前言
作为大数据开发者,深入理解MapReduce的框架原理至关重要。本文将从InputFormat数据输入 、Shuffle机制 、Partition分区 、Combiner合并 、Join应用 和数据压缩六大核心模块,结合源码与架构图,带你彻底搞懂MapReduce的底层设计。
一、MapReduce核心架构回顾
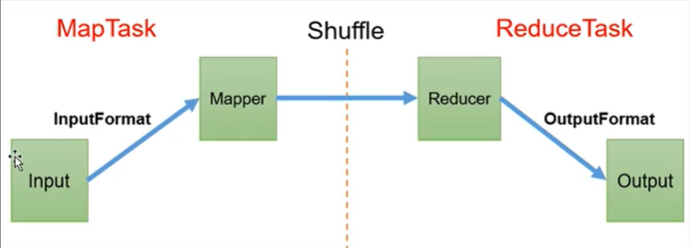
MapReduce程序运行时有三类实例进程:
| 进程 | 职责 |
|---|---|
| MrAppMaster | 负责整个程序的过程调度及状态协调(ApplicationMaster的子类) |
| MapTask | 负责Map阶段的整个数据处理流程 |
| ReduceTask | 负责Reduce阶段的整个数据处理流程 |
注意:在查看进程时,MapTask和ReduceTask显示为
yarnchild,是YARN的子进程。
二、InputFormat数据输入与切片机制
2.1 数据块 vs 数据切片
| 概念 | 说明 | 特点 |
|---|---|---|
| 数据块(Block) | HDFS物理上把数据分成一块一块 | 物理切割,默认128M,存储在不同DataNode |
| 数据切片(Split) | 逻辑上对输入进行分片 | 逻辑切割,不实际切分文件,决定MapTask数量 |
关键原则:
- 一个Job的Map阶段并行度由切片数决定
- 每一个Split切片分配一个MapTask并行实例处理
- 默认情况下,切片大小 = BlockSize(128M)
- 切片时不考虑数据集整体 ,而是逐个针对每一个文件单独切片
2.2 切片源码解析
java
// FileInputFormat.getSplits() 核心逻辑
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 其中 computeSplitSize = Math.max(minSize, Math.min(maxSize, blockSize))参数优先级:
minSize(1) < splitSize < maxSize(Long.MAX_VALUE)默认配置下:splitSize = blockSize = 128M
2.3 切片大小设置
xml
<!-- mapred-site.xml -->
<property>
<name>mapreduce.input.fileinputformat.split.minsize</name>
<value>1</value>
</property>
<property>
<name>mapreduce.input.fileinputformat.split.maxsize</name>
<value>Long.MAX_VALUE</value>
</property>生产环境中,若磁盘传输速度快(如SSD),可将BlockSize和切片大小调整为256M。
2.4 FileInputFormat实现类
| 实现类 | 输入K,V类型 | 特点 |
|---|---|---|
| TextInputFormat | LongWritable, Text | 默认实现,按行读取,K为偏移量 |
| KeyValueTextInputFormat | Text, Text | 按分隔符切割,第0位为K,第1位为V |
| NLineInputFormat | LongWritable, Text | 一次读取N行,效率更高 |
| CombineTextInputFormat | LongWritable, Text | 解决小文件问题,合并多个文件为一个切片 |
2.5 CombineTextInputFormat解决小文件问题
问题场景:大量1KB小文件,每个文件开启一个MapTask(占用1G内存+1个CPU),资源严重浪费。
解决方案:将多个小文件合并成一个切片处理。
java
// 在Driver中设置
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); // 4MB虚拟存储与切片过程:
示例:4个小文件(1.7M、5.1M、3.4M、6.8M),设置maxSize=4M
虚拟存储后:1.7M, (2.55M, 2.55M), 3.4M, (3.4M, 3.4M)
最终切片:(1.7+2.55)M, (2.55+3.4)M, (3.4+3.4)M → 3个切片,3个MapTask三、MapReduce完整工作流程
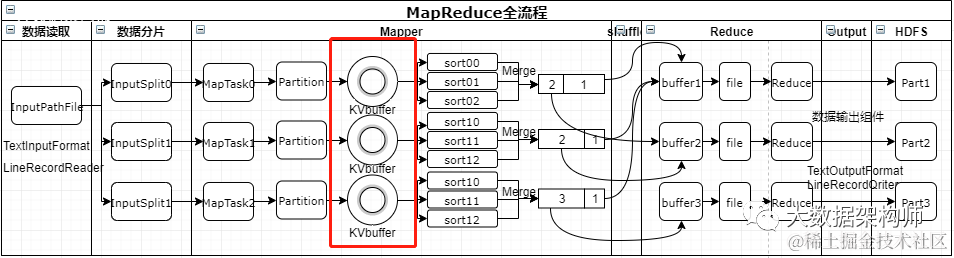
3.1 工作流程详解
| 阶段 | 操作 |
|---|---|
| ① 切片分析 | 客户端对原始文件进行切片,200M文件分成2片(0-128M, 128-200M) |
| ② 提交三样东西 | Jar包、切片规划文件、job.xml(配置参数) |
| ③ 启动MrAppMaster | YARN启动MrAppMaster,读取切片信息,决定MapTask数量 |
| ④ MapTask处理 | 用InputFormat读取数据(默认TextInputFormat→LineRecordReader),K为偏移量,V为行内容 |
| ⑤ Mapper业务逻辑 | 用户自定义map()方法处理数据 |
| ⑥ 输出到环形缓冲区 | 数据进入环形缓冲区,左侧存索引,右侧存数据 |
| ⑦ Shuffle阶段 | 分区→排序→溢写→合并→压缩→Reduce拉取→归并排序→分组 |
| ⑧ Reduce处理 | 用户自定义reduce()方法聚合数据 |
| ⑨ OutputFormat输出 | 默认TextOutputFormat,按行写入HDFS |
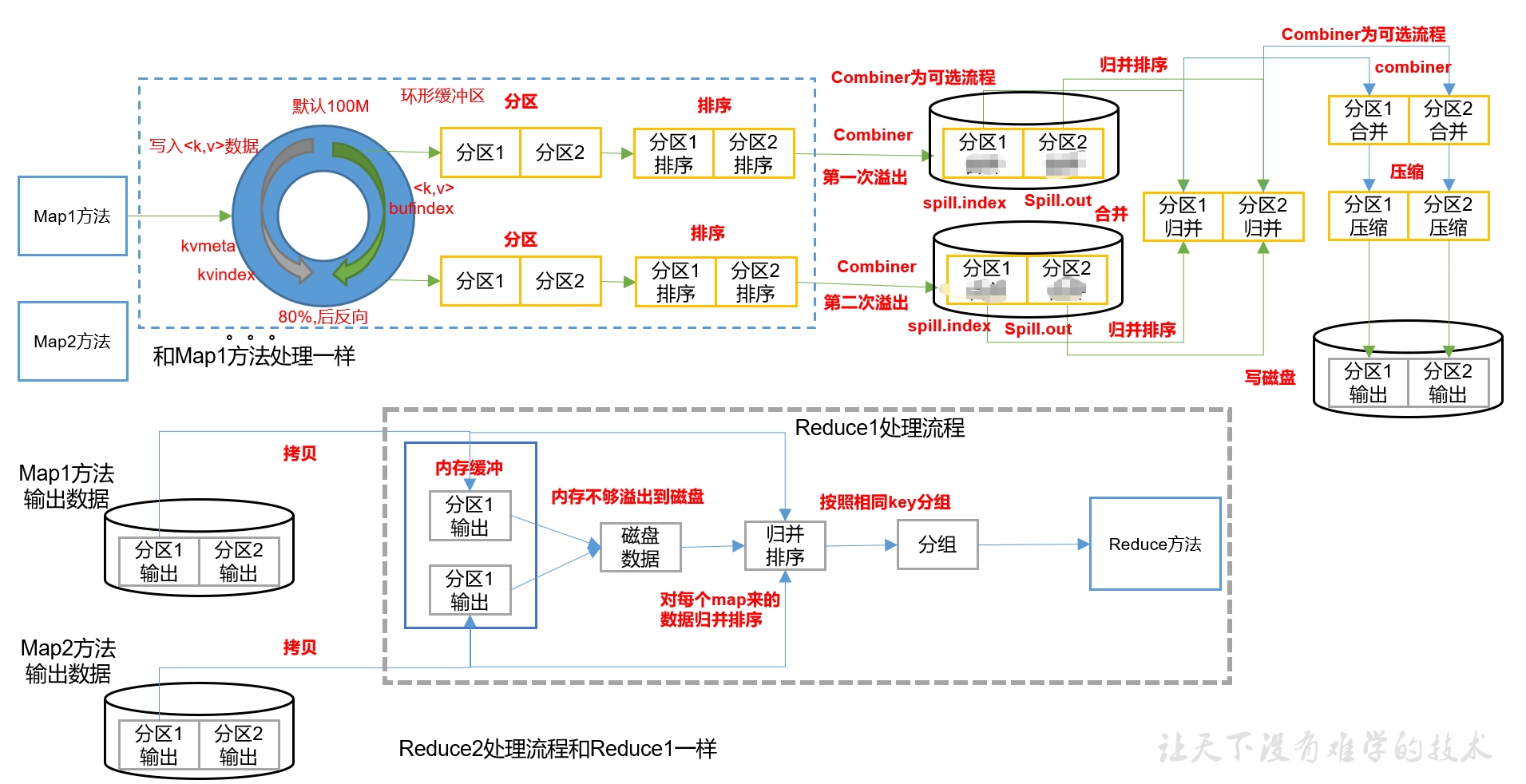
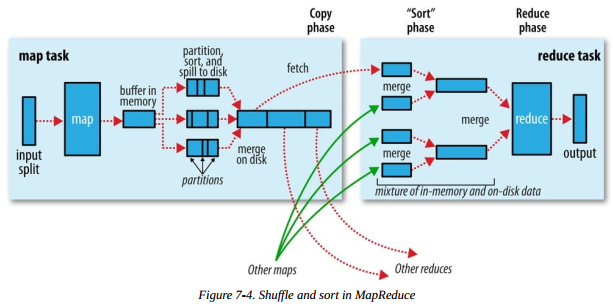
四、Shuffle机制(面试重点)
Shuffle是MapReduce的核心与灵魂,是Map方法之后、Reduce方法之前的数据处理过程。
4.1 环形缓冲区(Map端)
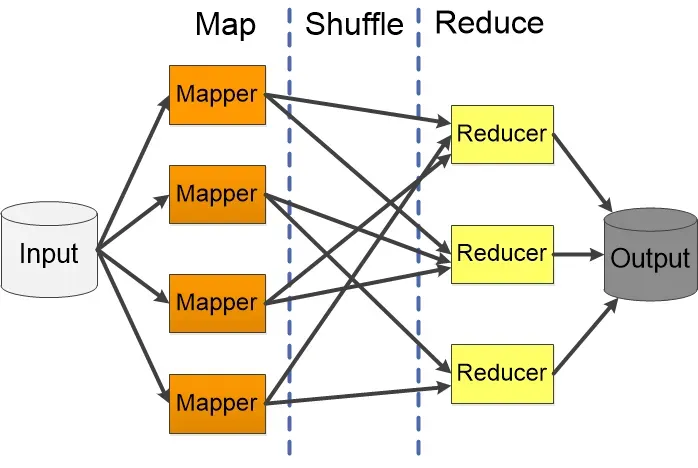
环形缓冲区结构:
- 左侧:存储索引(Metadata)------ 分区号、keystart、valstart、vallen
- 右侧:存储真实数据(Record)------ K,V序列化后的字节
- 默认大小:100M
- 溢写阈值:80%(反向溢写,预留20%给溢写线程)
为什么80%就溢写?如果等到100%再溢写,必须等所有数据写完磁盘才能继续写入缓冲区,效率低。80%时开启溢写线程,边写边处理。
4.2 Map端Shuffle详细流程
Map输出 → 分区(Partition) → 进入环形缓冲区 → 达到80% → 快排(按K索引排序)
→ 溢写到磁盘(spill.out + spill.index) → 多次溢写文件 → 归并排序(Merge)
→ Combiner(可选) → 压缩(可选) → 等待Reduce拉取关键细节:
- 排序不是移动数据 :快排是对索引排序,不是移动真实的K,V数据
- 分区内部有序:溢写前按分区号排序,同一分区内按Key字典序排序
- 溢写文件结构:一个文件包含多个分区数据,通过index文件记录每个分区的偏移量
4.3 Reduce端Shuffle详细流程
ReduceTask启动 → 从各MapTask拉取指定分区数据 → 内存缓冲/磁盘溢写
→ 归并排序所有拉取的数据 → 按Key分组 → 相同Key进入同一个Reduce方法Reduce拉取特点:
- 主动拉取:ReduceTask主动从MapTask拉取数据,不是MapTask推送
- 内存+磁盘:拉取的数据先放内存,不够则溢写到磁盘
- 全局排序:对所有拉取的数据进行一次归并排序,保证相同Key连续
4.4 Shuffle参数调优
xml
<!-- 环形缓冲区大小,默认100M -->
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>100</value>
</property>
<!-- 溢写阈值百分比,默认0.8 -->
<property>
<name>mapreduce.map.sort.spill.percent</name>
<value>0.80</value>
</property>
<!-- 归并时一次合并的文件数,默认10 -->
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>10</value>
</property>五、Partition分区机制
5.1 默认分区器 HashPartitioner
java
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}原理 :key.hashCode() & Integer.MAX_VALUE 防止负数,再对ReduceTask个数取余。
5.2 自定义分区案例
需求:将手机号按归属地输出到不同文件(136、137、138、139、其他)
java
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
String phone = text.toString();
String prePhone = phone.substring(0, 3);
int partition;
if("136".equals(prePhone)) partition = 0;
else if("137".equals(prePhone)) partition = 1;
else if("138".equals(prePhone)) partition = 2;
else if("139".equals(prePhone)) partition = 3;
else partition = 4;
return partition;
}
}Driver设置:
java
job.setPartitionerClass(ProvincePartitioner.class);
job.setNumReduceTasks(5); // 必须等于分区数!5.3 分区数与ReduceTask数的关系
| ReduceTask数 | 结果 |
|---|---|
| = 分区数 | 正常执行,每个分区一个输出文件 |
| < 分区数 | IOException,数据无处写入 |
| > 分区数 | 正常执行,多余ReduceTask输出空文件 |
| = 1 | 不执行分区过程,所有数据进入0号分区,输出一个文件 |
源码验证:MapTask中执行分区的前提是
numReduceTasks > 1
六、WritableComparable排序机制
6.1 排序发生的时机
MapReduce中共发生3次排序:
| 阶段 | 排序类型 | 算法 | 说明 |
|---|---|---|---|
| Map端 | 快速排序 | QuickSort | 环形缓冲区溢写前,对索引排序 |
| Map端 | 归并排序 | MergeSort | 多个溢写文件合并时 |
| Reduce端 | 归并排序 | MergeSort | 拉取所有Map数据后,全局排序 |
6.2 为什么必须排序?
核心原因:让相同Key的数据连续排列,Reduce只需顺序扫描即可判断Key是否相同,无需全量遍历。
未排序:(a,1) (b,1) (a,1) (d,1) → 需要遍历全部判断相同Key
已排序:(a,1) (a,1) (b,1) (d,1) → 顺序扫描,遇到不同Key即停止6.3 自定义排序实现
需求:按总流量倒序排序
java
public class FlowBean implements WritableComparable<FlowBean> {
private long upFlow;
private long downFlow;
private long sumFlow;
// 实现compareTo方法
@Override
public int compareTo(FlowBean o) {
// 总流量倒序
if(this.sumFlow > o.sumFlow) return -1;
else if(this.sumFlow < o.sumFlow) return 1;
else {
// 二次排序:总流量相同,按上行流量正序
if(this.upFlow > o.upFlow) return 1;
else if(this.upFlow < o.upFlow) return -1;
else return 0;
}
}
}6.4 排序类型总结
| 排序类型 | 说明 |
|---|---|
| 部分排序 | 对每个输出文件内部排序(默认行为) |
| 全排序 | 所有数据全局排序,通常只有1个ReduceTask |
| 二次排序 | 排序条件有两个,第一个条件相同按第二个排 |
| 区内排序 | 每个分区内部独立排序 |
七、Combiner合并机制
7.1 Combiner的作用
场景 :Map端输出(a,1)出现1万次,不开启Combiner需传输1万条到Reduce;开启后传输(a,10000)只需1条。
核心价值:减少Map到Reduce的网络传输量,提前局部聚合。
7.2 Combiner使用前提
必须满足:Combiner的逻辑不影响最终结果。
| 场景 | 是否可用 | 原因 |
|---|---|---|
| 求和 | 可用 | (a,1)+(a,1)=(a,2),结果正确 |
| 求平均值 | 不可用 | (1+2)/2=1.5 ≠ (1+2+3+4)/4=2.5 |
| 求最大值 | 可用 | max(max(a,b),c) = max(a,b,c) |
7.3 Combiner代码实现
java
// 方式一:自定义Combiner类
public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
context.write(key, outV);
}
}
// Driver中设置
job.setCombinerClass(WordCountCombiner.class);
// 方式二:若Combiner逻辑与Reducer完全相同,直接用Reducer
job.setCombinerClass(WordCountReducer.class);注意:若
setNumReduceTasks(0),则不执行Shuffle阶段,Combiner也不生效。
八、OutputFormat数据输出
8.1 默认输出 TextOutputFormat
将每个K,V对按行输出到文本文件。
8.2 自定义OutputFormat案例
需求 :将包含atguigu的日志输出到atguigu.log,其他输出到other.log。
java
// 1. 自定义OutputFormat
public class LogOutputFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException {
return new LogRecordWriter(job);
}
}
// 2. 自定义RecordWriter
public class LogRecordWriter extends RecordWriter<Text, NullWritable> {
private FSDataOutputStream atguiguOut;
private FSDataOutputStream otherOut;
public LogRecordWriter(TaskAttemptContext job) {
FileSystem fs = FileSystem.get(job.getConfiguration());
atguiguOut = fs.create(new Path("d:/hadoop/atguigu.log"));
otherOut = fs.create(new Path("d:/hadoop/other.log"));
}
@Override
public void write(Text key, NullWritable value) throws IOException {
String log = key.toString();
if (log.contains("atguigu")) {
atguiguOut.writeBytes(log + "\n");
} else {
otherOut.writeBytes(log + "\n");
}
}
@Override
public void close(TaskAttemptContext context) throws IOException {
IOUtils.closeStream(atguiguOut);
IOUtils.closeStream(otherOut); // 必须关流!否则文件为空
}
}
// 3. Driver设置
job.setOutputFormatClass(LogOutputFormat.class);九、MapTask与ReduceTask工作机制源码解析
9.1 MapTask五个阶段
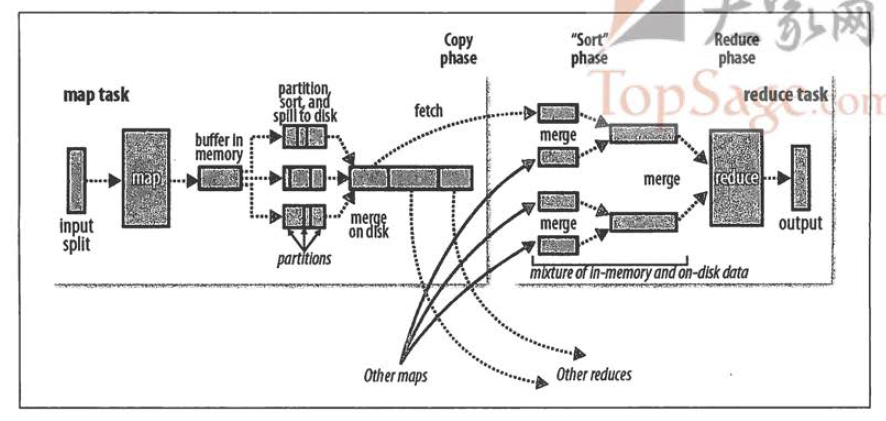
| 阶段 | 操作 |
|---|---|
| Read | 通过RecordReader从InputSplit解析K,V |
| Map | 调用用户自定义map()函数处理 |
| Collect | 调用OutputCollector.collect(),分区后写入环形缓冲区 |
| Spill | 缓冲区满80%后溢写到磁盘,先快排,再按分区写入 |
| Merge | 所有溢写文件归并成一个最终文件,每轮合并10个文件 |
9.2 ReduceTask三个阶段
| 阶段 | 操作 |
|---|---|
| Copy | 从各MapTask拉取指定分区数据,内存不够则溢写磁盘 |
| Sort | 对内存和磁盘上的文件进行归并排序 |
| Reduce | 调用用户自定义reduce()函数,结果写入HDFS |
9.3 ReduceTask并行度决定
java
// 手动设置ReduceTask数量
job.setNumReduceTasks(4);实验结论(1GB数据,16个MapTask):
| ReduceTask | 1 | 5 | 10 | 15 | 16 | 20 | 25 | 30 | 45 | 60 |
|---|---|---|---|---|---|---|---|---|---|---|
| 总时间(s) | 892 | 146 | 110 | 92 | 88 | 100 | 128 | 101 | 145 | 104 |
最佳实践:ReduceTask数量并非越多越好,需根据数据量和集群资源调优。一般设置为节点数的0.95倍或1.75倍。
十、Join应用
10.1 Reduce Join
原理:Map端为数据打标签区分来源,以连接字段为Key输出;Reduce端按Key分组,合并不同来源的数据。
缺点:合并操作在Reduce端完成,Reduce端压力大,易产生数据倾斜。
java
// Mapper中通过setup获取文件名,打标签
@Override
protected void setup(Context context) throws IOException {
InputSplit split = context.getInputSplit();
FileSplit fileSplit = (FileSplit) split;
filename = fileSplit.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) {
if(filename.contains("order")) {
// 订单表处理,flag="order"
} else {
// 商品表处理,flag="pd"
}
}10.2 Map Join(推荐)
适用场景:一张表很小(可放入内存),一张表很大。
优势 :在Map端缓存小表,提前处理Join逻辑,无需Reduce阶段,避免数据倾斜。
java
// Driver中加载缓存文件
job.addCacheFile(new URI("file:///D:/input/tablecache/pd.txt"));
job.setNumReduceTasks(0); // 不需要Reduce
// Mapper中setup读取缓存
@Override
protected void setup(Context context) throws IOException {
URI[] cacheFiles = context.getCacheFiles();
Path path = new Path(cacheFiles[0]);
FileSystem fs = FileSystem.get(context.getConfiguration());
FSDataInputStream fis = fs.open(path);
BufferedReader reader = new BufferedReader(new InputStreamReader(fis));
String line;
while (StringUtils.isNotEmpty(line = reader.readLine())) {
String[] split = line.split("\t");
pdMap.put(split[0], split[1]); // pid -> pname
}
}
@Override
protected void map(LongWritable key, Text value, Context context) {
// 直接通过pdMap获取pname,无需Reduce
String pname = pdMap.get(fields[1]);
}十一、Hadoop数据压缩
11.1 压缩算法对比
| 压缩格式 | 自带 | 算法 | 可切片 | 压缩率 | 速度 | 适用场景 |
|---|---|---|---|---|---|---|
| Gzip | 是 | DEFLATE | 否 | 高 | 一般 | 归档 |
| Bzip2 | 是 | bzip2 | 是 | 最高 | 慢 | 冷数据 |
| LZO | 否 | LZO | 是 | 一般 | 快 | 需建索引 |
| Snappy | 是 | Snappy | 否 | 一般 | 最快 | 热数据、实时 |
11.2 压缩位置选择
输入文件 → [InputFormat] → Map输出 → [Shuffle] → Reduce输出 → [OutputFormat] → HDFS
↑压缩可选 ↑强烈建议压缩 ↑压缩可选11.3 压缩参数配置
java
// Map输出端压缩
conf.setBoolean("mapreduce.map.output.compress", true);
conf.setClass("mapreduce.map.output.compress.codec",
BZip2Codec.class, CompressionCodec.class);
// Reduce输出端压缩
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);十二、MapReduce开发总结
| 组件 | 核心要点 |
|---|---|
| InputFormat | 默认TextInputFormat;CombineTextInputFormat解决小文件 |
| Mapper | 实现map()、setup()、cleanup()三个方法 |
| Partitioner | 默认HashPartitioner;自定义需配合setNumReduceTasks |
| Comparable | Key必须实现WritableComparable,重写compareTo() |
| Combiner | 提前聚合减少IO,但需保证不影响最终结果 |
| Reducer | 实现reduce()、setup()、cleanup()三个方法 |
| OutputFormat | 默认TextOutputFormat;可自定义输出到数据库等 |
十三、常见错误及解决方案
| 错误 | 原因 | 解决方案 |
|---|---|---|
Illegal partition for xxx |
Partition和ReduceTask个数不匹配 | 调整ReduceTask个数等于分区数 |
| 类型转换异常 | Map输入参数类型错误 | Mapper第一个输入必须是LongWritable或NullWritable |
| 输出文件夹已存在 | MapReduce不允许覆盖 | 删除旧目录或更换输出路径 |
Unsupported major.minor version 52.0 |
JDK版本不一致 | 统一Windows和Linux的JDK版本 |
| 找不到缓存文件 | 路径错误或文件名多了.txt | 检查路径,使用绝对路径 |
| 自定义OutputFormat输出为空 | RecordWriter未关闭流 | 在close()方法中关闭所有输出流 |
| ReduceTask=0时Combiner不生效 | 无Shuffle阶段 | 正常现象,Combiner依赖Shuffle |