文章目录
- [什么是 function calling?模型调用函数的一种能力](#什么是 function calling?模型调用函数的一种能力)
- [function calling协议内容分析](#function calling协议内容分析)
什么是 function calling?模型调用函数的一种能力
模型调用函数的一种能力。
可用的函数传给模型了,如果模型能够根据函数列表和函数描述选择合适函数,并生成结构化调用参数,解析函数的执行结果,并且根据结果给出最后终答案话,那么我们就称模型有function calling的能力。即
Function calling 本质上是模型根据函数列表和函数描述选择合适函数,并生成结构化调用参数的能力
我们大多数都是通过模型的api来间接的使用模型,所以大多数情况下,我们会把 function calling的概念稍微变一变,变为模型api调用函数的能力。本质上2者是一样的,都是从函数列表挑选函数的能力,只不过一个是用模型api在挑选,一个是用模型在挑选。一般情况下,只要模型有了function calling的能力,对应的模型api也必将有function calling的能力。模型api和模型之间仅仅是一些转换逻辑。
由于大部分情况下,我们都是调用的模型api,而并非直接调用模型,因此我们关注的更多是模型api是否支持function calling
更准确地说,function calling 涉及两层能力:模型能力:模型能不能根据函数描述,判断该调用哪个函数,并生成结构化参数
API/服务能力:接口是否支持传入 tools/functions,并把模型输出解析成 tool_call 格式
所以不能简单说:
只要模型有 function calling 能力,对应 API 必然有 function calling 能力
更准确是:
如果模型本身具备较强的工具调用能力,并且模型服务/API 层也支持 OpenAI tools 格式、函数 schema 注入、tool_call 解析,那么这个 API 才算真正支持 function calling。
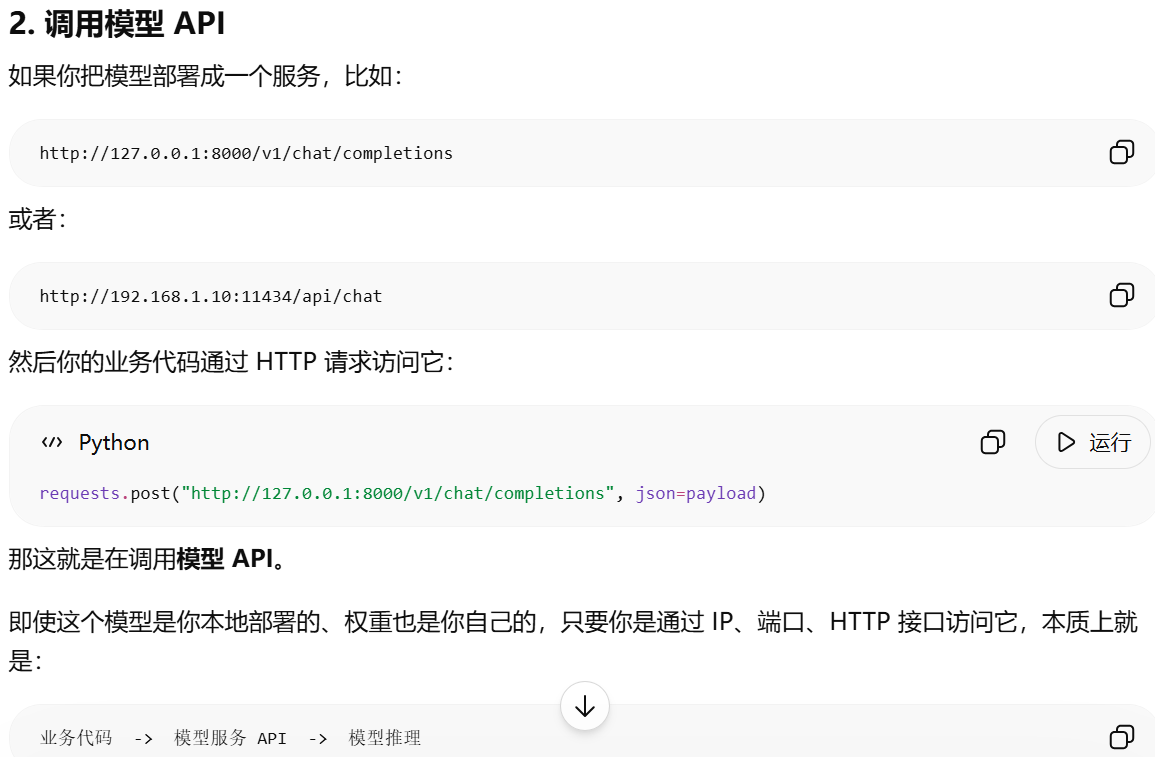
在大多数实际应用中,我们并不是直接加载模型权重并调用模型推理,而是通过模型服务提供的 API 间接使用模型。即使是本地部署的大模型,通常也会被封装成一个推理服务,并通过 IP、端口或 HTTP 接口对外提供访问能力。因此,从应用开发的角度看,我们关注的往往不是"模型本体是否存在某种能力",而是"当前模型 API 是否暴露并支持这种能力"。
Function calling 本质上是模型根据函数列表和函数描述选择合适函数,并生成结构化调用参数的能力。但在实际使用中,这一能力通常需要模型能力和 API 层能力共同支持:模型需要能够理解工具描述并生成合理的函数调用结果,API 层则需要支持传入函数列表、构造提示模板、解析模型输出,并以统一格式返回 tool call。因此,我们通常更关注模型 API 是否支持 function calling,而不仅仅是模型本身是否具备相关能力。
本地部署模型暴露 IP 和端口后,你调用的是自己搭建的"模型 API 服务";只有在代码里直接加载模型权重并执行推理,才算更严格意义上的"直接调用模型"。
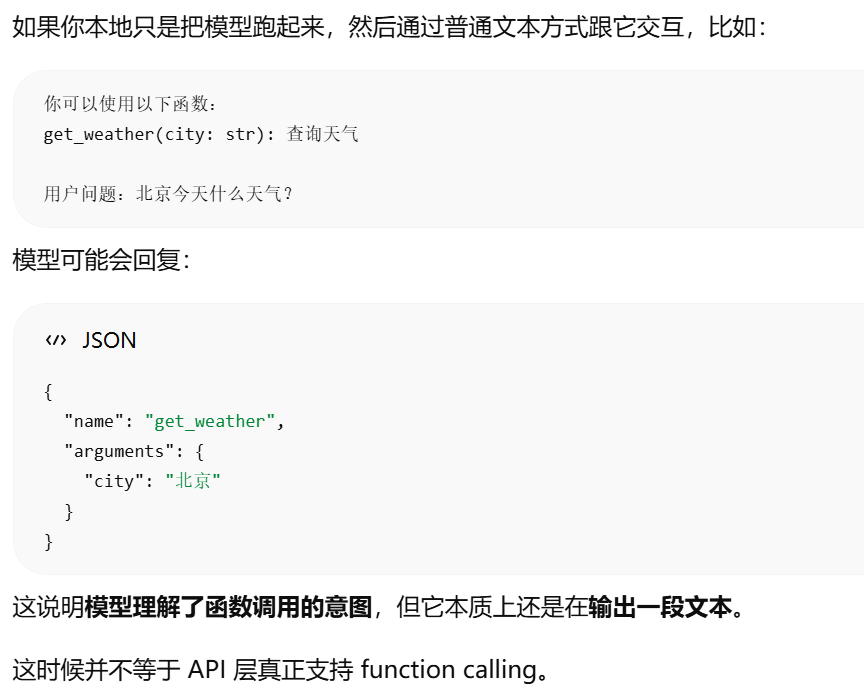
模型会 function calling ≠ API 支持 function calling。前者是模型能生成"调用函数的文本",后者是接口协议真正提供了 tools、tool_calls 这类结构化能力
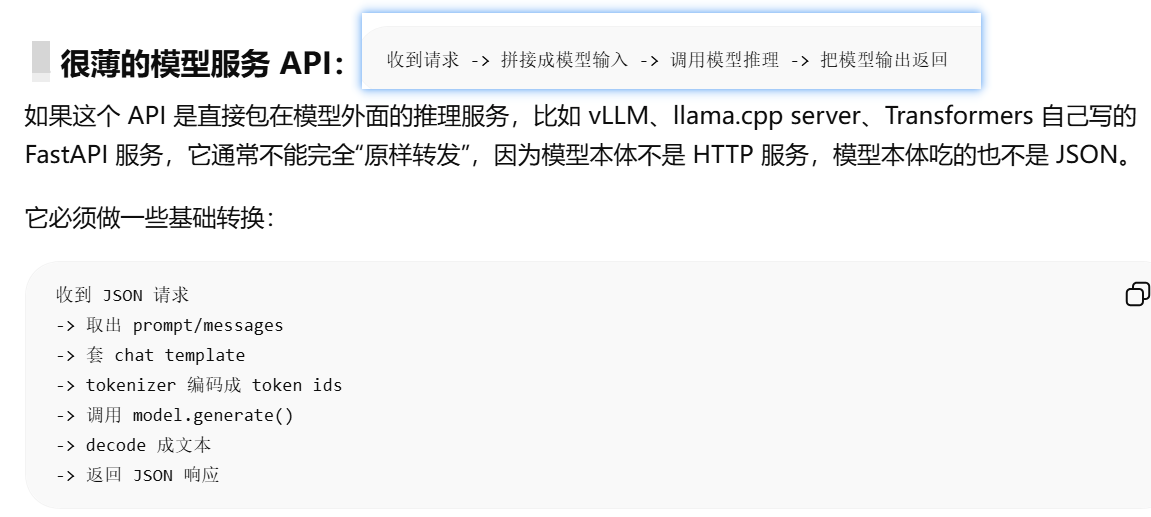
模型 API 可能做很多封装解析动作,也可能几乎什么都不做,只是纯转发请求到模型推理服务第一层:代理转发 API
只转发请求和响应,不处理模型输入输出。
第二层:基础推理 API
把 prompt/messages 转成模型输入,调用模型推理,再返回文本。
第三层:工具调用 API
除了基础推理,还支持 tools/functions 字段、tool_call 解析、参数格式化等。
本地用 vLLM / SGLang 部署的模型,一般属于:基础推理 API + OpenAI-compatible API 封装
如果你开启了 tool/function calling 参数,它还可以变成 工具调用 API。
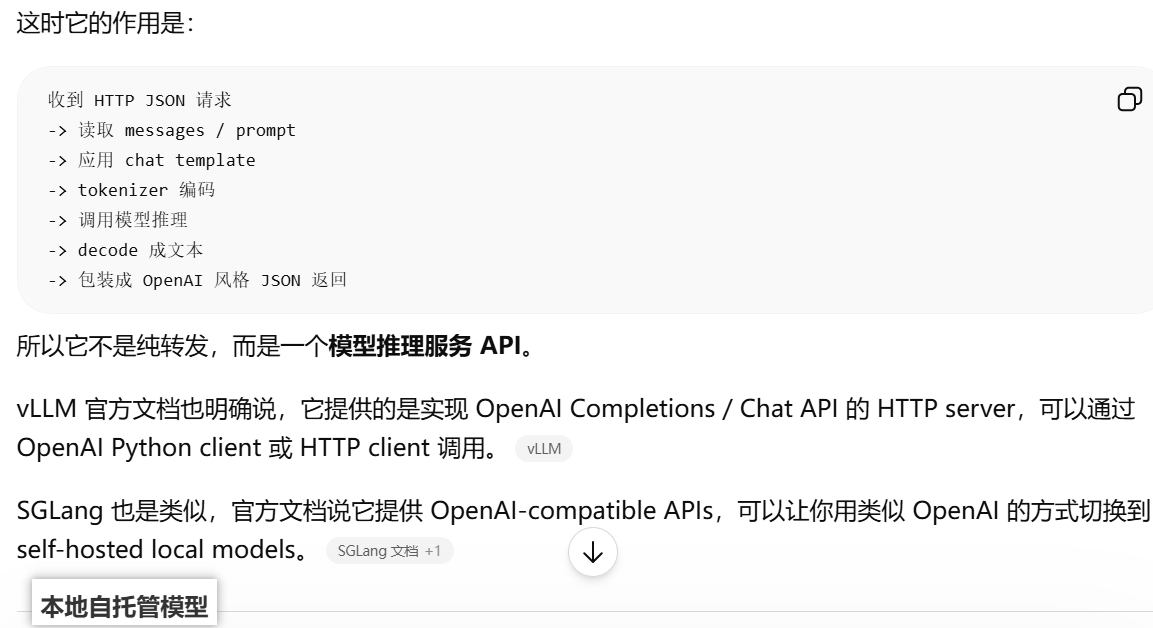
可以直接用 OpenAI 官方 SDK 调用 vLLM / SGLang 本地启动的模型 API 服务,但前提是:你的 vLLM / SGLang 服务启动的是 OpenAI-compatible API server。
基础推理 API解释:收到 HTTP JSON 请求
-> 读取 messages / prompt
-> 应用 chat template
-> tokenizer 编码
-> 调用模型推理
-> decode 成文本
-> 包装成 OpenAI 风格 JSON 返回
/v1/chat/completions -> 聊天补全接口/v1/completions -> 文本补全接口















































示例图
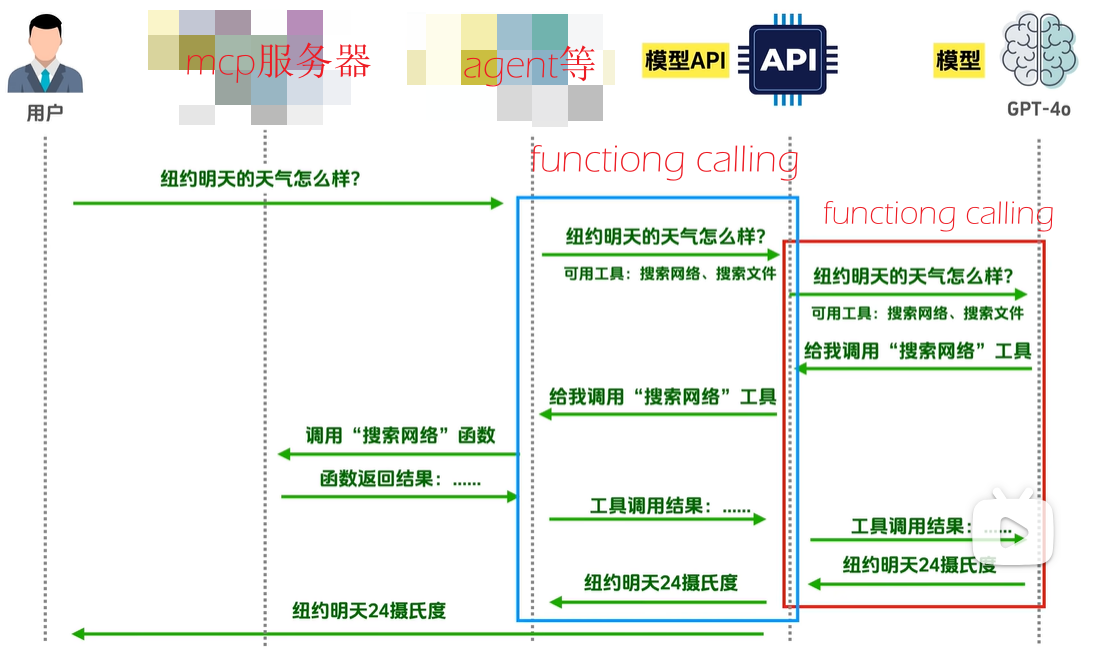
function calling协议内容分析
function calling
背后是由一套协议的,这套协议规定了工具列表要怎么传给模型api,而模型api又如何返回所挑选的工具以及对应的参数。各个大模型厂商的functiong
calling协议大致相同。

1、调用模型api
2、提取工具名称和参数
3、调用工具
4、再次调用模型api,此时模型会拿到工具的执行结果,并根据结果做出判断
5、返回模型api给出的最终答案

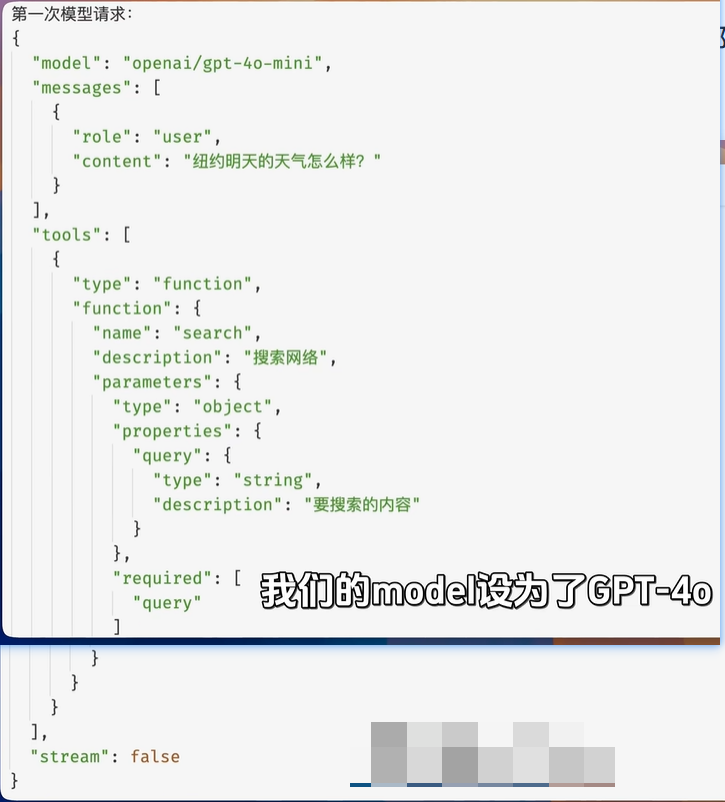
tools是一个列表,包含了所有可用的工具
streams:false 不要流式返回内容
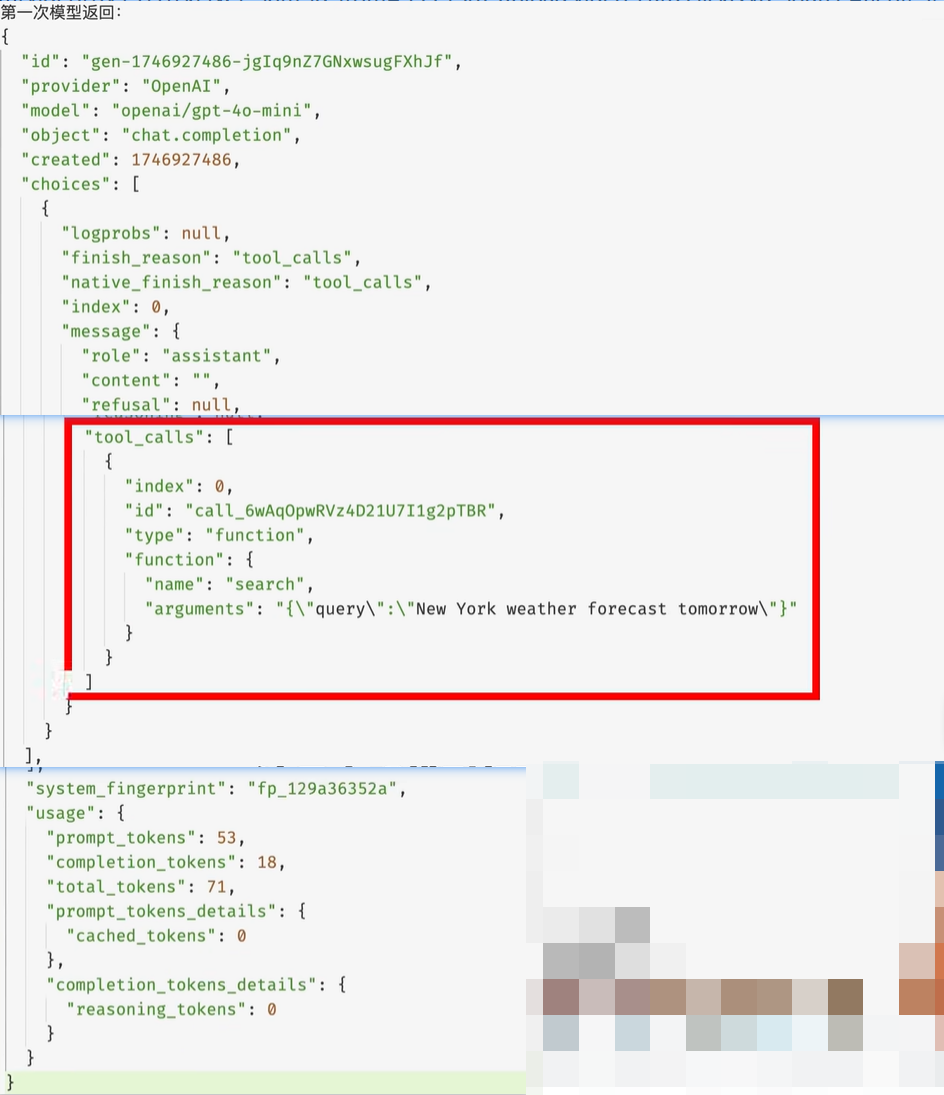
tool_calls表明模型想调用一个叫search的工具,调用参数是如图所示的
usage 字段就是这次 API 调用的 token 用量统计。它通常用来做两件事:
看这次请求消耗了多少上下文长度
估算这次请求的费用
prompt_tokens 指的是:输入给模型的 token 数量
completion_tokens 指的是:模型生成/完成出来的 token 数量。也就是模型输出token
total_tokens 指的是:这次请求总共使用的 token 数量,total_tokens = prompt_tokens + completion_tokens
prompt_tokens_details是对 prompt_tokens 的进一步拆分。
cached_tokens 表示:输入 token 中有多少命中了 prompt cache
cached_tokens 仍然属于 prompt_tokens,只是告诉你其中有多少是缓存命中的
audio_tokens
如果是音频输入,音频也会被转换成模型可处理的 token,这部分可能会计入 audio_tokens。
completion_tokens_details
这个字段是对 completion_tokens 的进一步拆分
reasoning_tokens 指的是:推理模型内部思考/推理过程消耗的 token。
accepted_prediction_tokens / rejected_prediction_tokens
这两个通常和 Predicted(预测) Outputs 相关。
简单理解:
accepted_prediction_tokens:预测输出中被模型接受并出现在 completion 里的 token
rejected_prediction_tokens:预测输出中被模型拒绝或未采用的 token
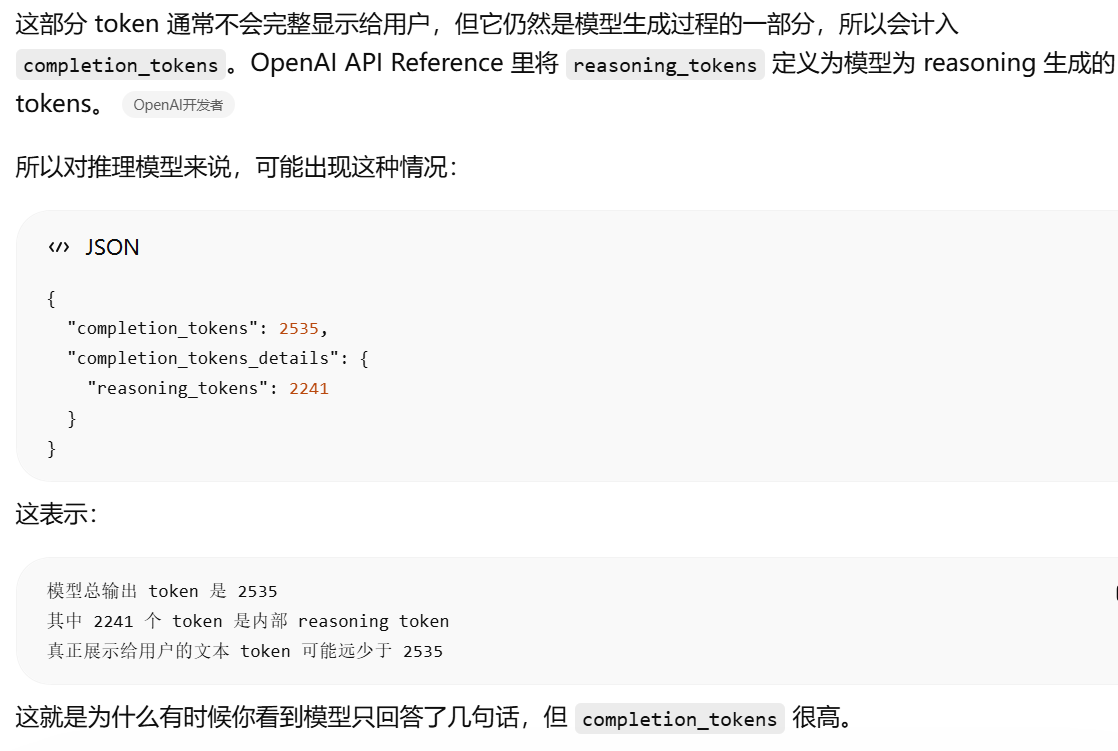

json{
// 以 OpenAI-compatible API 常见返回为例:
"usage": {
"prompt_tokens": 2006,
"completion_tokens": 300,
"total_tokens": 2306,
"prompt_tokens_details": {
"cached_tokens": 1920,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
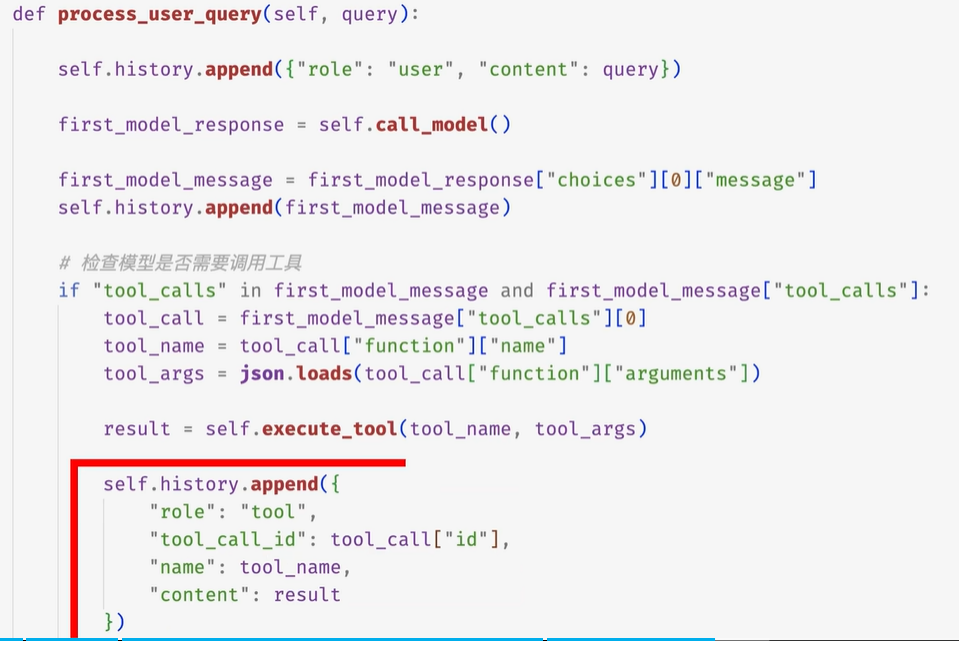
}role:tool是工具的执行结果
role: "tool" 的意思是:这条 message 不是用户说的,也不是模型说的,而是"工具/函数执行后的结果"。
tool_call_id 是用来对应前面模型发出的那次工具调用
因为模型一次可能调用多个工具,比如:
"tool_calls": [
{"id": "call_weather", "function": {"name": "get_weather", "...": "..."}},
{"id": "call_air", "function": {"name": "get_air_quality", "...": "..."}}
]
那你返回工具结果时,需要告诉模型:
{
"role": "tool",
"tool_call_id": "call_weather",
"content": "天气结果..."
}
以及:
{
"role": "tool",
"tool_call_id": "call_air",
"content": "空气质量结果..."
}
这样模型才能知道哪个结果对应哪个工具调用。



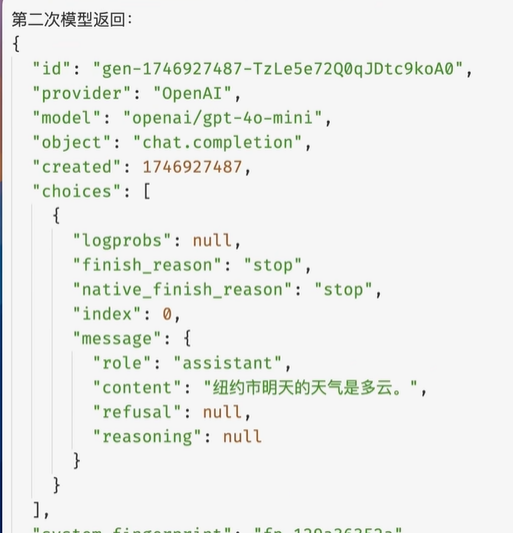
在message的conten里给出了答案
总结
