本文详解Linux进程切换原理、内核内嵌链表、O(1)调度队列、位图与active/expired双队列,吃透Linux调度底层,轻松应对面试
本篇文章涉及知识点与上一篇文章【进程优先级】高度耦合,有陌生的知识点建议回顾一下哦~
连接给大家放在下面啦~
目录
[1.struct runqueue运行队列](#1.struct runqueue运行队列)
一、进程切换
1.进程之间具有独立性
进程 = 内核数据结构 + 进程本身的代码和数据
多进程运行,需要各自独享各种资源,多进程运行之间互不干扰,你干你的我干我的,谁也不影响谁。
那父子进程之间是否也具有独立性呢???答案是肯定的,因为父子进程本质也是两个不同的进程,因此父子进程之间也具有独立性
2.并行与并发
并行:多个进程在多个CPU下,分别同时进行运行,这称之为并行。
并发:多个进程在一个CPU下采用进程切换的方式,在一段时间内,让多个进程都得以推进,称之为并发。
3.进程切换原理
CPU中含有寄存器,寄存器是共享的,但是寄存器内保存的数据本质是进程是私有的,称作进程上下文,当多任务内核决定运行另外的任务时,它会保存正在运行任务的当前状态,也就是CPU寄存器中的全部内容,这些内容被保存在任务自己的堆栈中,入栈工作完成后就把下一个将要运行的任务的当前状况从该任务的栈中重新装入CPU寄存器,并开始下一个任务的运行。
时间片:当代计算机都是分时操作系统,每个进程都有它适合的时间片(其实就是一个计数器),时间片到达,进程就被操作系统从CPU中剥离下来。
二、Linux内核中组织进程的链表结构
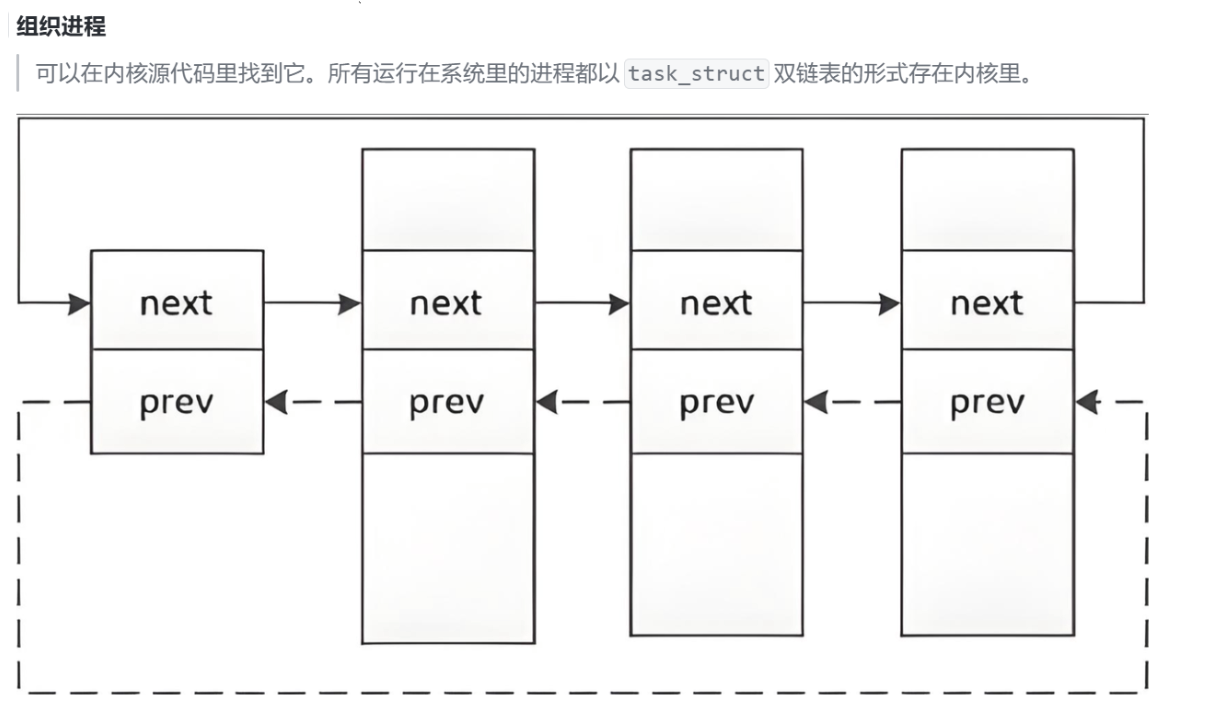
cpp
struct Node
{
DataType data;
struct Node *next;
struct Node *prev;
};虽然核心的双链表结构是这样的,但是局限性清晰可见,组织进程真的是直接把进程放在链表中这样调度得如此草率吗???Linux内核中,会将进程task_struct统一放在一张双链表中,但是进程不也有运行队列吗?不也有阻塞队列吗?同一个进程怎么可能同时存在于多个数据结构当中???因此接下来我们来详细剖析重塑一下我们对进程与这些调度相关数据结构关系的认识。
三、重新设计双链表
1.设计的新链表形式
其实要解决上述的矛盾很简单,我们只需要把思路反过来,并非是进程的struct_task结构体在这些数据结构当中,而是这些数据结构通通都放在struct_task结构体当中!!!怎么实现的呢?我们拿一个双链表来举例:
cpp
struct link
{
struct link *next;
struct link *prev;
};
cpp
struct task_struct
{
//很多个进程的属性
// ...
struct link task;
struct link run;
// ...
};以此类推,将各种数据结构放在task_struct当中,就可以实现同一个进程在多个数据结构中保存了,为什么要这么干呢?这么做增加了链式管理的扩展性,代码只需要维护一份!!!
2.如何获得当前进程的其他属性
我们先来看看C语言结构体内容中与地址相关的重要内容,一个结构体内含有多个变量,实例化后对该结构体变量取地址,其地址与结构体中第一个变量的地址是一致的
cpp
struct A
{
int m;
int n;
double c;
};比如在这个例子当中,实例化A obj后,对obj取地址与对m取地址得到的结果一致,即&obj == &(obj.m)。
在C语言中,任何变量的地址数字,是开辟众多字节当中,地址数据最小的那个,大白话来讲就是在一个数组当中,首元素地址是最小的,越往后地址越大,核心证明就是C++中的迭代器遍历是依靠不断++遍历的,那么根据这个知识点我们就可以通过结构体内任意元素的地址推出首元素地址,假设知道了c的地址,怎么推出首元素地址呢?具体这么做:
cpp
&((struct A*)0->c)将0强转为struct A*的结构体指针类型,这样默认首元素地址就从0开始了,此时对元素c取到的地址是不是就是c的地址相对于首元素地址的偏移量?那我们既然知道了偏移量,是不是就可以通过c的地址得到首元素地址了???听懂掌声
知道了这些再来看我们的核心问题,已知当前进程的某个属性,如何获得其他属性,是不是心中有了答案,实现形式也许不同,但本质原理都是一样的
3.设计优点以及解决的实际问题
这样设计除了能增加链式管理的扩展性和维护代码更加容易之外,我们可以往更加广泛去想,是不是不同的结构体对象都可以用链表来连接了?甚至包括红黑树,hash等数据结构都可以!!!这就解决了进程不能在不同调度队列的问题
四、Linux2.6内核O(1)调度队列
Linux2.6内核的调度算法极为优秀,时间复杂度仅为O(1)!!!接下来博主将不断剖析它是如何做到如此优秀的时间复杂度的
1.struct runqueue运行队列
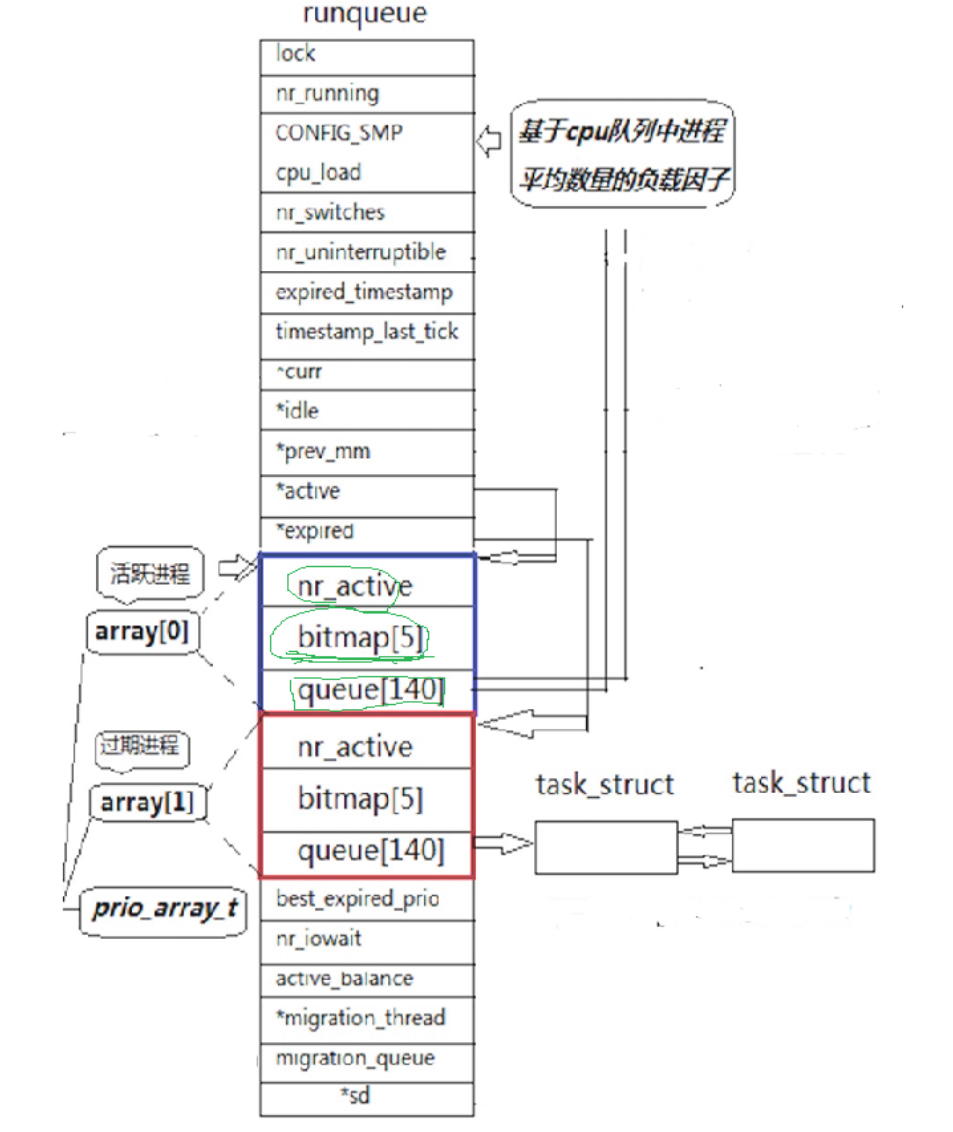
上图是Linux2.6内核中进程队列的数据结构,一个CPU拥有一个runqueue
接下来我们核心理解queue140、bitmap5、nr_active以及active、expierd两个指针的作用
2.queue140中的实时优先级与普通优先级
//引出上篇文章优先级40梯度与当前数组下标的关系,每一个数组元素都是连接着同一优先级进程的队列,根据进程优先级索引某个队列,根据FIFO原则取队首,O(1)复杂度
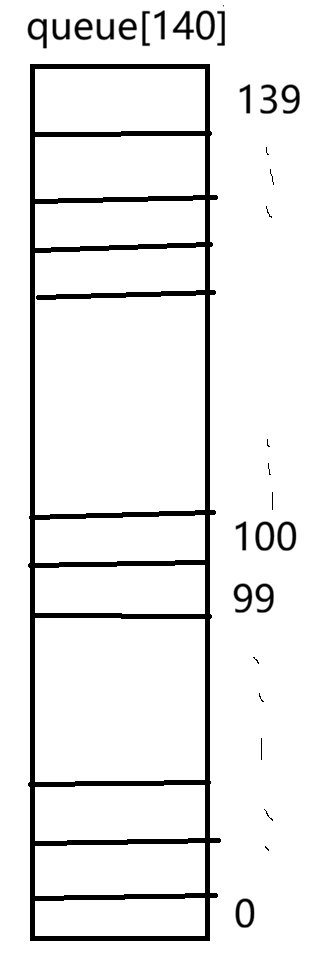
在这个数组当中,每一个元素都是连接着同一优先级进程的队列,下标为0-99的一百个梯度的优先级称为实时优先级,下标为100-139是四十个梯度的优先级称为普通优先级。
实时优先级我们暂时不用关心,但是我们看到四十个梯度的普通优先级是不是感觉莫名熟悉,没错,就是我们上篇文章讲到的PRI(进程优先级)范围是60,99,刚好是40个梯度,我们将这个范围的优先级都加上一个定值40,是不是就对应这里普通优先级的范围100,139了,这就是后面根据优先级寻找待调度进程的核心算法,操作系统调度到某个优先级后,根据这个优先级加上40,直接在queue140索引到目标队列,然后根据FIFO原则,取队首,就是我们将要调度的进程,全过程O(1)的时间复杂度。
3.nr_active与bitmap5
我们要在queue140中寻找优先级最高的进程进行调度,那是不是同时也存在某个优先级的队列为空的情况,那我们还得依次往优先级低的方向遍历,最坏的情况也有O(140)的时间复杂度开销,因此,聪明的你发明了位图(bitmap),位图用来标记queue140中的每个索引位置是否存在进程,按照每个位图有32比特位来算(0000 0000 ... 0000),要覆盖完140个索引,需要5个位图(5×32 = 160,第五个位图只有12个比特位有效),因此原本最坏需要遍历140次的算法变成了只需要遍历5个位图,通过位图快速定位最高优先级的非空队列,如果某个位图为0,证明这32个索引位置都没有可调度的进程,直接跳过,算法真正意义上实现了O(1)的复杂度
此时可能有人疑惑了,这样做最坏的时间复杂度也有O(5+32)啊,跟O(140)也没差多少吧,为什么要费这么大心思弄个位图?这里就要区分"实际实现的高效性"和"理论数字计算"了:
位图的位操作(如查找最高位1)依赖硬件指令(如x86的BSR),单次操作可直接定位,耗时是纳秒级的,几乎不存在"逐位遍历"的开销。而遍历队列即使140次操作,每次都要检查队列是否为空(涉及内存访问、指针判断),耗时远超单条硬件指令,且次数越多差异越明显。
总结来讲,这也是调度器设计中"以空间换时间"的经典优化。
但是如果整个队列都没有可以调度的进程了,以上的这些操作都算多余的开销,因此我们还要判断队列中是否存在可运行进程再决定遍历与否,那就需要一个能够实时记录进程数目的变量nr_active了,当且仅当nr_active不为0的时候才进行遍历,再次优化了进程调度。
4.进程饥饿问题与进程优先级修改问题
这里我们要引入两个进程调度会遇到的核心问题:
进程饥饿问题:
PRI值越低,进程优先级越高,假如当前队列中待调度的优先级最高的进程PRI为80,可一直有源源不断的PRI为79的进程加入进来,那么这些进程就一直被调度,永远排不到PRI为80的进程,它永远得不到CPU资源,就造成了进程的饥饿问题
进程优先级修改问题:
假如我们把某个进程的优先级从80改成了81,那么我们是不是要将该进程从旧的优先级队列中删除,然后再加入到新的优先级队列当中,这无论是空间还是时间成本都会大大提高,时间复杂度更是从O(1)变成了O(n),尤其是在进程数量较多时,系统相应速度会明显变慢,这样进程优先级的修改成本就太高了!
5.活动队列与过期队列
要想解决上面的两个问题,其实也很简单,只需要区分出活动队列和过期队列即可!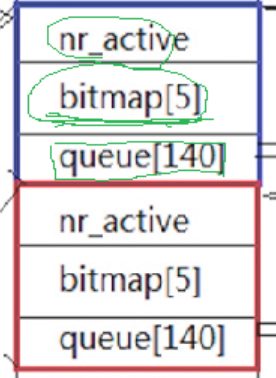
如上图,整个runqueue中存在着两个包含着一模一样元素的队列,这两个队列我们称为活动队列和过期队列,我们要调度的进程,只从活动队列的queue140中获取!!!而调度过的进程,等时间片结束后,从CPU上剥离下来不是回到活动队列中原来的位置,而是被放到了过期队列当中!这样就不会在一段时间内多次调度该进程了。
有了这两个队列的区分,我们的就可以完美解决上面提到的两个问题了:
解决进程饥饿问题:新加入进来的进程不放到活动队列当中,而是放到过期队列当中,虽然新加入进来的进程优先级可能会更高,但是在活动队列里的进程全部调度结束前的这段时间内,它没有被调度的资格,要想被调度,先去过期队列等下一批!
解决修改进程优先级成本高的问题:从上一篇的博客【进程优先级】中提到,要更改进程优先级,是要通过更改NI(nice值)来间接更改的,而不是直接修改PRI值,在更改进程优先级之后,当前进程先通过旧的PRI被CPU调度,然后运行结束后被放到过期队列的时候,要放到新的优先级队列当中,新的优先级根据PRI(new) = PRI(old)+ NI计算得来的。
有了这两套调度队列的区分,我们就能在分时系统当中,通过较为公平又不影响调度效率的方式,选择一个进程分配CPU资源,保证在一段时间内,让所有进程都能够得到CPU资源!!!
但到目前又出现了一个新的问题,活动队列的进程全部调度结束后,怎么把过期队列里面的进程再全部拿回来,开启新一轮的调度呢?解决了这个问题,我们才能真正的把Linux整个进程调度算法在我们的脑海里形成逻辑闭环。
这就需要两个指针来参与完成这最后一步了!
6.active指针与expired指针

前面我们已经知道了runqueue中存在两个调度队列,但是代码上如何把这两个队列写进去呢,如下:
cpp
struct prio_array_t
{
nr_active
bitmap[5]
queue[140]
};这里的数据类型不添加解释,用一个结构体伪代码供大家快速理解。
有了上面的结构体变量,我们只需要根据这个变量创建出大小为2的数组即可:
cpp
struct prio_array_t array[2];然后创建两个指针变量,分别指向数组的两个元素即可:
cpp
DataType *active = &array[0];
DataType *expierd = &array[1];于是就诞生了指向活动队列和过期队列的两个指针
话接刚才的最后一个问题,当活动队列的进程全部被调度完后,只需要将两个指针指向的内容swap一下,就能把过期队列里面的所有进程全部换给活动队列了!!!至此,下一轮新的进程调度开始!
7.总结
至此,Linux的整个O(1)的调度算法我们讲解到这里形成了一个逻辑闭环,我们对进程调度塑造了崭新的认识!相信大家此时脑海中对Linux的进程调度已经是可以形成一个动态的过程了!
感谢大家的观看与共同学习,更优质的Linux系列内容后续持续更新,喜欢博主的可以给一个三连哦~