目录
[CIFAR-10 数据集介绍](#CIFAR-10 数据集介绍)
[代码实现 1](#代码实现 1)
[1.1 导包](#1.1 导包)
[1.2 获取并组织数据集](#1.2 获取并组织数据集)
[1.3 整理训练集、验证集和测试集](#1.3 整理训练集、验证集和测试集)
[1.4 图像增广](#1.4 图像增广)
[1.5 构建模型](#1.5 构建模型)
[1.6 训练函数](#1.6 训练函数)
[1.7 训练](#1.7 训练)
[代码实现 2](#代码实现 2)
[2.1 图像数据类定义](#2.1 图像数据类定义)
[2.2 图像增广](#2.2 图像增广)
[2.3 划分验证集和训练集](#2.3 划分验证集和训练集)
[2.4 模型定义](#2.4 模型定义)
[2.5 训练函数](#2.5 训练函数)
[2.6 训练](#2.6 训练)
前言
之前的学习中,我们一直使用深度学习框架的高级API直接获取张量格式的图像数据集,但是实践当中,图像数据集通常以图像文件的形式出现,因此这一节内容从原始图像文件开始,然后逐步组织,读取它们并转为张量格式。
(为了提升自己的代码理解,笔者分别根据李沐老师课程和自己的理解完成两套代码实现,欢迎指正与建议~~~)
CIFAR-10 数据集介绍
CIFAR-10 是一个成熟的计算机视觉数据集,用于目标识别。它是包含 8000 万张微型图像的数据集的一个子集,由 60000 张 32x32 像素的彩色图像组成,每张图像包含 10 个目标类别(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车)中的 6000 张,共 10 个类别。该数据集由 Alex Krizhevsky、Vinod Nair 和 Geoffrey Hinton 收集。
比赛数据集划分为训练集和测试集,其中训练集50000张、测试集300000张。在测试集中,10000张图像将被用于评估,多出来的290000张图象是为了防止手动标记并提交结果。两个数据集中的图像都是png格式,尺寸为32×32且颜色通道数为3(RGB)。

原始图像数量较多,为了方便学习,d2l 提供了小型的数据集:
下载网址:http://d2l-data.s3-accelerate.amazonaws.com/kaggle_cifar10_tiny.zip
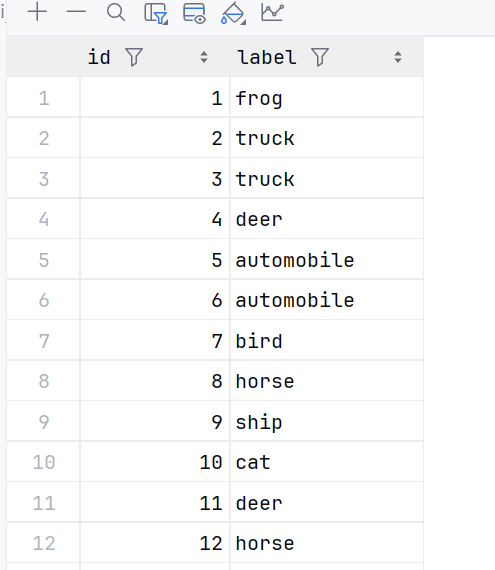
下载之后解压,我们简单看一下数据集:train和test分别包含1000、5张图象
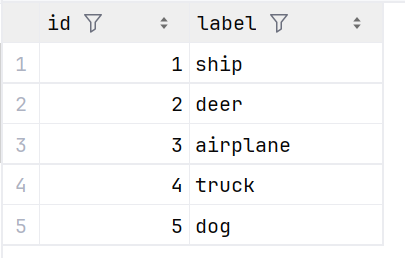
另外包含一个标签数据:trainLabels.csv:第1列为图像的文件名,第2列为相应的标签
代码实现 1
1.1 导包
python
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l1.2 获取并组织数据集
(1)获取数据集
python
d2l.DATA_HUB['cifar10_tiny'] = (d2l.DATA_URL + 'kaggle_cifar10_tiny.zip','2068874e4b9a9f0fb07ebe0ad2b29754449ccacd')
# 缩减规模:使用包含前1000个训练图像和随机测试图像的测试图像的数据集的小规模样本
demo = True
if demo:
data_dir = d2l.download_extract('cifar10_tiny')
else:
data_dir = './data/kaggle_cifar10_tiny'(2)整理数据集
l.rstrip()
- 含义:这是字符串的方法,意思是"去除右侧空白字符"。
- 作用 :文件里的每一行末尾通常都有一个看不见的换行符
\n。如果不删掉它,分割后的最后一个字段就会带着这个换行符(例如'truck\n'),这会影响后续处理。rstrip()能把它清理干净。
python
def read_csv_labels(fname):
with open(fname, 'r') as f:
# 跳过文件第一行(列名)
lines = f.readlines()[1:]
tokens = [l.rstrip().split(',') for l in lines] # 转化为结构化数据
return dict( ((name, label) for name, label in tokens) )
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
labels这样一来,我们就成功读取了.csv文件获得train数据集中每个图像的所属类别。

1.3 整理训练集、验证集和测试集
课程中为了让我们从0 理解原理,将此过程用较为底层的、原始的方式划分数据集:
python
def copyfile(filename, target_dir):
"""将文件复制到目标目录"""
os.makedirs(target_dir, exist_ok=True)
shutil.copy(filename, target_dir)
def reorg_train_valid(data_dir, labels, valid_ratio):
"""将验证集从原始的训练集中拆分出来"""
# 训练数据集中样本最少的类别中的样本数
n = collections.Counter(labels.values()).most_common()[-1][1]
# 验证集中每个类别的样本数
n_valid_per_label = max(1, math.floor(n * valid_ratio))
label_count = {}
for train_file in os.listdir(os.path.join(data_dir, 'train')):
label = labels[train_file.split('.')[0]] # 标号:1,2,3,...
fname = os.path.join(data_dir, 'train', train_file) #文件名
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train_valid', label))
if label not in label_count or label_count[label] < n_valid_per_label:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'valid', label))
label_count[label] = label_count.get(label, 0) + 1
else:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train', label))
return n_valid_per_label**1)下面这行代码执行逻辑是:**labels.values()拿到标签这一列数据,collections.Counter(xxx)表示对标签数据进行计数,.most_common()表示按照数量从前往后排,-1表示拿到最后一个元素(也就是数量最少的元素组合),例如('狗',10)表示只有10个样本的标签是狗,1则拿到其数量10。
python
n = collections.Counter(labels.values()).most_common()[-1][1]2)代码逻辑理解:
①先获取训练集中样本最少的类别的样本数→②乘比例作为验证集中每个类别的样本数→
③ 逐行读取完整训练集的数据→获取该数据(图像文件)对应的标签、文路径→
④将文件存储到目的文件夹当中:此项目中通过文件操作的方式重新划分磁盘上的数据 ------ 将创建一个文件夹 train_valid_test 用于训练/验证/测试(train/valid/test),其中,在训练(使用train、valid)完成后,将得到的模型在整个训练集(train_valid)上做训练,得到最终模型在 test上做测试后提交结果。
将测试集的图像复制到 train_valid_test/test/unknown文件夹,unkown表示其类别未知:
python
def reorg_test(data_dir):
for test_file in os.listdir(os.path.join(data_dir, 'test')):
copyfile(os.path.join(data_dir, 'test', test_file),
os.path.join(data_dir, 'train_valid_test', 'test','unknown'))定义读取cifar_10数据的函数:获取标签,从训练集中划分训练集和验证集,整理测试集。
设置了验证集比例为0.1,批量大小为32。(因为数据集的规模较小,如果使用原始数据集,可以设置到128/256合适)
python
def reorg_cifar10_data(data_dir, valid_ration):
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
reorg_train_valid(data_dir, labels, valid_ration)
reorg_test(data_dir)
valid_ratio = 0.1
batch_size = 32
reorg_cifar10_data(data_dir, valid_ratio)1.4 图像增广
**(1)增广处理:**注意一定要包含 .ToTensor()将其转为可处理的张量。
python
transform_train = torchvision.transforms.Compose([
#原始图像方法:32*32→40*40
#裁剪出来0.64~1.0大小的区域,再缩小到32*32
torchvision.transforms.Resize(40),
torchvision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])(2)做图像增广读取数据集:
torchvision.datasets.ImageFolder :
它是 PyTorch 中用于加载图像分类数据集的一个极其常用的工具类。
它的核心作用是:自动读取指定目录下的图片,并根据文件夹结构自动生成标签,从而让你无需编写繁琐的文件遍历和标签匹配代码。
1) 核心功能与原理
ImageFolder假设你的数据集是按照特定的文件夹结构组织的。它通过扫描根目录下的子文件夹来确定类别,子文件夹的名称即为类别名称。为了让ImageFolder正常工作,你的数据文件夹必须长这样:
pythonroot_dir/ ├── class_1/ <-- 类别1 (例如: cat) │ ├── img1.png │ ├── img2.jpg │ └── ... ├── class_2/ <-- 类别2 (例如: dog) │ ├── img1.png │ └── ... └── class_3/ <-- 类别3 (例如: bird) └── ...root_dir:表示传给函数的根路径; class_xxx:每个子文件夹代表一个类别;
images:文件夹内所有图片都属于该类别。
2) 常用参数详解
| 参数名 | 说明 | 典型用法 |
|root| (必填) 数据集的根目录路径。 |'./data/flower_photos'|
|transform| (常用) 对读取的图片进行预处理操作(如裁剪、归一化等)。 |transforms.ToTensor()|
|target_transform| (可选) 对标签进行转换的函数。 | 通常默认即可 |
loader(可选) 加载图片的函数,默认使用 PIL。 一般不需要修改 3)关键属性与方法
当你创建了
dataset = ImageFolder(...)对象后,可以通过以下方式访问数据:
dataset.classes: 返回一个列表,包含所有的类别名称(按字母顺序排序)。
- 例如 :
['cat', 'dog']dataset.class_to_idx: 返回一个字典,显示类别名称到索引的映射。
- 例如 :
{'cat': 0, 'dog': 1}dataset.imgs: 返回一个包含(图片路径, 类别索引)元组的列表。dataset[index]: 获取索引为index的数据,返回(image_tensor, label)。
python
train_ds, train_valid_ds = [
torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'train_valid_test', folder), transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [
torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'train_valid_test', folder), transform=transform_test) for folder in ['valid', 'test']
](3)创建数据迭代器
- 训练集 :为了"学得好",需要随机打乱 (
shuffle=True),并且为了计算稳定通常丢弃最后一点零头 (drop_last=True)。 - 验证/测试集 :为了"测得准",必须按顺序来 (
shuffle=False),且为了不漏掉任何数据通常保留零头 (drop_last=False)。
python
train_iter, train_valid_iter = [
torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True) for dataset in (train_ds, train_valid_ds)
]
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size=batch_size, shuffle=False, drop_last=True)
test_iter = torch.utils.data.DataLoader(test_ds, batch_size,shuffle=False,drop_last=False)具体来说:
(A) drop_last
**定义:**当总样本不能被batch_size整除时,会剩下一个不足一个批次大小的"残缺批次",drop_last=True:丢弃这个残缺的批次;drop_last=False:保留这个残缺的批次。
- 为什么训练集通常设置为True?
- 模型稳定性:很多模型结构在训练时需要计算当前批次的均值和方差,若最后一个批次太小(比如1-2个样本),计算出的的统计量会非常不稳定,甚至导致报错或梯度爆炸;
- 多卡训练:若使用多张GPU并行训练,数据会被切分,若批次不完整,很难均匀分配给每张卡,容易导致程序崩溃。
- 为什么测试集通常设为False?
- 评估准确性:测试姐u但的目标是评估模型的真实能力,每张图片都是宝贵的测试样本,若丢弃最后的那个批次,意味着你忽略了部分测试数据,这会导致评估结果不准确。
(B) shuffle
**定义:**是否在每个Epoch(轮次)开始时打乱数据的顺序。
shuffle=True:打乱顺序,shuffle=False:保持原有顺序。
为什么训练集设为True?
- 打破数据相关性:如果你的数据是按类别排序的(前1000张全是'cat',后1000张全是'dog')若不打乱,模型可能会先学会识别猫,然后突然遇到狗导致权重剧烈震荡,或者陷入局部最优解;
- 防止过拟合:随机性可以帮助模型更好地泛化,避免它"死记硬背"数据的排列顺序。
为什么验证/测试集设为False?
- 结果一致性:在验证和测试阶段,我们希望每次运行代码得到评估结果一样,若每次都打乱,虽然最终计算的平均指标差不多,但中间过程的Loss曲线会波动,不利于调试和对比。
- 符合实际场景:测试集通常代表真实世界的输入流,我们不需要对它进行人为的随机化处理。
1.5 构建模型
这里使用resnet18架构:
python
def get_net():
num_classses = 10
net = d2l.resnet18(num_classses, 3) # 输入为3通道
return net
loss = nn.CrossEntropyLoss(reduction='none') #不要sumreduction参数的三种模式:
'mean'(默认):计算所有样本损失的平均值,训练时最常用,因为梯度稳定,输出一个标量值;
'sum':计算所有样本损失的总和,输出一个标量值;
'none':返回每个样本独立的损失值,形状为(batch_size,),输出一个向量
1.6 训练函数
- 优化器(SGD):选择随机梯度下降算法,此处的weight_decay是L2正则化,用来防止模型过拟合,让权重不要太大;
- 学习率调度器(StepLR):"自动调参",每个lr_period个epoch,将学习率乘以lr_decay,让模型后期学的更细致和更加稳定;
python
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay):
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, step_size=lr_period, gamma=lr_decay)
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss', 'train acc']
if valid_iter:
legend.append('valid acc')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=legend)
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
# 可视化
for epoch in range(num_epochs):
net.train()
metric = d2l.Accumulator(3)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(net, features, labels,
loss, trainer, devices)
metric.add(l, acc, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[2],
None))
if valid_iter is not None:
valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)
animator.add(epoch + 1, (None, None, valid_acc))
scheduler.step()
measures = (f'train loss {metric[0] / metric[2]:.3f}, '
f'train acc {metric[1] / metric[2]:.3f}')
if valid_iter is not None:
measures += f', valid acc {valid_acc:.3f}'
print(measures + f'\n{metric[2] * num_epochs / timer.sum():.1f}'
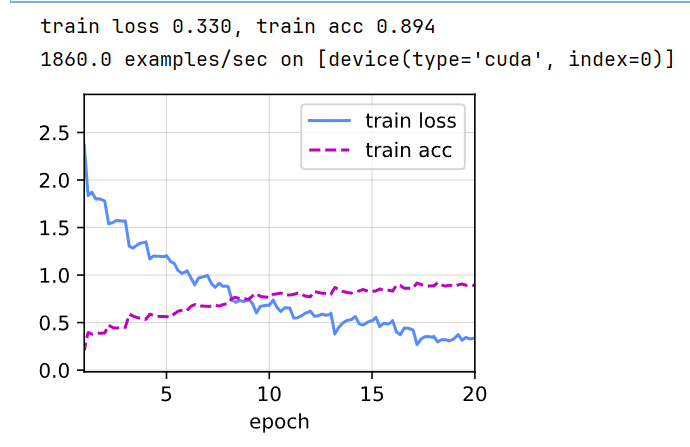
f' examples/sec on {str(devices)}')1.7 训练
在训练集/验证集上训练/预测:
python
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 2e-4, 5e-4
lr_period, lr_decay, net = 4, 0.9, get_net()
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,lr_decay)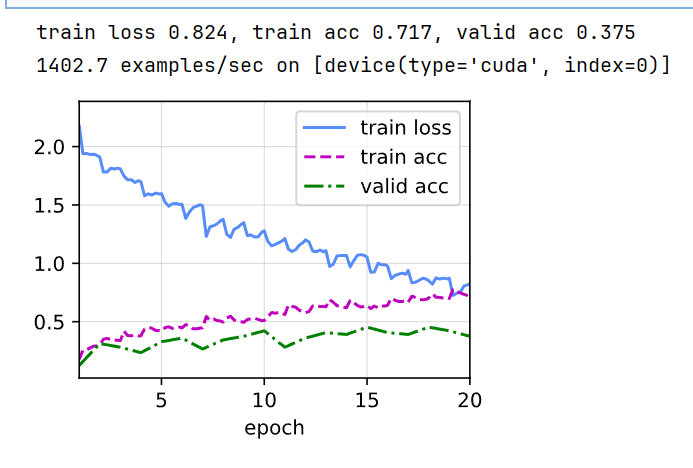
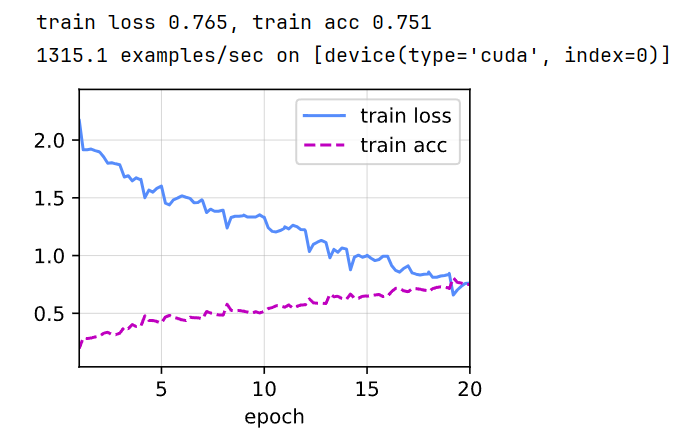
在整体训练集/测试集上训练/预测:
python
# 完整训练集上训练
net, preds = get_net(), []
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period,lr_decay)
# 测试集上预测
for X, _ in test_iter:
y_hat = net(X.to(devices[0]))
preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
# 保存预测结果
sorted_ids = list(range(1, len(test_ds) + 1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: train_valid_ds.classes[x])
df.to_csv('submission.csv', index=False)//可以看到在完整训练集上的精度提升了。
代码实现 2
2.1 图像数据类定义
类似于上一篇博客的处理方式,笔者直接操作文件夹内容而不是对其做磁盘上的划分:
自定义一个图像数据集类:在get_item时对图像做 transorm的处理。
python
import os
from torch.utils.data import Dataset
from PIL import Image
# 数据定义
class MyImgDataset(Dataset):
def __init__(self, df, data_dir, transform=None):
self.df = df
self.data_dir = data_dir
self.transform = transform
# 自动提取类别并映射为数值
self.classes = sorted(df.iloc[:, 1].unique())
self.class_to_idx = {cls_name:i for i,cls_name in enumerate(self.classes)}
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
# 1.读取图像
img_name = self.df.iloc[idx][0]
img_path = os.path.join(self.data_dir, f'{img_name}.png')
img = Image.open(img_path).convert('RGB')
# 2.获取标签所以
label = self.class_to_idx[self.df.iloc[idx][1]]
# 3.应用Transform
if self.transform:
img = self.transform(img)
return img, label2.2 图像增广
python
from torchvision import transforms
def get_transforms():
"""定义并返回训练和验证的 Transform"""
# 训练增强:Resize -> RandomCrop -> Flip -> ToTensor -> Normalize
transform_train = transforms.Compose([
transforms.Resize(40),
transforms.RandomResizedCrop(32, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])
])
# 验证增强:ToTensor -> Normalize
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])
])
return transform_train, transform_test
transform_train, transform_test = get_transforms()2.3 划分验证集和训练集
使用了 sklearn.model.selection 的 train_test_aplit函数,将 test_size表示验证集划分比例,这里设置为了0.2;在创建完整数据集的数据类之后,传入get_train_calid_iter通过DataLoader进行划分:
python
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader
import pandas as pd
# 训练集、验证集、整体迭代器创建
def get_train_valid_iter(full_df,ds, transform_train, transform_test,test_ratio=0.2, batch_size=32, num_workers=0):
train_df, val_df = train_test_split(full_df, test_size=test_ratio, random_state=42, stratify=df.iloc[:, 1])
# 划分
train_ds = MyImgDataset(train_df, train_valid_img_dir, transform_train)
valid_ds = MyImgDataset(val_df, train_valid_img_dir, transform_test)
# 迭代器
train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True, num_workers=num_workers)
valid_loader = DataLoader(valid_ds,batch_size=batch_size, shuffle=False, num_workers=num_workers)
train_valid_loader = DataLoader(ds, batch_size=batch_size, shuffle=True, num_workers=num_workers)
return train_loader, valid_loader, train_valid_loader
data_dir = './data/kaggle_cifar10_tiny'
train_valid_img_dir = data_dir + '/train'
# 读取训练集数据
df = pd.read_csv(data_dir + '/trainLabels.csv')
ds = MyImgDataset(df, train_valid_img_dir, transform=transform_train)
train_loader, valid_loader, train_valid_loader = get_train_valid_iter(df, ds, transform_train, transform_test, test_ratio=0.2, batch_size=32, num_workers=0)2.4 模型定义
这里使用models提供的 resnet18架构,并使用预训练权重,且在最后的全连接层增加了 Droptout 层,用于防止过拟合。
python
import torch
import torch.nn as nn
from torchvision import models
def get_net(num_classes=10, pretrained=True):
"""
获取 ResNet18 模型
Args:
num_classes: 分类数量
pretrained: 是否使用预训练权重 (对于小数据集非常有用)
"""
net = models.resnet18(pretrained=pretrained)
# 修改最后的全连接层
# 增加 Dropout 防止过拟合 (针对 Tiny 数据集)
net.fc = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
return net2.5 训练函数
和前面 1.6 一致。
python
import d2l.torch as d2l
def train(net, train_iter, valid_iter, loss, num_epochs, lr, wd, devices, lr_period, lr_decay):
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, step_size=lr_period, gamma=lr_decay)
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss', 'train acc']
if valid_iter:
legend.append('valid acc')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=legend)
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
net.train()
metric = d2l.Accumulator(3)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(net, features, labels,
loss, trainer, devices)
metric.add(l, acc, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[2],
None))
if valid_iter is not None:
valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)
animator.add(epoch + 1, (None, None, valid_acc))
scheduler.step()
measures = (f'train loss {metric[0] / metric[2]:.3f}, '
f'train acc {metric[1] / metric[2]:.3f}')
if valid_iter is not None:
measures += f', valid acc {valid_acc:.3f}'
print(measures + f'\n{metric[2] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')2.6 训练
python
num_classes = len(ds.classes)
python
# 损失函数设置
criterion = nn.CrossEntropyLoss(reduction='none')
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 2e-4, 5e-4
lr_period, lr_decay, net = 4, 0.9, get_net(num_classes)
train(net, train_loader, valid_loader, criterion, num_epochs, lr, wd, devices, lr_period,lr_decay)// 应该是添加了 Dropout 层的缘故, valid acc 相较于前面更高
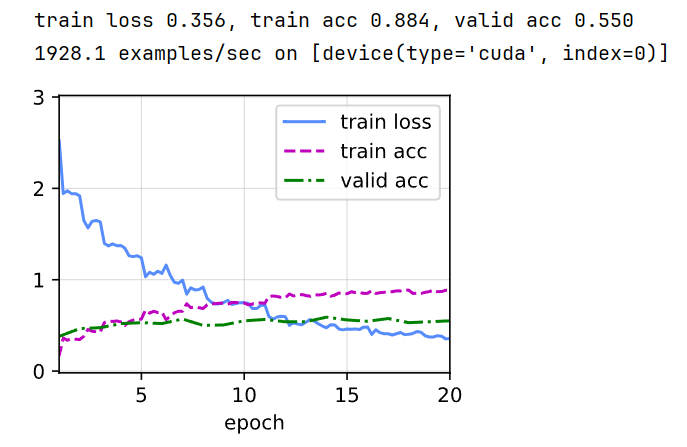
使用完整训练集训练,在 test 上验证:
python
import torchvision
# 网络
net, preds = get_net(), []
# 训练
train(net, train_valid_loader, None,criterion, num_epochs, lr, wd, devices, lr_period,lr_decay)
# 测试集数据组织
test_ds = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'test'), transform=transform_test)
test_loader = DataLoader(test_ds,batch_size=32,shuffle=False)
for X, _ in test_loader:
y_hat = net(X.to(devices[0]))
preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
sorted_ids = list(range(1, len(test_ds) + 1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: ds.classes[x])
df.to_csv('submission.csv', index=False)// 完整数据集上的训练效果好很多!