深度学习论文: ICPR 2026 Competition on Low-Resolution License Plate Recognition
ICPR 2026 Competition on Low-Resolution License Plate Recognition
PDF: https://arxiv.org/abs/2604.22506
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
自动车牌识别(ALPR)系统在交通执法、电子收费等场景中应用广泛。在标准成像条件下,车牌检测与识别性能已趋于饱和。然而,在真实监控环境中,由于摄像头距离远、硬件限制以及强压缩,车牌图像常常以低分辨率(Low-Resolution, LR)获取,字符模糊、失真,识别难度显著增加。尽管实际需求迫切,低分辨率车牌识别(LRLPR)仍是一个极具挑战且研究不足的问题,现有最先进方法在真实低质量图像上的识别率也仅为50-60%。
为了推动该领域发展,本文在ICPR 2026上组织了首届低分辨率车牌识别竞赛。竞赛基于LRLPR-26数据集,该数据集包含20,000个训练轨迹(每个轨迹含同一车牌的5张低分图和5张高分图)和3,000个测试轨迹(每个轨迹含5张低分图)。这是目前最大的真实低分与高分车牌配对数据集。
竞赛吸引了来自41个国家的269支队伍,最终99支队伍提交了有效结果。本文介绍了竞赛概况、数据集、评估协议、结果,并详细分析了前五名团队的方法。
2 竞赛详细说明
组织者利用 YOLOv11 进行车牌检测,并使用 BoT-SORT 进行跨帧跟踪。对于同一辆车,远处的帧被标记为 LR 样本,近处的帧则作为高分辨率(High-Resolution, HR)参考。最终的标注通过对 5 帧 HR 图像进行 OCR 识别并结合多数投票(Majority Voting)机制产生,确保了 Ground Truth 的准确性。
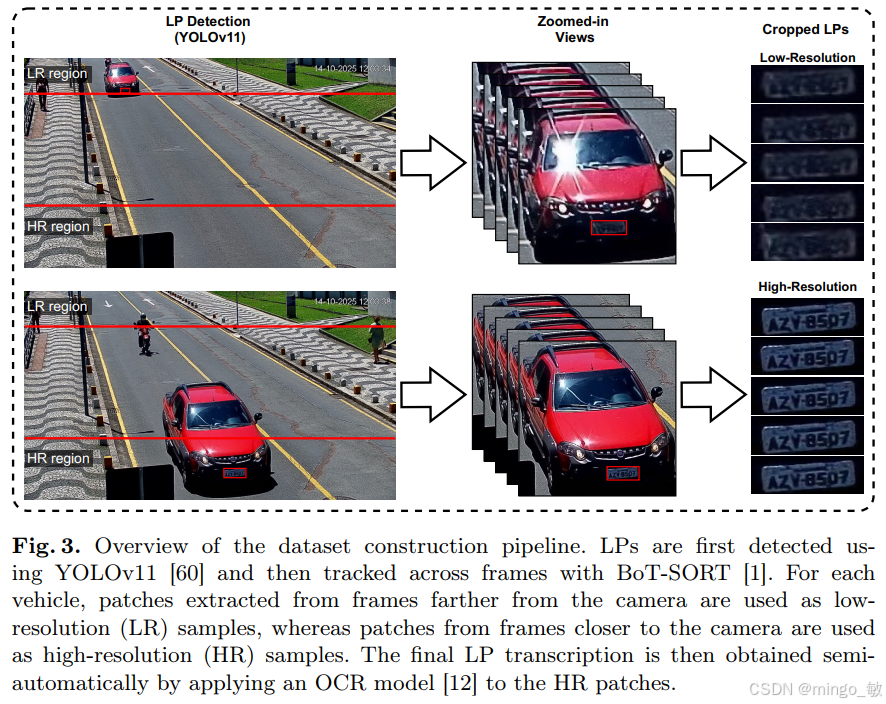
2.1 训练数据
- 20,000个轨迹 ,每个轨迹包含:
- 5张连续的低分辨率(LR)车牌图像
- 5张连续的高分辨率(HR)车牌图像

- 总计200,000张图像。
- 数据分为两个场景:
- 场景A(10,000轨迹):相对受控环境(白天、无雨)。
- 场景B(10,000轨迹):更具挑战性(雨天、夜间、不同方向)。
- 车牌布局:
- 巴西样式:3字母 + 4数字
- Mercosur样式:3字母 + 1数字 + 1字母 + 2数字
训练集提供了HR图像,鼓励参赛者探索超分辨率等增强策略。
2.2 测试数据
- 3,000个轨迹,全部来自场景B,每个轨迹对应唯一车辆。
- 每个轨迹仅包含5张LR图像(无HR图像,无标注)。
- 布局分布:600轨迹巴西样式,2,400轨迹Mercosur样式。
2.3 竞赛阶段与提交格式
- 公开测试阶段 (约1个月):
- 提供1,000个测试轨迹(含部分标签用于反馈)。
- 每日最多5次提交,总计最多25次。
- 公共排行榜。
- 盲测阶段 (约1周):
- 完整3,000个测试轨迹。
- 排行榜私密,仅能看见自己分数。
- 每个队伍总计最多3次提交。
- 提交格式 :每行
track_id,plate_text;confidence
2.4 评估协议
- 主要指标 :识别率(Recognition Rate)
- 定义:正确识别的轨迹数 / 总测试轨迹数
- 要求预测车牌字符串与真实标签完全匹配。
- 次要指标 (用于平局时):置信度差距(Confidence Gap)
- 正确预测的平均置信度 − 错误预测的平均置信度
- 值越大,模型置信度校准越好。
竞赛结果概览
- 第一名 :识别率 82.13%,置信度差距 6.67%
- 第二名:81.73%
- 第三名:80.17%
- 第四名:80.10%
- 第五名:79.83%
3 前五名团队方案详解
🥇 第一名:DLmath(韩国大学)
核心方法 :教师-学生框架,联合训练超分辨率模型和OCR模型。
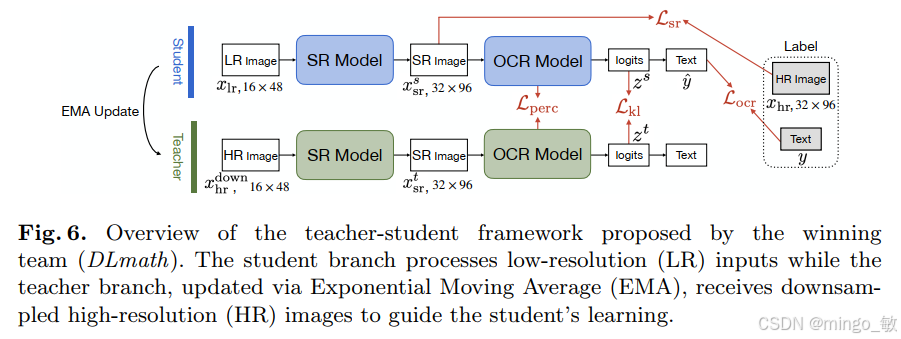
输入为5 帧低分辨率(LR)图像,输出为最终车牌识别文本。
核心逻辑:框架联合训练超分辨率(SR)模型与车牌 OCR 识别模型。学生分支以 LR 图像作为输入进行特征学习;教师分支基于指数移动平均(EMA) 动态更新权重,以降采样后的高分辨率(HR)图像作为监督信号,引导学生分支完成超分特征拟合。
模型组件:超分骨干选用 HATFIR 与 MambaIRv2;OCR 识别模块采用 GP-LPR。推理阶段采用后期融合策略,将 5 帧图像输出的预测 Logits 加权求和后再解码,有效提升车牌识别的鲁棒性与稳定性。
🥈 第二名:AIO_JiangnamCoffee(越南)
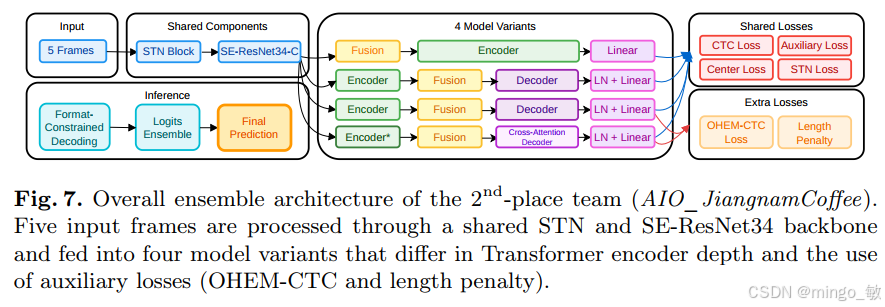
核心方法:四阶段识别流程 + 多模型集成。
- 空间变换(Spatial Transformer Network, STN):用于对齐倾斜的车牌。
- 特征提取:使用 SE-ResNet34-C 捕捉关键特征。
- 序列建模:引入 Transformer 编码器。
- 预测:采用连接时序分类(Connectionist Temporal Classification, CTC)损失进行解码。
特别设计了一个 CNN 注意力模块来评估每帧的质量,并对 5 帧特征进行加权融合。
🥉 第三名:OpenOCR(中国)
核心方法 :低分辨率车牌识别作为鲁棒场景文本识别问题,不显式使用超分辨率。
将问题视为鲁棒场景文本识别,使用了 SVTRv2 架构。没有使用显式的超分模块,而是通过字符级投票机制整合 20 个预测结果(5 帧 × 4 个模型),展现了强力 Backbone 的优势。
第四名:CAP2(韩国)
核心方法 :几何感知预处理 + 双流识别 + 位置感知集成。
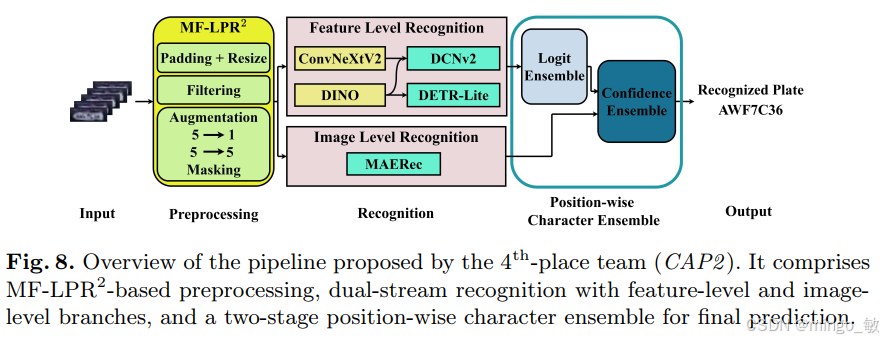
利用 U-Net 生成文本区域掩码进行背景抑制,并结合 DINOv3 等强力特征提取器进行双流识别。
第五名:UIT-MeoBeo(越南)
核心方法 :多阶段、多帧OCR管道 + 结构感知解码。
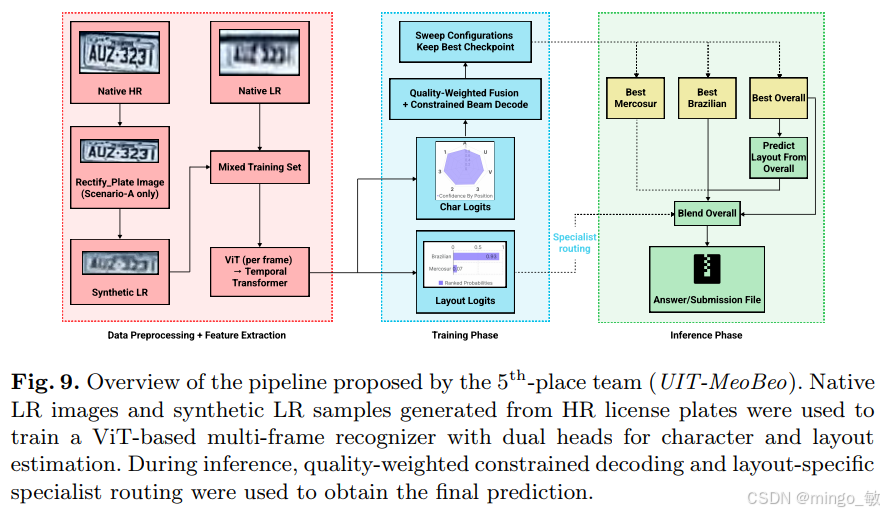
引入了时序 Transformer 进行跨帧融合,并根据巴西和南方共同市场(Mercosur)的车牌布局(如"三字母+一数字+一字母+两数字")进行约束解码。
5 总结与讨论
- 竞争激烈:前20名识别率仅差5.66个百分点,第一名错误率仍达17.87%,表明任务远未解决。
- 方法多样性:没有单一主导架构,不同团队在超分辨率、直接识别、多帧融合、集成、布局约束等方面各有侧重。
- 多帧利用是关键:几乎所有顶级方案都有效利用了5帧轨迹结构(投票、融合、时序建模)。
- 置信度差距很重要:识别率相近时,置信度差距差异大,影响实际应用中的可靠性。