如果说 Goroutine 是 Go 并发的"工人",Channel 是"传送带",那 GMP 就是整个工厂的调度指挥中心。一、Go 语言中的 GMP 模型是什么?
1.1 三个字母的本质
GMP 是 Go Runtime 设计的三级调度抽象:
| 字母 | 全称 | 本质 | 生活比喻 |
|---|---|---|---|
| G | Goroutine | 用户任务,待执行的函数 | 工人(带着图纸和工具,等待派活) |
| M | Machine | OS 线程(内核线程),真正跑代码的执行引擎 | 机床/工位(有电、有马达,能干活) |
| P | Processor | 逻辑处理器,包含调度上下文和本地队列 | 车间主任(手里有本地任务清单、工具箱、材料柜) |
1.2 三者如何协作?(核心关系)
就是这个模型让Go能在少量线程上调度海量goroutine,是Go⾼并发的基础。
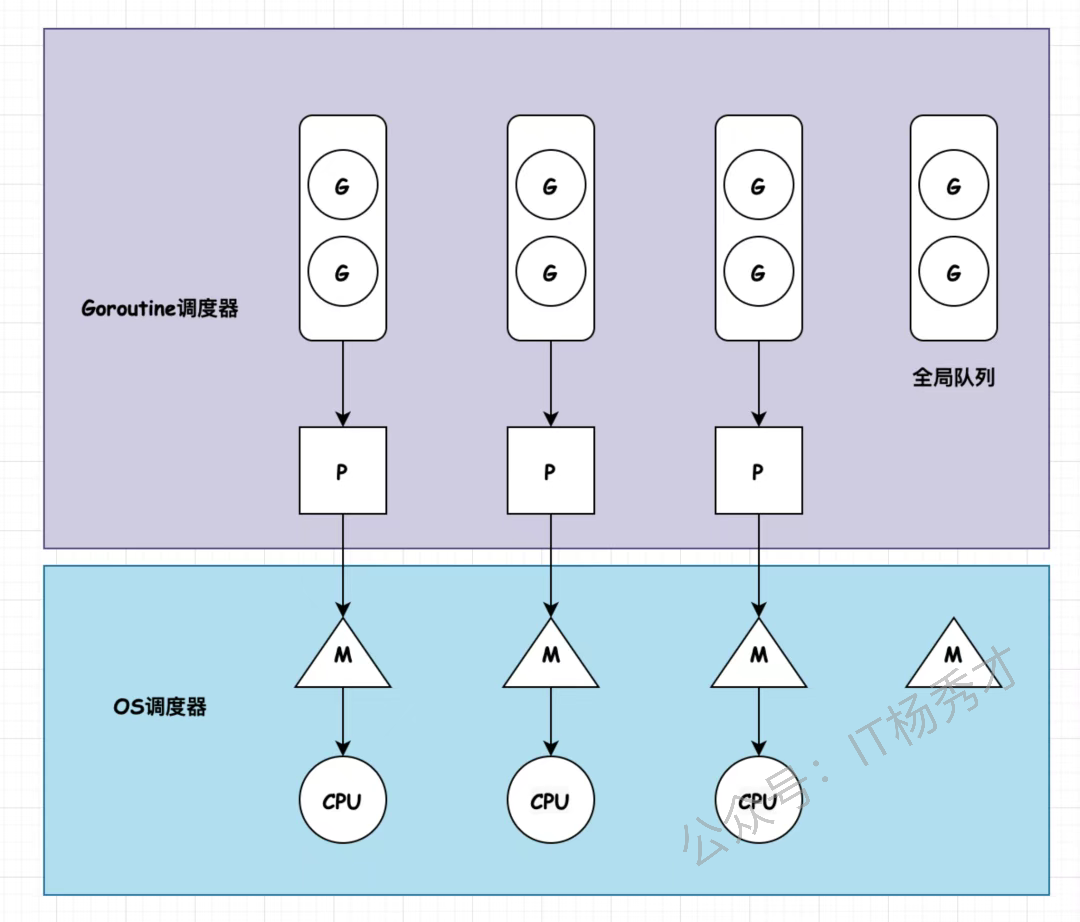
铁律:
-
G 想执行,必须先找到 P。没有 P 的 G 只能去全局队列排队。
-
P 想干活,必须先绑定 M。P 是逻辑概念,不能自己跑代码,必须寄生在 M 上。
-
M 可以没有 P(比如执行系统调用时),但此时它不能执行用户 G。
1.3 为什么需要三层?不是两层就行了吗?
P 是性能关键。
如果没有 P,直接让 G 和 M 绑定:
-
M1 绑定了 G1,G1 去 Channel 阻塞了 → M1 这个内核线程也跟着阻塞。
-
操作系统调度器会把 M1 切走,上下文切换开销巨大。
-
所有 G 竞争一个全局队列,锁争用惨烈。
有了 P 之后:
-
G1 阻塞在 Channel,只是 G1 被挂起 ,M 可以立刻切换到 g0(后面讲),然后绑定 P 去执行别的 G。
-
P 的本地队列让大部分调度无需加锁(无锁环形队列)。
二、什么是 Go Scheduler?
2.1 本质定义
Go Scheduler 是 Go Runtime 内部实现的一个用户态线程调度器(User-space Scheduler) ,运行在用户空间,与操作系统内核调度器(如 Linux CFS)是上下级关系。
它不是操作系统的某个组件,而是编译进你程序里的 runtime 包代码(主要在 runtime/proc.go、runtime/runtime2.go 中)。
2.2 它到底在管什么?
它只管理一件事:哪个 G(Goroutine)应该在哪个 M(OS 线程)上执行。
操作系统内核调度器管理的是进程/线程 (M),它根本不知道 G 的存在。Go Scheduler 夹在操作系统和你的业务代码之间,扮演**"中间商"**:
2.3 为什么需要它?直接用操作系统线程不行吗?
核心原因:OS 线程太重,Goroutine 太轻。
| 对比项 | OS 线程(Linux pthread) | Goroutine |
|---|---|---|
| 栈大小 | 默认 1~8 MB(固定或分页增长) | 默认 2 KB(可动态增长) |
| 上下文切换 | 1~2 微秒(进内核,保存/恢复大量寄存器,刷新 TLB) | ~200 纳秒(用户态,只改几个寄存器) |
| 创建销毁开销 | 大(需内核参与,分配大量资源) | 极小(用户态分配,约 ~2KB 内存) |
| 单机并发量 | 通常几千个就是极限 | 轻松几十万甚至上百万 |
如果没有 Go Scheduler,一个 Goroutine 绑定一个 OS 线程:
-
100 万个 Goroutine = 100 万个线程。
-
操作系统直接崩溃,内存不够,调度器本身也卡死。
Go Scheduler 通过 M:N 模型(少量 M 承载大量 G),把 Goroutine 的调度成本压到极低。
2.4 Scheduler 的核心入口函数
Go 程序里每个 M 都在执行一个永不退出的调度循环:
// runtime/proc.go 中的核心函数
func schedule() {
// 1. 找下一个可运行的 G
gp := findRunnable()
// 2. 执行它
execute(gp)
// 3. G 结束后,回到这里,继续循环
}这个 schedule() 函数就是 Go Scheduler 的心脏。你的程序里每个 M(除了极少数特殊情况)都在死循环地调用它。
三、Go 调度策略是什么?
3.1 大前提:M:N 调度 + 两级队列
Go 的调度器采用的是 M:N 模型:
-
M 个 OS 线程,调度 N 个 Goroutine(N >> M)。
-
调度队列分两级:P 的本地无锁队列 (Local Runq)+ 全局队列(Global Runq)。
3.2 抢占策略的演进
Go 的调度不是纯粹的协作式,也不是纯粹的操作系统抢占式 ,而是**"以协作为主,强制抢为辅"**的混合策略。=
① Go 1.14 之前:协作式抢占(Cooperative Preemption)
原理: 编译器在几乎所有函数调用的入口处(函数序言,Function Prologue),插入一段检查代码。这段代码会检查当前 G 是否被标记为需要让出 CPU。
源码层面的实现: 每个 G 结构体里有一个字段叫 stackguard0。当 sysmon 认为某个 G 运行太久了,就把它的 stackguard0 设置为一个特殊值 stackpreempt。
当 G 执行到下一个函数调用时,会检查栈空间:
// 伪代码,示意函数序言的检查逻辑
if sp < stackguard0 { // 正常是检查栈溢出
if stackguard0 == stackpreempt {
// 不是栈溢出,是被要求抢占了!
goschedImpl() // 主动让出 CPU
}
}致命缺陷: 如果某个 Goroutine 写了一个纯死循环,且循环体里没有任何函数调用:
for {}那么它永远不会走到函数序言的检查点 ,preempt 标志永远得不到检查。这个 G 会永久霸占所在的 M,同一个 P 本地队列里的其他 G 全部饿死。
② Go 1.14 之后:基于信号的异步抢占(Asynchronous Preemption)
Go 1.14 引入了新机制,解决了"无函数调用的死循环"问题。
完整流程:
Step 1:Sysmon 检测
-
sysmon是一个特殊的 M(由 Runtime 启动,不绑定 P),它死循环运行。 -
它定期检查每个 P 的
sysmontick记录。 -
如果发现某个 G 在同一个 M 上运行超过 10ms,判定为"需要抢占"。
Step 2:发送信号
-
sysmon向目标 M 发送一个 Unix 信号SIGURG(紧急信号,用户程序通常不用)。 -
注意:不是直接操作 G,而是给 M 发信号。
Step 3:M 的信号处理
-
每个 M 内部都有一个专门的信号处理 Goroutine,叫做
gsignal。 -
M 收到
SIGURG后,由gsignal接手处理(在信号上下文执行)。 -
gsignal会设置目标 G 的抢占标志,并记录"异步抢占请求"。
Step 4:安全点抢占
-
信号处理程序不会直接打断正在运行的 G(那样太危险,可能正在修改共享状态)。
-
它会在 G 到达下一个**安全点(Safe Point)**时触发抢占。安全点包括:
-
函数调用入口
-
循环的 backedge(循环边界)
-
某些特定的指令序列
-
-
在安全点,Runtime 检查抢占标志,然后执行和之前类似的
goschedImpl(),把 G 放回队列。
关键结论:
-
1.14 之前:只有函数调用时才能被抢占。
-
1.14 之后:即使无函数调用,信号机制也能强制你在安全点停下。但注意,它仍然不是"随时打断",而是"在安全点检查并打断"。
四、发生调度的时机有哪些?
调度不是随时发生的,而是在特定时机 触发。分为主动、被动、抢占三类:
4.1 主动调度(Goroutine 自己让出)
| 场景 | 函数 | 说明 |
|---|---|---|
| 显式让出 | runtime.Gosched() |
G 主动说"我先歇会儿" |
| park | gopark() |
Channel 阻塞、sleep、wait 等,G 挂起 |
| 结束 | G 的函数 return |
G 执行完了,M 必须找新 G |
4.2 被动调度(Goroutine 被迫让出)
| 场景 | 说明 |
|---|---|
| 系统调用 | G 调用 read/write 等,M 进入内核态,G 和 M 解绑,P 找新 M |
| Channel 阻塞 | 无缓冲 Channel 没配对,G 挂到队列,M 切换 |
| 锁阻塞 | sync.Mutex 拿不到,G 进等待队列 |
| GC | 触发 GC 时,所有 G 必须暂停(STW),调度器介入 |
| 栈增长 | G 的栈不够用了,切换到 g0 分配新栈 |
4.3 抢占式调度(Go 1.14+ 的关键改进)
以前 Go 是协作式调度,如果 G 里写了个死循环且不调用任何函数,它会永远占着 CPU。
Go 1.14 引入了基于信号的抢占:
-
系统监控线程(Sysmon)每 10ms 检查一次。
-
发现某个 G 运行太久,就发信号(
SIGURG)给对应的 M。 -
M 收到信号后,在**函数调用序言(prologue)**处检查抢占标志,主动让出。
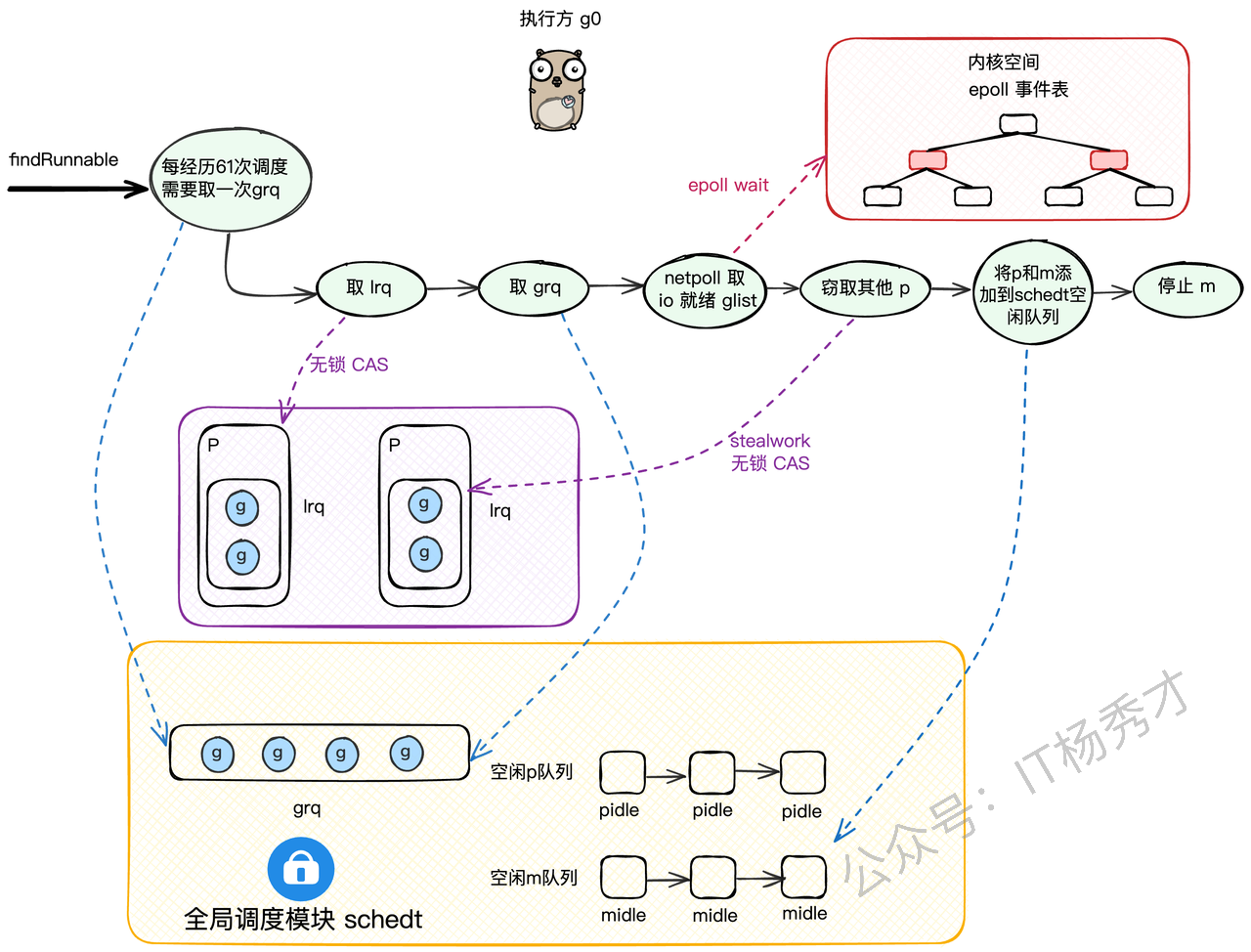
五、M 寻找可运行 G 的过程是怎样的?
这是 Go Scheduler 最核心的算法,我必须严格按照 runtime/proc.go 中 findrunnable() 的源码逻辑,给你分步骤拆解。
总览
当 M 上的当前 G 执行完毕(或阻塞)后,M 会调用 schedule(),进而调用 findrunnable() 来找下一个活干。
Step 1:检查 P 的 runnext(最快路径)
if gp := pp.runnext; gp != nil {
pp.runnext = nil
return gp
}每个 P 有一个单缓冲槽位 叫 runnext。如果某个 G 被标记为"下一个优先执行"(比如刚被唤醒的高优先级 G),直接拿走。无锁,最快。
Step 2:从 P 的本地队列取(runqget)
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}P 的 runq 是一个无锁环形数组队列 (长度 256)。M 优先从这里取 G。这也是无锁操作,性能极高。
Step 3:从全局队列取(globrunqget)
if gp := globrunqget(_p_, max); gp != nil {
return gp
}本地队列空了。M 去全局队列 sched.runq 取一批 G。
-
取多少个?
n = min(len(globalRunq), max),通常一次取 1 个或一批(具体算法会取一半,但上限约 128 个)。 -
为什么取一批而不是一个?减少全局锁竞争。
-
这批 G 被放到 P 的本地队列,然后执行第一个。
Step 4:检查 Netpoller(网络轮询器)
if gp := netpoll(0); gp != nil {
return gp
}看看有没有因为网络 I/O 阻塞、但底层 fd 已经就绪的 G(比如 socket 收到数据了)。这是一个非阻塞调用。
Step 5:Work Stealing(工作窃取)
// 尝试 4 轮
for i := 0; i < 4; i++ {
// 随机选择其他 P
for _, p2 := range stealOrder {
if gp := runqsteal(_p_, p2); gp != nil {
return gp
}
}
}-
M 随机挑选其他 P,尝试从它们的本地队列尾部偷一半任务过来。
-
偷取是批量的:把 victim P 队列里后半部分的 G 一次性搬到当前 P 的队列。
-
尝试 4 轮还偷不到,放弃。
Step 6:再次检查全局队列和 Netpoller
偷了一圈回来,可能全局队列有新任务了,或者网络包到了。再检查一次。
Step 7:GC 后台任务
if gp := gcBgMarkWorker(); gp != nil {
return gp
}实在没用户任务了,M 可以帮 GC 做后台标记工作(并发 GC 的一部分)。
Step 8:真的没有了,M 进入休眠(stopm)
stopm()-
M 和 P 解绑(P 被放回全局
pidle空闲列表)。 -
M 自己被放入全局
midle空闲列表。 -
调用操作系统的线程休眠原语(如
futex/WaitForSingleObject),进入睡眠状态。 -
等待将来有任务时,被
startm()或wakep()叫醒。
六、GMP 能不能去掉 P 层?去掉会怎么样?
6.1 结论:绝对不能去掉
如果你把 P 层抽掉,只剩下 G 和 M 两层,Go 的 Runtime 会在调度性能 和内存分配性能上同时崩塌。P 层存在的意义,远不止"一个中间层"这么简单。
6.2 原因一:本地无锁队列(Local Runq)
这是 P 层最核心的功能。
有 P 时的场景:
-
每个 P 有一个
runq[256]的环形数组。 -
M 从 P 的本地队列取 G 时,不需要任何锁(无锁环形队列,通过原子操作实现)。
-
4 个 P 就有 4 个独立队列,4 个 M 可以同时取 G,互不干扰。
去掉 P 后的场景:
-
所有 G 只能挤在一个全局队列里。
-
任何 M 想取 G,都必须先抢一把全局大锁。
-
4 个 M 同时取 G → 4 个线程抢同一把锁 → 缓存一致性流量爆炸 → CPU 大量时间花在自旋等待上。
-
实测:高并发下,调度器本身会吃掉 30%~50% 的 CPU 时间。
6.3 原因二:mcache(内存分配无锁)
这是很多人忽略的一点。P 层不仅管调度,还管内存分配。
Go 的内存分配器采用 TCMalloc 模型,分为三级:
G ──► mcache(P 本地)──► mcentral(全局,按 span class 分)──► mheap(全局,向 OS 申请)mcache 是什么?
-
每个 P 自带一个
mcache,里面缓存了各种规格(size class)的内存块(span)。 -
当 G 申请小对象(
< 32KB)时,直接从 P 的mcache拿,不需要加锁。 -
只有当
mcache空了,才会去全局的mcentral补充(这时才需要锁)。
去掉 P 后的场景:
-
所有 G 申请内存都直接走全局
mcentral或mheap。 -
100 万个 G 同时抢内存分配锁 → 程序直接卡死。
-
有 P 时,99% 的内存分配是无锁的。
6.4 原因三:调度上下文缓存
P 保存了一个 G 运行所需的完整上下文环境:
-
mcache:内存分配缓存。 -
pctrace:性能分析采样状态。 -
defer pool:defer 结构体缓存池,减少重复分配。 -
sudog cache:Channel 操作时sudog对象的缓存池。 -
writebuf:GC 写屏障缓冲区。
这意味着: 当 G1 在 P 上阻塞后,P 可以立刻把 G1 的上下文冻结,然后执行 G2。G1 恢复时,P 上的缓存还在,无需重建。
去掉 P 后: 每次切换 G,都要重新初始化内存分配环境、重新分配 defer/sudog 缓存,开销巨大。
七、P 和 M 在什么时候会被创建?
7.1 P 的创建时机
P 是程序启动时一次性创建的。
func main() {
runtime.GOMAXPROCS(4) // 默认等于 CPU 核心数
}具体流程:
-
Go 程序启动,执行
runtime.rt0_go。 -
调用
schedinit(),其中读取环境变量$GOMAXPROCS或调用runtime.GOMAXPROCS(n)。 -
调用
procresize(n),创建 n 个 P。 -
这些 P 被放入全局
allp数组,同时大部分被放入 空闲池pidle。
P 的数量是固定的吗?
-
运行时可以动态调整(
runtime.GOMAXPROCS(newN)),但极少这么做。 -
调整时,多余的 P 会被剥离(上面的 G 转移到其他 P),然后放入
pidle;不足的 P 从pidle取出或新建。
pidle 是什么?
-
pidle是全局的 P 空闲链表(singly-linked list)。 -
当 M 进入休眠(
stopm)时,它绑定的 P 会被解绑 ,放入pidle。 -
当有新任务时,
wakep()或startm()从pidle取一个 P,绑定到 M 上。
7.2 M 的创建时机
M 是 OS 线程,创建成本较高,Go 会尽量复用。M 是动态创建的。
创建 M 的入口是 newm(),触发场景:
场景 1:程序启动时
创建第一个 M,即 m0(主线程)。
场景 2:有 G 要执行,但没有空闲 M
// 当需要执行 G 时,调用 startm()
func startm(_p_ *p, spinning bool) {
// 1. 先尝试从 midle(M 空闲列表)拿一个休眠的 M
mp := mget()
if mp == nil {
// 2. 没有空闲 M,新建一个!
newm(fn, _p_, spinning)
return
}
// ...绑定 P,唤醒 M
}场景 3:G 进入系统调用,当前 M 阻塞
当 G 执行 read() / write() 等系统调用时:
-
当前 M 进入内核态,可能长时间阻塞。
-
P 和 M 解绑(P 不能跟着 M 一起睡)。
-
P 需要找新的 M 来继续执行其他 G。
-
如果
midle里没有空闲 M,就调用newm()新建一个。
场景 4:GC 并行标记需要
GC 的并发标记阶段可能需要额外的 M 并行工作。
midle 是什么?
-
midle是全局的 M 空闲链表。 -
M 没活干时(
stopm),不会被操作系统销毁,而是放入midle睡觉。 -
下次需要 M 时,优先从
midle唤醒,避免频繁创建/销毁 OS 线程。
八、m0 是什么?有什么用?
8.1 m0 的定义
m0 是 Go 程序启动时,由操作系统创建的第一个 OS 线程(主线程)。 它是 Go Runtime 的"盘古",一切从这里开始。
8.2 m0 的特殊身世
普通 M 是 Go Runtime 自己调用操作系统 API(如 clone / CreateThread)创建的,但 m0 不是------它是操作系统启动你的程序时,就已经存在的那条线程。
操作系统加载可执行文件
│
▼
创建进程 + 主线程
│
▼
进入 _rt0_amd64_linux(或对应平台的入口)
│
▼
这条主线程,就是 m08.3 m0 的不可替代职责
| 阶段 | m0 做什么 |
|---|---|
| Runtime 初始化 | 执行 runtime.rt0_go,设置栈、初始化内存分配器、初始化调度器 |
| 创建 G0 和 main goroutine | 创建第一个 G(不是 g0,是执行 main.main 的那个 G) |
| 进入调度循环 | m0 也调用 mstart() → schedule(),和普通 M 一样干活 |
| 兜底 | 如果所有其他 M 都阻塞在系统调用里,至少 m0 还在运行,保证程序不死 |
8.4 m0 与普通 M 的区别
| 特性 | m0 | 普通 M |
|---|---|---|
| 创建者 | 操作系统 | Go Runtime (newm) |
| g0 栈 | 使用操作系统分配的初始栈 | 使用 Runtime 在堆上分配的栈 |
| 生命周期 | 与进程同生共死 | 可以休眠复用,理论上可销毁(实际很少) |
| 数量 | 全局只有 1 个 | 可以有多个 |
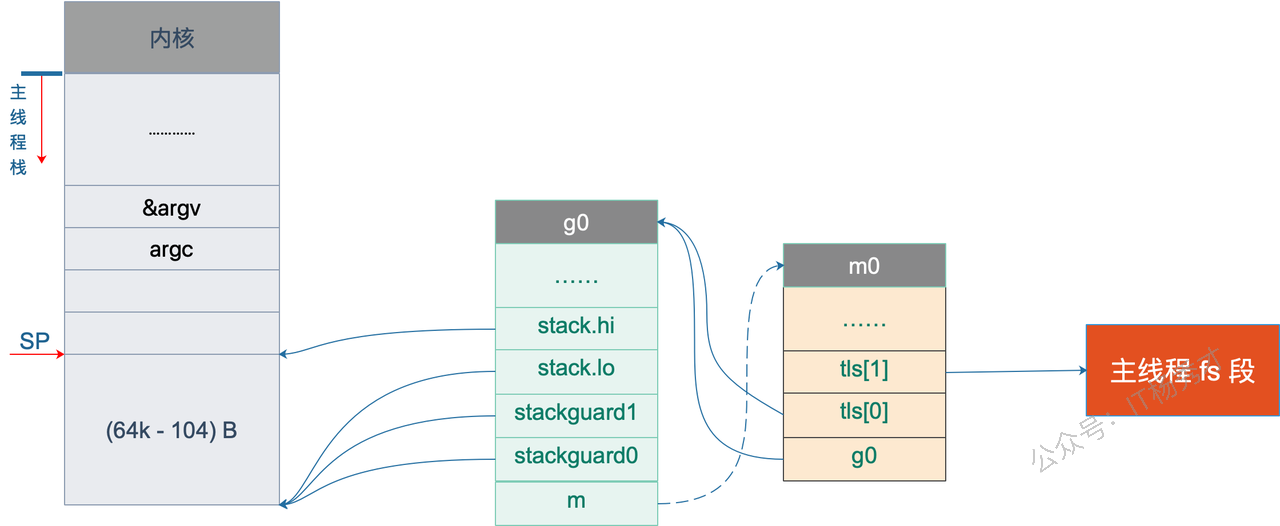
九、g0 是一个怎样的协程?有什么用?
9.1 g0 的定义
每个 M 都有一个专属的 g0,它是一个"系统 Goroutine",不执行用户代码,只执行 Runtime 代码。
9.2 g0 与普通 G 的本质区别
| 特性 | 普通 G | g0 |
|---|---|---|
| 栈 | 2KB 起步,动态增长(通常几 KB 到几 MB) | 较大(通常 8KB+),固定大小,系统栈 |
| 执行内容 | 用户写的函数 | Runtime 内部函数(schedule、GC、syscall 封装) |
| 调度行为 | 被调度(被动等待 M 执行) | 主动调度别人(执行 schedule() 决定下一个跑谁) |
| 数量 | 用户创建,无数多个 | 每个 M 严格只有 1 个 |
9.3 g0 的三大核心作用
作用 1:调度中转站(最重要的作用)
当 M 上的普通 G1 需要让出 CPU 时,必须切换到 g0,由 g0 执行调度逻辑。
G1 正在执行用户代码
│
▼
G1 阻塞(Channel / Sleep / 系统调用)
│
▼
保存 G1 的上下文(SP, PC, BP)到 G1.gobuf
│
▼
【切换到 g0 栈】← 关键!
│
▼
g0 执行 schedule() → findrunnable() → 找到 G2
│
▼
恢复 G2 的上下文
│
▼
【从 g0 切换回 G2】
│
▼
G2 开始执行为什么必须切到 g0? 因为 schedule() 本身是 Runtime 函数,它如果跑在普通 G 的栈上,可能会污染用户栈(比如占用太多栈空间、修改栈布局)。g0 有独立的、足够大的系统栈,可以安全地执行复杂的调度逻辑。
作用 2:系统调用的代理
普通 G 执行 read() / write() 时:
-
切换到 g0 栈。
-
g0 调用
entersyscall(),保存状态,把 G 标记为_Gsyscall。 -
g0 执行真正的系统调用。
-
系统调用返回后,g0 调用
exitsyscall(),尝试重新获取 P,恢复用户 G。
作用 3:栈增长管理
当普通 G 的栈不够用时,会触发 morestack。这个函数运行在 g0 栈上,负责分配更大的栈空间,拷贝旧栈数据,然后切回用户 G。
十、Go 栈和用户栈是如何进行切换的?
10.1 两种栈的明确区分
| 栈 | 归属 | 用途 | 大小 |
|---|---|---|---|
| 用户栈(G 栈) | 每个普通 G 独有 | 执行用户函数、局部变量、defer、panic recover | 2KB 起步,可动态增长 |
| 系统栈(g0 栈) | 每个 M 的 g0 独有 | 执行 Runtime 代码、调度、系统调用 | 较大,固定 |
10.2 切换的核心数据结构:gobuf
Go 在 G 结构体里保存了切换所需的全部寄存器状态:
type gobuf struct {
sp uintptr // Stack Pointer:栈顶指针
pc uintptr // Program Counter:下一条要执行的指令地址
g uintptr // 指向当前 G 的指针(恢复时知道切到哪个 G)
bp uintptr // Frame Pointer:帧指针/基址指针
ret uintptr // 返回值(某些架构用)
lr uintptr // Link Register:返回地址(ARM 等架构用)
}10.3 完整切换过程(以 G1 阻塞、切换到 G2 为例)
阶段 A:保存 G1 的现场(G1 → g0)
发生时机: G1 执行到 Channel 发送/接收、Sleep、锁阻塞等。
; 伪汇编
; 1. 把 G1 的寄存器保存到 G1.sched(gobuf)
MOVQ SP, G1.sched.sp ; 保存栈指针
MOVQ PC, G1.sched.pc ; 保存程序计数器(当前指令地址)
MOVQ BP, G1.sched.bp ; 保存帧指针
MOVQ $G1, G1.sched.g ; 保存 G 指针
; 2. 修改 G1 状态
MOVQ $_Gwaiting, G1.status ; G1 变成等待状态
; 3. 切换到 g0 栈
MOVQ g0.sched.sp, SP ; SP 切到 g0 的栈顶
MOVQ g0, g ; 当前 G 寄存器指向 g0
; 4. 调用 runtime.schedule()
CALL runtime.schedule(SB)阶段 B:g0 执行调度
func schedule() {
gp := findRunnable() // 找到 G2
execute(gp) // 准备执行 G2
}阶段 C:恢复 G2 的现场(g0 → G2)
; 伪汇编
; 1. 修改 G2 状态
MOVQ $_Grunning, G2.status
; 2. 从 G2.sched 恢复寄存器
MOVQ G2.sched.sp, SP ; 恢复栈指针
MOVQ G2.sched.pc, PC ; 恢复程序计数器(下一条指令)
MOVQ G2.sched.bp, BP ; 恢复帧指针
MOVQ G2.sched.g, g ; 当前 G 寄存器指向 G2
; 3. 跳转到 G2 的 PC 继续执行
JMP G2.sched.pc关键点: 这不是操作系统级别的线程切换(不需要进内核),只是修改了几个 CPU 寄存器(SP、PC、BP、g),所以速度极快(约 200 纳秒)。
10.4 系统调用时的特殊切换
当 G1 执行 read() 时,切换更复杂:
G1 用户栈
│
▼
调用 syscall.Read
│
▼
【切换到 g0 栈】
│
▼
g0 调用 entersyscall()
├── 保存 G1 上下文
├── G1.status = _Gsyscall
├── P 和 M 解绑(P 可以去找别的 M)
└── 释放 P 的锁
│
▼
g0 执行真正的 syscall(进入内核态)
│
▼
内核完成 read,返回用户态
│
▼
g0 调用 exitsyscall()
├── 尝试重新绑定原来的 P
├── 如果 P 被抢走了 → G1 进全局队列
└── 如果绑定成功 → 恢复 G1 上下文
│
▼
【切回 G1 用户栈】
│
▼
G1 继续执行十一:GOMAXPROCS=4,100 万个 Goroutine,P 只有 4 个,为什么不会成为瓶颈?
答案分三层:
① P 是"逻辑处理器",不是"执行单元" 真正消耗 CPU 的是 M(OS 线程)。P 只是一个调度上下文,本身不消耗 CPU 时间。4 个 P 意味着最多 4 个 M 同时执行用户代码,这与你的 4 核 CPU 完全匹配。
② 100 万个 G 大部分时间在睡觉 在真实的高并发程序中(如 Web 服务器),绝大多数 G 处于:
-
等待网络 I/O(
netpoll管理) -
等待 Channel
-
等待锁
-
等待定时器
这些 G 不需要占用 P。只有**就绪状态(_Grunnable)**的 G 才需要排队等 P。通常就绪的 G 数量远小于 100 万。
③ G 的本地队列分散了压力
-
4 个 P,每个 P 的本地队列可容纳 256 个 G。
-
4 个 P 合计能缓存 1024 个就绪 G,无需加锁。
-
全局队列作为兜底,Work Stealing 保证负载均衡。
④ G 本身极轻量
-
每个 G 初始栈 2KB,100 万个 G 约 2GB 内存。
-
现代服务器轻松承受。且栈是按需增长的,很多 G 实际只占用几 KB。
十二:纯死循环 for {},Go 1.14 前后分别发生什么?
Go 1.14 之前:
-
协作式抢占,依赖函数调用序言 检查
preempt标志。 -
for {}循环体里没有任何函数调用,永远不会走到检查点。 -
sysmon虽然能检测到 G 运行超 10ms,也设置了preempt标志,但 G 永远不去检查。 -
结果:这个 G 永久霸占一个 M 和 P,同 P 本地队列里的其他 G 全部饿死。程序表现为"卡死"(部分逻辑不执行)。
Go 1.14 之后:
-
sysmon检测到 G 运行超 10ms,向 M 发送SIGURG信号。 -
M 的信号处理程序(
gsignal)在**循环的安全点(backedge)**设置抢占标记。 -
即使
for {}没有函数调用,循环跳转指令(JMP)本身被编译器标记为安全点。 -
下一次循环迭代时,检查到抢占标记,G 主动让出 CPU。
-
结果:G 运行约 10ms 后被强制切走,其他 G 得到执行机会。
十三:栈切换时除了 SP/PC,还需要保存什么?为什么 BP 很重要?
gobuf 中保存的关键信息:
-
SP(栈指针):知道栈顶在哪,恢复后才能正确读写局部变量。
-
PC(程序计数器):知道下一条该执行哪条指令,恢复后才能继续执行。
-
G(Goroutine 指针) :知道当前是哪个 G,恢复后 M 的
curg才能正确指向它。 -
BP(帧指针/基址指针):用于栈帧回溯。
为什么 BP 极其重要?
BP 指向当前栈帧的底部。通过 BP 链表,可以回溯整个调用链:
当前函数的 BP ──► 调用者的 BP ──► 调用者的调用者的 BP ──► ...如果没有 BP:
-
Panic 时无法打印堆栈 :
runtime.Callers和runtime.Stack依赖 BP 链表回溯调用链。 -
GC 无法准确扫描栈:GC 需要知道栈上哪些位置是指针。通过 BP 和编译器生成的栈地图(stack map),GC 才能正确识别存活对象。
-
Defer 和 Recover 无法定位 :
defer链表挂在栈帧上,没有 BP 就找不到它们。
Go 在 AMD64 架构 上默认启用帧指针(-fno-omit-frame-pointer),就是为了保证调试和 GC 的正确性。