技术选型
Google 为 Android 开发者提供了三套机器学习方案,选择哪一条路径取决于具体场景:
-
ML Kit:开箱即用的预训练 API 套件。最低支持 API 21(Android 5.0)。适合快速集成文本识别、人脸检测、语言翻译等通用 AI 功能,开发者无需机器学习知识即可使用。
-
MediaPipe:Google 跨平台多媒体 ML 框架,支持目标检测、姿态估计、手势识别甚至端侧 LLM 部署。适合需要定制化机器学习模型和高性能推理的场景,但需要基础的模型训练和调优知识。
-
TensorFlow Lite:端侧推理引擎,允许自定义训练模型,支持 GPU、NPU 硬件加速。适合有完整模型训练能力的团队进行深度定制。
环境配置
无论选择哪条技术路径,首先都需要在 build.gradle(Project) 中配置 Google 的 Maven 仓库:
groovy
buildscript {
repositories {
google()
mavenCentral()
}
}接下来依据不同技术展开具体配置步骤与代码。
路径一:ML Kit 快速实现通用 AI 功能
ML Kit 提供 Vision 和 Natural Language 两大类 API,所有功能均支持端侧离线运行。
1. 添加依赖
在 app/build.gradle 中添加需要的模块:
groovy
dependencies {
// 文字识别 OCR
implementation 'com.google.mlkit:text-recognition:16.0.0'
// 人脸检测
implementation 'com.google.mlkit:face-detection:16.0.3'
// 图像标签识别(支持 80 余种常见物体)
implementation 'com.google.mlkit:image-labeling:17.0.8'
// 条码扫描
implementation 'com.google.mlkit:barcode-scanning:17.0.0'
// 翻译(需要连接翻译服务)
implementation 'com.google.mlkit:translate:17.0.0'
}2. 初始化
ML Kit 各 API 的初始化方式高度一致:
kotlin
// 文字识别
val textRecognizer = TextRecognition.getClient(TextRecognizerOptions.DEFAULT_OPTIONS)
// 人脸检测
val faceDetector = FaceDetection.getClient(FaceDetectorOptions.DEFAULT_OPTIONS)
// 物体检测与跟踪
val objectDetector = ObjectDetection.getClient(ObjectDetectorOptions.DEFAULT_OPTIONS)
// 图像标签识别
val imageLabeler = ImageLabeling.getClient(ImageLabelerOptions.DEFAULT_OPTIONS)
// 数字手写识别
val digitalInkRecognizer = DigitalInkRecognition.getClient()3. 核心代码实现
文字识别(OCR)
kotlin
/**
* 从 Bitmap 识别文字
*/
fun recognizeTextFromBitmap(bitmap: Bitmap, onSuccess: (String) -> Unit) {
val inputImage = InputImage.fromBitmap(bitmap, 0)
textRecognizer.process(inputImage)
.addOnSuccessListener { visionText ->
val result = StringBuilder()
visionText.textBlocks.forEach { block ->
block.lines.forEach { line ->
line.elements.forEach { element ->
result.append(element.text).append(" ")
}
result.append("\n")
}
}
onSuccess(result.toString())
}
.addOnFailureListener { e ->
Log.e("MLKit", "文字识别失败: ${e.message}", e)
}
}
/**
* 多语言识别(支持中文、英文、日文等混排)
*/
fun createMultiLanguageRecognizer(): TextRecognizer {
val options = TextRecognizerOptions.Builder()
.setLanguageHints(listOf("en", "zh", "ja"))
.build()
return TextRecognition.getClient(options)
}人脸检测
kotlin
/**
* 人脸检测
*/
fun detectFaces(bitmap: Bitmap, onResult: (List<Face>) -> Unit) {
val image = InputImage.fromBitmap(bitmap, 0)
faceDetector.process(image)
.addOnSuccessListener { faces ->
// faces 包含人脸位置、边界框、特征点等
onResult(faces)
}
.addOnFailureListener { e ->
Log.e("MLKit", "人脸检测失败: ${e.message}", e)
}
}
/**
* 配置人脸检测器(开启轮廓检测和分类)
*/
fun createFaceDetectorWithOptions(): FaceDetector {
val highAccuracyOpts = FaceDetectorOptions.Builder()
.setPerformanceMode(FaceDetectorOptions.PERFORMANCE_MODE_ACCURATE)
.setLandmarkMode(FaceDetectorOptions.LANDMARK_MODE_ALL) // 开启特征点(眼睛、鼻子等)
.setClassificationMode(FaceDetectorOptions.CLASSIFICATION_MODE_ALL) // 开启表情分类
.enableTracking()
.build()
return FaceDetection.getClient(highAccuracyOpts)
}物体检测与分类
kotlin
/**
* 物体检测(支持多物体跟踪)
*/
fun detectObjects(bitmap: Bitmap, onResult: (List<DetectedObject>) -> Unit) {
val image = InputImage.fromBitmap(bitmap, 0)
objectDetector.process(image)
.addOnSuccessListener { detectedObjects ->
// 每个对象包含边界框、跟踪 ID 和标签
onResult(detectedObjects)
}
.addOnFailureListener { e ->
Log.e("MLKit", "物体检测失败: ${e.message}", e)
}
}4. 自定义模型集成
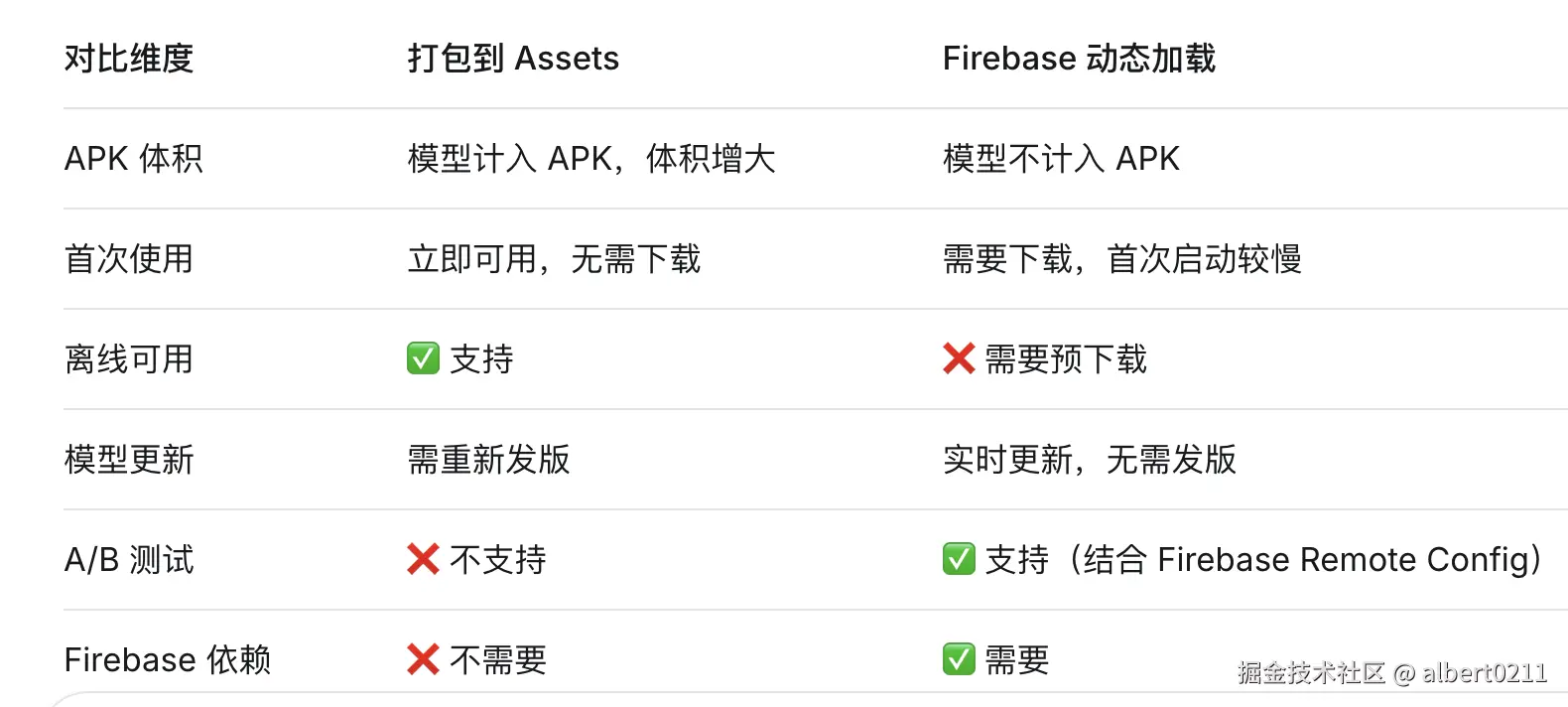
无需从头训练,使用 ML Kit 可以直接加载已有的 TensorFlow Lite 模型。 方案一:模型打包进 Assets 在 build.gradle 中引入自定义模型依赖:
groovy
dependencies {
implementation 'com.google.mlkit:object-detection-custom:17.0.2'
implementation 'com.google.mlkit:image-labeling-custom:17.0.0'
}将 .tflite 模型文件放入 app/src/main/assets/ 目录,加载时指定模型名称即可。
方案二:从 Firebase 动态加载(推荐)
依赖配置:
groovy
dependencies {
implementation 'com.google.mlkit:object-detection-custom:17.0.2'
implementation 'com.google.mlkit:linkfirebase:17.0.0'
implementation 'com.google.firebase:firebase-ml-modeldownloader:16.5.0'
}实现代码:
kotlin
import com.google.firebase.ml.modeldownloader.FirebaseModelDownloader
import com.google.mlkit.linkfirebase.FirebaseModelSource
import com.google.mlkit.linkfirebase.LinkFirebaseModelSource
import com.google.mlkit.vision.objects.ObjectDetection
import com.google.mlkit.vision.objects.custom.CustomObjectDetectorOptions
class CustomModelActivity : AppCompatActivity() {
private lateinit var customDetector: ObjectDetector
private fun loadModel() {
val modelDownloader = FirebaseModelDownloader.getInstance()
val customModel = FirebaseModelSource.Builder(
modelDownloader.getModel("custom_model", DownloadType.LATEST_MODEL)
).build()
val options = CustomObjectDetectorOptions.Builder(customModel)
.setDetectorMode(CustomObjectDetectorOptions.STREAM_MODE)
.enableClassification()
.build()
customDetector = ObjectDetection.getClient(options)
}
}两种集成方式的取舍如下表所示:
5. 实时摄像头识别
结合 CameraX 可实现实时视频帧处理:
kotlin
private val imageAnalyzer = ImageAnalysis.Analyzer { imageProxy ->
val mediaImage = imageProxy.image ?: return@Analyzer
val inputImage = InputImage.fromMediaImage(
mediaImage,
imageProxy.imageInfo.rotationDegrees
)
textRecognizer.process(inputImage)
.addOnSuccessListener { visionText ->
// 处理识别结果,更新 UI
runOnUiThread { updateTextResult(visionText) }
}
.addOnFailureListener { e ->
Log.e("MLKit", "实时识别失败: ${e.message}", e)
}
.addOnCompleteListener { imageProxy.close() }
}6. 性能优化建议
-
调整检测模式 :开启
STREAM_MODE可显著提升检测帧率。若开启多个检测器导致性能下降,可统一在后台线程处理输入并同步降级 UI 帧率。 -
限制并发调用:避免在短时间内发起大量信号调用,建议接收并合并后续数据队列定时统一处理。
-
缩略图降精度:使用按比例压缩的原图输入比原始高精度图可节约算力资源。
-
按需加载模型 :Firebase Model Downloader 支持指定
DownloadType.LATEST_MODEL,并在后台缓存结果再使用。 -
模型按需打包 :针对
object-detection-custom等自定义模块,可选择性引入所需模型以减少 APK 体积。
路径二:MediaPipe 构建自研端侧 AI 功能
MediaPipe 提供更底层的自研模型框架,适合构建从计算机视觉到生成式 AI 的各类端侧推理任务。
1. Vertex AI 兼容与 MediaPipe Tasks
-
开发效率优先 :直接安装
tasks-vision依赖即可使用简单 API。 -
自定义模型:通过 Bazel 构建 AAR 文件(Android Archive Library,Android 专用打包格式)。
2. 集成 MediaPipe Tasks(以图像分类为例)
Gradle 依赖配置:
groovy
dependencies {
implementation 'com.google.mediapipe:tasks-vision:latest.release'
}实现代码:
kotlin
import com.google.mediapipe.tasks.vision.core.RunningMode
import com.google.mediapipe.tasks.vision.imagesegmenter.ImageSegmenter
import com.google.mediapipe.tasks.vision.imagesegmenter.ImageSegmenterOptions
class MediaPipeVisionActivity : AppCompatActivity() {
private lateinit var imageClassifier: ImageClassifier
private lateinit var imageSegmenter: ImageSegmenter
private lateinit var faceDetector: FaceDetector
private fun setupImageClassifier() {
val options = ImageClassifierOptions.builder()
.setModelAssetPath("mobilenet_v2_1.0_224.tflite")
.setRunningMode(RunningMode.IMAGE) // 静态图像模式
.setMaxResults(5)
.build()
imageClassifier = ImageClassifier.createFromOptions(context, options)
}
private fun setupImageSegmenter() {
val options = ImageSegmenterOptions.builder()
.setModelAssetPath("deeplab_v3.tflite")
.setRunningMode(RunningMode.IMAGE)
.build()
imageSegmenter = ImageSegmenter.createFromOptions(context, options)
}
private fun classifyImage(bitmap: Bitmap) {
val mpImage = BitmapImageBuilder(bitmap).build()
val result = imageClassifier.classify(mpImage)
result.classificationResults().forEach { classification ->
classification.categories().forEach { category ->
Log.d("MediaPipe", "${category.categoryName()}: ${category.score()}")
}
}
}
}3. 从源码构建 tasks_vision 模块
若需深度定制 MediaPipe(如集成私有预处理/后处理逻辑、针对特定硬件调优),建议从源码构建 AAR 文件。
环境要求:Ubuntu 18.04+、Bazel 6.0+、Android SDK/NDK、至少 8GB 内存与 50GB 磁盘。
bash
# 获取源码
git clone https://github.com/google/mediapipe
cd mediapipe
# 基础依赖模块构建
bazel build -c opt --config=android_arm64 \
//mediapipe/tasks/java/com/google/mediapipe/tasks/core:tasks_core.aar
# 视觉模块完整构建(含 armeabi-v7a 和 arm64-v8a 双架构)
bazel build -c opt --strip=ALWAYS \
--host_crosstool_top=@bazel_tools//tools/cpp:toolchain \
--fat_apk_cpu=arm64-v8a,armeabi-v7a \
--legacy_whole_archive=0 \
--features=-legacy_whole_archive \
--copt=-fvisibility=hidden \
--copt=-ffunction-sections \
--copt=-fdata-sections \
--copt=-fstack-protector \
--copt=-Oz \
--linkopt=-Wl,--gc-sections,--strip-all \
mediapipe/tasks/java/com/google/mediapipe/tasks/vision:tasks_vision构建产物位于 bazel-bin/mediapipe/tasks/java/com/google/mediapipe/tasks/vision/tasks_vision.aar 和 bazel-bin/mediapipe/tasks/java/com/google/mediapipe/tasks/core/tasks_core.aar。
4. MediaPipe LLM Inference API(端侧大语言模型)
MediaPipe 支持在 Android 设备上运行大语言模型推理,基于 AICore 系统服务实现模型共享和硬件加速。 AICore 是 Android 的系统级 AI 服务,负责管理 Gemini Nano 模型的生命周期、更新和执行。多个应用可共享同一模型实例,避免了每个应用单独打包 2GB 模型导致的内存溢出;模型更新由 Google Play 系统更新推送,无需应用发版。
kotlin
class LLMSession {
private lateinit var llmInference: LlmInference
fun initializeLLM() {
val options = LlmInferenceOptions.builder()
.setModelPath("gemma2_2b.task") // 使用 .task 格式模型文件
.setMaxTokens(512)
.setTemperature(0.7f)
.build()
llmInference = LlmInference.createFromOptions(context, options)
}
suspend fun generateResponse(prompt: String): String = suspendCancellableCoroutine { continuation ->
llmInference.generateResponse(prompt) { response, error ->
if (error == null) {
continuation.resume(response)
} else {
continuation.resumeWithException(Exception(error))
}
}
}
}模型初始化为高延迟操作,必须在后台线程执行,切勿在主线程调用,否则会触发 ANR(Application Not Responding,应用无响应错误)。
路径三:TensorFlow Lite + Model Maker 自定义训练部署
当 ML Kit 的通用 API 和 MediaPipe 的预置任务无法满足业务需求时,建议选择此路径。
1. 模型训练与转换(TensorFlow Lite Model Maker)
Model Maker 可将自定义训练集自动转化为优化的 .tflite 模型,并完成量化压缩(模型体积最高减少 75%)。
python
# Python 端训练
import tensorflow as tf
from tflite_model_maker import image_classifier
from tflite_model_maker.image_classifier import DataLoader
# 加载数据
data = DataLoader.from_folder('flower_photos/')
train_data, test_data = data.split(0.9)
# 训练模型
model = image_classifier.create(train_data)
# 评估并导出 TensorFlow Lite 模型
loss, accuracy = model.evaluate(test_data)
model.export(export_dir='.')2. Android 集成
将生成的 .tflite 模型放入 assets/ 目录,通过 LiteRT Task Library 加载:
kotlin
dependencies {
implementation 'org.tensorflow:tensorflow-lite-task-vision:0.4.4'
implementation 'org.tensorflow:tensorflow-lite-gpu:2.13.0' // GPU 加速
}
kotlin
class TFLiteClassifier(private val context: Context) {
private lateinit var imageClassifier: ImageClassifier
init {
val options = ImageClassifierOptions.builder()
.setModelAssetPath("custom_model.tflite")
.setMaxResults(3)
.setDelegate(Delegate.GPU) // 启用 GPU 加速
.build()
imageClassifier = ImageClassifier.createFromOptions(context, options)
}
fun classify(bitmap: Bitmap): List<Category> {
val tensorImage = TensorImage.fromBitmap(bitmap)
val result = imageClassifier.classify(tensorImage)
return result[0].categories
}
}3. 部署方案对比

性能优化与最佳实践
