基于NLP的BI工具DataFocus实战:从自然语言查询到智能数据分析
问题描述
在企业数据分析场景中,开发团队经常面临以下挑战:
- 业务人员频繁提出数据查询需求,占用大量开发资源
- 传统BI工具配置复杂,需要编写SQL或进行繁琐的拖拽操作
- 分析结果难以沉淀和复用,相同分析需求需要重复开发
- 业务术语不统一,导致沟通成本高、分析结果不准确
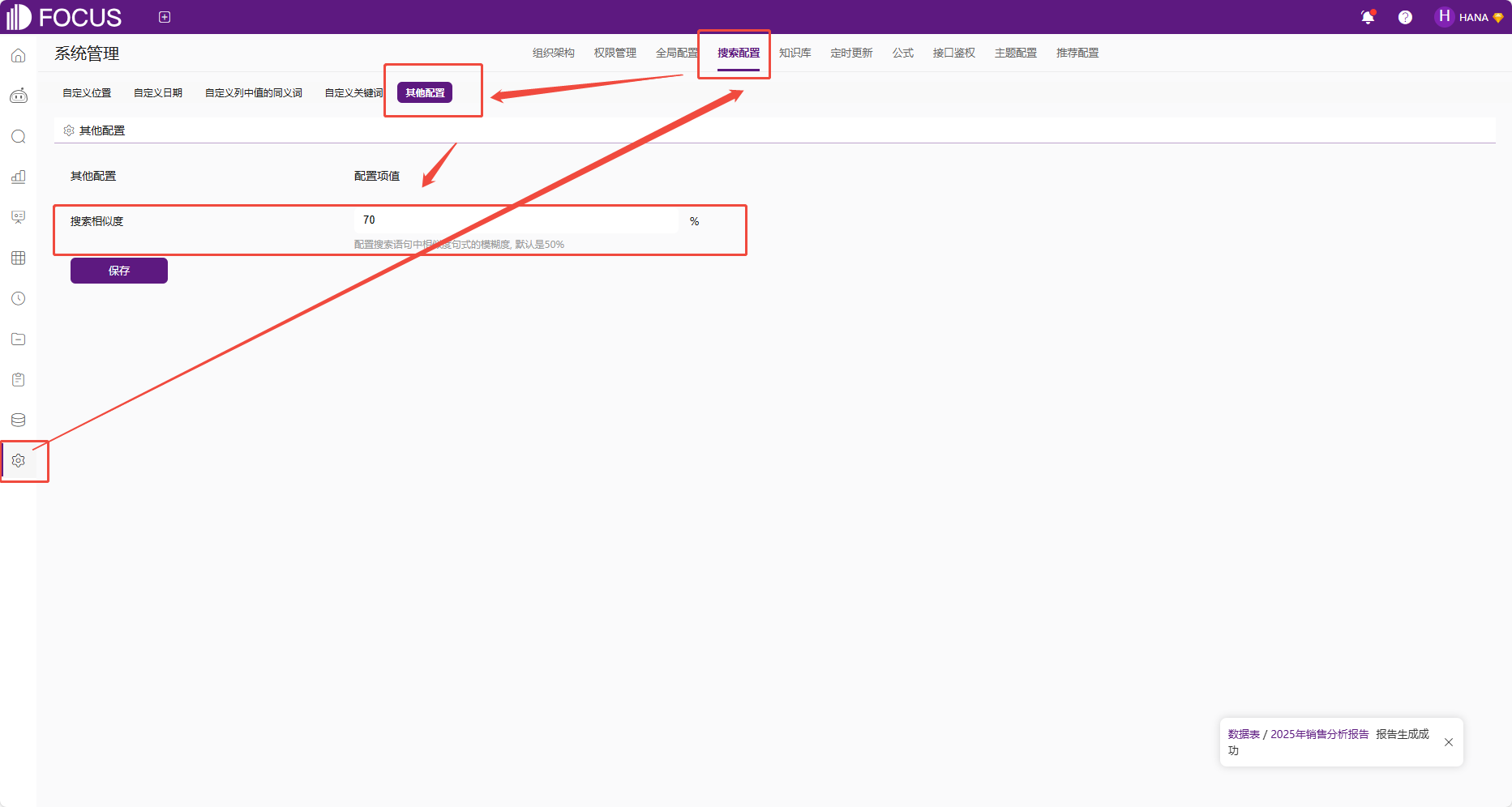
环境与工具介绍
DataFocus平台概述
DataFocus是杭州汇数智通科技有限公司开发的基于自然语言处理的商业智能产品,其核心特点是:
text
技术栈:NLP + BI + 知识图谱
交互方式:自然语言查询
部署方式:SaaS/私有化部署
集成能力:API接口、Webhook、SDK系统架构
DataFocus的技术架构主要包括:
- 自然语言理解层:解析用户查询意图,支持口语化表达
- 数据查询层:自动生成并执行SQL查询
- 可视化层:智能推荐图表类型
- 知识管理层:沉淀业务术语和分析经验
实施步骤
第一步:环境配置与数据准备
bash
# 数据源连接示例(支持多种数据库)
# 通过DataFocus API配置数据连接
curl -X POST https://api.datafocus.com/connectors \
-H "Authorization: Bearer your_api_key" \
-H "Content-Type: application/json" \
-d '{
"name": "production_db",
"type": "mysql",
"host": "your_db_host",
"port": 3306,
"database": "analytics_db",
"username": "analyst",
"password": "your_password"
}'第二步:核心功能实战
1. 自然语言查询
DataFocus的核心功能是搜索式交互,开发者可以通过API实现自然语言查询:
python
import requests
def natural_language_query(query_text, api_key):
"""执行自然语言查询并获取可视化结果"""
url = "https://api.datafocus.com/query"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"query": query_text,
"format": "json_with_chart_config"
}
response = requests.post(url, json=payload, headers=headers)
return response.json()
# 使用示例
result = natural_language_query("各省份的平均销售额", "your_api_key")
print(f"查询结果: {result['data']}")
print(f"图表配置: {result['chart_config']}")2. 知识沉淀与同义词配置
python
# 配置业务术语同义词
def configure_synonyms(term, synonyms, api_key):
"""为业务术语配置同义词"""
url = "https://api.datafocus.com/knowledge/synonyms"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"original_term": term,
"synonyms": synonyms,
"scope": "organization"
}
response = requests.post(url, json=payload, headers=headers)
return response.status_code == 200
# 配置示例
configure_synonyms("产品类型", ["大类", "产品分类", "商品类别"], "your_api_key")3. 概念定义与自动学习
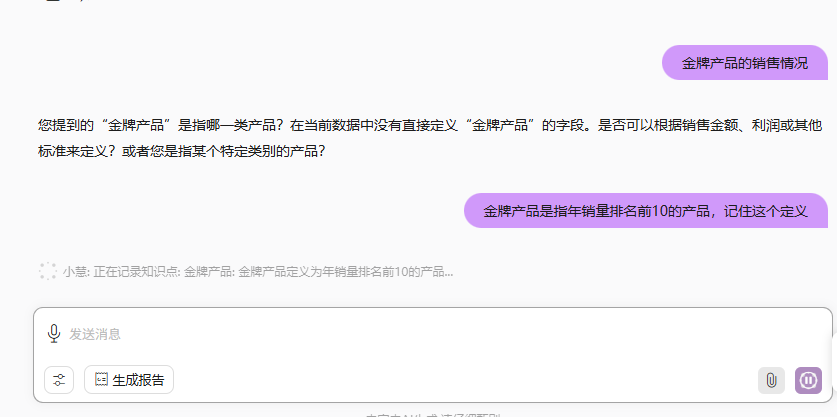
系统支持在对话过程中动态定义新概念:
javascript
// 概念定义API调用示例
const defineConcept = async (conceptName, definition) => {
const response = await fetch('https://api.datafocus.com/knowledge/concepts', {
method: 'POST',
headers: {
'Authorization': `Bearer ${apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
concept_name: conceptName,
definition: definition,
learning_mode: 'conversation'
})
});
return response.json();
};
// 定义"金牌产品"概念
defineConcept('金牌产品', '年销量排名前10的产品');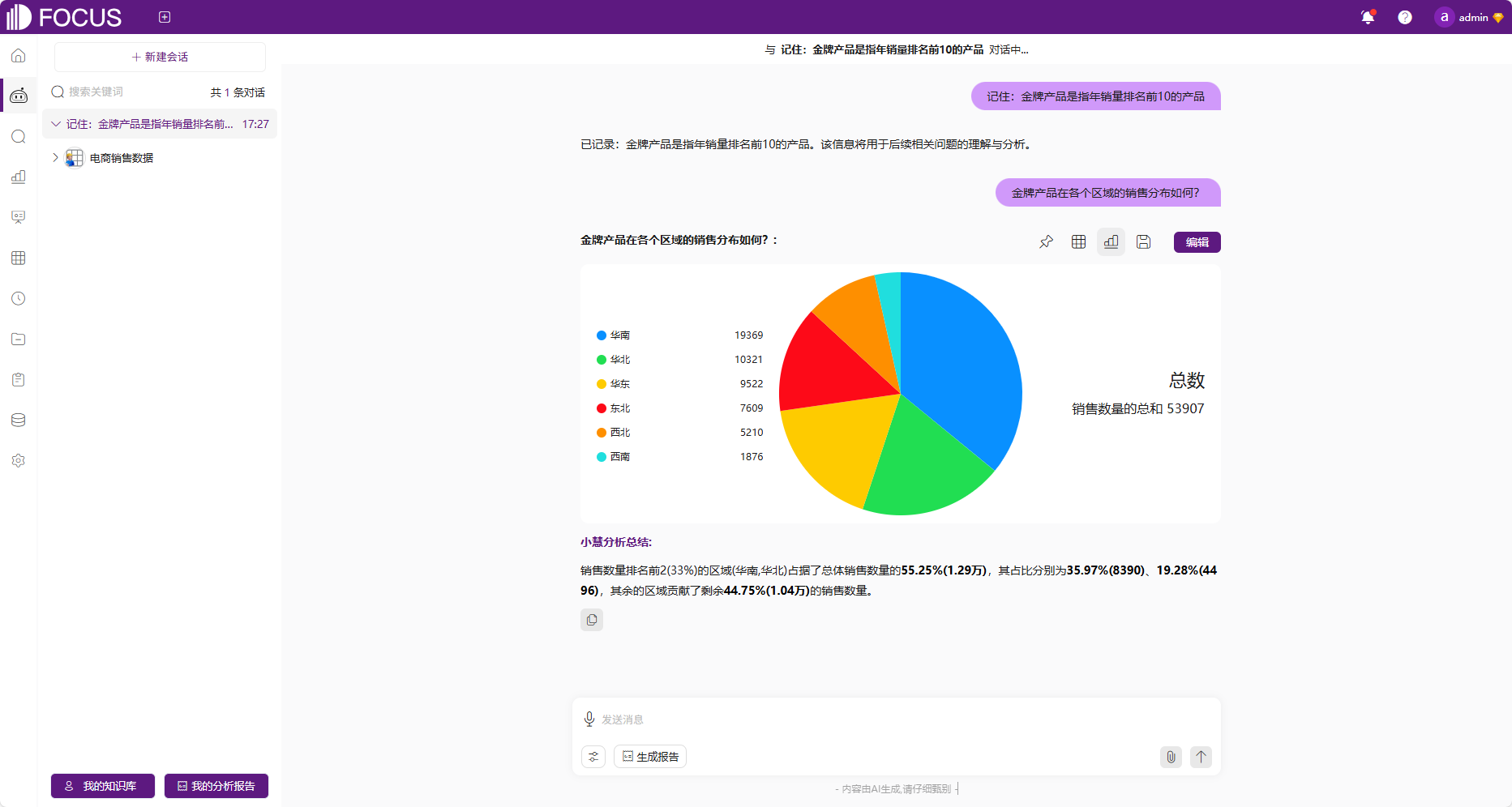
4. 反馈调优机制
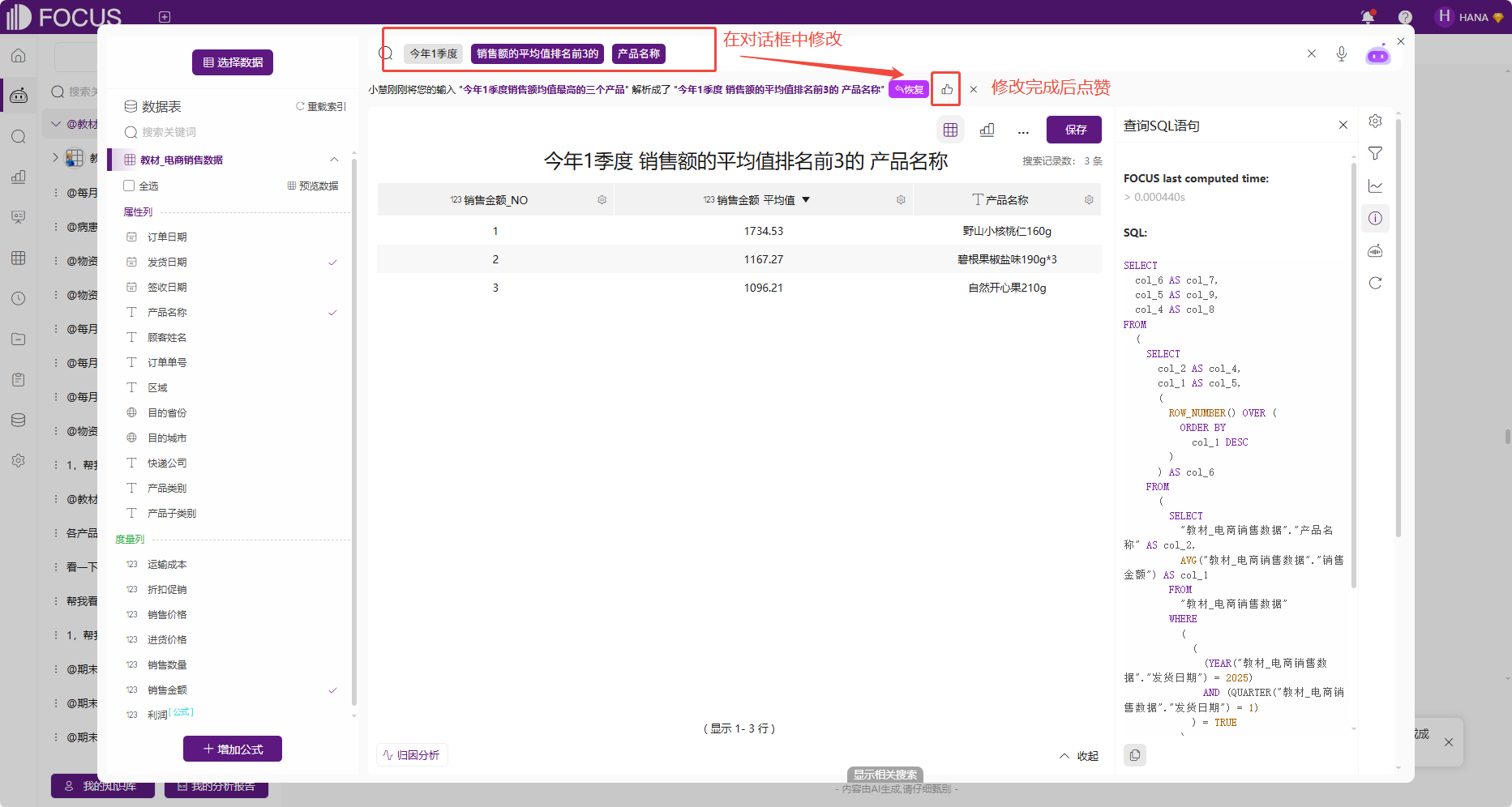
python
def provide_feedback(query_id, correction, api_key):
"""提供查询结果反馈,优化系统理解"""
url = f"https://api.datafocus.com/feedback/{query_id}"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"correction_type": "keyword_correction",
"correction_data": correction,
"confidence": 0.9
}
response = requests.put(url, json=payload, headers=headers)
return response.json()第三步:高级功能集成
智能异常检测
DataFocus内置多种统计分析算法,可通过API调用:
python
def detect_anomalies(metric_name, time_range, api_key):
"""执行智能异常检测"""
url = "https://api.datafocus.com/analytics/anomalies"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"metric": metric_name,
"time_range": time_range,
"algorithms": ["z_score", "pettitt"],
"sensitivity": "medium"
}
response = requests.post(url, json=payload, headers=headers)
return response.json()
# 检测销售数据异常
anomalies = detect_anomalies("daily_sales", "last_30_days", "your_api_key")贡献度归因分析
sql
-- DataFocus自动生成的归因分析SQL示例
-- 用户查询:"为什么11月销售额这么高"
WITH monthly_data AS (
SELECT
DATE_TRUNC('month', order_date) AS month,
SUM(amount) AS sales,
LAG(SUM(amount)) OVER (ORDER BY DATE_TRUNC('month', order_date)) AS prev_month_sales
FROM orders
WHERE DATE_TRUNC('month', order_date) = '2023-11-01'
GROUP BY 1
),
dimension_contributions AS (
SELECT
region,
product_category,
SUM(amount) AS contribution,
RANK() OVER (PARTITION BY region ORDER BY SUM(amount) DESC) AS rank
FROM orders
WHERE DATE_TRUNC('month', order_date) = '2023-11-01'
GROUP BY 1, 2
)
SELECT * FROM dimension_contributions
WHERE rank <= 3
ORDER BY region, contribution DESC;开发实践建议
1. API集成最佳实践
python
class DataFocusClient:
"""DataFocus API客户端封装"""
def __init__(self, api_key, base_url="https://api.datafocus.com"):
self.api_key = api_key
self.base_url = base_url
self.session = requests.Session()
self.session.headers.update({
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
})
def query(self, natural_language):
"""执行自然语言查询"""
endpoint = f"{self.base_url}/query"
response = self.session.post(endpoint, json={"query": natural_language})
return self._parse_response(response)
def _parse_response(self, response):
"""解析API响应"""
if response.status_code == 200:
data = response.json()
return {
"status": "success",
"data": data.get("data"),
"chart": data.get("chart_config"),
"sql": data.get("generated_sql")
}
else:
return {
"status": "error",
"code": response.status_code,
"message": response.text
}2. 性能优化策略
- 缓存策略:对频繁查询结果实施缓存
- 批量查询:支持批量自然语言查询
- 异步处理:对复杂分析任务采用异步模式
- 预热知识库:提前配置常用业务术语
3. 安全与权限管理
json
{
"role": "data_analyst",
"permissions": [
"query:read",
"knowledge:write",
"feedback:submit",
"analytics:advanced"
],
"data_scope": ["sales_db.*", "marketing_db.campaigns"],
"rate_limit": "1000/hour"
}技术总结
核心价值
- 降低数据分析门槛:自然语言查询取代SQL编写
- 知识资产沉淀:业务术语和分析经验可配置化存储
- 持续学习优化:通过反馈机制不断改进查询理解能力
- 开发效率提升:标准化API集成,减少重复开发
适用场景
- 企业内部数据自助查询平台开发
- BI系统自然语言接口集成
- 业务人员数据能力建设
- 数据分析工作流自动化
技术局限
- 复杂统计模型仍需专业分析师介入
- 实时数据流处理能力有限
- 非结构化数据分析支持有待加强
扩展阅读
- NLP在BI系统中的应用架构
- 知识图谱与业务术语管理
- 自然语言查询的SQL生成算法
- 商业智能系统的API设计模式
通过DataFocus的技术方案,开发者可以快速构建智能数据分析应用,将自然语言处理能力融入现有业务系统,显著提升数据驱动决策的效率。