1.1 文件打开和读写的基本过程
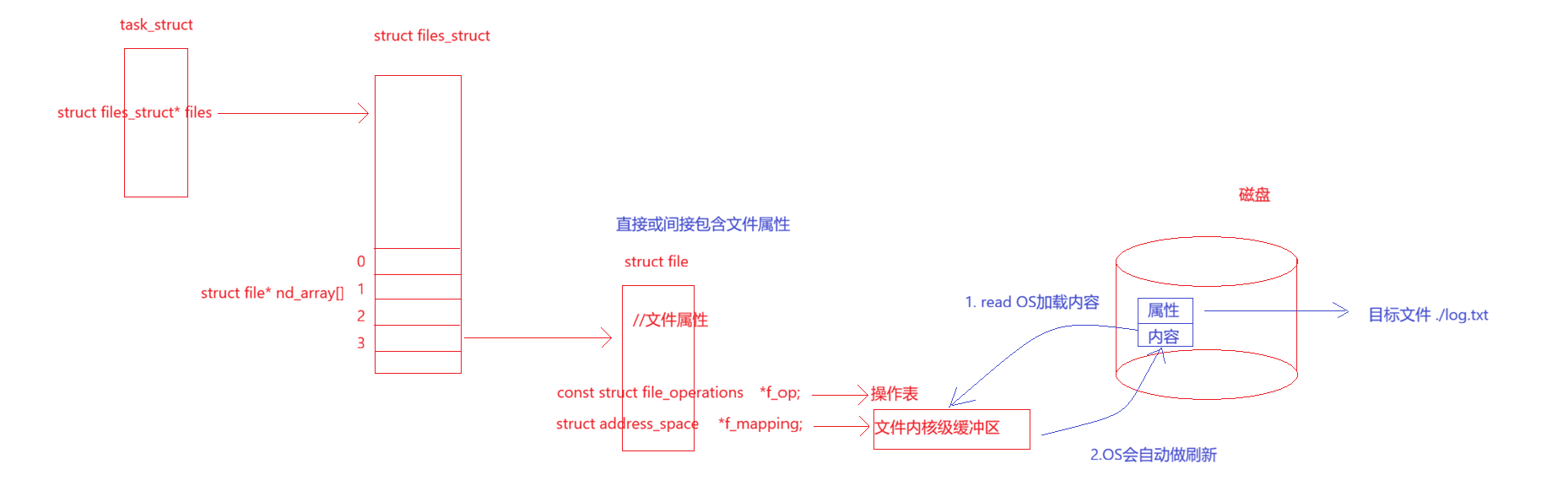
读、写文件第一件事都是把文件内容从磁盘加载内核级缓冲区,因为CPU是没有办法去访问磁盘的,如果访问某一个文件时,其缓冲区为空,那么就需要阻塞进程(比如scanf,如果键盘不输入的话,进程就会一直阻塞),但如果访问的是普通文件,阻塞的时间都很短,短到用户感知不到,由操作系统去进行相应的处理(因为把内容从磁盘加载到内存,本质上涉及的是对硬件的处理,而操作系统是软硬件资源的管理者,只有OS有这个权限),把磁盘文件内容加载到文件缓冲区之后,再唤醒进程
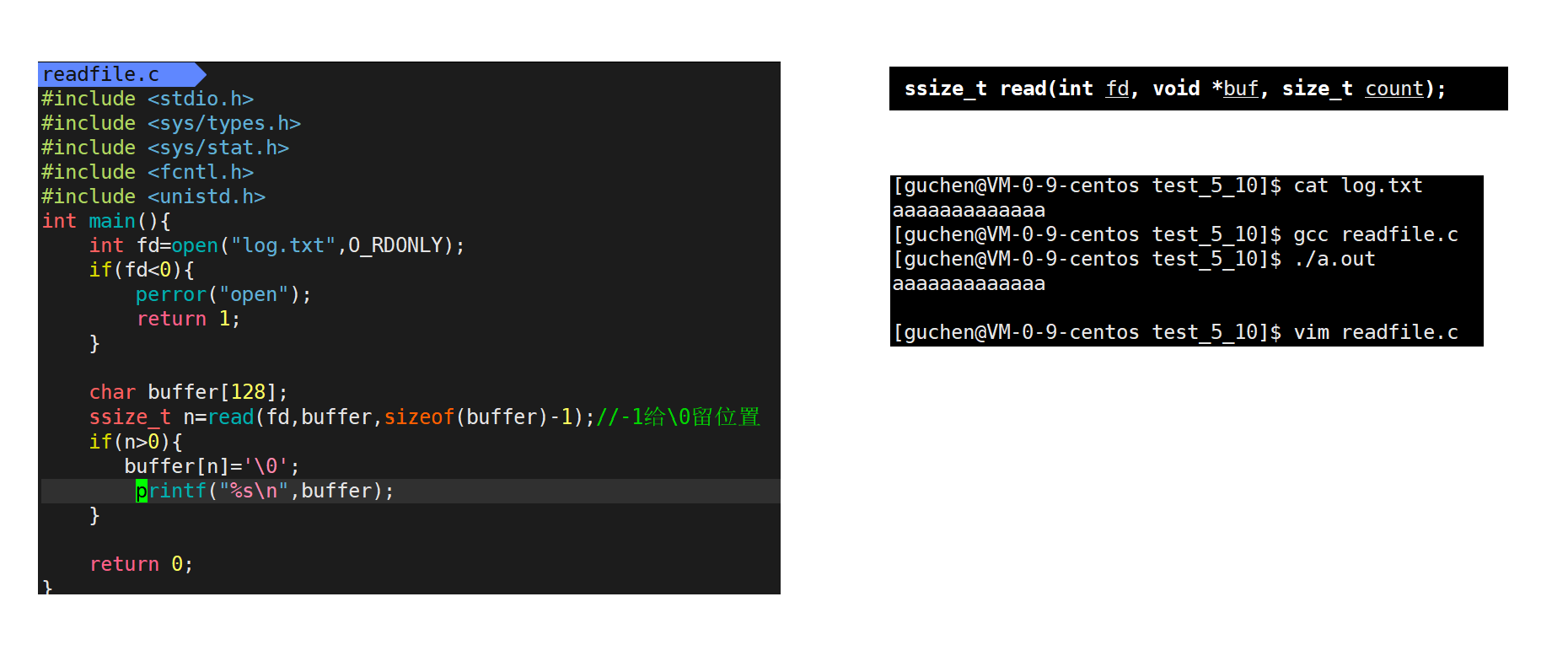
无论是read还是write,都是系统调用,调用OS来为用户服务
如果是读的话,先把磁盘文件加载到内核级缓冲区,把缓冲区的内容拷贝到用户数据
如果是写的话,先把磁盘文件加载到内核级缓冲区,将用户数据拷贝到缓冲区(新内容覆盖旧内容达到修改的效果,或者是删除和增加),再刷新到磁盘
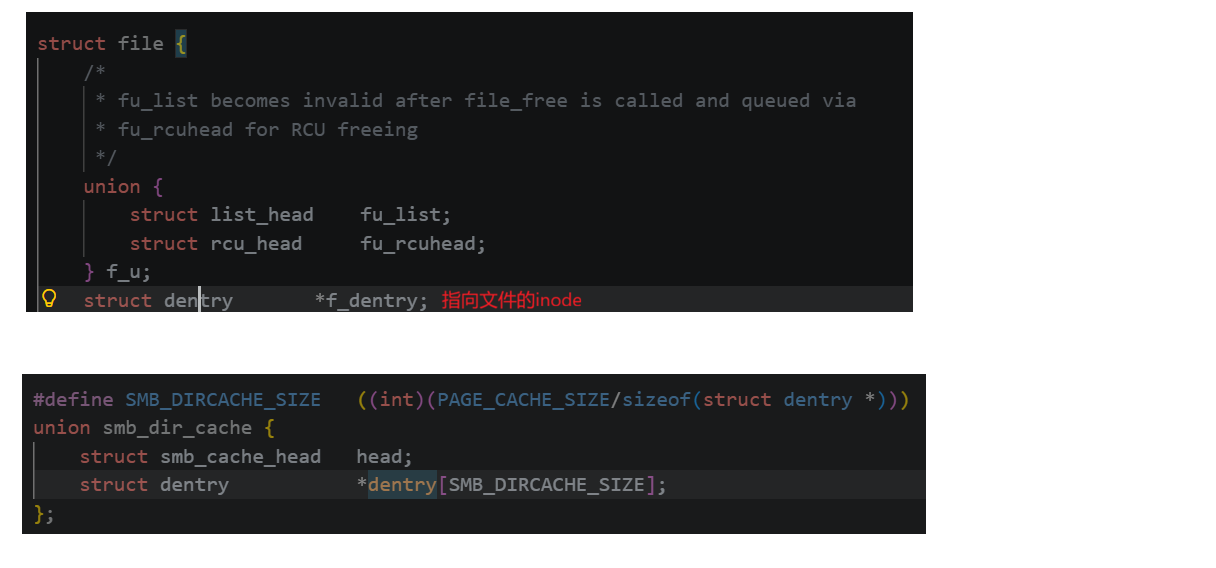
无论是从磁盘中加载,还是把内容同步到磁盘,都是由struct file中的函数指针来处理,这些函数指针指向的是硬件的各种操作方法
如果在打开文件的时候,选择O_TRUNC选项,也就是先把文件清空,这时候没有必要把文件内容加载到磁盘,将文件属性的文件大小清零即可
所以write,read等系统调用的本质是拷贝函数
但是,系统调用是有代价的,会涉及到用户态和内核态之间的切换🔄,中断等,而OS有很多工作要做,如果文件操作频繁的进行系统调用,会导致CPU的效率降低,大部分时间用于切换开销而非实际业务逻辑。比如C++中stl的vector或者空间配置器扩容一般是2倍扩,而不是用户申请多少字节,就扩充多少字节,因为每一次扩容都是有成本的,要进行系统调用,使用malloc/new,至少要改变堆的vm_end也就是进程地址空间的分配,使用空间的话还要分配物理内存,而一次扩两倍,就可能把每次几个字节或几十个字节的扩容次数大大减少,核心就是有效减少系统调用次数,提高效率,说的是有效,在保证正确性等的情况下减少系统调用次数
那么C语言的设计者想,我们能不能减少系统调用次数呢?举个例子🌰,我们去菜鸟驿站寄快递,快递员不会因为1个或者2个快递来了就发车,因为运输开销远大于用户付的费用,那是怎么做的呢?等到快递数量达到一定程度,才发车,这样成本摊到每一个快递上,才能有机会盈利
那C语言是怎么做的呢?我们都知道C语言的缓冲区,我们在调用库函数比如printf向stdout写入的时候,本质不是直接写入到显示器的内核级文件缓冲区中,而是写入到了C语言的输出缓冲区中,当缓冲区满了或者符合一定的刷新规则才刷新,这样可以减少本来多次fprintf要进行的多次系统调用,也有输入缓冲区,本质是提高C语言IO函数的效率。
那么输入缓冲区和输入缓冲区在哪呢?我们知道向stdout和向log.txt写入的内容是不能混淆的,我们只是把本来多次进行的系统调用通过C语言缓冲区的缓冲,减少次数,每次多写入/读出一些内容,所以可以推断每个文件是有自己的语言级缓冲区的,如果多个文件用一个语言级缓冲区,缓冲区的内容如何区分是谁的呢?关闭文件的时候对缓冲区如何处理呢?所以每个文件有自己的输入缓冲区和输出缓冲区,也就是存在FILE结构体中
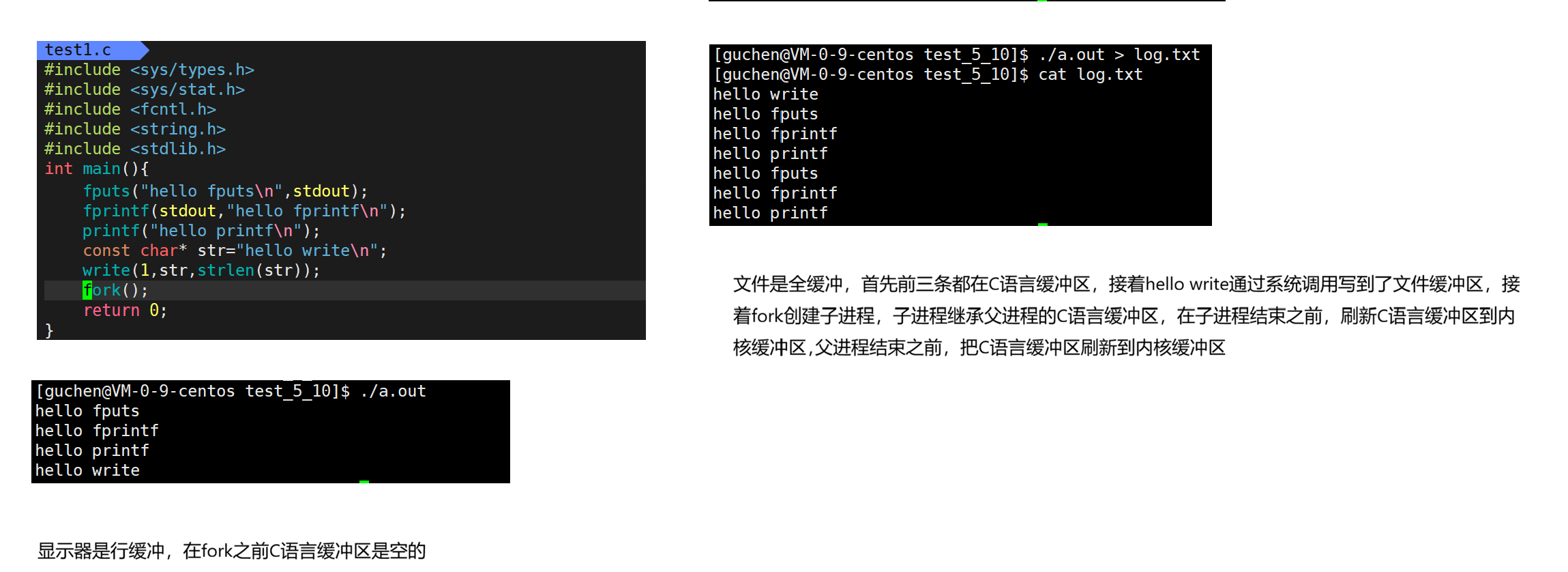
下面代码不会一开始就打印--------------------------------aaaa,而是在一段时间后才打印到显示器上,而且一次打印很多内容,此时是stdout的输出缓冲区满了,刷新缓冲区到内核级缓冲区,再有OS刷新到显示器

我们可以看到打开文件的时候没有加O_TRUNC选项,直接就是覆盖式写入,本质是把log.txt内容加载到内核级缓冲区,把"hello write"拷贝到内核级缓冲区覆盖刚开始的1111,内核级缓冲区内容刷新到log.txt
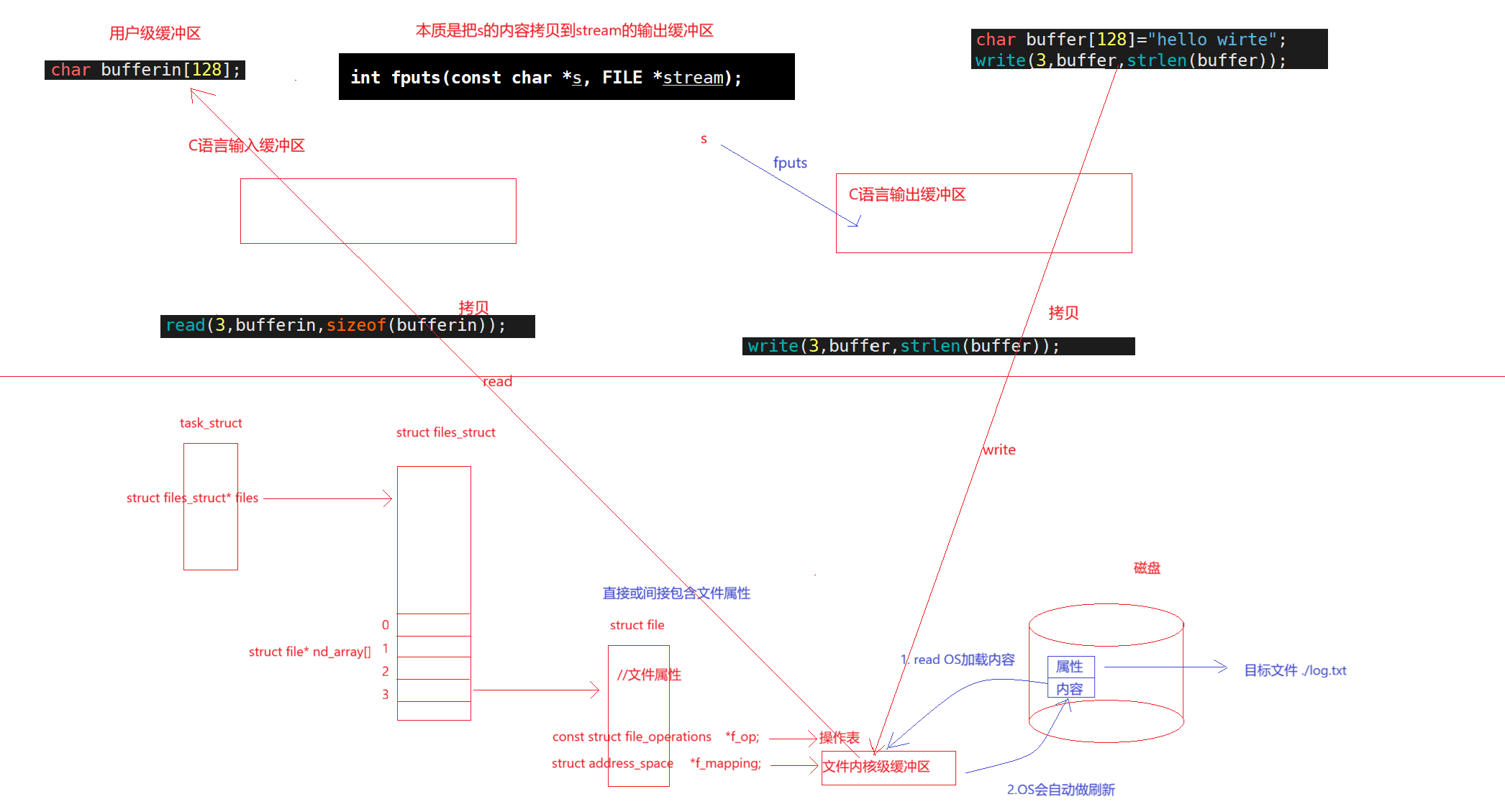
刷新的本质,语言缓冲区,拷贝到内核级缓冲区
stdout缓冲刷新的方式
1.显示器 行缓冲
2.文件 全缓冲
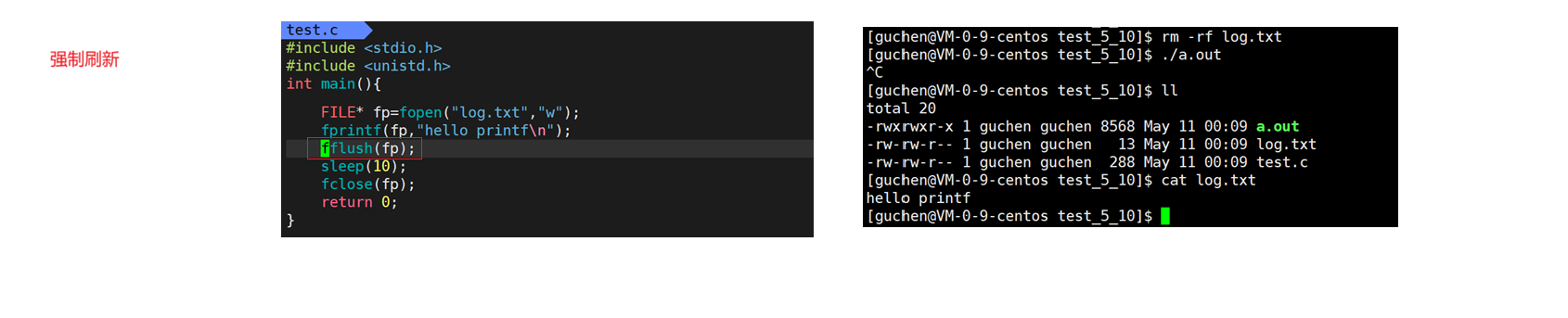
3.fflush强制刷新
行刷新测试,遇到\n,stdout调用write把stdout缓冲区的内容写到内核级缓冲区
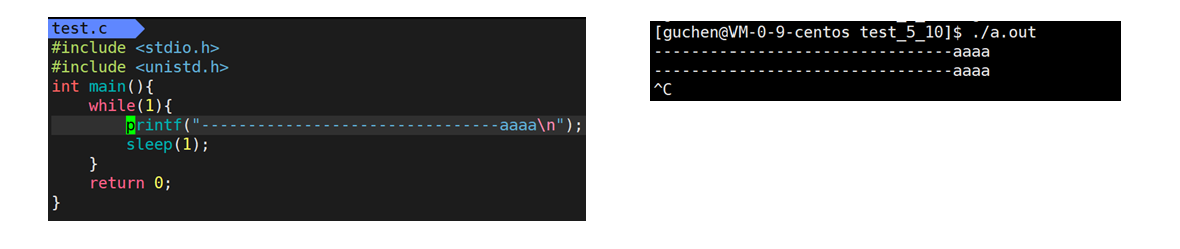
全缓冲测试
10s内在命令行通过ctrl+c异常终止程序,C标准库用户缓冲区内容丢失,log.txt内容是空的
如果等待10s,程序正常结束,return之前自动关闭所有文件,fflush会强制刷新缓冲区,隐式调用write写到log.txt的内存级缓冲区

其实内核级缓冲区也要刷新到磁盘文件/显示器文件等,那么这个原理是一致的,OS向磁盘写入也是有代价的,因为磁盘速度比较慢,OS肯定会被磁盘的速度拖累,所以就出现了内核级缓冲区,缓冲区嘛,就是先把用户数据通过write写到内核级缓冲区,接着根据合适的刷新规则(比如内核级缓冲区满了),把内核级缓冲区的内容刷新到磁盘,内核级缓冲区也是独属于某个文件的,向磁盘刷新有直写(WT,write through)和WB(write back)两种方式,直写是缓冲区一有数据就刷新到磁盘,写回则是等OS有空了再写回
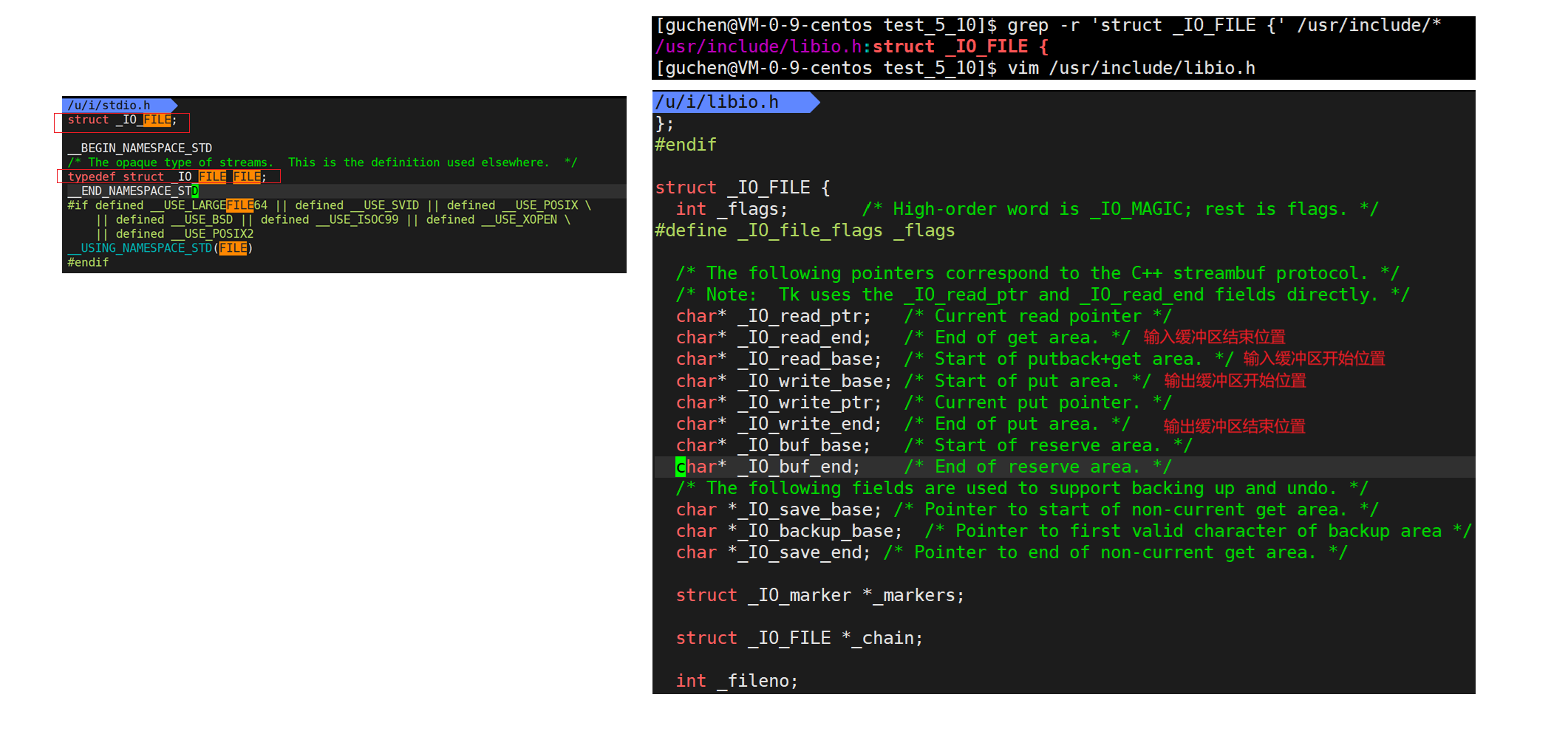
FILE

1.2 关于缓冲区的几种现象
1.2.1 缓冲区内容丢失
1.2.1.1 现象1
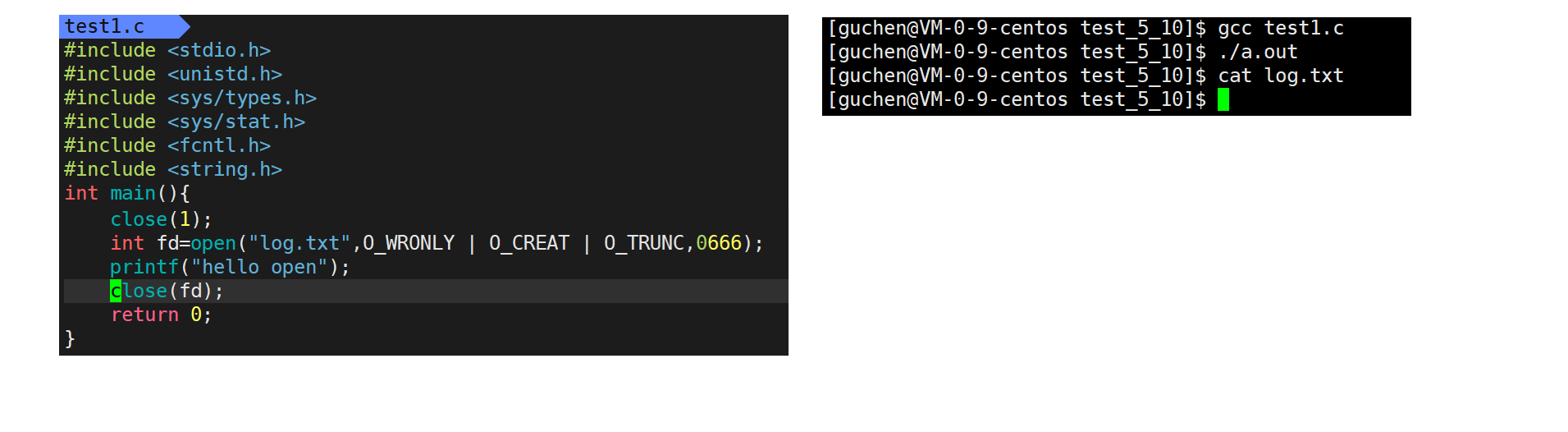
下面中关闭文件描述符1对应的文件,也就是显示器,此时最小没有被分配的文件描述符就是1,接着打开log.txt,把文件描述符1分配给log.txt,接着向stdout写入,stdout是C语言用户态malloc出来的结构体对象,存储的文件描述符是1,printf相当于向log.txt写入,但是由于C语言缓冲区的存在,hello open会写入到C语言缓冲区,接着关闭fd指向的文件,也就是文件描述符1对应的文件关闭了,在进程结束之,也就是return之前,C语言会把语言级缓冲区的内容尝试刷新到文件描述符1对应的内核级文件缓冲区,但是此时nd_array1为空,无法写入,导致C语言缓冲区的内容丢失,无论是显示器还是log.txt内容均为空
1.2.2.2 现象2
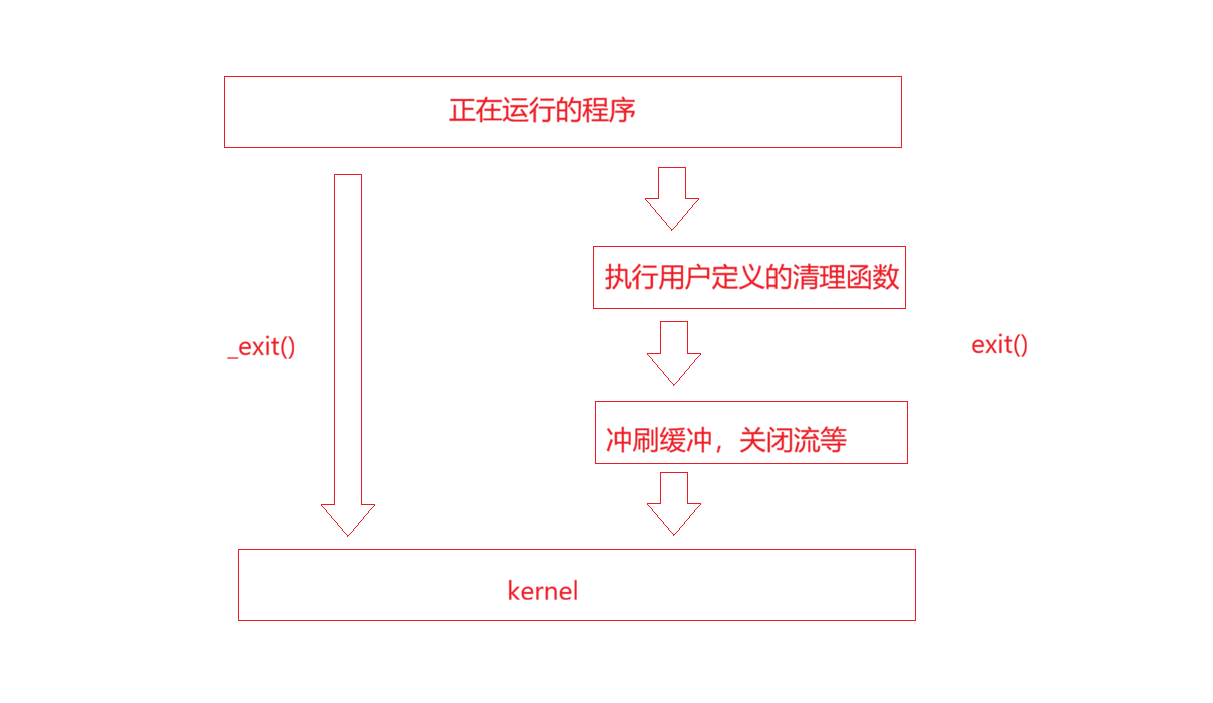
exit/_exit

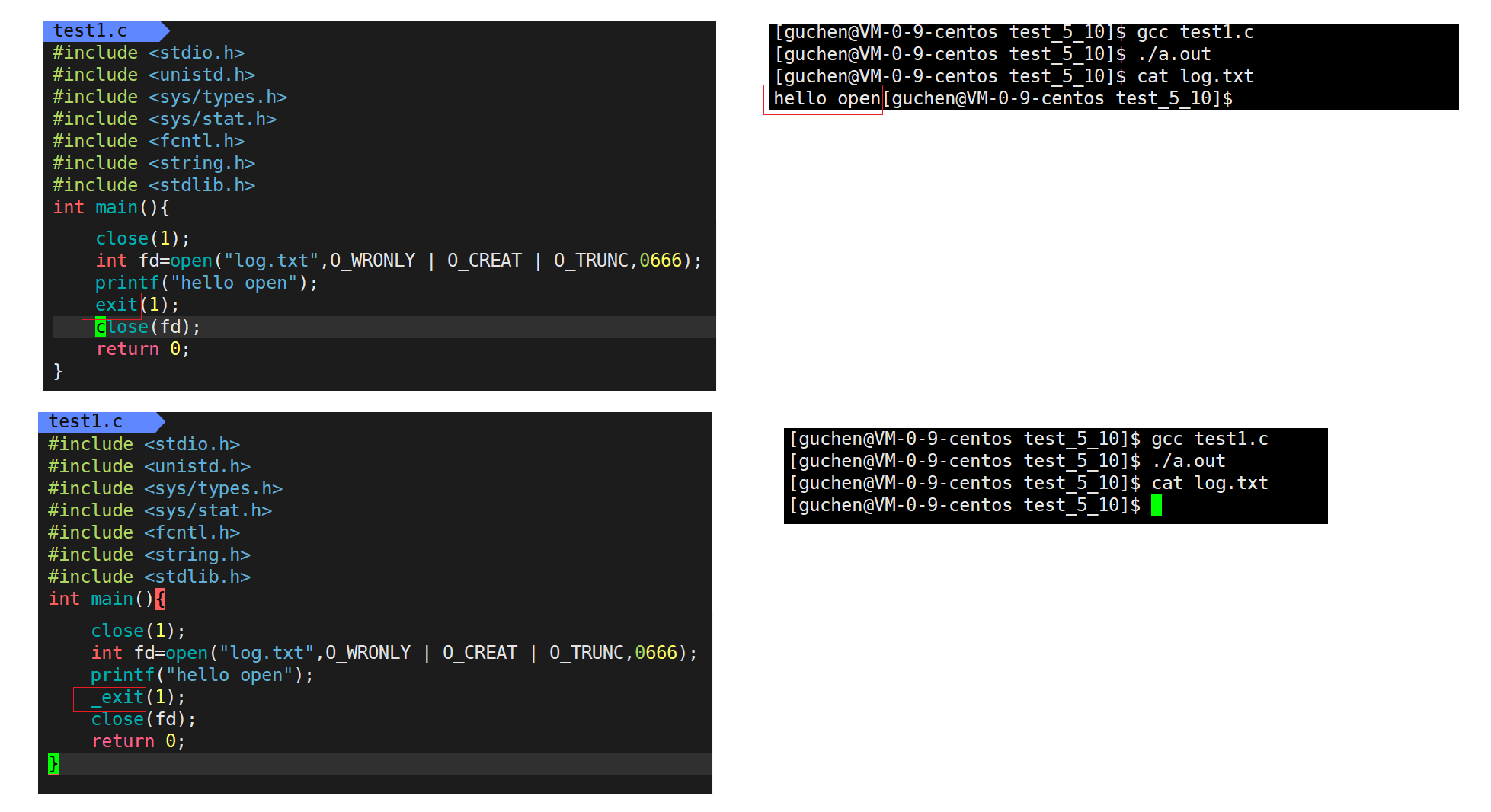
看现象,在close(fd)之前调用exit结束进程,内容成功写到了log.xt,在close(fd)之前调用_exit结束进程,内容没有写到log.txt
可以这样说,C语言为自己的缓冲区负责,但是系统调用不为C语言的缓冲区负责,那么用户把内容交给C语言,C语言负责把内容交给系统,至于C语言如何缓冲那是C语言的事情,用户不关心,C语言为了效率可以暂时不把内容写到内核级缓冲区,但是最终会完成这件事情;
而C语言负责把用户数据拷贝到内核级缓冲区,对于C语言来说,就认为交给了磁盘等硬件,就好像用户把数据交给缓冲区就认为把数据交给了OS,但是内核级缓冲区什么时候刷新到磁盘,这是OS的事情,包括直写和写回,也可以强制刷新,可以使用下面的系统调用,因为内核级缓冲区是struct file指向的,而struct file是以fd为唯一标识的,所以使用的是fd
也就是说OS为自己的内核级缓冲区负责


1.2.2 多种向显示器的方式
1.2.2.1 现象3
使用库函数/系统调用向显示器写入(行缓冲)
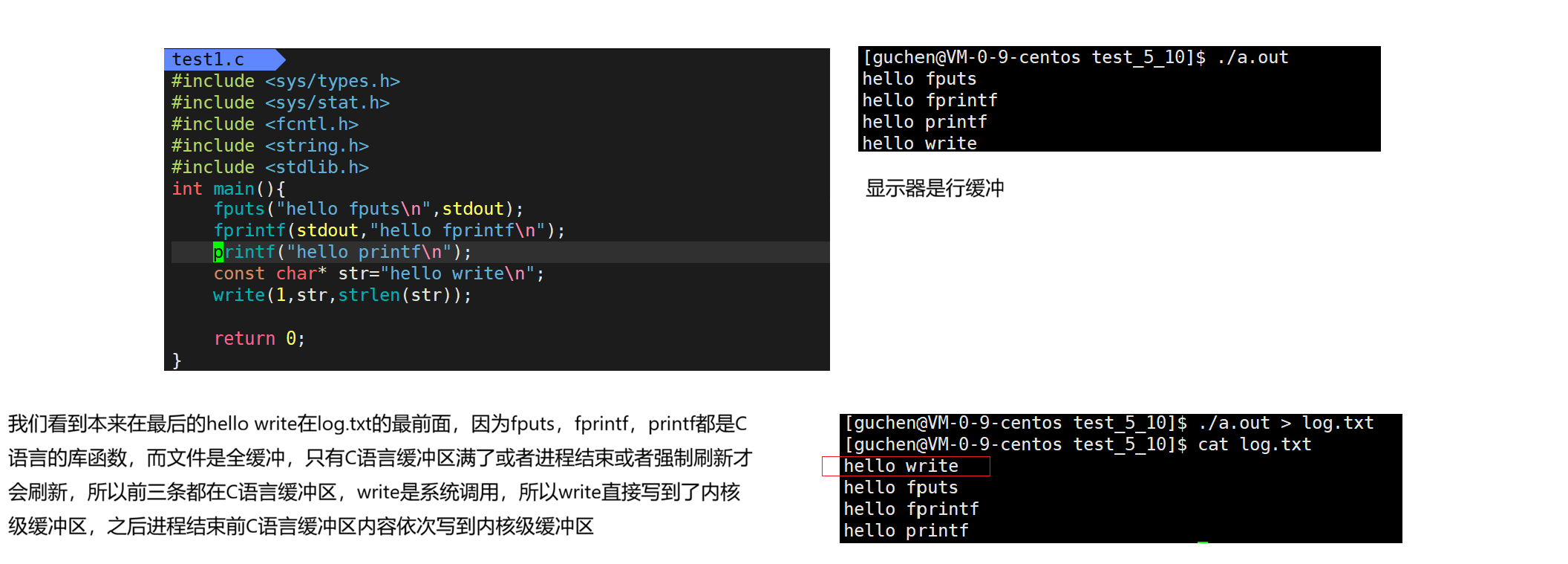
使用库函数/系统调用向文件写入(全缓冲)