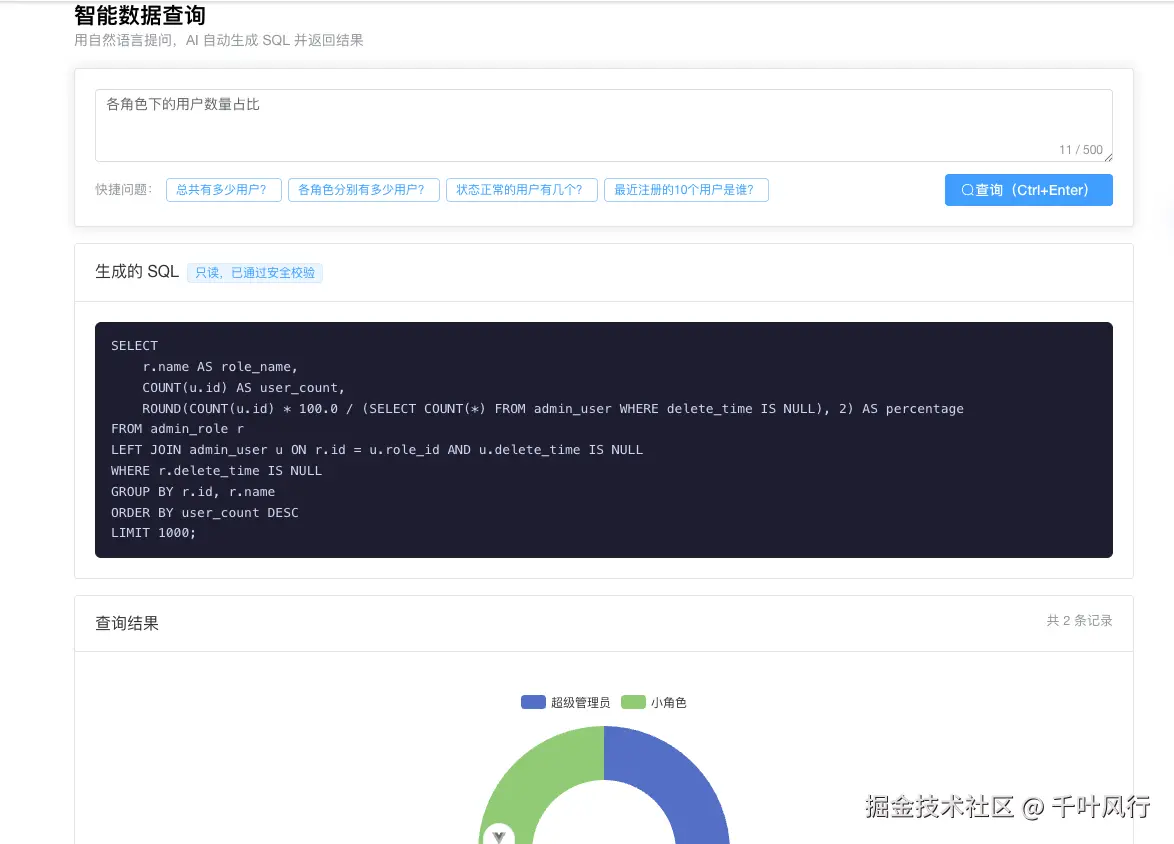
1. Text-to-SQL 是什么?为什么要做?有什么用?
是什么
Text-to-SQL 是一种将自然语言问题自动转换为 SQL 查询语句并执行的技术。用户无需懂 SQL,直接用中文提问,系统返回数据结果。
为什么要做
传统后台管理系统的痛点:
- 业务人员想看数据 → 必须找开发写 SQL 或加报表页面
- 开发资源有限,数据需求却是长尾的、频繁变化的
- 固定报表无法覆盖所有临时数据分析需求
Text-to-SQL 的价值:让业务人员直接提问,系统自动出数,把数据分析的门槛从"会写 SQL"降低到"会说话"。
有什么用(典型场景)
| 问题示例 | 背后的 SQL 意图 |
|---|---|
| 上周新增了多少用户? | COUNT + WHERE 时间范围 |
| 各角色的用户数量分布? | GROUP BY + JOIN |
| 最近登录失败次数最多的 IP? | ORDER BY + LIMIT |
2. 具体实现步骤
整体数据流:
sql
text
插入
复制
自然语言输入
↓
前端 POST /api/ai/text2sql
↓
后端构建 Prompt(注入表结构)
↓
调用 LLM API(OpenAI 兼容)
↓
SQL 安全校验(双重防护)
↓
执行 SQL → 推断图表类型
↓
前端动态渲染(Table / 数字卡片 / ECharts)2.1 Schema 动态注入
核心问题:LLM 不认识你的数据库,必须把表结构告诉它。
实现方式 :在每次请求时,从 MySQL 的 information_schema 动态提取当前库的表结构:
sql
sql
插入
复制
SELECT TABLE_NAME, COLUMN_NAME, COLUMN_TYPE, COLUMN_COMMENT
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = ?
AND COLUMN_NAME NOT IN ('password','token','secret','salt')
ORDER BY TABLE_NAME, ORDINAL_POSITION两个关键设计决策:
- 敏感字段在 SQL 层过滤 :
password / token / secret / salt从查询结果中直接排除。LLM 拿到的 Schema 里根本没有这些字段,从根源杜绝泄露风险。 - Redis 缓存 :表结构不会频繁变化,查出来的结果序列化为 JSON 缓存至 Redis,
Key = ai:schema,TTL = 1h,避免每次请求都查 information_schema 带来的性能损耗。
2.2 Prompt 工程
Prompt 是整个方案的"大脑接口",设计好坏直接决定 SQL 质量。
Prompt 结构:
sql
text
插入
复制
你是一个 MySQL 专家。根据以下表结构将自然语言问题转换为 SQL。
【表结构】
{schema} ← 动态注入,来自 schema_extractor.go
【约束】
1. 只生成 SELECT 语句
2. 不得查询 password、token、secret、salt 字段
3. 结果必须包含 LIMIT,最大 1000
4. 只输出 SQL,不要任何解释
【问题】{question}设计要点:
- 角色设定:明确告知 LLM 它是 MySQL 专家,而非通用助手
- 约束显式化:把安全规则写进 Prompt,形成第一道防线
- 只输出 SQL:避免 LLM 输出多余文字导致解析失败
- COLUMN_COMMENT 的价值 :表结构里带上列注释(如
create_time 创建时间),LLM 能更准确地理解业务语义,生成更精准的 SQL
2.3 SQL 安全校验
核心理念:永远不信任 LLM 的输出,程序层独立做二次验证。
Prompt 约束是"君子协定",安全校验才是"法律"。
校验逻辑(sql_validator.go) :
sql
text
插入
复制
Step 1: 解析 SQL 首个 token
→ 非 SELECT 直接返回错误,拒绝执行
Step 2: 关键字黑名单扫描
→ INSERT / UPDATE / DELETE / DROP / TRUNCATE
CREATE / ALTER / EXEC 任意出现 → 拒绝
Step 3: 敏感字段扫描
→ SQL 文本中包含 password / token / secret / salt → 拒绝
Step 4: LIMIT 检查
→ 若 LLM 漏写 LIMIT,强制注入 LIMIT 1000为什么这样设计:LLM 存在幻觉,即便 Prompt 明确约束,极端情况下仍可能生成危险 SQL。双重校验(Prompt 约束 + 程序校验)形成纵深防御。
2.4 图表类型自动推断
问题:用户不知道自己的问题适合用什么图表展示,不应该让用户选。
方案 :后端根据查询结果的结构特征自动推断,返回 chartType 字段:
| 结果特征 | chartType | 说明 |
|---|---|---|
| 1 列 + 1 行 | number |
单一聚合值,大数字卡片最直观 |
| 2 列 + 行数 ≤ 8 | pie |
类目少,饼图看占比 |
| 2 列 + 行数 > 8 | bar |
类目多,柱状图看对比 |
| 含时间列(date/time/year) | line |
时序数据,折线图看趋势 |
| 其他多列 | table |
兜底,通用表格展示 |
推断逻辑完全在后端 ,前端只需按 chartType 切换渲染组件,职责清晰。
2.5 前端动态渲染
页面三区布局:
scss
text
插入
复制
┌─────────────────────────────────────┐
│ 输入区 │
│ [文本框] [快捷问题标签] [发送] │
├─────────────────────────────────────┤
│ SQL 展示区(只读代码块) │
│ SELECT COUNT(*) AS cnt FROM ... │
├─────────────────────────────────────┤
│ 结果区(动态渲染) │
│ 根据 chartType 切换: │
│ number → 大数字卡片 │
│ bar/line/pie → ECharts 图表 │
│ table → el-table 分页 │
└─────────────────────────────────────┘SQL 展示区的意义:不隐藏生成的 SQL,用户可以看到系统"是怎么查的",增加透明度,也帮助用户学习 SQL。这是信任建立的关键设计。
技术实现:
vue-echarts封装 ECharts,响应式渲染- API 模块独立 axios 实例,超时时间 30s(LLM 响应较慢)
- 路由懒加载:
() => import('@/views/ai/TextToSQL.vue')
3. 安全设计亮点 / 系统稳定性 / 企业级 vs Demo 级
安全五层防御
| 层级 | 风险 | 防护措施 |
|---|---|---|
| 1 | LLM 生成恶意 SQL | 首 token 校验 + 关键字黑名单(程序层) |
| 2 | 泄露敏感字段 | Schema 提取时过滤 + Prompt 约束(双保险) |
| 3 | 大批量查询打垮 DB | 强制注入 LIMIT 1000 |
| 4 | 未授权访问 | JWT 中间件鉴权,接口需登录 |
| 5 | Prompt 注入攻击 | 用户输入长度限制 ≤ 500 字符 |
为什么不是 Demo 级,而是企业级?
Demo 级系统通常的问题:
| 问题 | 本方案的处理 |
|---|---|
| 直接把用户输入塞进 SQL 执行 | 中间有 LLM 隔离层 + 安全校验层 |
| 全部表结构暴露给 LLM | Schema 提取时过滤敏感字段 |
| 没有访问控制 | JWT 鉴权,权限与主系统统一 |
| 没有限流/防护 | LIMIT 强制注入,输入长度限制 |
| 每次都查 information_schema | Redis 缓存,TTL 1h |
| 图表类型写死 | 自动推断,自适应结果结构 |
| LLM 配置硬编码 | yaml 配置 + 环境变量,支持切换模型 |
稳定性设计
- Redis 缓存 Schema:避免 information_schema 查询成为瓶颈
- axios 30s 超时:LLM 响应慢时前端不会无限等待
- MaxTokens: 512:控制 LLM 输出长度,防止超长响应
- LIMIT 兜底:防止意外的全表扫描
- 模型可配置 :
gpt-4o-mini成本低,生产可按需切换更强模型
针对"无法理解的自然语言查询"如何引导用户?
这是企业级系统必须考虑的体验问题,方案中设计了快捷问题标签:
scss
text
插入
复制
前端输入区预置常用问题标签,例如:
[上周新增用户数] [各角色用户分布] [今日登录次数]用户点击标签直接填充问题,降低输入门槛,同时隐式告知用户"可以问什么类型的问题"。
其他引导策略(可扩展):
- SQL 展示区透明展示生成的 SQL → 用户理解系统能力边界
- 查询失败时返回友好提示(如"请尝试更具体的问题描述")
- 可在标签上补充领域提示(如"仅支持查询用户、角色相关数据")