content = [{"type": "image", "image": str(tmp_path)}, {"type": "text", "text": prompt}]
messages = [{"role": "user", "content": content}]
inputs = app.state.processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
)
inputs = inputs.to(app.state.device)
with torch.no_grad():
generated_ids = app.state.model.generate(
**inputs,
max_new_tokens=LOCAL_MAX_NEW_TOKENS,
do_sample=(LOCAL_TEMPERATURE > 0),
top_p=LOCAL_TOP_P,
temperature=LOCAL_TEMPERATURE,
)
input_ids = inputs["input_ids"]
new_token_ids = [out_ids[len(in_ids):] for in_ids, out_ids in zip(input_ids, generated_ids)]
out_text = app.state.processor.batch_decode(
new_token_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False,
)[0]
return out_text
finally:
try:
tmp_path.unlink(missing_ok=True)
except Exception:
pass
# -------------------- 3) ollama 后端 --------------------
def ollama_infer(prompt: str, image_b64: str) -> str:
"""
使用 /api/generate:支持 images: [base64],并支持 format=json 结构化输出 :contentReference[oaicite:1]{index=1}
"""
url = f"{OLLAMA_URL}/api/generate"
payload = {
"model": OLLAMA_MODEL,
"prompt": prompt,
"images": [image_b64], # base64 数组 :contentReference[oaicite:2]{index=2}
"stream": False,
"format": "json", # 让输出是合法 JSON :contentReference[oaicite:3]{index=3}
}
r = requests.post(url, json=payload, timeout=OLLAMA_TIMEOUT_S)
r.raise_for_status()
data = r.json()
# /api/generate 在非流式时一般返回 {"response": "...", "done": true, ...} :contentReference[oaicite:4]{index=4}
return data.get("response", "")
# -------------------- 4) cloud 后端 --------------------
def cloud_infer(prompt: str, image_b64: str) -> str:
# 使用 OpenAI 风格的 chat/completions 接口发起图文推理
url = f"{CLOUD_BASE_URL}/chat/completions"
headers = {
"Authorization": f"Bearer {CLOUD_API_KEY}",
"Content-Type": "application/json",
}
payload = {
"model": CLOUD_MODEL,
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"},
},
],
}
],
"max_tokens": CLOUD_MAX_TOKENS,
"temperature": CLOUD_TEMPERATURE,
"stream": False,
}
r = requests.post(url, headers=headers, json=payload, timeout=CLOUD_TIMEOUT_S)
r.raise_for_status()
data = r.json()
# 常见返回是 choices[0].message.content
return data.get("choices", [{}])[0].get("message", {}).get("content", "")
# -------------------- FastAPI 生命周期:按后端加载模型 --------------------
@app.on_event("startup")
def _startup():
app.state.backend = BACKEND
app.state.lock = asyncio.Lock()
if BACKEND == "local-model":
if not LOCAL_VLM_AVAILABLE:
raise RuntimeError(
"BACKEND=local-model but transformers/torch/Qwen3VL imports failed. "
"Install deps first."
)
app.state.device = get_device()
print(f"[INFO] local-model device = {app.state.device}")
# Qwen3-VL 的 transformers 版本经常需要较新/源码版(官方卡片有提示):contentReference[oaicite:5]{index=5}
model = Qwen3VLForConditionalGeneration.from_pretrained(
LOCAL_MODEL_DIR,
torch_dtype=(torch.float16 if app.state.device.type in {"cuda", "mps"} else torch.float32),
device_map="auto" if app.state.device.type != "cpu" else None,
)
model.eval()
processor = AutoProcessor.from_pretrained(LOCAL_MODEL_DIR)
app.state.model = model
app.state.processor = processor
print(f"[INFO] local-model loaded from: {LOCAL_MODEL_DIR}")
elif BACKEND == "ollama":
print(f"[INFO] ollama backend: {OLLAMA_URL}, model={OLLAMA_MODEL}")
elif BACKEND == "cloud":
if not CLOUD_API_KEY:
raise RuntimeError("BACKEND=cloud but CLOUD_API_KEY is empty.")
print(f"[INFO] cloud backend: model={CLOUD_MODEL}")#{CLOUD_BASE_URL},
else:
print("[INFO] rule backend enabled")
@app.get("/health")
def health():
info = {"ok": True, "backend": BACKEND}
if BACKEND == "local-model" and hasattr(app.state, "device"):
info["device"] = str(app.state.device)
info["model_dir"] = LOCAL_MODEL_DIR
if BACKEND == "ollama":
info["ollama_url"] = OLLAMA_URL
info["ollama_model"] = OLLAMA_MODEL
if BACKEND == "cloud":
info["cloud_base_url"] = CLOUD_BASE_URL
info["cloud_model"] = CLOUD_MODEL
return info
@app.post("/act")
async def act(req: ActRequest):
t0 = time.time() # ← 起始计时
# 1) 解码图像(BGR)用于 rule 后端;同时保留 bytes 给 VLM
try:
img_bgr = decode_image_b64_to_bgr(req.image_b64)
img_bytes = base64.b64decode(req.image_b64.encode("utf-8"))
# gray = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2GRAY)
# mean = float(np.mean(gray))
# h, w = gray.shape[:2]
# print(f"[DEBUG] image={w}x{h}, gray_mean={mean:.1f}")
# # 每 5 秒存一张,方便打开确认
# if int(time.time()) % 5 == 0:
# global id
# cv2.imwrite("tmp-data/vla_{id}.jpg".format(id=id), img_bgr)
# print('[DEBUG]保存图像')
# id+=1
except Exception as e:
print(e)
raise HTTPException(status_code=400, detail=f"Bad image_b64: {e}")
instruction = (req.instruction or "").strip()
if not instruction:
raise HTTPException(status_code=400, detail="instruction is empty")
# 2) 后端分发
if BACKEND == "rule":
action = rule_vla(instruction, img_bgr)
return {"action": action, "model": "rule_vla_stub"}
prompt = build_action_prompt(instruction, req.sensor_context)
try:
async with app.state.lock:
if BACKEND == "local-model":
global id
cv2.imwrite("tmp-data/vla_{id}.jpg".format(id=id), img_bgr)
out_text = local_model_infer(prompt, img_bytes)
md5 = hashlib.md5(img_bytes).hexdigest()
print(f'DEBUG] id={id} md5={md5} 本地模型输出:',out_text)
id+=1
action = parse_action_from_text(out_text)
print(f'本地模型的动作解析结果:{action} 用时{time.time() - t0}')
return {"action": action, "model": "local-model", "raw": out_text}
if BACKEND == "ollama":
out_text = ollama_infer(prompt, req.image_b64)
action = parse_action_from_text(out_text)
return {"action": action, "model": f"ollama:{OLLAMA_MODEL}", "raw": out_text}
if BACKEND == "cloud":
out_text = cloud_infer(prompt, req.image_b64)
action = parse_action_from_text(out_text) or {"linear_x": 0.0, "angular_z": 0.0}
elapsed_ms = round((time.time() - t0) * 1000, 2)
print(f'[CLOUD] raw={out_text!r} action={action} latency={elapsed_ms}ms')
return {
"action": action,
"model": f"cloud:{CLOUD_MODEL}",
"raw": out_text,
"latency_ms": elapsed_ms,
}
raise HTTPException(status_code=500, detail=f"Unknown backend: {BACKEND}")
except requests.RequestException as e:
raise HTTPException(status_code=502, detail=f"Model request failed: {e}")
except json.JSONDecodeError as e:
raise HTTPException(status_code=500, detail=f"Model returned non-JSON: {e}")
except ValueError as e:
raise HTTPException(status_code=500, detail=f"Model output parse error: {e}")
except Exception as e:
raise HTTPException(status_code=500, detail=f"Inference failed: {e}")
if __name__ == "__main__":
def parse_args() -> argparse.Namespace:
# 命令行参数用于覆盖默认配置,不传则使用环境变量和代码内默认值
parser = argparse.ArgumentParser(description="VLA Server")
parser.add_argument("--backend", default=BACKEND, choices=["rule", "local-model", "ollama", "cloud"], help="执行后端")
parser.add_argument("--host", default=os.getenv("VLA_HOST", "0.0.0.0"), help="监听地址")
parser.add_argument("--port", type=int, default=int(os.getenv("VLA_PORT", "8000")), help="监听端口")
# local-model 参数(保持历史默认值)
parser.add_argument("--local-model-dir", default=LOCAL_MODEL_DIR, help="本地模型目录")
parser.add_argument("--local-max-new-tokens", type=int, default=LOCAL_MAX_NEW_TOKENS, help="本地模型最大新 token")
parser.add_argument("--local-top-p", type=float, default=LOCAL_TOP_P, help="本地模型 top_p")
parser.add_argument("--local-temperature", type=float, default=LOCAL_TEMPERATURE, help="本地模型温度")
# ollama 参数
parser.add_argument("--ollama-url", default=OLLAMA_URL, help="ollama 服务地址")
parser.add_argument("--ollama-model", default=OLLAMA_MODEL, help="ollama 模型名")
parser.add_argument("--ollama-timeout-s", type=float, default=OLLAMA_TIMEOUT_S, help="ollama 超时秒数")
# cloud 参数
parser.add_argument("--cloud-base-url", default=CLOUD_BASE_URL, help="cloud 接口 base_url")
parser.add_argument("--cloud-api-key", default=CLOUD_API_KEY, help="cloud 鉴权 Key")
parser.add_argument("--cloud-model", default=CLOUD_MODEL, help="cloud 模型名")
parser.add_argument("--cloud-timeout-s", type=float, default=CLOUD_TIMEOUT_S, help="cloud 超时秒数")
parser.add_argument("--cloud-max-tokens", type=int, default=CLOUD_MAX_TOKENS, help="cloud max_tokens")
parser.add_argument("--cloud-temperature", type=float, default=CLOUD_TEMPERATURE, help="cloud temperature")
return parser.parse_args()
def apply_cli_config(args: argparse.Namespace) -> None:
# CLI 配置生效于启动前的全局变量,用于后续所有推理逻辑
global BACKEND
global LOCAL_MODEL_DIR, LOCAL_MAX_NEW_TOKENS, LOCAL_TOP_P, LOCAL_TEMPERATURE
global OLLAMA_URL, OLLAMA_MODEL, OLLAMA_TIMEOUT_S
global CLOUD_BASE_URL, CLOUD_API_KEY, CLOUD_MODEL, CLOUD_TIMEOUT_S, CLOUD_MAX_TOKENS, CLOUD_TEMPERATURE
BACKEND = args.backend
LOCAL_MODEL_DIR = args.local_model_dir
LOCAL_MAX_NEW_TOKENS = args.local_max_new_tokens
LOCAL_TOP_P = args.local_top_p
LOCAL_TEMPERATURE = args.local_temperature
OLLAMA_URL = args.ollama_url.rstrip("/")
OLLAMA_MODEL = args.ollama_model
OLLAMA_TIMEOUT_S = args.ollama_timeout_s
CLOUD_BASE_URL = args.cloud_base_url.rstrip("/")
CLOUD_API_KEY = args.cloud_api_key
CLOUD_MODEL = args.cloud_model
CLOUD_TIMEOUT_S = args.cloud_timeout_s
CLOUD_MAX_TOKENS = args.cloud_max_tokens
CLOUD_TEMPERATURE = args.cloud_temperature
args = parse_args()
apply_cli_config(args)
uvicorn.run(app, host=args.host, port=args.port)核心功能:
-
提供HTTP REST API端点 (
/act) -
支持多种推理后端
-
处理图像和指令,输出运动控制命令
支持的推理后端:
| 后端 | 说明 | 适用场景 |
|---|---|---|
rule |
基于规则的简单控制 | 测试、调试 |
local-model |
本地Qwen3-VL模型 | 有GPU/mps的宿主机 |
ollama |
Ollama服务 | 本地部署大模型 |
cloud |
云端API (OpenAI兼容) | 生产环境 |
API接口:
POST /act
Content-Type: application/json
{
"instruction": "前进到白色圆柱体",
"image_b64": "<base64编码的JPEG图像>",
"timestamp": 1234567890.123,
"sensor_context": { // 可选
"source": "laser_scan",
"scan": {...}
}
}响应格式:
{
"action": {
"linear_x": 0.5,
"angular_z": -0.2
},
"model": "cloud:mimo-v2.5",
"raw": "原始模型输出",
"latency_ms": 150.5
}在对应目录运行uv run vla_server2.py(conda虚拟环境或python原生用python vla_server2.py)启动
ROS 2 ↔ VLM/VLA 控制桥接
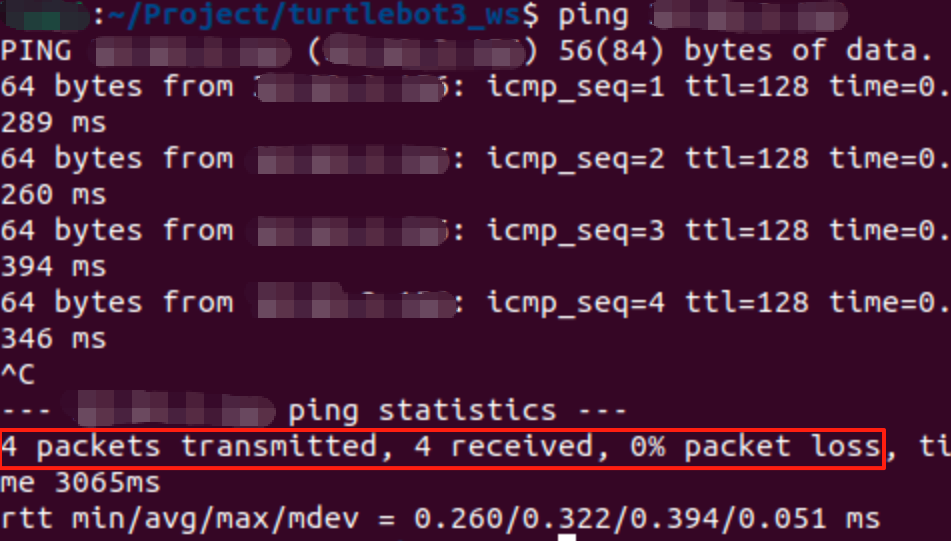
在终端,Windows系统通过命令ipconfig查ip,在Linux/macOS 系统通过ifconfig或得到ip
在虚拟机里,ping <你的ip>确认是否联通,'4 packets transmitted, 4 received, 0% packet loss'是4个数据包传输并被接受,没有丢失
开启终端,先设置环境变量和注册路径,路径以实际为准,同样需要开三个终端,具体环境变量配置可见上个教程,如果认为麻烦可以一个终端开三个tab
bash
source /opt/ros/humble/setup.bash
source ~/Project/gazebo_ros_pkgs/install/setup.bash
source ~/Project/turtlebot3_ws/install/setup.bash
export GAZEBO_MODEL_PATH=\
$GAZEBO_MODEL_PATH:\
~/Project/turtlebot3_ws/src/turtlebot3/turtlebot3_common/models:\
~/Project/turtlebot3_ws/src/turtlebot3_simulations/turtlebot3_gazebo/models
export TURTLEBOT3_MODEL=waffle_pi
export GAZEBO_PLUGIN_PATH=$GAZEBO_PLUGIN_PATH:~/Project/gazebo_ros_pkgs/install/gazebo_ros/lib把 ~/Project/vla_ws/src/vla_bridge/setup.py 进行修改,注册可执行入口,告诉 ROS2/ament 这个包里有哪些可运行的程序
python
from setuptools import setup
package_name = "vla_bridge"
setup(
name=package_name,
version="0.0.1",
packages=[package_name],
data_files=[
("share/ament_index/resource_index/packages", ["resource/" + package_name]),
("share/" + package_name, ["package.xml"]),
],
install_requires=["setuptools", "requests"],
zip_safe=True,
maintainer="you",
maintainer_email="you@example.com",
description="ROS2 bridge: camera+instruction -> VLA /act -> cmd_vel",
license="MIT",
tests_require=["pytest"],
entry_points={
"console_scripts": [
"vla_agent = vla_bridge.vla_agent_node:main",
"vla_agent2 = vla_bridge.vla_agent_node2:main",
"send_instruction = vla_bridge.instruction_publisher:main",
],
},
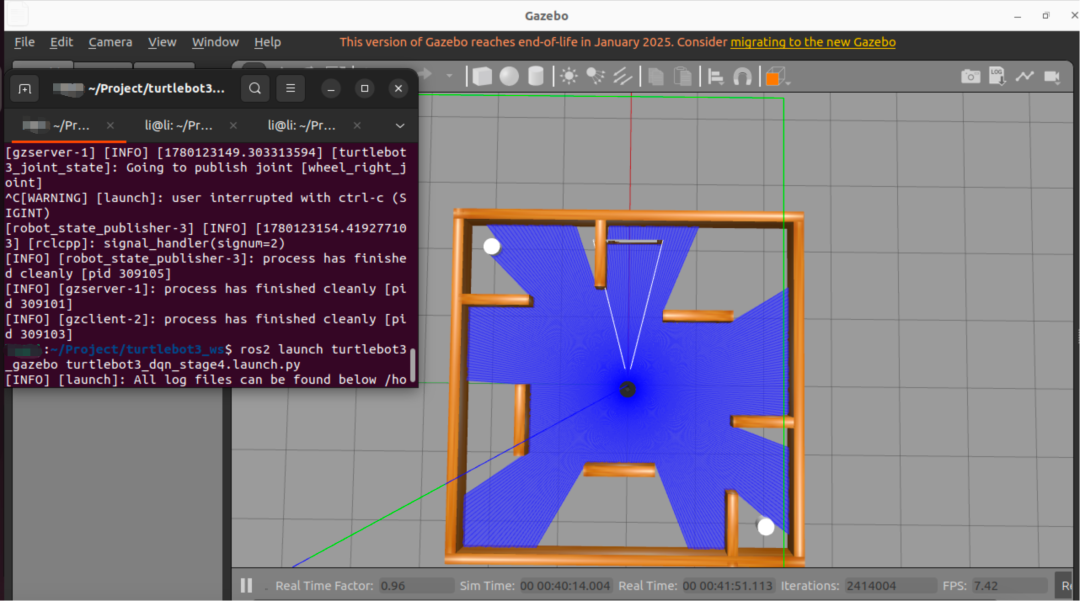
)执行cd ~/Project/turtlebot3_ws进入目录(以实际路径为准),然后执行ros2 launch turtlebot3_gazebo turtlebot3_dqn_stage4.launch.py启动仿真空间
编写 ROS 节点 vla_agent_node2.py作为桥接的主体,保存到 ~/Project/vla_ws/src/vla_bridge/vla_bridge目录中,注意线速度和角速度时有限制,突破极限要知道Gazebo 差速驱动插件
python
import base64
import time
import json
from typing import Any, Dict, Optional, Tuple
import cv2
import requests
# 导入ROS 2 Python核心库:创建节点、处理ROS通信
import rclpy
from rclpy.node import Node
from rclpy.executors import MultiThreadedExecutor #解决HTTP 阻塞
from rclpy.qos import qos_profile_sensor_data
# 导入ROS 2消息类型:传感器图像、字符串、运动指令
from sensor_msgs.msg import Image # 相机图像消息
from std_msgs.msg import String # 文本指令消息
from geometry_msgs.msg import Twist # 机器人运动速度指令
# 导入ROS-OpenCV桥接库:实现ROS Image和OpenCV Mat格式互转
from cv_bridge import CvBridge
from sensor_msgs.msg import LaserScan #激光雷达
import math
import numpy as np
import hashlib
def cv_to_jpeg_b64(cv_img) -> str:
"""
将OpenCV格式的图像编码为JPEG格式,并转换为Base64字符串(HTTP传输友好)
Args:
cv_img: OpenCV格式的图像(numpy.ndarray),BGR通道
Returns:
str: 编码后的Base64字符串(UTF-8编码)
Raises:
RuntimeError: 图像编码失败时抛出异常
"""
# cv2.imencode:将OpenCV图像编码为JPEG格式的二进制缓冲区
# [int(cv2.IMWRITE_JPEG_QUALITY), 80]:设置JPEG质量为80(平衡体积和画质)
ok, buf = cv2.imencode(".jpg", cv_img, [int(cv2.IMWRITE_JPEG_QUALITY), 80])
if not ok:
raise RuntimeError("cv2.imencode failed")
# 1. buf.tobytes():将numpy缓冲区转为二进制字节串
# 2. base64.b64encode():对二进制数据进行Base64编码
# 3. decode("utf-8"):将Base64二进制编码转为UTF-8字符串(方便JSON传输)
return base64.b64encode(buf.tobytes()).decode("utf-8")
class VLABridgeNode(Node):
"""
VLA桥接节点:实现ROS 2与VLA服务器的通信桥接,核心功能:
1. 订阅ROS话题:
- camera_topic (sensor_msgs/Image):机器人相机原始图像
- instruction_topic (std_msgs/String):控制指令(如"前进"、"左转")
2. 向VLA服务器发起HTTP POST请求:{vla_url}/act(携带指令+Base64编码的图像)
3. 发布ROS话题:
- cmd_vel_topic (geometry_msgs/Twist):机器人运动速度指令(来自VLA服务器返回)
"""
def __init__(self):
super().__init__("vla_bridge_node") # 初始化ROS 2节点,节点名称为"vla_bridge_node"(标识)
# ---- 声明ROS 2参数(支持运行时通过--ros-args -p 覆盖,提高灵活性)----
self.declare_parameter("camera_topic", "/camera/image_raw") # 相机图像话题名(默认:/camera/image_raw)
self.declare_parameter("instruction_topic", "/vla/instruction") # 控制指令话题名(默认:/vla/instruction)
self.declare_parameter("cmd_vel_topic", "/cmd_vel") # 机器人速度指令发布话题名(默认:/cmd_vel)
self.declare_parameter("vla_url", "http://127.0.0.1:8000") # VLA服务器地址(默认:http://127.0.0.1:8000)若VLA服务器是宿主机必须用宿主机局域网 IP
self.declare_parameter("rate_hz", 0.2) # 定时器频率(默认1Hz:每5秒向VLA服务器请求1次)
self.declare_parameter("http_timeout_s", 25.0) #8.0 HTTP请求超时时间(默认8秒:防止请求卡住)
self.declare_parameter("lin_scale", 1.0)
self.declare_parameter("ang_scale", 1.0)
self.declare_parameter("max_lin", 0.26) # TurtleBot3 常见安全量级 :contentReference[oaicite:2]{index=2}
self.declare_parameter("max_ang", 1.82) # 教学/实践常用安全量级 :contentReference[oaicite:3]{index=3}
self.declare_parameter("accel_lin", 0.5) # m/s^2,0 表示不做加速度限制
self.declare_parameter("accel_ang", 2.0) # rad/s^2
self.declare_parameter("scan_topic", "/scan")
self.declare_parameter("front_angle", 0.0) # rad,默认认为 scan 的 0 就是正前方
self.declare_parameter("obstacle_dist", 0.40) # 前方小于 0.4m 认为危险
self.declare_parameter("control_hz", 10.0) # 小脑控制频率
self.declare_parameter("remote_fresh_s", 6.0) # 0 表示自动推导
self.declare_parameter("stop_when_no_instruction", True) # 无指令时是否停止机器人(默认True:安全保护)
self.declare_parameter("send_sensor_context", True) # 是否默认发送传感器摘要给VLM
# 读取参数值并赋值给实例变量(方便后续调用)
self.camera_topic = self.get_parameter("camera_topic").value
self.instruction_topic = self.get_parameter("instruction_topic").value
self.cmd_vel_topic = self.get_parameter("cmd_vel_topic").value
self.vla_url = self.get_parameter("vla_url").value.rstrip("/")
self.rate_hz = float(self.get_parameter("rate_hz").value)
self.http_timeout_s = float(self.get_parameter("http_timeout_s").value)
self.lin_scale = float(self.get_parameter("lin_scale").value)
self.ang_scale = float(self.get_parameter("ang_scale").value)
#突破极限要知道Gazebo 差速驱动插件(diff drive plugin),很多项目是把插件放在单独的 *.gazebo.xacro 或 Gazebo 的 model.sdf 里
self.max_lin = float(self.get_parameter("max_lin").value)#不突破仿真控制器的最大速度上限
self.max_ang = float(self.get_parameter("max_ang").value)#不突破仿真控制器的最大角速度上限
self.accel_lin = float(self.get_parameter("accel_lin").value)
self.accel_ang = float(self.get_parameter("accel_ang").value)
self.front_angle = float(self.get_parameter("front_angle").value)
self.scan_topic = self.get_parameter("scan_topic").value
self.obstacle_dist = float(self.get_parameter("obstacle_dist").value)
self.control_hz = float(self.get_parameter("control_hz").value)
self.send_sensor_context = bool(self.get_parameter("send_sensor_context").value)
remote_fresh_s = float(self.get_parameter("remote_fresh_s").value)
# ✅ 自动推导:给网络/推理抖动留余量,但又不会太久
if remote_fresh_s <= 0.0:
# 只跟 tick 周期相关:信任最近 1~2 个周期即可,不要被 timeout 拉长
auto = max(1.6 / max(self.rate_hz, 0.1), 0.5) # 约等于 1~2 个周期
auto = min(auto, 5.0) # 上限 5s,避免旧动作拖太久
self.remote_fresh_s = auto
else:
self.remote_fresh_s = remote_fresh_s
self._inflight = False
self._next_try_t = 0.0
self._last_cmd_lin = 0.0
self._last_cmd_ang = 0.0
self._last_tick_t = time.time()
self.latest_scan: Optional[LaserScan] = None
self.latest_scan_t: float = 0.0
self.remote_action: Optional[tuple[float, float, float]] = None # (lin, ang, t)
self.stop_when_no_instruction = bool(self.get_parameter("stop_when_no_instruction").value)
self.bridge = CvBridge() # 初始化CvBridge:用于ROS Image <-> OpenCV Mat格式转换
self.latest_img: Optional[Image] = None # 存储最新的相机图像(初始为None:表示还未接收到图像)
self.latest_instruction: str = "" # 存储最新的控制指令(初始为空字符串)
# ---- 创建ROS 2订阅器 ----
# 订阅相机图像话题,回调函数on_image,队列大小10(缓存最多10条消息)
self.sub_img = self.create_subscription(Image, self.camera_topic, self.on_image, qos_profile_sensor_data)#10
# 订阅控制指令话题,回调函数on_instruction,队列大小10
self.sub_inst = self.create_subscription(String, self.instruction_topic, self.on_instruction, 10)
self.sub_scan = self.create_subscription(LaserScan, self.scan_topic, self.on_scan, qos_profile_sensor_data)#10
# ---- 创建ROS 2发布器 ----
self.pub_cmd = self.create_publisher(Twist, self.cmd_vel_topic, 10) # 发布机器人速度指令,队列大小10
period = 1.0 / max(self.rate_hz, 0.1) # 计算定时器周期(秒),max避免rate_hz为0导致除零错误
self.timer = self.create_timer(period, self.tick) # 创建定时器:每隔period秒执行一次tick回调函数(核心业务逻辑)
control_period = 1.0 / max(self.control_hz, 1.0)
self.control_timer = self.create_timer(control_period, self.control_tick)
# 打印节点初始化信息(方便调试,确认参数是否正确加载)
self.get_logger().info(f"camera_topic={self.camera_topic}")
self.get_logger().info(f"instruction_topic={self.instruction_topic}")
self.get_logger().info(f"cmd_vel_topic={self.cmd_vel_topic}")
self.get_logger().info(f"vla_url={self.vla_url} (POST {self.vla_url}/act)")
def on_image(self, msg: Image):
"""
相机图像话题回调函数:接收到新图像时,更新最新图像缓存
Args:
msg: ROS 2 sensor_msgs/Image类型的消息(相机原始图像)
"""
# 不改 launch:用 Unix 时间覆盖 ROS 相对时间
now = time.time()
msg.header.stamp.sec = int(now)
msg.header.stamp.nanosec = int((now - int(now)) * 1e9)
self.latest_img = msg
def on_instruction(self, msg: String):
"""
控制指令话题回调函数:接收到新指令时,更新最新指令缓存
Args:
msg: ROS 2 std_msgs/String类型的消息(控制指令文本)
"""
self.latest_instruction = (msg.data or "").strip() # strip():去除指令前后的空格/换行符,避免无效指令
self.get_logger().info(f"Instruction updated: {self.latest_instruction!r}") # 打印指令更新日志(方便调试,确认指令是否正确接收)
# 指令一变:立即让旧的远端动作失效,避免继续跑旧动作
self.remote_action = None # (lin, ang, t)
def on_scan(self, msg: LaserScan):
self.latest_scan = msg
self.latest_scan_t = time.time()
def publish_stop(self):
"""发布停止指令:让机器人线性速度和角速度都为0(紧急停止/无指令时使用)"""
tw = Twist() # 创建空的Twist消息
tw.linear.x = 0.0 # 线性速度(前进/后退)为0
tw.angular.z = 0.0 # 角速度(左转/右转)为0
self.pub_cmd.publish(tw) # 发布停止指令
self.get_logger().debug("🛑 发布停止指令")
def tick(self):
"""
大脑请求定时器(低频):只负责向VLA服务器请求动作,并缓存结果
✅ 不在这里发布 /cmd_vel,避免和 control_tick(小脑) 打架
"""
# 1) 无控制指令时:不请求大脑(小脑会负责 stop)
if not self.latest_instruction:
return
now = time.time()
# 退避:上一轮失败后,短时间内不重试,避免失败风暴
if now < self._next_try_t:
return
# 2) 无相机图像时:跳过请求(小脑仍可用雷达/灰度 fallback)
if self.latest_img is None:
self.get_logger().warn("⚠️ 未接收到相机图像,跳过本次大脑请求")
return
# 单飞:1.上一次请求没完成就不再发,避免堆积/并发/乱序 2.如果图像过旧(或无更新),跳过请求
img_time = self.latest_img.header.stamp.sec + self.latest_img.header.stamp.nanosec * 1e-9#用计算好的img_time(完整时间戳)代替stamp.sec
self.get_logger().info(f"time.time() - img_time({img_time})={time.time() - img_time}")
if self._inflight or time.time() - img_time > 8.0:#1.0 判断旧图的间隔的时间根据模型推理的速度改动,越慢越大
return
self._inflight = True
self.get_logger().debug(f"Image stamp: {self.latest_img.header.stamp.sec}.{self.latest_img.header.stamp.nanosec}")
# 3) ROS Image → OpenCV
try:
cv_img = self.bridge.imgmsg_to_cv2(self.latest_img, desired_encoding="bgr8")
self.get_logger().debug(f"img shape={cv_img.shape}, mean={cv2.mean(cv_img)}")
except Exception as e:
self.get_logger().warn(f"❌ 图像格式转换失败: {e}")
# ========== 新增:释放_inflight后再return ==========
self._inflight = False
return
# 4) OpenCV图像 → Base64(HTTP传输)
try:
image_b64 = cv_to_jpeg_b64(cv_img)
img_md5 = hashlib.md5(base64.b64decode(image_b64.encode("utf-8"))).hexdigest()
self.get_logger().info(f"[IMG] stamp={self.latest_img.header.stamp.sec}.{self.latest_img.header.stamp.nanosec} md5={img_md5}")
except Exception as e:
self.get_logger().warn(f"❌ 图像Base64编码失败: {e}")
# ========== 新增:释放_inflight后再return ==========
self._inflight = False
return
# ========== 修改2:删除Base64编码后的finally(提前释放_inflight的问题) ==========
# 5) 构造请求体
payload = {
"instruction": self.latest_instruction,
"image_b64": image_b64,
"timestamp": time.time(),
}
if self.send_sensor_context:
# 默认携带雷达摘要,减少传输量且保留上下文安全性
payload["sensor_context"] = {
"source": "laser_scan",
"scan": self._scan_summary(self.latest_scan),
}
# 6) 请求VLA服务器(大脑)
try:
resp = requests.post(
f"{self.vla_url}/act",
json=payload,
timeout=self.http_timeout_s,
)
resp.raise_for_status()
data = resp.json()
except Exception as e:
# 大脑慢/失败没关系:小脑会继续用本地避障输出
self.get_logger().warn(f"❌ 大脑请求失败(将继续小脑避障): {e}")
self._next_try_t = time.time() + 1.0 # ✅ 失败退避 1s(可调)
self._inflight = False # ========== 新增:释放_inflight ==========
return #finally先执行
finally:
self._inflight = False
# 7) 解析响应并缓存(注意:这里不做 scale/clamp/ramp)
action = data.get("action", {})
lin = float(action.get("linear_x", 0.0))
ang = float(action.get("angular_z", 0.0))
# 缓存远端动作与时间戳(供 control_tick 使用)
t = time.time()
self.remote_action = (lin, ang, t)
self.get_logger().info(f"✅ 接收大脑指令:linear_x={self.remote_action[0]:.3f}, angular_z={self.remote_action[1]:.3f} (有效期至:{t + self.remote_fresh_s:.2f})")
def _sector_min(self, scan: LaserScan, center_angle: float, half_width: float) -> float:
# 返回某个扇区内的最小距离(无有效值则 inf)
if scan is None or not scan.ranges:
return float("inf")
inc = scan.angle_increment
if inc <= 0:
return float("inf")
# TB3 仿真常见 angle_min=0, angle_max=2pi;也兼容 -pi..pi
vals = []
rmin = scan.range_min if scan.range_min > 0 else 0.0
rmax = scan.range_max if scan.range_max > 0 else float("inf")
a = scan.angle_min
for r in scan.ranges:
if np.isfinite(r) and (r > rmin) and (r < rmax):
# 角度差归一化到 [-pi, pi]
d = (a - center_angle + math.pi) % (2*math.pi) - math.pi
if abs(d) <= half_width:
vals.append(r)
a += inc
return float(min(vals)) if vals else float("inf")
def _scan_summary(self, scan: Optional[LaserScan]) -> Optional[Dict[str, Any]]:
# 把雷达扇区关键距离压缩成少量指标,避免把几百个 ranges 全发给VLM
if scan is None:
return None
valid_ranges = [r for r in scan.ranges if np.isfinite(r) and r > 0]
if not valid_ranges:
return {
"ok": False,
"reason": "no finite ranges",
"angle_min": float(scan.angle_min),
"angle_max": float(scan.angle_max),
"angle_increment": float(scan.angle_increment),
"range_min": float(scan.range_min),
"range_max": float(scan.range_max),
}
front = self._sector_min(scan, center_angle=self.front_angle, half_width=math.radians(15))
left = self._sector_min(
scan,
center_angle=self.front_angle + math.pi / 2.0,
half_width=math.radians(20),
)
right = self._sector_min(
scan,
center_angle=self.front_angle - math.pi / 2.0,
half_width=math.radians(20),
)
sorted_ranges = sorted(valid_ranges)
scan_seq = [float(v) for v in scan.ranges]
return {
"ok": True,
"stamp_sec": float(scan.header.stamp.sec),
"stamp_nsec": float(scan.header.stamp.nanosec),
"angle_min": float(scan.angle_min),
"angle_max": float(scan.angle_max),
"angle_increment": float(scan.angle_increment),
"range_min": float(scan.range_min),
"range_max": float(scan.range_max),
"ranges_valid_ratio": float(len(valid_ranges)) / max(len(scan_seq), 1),
"global_min_m": float(sorted_ranges[0]),
"global_med_m": float(sorted_ranges[len(sorted_ranges) // 2]) if sorted_ranges else float("nan"),
"front_min_m": float(front),
"left_min_m": float(left),
"right_min_m": float(right),
"obstacle_front": bool(front < self.obstacle_dist),
"scan_age_s": float(time.time() - self.latest_scan_t) if self.latest_scan_t > 0 else None,
}
def _lidar_avoid_needed(self) -> bool:
"""
判断是否需要雷达硬避障(永远优先):
- 取正前方一个扇区的最小距离
- 小于 obstacle_dist 则认为必须避障
"""
sc = self.latest_scan
if sc is None:
return False
front = self._sector_min(sc, center_angle=self.front_angle, half_width=math.radians(15))
return front < self.obstacle_dist
def fallback_action(self) -> tuple[float, float, bool]:
"""
小脑本地策略(高频、实时):
1) 雷达硬避障:只要前方太近,立刻转向(hard_avoid=True)
2) 否则可选用灰度规则微调
返回:(linear_x, angular_z, hard_avoid)
"""
# 默认慢速前进
lin, ang = 0.15, 0.0
hard_avoid = False
sc = self.latest_scan
if sc is not None:
front_center = self.front_angle
left_center = self.front_angle + math.pi / 2.0
right_center = self.front_angle - math.pi / 2.0
# 前方 ±15°
front = self._sector_min(sc, center_angle=front_center, half_width=math.radians(15))
# 左右扇区:用于决定往哪边转更安全
left = self._sector_min(sc, center_angle=left_center, half_width=math.radians(20))
right = self._sector_min(sc, center_angle=right_center, half_width=math.radians(20))
if front < self.obstacle_dist:
# ✅ 雷达触发:硬避障永远优先
hard_avoid = True
lin = 0.0
ang = +0.9 if left > right else -0.9
return lin, ang, hard_avoid
# 雷达未触发:可选灰度规则(例如画面过暗就转一下)
if self.latest_img is not None:
try:
cv_img = self.bridge.imgmsg_to_cv2(self.latest_img, desired_encoding="bgr8")
gray = cv2.cvtColor(cv_img, cv2.COLOR_BGR2GRAY)
center = gray[
gray.shape[0] // 3 : 2 * gray.shape[0] // 3,
gray.shape[1] // 3 : 2 * gray.shape[1] // 3,
]
if float(np.mean(center)) < 60:
return 0.0, 0.8, False
except Exception:
pass
return lin, ang, hard_avoid
def control_tick(self):
"""
小脑控制定时器(高频):始终发布 /cmd_vel
优先级(从高到低):
1) 无指令:stop(安全)
2) 雷达硬避障:永远优先(不允许大脑覆盖)
3) 大脑动作(若足够新鲜)
4) 本地fallback(灰度/慢速前进)
并在最终发布前统一做:scale/clamp/ramp
"""
# 0) 无指令:立即停
if not self.latest_instruction:
if self.stop_when_no_instruction:
self.publish_stop()
return
now = time.time()
# 1) 先算本地 fallback,并知道是否触发"雷达硬避障"
fb_lin, fb_ang, hard_avoid = self.fallback_action()
# 2) 决定是否使用大脑动作
lin, ang = fb_lin, fb_ang
ra = self.remote_action # 只读一次,避免中途被替换
remote_fresh = (ra is not None) and ((now - ra[2]) < self.remote_fresh_s)
if hard_avoid:
# ✅ 雷达硬避障永远优先:大脑绝不能覆盖
lin, ang = fb_lin, fb_ang
self.get_logger().info(f"🔧 小脑使用雷达硬避障")
else:
# 雷达未触发:如果大脑新鲜就用大脑,否则用fallback
if remote_fresh:
lin, ang = float(ra[0]), float(ra[1])
self.get_logger().info(f"🔧 小脑使用大脑指令:lin={lin:.3f}, ang={ang:.3f}")
else:
self.get_logger().info(f"🔧 小脑使用fallback指令:lin={lin:.3f}, ang={ang:.3f}")
# 3) 统一做 scale + clamp(最终发给底盘的速度)
lin *= self.lin_scale
ang *= self.ang_scale
lin = max(-self.max_lin, min(self.max_lin, lin))
ang = max(-self.max_ang, min(self.max_ang, ang))
# 4) ramp:用 control_tick 的 dt 进行加速度限制(平滑)
dt = max(1e-3, now - self._last_tick_t)
self._last_tick_t = now
if self.accel_lin > 0:
step = self.accel_lin * dt
lin = max(self._last_cmd_lin - step, min(self._last_cmd_lin + step, lin))
if self.accel_ang > 0:
step = self.accel_ang * dt
ang = max(self._last_cmd_ang - step, min(self._last_cmd_ang + step, ang))
self._last_cmd_lin = lin
self._last_cmd_ang = ang
# 5) 发布速度
tw = Twist()
tw.linear.x = lin
tw.angular.z = ang
self.pub_cmd.publish(tw)
def main():
"""ROS 2节点主函数:标准启动流程"""
rclpy.init() # 初始化ROS 2上下文
node = VLABridgeNode() # 创建VLA桥接节点实例
executor = MultiThreadedExecutor(num_threads=2) # 最小:2线程足够
executor.add_node(node)
try:
#rclpy.spin(node) # 自旋节点:持续处理回调函数(订阅/定时器),阻塞直到节点关闭
executor.spin()
finally:
executor.shutdown()
node.destroy_node() # 确保节点正常销毁(释放资源)
rclpy.shutdown() # 关闭ROS 2上下文
if __name__ == "__main__":
main()这段代码实现了一个 ROS 2 节点 ,作为机器人的 "大脑-小脑"混合控制器:
-
大脑:低频(默认0.2Hz)将相机图像和文本指令发送给远程 VLA 服务器,获取运动指令并缓存。
-
小脑 :高频(默认10Hz)运行,优先使用雷达避障 (前方<0.4m强制转向),否则使用缓存的大脑指令或本地回退(慢速前进/昏暗时右转),最后限幅、平滑后发布
/cmd_vel控制机器人。
功能:
-
订阅相机图像和控制指令
-
定时向VLA服务器请求推理
-
高频发布运动控制指令
-
实现本地安全避障
双定时器架构:
-
tick()定时器 (低频 0.2Hz):-
向VLA服务器发送推理请求
-
缓存推理结果
-
实现请求退避机制
-
-
control_tick()定时器 (高频 10Hz):-
发布运动控制指令
-
实现优先级控制
-
执行加速度平滑
-
核心作用是让机器人既能理解自然语言指令(通过VLA),又能保证实时安全避障。
用 colcon 安装到 ROS2 环境里,使 ros2 run 直接启动
cd ~/Project/vla_wscolcon build --symlink-install开始桥接ROS 2 与 VLA 服务器
source ~/Project/vla_ws/install/setup.bashros2 run vla_bridge vla_agent2 --ros-args -p vla_url:="http://<你的ip>:8000"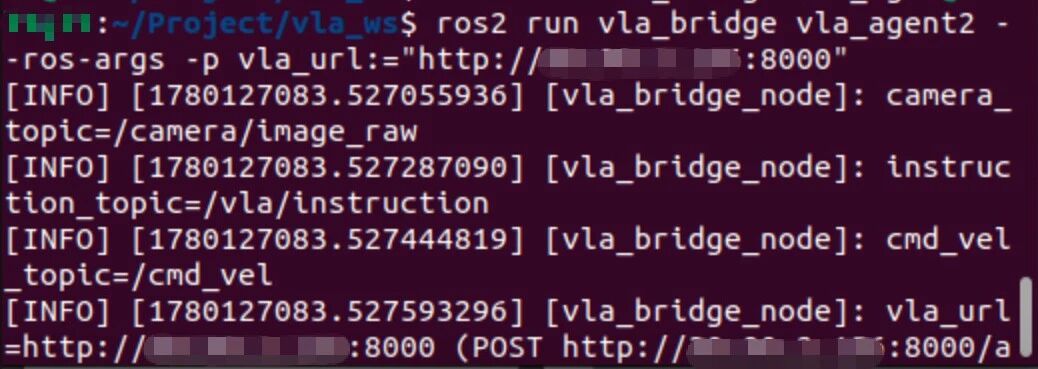
开新终端,通过指令发布器instruction_publisher.py发布指令,控制机器人移动
source ~/Project/vla_ws/install/setup.bashros2 run vla_bridge send_instruction "forward"核心功能:
-
向ROS2话题发布控制指令
-
支持命令行参数指定指令
-
简单的测试工具
启动时没有立刻收到大脑指令,且没有激光雷达的警告,则进行常规低速移动
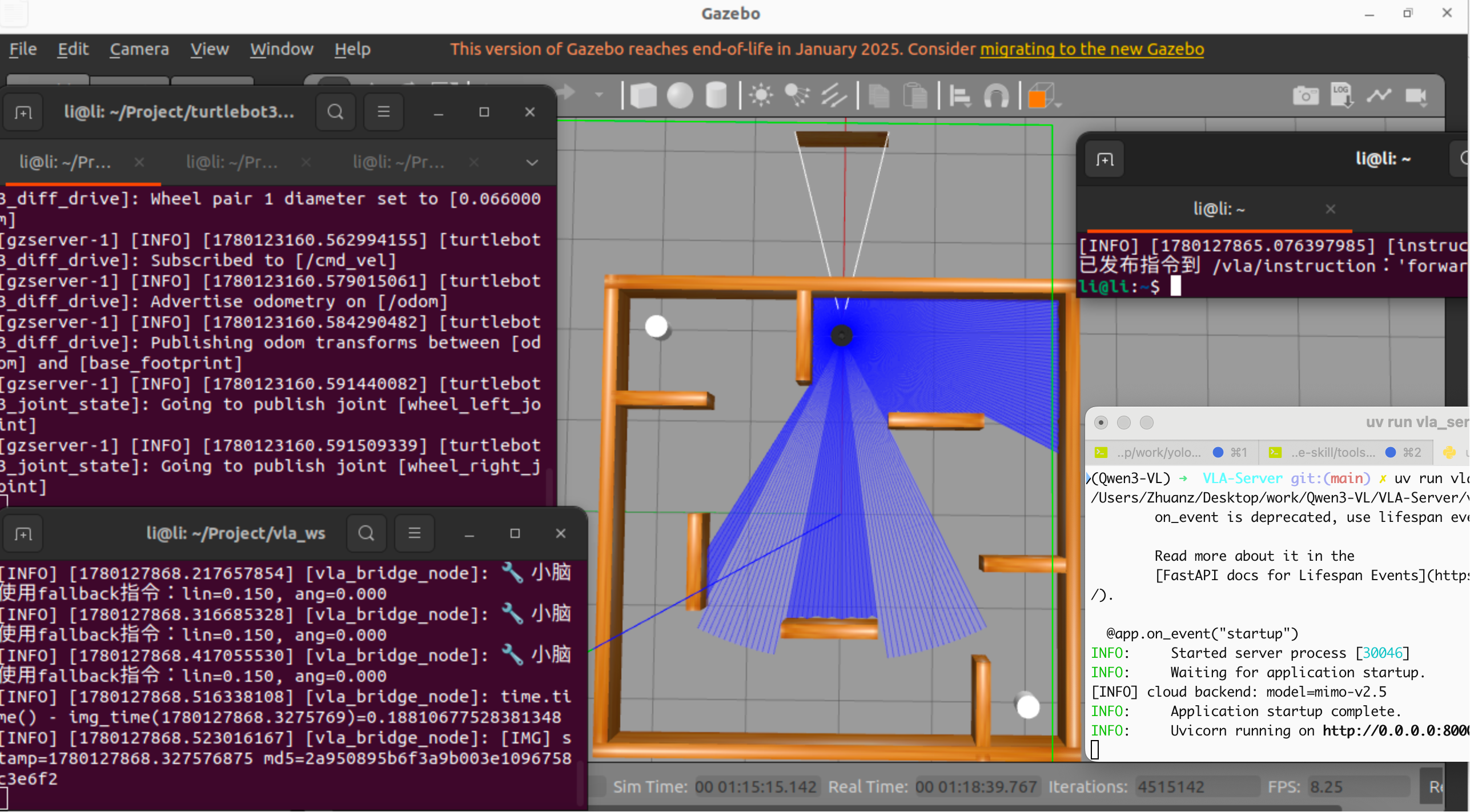
收到大脑指令,加速向前移动,当解析不出合法格式的大脑指令会直接停止(建议用智能的多模态视觉模型避免出现多次不符合格式的输出,或者直接用VLA模型)
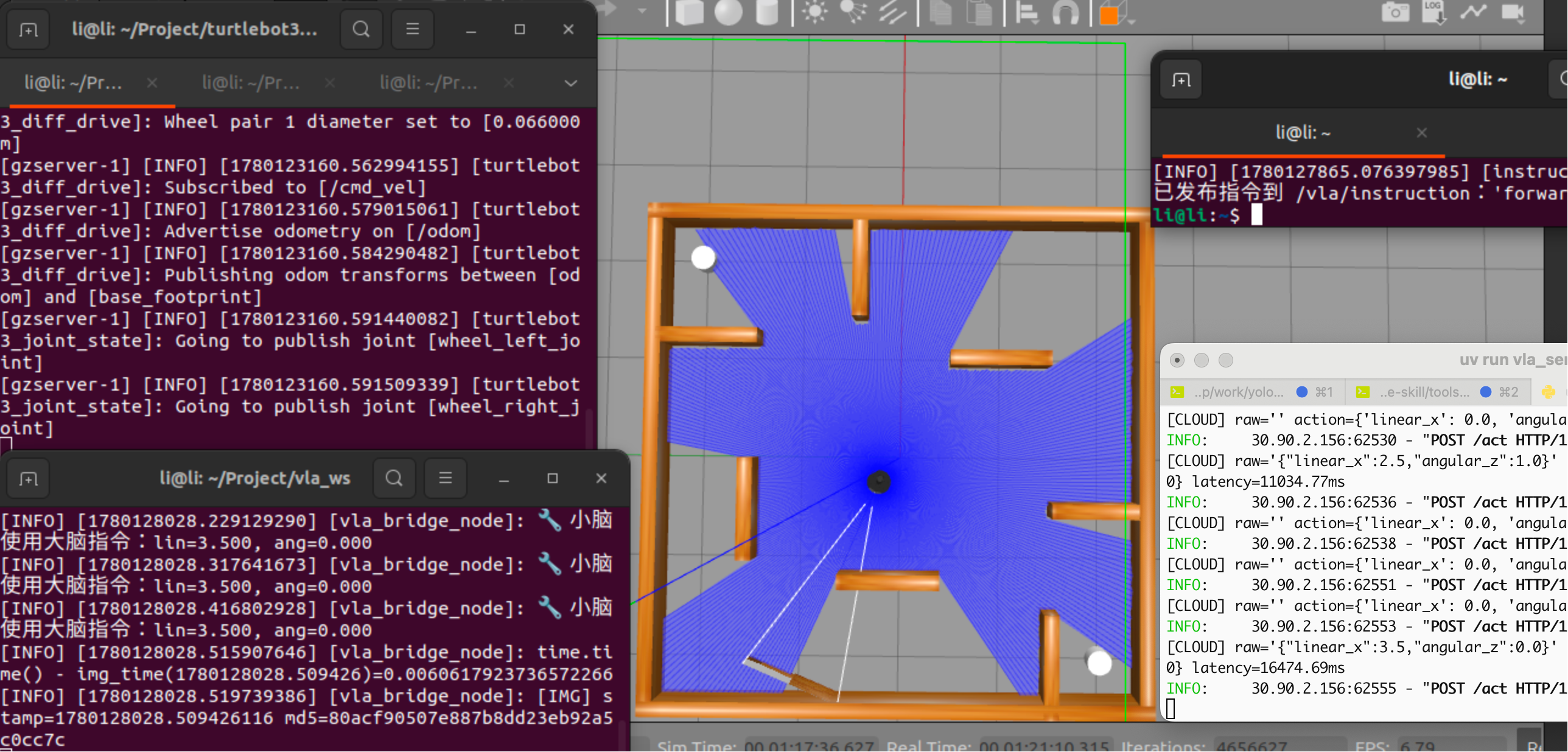
出现超时,低速运行
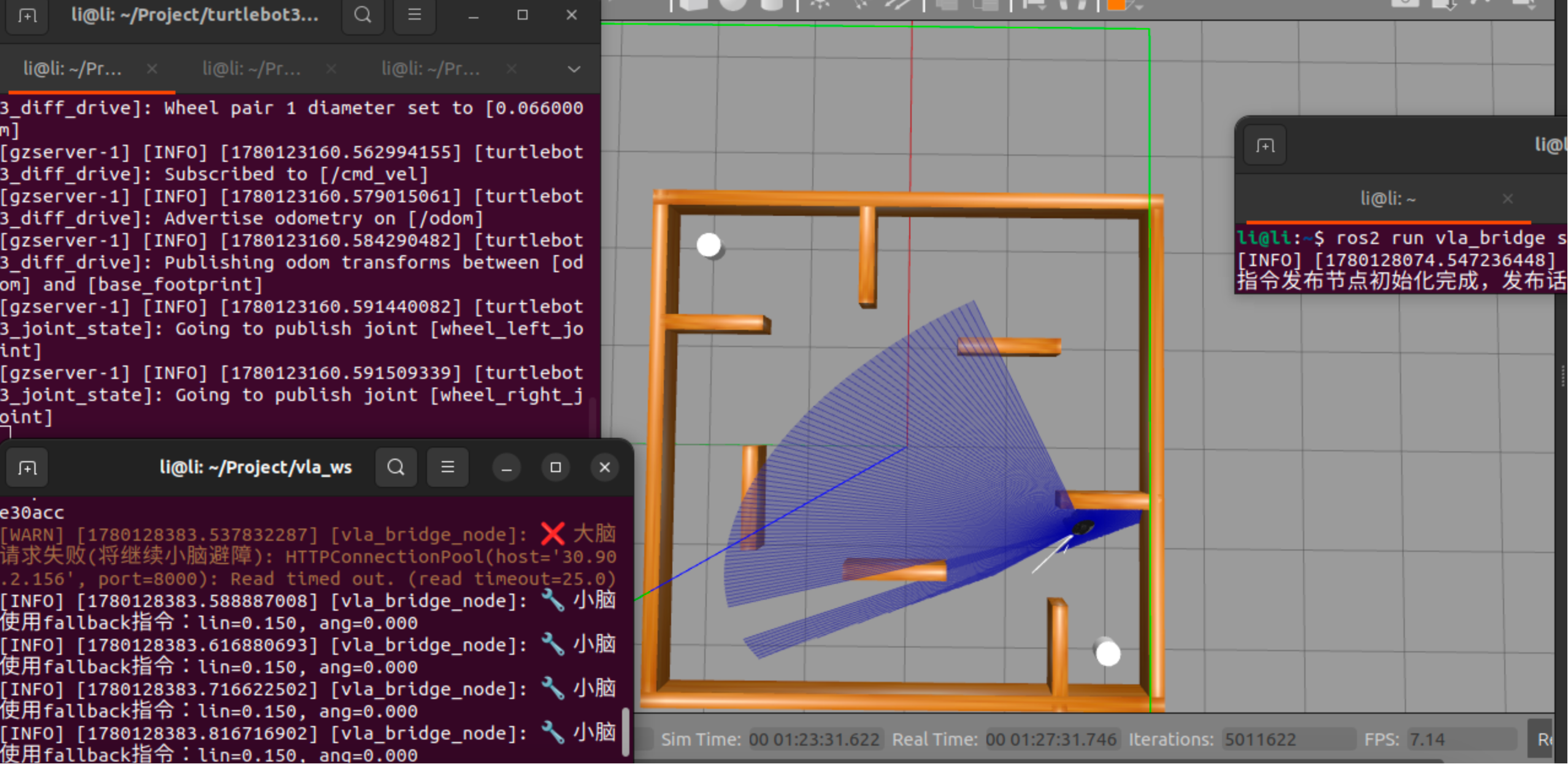
一旦激光雷达检测到危险会转向避开障碍
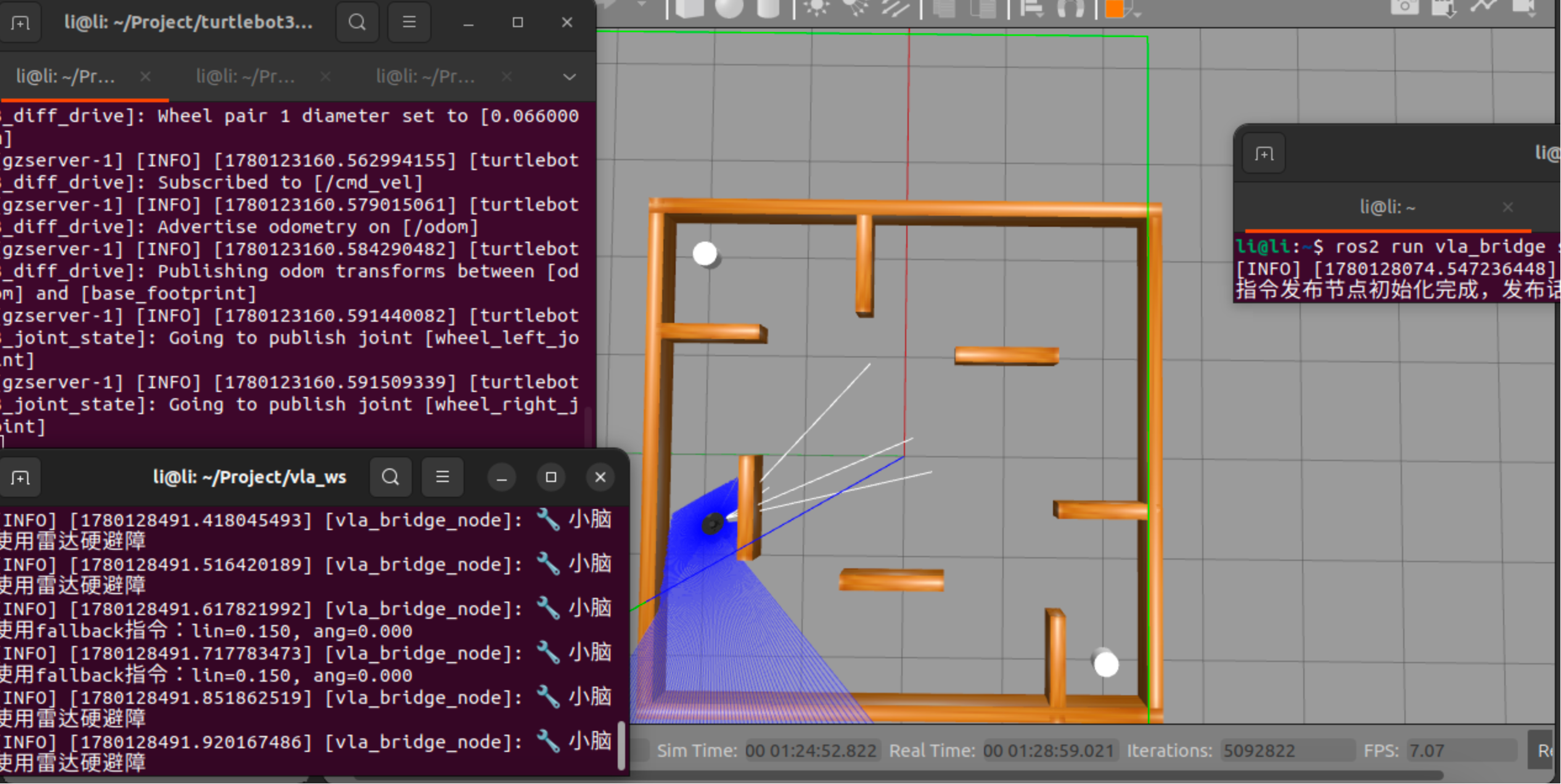
总结
本架构通过大脑-小脑分离设计,实现了:
-
安全性: 雷达硬避障永远优先
-
实时性: 高频本地控制保证响应速度
-
智能性: VLM提供高层视觉语言理解
-
容错性: 多层fallback保证系统稳定
-
扩展性: 模块化设计便于功能扩展
这种架构特别适合需要结合AI视觉理解和实时机器人控制的场景,如自主导航、目标跟踪等应用。
创作不易,禁止抄袭,转载请附上原文链接及标题