Web开发入门必懂:从浏览器到互联网的完整数据流
今天系统梳理了Web开发最核心的底层逻辑,从浏览器点击到服务器响应,再到数据在全球互联网中的传输路径,把零散的知识点串成了完整的链条。这篇笔记既是对今天内容的总结,也希望能帮到刚入门的同学建立全局认知。
一、Web应用的核心架构:浏览器与服务器的对话
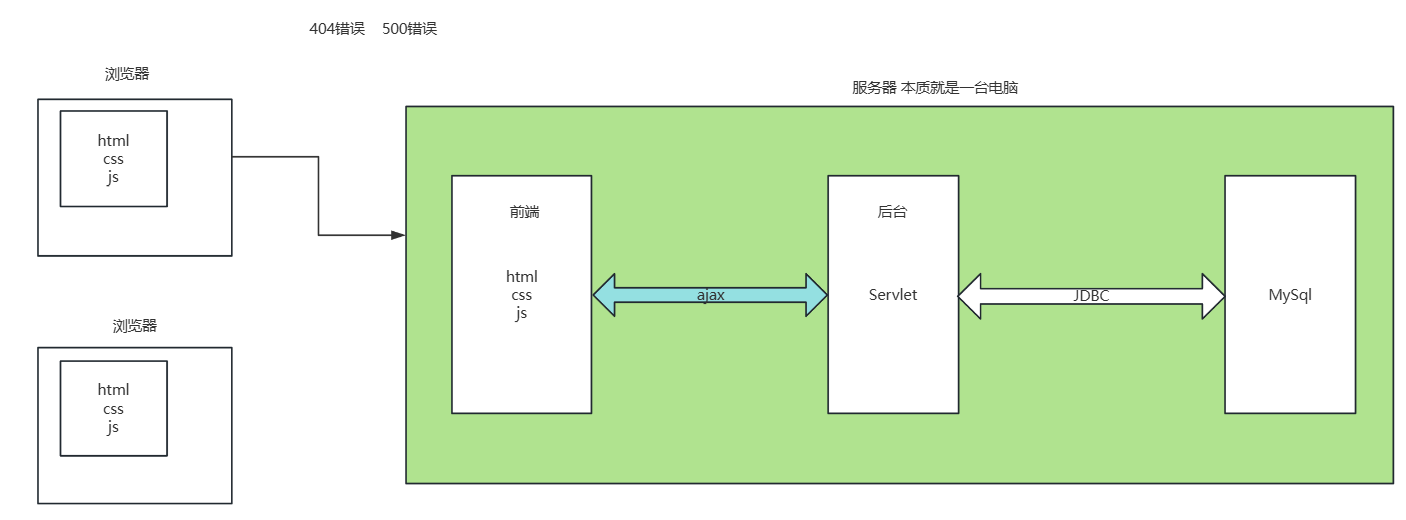
所有Web应用的本质,都是**客户端(浏览器)和服务端(服务器)**之间的请求-响应交互。很多人会混淆"前端"和"浏览器",其实它们是两个完全不同的概念:
- 浏览器:运行在用户本地电脑上的软件,负责解析HTML/CSS/JS代码,渲染成我们看到的页面
- 服务器 :本质就是一台24小时不关机的电脑,上面同时存放着前端资源 和后台程序
完整的数据流转链路
用户浏览器 → 服务器前端(HTML/CSS/JS) ←[AJAX]→ 服务器后台(Servlet) ←[JDBC]→ 数据库(MySQL)-
第一步:请求静态资源
用户在浏览器输入网址,首先向服务器请求HTML、CSS、JS这些静态文件。服务器找到对应文件后,返回给浏览器,浏览器解析并渲染出页面。
-
第二步:动态数据交互
页面上需要动态加载的数据(比如用户信息、商品列表),不会直接写在HTML里。而是通过AJAX技术,由前端JS代码异步向后台发送请求。
-
第三步:后台处理与数据库交互
后台的Servlet 接收AJAX请求,执行业务逻辑(比如验证用户身份、查询数据)。如果需要操作数据库,就通过JDBC(Java数据库连接)接口与MySQL通信。
-
第四步:数据返回与页面更新
后台把处理结果(通常是JSON格式)返回给前端,前端JS拿到数据后,动态更新页面的对应部分,整个过程不需要刷新整个页面。
最常见的两个错误码
- 404 Not Found:资源不存在。服务器找不到你请求的文件或接口,90%的情况是路径写错了。
- 500 Internal Server Error:服务器内部错误。后台代码执行出错了,比如空指针异常、数据库连接失败等。
二、本地开发环境:Tomcat与404错误详解
在开发阶段,我们不会直接把代码部署到远程服务器,而是在自己的电脑上搭建本地开发环境,这时候最常用的就是Tomcat 服务器。
本地URL的构成
本地开发时访问项目的URL格式是固定的:
http://localhost:8080/项目名称/xxx.htmlhttp:传输协议,规定了浏览器和服务器之间通信的规则localhost:特殊的域名,指向你自己的电脑,等价于IP地址127.0.0.18080:Tomcat的默认端口号。一台电脑可以同时运行多个程序,每个程序用不同的端口号区分,比如QQ用7788端口,微信用其他端口。/项目名称:你在Tomcat中部署的项目的上下文路径/xxx.html:你要访问的具体文件或接口路径
404错误的完整排查思路
当页面显示404时,按照以下顺序排查,效率最高:
- 检查URL是否正确,特别是项目名称 和文件名,Linux系统区分大小写
- 检查文件是否真的存在于项目的正确目录下(通常是webapp目录)
- 检查项目是否已经成功部署到Tomcat,Tomcat控制台有没有报错
- 检查Tomcat是否已经启动,端口号是否被其他程序占用
三、网络基础:数据是怎么从你的电脑传到百度的
很多人用了十几年互联网,却不知道当你在浏览器输入www.baidu.com并按下回车后,数据到底经历了什么。这部分是理解网络编程的基础。
三个核心地址的区别
| 地址类型 | 层级 | 作用 | 特点 |
|---|---|---|---|
| MAC地址 | 数据链路层 | 局域网内定位设备 | 网卡的物理地址,全球唯一,出厂时固化,不可更改 |
| IP地址 | 网络层 | 互联网上定位电脑 | 逻辑地址,可以动态分配。分为网络部分 和主机部分,就像家庭地址的"省市区+门牌号" |
| 域名 | 应用层 | 方便人类记忆 | 比如www.baidu.com,需要通过DNS解析成IP地址才能使用 |
数据在网络中的传输过程
数据在互联网中传输时,会被层层封装,最终变成二进制的比特流在网线中传输。一个完整的数据包结构如下:
[数据] + [源IP地址] + [目标IP地址] + [源MAC地址] + [目标MAC地址]寻址过程分为两步:
- IP寻址:通过目标IP地址,找到目标电脑所在的网络
- MAC寻址:在目标局域网内,通过目标MAC地址,找到具体的设备
DNS:互联网的电话簿
因为IP地址是一串数字,非常难记,所以人类发明了域名系统(DNS)。DNS的作用就是把人类容易记忆的域名,转换成电脑能识别的IP地址。
当你输入www.baidu.com时,DNS解析过程如下:
- 浏览器先查自己的本地缓存,看有没有这个域名对应的IP
- 如果没有,就查操作系统的本地缓存
- 如果还没有,就向你网络运营商的DNS服务器发送请求
- 运营商DNS服务器如果也不知道,就会向上级DNS服务器查询,直到找到权威DNS服务器
- 最终得到百度服务器的IP地址
188.69.57.22(示例)
四、互联网的层级结构:从村到全球
互联网不是一个单一的网络,而是由无数个小网络连接而成的巨大网络。它的结构和我们的行政区划非常相似:
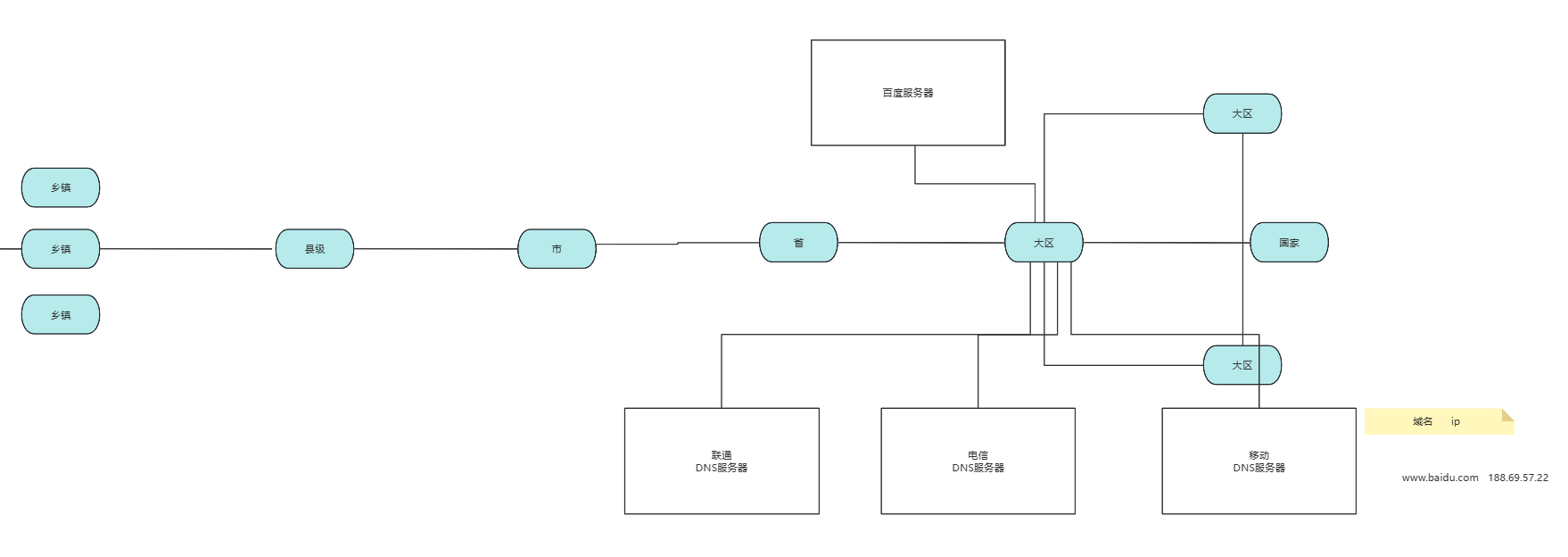
用户电脑 → 村L3交换机 → 乡镇节点 → 县级节点 → 市级节点 → 省级节点 → 大区节点 → 国家骨干网 → 百度服务器- 三大运营商:联通、电信、移动各自拥有自己的全国性骨干网络,它们之间在国家节点处互联互通
- DNS服务器层级:每个运营商都有自己的DNS服务器,从省级到大区再到国家级,形成一个分布式的查询系统
- CDN加速:为了让不同地区的用户都能快速访问,大公司会在全国各个大区都部署服务器,把静态资源缓存到离用户最近的节点
五、完整流程总结
现在,我们把整个过程串起来,当你在浏览器输入www.baidu.com并按下回车后,发生了以下事情:
- 浏览器解析URL,提取出域名
www.baidu.com - 浏览器向DNS服务器发送请求,解析得到百度服务器的IP地址
- 浏览器与百度服务器建立TCP连接(三次握手)
- 浏览器发送HTTP请求,请求百度的首页HTML文件
- 请求数据包经过层层路由器和交换机,通过IP寻址和MAC寻址,最终到达百度服务器
- 百度服务器处理请求,生成HTML页面,通过HTTP响应返回给浏览器
- 浏览器解析HTML,遇到CSS和JS文件时,再次发送请求获取
- 浏览器把所有资源渲染成我们看到的百度首页
- 当你在搜索框输入内容并点击搜索时,浏览器通过AJAX发送请求,后台处理后返回搜索结果,前端动态更新页面
写在最后
很多初学者一上来就埋头写代码,却忽略了这些最基础的底层原理。其实当你理解了整个数据流之后,再去学Servlet、Spring Boot这些框架,就会发现它们只是把这些底层过程做了封装,让你不用再写重复的代码而已。
建立全局观,再深入细节,这是学习任何技术的最佳路径。