1. 定位导航
前面已经学习了如何判断算法运行时间、如何理解复杂度增长、如何证明循环算法正确。接下来进入一种非常重要的算法设计思想:
text
分治。它解决的问题是:
text
当一个问题太大、太复杂时,能不能把它拆成更小的同类问题?如果可以,就有机会用递归方式解决。
2. 概念术语
| 术语 | 定义 | 举例 |
|---|---|---|
| 分治 | 把大问题拆成小问题,分别解决后再合并 | 归并排序 |
| 分解 | 把原问题拆成若干个子问题 | 数组一分为二 |
| 解决 | 递归求解子问题 | 分别排序左右子数组 |
| 合并 | 把子问题答案组合成原问题答案 | 合并两个有序数组 |
| 子问题 | 原问题拆出来的小问题 | 排序左半部分 |
| 递归 | 函数调用自身解决更小问题 | merge_sort(left) |
| 递归基 | 小到可以直接求解的情况 | 数组长度为 1 |
关键澄清:
- 分治不是单纯拆任务,而是拆成结构相似的子问题。
- 子问题必须更小,否则递归无法收敛。
- 合并步骤必须可行,否则分解没有意义。
- 分治算法的复杂度通常要看每层工作量和递归层数。
3. 什么是分治思想
分治思想的核心可以概括为:
text
一个大问题不好直接解决,就把它拆成几个小问题;
小问题继续拆,直到足够简单;
最后再把小问题的答案合并起来。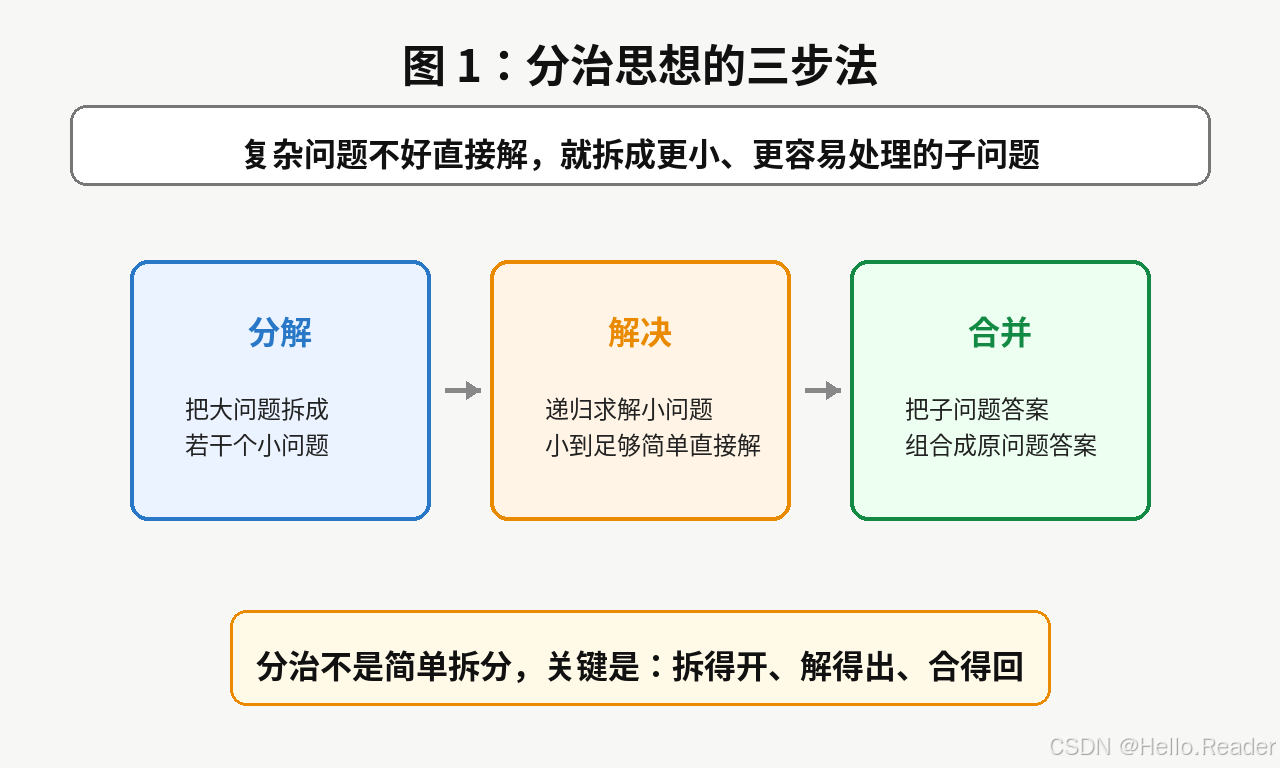
它通常包含三步:
- 分解:把原问题拆成若干子问题;
- 解决:递归求解这些子问题;
- 合并:把子问题答案组合成原问题答案。
这三步缺一不可。
如果只能拆,不能合,就不是完整的分治。
4. 分治的三步法
4.1 分解
分解阶段要回答:
text
原问题如何拆成更小的问题?例如排序一个数组:
text
[38, 27, 43, 3, 9, 82, 10]可以拆成左右两半:
text
[38, 27, 43, 3]
[9, 82, 10]4.2 解决
解决阶段要回答:
text
子问题如何得到答案?如果子问题仍然很大,就继续递归拆分。
如果子问题已经足够小,比如只剩一个元素,那它天然有序,可以直接返回。
4.3 合并
合并阶段要回答:
text
多个子问题的答案如何组合成原问题答案?对于归并排序,合并就是:
text
把两个已经有序的数组合并成一个更大的有序数组。这一步非常关键。
5. 用归并排序理解分治
归并排序是理解分治思想的经典例子。
它的整体逻辑是:
text
如果数组长度 <= 1,直接返回;
否则把数组拆成左右两半;
分别对左右两半排序;
最后合并两个有序数组。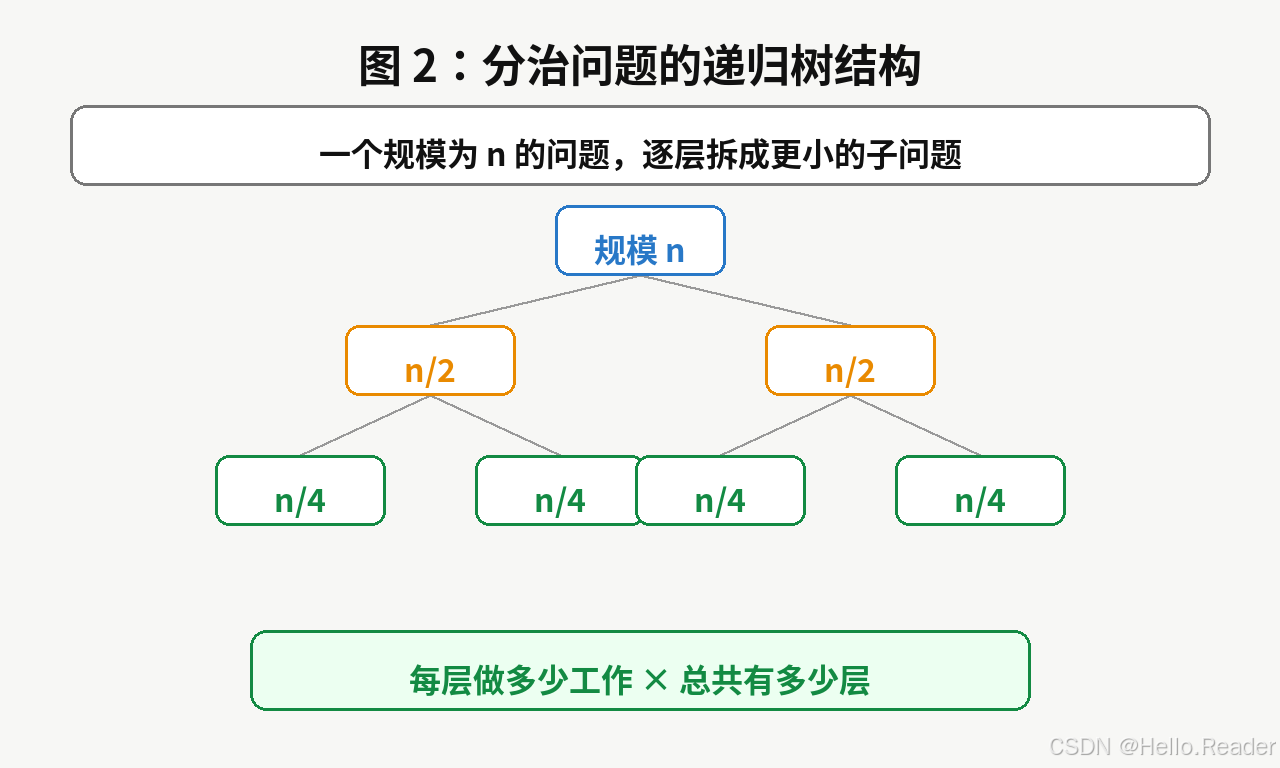
这个递归树展示了一个重要现象:
- 每一层问题规模越来越小;
- 层数大约是
log n; - 每一层合并总工作量大约是
n; - 所以总复杂度大致是
O(n log n)。
6. 动态推演:归并排序的分治过程
下面用动态图看完整过程。

过程可以理解为:
- 先把原数组拆成左右两半;
- 左右两半继续递归拆分;
- 拆到单个元素时停止;
- 单个元素天然有序;
- 两两合并成小有序数组;
- 最后合并成完整有序数组。
这就是分治思想最典型的执行流程。
7. 合并过程为什么是关键
分治算法中,很多人只注意"拆分",忽略"合并"。
但在归并排序里,真正把答案组织起来的是合并过程。
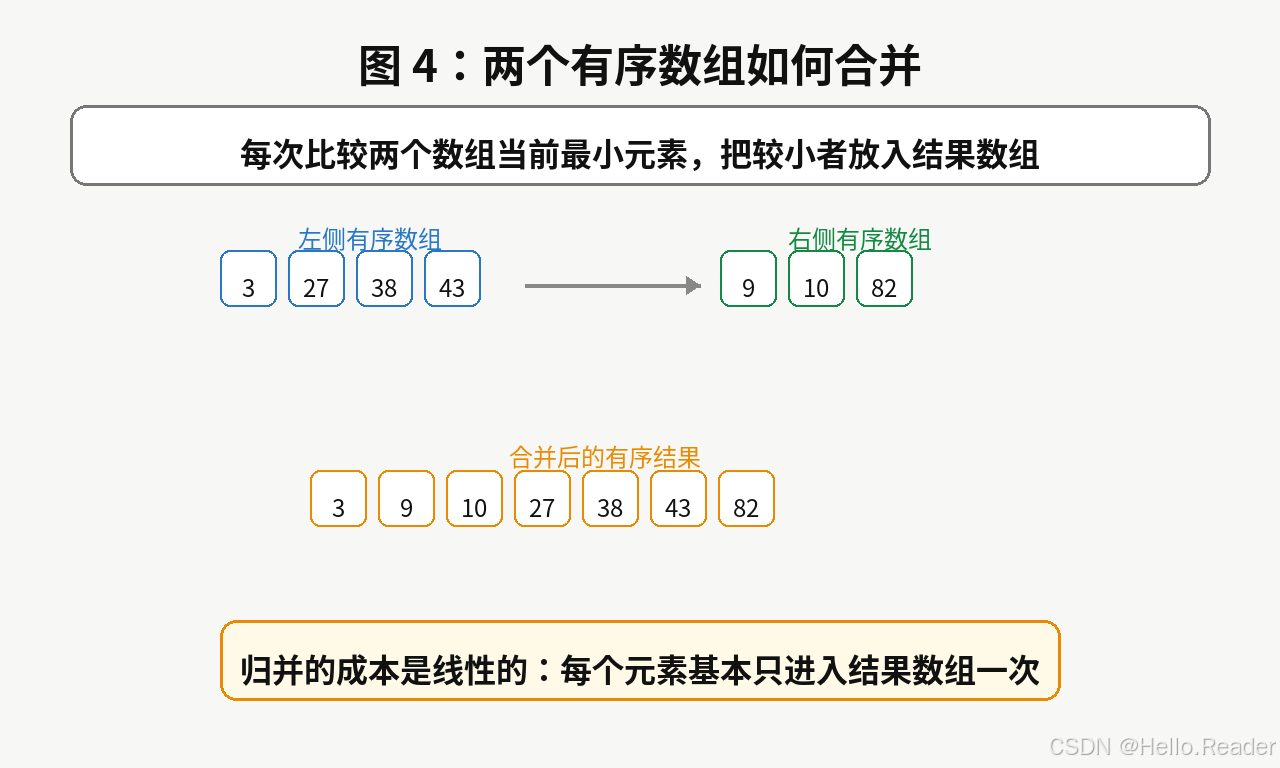
假设有两个有序数组:
text
[3, 27, 38, 43]
[9, 10, 82]合并时只需要比较两个数组当前最小元素:
- 谁小,就把谁放入结果数组;
- 被放入结果数组的一侧向后移动;
- 直到某一侧用完,再把另一侧剩余元素追加进去。
因为每个元素最多被放入结果数组一次,所以合并成本是线性的:
O(n) O(n) O(n)
8. 分治算法的复杂度直觉
归并排序为什么是:
O(nlogn) O(n \log n) O(nlogn)
可以这样理解:
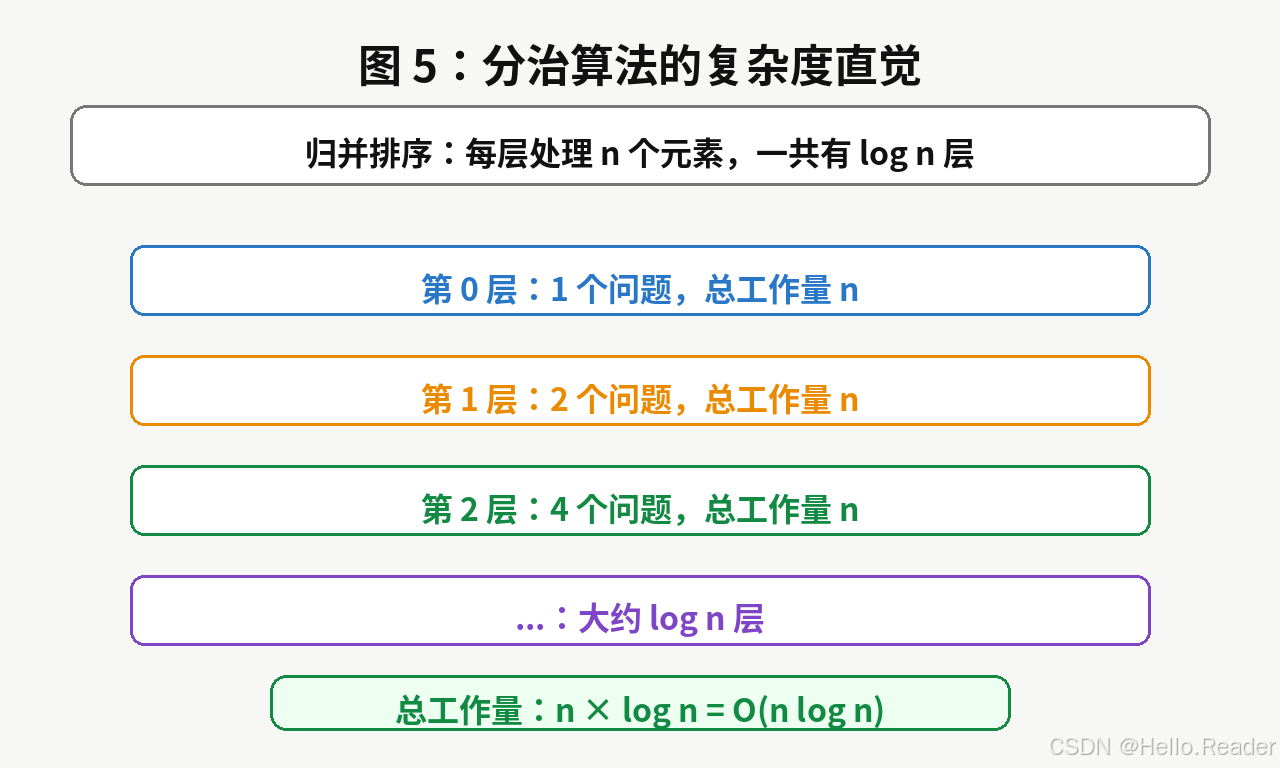
每一层都要处理所有元素,工作量大约是:
O(n) O(n) O(n)
而每次把问题规模折半,所以递归层数大约是:
O(logn) O(\log n) O(logn)
因此总工作量是:
O(n)×O(logn)=O(nlogn) O(n) \times O(\log n) = O(n \log n) O(n)×O(logn)=O(nlogn)
这就是分治算法复杂度分析的常见套路:
text
每层工作量 × 层数9. 代码实践:归并排序
下面给出 Python 版本归并排序。
python
def merge(left, right):
result = []
i = 0
j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(nums):
if len(nums) <= 1:
return nums[:]
mid = len(nums) // 2
left = nums[:mid]
right = nums[mid:]
sorted_left = merge_sort(left)
sorted_right = merge_sort(right)
return merge(sorted_left, sorted_right)
if __name__ == "__main__":
nums = [38, 27, 43, 3, 9, 82, 10]
print(merge_sort(nums))输出:
text
[3, 9, 10, 27, 38, 43, 82]C++ 版本
cpp
#include <iostream>
#include <vector>
using namespace std;
vector<int> mergeArray(const vector<int>& left, const vector<int>& right) {
vector<int> result;
int i = 0, j = 0;
while (i < left.size() && j < right.size()) {
if (left[i] <= right[j]) {
result.push_back(left[i]);
i++;
} else {
result.push_back(right[j]);
j++;
}
}
while (i < left.size()) {
result.push_back(left[i]);
i++;
}
while (j < right.size()) {
result.push_back(right[j]);
j++;
}
return result;
}
vector<int> mergeSort(const vector<int>& nums) {
if (nums.size() <= 1) {
return nums;
}
int mid = nums.size() / 2;
vector<int> left(nums.begin(), nums.begin() + mid);
vector<int> right(nums.begin() + mid, nums.end());
vector<int> sortedLeft = mergeSort(left);
vector<int> sortedRight = mergeSort(right);
return mergeArray(sortedLeft, sortedRight);
}
int main() {
vector<int> nums = {38, 27, 43, 3, 9, 82, 10};
vector<int> result = mergeSort(nums);
for (int x : result) {
cout << x << " ";
}
return 0;
}10. 常见误区
误区一:分治就是简单拆成几份
不对。
拆分只是第一步,还要能解决子问题,并且能把答案合并回来。
误区二:所有递归都是分治
不一定。
分治通常要求子问题结构相似,并且子问题答案可以组合成原问题答案。
误区三:分治一定更快
也不一定。
如果合并成本太高,或者拆分后子问题之间强依赖,分治未必划算。
误区四:只看递归深度就能判断复杂度
不够。
还要看每一层做多少工作。
归并排序是每层 O(n),层数 O(log n),所以总共 O(n log n)。
11. 现代延伸
分治思想在工程中非常常见。
| 场景 | 分治思想体现 |
|---|---|
| 归并排序 | 拆分数组,分别排序,再合并 |
| 快速排序 | 按基准值划分左右区域 |
| 二分查找 | 每次丢弃一半搜索空间 |
| MapReduce | 分片处理数据,再汇总结果 |
| 并行计算 | 把任务拆给多个线程或节点 |
| 大文件处理 | 分块读取、分块处理、最后合并 |
| 分布式聚合 | 局部聚合后再做全局聚合 |
很多大数据和分布式系统,本质上都离不开分治思想。
比如统计海量日志中的访问量,可以先把日志按文件块、时间段或机器拆开,每个节点局部统计,再把结果合并。这就是非常典型的"分解---解决---合并"。
12. 思考题
- 分治的三步分别是什么?
- 为什么归并排序可以看成分治算法?
- 归并排序为什么是
O(n log n)? - 分治和普通递归有什么区别?
- 举一个工程场景,说明如何把一个大任务拆成多个小任务处理。
13. 本篇小结
本篇讲清楚了分治思想。
核心结论是:
- 分治的基本流程是:分解、解决、合并;
- 分解要让问题规模变小;
- 解决阶段通常通过递归完成;
- 合并阶段必须能把子问题答案组合成原问题答案;
- 归并排序是理解分治思想的典型例子;
- 归并排序每层处理
n个元素,大约有log n层,所以复杂度是O(n log n); - 工程中的分布式处理、并行计算、大文件处理,也经常使用分治思想。
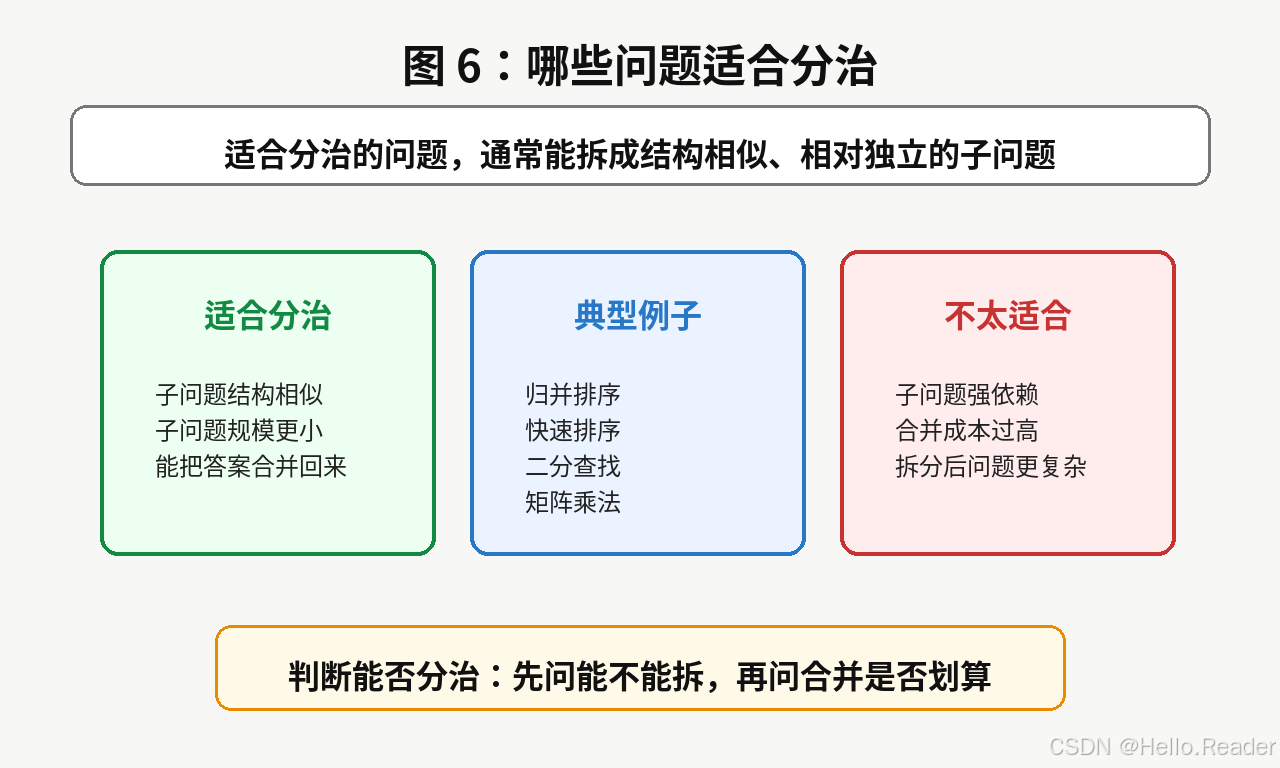
判断一个问题是否适合分治,可以先问三个问题:
text
能不能拆?
拆完之后是不是同类问题?
子问题答案能不能高效合并?如果三个问题答案都是肯定的,分治往往是一个值得尝试的方向。