让一个模型同时处理 10 个推理请求是棘手的,但还算简单;让它在全天候面对 2,000 名工程师使用长上下文的代码助手时保持稳定、不产生失控成本,这才是团队容易卡住的地方。一个能工作的端点只是起点。团队需要识别支持硬件、连接正确的组件------服务、扩缩容、可观测性和成本护栏------这样部署才能在真实、持续负载下支撑预期的 SLA 和 SLO。
DigitalOcean 已在 DigitalOcean AI Platform 上提供 无服务推理Serverless Inference:一条快速接入 OpenAI、Anthropic、Meta、Deepseek 或其他提供商模型的路径,最小配置、按 token 定价。这种产品适合很多使用场景。然而,当你需要跑自己的模型权重、要在专用 GPU 上获得可预测的性能,并且从经济角度看,持续的大量 token 生成远比按 token 突发计费更划算时,就需要另一种方式了。
专用推理Dedicated Inference------我们在 DigitalOcean AI Platform 上的托管 LLM 托管服务------填补了这一空白。
专用推理Dedicated Inference 在专用 GPU上部署并运维一套带有明确倾向的推理栈,底层采用 Kubernetes 原生编排。你通过已经在 DigitalOcean 生态中使用的控制平面和 API 进行交互;数据平面则暴露公网和私有网端点,让 VPC 内外的应用都能安全调用你的模型。
这项服务的设计初衷,是将一个庞大的组合空间------GPU 型号、运行时、路由器、自动扩缩策略------收敛为引导式的默认配置,让团队比自建栈更快达成生产就绪的里程碑,同时保留模型服务中真正重要的那几个可调旋钮:副本数、扩缩行为,以及在推进产品路线图时需要用到的高级优化能力。
我们管什么,你管什么
每项托管产品都会在平台负责和客户负责的事项之间划一条线。专用推理的目标,是把 Day 2 运维------集群生命周期集成、流量入口、核心推理服务与路由组件,以及它们之间的衔接------放在平台侧,而把模型选择、容量规划以及针对具体工作负载的调优留给你。
通常由平台管理:
- 底层编排体系的供应与生命周期,遵循产品设计(例如托管 Kubernetes 集成以及 GPU 资源池协调)。
- 核心推理引擎与编排集成,包含规模化下真正关键的模式:智能路由、自动扩缩钩子,以及面向生产环境的服务路径。
- 端点的创建、健康检查与弹性伸缩工作流,以及让端点持续符合声明式配置所需要的运维自动化。
由你掌握:
- 选择适合你 SLO 和预算的模型(含支持的自带模型路径)、GPU 规格以及副本数。
- 配置扩缩行为,并随着时间推移,逐步启用与你的延迟、吞吐和成本目标相匹配的高级服务选项。
- 通过稳定的 HTTP API 接入应用,API 与主流 LLM 客户端栈保持一致。
专用推理Dedicated Inference 是什么?
专用推理构建于业界标准组件之上,让客户能够受益于社区推动的持续改进:
- vLLM 是一个功能强大且被广泛采用的推理引擎,适用于在现代 GPU 上运行大语言模型。
- LLM-d 是一套面向 Kubernetes 的分布式推理模式技术栈------精确的前缀缓存感知路由、有别于传统 HTTP 服务的扩缩考量,并留有随着工作负载需求而向更高级拓扑发展的空间。
这一组合反映了一种深思熟虑的选择:在客户当前所处的位置与之相遇(兼容 OpenAI 的 API、DigitalOcean 上熟悉的 GPU 产品),同时与路由、副本和横向扩展推理的生态演进方向保持一致。
高层架构
系统设计将控制平面(端点如何创建、更新、列出及删除)与数据平面(聊天/补全请求流量如何抵达你的模型)进行了分离。这与管理请求相呼应:管理请求走的是一条为区域部署和持久化生命周期工作而构建的路径;推理请求则走的是 GPU 前面一条直接且低延迟的路径。
控制平面:中心入口,区域执行
这里所说的"控制平面"是指什么?在这种划分中,控制平面就是处理管理流量的那一整套东西:针对专用推理端点的管理 RPC,以及将你声明的意图转化为实际运行的 DI 基础设施所依赖的持久化记录。它与数据平面是分离的,数据平面是端点健康后推理请求(聊天/补全风格)所经过的"热路径"。
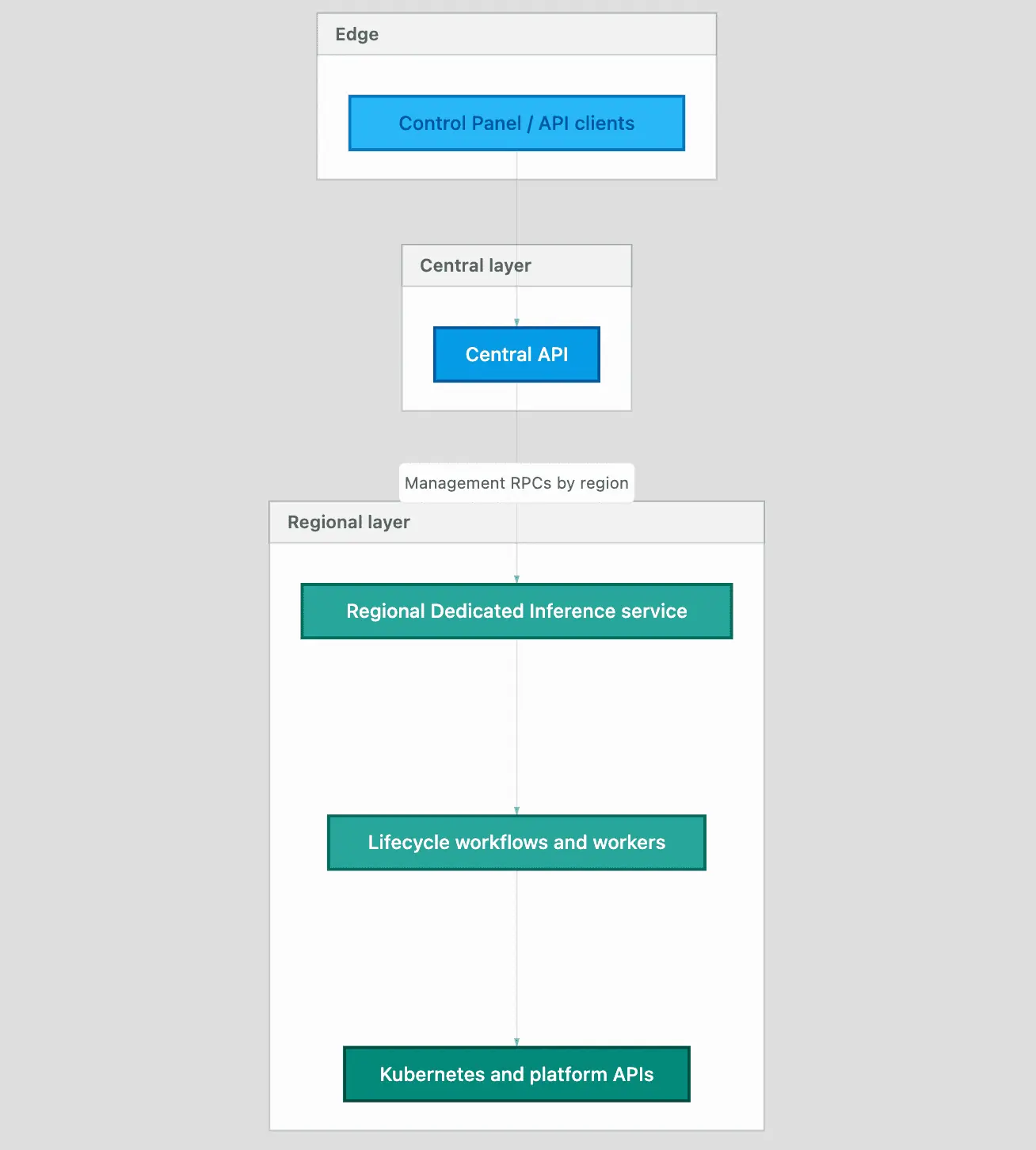
中心 API 层:源自 DigitalOcean Cloud UI、自动化工作流或公共 API 的请求,首先会被路由经过一个中心化的 API 层。这一层维护着按区域划分的端点归属映射关系,并将每个请求透明地转发至对应的区域后端。这一设计遵循多区域扇出模型,通过稳定的标识符来定位区域端点。
区域专用推理服务:每个区域运行一个控制平面服务,负责其范围内实例的完整生命周期管理。这包括持久化期望状态、根据观察到的状态进行调和、推进生命周期状态(例如 创建中 → 活跃),以及将供应或变更底层基础设施的工作流排入队列。在此语境中,生命周期指的是那台状态机,它管理者从被请求到正在运行再到可达的状态转换。一个实例代表了整个托管推理部署------既包含其控制平面记录,也包含相关联的后备资源。
独立的 Worker 式组件负责执行那些需要重试、退避和幂等性的集成操作------调用 Kubernetes API、观察对象状态,并将生命周期更新发布回核心服务。这类似于我们熟知的 Kubernetes Operator 协调器模式:观察期望状态、采取行动、不断重复直至现实与意图一致。典型场景:临时性 API 错误或缓慢的节点启动不会卡住面向用户的 API;系统会持续尝试,并展现一个清晰的状态,而非一个只应用了一半的状态。
DigitalOcean Kubernetes 与容量:平台首先帮助确保目标 VPC 内拥有足够的 DigitalOcean Kubernetes 容量,挂接所需的 GPU 及配套 CPU 节点容量,铺开托管推理栈(网关与模型工作负载),并为公网和私有端点创建区域网络负载均衡器。
数据平面:VPC 原生流量,经网关路由的请求
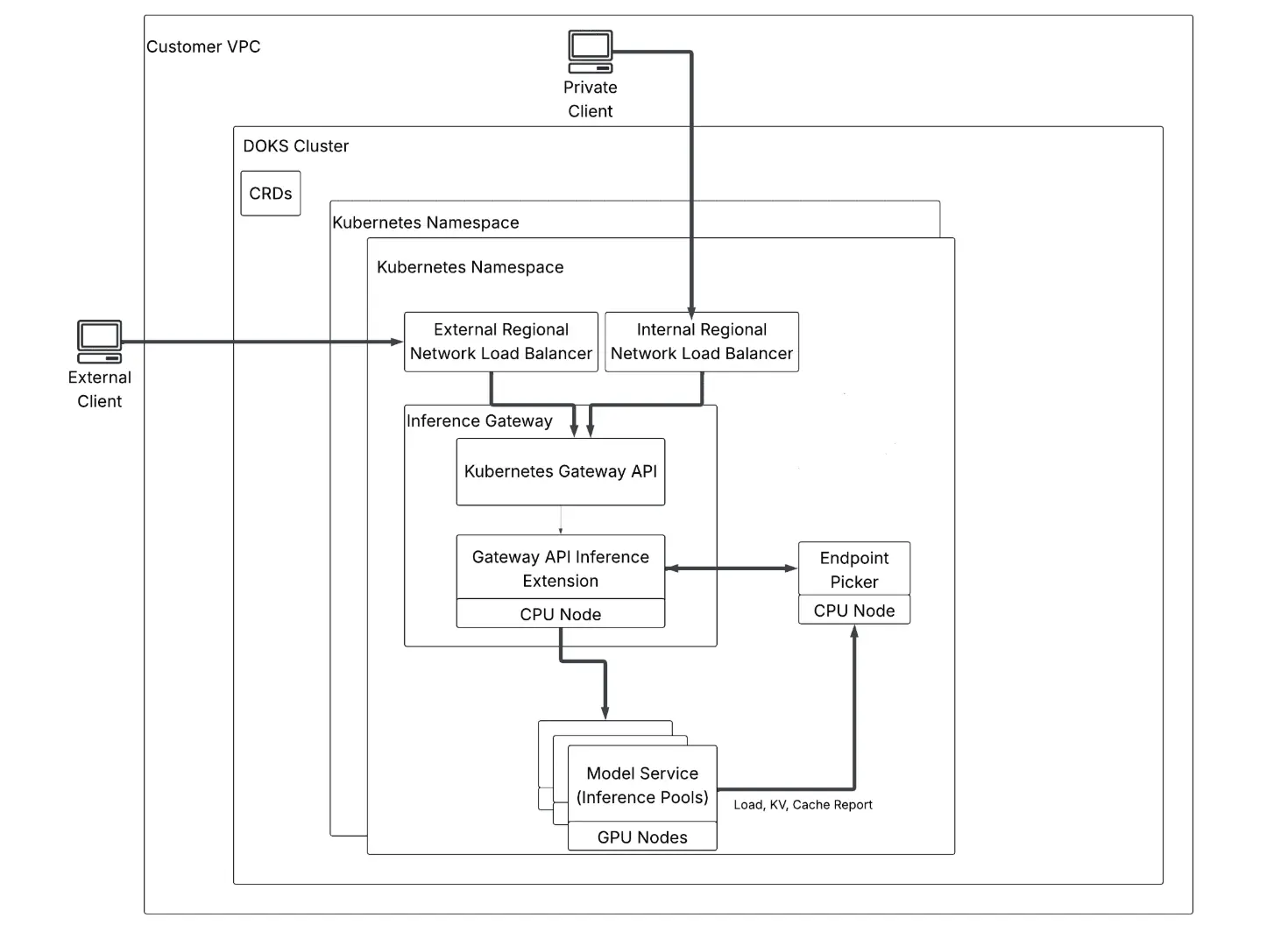
客户合约与端点连接:一旦端点处于活跃状态,客户端便发送兼容 OpenAI 的 API 请求(例如,到 /v1/chat/completions 风格路由的 HTTPS 请求)。你的公网端点 FQDN 解析到一个外部区域网络负载均衡器(L4);你的私有端点则解析到一个内部区域网络负载均衡器,因此同一个推理栈既可从公网访问,也可停留在你的私有 VPC 网络上。在这两种情况下,流量都是符合 OpenAI 格式的 JSON,承载着模型 ID、消息及生成参数。
集群放置与 VPC 隔离:在 VPC 内部,工作负载运行在 DOKS 上。每个 VPC 一个集群可以承载多个专用推理部署,每个部署通过一个 Kubernetes 命名空间隔离。所期望的网关与模型接线通过 Custom Resources(CRD------自定义资源定义)来表达:是以声明式对象的方式 kubectl apply(或由平台代为 apply),而非使用命令式脚本。
推理网关与 Kubernetes Gateway API:经过 NLB 后,流量到达推理网关,该网关基于上游 Kubernetes Gateway API 实现------这是描述 HTTP/TLS 路由进入集群的社区标准。
Gateway API 推理扩展(推理感知路由):在网关之下,Gateway API Inference Extension 教会路由如何识别推理信号:队列深度、副本健康度以及 KV 缓存亲和性(优先选择一个已经存有可复用提示前缀的键/值张量的副本,以避免从头重新计算)。KV 缓存是先前 token 注意力状态的保存;推理感知路由特意不是简单的轮询,因为"最廉价"的副本往往是那个已经缓存了你前缀的副本。
端点选择器:在 CPU 节点上,端点选择器是与推理扩展通信,并为每个请求选出应由哪个 GPU 副本接收的组件。
模型服务与推理池:在 GPU 节点上,模型服务------在配置中由推理池提供支撑------运行着你的模型副本(能够服务于相同模型 ID 的不同 Pod/进程)。每个副本向上报告负载、KV 及缓存元数据,使端点选择器的选择在滚动更新、崩溃及自动扩缩事件中始终保持准确。副本是同一模型服务器的水平扩展拷贝;池则是为路由和容量而对这些副本的分组。
谁适合使用专用推理?
专用推理面向的是那些已经清楚自己需要 GPU,但又不想成为一支全职推理平台团队的构建者:
- 在裸金属 GPU Droplet 或 Kubernetes 上自托管,并希望将编排、基线优化以及重复性的基础设施工作卸载出去,同时保持对应用 API 级别自主权的团队。
- 已从无服务器推理毕业,需要硬件层面的控制或自带模型,但又不想放弃托管运营的团队。
- 推理需求持续稳定,对可预测的 GPU 小时经济性和性能隔离的看重程度超过纯粹突发弹性的组织。
推理已不再是一个新奇层;它已是核心应用栈的一部分。这一转变拔高了可靠性、性能及成本可预测性的门槛。专用推理是为那些需要生产级、专用 GPU 推理,且需要一条从模型选择到稳定端点的托管路径的团队而建------这样,你们的工程周期就可以花在产品与提示上,而非重新发明一遍服务平台。