PyTorch强化学习实战(7)------表格学习与贝尔曼方程
0. 前言
我们已经学习了交叉熵方法及其优缺点。本节将探讨另一类更灵活、更强大的方法:Q学习。以 FrozenLake 环境为例,并探索Q学习如何与该环境结合,解决其不确定性相关问题。尽管本节使用的环境相对简单,但为深度Q学习方法奠定了基础。
1. 价值、状态和最优性
状态价值可以定义为从状态中获得的期望总奖励(可选择是否进行折扣)。其数学表达式为:
V ( s ) = E ∑ t 0 ∞ r t γ t V(s)=\mathbb E\\sum_{t_0}\^\\infty r_t\\gamma \^t V(s)=Et0∑∞rtγt
其中, r t r_t rt 是在回合第 t t t 步获得的即时奖励。总奖励可以使用 0 < γ < 1 0 < γ < 1 0<γ<1 的折扣因子进行折扣,或者不进行折扣(当 γ = 1 γ = 1 γ=1 时);这取决于我们的定义。状态价值的计算始终基于智能体所遵循的某个策略。为了便于理解,以一个包含三个状态的简单环境为例(如下图所示):
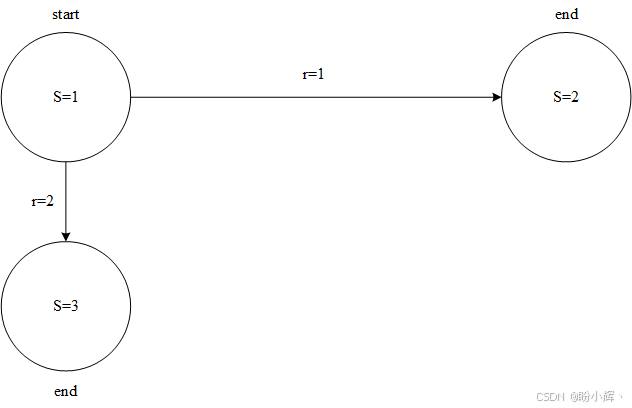
- 智能体的初始状态
- 从初始状态执行"向右"动作后的最终状态,获得的奖励为
1 - 执行"向下"动作后的最终状态,获得的奖励为
2
环境始终是确定性的------每个动作都会成功,且我们总是从状态 1 开始。一旦到达状态 2 或状态 3,当前回合结束。现在的问题是:状态 1 的价值是多少?如果没有关于智能体行为(即其策略)的信息,这个问题是无意义的。即使在这个简单环境中,智能体也可能有无限多种行为方式,每种方式下状态 1 的价值都不同。例如:
- 智能体总是向右
- 智能体总是向下
- 智能体以
50%概率向右、50%概率向下 - 智能体在
10%的情况下向右,90%的情况下执行"向下"动作
为了说明价值如何计算,我们对上述每种策略都进行计算:
- 对于"总是向右"的智能体,状态1的价值是
1.0(每次向左移动获得1,回合结束) - 对于"总是向下"的智能体,状态
1的价值是2.0 - 对于
50%向右/50%向下的智能体,状态1的价值为1.0×0.5 + 2.0×0.5 = 1.5 - 对于
10%向右/90%向下的智能体,状态1的价值为1.0×0.1 + 2.0×0.9 = 1.9
另一个问题:智能体的最优策略是什么?强化学习的目标是获取尽可能多的总奖励。在这个单步环境中,总奖励等于状态 1 的价值,显然,在策略 2 (总是向下)下,状态 1 的价值最大。
但这种具有明显最优策略的简单环境在实际中并不常见。对于复杂环境,最优策略更难设计,甚至更难证明其最优性。接下来,我们将逐步实现让计算机自主学习最优行为的目标。
在以上示例中,可能会误以为我们应该总是选择奖励最高的动作,但实际情况并非如此简单。为了说明这一点,让以上环境增加一个从状态 3 可达的新状态 4。状态 3 不再是一个终止状态,而是可以转移到状态 4,且获得的奖励为 -20。一旦在状态 1 选择"向下"动作,就无法避免获得负奖励,因为从状态 3 只有一条通向状态 4 的路径。因此,对于认为"贪婪策略"有效的智能体来说,这是一个陷阱。
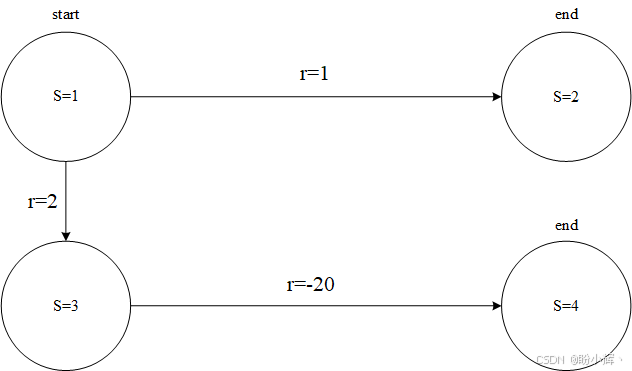
经过这一调整,状态 1 的价值计算方式如下:
- "总是向右"的智能体状态
1的价值保持不变:1.0 - "总是向下"的智能体状态
1的价值:2.0 + (−20) = −18 50%/50%的智能体状态1的价值:0.5×1.0 + 0.5×(2.0 + (−20)) = −8.510%/90%的智能体状态1的价值:0.1×1.0 + 0.9×(2.0 + (−20)) = −16.1
因此,在这个新环境中,最优策略变为策略 1:始终向右。
2. 贝尔曼最优性方程
为了解释贝尔曼方程,先进行一定抽象化说明。我们从确定性场景开始------即所有动作都具有 100% 确定结果的情况。假设智能体处于状态 s 0 s_0 s0,拥有 N N N 个可选动作。每个动作都会导向一个新状态 s 1 . . . s N s_1...s_N s1...sN,并产生对应奖励 r 1 . . . r N r_1...r_N r1...rN。同时假定我们已经知道所有与 s 0 s_0 s0 关联状态的价值 V i V_i Vi。那么,智能体在此状态下应采取的最佳策略是什么?
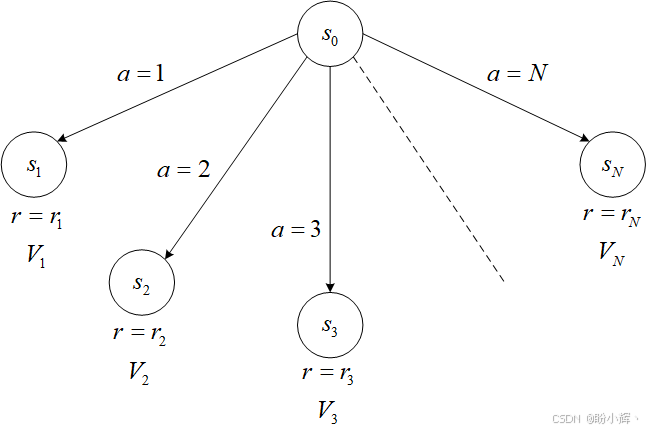
如果选择具体动作 a i a_i ai,并计算该动作的价值,则其价值为 V 0 ( a = a i ) = r i + V i V_0(a=a_i)=r_i+V_i V0(a=ai)=ri+Vi。因此,为了选择最优动作,智能体需要计算每个动作的预期价值,并选择最大可能的结果。换句话说: V 0 = m a x a ∈ 1 ... N ( r a + V a ) V_0 = max_{a∈1...N}(r_a + V_a) V0=maxa∈1...N(ra+Va)。如果引入折扣因子 γ γ γ,则需要将下一状态的价值乘以 γ γ γ: V 0 = m a x a ∈ 1 ... N ( r a + γ V a ) V_0 = max_{a∈1...N}(r_a + γV_a) V0=maxa∈1...N(ra+γVa)。
这看起来可能与贪心策略示例非常相似,实际上也确实如此。但关键区别在于:不仅考虑动作的即时奖励,还计算即时奖励 + 状态的长期价值。这种方法能避免落入"高即时奖励但后续状态价值极低"的陷阱。
贝尔曼证明了,通过这种扩展,智能体的行为将获得最优结果。因此,上述方程称为 (确定性条件下的)贝尔曼价值方程。
将该思想扩展到随机性情况(即动作可能导致不同状态)并不复杂。此时,我们需要计算每个动作的期望价值,而非仅考虑单一后续状态的价值。举例说明:假设状态 s 0 s_0 s0 下有一个动作,但可能触发三种不同结果:
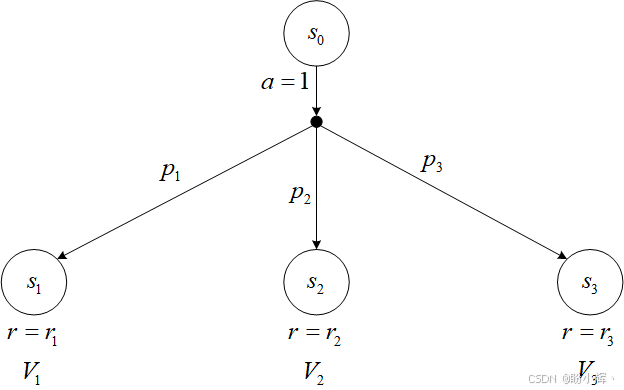
在这种情况下,某个动作可能以不同概率导向三个不同状态。以 p 1 p_1 p1 概率进入状态 s 1 s_1 s1,以 p 2 p_2 p2 的概率进入状态 s 2 s_2 s2,以 p 3 p_3 p3 的概率进入状态 s 3 s_3 s3 (显然 p 1 + p 2 + p 3 = 1 p_1 + p_2 + p_3 = 1 p1+p2+p3=1)。每个目标状态对应各自的奖励( r 1 r_1 r1、 r 2 r_2 r2 或 r 3 r_3 r3)。为了计算执行该动作后的期望价值,需要将所有价值乘以它们的概率并求和:
V 0 ( a = 1 ) = p 1 ( r 1 + γ V 1 ) + p 2 ( r 2 + γ V 2 ) + p 3 ( r 3 + γ V 3 ) V_0(a=1)=p_1(r_1+\gamma V_1)+p_2(r_2+\gamma V_2)+p_3(r_3+\gamma V_3) V0(a=1)=p1(r1+γV1)+p2(r2+γV2)+p3(r3+γV3)
或更规范地表示为:
V 0 ( a ) = E s ∼ S r s , a + γ V s = ∑ s ∈ S p a , 0 → s ( r s , a + γ V s ) V_0(a)=\mathbb E_{s\sim S}r_{s,a}+\\gamma V_s=\sum_{s\in S}p_{a,0\rightarrow s}(r_{s,a}+\gamma V_s) V0(a)=Es∼Srs,a+γVs=s∈S∑pa,0→s(rs,a+γVs)
其中符号 E s ∼ S \mathbb E_{s\sim S} Es∼S 表示对状态空间 S S S 所有可能状态取期望值。
将确定性情况的贝尔曼方程与随机动作的期望价值计算结合,得到通用形式的贝尔曼最优性方程:
V 0 = m a x a ∈ A E s ∼ S r s , a + γ V s = m a x a ∈ A ∑ s ∈ S p a , 0 → s ( r s , a + γ V s ) V_0=max_{a\in A}\mathbb E_{s\sim S}r_{s,a}+\\gamma V_s=max_{a\in A}\sum_{s\in S}p_{a,0\rightarrow s}(r_{s,a}+\gamma V_s) V0=maxa∈AEs∼Srs,a+γVs=maxa∈As∈S∑pa,0→s(rs,a+γVs)
其中, p a , i → j p_{a,i\rightarrow j} pa,i→j 表示在状态 i i i 中执行动作 a a a 后转移到状态 j j j 的概率。其核心含义依然不变:状态的最优价值等于能带来最大期望即时奖励的动作,加上后续状态的折扣长期价值。值得注意的是,该定义具有递归性------状态价值通过其直接可达状态的价值来定义。这种看似"循环论证"的手法(假设已知解来定义解)实为计算机科学乃至数学中的经典方法(如数学归纳法)。贝尔曼方程不仅是强化学习的基石,更是动态规划这一通用优化方法的核心,后者被广泛应用于解决现实世界的复杂优化问题。
这些状态价值不仅能告诉我们可获得的最佳奖励,而且基本上给出了获得该奖励的最优策略:如果我们的代理知道每个状态的值,那么它就自动知道如何获取这个奖励。得益于贝尔曼的最优性证明,智能体在任意状态下只需选择具有最大期望收益的动作------也就是即时奖励与折扣长期奖励之和,如此即可实现最优决策。因此,准确计算这些价值具有重大意义。
3. 动作价值函数
为简化问题,我们除了定义状态价值 V ( s ) V(s) V(s) 外,还可定义动作价值 Q ( s , a ) Q(s,a) Q(s,a)。其本质表示在状态 s s s 执行动作 a a a 能获得的总收益,可通过 V ( s ) V(s) V(s) 推导得出。虽然 Q ( s , a ) Q(s,a) Q(s,a) 的理论重要性不及 V ( s ) V(s) V(s),但它却催生了著名的Q学习 (Q-learning) 方法,其在实际应用中更为便捷。这类方法的核心目标就是计算所有状态-动作对的Q值:
Q ( s , a ) = E s ′ ∼ S r ( s , a ) + γ V ( s ′ ) = ∑ s ′ ∈ S p a , s → s ′ ( r ( s , a ) + γ V ( s ′ ) ) Q(s,a)=\mathbb E_{s'\sim S}r(s,a)+\\gamma V(s')=\sum_{s'\in S}p_{a,s\rightarrow s'}(r(s,a)+\gamma V(s')) Q(s,a)=Es′∼Sr(s,a)+γV(s′)=s′∈S∑pa,s→s′(r(s,a)+γV(s′))
其中 s ′ s′ s′ 表示执行动作后的新状态。动作价值 Q ( s , a ) Q(s,a) Q(s,a) 可理解为即时奖励与后续状态折扣价值的期望总和。反过来,状态价值 V ( s ) V(s) V(s) 也可通过 Q ( s , a ) Q(s,a) Q(s,a) 表示:
V ( s ) = m a x a ∈ A Q ( s , a ) V(s)=max_{a\in A}Q(s,a) V(s)=maxa∈AQ(s,a)
这意味着某状态的价值等于从该状态可执行动作中的最大动作价值。更进一步,我们还能递归定义 Q ( s , a ) Q(s,a) Q(s,a):
Q ( s , a ) = r ( s , a ) + γ m a x a ′ ∈ A Q ( s ′ , a ′ ) Q(s,a)=r(s,a)+\gamma max_{a'\in A} Q(s',a') Q(s,a)=r(s,a)+γmaxa′∈AQ(s′,a′)
在关于即时奖励的下标标注 ( s , a ) (s,a) (s,a) 需注意环境设定差异:
- 动作触发奖励:若奖励在状态 s s s 执行动作 a a a 后立即获得,使用索引 ( s , a ) (s,a) (s,a),并保持上述公式形式。
- 状态到达奖励:若奖励在通过动作 a ′ a′ a′ 进入状态 s ′ s′ s′ 时获得,则使用索引 ( s ′ , a ′ ) (s', a') (s′,a′),并且需要移动到最大操作符 m a x max max 中:
Q ( s , a ) = m a x a ′ ∈ A ( r ( s ′ , a ′ ) + γ Q ( s ′ , a ′ ) ) Q(s,a)=max_{a'\in A}(r(s',a')+\gamma Q(s',a')) Q(s,a)=maxa′∈A(r(s′,a′)+γQ(s′,a′))
虽然数学本质相同,但这对算法实现有重要影响。第一种情况更为常见,后续我们将沿用其公式。
假设有一个结构比 FrozenLake 更简单的环境:有一个初始状态 s 0 s_0 s0,四个目标状态 s 1 , s 2 , s 3 , s 4 s_1, s_2, s_3, s_4 s1,s2,s3,s4:
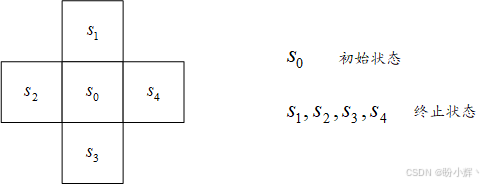
每个动作都像 FrozenLake 环境一样具有随机性:33% 概率正确执行选定动作;33% 概率相对目标位置向左偏移,33% 概率相对目标位置向右偏移。为简化计算,我们设折扣因子 γ = 1 γ=1 γ=1 (即不考虑未来奖励的衰减)。
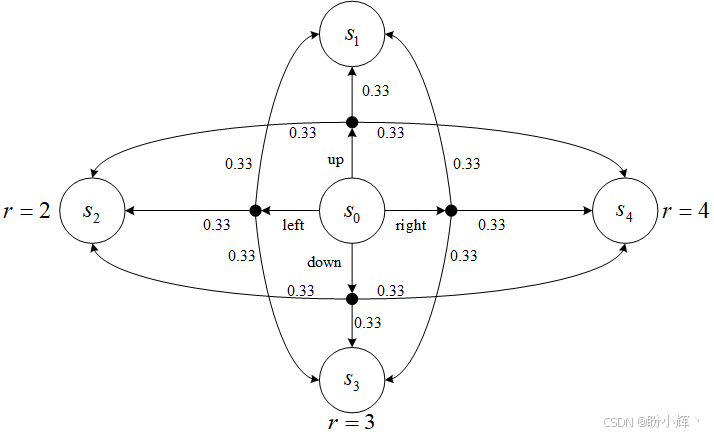
首先计算各动作价值。终止状态 s 1 s_1 s1 到 s 4 s_4 s4 没有外部连接,因此这些状态的所有行动的Q值为零。因此,终止状态的价值等于它们的即时奖励(到达终止状态后,回合结束,没有后续的状态): V 1 = 1 , V 2 = 2 , V 3 = 3 , V 4 = 4 V_1 = 1, V_2 = 2, V_3 = 3, V_4 = 4 V1=1,V2=2,V3=3,V4=4。
状态 s 0 s_0 s0 的动作价值计算更为复杂。以"向上"动作为例,其价值等于即时奖励与后续长期价值的期望和。由于该动作所有可能的转移都会直接进入终止状态,没有后续步骤可以进行任何转移:
Q ( s 0 , u p ) = 0.33 ⋅ V 1 + 0.33 ⋅ V 2 + 0.33 ⋅ V 4 = 0.33 ⋅ ( 1 + 2 + 4 ) = 2.31 Q(s_0,up)=0.33 \cdot V_1+0.33 \cdot V_2+0.33 \cdot V_4=0.33 \cdot (1+2+4)=2.31 Q(s0,up)=0.33⋅V1+0.33⋅V2+0.33⋅V4=0.33⋅(1+2+4)=2.31
同理可计算其他动作价值:
Q ( s 0 , l e f t ) = 0.33 ⋅ V 1 + 0.33 ⋅ V 2 + 0.33 ⋅ V 3 = 1.98 Q ( s 0 , r i g h t ) = 0.33 ⋅ V 4 + 0.33 ⋅ V 1 + 0.33 ⋅ V 3 = 2.64 Q ( s 0 , d o w n ) = 0.33 ⋅ V 3 + 0.33 ⋅ V 2 + 0.33 ⋅ V 4 = 2.97 Q(s_0, left) = 0.33 \cdot V_1 + 0.33 \cdot V_2 + 0.33 \cdot V_3 = 1.98\\ Q(s_0, right) = 0.33 \cdot V_4 + 0.33 \cdot V_1 + 0.33 \cdot V_3 = 2.64\\ Q(s_0, down) = 0.33 \cdot V_3 + 0.33 \cdot V_2 + 0.33 \cdot V_4 = 2.97\\ Q(s0,left)=0.33⋅V1+0.33⋅V2+0.33⋅V3=1.98Q(s0,right)=0.33⋅V4+0.33⋅V1+0.33⋅V3=2.64Q(s0,down)=0.33⋅V3+0.33⋅V2+0.33⋅V4=2.97
最终 s 0 s_0 s0 的状态价值取这些动作价值的最大值 2.97。
在实践中,Q值比状态价值V更实用,因为智能体基于Q值做出动作决策要比基于V值简单得多。对于Q值而言,智能体只需根据当前状态计算所有可行动作对应的Q值,然后选择Q值最大的动作即可。而若要通过状态价值函数实现相同目标,智能体不仅需要掌握状态价值,还需了解状态转移概率。由于实际场景中我们往往无法预先获知这些概率,智能体不得不针对每个状态-动作组合估算转移概率。后续将通过 FrozenLake 环境的两种解法来具体演示这一过程。然而在此之前,我们还需要解决一个关键问题:如何以一种通用的方式计算 V i V_i Vi 和 Q i Q_i Qi。
4. 价值迭代方法
在前述简单示例中,我们通过利用环境的特殊结构(状态转移无循环)来计算状态和动作价值:从终止状态开始计算其价值,再逐步推导至中心状态。然而只要环境中存在一个循环,这种方法就会失效。假设某个环境包含两个状态:
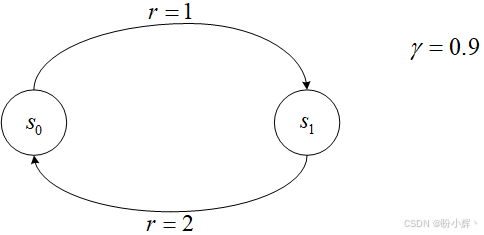
我们从状态 s 1 s_1 s1 出发,此时唯一可执行的动作将引导我们进入状态 s 2 s_2 s2。在此过程中获得奖励 r = 1 r=1 r=1,而从 s 2 s_2 s2 出发的唯一转移动作又会将我们带回 s 1 s_1 s1。因此,智能体的生命周期将形成无限循环的状态序列 s 1 , s 2 , s 1 , s 2 , ... s_1, s_2, s_1, s_2,... s1,s2,s1,s2,...。为处理这种无限循环,我们可以引入折扣因子 γ = 0.9 γ=0.9 γ=0.9。现在的问题是:这两个状态的价值该如何计算?事实上答案并不复杂。每次从 s 1 s_1 s1 转移到 s 2 s_2 s2 可获得奖励 1,而每次反向转移则获得奖励 2。因此我们的奖励序列呈现 [1,2,1,2,1,2,...] 的交替模式。由于每个状态仅存在单一可选动作,实际上无需进行最大化运算,公式中的 max 操作可以省略。
每个状态的值将等于无限和:
V ( s 1 ) = 1 + γ ( 2 + γ ( 1 + γ ( 2 + ... ) ) ) = ∑ i = 0 ∞ 1 γ 2 i + 2 γ 2 i + 1 V ( s 2 ) = 2 + γ ( 1 + γ ( 2 + γ ( 1 + ... ) ) ) = ∑ i = 0 ∞ 2 γ 2 i + 1 γ 2 i + 1 V(s_1) = 1 + \gamma(2 + \gamma(1 + \gamma(2 + \dots))) = \sum_{i=0}^{\infty} 1 \gamma^{2i} + 2 \gamma^{2i+1} \\ V(s_2) = 2 + \gamma(1 + \gamma(2 + \gamma(1 + \dots))) = \sum_{i=0}^{\infty} 2 \gamma^{2i} + 1 \gamma^{2i+1} V(s1)=1+γ(2+γ(1+γ(2+...)))=i=0∑∞1γ2i+2γ2i+1V(s2)=2+γ(1+γ(2+γ(1+...)))=i=0∑∞2γ2i+1γ2i+1
严格来说,我们无法计算出状态的精确价值,但在 γ = 0.9 γ=0.9 γ=0.9 的折扣因子下,每次转移的贡献值会随时间快速衰减。例如:10 步后 γ 10 ≈ 0.349 γ^{10}≈0.349 γ10≈0.349,而 100 步后衰减至 0.0000266。基于此特性,我们仅需迭代 50 次即可获得足够精确的估值:
shell
>>> sum([0.9**(2*i) + 2*(0.9**(2*i+1)) for i in range(50)])
14.736450674121663
>>> sum([2*(0.9**(2*i)) + 0.9**(2*i+1) for i in range(50)])
15.262752483911719上述示例揭示了价值迭代算法的核心思想------该算法能通过数值计算求解马尔可夫决策过程 (Markov Decision Process, MDP)的状态价值与动作价值(需已知转移概率和奖励机制)。该过程(针对状态值)计算流程如下:
- 初始化:将所有状态价值 V i V_i Vi 的初始值设置为某个初始值(通常为零)
- 对于
MDP中的每个状态 s s s,执行贝尔曼更新:
V s ← m a x a ∑ s ′ p a , s → s ′ ( r s , a , s ′ + γ V s ′ ) V_s\leftarrow \underset {a}{max}\sum_{s'}p_{a,s\rightarrow s'}(r_{s,a,s'}+\gamma V_{s'}) Vs←amaxs′∑pa,s→s′(rs,a,s′+γVs′) - 重复步骤
2直至达到最大迭代次数或价值变化收敛
但在实际应用中,这种方法存在明显的局限性。首先,我们的状态空间必须是离散的,并且要足够小以便对所有状态进行多次迭代。对于 4x4 的 FrozenLake (甚至更具挑战性的 8x8 版本)这不成问题,但对于 CartPole 环境,情况就复杂得多。CartPole 的观测值是四个浮点数,代表系统的物理特征。这些数值的细微差异都可能影响状态价值。解决方案之一是对观测值进行离散化处理------例如将 CartPole 的观测空间划分为若干区间,每个区间视为独立的离散状态。但这会引发一系列实际问题:区间间隔该设多大?需要多少环境数据才能准确估算价值?我们将在后续介绍神经网络在Q学习中的应用时解决这个问题。
第二个实际难题在于:我们几乎无法预先获知状态转移概率矩阵和奖励矩阵。根据 Gymnasium 提供给智能体的接口:我们观测到状态后选择动作,之后才能获得转移后的新观测值和奖励。若不查看 Gymnasium 环境源代码,我们根本不知道从状态 s 0 s_0 s0 执行动作 a 0 a_0 a0 转移到状态 s 1 s_1 s1 的概率。我们拥有的只是智能体与环境交互的历史记录。但贝尔曼更新需要每个转移的奖励及其概率,因此解决方案很明确:用智能体经验来估算这两个未知量。奖励值可以直接使用,只需记住从 s 0 s_0 s0 通过动作 a a a 转移到 s 1 s_1 s1 时获得的奖励;而要估算概率,则需要为每个三元组 ( s 0 , s 1 , a ) (s_0,s_1,a) (s0,s1,a) 维护计数器并做归一化处理。
了解理论基础后,接下来在实践中进行应用。
5. 价值迭代实践
接下来,我们将讨论价值迭代方法如何应用于 FrozenLake。核心数据结构如下:
- 奖励表 (reward table):一个复合键字典,键由"原状态+动作+目标状态"组成,其值为即时奖励值
- 转移表 (transitions table) :该字典记录已发生的状态转移次数。其键为复合的"状态+动作",值则是另一个字典------该字典将"目标状态"映射到该状态出现的次数。例如,在状态
0中执行动作10次,其中3次转移到状态4,7次转移到状态5。那么该表中键(0,1)对应的值就是{4:3, 5:7}。通过这个表我们可以估算状态转移概率 - 价值表 (value table):将状态映射到其计算价值的字典
代码的核心逻辑非常简单:在循环中,我们首先执行 100 次随机动作来探索环境,填充奖励表和转移表。完成这 100 步后,对所有状态进行价值迭代循环,更新价值表。接着运行若干完整回合,用更新后的价值表检验效果。若测试回合的平均奖励超过 0.8 阈值,则停止训练。测试回合期间同样会更新奖励表和转移表以充分利用环境数据。
(1) 首先导入必要的包并定义常量,随后设置几个类型别名:
python
import typing as tt
import gymnasium as gym
from collections import defaultdict, Counter
from torch.utils.tensorboard.writer import SummaryWriter
ENV_NAME = "FrozenLake-v1"
GAMMA = 0.9
TEST_EPISODES = 20在 FrozenLake 环境中,观测空间和动作空间都属于 Box 类,因此状态和动作都用整型 (int) 值表示。我们还需要为奖励表和转移表的键定义类型型。对于奖励表,键是一个元组 [State, Action, State],而对于转移表,键是 [State, Action]:
python
State = int
Action = int
RewardKey = tt.Tuple[State, Action, State]
TransitKey = tt.Tuple[State, Action](2) 然后,定义 Agent 类,该类将维护所有表格并包含训练循环中需要用到的函数。在类的构造函数中,我们创建用于数据采样的环境,获取初始观测值,并初始化奖励表、转移表和价值表:
python
class Agent:
def __init__(self):
self.env = gym.make(ENV_NAME)
self.state, _ = self.env.reset()
self.rewards: tt.Dict[RewardKey, float] = defaultdict(float)
self.transits: tt.Dict[TransitKey, Counter] = defaultdict(Counter)
self.values: tt.Dict[State, float] = defaultdict(float)(3) play_n_random_steps 函数用于从环境中收集随机经验并更新奖励表和转移表。需要注意的是,我们不需要等待整个回合结束才开始学习------只需执行 N 步并记录结果即可。这是价值迭代与交叉熵法的区别之一,后者必须依赖完整回合数据进行学习:
python
def play_n_random_steps(self, n: int):
for _ in range(n):
action = self.env.action_space.sample()
new_state, reward, is_done, is_trunc, _ = self.env.step(action)
rw_key = (self.state, action, new_state)
self.rewards[rw_key] = float(reward)
tr_key = (self.state, action)
self.transits[tr_key][new_state] += 1
if is_done or is_trunc:
self.state, _ = self.env.reset()
else:
self.state = new_state(4) 函数 calc_action_value() 利用转移、奖励和价值表,从状态出发计算行动的价值。该函数将用于两个场景:从当前状态选择最佳执行动作,以及在价值迭代中计算状态的新价值。具体实现流程如下:
- 从转移表中提取给定状态和动作对应的转移计数器。这些计数器以字典形式存储,键为目标状态,值为实际发生的转移次数。汇总所有计数器值,得到该状态下执行此动作的总次数,后续将用此总次数将单个计数器值转换为概率
- 然后遍历该动作可能到达的所有目标状态,根据贝尔曼方程计算每个状态对动作总价值的贡献值。这个贡献等于即时奖励加上目标状态的折扣价值,将该求和结果乘以对应的转移概率,然后将乘积累积到最终动作价值中
下图直观展示了该计算逻辑:
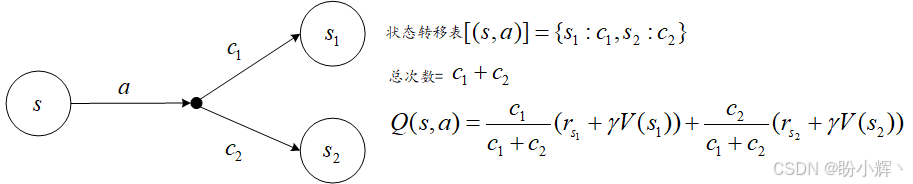
在上图所示的计算过程中,我们针对状态s和动作a进行价值评估。假设在历史经验中,我们已多次执行该动作(总次数 c 2 + c 2 c_2 + c_2 c2+c2),且最终会进入 s 1 s_1 s1 或 s 2 s_2 s2 其中一种状态。转移表中以字典形式 s 1 : c 1 , s 2 : c 2 {s_1:c_1, s_2:c_2} s1:c1,s2:c2 记录了转移到各目标状态的次数。
此时,该状态动作对的价值估值 Q ( s , a ) Q(s,a) Q(s,a) 可表示为:各目标状态转移概率与其对应状态价值的乘积之和。根据贝尔曼方程,每个目标状态的价值等于即时奖励与折扣后长期价值之和:
python
def calc_action_value(self, state: State, action: Action) -> float:
target_counts = self.transits[(state, action)]
total = sum(target_counts.values())
action_value = 0.0
for tgt_state, count in target_counts.items():
rw_key = (state, action, tgt_state)
reward = self.rewards[rw_key]
val = reward + GAMMA * self.values[tgt_state]
action_value += (count / total) * val
return action_value(5) select_action() 函数使运用上述方法,从给定状态中确定最佳动作。它会遍历环境中所有可能动作,计算每个动作的价值。最终选择价值最大的动作作为执行目标。由于 play_n_random_steps() 函数已提供充分探索,这个动作选择过程是确定性的。因此我们的智能体会基于价值近似结果采取贪婪策略:
python
def select_action(self, state: State) -> Action:
best_action, best_value = None, None
for action in range(self.env.action_space.n):
action_value = self.calc_action_value(state, action)
if best_value is None or best_value < action_value:
best_value = action_value
best_action = action
return best_action(6) play_episode() 函数通过调用 select_action() 选择最优动作,并利用给定的环境完整运行一个回合。该函数专门用于测试回合的运行------在此期间我们需要保持主环境(用于收集随机数据)的当前状态不受干扰,因此使用传入的第二个环境作为测试环境。其逻辑非常简单,只需循环遍历状态并累计单回合奖励:
python
def play_episode(self, env: gym.Env) -> float:
total_reward = 0.0
state, _ = env.reset()
while True:
action = self.select_action(state)
new_state, reward, is_done, is_trunc, _ = env.step(action)
rw_key = (state, action, new_state)
self.rewards[rw_key] = float(reward)
tr_key = (state, action)
self.transits[tr_key][new_state] += 1
total_reward += reward
if is_done or is_trunc:
break
state = new_state
return total_reward(7) 最后,实现 Agent 类的价值迭代方法。遍历环境中所有状态,针对每个状态计算其可达状态的价值,从而得到该状态的候选价值集合,然后以当前状态可用动作的最大价值更新状态价值:
python
def value_iteration(self):
for state in range(self.env.observation_space.n):
state_values = [
self.calc_action_value(state, action)
for action in range(self.env.action_space.n)
]
self.values[state] = max(state_values)(8) 实现训练循环和代码监控模块:
python
if __name__ == "__main__":
test_env = gym.make(ENV_NAME)
agent = Agent()
writer = SummaryWriter(comment="-v-iteration")(9) 创建用于测试的环境实例、Agent 类实例以及 TensorBoard 的记录器:
python
iter_no = 0
best_reward = 0.0
while True:
iter_no += 1
agent.play_n_random_steps(100)
agent.value_iteration()以上代码片段中的最后两行是训练循环中的关键部分。首先执行 100 次随机探索步骤,用最新数据填充奖励表和状态转移表,随后对所有状态执行价值迭代。代码的其余部分使用价值表作为策略运行测试回合,将数据写入 TensorBoard,跟踪最佳平均奖励,并检测训练循环的停止条件:
python
reward = 0.0
for _ in range(TEST_EPISODES):
reward += agent.play_episode(test_env)
reward /= TEST_EPISODES
writer.add_scalar("reward", reward, iter_no)
if reward > best_reward:
print(f"{iter_no}: Best reward updated {best_reward:.3} -> {reward:.3}")
best_reward = reward
if reward > 0.80:
print("Solved in %d iterations!" % iter_no)
break
writer.close()(10) 接下来,运行程序:

我们的解决方案具有随机性,根据实验数据通常需要 10 到 100 次迭代才能收敛,但所有案例均在 1 秒内就能找到成功率 80% 的优秀策略。作为对比,采用交叉熵方法需要约 1 小时才能达到 60% 成功率,所以这是一个巨大的改进。究其原因主要有二:
首先,动作的随机性叠加回合长度(平均 6-10 步)导致交叉熵方法难以判断具体步骤的优劣。而价值迭代通过状态/动作的单独价值,天然融合动作概率结果------既估算转移概率又计算期望价值,因此具有更高的样本效率(即强化学习中的样本利用率),所需环境数据量大幅减少。
其二,价值迭代无需完整回合即可开始学习。极端情况下,单个样本就能触发价值更新。不过在 FrozenLake 环境中,由于奖励结构限制(仅成功抵达目标状态才获得 +1 奖励),仍需至少一次成功回合才能启动有效学习,这在更复杂的环境中可能是一个挑战。例如,尝试将现有代码切换到一个更大的 FrozenLake 版本 FrozenLake8x8-v1,可能需要 150 到 1000 次迭代才能解决,根据 TensorBoard 的可视化结果,大部分时间它都在等待首次成功回合,一旦获得初始成功样本,系统会快速达到收敛。
下图对比了两组训练曲线对比,第一个图显示了在 FrozenLake-4x4 上的训练奖励动态,第二个是 8×8 版本的训练奖励动态。
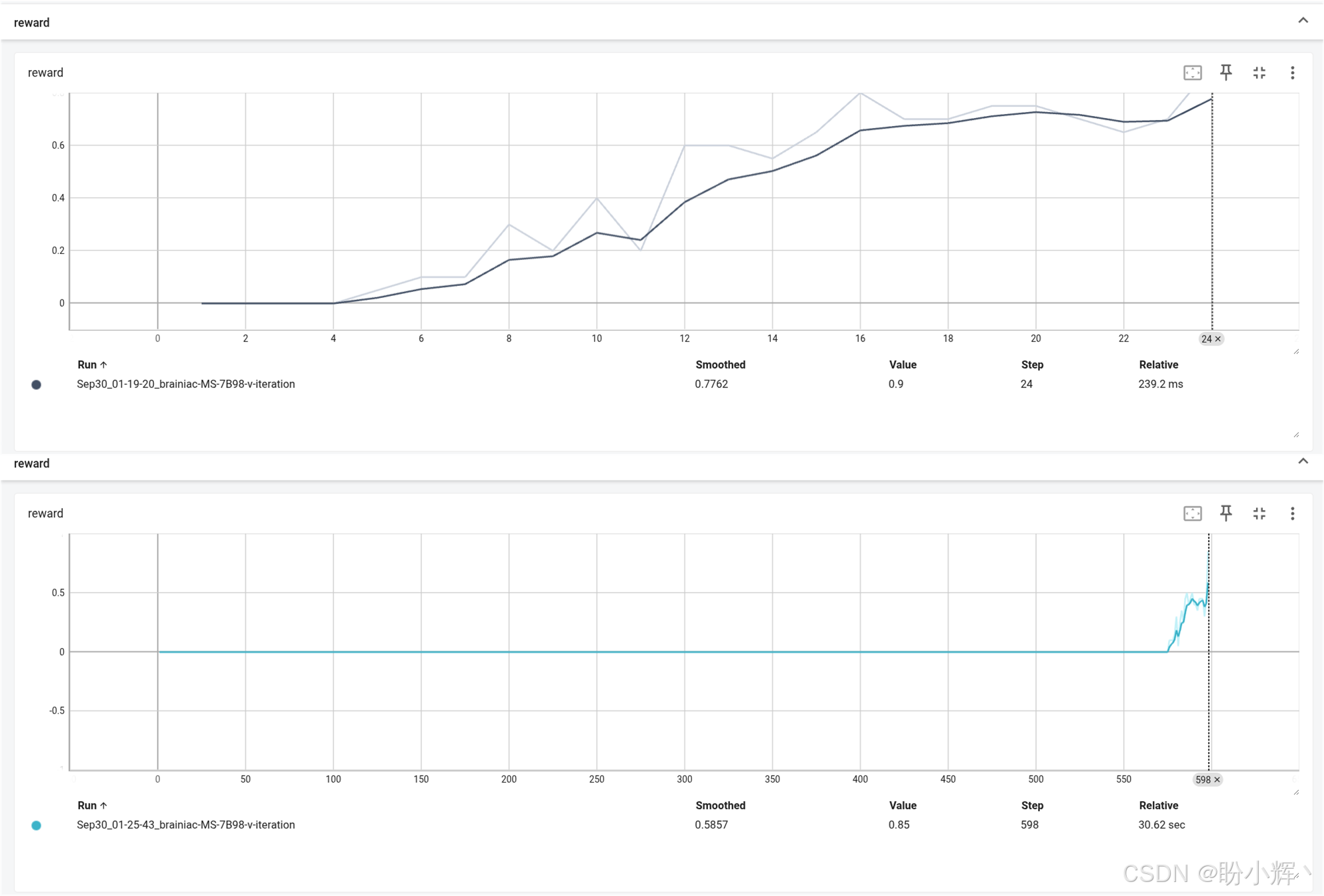
接下来,我们对比状态价值学习代码与动作价值学习代码。
6. Q值迭代
状态价值学习代码与动作价值学习代码差异很小:
- 最明显的变化在于价值表。在之前的示例中,我们存储的是状态价值,因此字典的键仅包含状态 (
state)。而现在需要存储Q函数的值,该函数包含两个参数------状态 (state) 和动作 (action),因此价值表的键变为复合值(State, Action) - 第二个区别是移除了
calc_action_value()函数。由于动作价值已直接存储在价值表中,该函数不再需要 - 最后,代码中最重要的变化在智能体的
value_iteration()方法中。此前它仅是calc_action_value()的封装层,由后者完成贝尔曼近似计算。而随着该函数被价值表取代,我们需要在value_iteration()内部直接实现这一近似计算
(1) 由于大部分逻辑相同,我们直接跳转至最关键的 value_iteration() 函数:
python
def value_iteration(self):
for state in range(self.env.observation_space.n):
for action in range(self.env.action_space.n):
action_value = 0.0
target_counts = self.transits[(state, action)]
total = sum(target_counts.values())
for tgt_state, count in target_counts.items():
rw_key = (state, action, tgt_state)
reward = self.rewards[rw_key]
best_action = self.select_action(tgt_state)
val = reward + GAMMA * self.values[(tgt_state, best_action)]
action_value += (count / total) * val
self.values[(state, action)] = action_value这段代码与前例中的 calc_action_value() 非常相似,实际上功能也几乎相同。对于给定的状态和动作,它需要利用该动作对应的目标状态统计信息来计算动作价值。我们通过贝尔曼方程和状态转移计数器(用于估算目标状态概率)来完成这一计算。但问题在于:贝尔曼方程中需要用到状态价值 (state value),而现在的计算方式已发生变化。
在之前的实现中,状态价值直接存储于价值表(因为我们当时估算的是状态价值),因此可直接查表获取。但现在我们无法这样操作,于是改为调用 select_action 方法------该方法会为我们选择具有最大Q值的动作,我们将该Q值作为目标状态的价值。当然,我们也可以专门编写一个计算状态价值的函数,但由于 select_action 已涵盖大部分所需功能,因此我们将在这里直接复用。
(2) select_action 方法如下:
python
def select_action(self, state: State) -> Action:
best_action, best_value = None, None
for action in range(self.env.action_space.n):
action_value = self.values[(state, action)]
if best_value is None or best_value < action_value:
best_value = action_value
best_action = action
return best_action如前所述,我们不再需要 calc_action_value 方法------在选择动作时,只需遍历所有动作并在价值表中查询其对应Q值。这看似只是微小改进,但若细想 calc_action_value 所依赖的数据,就能理解为何在强化学习中Q函数学习比V函数学习更受青睐。
calc_action_value 函数需要同时依赖奖励信息和状态转移概率。这对依赖此类信息进行训练的价值迭代法并非大问题,但价值迭代扩展方法中(该方法直接从环境采样中获取数据而无需概率估算),这种对概率的依赖反而会成为智能体的额外负担。而Q学习方法中,智能体决策仅需依赖Q值即可。
并非说V函数毫无价值(它们是演员-评论家方法的核心组件),但在价值学习领域,Q函数无疑是更优选择。就收敛速度而言,两种版本几乎相当(但Q学习版本需要四倍于价值表的内存)。
Q学习版本的输出结果如下所示,与价值迭代版本并无显著差异:

小结
在本节中,我们学习了许多深度强化学习中广泛使用的重要概念:状态价值 (state value)、动作价值 (action value) 以及贝尔曼方程 (Bellman equation) 的多种形式。我们还深入探讨了价值迭代法 (value iteration),这一方法是Q学习领域的重要基石。最后,我们介绍了价值迭代如何改进FrozenLake 游戏的解决方案。
系列链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能
PyTorch强化学习实战(4)------PyTorch基础
PyTorch强化学习实战(5)------PyTorch Ignite 事件驱动机制与实践
PyTorch强化学习实战(6)------交叉熵方法详解与实现