🌈欢迎来到Linux专栏 ~~ 线程控制
- 🌍博客主页 :张小姐的猫~江湖背景
- 🔥所属专栏 :Linux ~ 不破不立
- 作者水平很有限,如果发现错误,可在评论区指正,感谢🙏


线程控制
- [🌈欢迎来到Linux专栏 ~~ 线程控制](#🌈欢迎来到Linux专栏 ~~ 线程控制)
- ✨线程控制接口
- [✨理解线程库及线程 ID](#✨理解线程库及线程 ID)
- ✨理解线程独立栈
- ✨线程局部存储
- 📢写在最后

✨线程控制接口
与线程有关的函数构成了⼀个完整的系列,绝大多数函数的名字都是以"pthread_"打头的
要使用这些函数库,要通过引入头文件 <pthread.h>
链接这些线程函数库时要使用编译器命令 的"-lpthread"选项
💖线程创建
对于 原生线程库 来说,创建线程 使用的是 pthread_create
cpp
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);参数1:线程 ID ,用于标识线程,其实这玩意本质上就是一个 unsigned long int 类型
cpp
typedef unsigned long int pthread_t ps:pthread_t* 表明这是一个输出型参数 ,旨在创建线程后,获取新线程 ID
参数2:const pthread_attr_t*:用于设置线程的属性 ,比如优先级、状态、私有栈大小,这个参数一般不考虑,直接传递 nullptr 使用默认设置即可
参数3: void *(*start_routine) (void *):这是一个很重要的参数,它是一个 返回值为 void* 参数也为 void* 的函数指针,线程启动时,会自动回调此函数(类似于 signal 函数中的参数2)
参数4: void*:显然,这个类型与回调函数中的参数类型匹配上了,而这正是线程运行时,传递给回调函数的参数
返回值 int:创建成功主线程返回 0,失败返回 error number
错误检查:
传统的⼀些函数是,成功返回0,失败返回-1 ,并且对全局变量
errno赋值以指示错误。
pthreads函数出错时不会设置全局变量errno(⽽⼤部分其他POSIX函数会这样做)。而是将错误代码通过返回值返回。对于pthreads函数的错误,建议通过返回值来判定,因为读取返回值要比读取线程内的errno变量的开销更小
cpp
void* Routine(void * args)
{
std::string name = static_cast<const char*>(args);
while(true)
{
std::cout << "我是新线程..." << name << std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, Routine, (void*)"thread - 1");
(void)n;
printf("新线程id: 0x%lx\n", &tid);
while(true)
{
std::cout << "我是主线程...." << std::endl;
sleep(1);
}
return 0;
}细节1️⃣:创建新线程成功,主线程拿到的新线程ID是什么?
- 并不是
LWD,而是一个地址 (十六进制数)------------ 具体是什么后续再讲
那么怎么保证打印出来的数是新线程的ID呢? ------ 引出一个新函数:pthread_self
✅获取线程ID
线程 ID 是线程的唯一标识符,可以通过 pthread_self 获取当前线程的 ID(有点类似getpid 哈哈)
cpp
#include <pthread.h>
pthread_t pthread_self(void);返回值:当前线程的 ID
cpp
printf("我是新线程: %s, tid: 0x%lx, \n", name.c_str(), pthread_self());跑出的结果是相等的!也就说主线程也能拿到新线程的id,方便对其做管理! 
程序运行时,主次线程的运行顺序?
线程的调度机制源于进程 ,而多进程运行时,谁先运行取决于调度器,因此主次线程运行的先后顺序不定,具体取决于调度器的调度

✅如何创建多线程呢??
展示!
cpp
//因为线程资源共享 ------代码共享
void PrintName(const std::string & name)
{
printf("我是新线程: %s, tid: 0x%lx, pid: %d\n", name.c_str(), pthread_self(), getpid());
}
//调度器多个执行流同时进入Routine ------ 说明函数被重入了(只是进入函数的先后顺序不同)
void *Routine(void *args)
{
std::string name = static_cast<const char *>(args);
printf("--------------------------------------------------\n");
while (true)
{
// std::cout << "我是新线程..." << name << std::endl;
PrintName(name);
sleep(1);
}
}
int main()
{
// 创建多线程
const int sum = 10;
for (int i = 0; i < sum; i++)
{
pthread_t tid;
// 构建线程名字?
char threadname[64]; //栈
snprintf(threadname, sizeof(threadname), "thread - %d", i + 1);//向threadname中写入
int n = pthread_create(&tid, nullptr, Routine, threadname);
(void)n;
sleep(1);
}
while (1)
{
printf("我是主线程 tid: 0x%lx, pid: %d\n", pthread_self(), getpid());
sleep(1);
}
return 0;
}创建的多个线程都执行Routine函数,不就是多个执行流同时进入Routine ------ 函数被重入了 (只是进入函数的先后顺序不同,到最后都是同时执行的)。
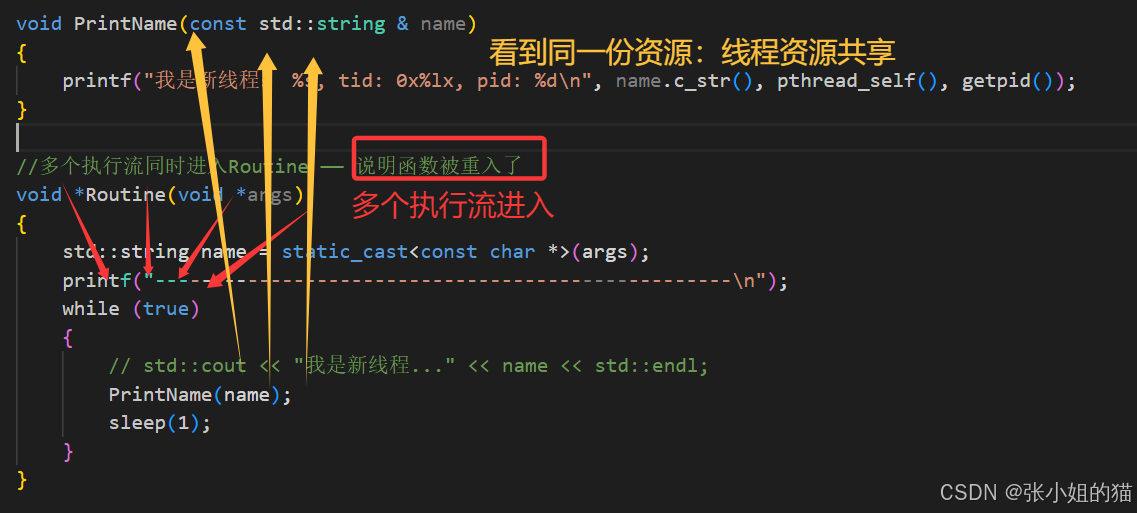
并且多个执行流都能看见同一份资源:线程大部分资源是共享的!
运行结果,我们发现打印出来的值好像是随机的?!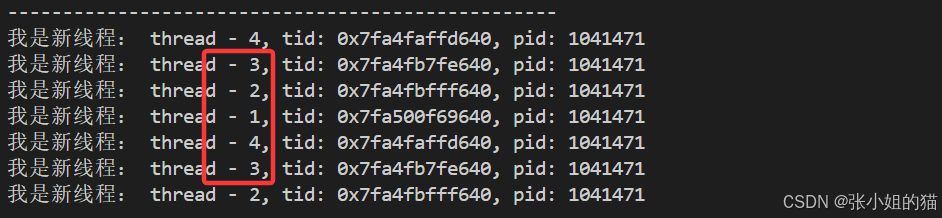
但是此处藏着一个致命 BUG
因为 threadname 是循环内的栈变量 (临时空间),退出循环体就销毁了:
- 主线程创建线程后,循环结束 →
threadname内存被回收 - 子线程如果刚要读取这个名字 → 访问的是已经销毁的野指针!
结果:线程名字打印乱码、程序崩溃 ,本质上是野指针的问题
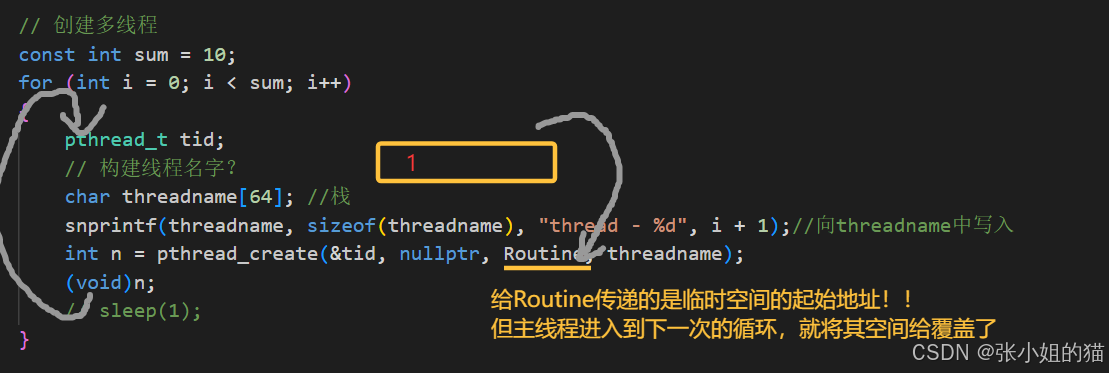
为了解决这个问题:只要把在堆区 建立一个变量name即可
cpp
char* threadname = new char[64];堆空间不会自动销毁 ,子线程拿到指针,任何时候访问都合法;用 new 后,不会出现10 个线程访问同一个资源吗,因为每次循环都是new出来一块新的堆内存
记住:new 要配对释放,堆内存不会自动回收,子线程用完要释放Delete,避免内存泄漏:
 哪个线程先执行,都是看调度器怎么样调度~
哪个线程先执行,都是看调度器怎么样调度~
✅关于传参问题
cpp
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);我们可以看见后两个参数的类型都是void*,void* :任意类型
传整数、字符甚至类和结构体对象的地址 (打破思维惯性)------------ 那么不就可以给线程传递任务了吗??
cpp
void *Routine(void *args)
{
//所以要用结构体指针,此处还需强转回来
Task* t = static_cast<Task*> (args);
t->Excute();
std::cout << t->Result() << std::endl;
sleep(2);
return nullptr;
}
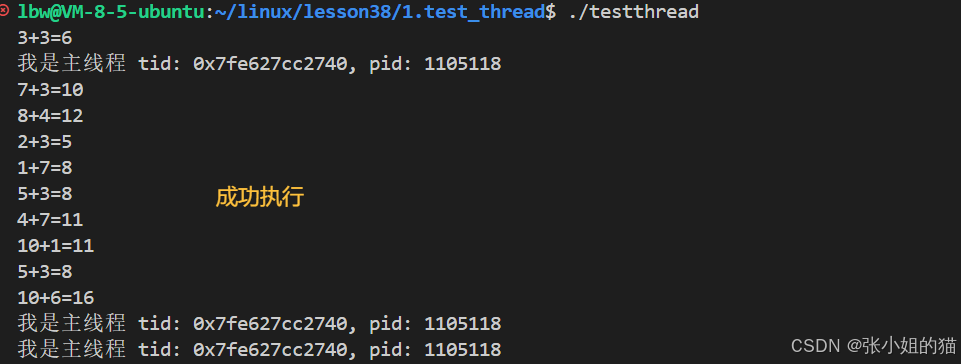
int main()
{
// 创建多线程
srand(time(nullptr) ^ getpid());
const int sum = 10;
for (int i = 0; i < sum; i++)
{
pthread_t tid;
int x = rand() % 10 + 1;
usleep(66);
int y = rand() % 7 + 1;
Task *t = new Task(x, y); //new在堆里
int n = pthread_create(&tid, nullptr, Routine, t);
(void)n;
// sleep(1);
}
return 0;
}小细节:
1、创建一个Task结构体对象,返回指向它的指针:Task*
2、因为函数限制只能传 1 个 void* 指针,索性传一个结构体指针 ,但编译器自动隐式转换 :Task* → void*
3、线程函数接收的是 void*,这个 args 里存的就是刚才 Task对象的地址,编译器不知道它指向Task,所以必须手动强转回Task*,才好访问x、y对象
✅返回值问题 void*
既然传参是可以传自定义类型,那么返回值为什么不行呢??
cpp
class Res
{
public:
int code;
std::string name;
std::string info;
};
void* Routine(void* args)
{
std::string name = static_cast<const char*>(args);
while(true)
{
std::cout << "我是新线程:" << name << std::endl;
sleep(5);
break;
}
Res *res = new Res(); //堆空间
res->code = 10;
res->name = name;
res->info = "我这个线程已经完蛋了";
return (void*)res;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, Routine, (void*) "thread - 1");
Res* retval = nullptr;
int n = pthread_join(tid, (void**)&retval);
if(n == 0)
{
std::cout << "等待成功" << retval->code << std::endl;
std::cout << "等待成功" << retval->info << std::endl;
std::cout << "等待成功" << retval->name << std::endl;
}
return 0;
}
🤏线程等待
新线程必须被主线程等待
- 类似于进程那的僵尸问题 (必须的)
- 主线程要获取新线程的执行结果(不是必须的,顺便知道你执行的怎么样了)
pthread_join,用于等待次线程运行结束,如果新线程不终止、不死,就只能阻塞等待了
cpp
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);参数1 :pthread_t:待等待的线程 ID,本质上就是一个无符号长整型类型;这里传递是数值,并非地址
参数2 :void**:这是一个输出型参数 ,用于获取新线程的退出的返回值 (void* routine(void *)),如果不关心,可以传递 nullptr
- 为什么是
void**呢? 因为其返回值是void*,要获取void*的内容就要用void**来获取!( 获取int内容,就需要用int*来获取)
返回值 :成功返回 0,失败返回 error number~ 错误码
调用该函数的线程将挂起等待,直到id为thread的线程终止 。thread线程以不同的方法终止,通过pthread_join得到的终止状态是不同的,总结如下:
- 如果thread线程通过
return返回 ,value_ptr所指向的单元里存放的是thread线程函数的返回值 - 如果thread线程被别的线程调用
pthread_cancel异常终掉,value_ptr所指向的单元⾥存放的是常数PTHREAD_CANCELED(-1) - 如果thread线程是直接调用pthread_exit终止的 ,value_ptr所指向的单元存放的是传给pthread_exit的参数
- 如果对thread线程的终止状态不感兴趣,可以传
NULL给value_ptr参数
cpp
void* Routine(void* args)
{
std::string name = static_cast<const char*>(args);
while(true)
{
std::cout << "我是新线程:" << name << std::endl;
sleep(5);
break;
}
return (void*)10;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, Routine, (void*) "thread - 1");
//1.主线程创建新线程,必须等待新线程退出 ,否则出现僵尸进程问题
//2.为了获取新线程执行的结果
void* retval = nullptr;
int n = pthread_join(tid, &retval);
if(n == 0)
{
std::cout << "等待成功" << (long long)retval << std::endl;
}
return 0;
}
✅线程退出后:
- 线程的执行流没了
- 但 PCB / 内核线程描述符 ,和
pthread用户态控制信息 仍可能保留
此时线程进入:"joinable terminated",类似:僵尸线程 等待回收 - 证明:新线程退出后5秒后,再进程等待,仍可以获取到退出码!!
❓退出信息是怎么保存的?怎么样拿到的呢??
现在客观上已经拿到退出信息了:10,这是咋拿到的呢??
底层最后*ret就是会拿到10,也就说*ret 就是 *retval,retval未来准备存:线程退出值 ;pthread_join最终会拿到退出值:*ret = void *,也就是retval最后会拿得到10
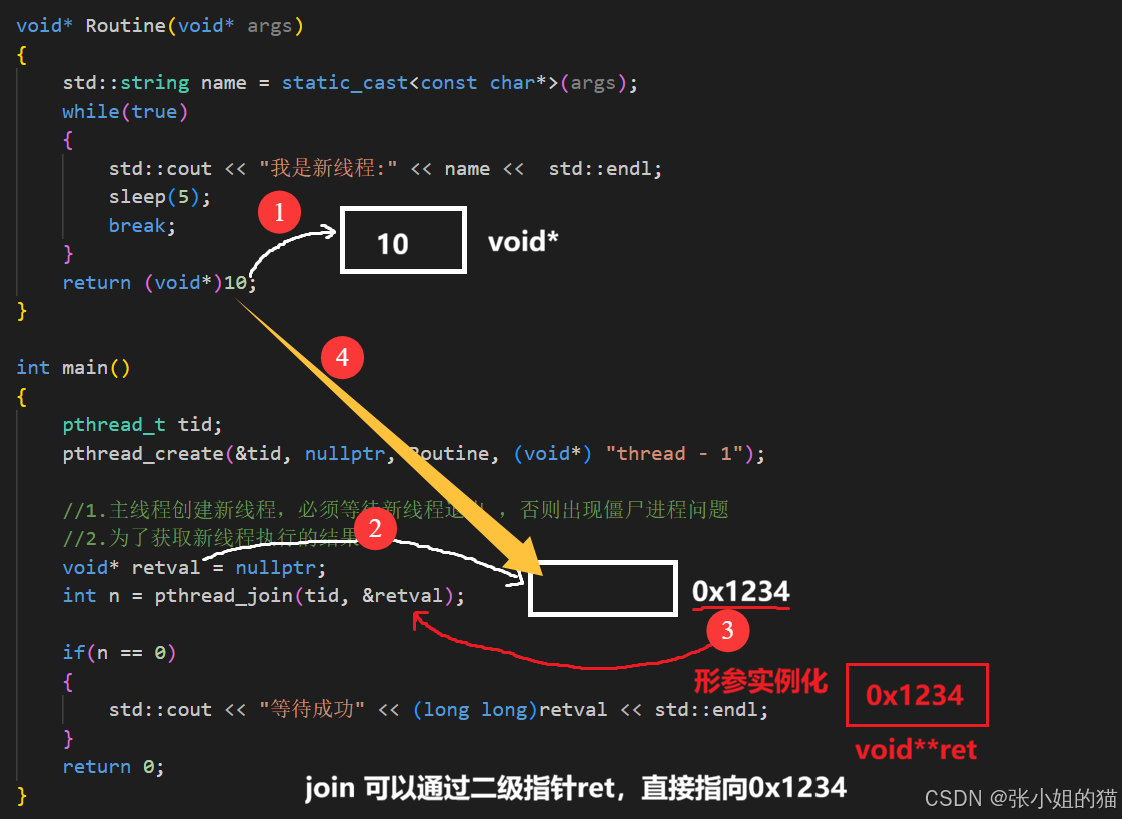
所以说最后pthread_join是可以获取到新线程的退出数字的!!
新线程出异常了,进程全部都会退出,根本没有机会join成功!所以不需要关心异常!
所以进程等待只关心正常情况:看退出码 判断执行结果就可以!
❌线程终止
如果需要只终止某个线程而不终止整个进程,可以有三种方法:
- 💥从线程函数
return。这种方法对主线程不适用 ,从main函数return相当于调用exit。 - 💥线程可以调用
pthread_exit终止自己。 - ⼀个线程可以调用
pthread_cancel终止同⼀进程中的另⼀个线程 ------ 不推荐
ps:前两种是最佳实践
1️⃣原生线程库 中有专门终止线程运行的接口 pthread_exit,专门用来细粒度地终止线程,谁调用就终止谁,不会误伤其他线程 ------ 立刻终止调用它的这个线程
cpp
#include <pthread.h>
void pthread_exit(void *retval);仅有一个参数 void*:用于传递 线程退出返回值 ,可以给 pthread_join 接收
主线程用此函数:也是自己退出,保子线程继续运行
和最熟悉的 exit() 天差地别

2️⃣pthread_cancel:其他线程,主动「发送取消请求」杀死指定的目标线程
cpp
int pthread_cancel(pthread_t thread);thread:要取消的线程 tid
返回值:0 表示成功发送取消请求
cpp
std::vector<pthread_t> tids;
for(auto &tid : tids)
{
pthread_cancel(tid); // 给每个子线程发取消请求
}那么是不是就可以在新线程里干掉主线程呢?? ~ 一段伪代码
cpp
void *Routine(void *args)
{
int n = pthread_cancel(mainid);
std::cout << "n - >" << n << std::endl;
}
int main()
{
mainid = pthread_self();
}操作成功了,但是并没有杀掉,主线程暂停执行了~
- 只有主线程能杀新线程,新线程不得造反!!
💖分离线程
父进程需要阻塞式等待子进程退出,主线程等该次线程时也是阻塞式等待,父进程可以设置为 WNOHANG,变成轮询式等待,避免自己一直处于阻塞;
如果不关心线程的返回值,join是⼀种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源
线程在被创建时,默认属性都是
joinable的,即主线程需要使用pthread_join来等待次线程退出,并对其进行资源释放;实际上我们可以把这一操作留给系统自动处理,如此一来主线程就可以不必等待次线程,也就可以避免等待时阻塞了,这一操作叫做 线程分离
原生线程库 提供的线程分离接口是 pthread_detach
cpp
#include <pthread.h>
int pthread_detach(pthread_t thread);参数1: pthread_t ------ 待分离的线程 ID
返回值:成功返回 0,失败返回 error number
线程分离的本质是将 joinable 属性修改为 detach,告诉系统线程退出后资源自动释放
注意: 如果线程失去了
joinable属性,就无法被 join,如果 join 就会报错
🏆最佳实践:一旦线程要被设置为分离,主线程不能提前退出,甚至主线程是死循环!
- 我是把你分离出去了,但是你(主线程)必须"死"在我后面哈哈
- 分离只是在功能上、逻辑上表示的一种状态,仅仅表示主线程不用等待新线程,但其他特性依旧存在(一起挂)
- 真正的分家是:
fork创建子进程
下面简单使用一下线程分离:
cpp
void* Routine(void* args)
{
//我自己申请分离
pthread_detach(pthread_self());
int cnt = 5;
while(cnt)
{
std::cout << "新线程在运行: " << cnt-- << std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
Task t(10, 20);
pthread_t tid;
pthread_create(&tid, nullptr, Routine, (void*) &t);
sleep(1);
void *ret = nullptr;
int n = pthread_join(tid, &ret);
if(n == 0)
{
std::cout << "等待成功" << (long long) ret << std::endl;
}
else{
std::cout << "等待失败" << std::endl;
}
return 0;
} 那么如果分离出去的线程出现:除0,野指针等,会发生什么??
那么如果分离出去的线程出现:除0,野指针等,会发生什么??

也就说明了分离出去的线程和其他线程仍然属于一个地址空间 ,分离线程出问题依然会连累到其他线程和主进程的
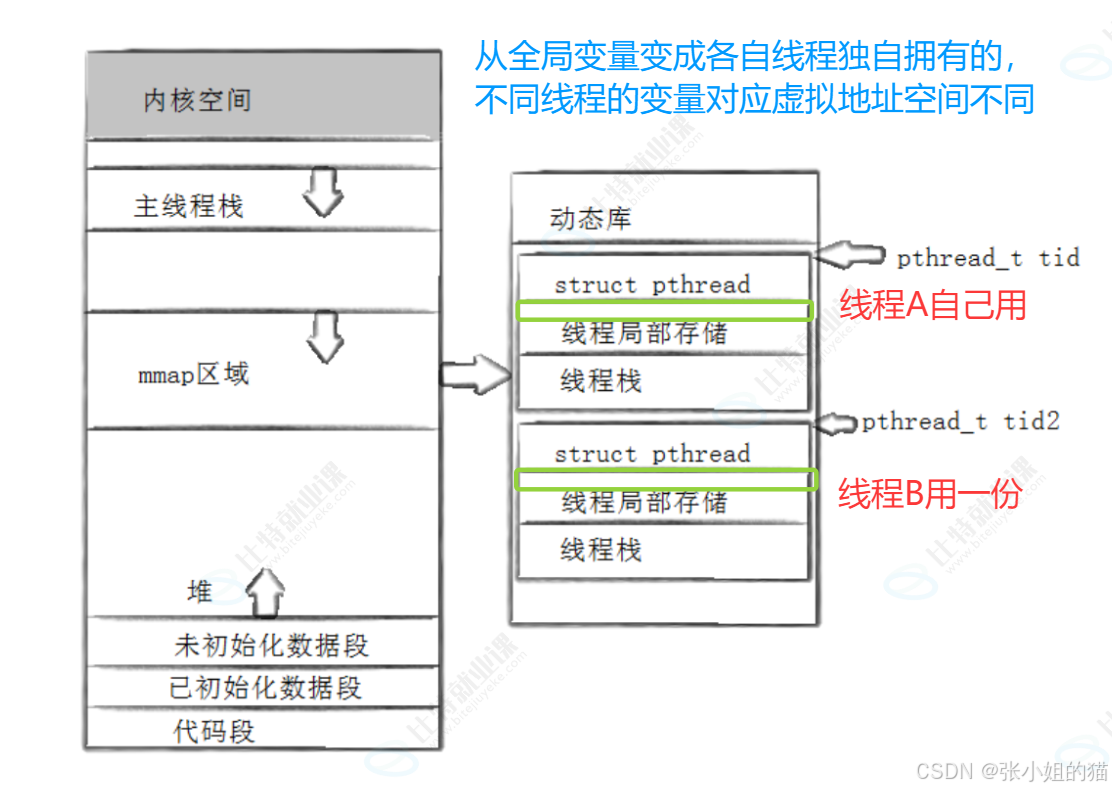
✨理解线程库及线程 ID
在见识过 原生线程库 提供的一批便利接口后,如此强大的库究竟是如何工作的呢?
原生线程库本质上也是一个文件,是一个存储在 /lib64 目录下的动态库,要想使用这个库,就得在编译时带上 -lpthread 指明使用动态库
程序运行时,原生线程库 需要从 磁盘 加载至 内存 中,再通过 进程地址空间 映射至 共享区 中供线程使用
1️⃣pthread库也是库,要被映射到当前进程的虚拟地址空间以支持线程控制 。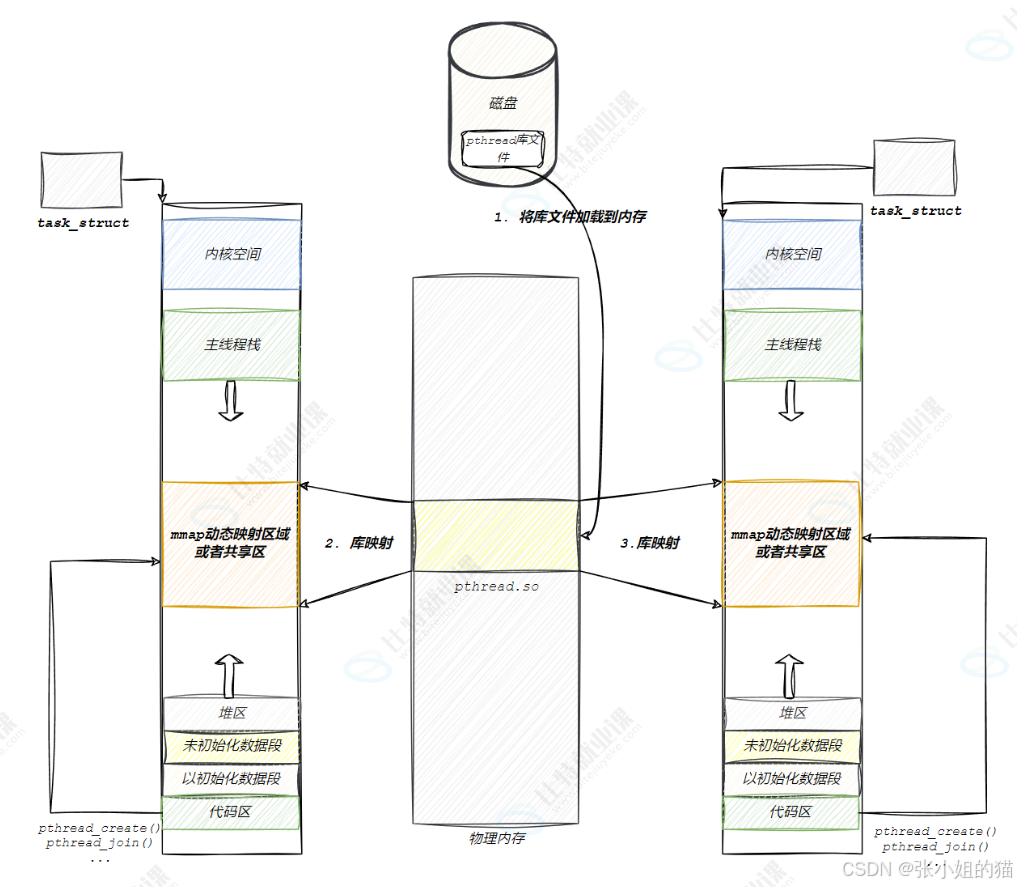
2️⃣线程id是一个地址!! ,是给线程在动态库中申请一块空间(struct_pthread、线程局部存储)的起始地址
3️⃣对于原生线程库 来说,线程不止一个 ,因此遵循 先描述,再组织 原则进行管理!在线程库中创建 TCB 结构(类似于 PCB),其中存储线程的各种信息 ,比如线程独立栈信息
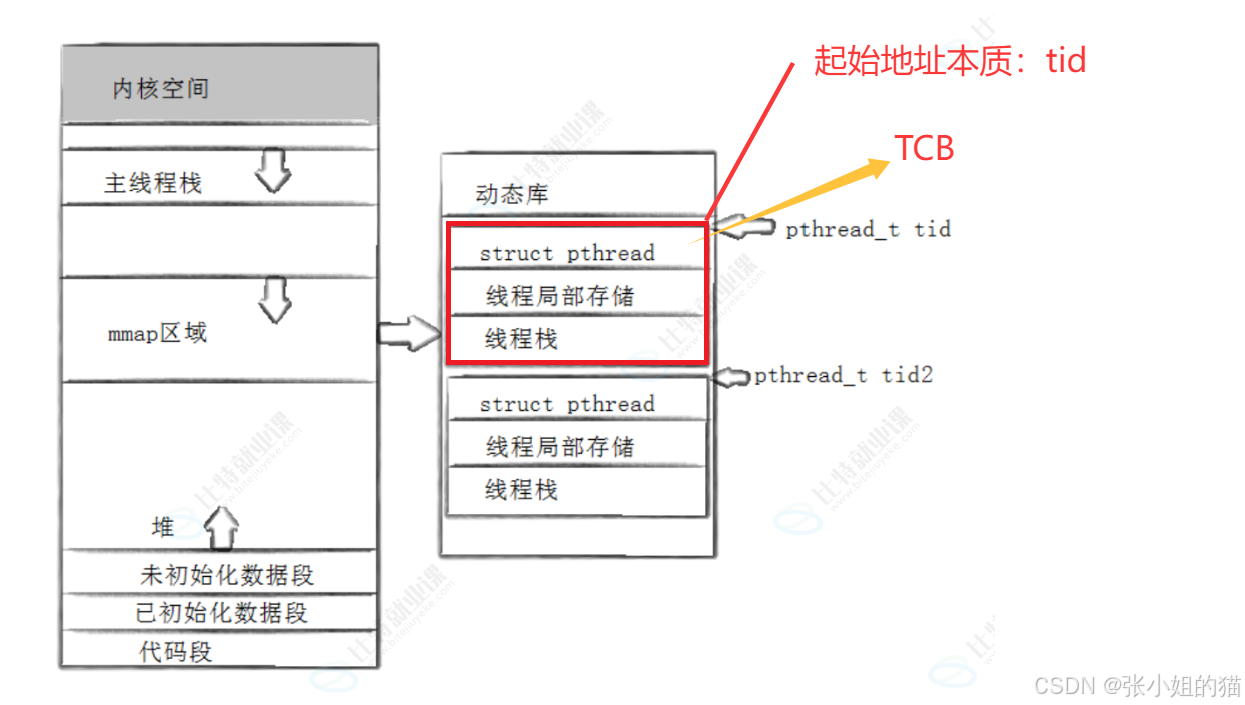
如果A进程有10个TCB,B有20个TCB,全部的TCB都在库里管理!只要拿对应的虚拟地址去找即可
眼见为实!
📕看看源码
当我们在调用pthread_create函数时,整个代码会自动调用 ~ 申请空间都是在库里面完成的。
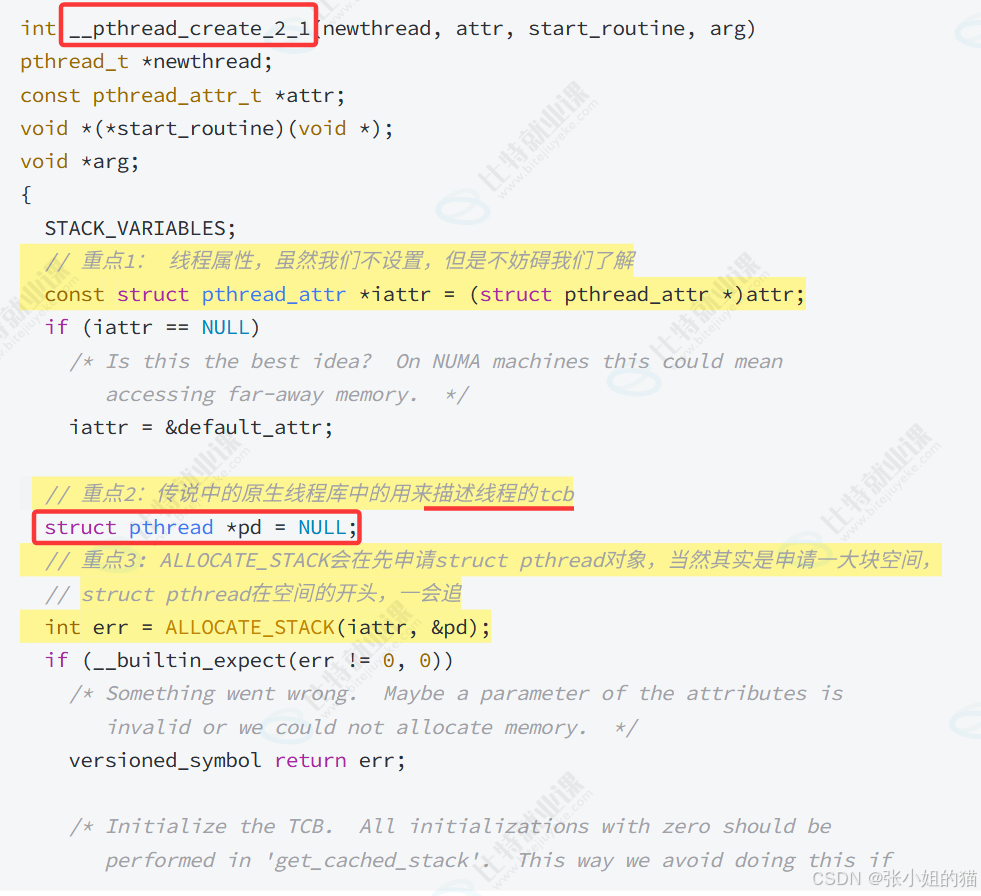

接着看TCB结构体~

今天开始,虚拟地址空间的栈叫做主线程栈,只有主线程在用 ,新线程的栈在库里面动态申请,所以每个线程都有自己的线程级库
- 主线程栈是由进程自动申请的,新线程栈是由用户申请的,是由用户所提供!!
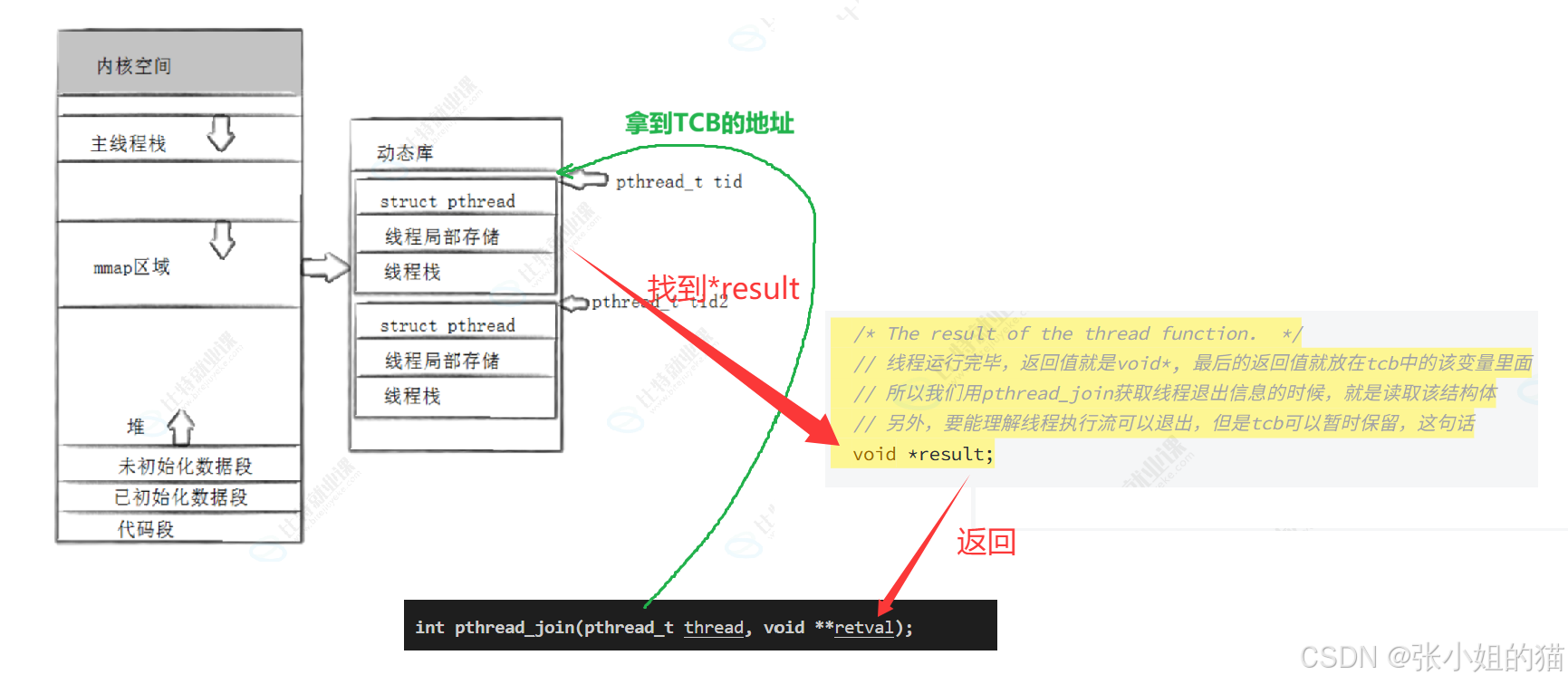
上述拿到了TCB的起始地址,在TCB里找到*result 返回给retval
也应该秒懂:线程运行结束后,返回结果 void*是会被写到线程控制块的*result 里
最后我们知道
pthread_create的底层是调用clone,clone 会:创建新的task_struct。说明
struct pthread:struct task_struct = 1:1 是一比一式的用户级线程!!
task_struct维护:调度、优先级、切换、状态,整个调度的相关参数!!struct pthread:包括线程是否分离、栈大小、其实栈空间等等用户所关心的线程属性
struct pthread在库里就是一个摆设,线程一旦被创建好了,真正被调度的是task_struct ,运行完的结果设置到pthread里,最后返回到上层(用库函数让用户读到)
在标准库里一次性把一大批空间(TCB)申请完,在TCB里的核心struct pthread会记录下线程栈的起始地址与大小 ------ 也就说要申请时算出struct pthread、线程局部存储、线程栈的大小,最后申请一大块空间。
🌍小细节:为什么线程退出了,还需要用pthread_join去回收对应的 "僵尸线程"
- 因为设计的是1:1的用户级线程 !!线程退出了说明内核的
task_struct已经被释放了,轻量级进程已经消失了,甚至把退出信息写到了线程控制块(TCB)里。所以在系统中当然是查不到对应的线程的。 - 但是在库中
TCB依旧存在,pthread_join之后把对应的退出信息获取了后,TCB才会最终被释放
- 所以此处用回收僵尸线程也不恰当的,因为它线程已经回收,只是在库内有内存没有被回收 ------ 导致了内存泄露!
✨理解线程独立栈
线程 之间存在 独立栈,可以保证彼此之前执行任务时不会相互干扰,可以通过代码证明
多个线程使用同一个入口函数,并打印其中临时变量的地址
cpp
#include <iostream>
#include <string>
#include <unistd.h>
#include <pthread.h>
using namespace std;
//打印出16进制的初始地址
string toHex(pthread_t t)
{
char id[64];
snprintf(id, sizeof(id), "0x%x", t);
return id;
}
void *threadRun(void *arg)
{
int tmp = 0;
cout << "thread " << toHex(pthread_self()) << " &tmp: " << &tmp << endl;
return (void*)0;
}
int main()
{
pthread_t t[5];
for(int i = 0; i < 5; i++)
{
pthread_create(t + i, nullptr, threadRun, nullptr);
sleep(1);
}
for(int i = 0; i < 5; i++)
pthread_join(t[i], nullptr);
return 0;
}观察每个线程打印出的 &tmp 地址是否相同
cpp
thread 0x7f9e1b7f8700 &tmp: 0x7f9e1b7f7edc
thread 0x7f9e1aff7700 &tmp: 0x7f9e1aff6edc
thread 0x7f9e1a7f6700 &tmp: 0x7f9e1a7f5edc
thread 0x7f9e19ff5700 &tmp: 0x7f9e19ff4edc
thread 0x7f9e197f4700 &tmp: 0x7f9e197f3edc存在这么多 栈结构,CPU 在运行时是如何区分的呢?
答案是通过栈顶指针 ebp 和 栈底指针 esp 进行切换,ebp 和 esp 是 CPU 中两个非常重要的 寄存器 ,即便是程序启动,也需要借助这两个寄存器 为 main 函数开辟对应的 栈区
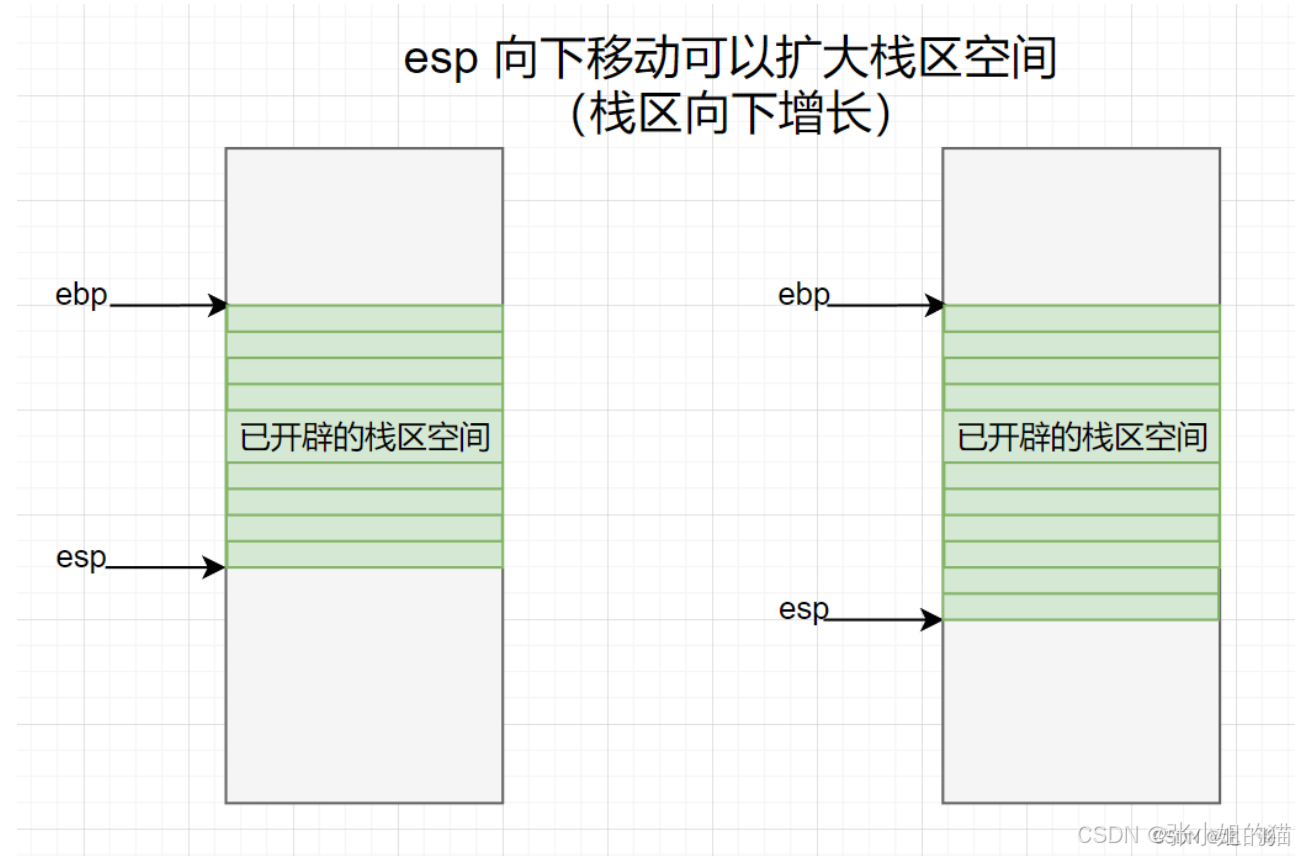
除了移动 esp 扩大栈区外,还可以同时移动 ebp 和 esp 更改当前所处栈区
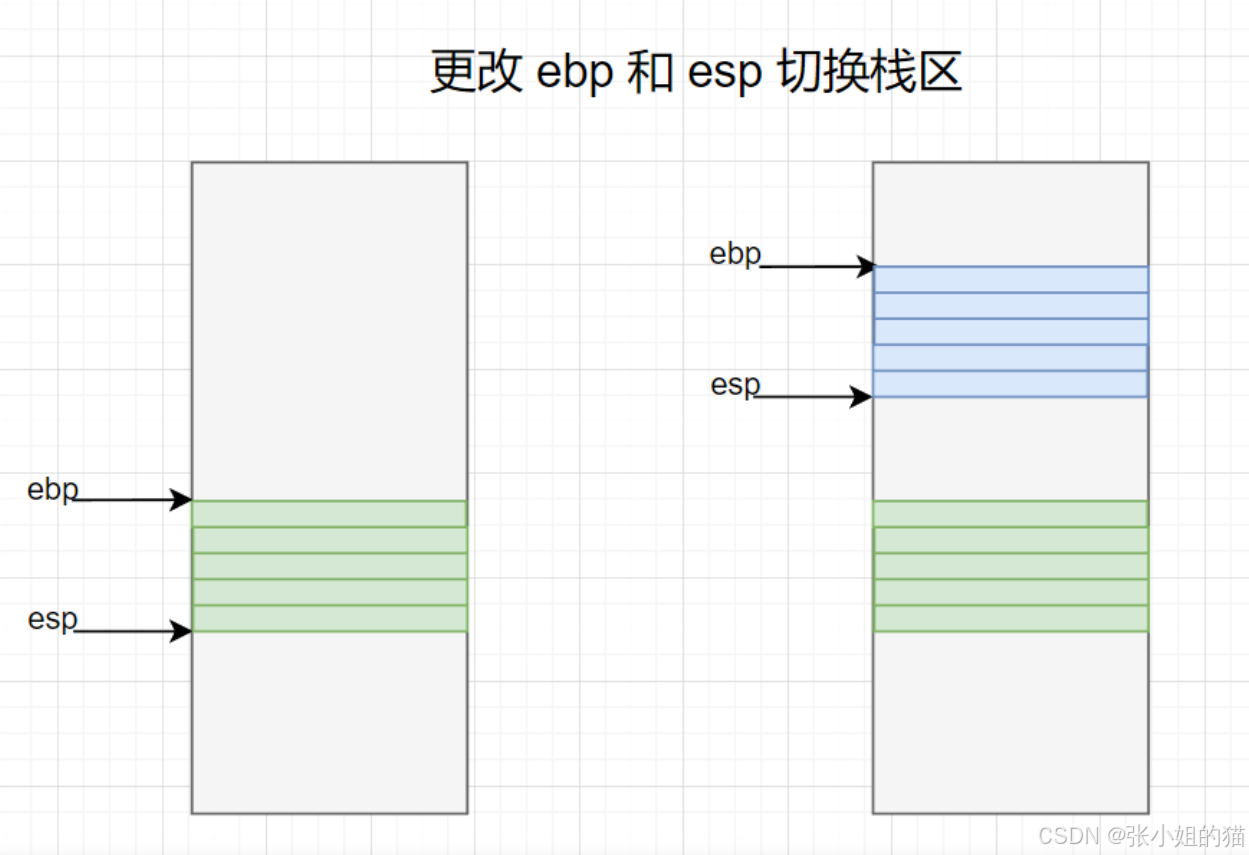
所以,多线程中 独立栈 可以通过 ebp 和 esp 轻松切换并使用 ------ 线程暂停/恢复时,esp/ebp 就随着上下文一起被保存和恢复,从而透明地切换栈。
如果想要在栈区中开辟整型空间 ,可以使用 ebp - 4 定位对应的空间区域并使用,其他类型也是如此,原理都是 基地址 + 偏移量
-
所有线程都要有自己独立的栈结构(独立栈),主线程中用的是进程系统栈,次线程用的是库中提供的栈
-
多个线程调用同一个入口函数(回调方法),其中的局部变量地址一定不一样,因为存储在线程独立栈中
✨线程局部存储
线程之间共享全局变量 ,对 全局变量 进行操作时,会影响其他线程
如何让全局变量私有化呢?即每个线程看到的全局变量不同
可以给全局变量加 __thread 修饰,修饰之后,全局变量不再存储至全局数据区,而且存储至线程的 局部存储区中
- 两个线程都想用同一个全局变量,但是想分开用(互不干扰)
- 主要的应用场景:新老线程各自保存自己的
LWP,定义一个全局变量,各自都局部存储即可
cpp
//线程局部存储
__thread pid_t id = 0;
void *Routine(void *args)
{
std::string name = static_cast<const char *>(args);
while (true)
{
std::cout << "new thread id :" << id << std::endl;
id++;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, Routine, (void *)"thread - 1");
while (true)
{
std::cout << "mian thread id :" << id << std::endl;
sleep(1);
}
pthread_join(tid, nullptr);
return 0;
}

- 只能用来局部存储内置类型,常见的是整形!
- 可以让不同的线程用同样的变量名,访问不同的内存块,各自访问自己的局部存储!
C++也有多线程!并且是具有跨平台性的
因为C++多线程操作是对pthread库的封装,才可跨平台
- 底层会区分出在什么操作平台下,调用对应的接口
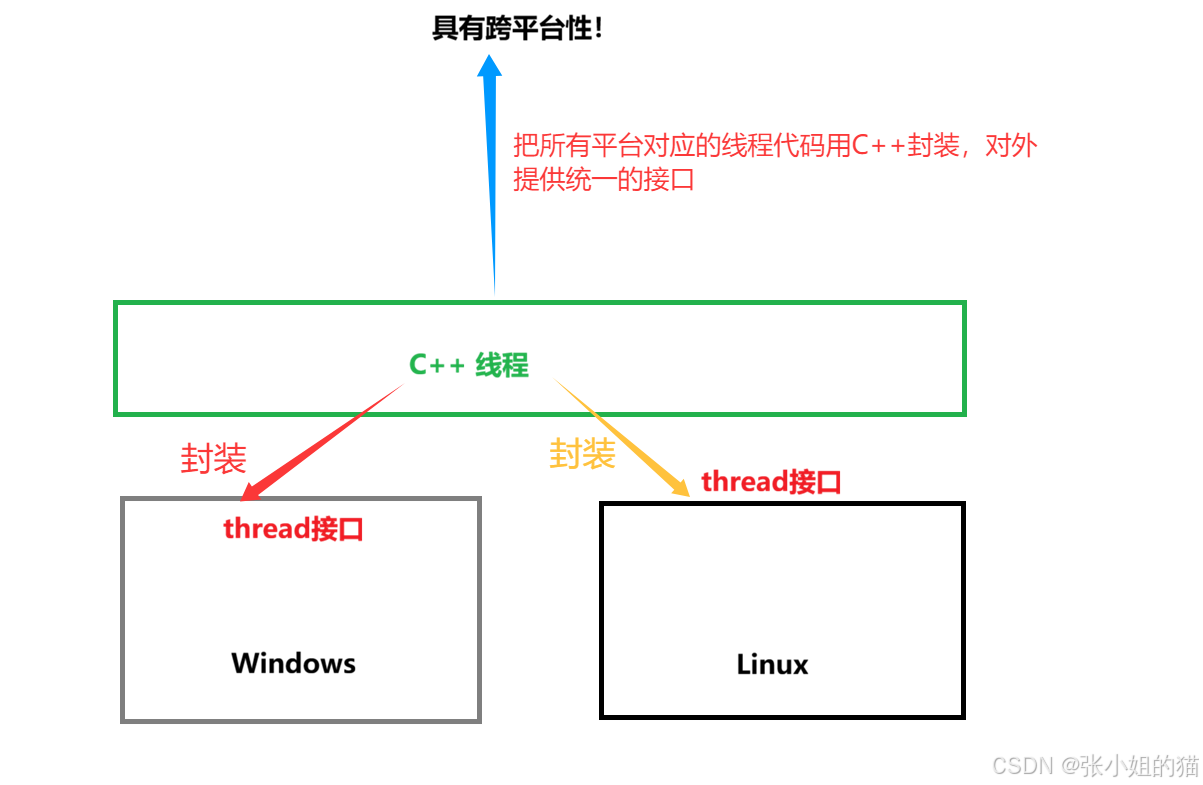
为什么C++新特性支持通常会以年为单位?
- 从技术角度,要把所有平台对应的功能全部封装一遍!
为什么所以语言都追求跨平台性?
- 占有更多的市场份额 ------ 吸引更多的用户!
📢写在最后
接下来是线程封装 ------ 冲冲冲🚀
