你会读到:概念梳理 → 搭好 PyTorch 环境、认识张量 → 两个实战项目:
- 古诗续写 :
transformers对接预训练中文 GPT-2;Tokenizer与TextGenerationPipeline生成古诗后续。 - MNIST 图像降噪 :从 NumPy 读数数据集与预处理 → 自建 U-Net → 前向计算→
MSELoss不断计算损失 → 反向传播 →Adam梯度下降更新权重 → 周期性保存权重与预览图,把模型微调的全流程一次跑通。
有兴趣运行代码跑一下的同学,可以点赞+关注,我将源代码和数据集发给你。
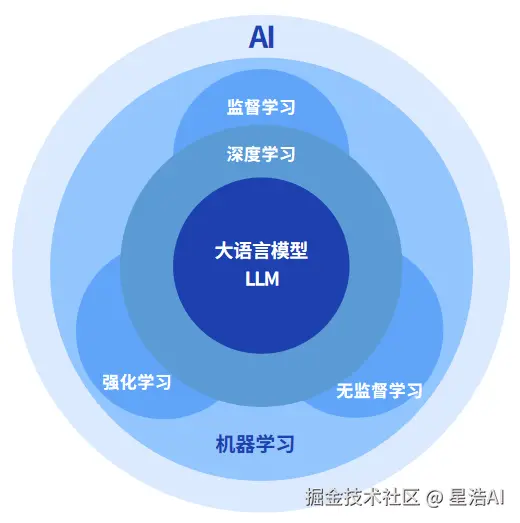
AI、ML、DL 之间的关系
人工智能
人工智能(AI)指让机器表现出需要智能才能完成的行为;其中机器学习 是当今最重要的一类实现路径,而深度学习又是机器学习中基于深层神经网络的一大分支。
机器学习(Machine Learning,ML)
通过数据学习和改进,研究如何让计算机具备学习能力。
深度学习(Deep Learning, DL)
通过构建多层神经网络实现对复杂模式的自动识别和分类,进而实现对图像、语音、自然语言等数据的深层次理解和分析。
深度学习的核心是神经网络,主要负责对数据进行特征提取、分析,得到最终结果。
深度学习的学习方式:强化学习 、监督学习 、无监督学习。
大语言模型
基于海量数据训练而成。可用于生成,以及自然语言处理(NLP)任务。
根据参数量进行区分,参数量大于 10 亿(即 1B),才算得上是大语言模型。
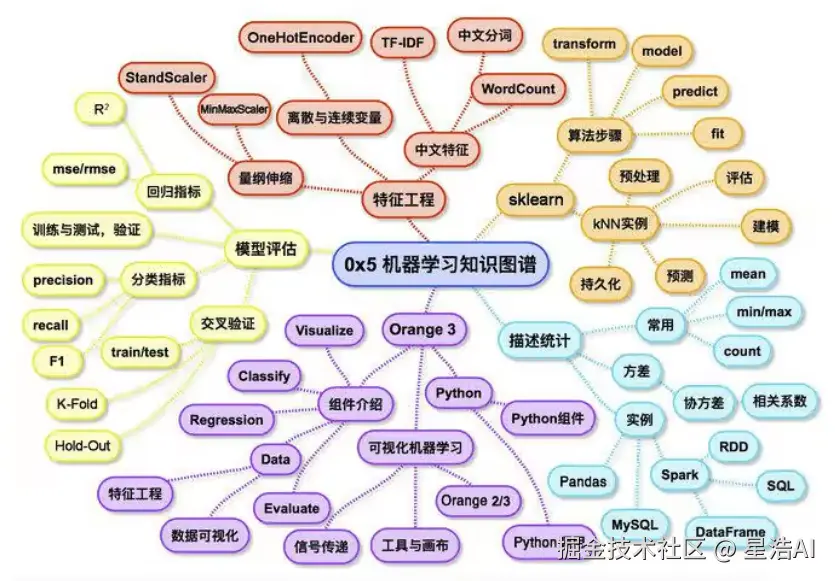
机器学习知识图谱
- 特征工程
把现实世界中的物体转换为向量、矩阵、张量的形式,以便于大模型输入。
机器学习流程中重要环节,核心目标是通过数据转换和特征构造提升模型性能。
- sklearn
Python中最流行的开源机器学习库之一,专注于提供简单高效的数据挖掘和数据分析工具。
- Orange3
开源的Python数据挖掘和机器学习工具箱。提供可视化编程界面和丰富功能著称,适合从新手到专家的各类用户。
- 模型评估
验证模型性能的关键环节,核心目标是通过量化指标和可视化分析判断模型的泛化能力、稳定性和适用性。
 注:该图片截取自网络,仅用于学习交流。
注:该图片截取自网络,仅用于学习交流。
机器学习流程
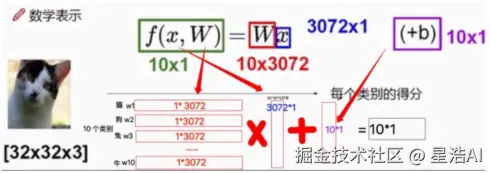
注:该图片截取自网络,仅用于学习交流。
简单来说,机器学习的"学习"过程,就是通过算法自动寻找最优参数 (w 和 b) 的过程。
text
x * w + b = h
x 是输入的数据
w 是一个未知数
b 偏置量
h 是输出结果
在计算过程中,不断调整w,b,让h不断逼近标准y(loss=(h-y)的平方)核心公式中的"已知"与"未知"
在模型训练阶段,我们可以把公式 h = x ⋅ w + b 看作一个解谜游戏。
- 已知(固定的):
x (输入数据): 比如图片的像素值、房屋的面积等。这是模型看到的"题目"。
y (标签/标准答案): 比如这张图是"猫"、这房子卖"500万"。这是用来批改作业的"答案"。
- 未知(待学习的):
w (权重) 和 b (偏置): 这就是模型的"大脑"。在训练开始前,它们通常是随机生成的(比如从正态分布中随机抽取)。
为什么是随机的? 如果一开始都设为0或1,所有神经元都会做同样的事情(对称性),导致无法学习复杂的特征。随机初始化是为了打破这种对称性,让它们从不同的角度开始探索。
- 计算出来的:
h (预测值): 这是模型拿着当前的 w 和 b ,结合输入 x 算出来的结果。
Loss (损失): 通过 (h−y)的平方 计算得出。它告诉模型:"你这次猜得离谱了,误差有多大"。
机器学习中的任务
分类(classification)
先找到数据样本点中的分界线,再根据分界线对新数据进行分类,分类数据是离散的值。
典型分类任务需要标签(监督信号);此外还有半监督、自监督等扩展设定,入门阶段可先记住「有标签即可监督分类」。
二分类:只涉及两个类别的分类任务。 多分类:涉及多个类别的分类。
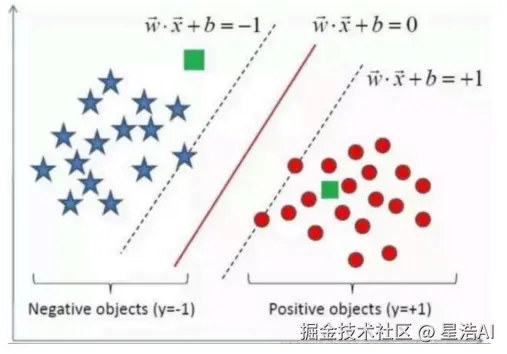 注:该图片截取自网络,仅用于学习交流。
注:该图片截取自网络,仅用于学习交流。
比如:图片识别、情感分析等等。
回归
根据历史数据,寻找到历史数据的发展规律,再结合这个规律,预测未来的趋势。
对已有的数据样本点进行拟合,再根据拟合出来的函数,对未来进行预测。
 注:该图片截取自网络,仅用于学习交流。
注:该图片截取自网络,仅用于学习交流。
比如:房价预测、股价预测等等。
聚类
与「已知类别名」的分类不同,聚类事先没有类别定义,只根据样本相似度把数据分成若干组,常被视为一种无监督的「分群」。聚类没有标签,是无监督学习。
缺点:受数据量的影响,数据量越大,计算速度越慢。
 注:该图片截取自网络,仅用于学习交流。
注:该图片截取自网络,仅用于学习交流。
比如:用户分组、异常值检测等。
降维(特征提取)
减少数据的维度,对数据进行降噪、去冗余,方便计算和训练。
实际就是特征提取。根据需求提取相关的关键特征,把无关的特征剔除掉。提高计算效率和计算准确率。
举例:跳高运动会和诗歌朗诵比赛需要的关键特征是不一样的。
机器学习任务流程
数据处理:
把数据处理成模型可以输入的形式。(使用数据处理API将数据集从磁盘读入)。
模型定义:
使用模型定义API来定义机器学习模型。(模型带有模型参数、可以对给定的数据进行推理)
优化器定义:
优化器由框架提供,通过迭代最小化**损失函数(Loss)**来降低误差:把模型输出与标签对比,用 Loss 量化差距,再反向更新参数(如调整 W 和 B)。
训练:
给定一个数据集、模型、操作函数和优化器,循环计算梯度,来更新模型。
测试和调试:
训练过程中,不断地对当前模型的精度进行评估。当精度达到目标后,训练结束。
PyTorch 深度学习环境搭建
工欲善其事,必先利其器。
PyTorch 是一个由 Meta(原 Facebook)开源的深度学习框架,也是目前主流的深度学习框架之一。
PyTorch 的应用范围非常广泛,包括图像和语音识别、自然语言处理、计算机视觉、推荐系统等领域。
具有易于使用、灵活性高和代码可读性好等特点,是深度学习研究与应用的常用选择之一。
环境搭建 1:安装 Python
Python 是深度学习的首选开发语言,提供了大量科学计算类库的 Python 标准安装包,建议使用 Miniconda 来管理第三方库的安装和使用。
- 下载安装 Miniconda
Miniconda 下载地址: www.anaconda.com/download/su...
清华大学开源软件镜像站 mirrors.tuna.tsinghua.edu.cn/anaconda/mi...
- 查看当前环境的版本、信息
bash
conda --version
conda info- 创建虚拟环境 使用 conda 可以在电脑上创建很多套相互隔离的 Python 环境,命令如下:
bash
conda create -n pytorch_dev python=3.12 - 查看已创建的虚拟环境
bash
conda info -e- 激活虚拟环境
bash
conda activate pytorch_dev
# 关闭当前激活的虚拟环境
conda deactivate 环境搭建 2:安装 PyTorch 2
访问地址:pytorch.org/ ,导航进入:Learn -> Get Started :
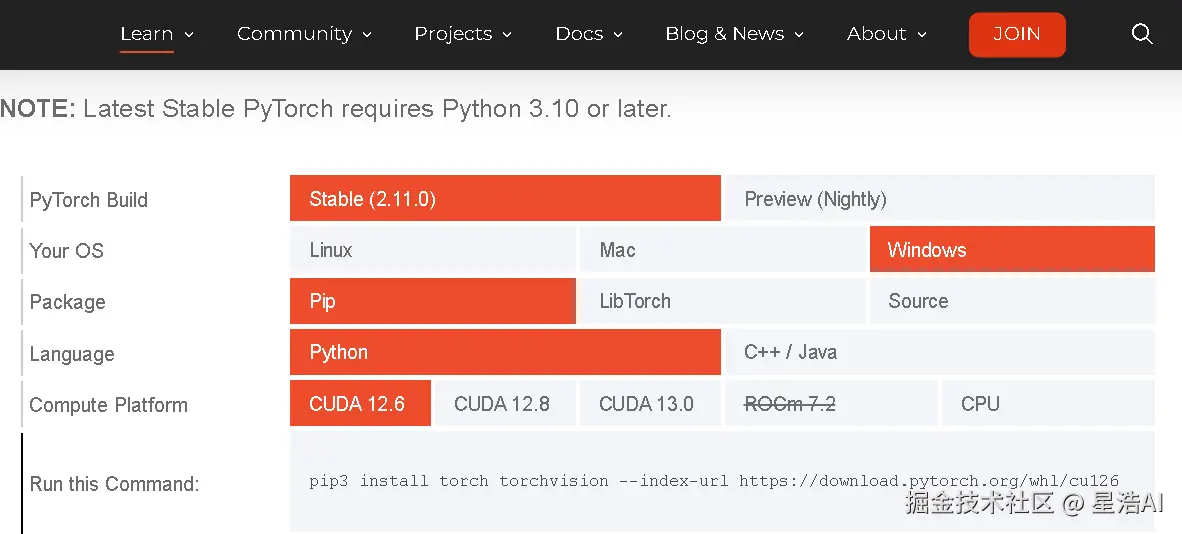
结合本机操作系统、CUDA 版本等,在官网页面中按需选择安装命令即可。
我本地使用的 Python 环境是 3.12 版本,PyTorch 版本是 2.5,CUDA 版本是 12.6。
bash
# 激活虚拟环境
conda activate pytorch_dev
# 安装插件(大概2.6G)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# numpy / matplotlib 版本请与当前 PyTorch 兼容;若安装报错可查阅 PyTorch 官方说明或去掉固定版本号
pip install numpy==2.4.3
pip install matplotlib==3.10.9PyTorch 安装验证
写一个 Hello PyTorch,验证安装是否成功。
python
import torch
result = torch.tensor(1) + torch.tensor(2)
print(result)
数学基础
标量
没有方向,只有大小,就是点。使用单个实数和复数表示。
向量
既有大小又有方向的量,可看作一维有序数组,是一阶张量。
特点:
- 可进行加减、标量乘法、点积、叉积
- 方向性体现在其分量随坐标变化
- 机器学习中的特征向量(如用户画像的数值表示)
张量(Tensor)
广义的多维数据,可表示任何阶数的数据。标量是0阶张量,向量是1阶张量,矩阵是2阶张量,更高维的数组为高阶张量。
- 数学表示
- 阶数由索引数量决定。
- 例子:
- 矩阵(2阶张量):例如图像灰度像素矩阵 28×28
- 3阶张量:RGB 彩色图像
- 4阶张量:视频等;各框架维度顺序可能为「批次×时间×高×宽×通道」等,依 API 而定,此处仅示意「比图像多一维时间」。
张量的基本操作
python
import torch
# ==============================
# 1. 张量的基本操作
# ==============================
print("="*50)
print("1. 张量基本操作示例")
print("="*50)
# 创建张量
# 创建了一个 2x3 的浮点数张量,类型为float
x = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.float32)
# 根据正态分布随机生成一个 2x3 的张量。
y = torch.randn(2, 3) # 正态分布随机张量
# 创建了一个 3x2 全零的张量。
z = torch.zeros(3, 2)
print(f"创建张量:\n x={x}\n y={y}\n z={z}")
# 索引和切片
print("\n===索引和切片:===")
# 获取了张量 x 第二行第三列的元素值,并将其转换为 Python 标量。
print("x[1, 2] =", x[1, 2].item()) # 获取标量值
# 对张量 x 进行切片操作,选择了所有行的第二列到最后一列的数据。
print("x[:, 1:] =\n", x[:, 1:])
# 形状变换
# 将 x 转换为形状为 3x2 的张量,但不复制数据(视图操作)。
reshaped = x.view(3, 2) # 视图操作(不复制数据)
# 对 x 进行转置操作。
transposed = x.t() # 转置
# 去除大小为1的所有维度,从而简化张量的形状。
squeezed = torch.randn(1, 3, 1).squeeze() # 压缩维度
print(f"\n形状变换:\n 重塑后: {reshaped.shape}\n 转置后: {transposed.shape}\n 压缩后: {squeezed.shape}")
# 数学运算
print("y=",y)
add = x + y # 逐元素加法操作。
print("transposed=",transposed)
matmul = x @ transposed # 矩阵乘法
sum_x = x.sum(dim=1) # 沿指定维度(这里是每行)求和。
print(f"\n===数学运算:===\n 加法:\n{add}\n 矩阵乘法:\n{matmul}\n 行和: {sum_x}\n")
# 广播机制
# 创建一个形状为 (3,) 的一维张量 a,即它有 3 个元素。相当于向量 [1, 2, 3]
a = torch.tensor([1, 2, 3])
# 创建一个形状为 (2, 1) 的二维张量 b,即它有 2 行 1 列。
b = torch.tensor([[10], [20]])
print("\n===广播机制===")
print("a的张量形状:",a.shape,",a=",a) # 输出张量的形状:
print("b的张量形状:",b.shape,",b=",b) # 输出张量的形状:
# 在 PyTorch 中,当你对两个不同形状的张量进行运算(如加法、乘法等)时,广播机制会自动扩展它们的维度,
# 使得它们的形状匹配,从而能够进行逐元素运算。
print(f"\n广播加法:\n{a + b}")
"""
1. 张量 a 和 b 的形状:
a.shape = (3,)
b.shape = (2, 1)
2. 广播过程(伪扩展):
👉 首先,在 a 前面自动添加维度使其变成 (1, 3):
a: (3,) → 自动变为 (1, 3)
👉 然后,b 的列数为 1,会沿着列方向复制以匹配 a 的列数(3):
b: (2, 1) → 扩展成 (2, 3)
👉 最终结果形状:(2, 3)
运算后的每个元素是 a[i] + b[j],其中 i 和 j 是广播后的索引
"""
# 内存共享验证
# 创建一个 view_tensor,它是 x 的一个视图(即与原张量共享内存)
view_tensor = x.view(6)
# 修改 view_tensor 中的一个元素后,可以看到原始张量 x 中相应的元素也被修改了,这证明了它们之间的内存是共享的。
view_tensor[0] = 100
print("\n内存共享验证(修改视图影响原始张量):")
print(f"视图: {view_tensor}\n原始: {x}")
小结
| 属性 | 数量(标量) | 向量 | 张量 |
|---|---|---|---|
| 阶数(维度) | 0阶(0维) | 1阶(1维) | 任意阶(n维) |
| 数据结构 | 单个数值 | 一维数组 | 多维数组 |
| 方向性 | 无方向 | 有方向 | 可能包含多个方向 |
| 数学运算 | 普通算术(+-*/) | 向量加减、点积、叉积 | 张量积、收缩、卷积等 |
| 物理意义 | 纯量(如能量) | 有方向的量(如力) | 复杂关系(如应力) |
生成式模型实战:古诗词的生成
首先,安装本实战所需的类库 transformers,安装命令如下:
bash
pip install transformers 下载模型和分词器
python
#将模型下载到本地调用
from transformers import AutoModelForCausalLM,AutoTokenizer
model_name = "uer/gpt2-chinese-poem"
#将模型和分词器下载到本地,并指定保存路径(Windows 请改为例如 D:/models/...,勿照搬 Linux 的 /root)
cache_dir = "/root/model/uer/gpt2-chinese-poem"
print(f"正在从镜像源下载模型到:{cache_dir} ...")
#下载模型
AutoModelForCausalLM.from_pretrained(model_name,cache_dir=cache_dir,trust_remote_code=True)
#下载分词工具
AutoTokenizer.from_pretrained(model_name,cache_dir=cache_dir,trust_remote_code=True)
print(f"✅ 下载成功!")
print(f"模型分词器已下载到:{cache_dir}")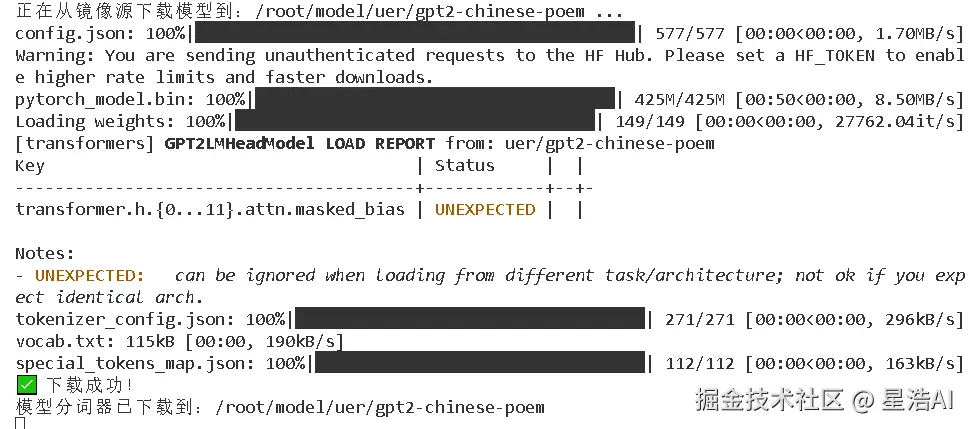
根据起始内容,输出后续诗句:
python
from transformers import BertTokenizer , GPT2LMHeadModel , TextGenerationPipeline
# 路径需与上一步 cache_dir 一致;snapshots 下哈希目录若不同,请改为本机 Hugging Face 缓存中的实际路径
tokenizer = BertTokenizer.from_pretrained("/root/model/uer/gpt2-chinese-poem/models--uer--gpt2-chinese-poem/snapshots/6335c88ef6a3362dcdf2e988577b7bafeda6052b")
model = GPT2LMHeadModel.from_pretrained("/root/model/uer/gpt2-chinese-poem/models--uer--gpt2-chinese-poem/snapshots/6335c88ef6a3362dcdf2e988577b7bafeda6052b")
text_generator = TextGenerationPipeline(model, tokenizer)
result = text_generator("[CLS] 万 叠 春 山 积 雨 晴 , ", max_length=20,do_sample=True)
print(result)这里需要提示一下,在上述代码段中,"CLS万叠春山积雨晴"是起始内容,然后根据所输入的起始内容输出后续的诗句,当然读者也可以自定义起始句子,如图所示。

图像降噪:手把手实战第一个深度学习模型
上面的示例读者可能感觉过于简单,真正深度学习程序设计不会这么简单,为了给读者建立一个使用PyTorch进行深度学习的总体印象,在这里准备了一个实战案例,手把手演示进行深度学习任务所需要的整体流程。
MNIST数据集的准备
MNIST 是一个手写数字图片的数据集,它有6万个训练样本集和1万个测试样本集。MNIST数据集如下所示:

本文配套源码中提供MNIST数据集,保存在 dataset 文件夹中,如图所示:

之后使用 NumPy 数据库进行数据读取,代码如下:
ini
import numpy as np
x_train = np.load("../dataset/mnist/x_train.npy")
y_train_label = np.load("../dataset/mnist/y_train_label.npy")你也可以从阿里云-天池下载(tianchi.aliyun.com/dataset/191...
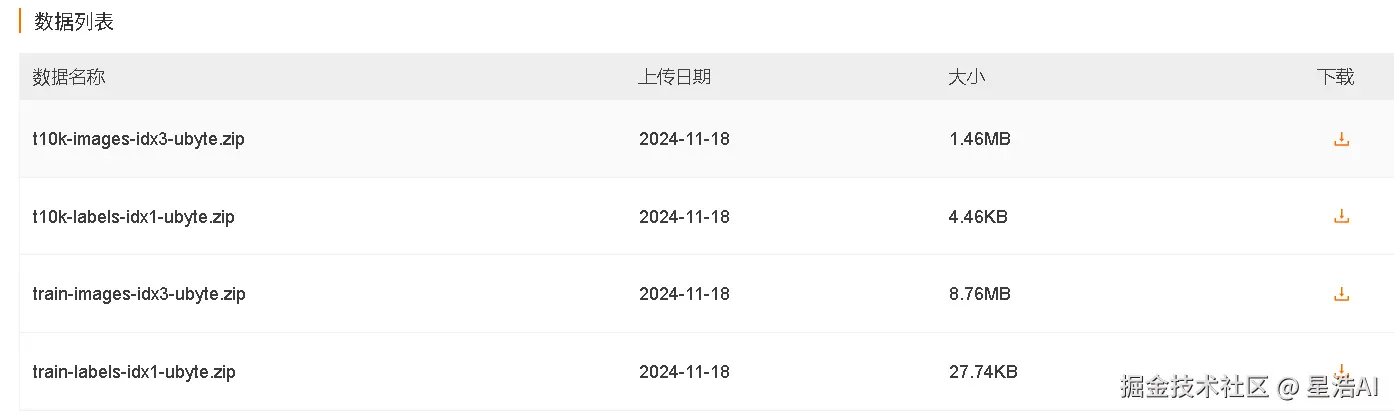
下载这4个文件并解压缩。解压缩后可以发现这些文件并不是标准的图像格式,而是二进制格式,包括一个训练图片集、一个训练标签集、一个测试图片集以及一个测试标签集。
MNIST数据集的特征和标签介绍
ini
import numpy as np
x_train = np.load("../dataset/mnist/x_train.npy")
y_train_label = np.load("../dataset/mnist/y_train_label.npy")
print(x_train.shape)
print(y_train_label.shape)这里numpy库函数会根据输入的地址对数据进行处理,并自动将其分解为训练集和验证集。打印训练集的维度如下:
scss
(60000, 28, 28)
(60000,)每个MNIST实例数据单元由两部分构成,分别是一幅包含手写数字的图片和一个与其对应的标签。可以将其中的标签特征设置成y,而图片特征矩阵以x来代替,所有的训练集和测试集中都包含x和y。
图片转换为向量模式,图片数据被展开成矩阵的形式,矩阵的大小为28×28个向量用以对图片特征进行标注。实际上,这些特征向量就是图片中的像素点,每幅手写图片是28,28的大小,每个像转化为一个0-1的浮点数,构成矩阵。
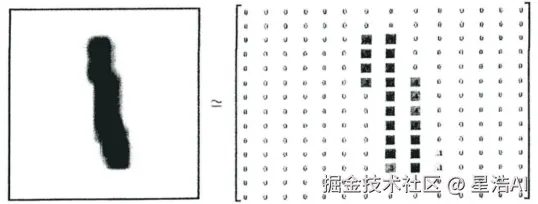
模型准备
对于使用PyTorch进行深度学习的项目来说,一个非常重要的内容是模型的设计。本示例的目的,输入一幅图像之后对其进行去噪处理。
对于模型的选择,简单的思路是,图像输出的大小就应该是输入的大小,在这里选择Unet(一种卷积神经网络)作为设计的主要模型。
对于Unet的结构,在这里我们只需要知道Unet的输入和输出大小是同样的维度即可。Unet模型的整体代码如下:
python
import torch
import einops.layers.torch as elt
class Unet(torch.nn.Module):
def __init__(self):
super(Unet, self).__init__()
#模块化结构,这也是后面常用到的模型结构
self.first_block_down = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1,out_channels=32,kernel_size=3,padding=1),torch.nn.GELU(),
torch.nn.MaxPool2d(kernel_size=2,stride=2)
)
self.second_block_down = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,padding=1),torch.nn.GELU(),
torch.nn.MaxPool2d(kernel_size=2,stride=2)
)
self.latent_space_block = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,padding=1),torch.nn.GELU(),
)
self.second_block_up = torch.nn.Sequential(
torch.nn.Upsample(scale_factor=2),
torch.nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, padding=1), torch.nn.GELU(),
)
self.first_block_up = torch.nn.Sequential(
torch.nn.Upsample(scale_factor=2),
torch.nn.Conv2d(in_channels=64, out_channels=32, kernel_size=3, padding=1), torch.nn.GELU(),
)
self.convUP_end = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=32,out_channels=1,kernel_size=3,padding=1),
torch.nn.Tanh()
)
def forward(self,img_tensor):
image = img_tensor
image = self.first_block_down(image)#;print(image.shape) # torch.Size([5, 32, 14, 14])
image = self.second_block_down(image)#;print(image.shape) # torch.Size([5, 16, 7, 7])
image = self.latent_space_block(image)#;print(image.shape) # torch.Size([5, 8, 7, 7])
image = self.second_block_up(image)#;print(image.shape) # torch.Size([5, 16, 14, 14])
image = self.first_block_up(image)#;print(image.shape) # torch.Size([5, 32, 28, 28])
image = self.convUP_end(image)#;print(image.shape) # torch.Size([5, 32, 28, 28])
return image
if __name__ == '__main__':
image = torch.randn(size=(5,1,28,28))
unet_model = Unet()
torch.save(unet_model, './unet_model.pth')对目标的逼近-模型的损失函数与优化函数
另外一个非常重要的内容是设定模型的损失函数与优化函数。
- 损失函数 损失函数的选择,在这里选用MSELoss作为损失函数,中文名字为均方损失函数。
MSELoss的作用是计算预测值和真实值之间的欧式距离。预测值和真实值越接近,两者的均方差超越小,均方差函数常用于线性回归模型的计算。在PyTorch中,使用MSELoss的代码如下:
ini
loss = torch.nn.MSELoss(reduction="sum")(pred, y_batch)- 优化函数 优化函数的选择,在这里选择Adam优化器。Adam优化器的代码,如下:
ini
optimizer = torch.optim.Adam(model.parmeters(), lr=2e-5)基于深度学习的模型训练
前面介绍了深度学习的数据准备、模型、损失函数以及优化函数,接下来使用PyTorch训练出一个可以实现去噪性能的深度学习整理模型,完整代码如下:
python
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #指定GPU编码
batch_size = 320 #设定每次训练的批次数
epochs = 1024 #设定训练次数
#device = "cpu" #Pytorch的特性,需要指定计算的硬件,如果没有GPU的存在,就使用CPU进行计算
device = "cuda" #在这里默认使用GPU,如果出现运行问题可以将其改成cpu模式
model = unet.Unet() #导入Unet模型
model = model.to(device) #将计算模型传入GPU硬件等待计算
model = torch.compile(model) #Pytorch2.0的特性,加速计算速度 选择使用内容
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5) #设定优化函数
#载入数据
x_train = np.load("../dataset/mnist/x_train.npy")
y_train_label = np.load("../dataset/mnist/y_train_label.npy")
x_train_batch = []
for i in range(len(y_train_label)):
if y_train_label[i] <= 10: #为了加速演示只对数据集中的小于2的数字,也就是0和1进行运行,读者可以自行增加训练个数
x_train_batch.append(x_train[i])
for epoch in range(30):
train_num = train_length // batch_size #计算有多少批次数
train_loss = 0 #用于损失函数的统计
#开始循环训练
....
#计算并打印损失值
train_loss /= train_num
print("train_loss:", train_loss)
if epoch%6 == 0:
torch.save(model.state_dict(),"./saver/unet.pth")
#下面是对数据进行打印
image = x_train[np.random.randint(x_train.shape[0])] #随机挑选一条数据进行计算
image = np.reshape(image,[1,1,28,28]) #修正数据维度
image = torch.tensor(image).float().to(device) #挑选的数据传入硬件中等待计算
image = model(image) #使用模型对数据进行计算
image = torch.reshape(image, shape=[28,28]) #修正模型输出结果
image = image.detach().cpu().numpy() #将计算结果导入CPU中进行后续计算或者展示
#展示或计算数据结果
plt.imshow(image)
plt.savefig(f"./img/img_{epoch}.jpg")运行代码之前先安装依赖包:
bash
pip install einops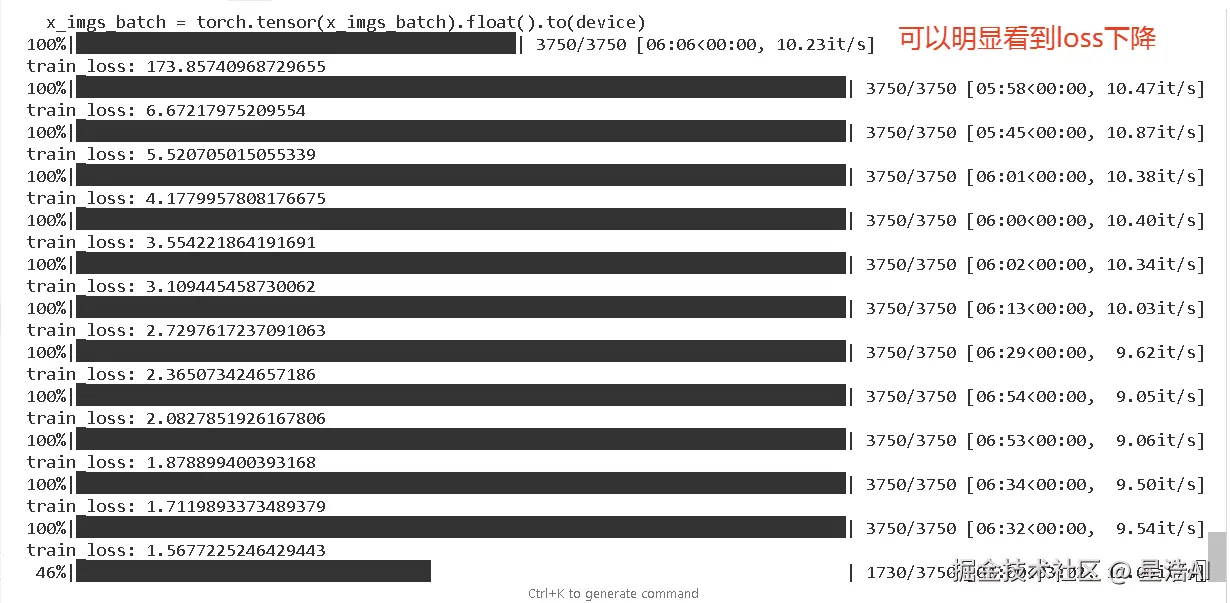 在这里展示了完整的模型训练过程,首先传入数据,然后使用模型对数据进行计算,计算结果与真实值的误差被回传到模型中,最后PyTorch框架根据回传的误差对整体模型参数进行修正。训练流程如下图所示:
在这里展示了完整的模型训练过程,首先传入数据,然后使用模型对数据进行计算,计算结果与真实值的误差被回传到模型中,最后PyTorch框架根据回传的误差对整体模型参数进行修正。训练流程如下图所示:

从上图中可以很清楚地看到,随着训练的进行,模型逐渐学会对输入的数据进行整形和输出,此时从输出结果来看,模型已经能够很好地对输入的图形细节进行修正。
有同学想自行运行代码测试一下的,可以点赞+关注,我将代码和数据集私信发给你,一起探索深度学习的奥秘。
小结
- 概念与工具:从 AI / ML / DL 与常见任务讲起,完成 PyTorch 环境与张量入门。
- 示例一(文本生成) :用
transformers跑通古诗续写,熟悉「模型 + 数据管线」的基本用法。 - 示例二(图像降噪):以 MNIST 为数据、U-Net 为模型,串起数据读取、损失函数与优化器、PyTorch 训练与权重保存的完整思路。
- 参考说明:结构与部分示例思路参考王晓华《从零开始大模型开发与微调》;本文为个人学习整理,与原著章节顺序、表述未必一致,系统学习请以正式出版物为准。