最近和朋友聊到一个问题:为什么现在的大语言模型在解读基因组数据时,效果总差那么一点意思?
不是模型能力不够,也不是训练数据不足,问题可能出在数据格式本身。
比如我们用了十几年的VCF格式,设计初衷是让生物信息分析师能看懂、能处理。每一行记录的是与参考基因组的差异,配合大量的元数据和外部注释文件,人类专家可以逐步推导变异的功能意义。
但人工智能不太适合这种复杂的推导过程,逻辑太复杂会造成token消耗大,且幻觉严重。
当模型读取VCF文件时,它面对的是大量坐标、碱基符号和缩写标签。模型需要先理解格式规范,再关联外部数据库,最后才能提取出有临床/育种意义的信息。这个过程消耗大量计算资源,还容易因为上下文缺失产生错误判断。
更关键的是,VCF 是静态的。生物学知识每天在更新,新的致病位点不断被发现,但已经生成的VCF文件不会自动同步这些进展。每次分析都要重新注释,效率低且容易遗漏。
生信分析的范式需要调整。
过去我们设计数据格式,考虑的是人类专家怎么读、怎么分析、怎么写报告。现在应该换个思路:如果数据的主要消费者是AI,格式应该怎么设计?
一些团队已经开始尝试。
他们提出的新格式不再记录原始坐标差异,而是直接输出结构化语义信息。比如某个基因变异,不再只写chr19:44908684 T>C,而是直接标注该变异对应的基因名称、功能影响、临床/育种意义、用药/配组建议。
这种格式下,人工智能拿到数据就能直接进入决策环节,不需要额外消耗算力去解析格式、查询注释、拼凑上下文。
实际效果很明显。
数据体积从几百GB 压缩到几MB ,模型处理的token消耗降低数倍,解读准确率提升显著。更重要的是,医学/育种规则被直接嵌入数据结构,版本更新可以自动同步,分析流程的可复现性也得到保障。
这套思路已经有落地实践。
The Genome Computer Company 最近发布了.genome文件格式,专为人工智能读取设计。该格式将变异数据、功能解读、判断规则三者分离,全部显式标注、类型定义、版本管理。相比传统VCF ,.genome文件使模型处理时的token用量减少3到10倍,事实性错误降低10到20倍。
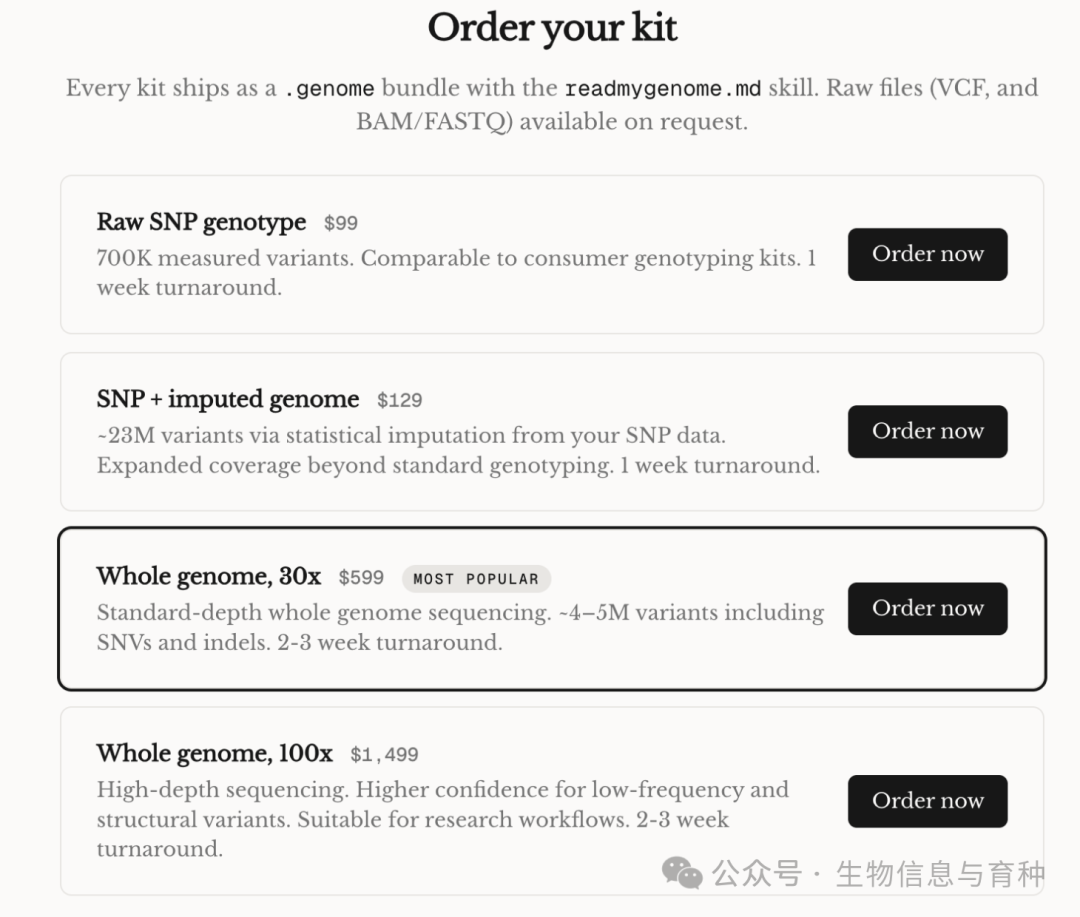
他们同时提供了转换工具,可将现有VCF 文件一键转为.genome格式,无需重写分析流程。用户保留原始数据主权,新生成的格式作为增强层叠加使用。配套的读取模块已开源,任何模型或应用都能快速接入。
这对行业意味着什么?
-
- 数据生产环节需要前置考虑下游的AI消费场景。测序仪输出的不只是原始数据,还应该包含语义化标注(关键这种标注仍然需要大量实验证明!),让数据从产生那一刻起就具备AI可读性 。
-
- 分析流程需要重构。传统的多步骤注释、过滤、解读流程,可以简化为端到端的语义推理,减少中间环节的信息损失。
-
- 数据交付形式需要改变。基因检测报告不应只是给人看的文档,更应该是AI可解析的结构化数据,方便集成到健康管理、临床/育种决策等智能系统中。
我们正在进入一个数据驱动智能决策的阶段。
AI不是替代生物信息分析师,而是要求我们重新思考数据的设计逻辑。当数据格式从人类友好转向AI友好,生信分析的效率、准确性和应用场景都会发生质的变化。
这个转变不会一蹴而就,但似乎方向已经清晰。
与其等待工具适应旧格式,不如主动设计适配新范式的数据标准。毕竟,未来调用你数据的可能不是坐在电脑前的分析师,而是持续运行的智能系统。
数据格式的小调整,可能带来行业效率的大提升。
这件事值得每个从业者认真考虑。
[