1、RLHF概念
RLHF:基于人类反馈的强化学习。
2、RLHF训练数据样式
RLHF的数据并没有单一的标准格式,具体包含哪些字段,根据训练阶段和算法不同而有差异。
(1)基础的成对偏好数据
- 应用场景:这是RLHF中最核心、使用最广泛的格式,用于训练一个"奖励模型"。
- 核心字段:prompt(用户问题)、chosen(优质回答)、rejected(质量较差的回答)
示例:
{
"prompt": "解释大语言模型的SFT算法",
"chosen": "SFT即监督微调,是大模型人类对齐的第一步,通过高质量人类标注的指令-回答数据对预训练模型做轻量化微调...",
"rejected": "SFT是一种微调方法,用数据训练模型,让模型听懂指令。"
}(2)带对话历史的多轮数据
-
应用场景:奖励模型训练,尤其适用于需要考虑上下文理解的复杂对话
-
核心字段:context(对话历史)、chosen(优质回答)、rejected(质量较差的回答)
{
"context": [
{"role": "human", "text": "我可以用笔作什么恶作剧?"},
{"role": "assistant", "text": "你在找实际的笑话想法吗?"},
{"role": "human", "text": "yep (对)"},
{"role": "assistant", "text": "OK,我给你们举几个例子...用笔作为拉链..."},
{"role": "human", "text": "其中一些与笔没有任何关系"}
],
"chosen": {"role": "assistant", "text": "不,对不起,所有这一切都涉及一支笔..."},
"rejected": {"role": "assistant", "text": "你可以用笔做很多有趣的事情,例如用笔在手指上涂鸦..."}
}
3、奖励模型
(1)概念
输入:一个提示(prompt)和一个对应的回答(response)
输出:一个标量分数,代表该回答的好/坏程度。分数越高表示模型越应该学习这种行为,分数越低表示应该避免。
(2)训练数据准备
训练奖励模型不需要绝对分数标签,而是利用成对比较。
人工标注员会比较同一个prompt下两个模型生成的回答A和B,判断哪一个更好。
奖励模型通过大量这样的比较数据,学习预测出符合人类偏好的相对排序。
举例:
Prompt:"解释一下机器学习中的 SFT。"
回答A(chosen):"SFT 即监督微调,它是指..."(详细、正确、条理清晰)
回答B(rejected):"SFT 是一种微调方法。"(过于简短、信息不全)
训练数据告诉奖励模型:chosen 的分数应该高于 rejected。(3)损失函数
主流损失函数是一个排序模型的损失函数:
Bradley-Terry损失,一个Pairwise Ranking Loss。
假设对于同一个prompt x,有两个回答(赢家,人类偏好)和
(输家)。
奖励模型分别为它们打分和
,分别记为
和
。
Bradley-Terry假设人类偏好而非
的概率为:
,
是sigmoid函数
Bradley-Terry损失函数为:
当 -
很大时,
约为1,那么L约为0,损失很小,模型已经正确区分。
当 -
为0时,
为0.5,L约为0.693
当 -
为负数比如-5时,
约为0.0067,L约为5,损失很大
(4)怎么训练
【步骤1:准备偏好数据集】
- 收集大量prompt,来自用户真实查询或人工编写
- 对每个prompt,用若干个待对齐的模型(通常是SFT模型或其他中间模型)生成2~4个回答
- 人类标注员进行成对比较或排序,生成(prompt, chosen, rejected)格式的数据
【步骤2:确定模型架构】
- 通常复用语言模型的backbone,然后在最后一层之上增加一个线性层(输出1维标量分数)
- 常见选择:与待对齐的策略模型使用相同或相近结构的模型(例如7B/13B的LLaMA或GPT架构)
- 也可以使用更小的专用评分模型
【步骤3:训练前处理】
- 对于每一条(prompt, chosen, rejected),分别构造两个输入:
-
prompt + chosen
-
prompt + rejected
- 使用相同的奖励模型分别计算两个分数
和
- 因为损失函数只关心分数差,因此在同一batch内成对传入
【步骤4:优化训练】
- 损失函数:标准Bradley-Terry负对数似然
- 优化器:AdamW等,学习率通常与预训练阶段小
- 训练数据充分时,奖励模型可以非常准确地拟合人类偏好
【步骤5:正则化】
- 为防止奖励模型过拟合或分数爆炸,可以加入奖励归一化(如将分数转为平均0方差1)或权重衰减。
归一化目标:将奖励模型的输出分数变换为均值为0、方差为1的标准分布,这样分数范围受控(大部分在-3,3左右),奖励分数的相对大小依然保持排序性质
归一化常见方法:在奖励模型的最后一层(线性层输出标量之前或之后)插入 BatchNorm 层。训练时,每个 batch 计算输出的均值和方差,并归一化。推理时使用训练阶段累积的全局均值和方差。
权重衰减定义:
权重衰减是一种最常见的显式正则化技术,在损失函数中添加参数的 L2 范数惩罚:
其中是模型所有可训练参数(主要是线性层权重),
是权重衰减系数(通常很小,比如1e-5或更小)。
权重衰减的防止过拟合机制:
-
限制参数复杂度:L2惩罚鼓励模型权重趋向于小值,从而降低模型对输入微笑变化的敏感度,迫使模型学习更平滑的函数。对于奖励模型,这意味着不会对特定prompt-response对的微小差异产生极端分数变化。
-
抑制噪声拟合:如果偏好数据中存在标注错误或噪音,没有正则化的模型可能强行记住这些噪声,导致过拟合,权重衰减可以减弱这种记忆能力。
|--------|--------------|
| 方法 | 作用 |
| 奖励归一化 | 处理输出分数层面的稳定性 |
| 权重衰减 | 处理参数层的复杂度惩罚 |
4、小结1
RLHF数据的样式:JSONL格式,包含prompt,chosen,rejected等字段,以及多轮对话、二元反馈等变体。
奖励模型的原理:输入prompt + response输出标量分数,用Bradley-Terry损失训练,sigmoid将分数转为偏好概率,负对数似然。
奖励模型的训练:偏好数据集、模型架构(backbone+线性头)、训练过程、正则化(权重衰减、奖励归一化)。
RLHF的整体流程:
- 先对预训练模型进行监督微调(SFT),使其具备基本的指令跟随能力;
- 利用SFT模型生成候选回答,收集人类偏好数据,训练一个奖励模型用于给回答打分;
- 最后通过强化学习(如PPO),使用奖励模型的打分作为优化信号,进一步对齐人类偏好,迭代更新LLM模型。
5、RLHF的强化学习
(1)有了SFT,为什么需要RL
概述:SFT后的模型通常已经不错,但强化学习(RL)可以进一步优化它与人类偏好的对齐,尤其是在"偏好差异微妙"或"需要权衡多个目标"时。但RLHF并不是唯一或必须的步骤,近年来出现了更简单的替代方案(如DPO)。
详细解读如下:
SFT本质是最大似然估计:让模型模仿人类标注的"标准答案",这带来了4个局限:
- 无法学习偏好排序:SFT只学到"正确答案长什么样",但不知道两个回答间哪个更好,例如都正确但一个更礼貌、更简洁。人类偏好是相对的,而SFT丢失了这种排序信息。
- 暴露偏差:SFT训练时每个token的输入都是ground truth,但推理时模型看到的是自己生成的token。微小错误会累积。RL在完整序列上优化,可缓解这一问题。
- 难以融入复杂、冲突的目标:真实人类偏好是多维的(helpful、harmless、honest...),且彼此冲突。SFT只能拟合数据分布,而RL可以通过奖励函数灵活调整这些目标的权重。
- 对"不完美数据"鲁棒性差:SFT数据中存在噪声(标注错误、主观差异),模型会无差别学习。RL结合奖励模型(学习的是整体偏好)可在一定程度上过滤噪声。
(2)基本概念
- 策略(Policy,
- 动作(Action):生成一个token或完整回答
- 状态(State):当前已生成的token序列(包括prompt)
- 奖励(Reward):由奖励模型对完整回答打分
- 轨迹(Trajectory):一个完整的prompt 以及 回答序列。
- 优势函数(Advantage Function):衡量某个动作比平均动作好多少,用于减少方差
- 价值函数(Value Function,V):估测当前状态下的期望累积奖励,通过由一个Critic网络(与策略模型结构类似)学习。
6、PPO算法通俗简洁说明
【核心】
每次只允许模型"改进一点点",既鼓励得高分,又防止模型偏离太远导致能力退化。
【为什么要PPO】
- 直接用奖励模型分数更新LLM模型,容易一步学崩,比如遗忘语法、重复乱码
- PPO通过限制更新幅度保证稳定
【关键机制:概率比裁剪】
定义概率比 = 新模型输出该token的概率 / 旧模型输出该token的概率
- 裁剪:让
-
若奖励好,想增加概率 -> 最多增加20%
-
若奖励差,想降低概率 -> 最多降低20%
- 效果:稳健小步走,不激进
【额外安全绳:KL惩罚】
在奖励里扣除"新旧策略分布差异",防止模型变得太离谱,保留基础语言能力。
【需要的两个网络】
Actor:生成回答,更新时受裁剪限制
Critic:预测当前状态未来总奖励,帮助计算优势(好/坏的相对值)
【训练循环】
-
采样:用旧策略对一批prompt生成回答
-
打分:奖励模型打分 + 减去KL惩罚
-
计算优势:Critic帮忙算出每个token比平均好多少
-
更新Actor:用裁剪后的目标函数,小步更新
-
更新Critic:让它预测更准
【总结】
PPO = 带缓冲带的教练:大步不让跨,方向不能偏(KL),副手看路(Critic)。
7、奖励模型与Critic的联动
(1)奖励模型(RM)提供原始奖励
对于一个完整的回答,从prompt到最后一个token,奖励模型输出一个标量分数R。
在RLHF的PPO中,通常把这个最终奖励下播给回答中的每个token位置,即每个时间步t都能拿到这个最终的R(也可以只给最后一个token奖励,其他为0)。简化理解:整个序列共享同一个奖励分数。
(2)Critic(价值网络)估计每个状态的价值
Critic接收当前状态(当前已生成的token序列),输出一个标量
。
表示:如果从现在开始按照当前策略继续生成,最终能获得的期望总奖励。
(3)计算回报-实际累积奖励
回报是从时间步t开始,实际获得的奖励之和(通常是衰减求和)。
在RLHF简化版中,若整个回答只有一个最终奖励R,则每个token位置的回报可以设为,或折扣因子
。
(4)优势(Advantage)- 连接Critic和奖励模型的关键
:实际获得的奖励,来自奖励模型+折扣
:Critic预测的期望奖励
优势为正:这个token比平均水平好,策略应该增加它出现的概率。
优势为负:比平均差,降低概率。
奖励模型提供了"实际表现",Critic提供了"预期基准",二者差值高速策略模型该往哪方向调整。
(5)PPO更新策略时使用优势
PPO中的裁剪损失函数直接使用乘以概率比
:
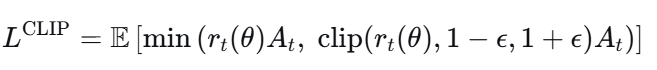
所以,奖励模型的分数通过影响,进而影响
,最终驱动策略更新。
(6)小结
奖励模型给出"实际得分",Critic预测"期望得分",两者相减得到"优势",优势告诉PPO哪些token该加强,哪些该削弱。
8、PPO算法详细说明
(1)策略梯度方法的局限性
传统策略梯度Actor-Critic的目标函数为:
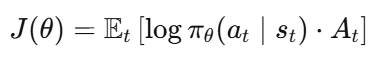
其中是优势函数,更新时:
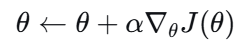
问题:更新步长难以选择。步长过大,策略奔溃;步长过小,收敛缓慢。
(2)限制策略更新幅度
定义概率比:
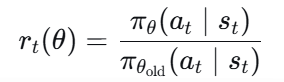
若新旧策略相同,则
偏离1表示新策略在该动作上的概率发生了变化。
PPO通过裁剪,使其保持在
范围内,从而限制单步更新幅度。
(3)PPO-Clip目标函数
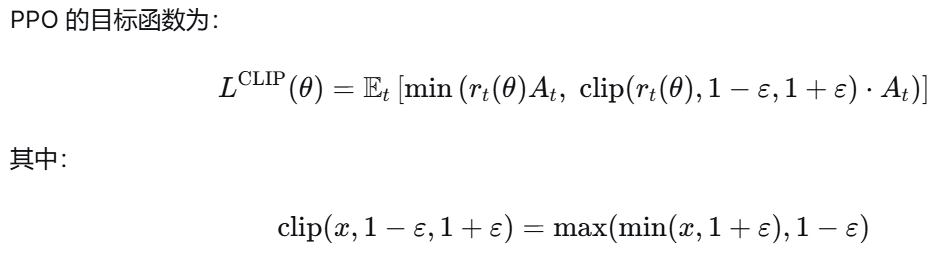
(4)优势估计:GAE(广义优势估计)
奖励模型给出每个token的即时奖励(通常最终奖励下放到每一步)。定义TD误差:
其中是价值网络Critic的输出。GAE累加多部TD误差:
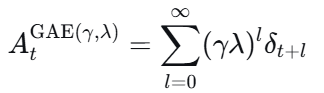
:只看一步,低偏差高方差
:看完整轨迹,高偏差低方差
常用超参:
此时回报(目标价值)为:
(5)总结
PPO通过裁剪概率比限制新旧策略的差异,结合GAE优势估计和价值网络,实现稳定且高效的策略优化。
9、RLHF总结
(1)SFT阶段的细节
【数据来源】
人工白哦住的指令-回答对
【训练方式】
标准自回归语言建模损失(CrossEntropy),通常全量微调或LoRA
【关键技巧】
使用prompt+answer格式,answer部分计算loss,prompt部分mask掉
【输出】
SFT模型作为RL阶段的初始策略,也将用于KL惩罚的参考分布
【为什么要RLHF?】
SFT模型本身已经能回答指令,但它在"偏好排序"任务上未经优化,这正是RLHF要解决的。
(2)奖励模型RM训练细节
【数据构造】
每个prompt生成2~4个回答,人工标注成对比较(chosen/rejected)
【模型结构】
通常复用SFT模型,最后一层改为线性层输出1维标量
【损失函数】
Bradley-Terry成对排序损失:
【批次处理】
每条数据两个输入(chosen和rejected),分别前向得到分数后再计算损失。
【正则化】
权重衰减 + 输出归一化 可防止分数爆炸
【验证指标】
准确率(测试集上chosen得分 > rejected得分的比例),通常要求大于70%。
(3)RL阶段与RLHF的具体结合细节
(3.1)KL惩罚项
避免策略模型偏移SFT模型太远,在每一步的奖励中减去KL散度:
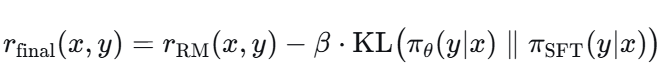
其中KL通常逐token计算。
平衡对齐强度与原始能力保持(常用0.1~0.01)
(3.2)Critic网络初始化
Critic 通常与 Actor 共享大部分参数(如主干网络),只将输出层改为 1 维。初始化时其输出应接近 0,以配合奖励归一化。
(3.3)优势归一化
对每个batch计算的优势进行z-score归一化:减去均值除以标准差。这能稳定训练,防止优势绝对值过大。
(3.4)经验回放与批量处理
PPO是On-Policy,但允许使用当前策略采样的一批数据多次更新(K epochs),需小心过拟合这批数据。
(3.5)奖励模型的推理缓存
RL阶段每生成一个回答就要调用一次RM打分,计算开销大。
通常将RM与策略模型放在同一设备或分布式推理。
(4)通俗解读
训练需要搭建一整套"教学团队":
- 学生:就是我们要训练的语言模型(策略网络),目标是写好作文(生成高质量回答)
- 参考书:学生的"基础教材",也就是SFT模型。学生不能完全丢掉教材乱写,否则会胡言乱语
- 老师:奖励模型(RM)。老师专门否则给任何一篇作文打分,分数越高代表越符合人类偏好
- 助教:价值网络(Critic)。助教的职责是预测学生当前作文大概能得多少分,帮助教练判断每一步进步了多少
- 教练:PPO 算法。教练不亲自写作文,而是监督学生练习:让学生在操场上写很多篇作文,老师每篇打分,助教给出期望分数,教练综合这些反馈,小心翼翼地调整学生的写作方法------而且必须一步一小步,因为步子迈太大(策略更新过猛)学生会摔跤(输出乱码)。
结果:整个团队养着 学生+参考书+老师+助教 四个模型,教练还要调一大堆参数(步幅、KL惩罚系数等)。训练慢、又容易崩,光是让几个人配合默契就要花很多精力。
10、DPO算法
DPO的做法:不需要老师、助教、教练,只要把"好答案 vs 坏答案"直接扔给学生,学生自己就能学会。
1. 数据前提
学生手上有参考书(SFT模型,冻结不动),以及一个(好答案 vs 坏答案
)对。
2.计算分数差
学生自动计算出一个隐形的分数差:
分数差= 好答案的"相对优势" - 坏答案的"相对优势"
其中,
相对优势 = 当前模型对该答案的偏好程度 - 参考书对该答案的偏好程度。
这个值可以是正数(当前模型比参考书更喜欢这个答案),也可以是负数(当前模型比参考书更讨厌这个答案)。
对于好答案:我们希望当前模型比参考书更喜欢它,相对优势为正。
对于坏答案:我们希望当前模型比参考书更讨厌它,相对优势为负。
因此:分数差 = (一个正数 - 一个负数)=
(正数 + 正数)=一定是一个更大的正数。
这个分数差越大,说明模型对好答案的偏爱程度远超过对坏答案的偏爱程度。
3.计算"好答案优于坏答案"的概率
将这个分数差放入sigmoid函数,得到"好答案由于坏答案"的概率:
,score为分数差
4.二分类任务
我们希望模型预测的"好答案优于坏答案"的概率P尽量接近1。
DPO的二分类:
输入是分数差
输出
标签始终为1,因为好答案理应胜出。
损失:BCE,且标签固定为1,就成了。
DPO 的二分类任务:将 (好答案, 坏答案) 对输入模型,计算隐式奖励差值,输出"好答案优于坏答案"的概率;然后用固定标签"1"计算二元交叉熵损失,驱使模型拉大正负样本的分数差距。
5.结果
学生看着(好答案,坏答案)对,自己更新参数,让好答案更容易出现,坏答案更难出现。
全程只有一个学生在学,参考书冻在那里不动。
没有老师打分,没有助教预测,没有教练调步幅。