面试高频算法专题|通俗讲清原理、训练方法、常见类型、优缺点与高分答法
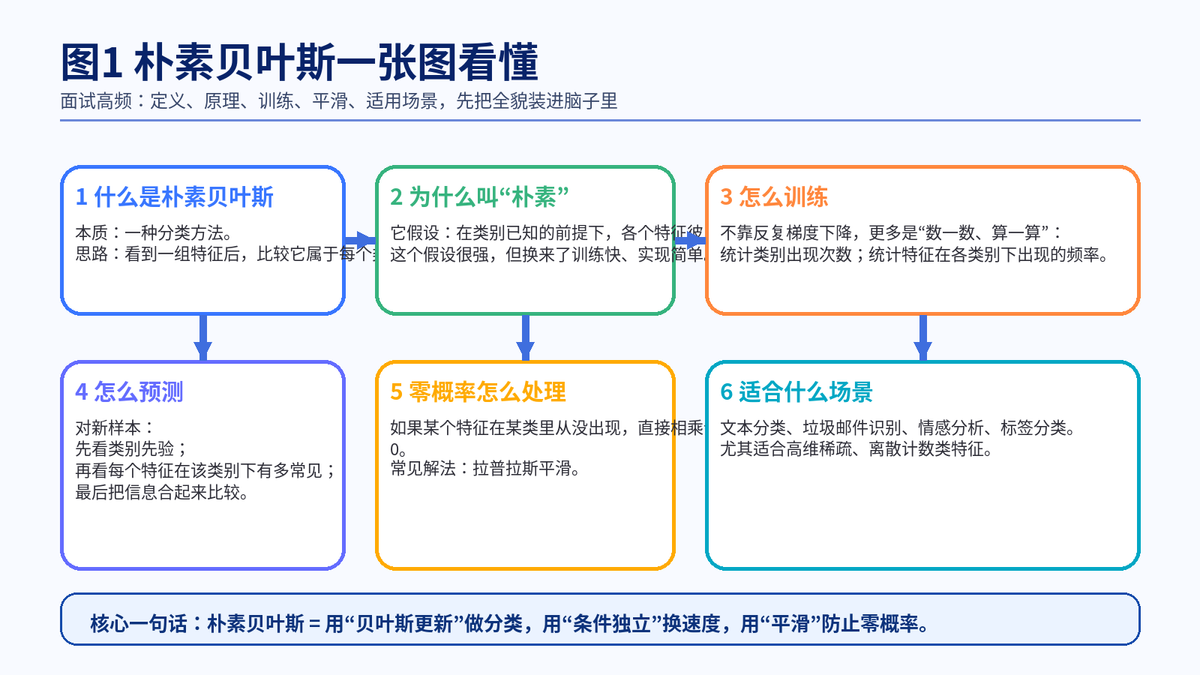
很多人第一次听到"朴素贝叶斯",会觉得名字字很玄。其实它的核心并不复杂:它是一种经典分类方法,用贝叶斯定理去估计"一个样本更像哪一类",再把样本分到概率最大的类别里。
它之所以常年出现在面试里,不是因为它最花哨,而是因为它把机器学习里几个非常重要的思想压缩在了一起:概率思维、条件独立假设、统计式训练、平滑处理,以及模型选择。把它理解透,很多分类模型的思维方式你都会顺手打开。
1. 为什么朴素贝叶斯总是面试高频题
1.1 它是"又老又能打"的经典分类器
朴素贝叶斯不属于那种参数特别多、结构特别深的模型,但它有一个非常大的优点:简单、快、轻。特别是在文本分类、垃圾邮件过滤、情感分析、标签归类这类高维稀疏问题里,它经常能用很低的成本做出一个不错的基线模型。
1.2 面试官真正想听的,不只是定义
面试官通常不是只想听你背一句"它基于贝叶斯定理"。他们更想判断你是否真的理解这五件事:
它为什么主要用于分类,而不是回归。
为什么名字里有"朴素"两个字。
训练时到底在"学"什么。
为什么会出现零概率问题,以及怎么解决。
什么时候适合用它,什么时候不适合。
2. 什么是朴素贝叶斯
2.1 一句话定义
朴素贝叶斯是一类基于贝叶斯定理的概率分类模型。它会对每个候选类别计算一个"后验概率",然后把样本分到后验概率最大的那个类别。
2.2 它主要做的是分类,不是回归
原因很简单:它天生擅长回答的是"这条样本更像 A 类,还是更像 B 类",本质是比较类别概率大小。而回归问题要预测的是一个连续数值,比如房价、时长、销量,这不是朴素贝叶斯最自然的输出形式。
2.3 朴素贝叶斯到底在做什么
你可以把它想成一个"概率裁判"。来了一个新样本后,它会分别站在每个类别的立场上去看:如果这个样本真的属于这个类别,那么它现在表现出来的这些特征,合理不合理?最后,哪个类别看起来更合理,就判给哪个类别。
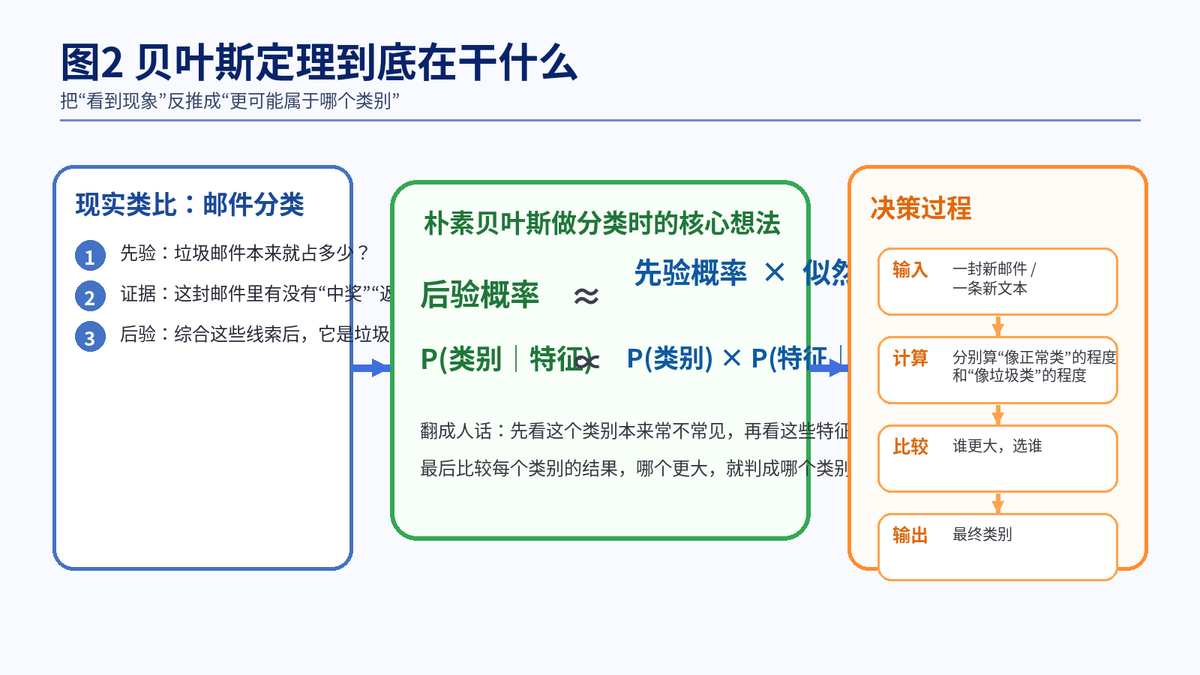
3. 贝叶斯定理在机器学习中是怎么用的
3.1 先验、似然、后验,分别是什么意思
先验概率,可以理解为"在看数据之前,这个类别本来就有多常见";似然,可以理解为"如果样本真的属于这个类别,那么现在这些特征出现得合不合理";后验概率,就是"看完这些特征之后,这个样本属于该类别的概率"。
3.2 朴素贝叶斯的核心公式,记住这一条就够了
在面试里,不需要把复杂公式铺一屏。记住一句最关键的话就足够:后验概率 ≈ 先验概率 × 似然。翻成人话,就是"先看类别本身常不常见,再看这些特征在该类别下常不常见"。
3.3 为什么最后只比较大小就行
因为分类任务关心的不是把概率写得多漂亮,而是哪个类别更大。对于同一个样本来说,很多公共项对所有类别都一样,所以预测时通常直接比较各类别的相对大小即可。
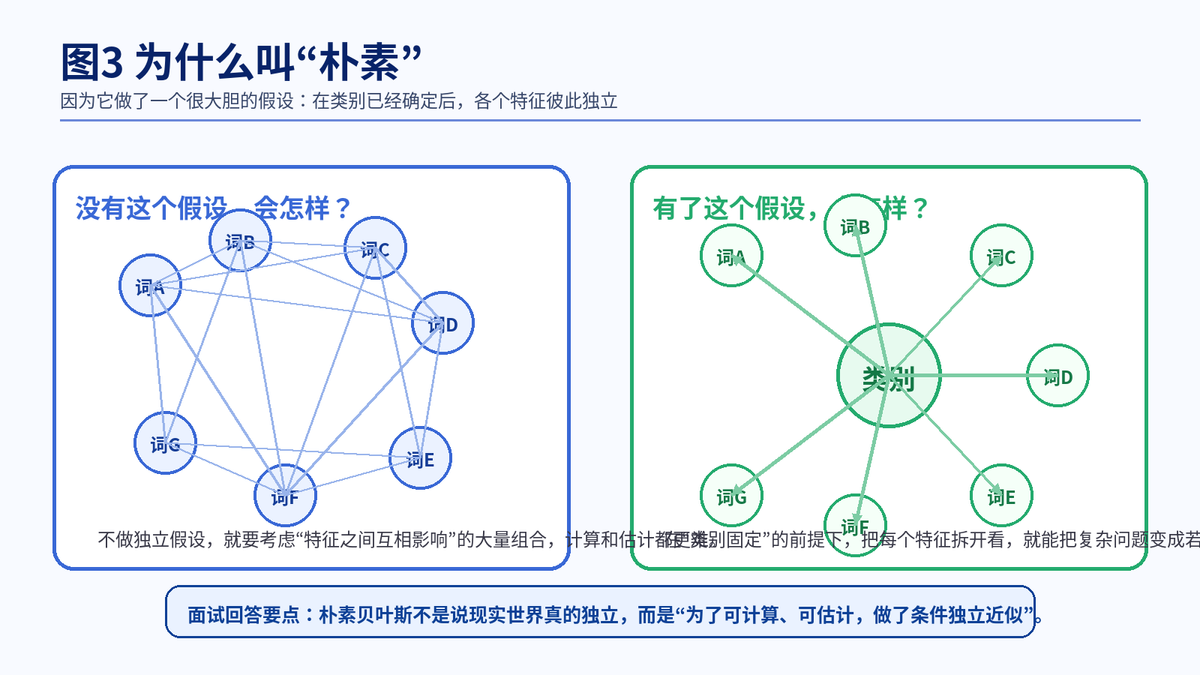
4. 为什么它叫'朴素'贝叶斯
4.1 '朴素'指的不是模型低级,而是假设大胆
这里的"朴素",不是说它很笨,而是说它做了一个很强的近似:在类别已经确定的前提下,样本的各个特征彼此独立。
4.2 为什么这个假设这么重要
如果不做这个假设,模型就必须同时考虑'特征和特征之间互相影响'的各种组合,估计起来会非常难。做了条件独立假设后,原来复杂的联合问题,就能被拆成很多个简单的小概率去分别统计。
4.3 这个假设明明不完全真实,为什么模型还能用
因为机器学习里很多模型都不是在追求对现实的百分百还原,而是在追求'用足够简单的假设,换取足够好的效果'。朴素贝叶斯正是这种思想的代表:假设未必完美,但在很多实际任务里已经够用,甚至很好用。
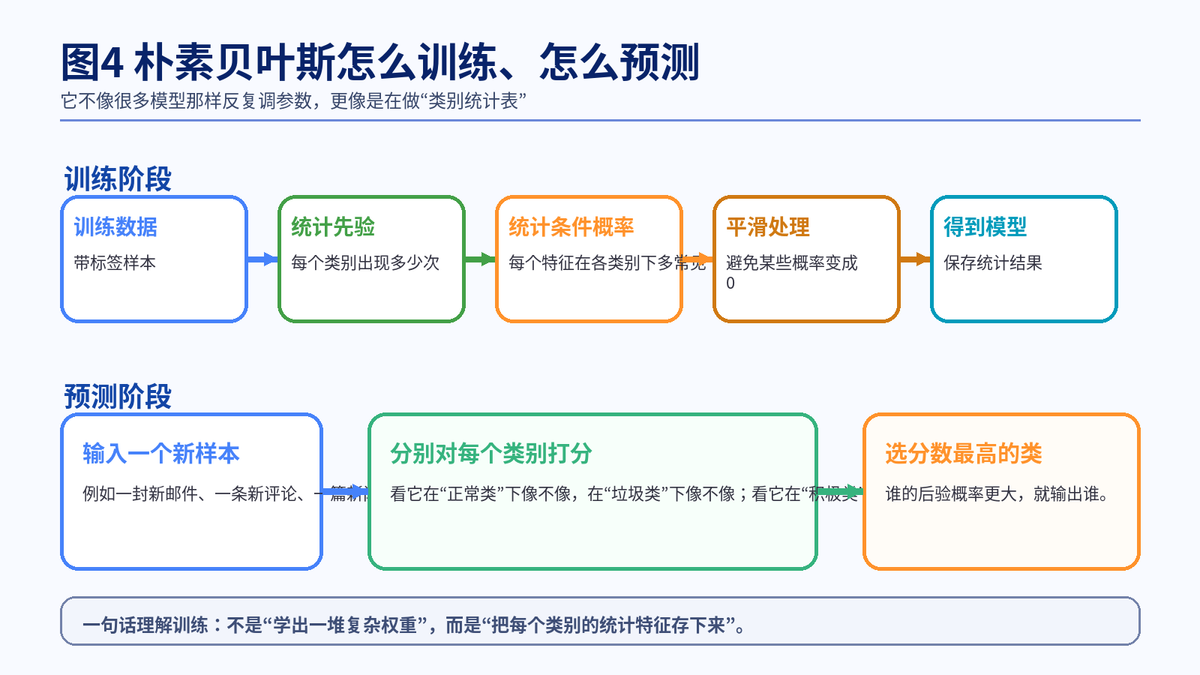
5. 朴素贝叶斯是怎么训练出来的
5.1 它的训练,核心不是梯度下降,而是统计
这一点特别容易在面试中加分。很多人一谈模型训练就下意识想到梯度下降、反向传播、迭代优化。但朴素贝叶斯更像是在建一张"类别统计表"。
5.2 第一步:统计类别先验
先看训练集中每个类别出现了多少次。某一类出现得越多,它的先验概率通常就越高。比如 100 封邮件里有 70 封是正常邮件、30 封是垃圾邮件,那么正常邮件的先验通常就更高。
5.3 第二步:统计条件概率
再看每个特征在每个类别下出现得多不多。比如在垃圾邮件类里,"中奖""返利""点击领取"这些词是不是很常见;在正常邮件类里,"会议""发票""汇报"是不是更常见。
5.4 第三步:预测时把信息合起来
来了一个新样本后,模型会分别计算它属于每个类别的后验概率。直观上就是:站在每个类别的角度,问一句"如果它真是这一类,那现在这些特征常不常见?"谁更合理,就归谁。
5.5 为什么实际实现里常常用对数概率
因为多个很小的概率连乘,很容易越乘越小,甚至造成数值下溢。把乘法改成对数空间里的加法,计算会更稳定。这是工程实现里非常常见的一步。
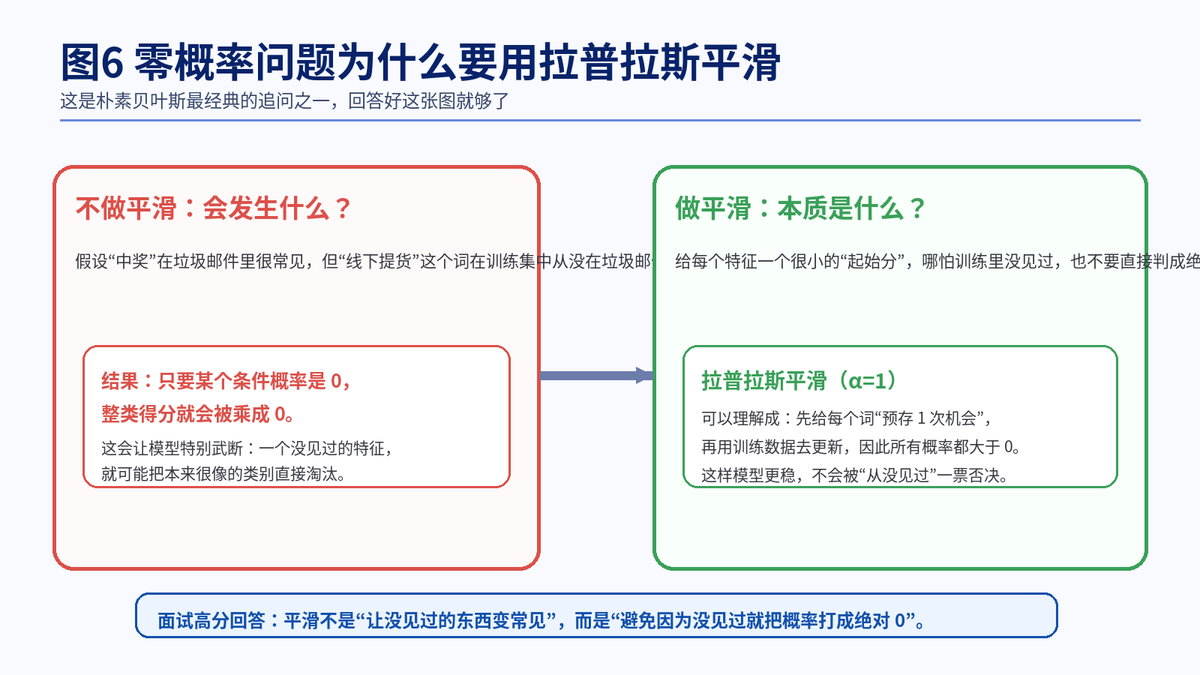
6. 估计条件概率 P(X|Y) 时,为什么会出现概率为 0
6.1 零概率问题是怎么来的
如果某个特征在某个类别的训练样本里一次都没出现过,那么按最朴素的频率统计,它的条件概率就是 0。问题在于,朴素贝叶斯在预测时要把多个特征信息合起来,只要其中一个概率为 0,整个类别的得分就会被直接打成 0。
6.2 这会带来什么坏处
这会让模型变得过于绝对。现实里,一个特征没在训练集中见过,不代表它在这个类别下永远不可能出现。直接给 0,会把模型搞得特别僵硬。
6.3 拉普拉斯平滑为什么有效
拉普拉斯平滑的直观理解是:先给每个特征一个很小的"初始次数",不要让任何特征一上来就是绝对 0。这样一来,就算训练中没见过,它的概率也只是很小,而不是彻底归零。
6.4 α 参数怎么理解
当 α=1 时,通常叫拉普拉斯平滑;更一般地,α 取其他正值时,也可以看成更广义的加性平滑。α 越大,平滑越强,模型越保守;α 太大,也可能把真实差异抹平。
7. 朴素贝叶斯有哪些常见类型
7.1 GaussianNB:连续数值特征常用
如果你的特征更像连续数值,例如时长、金额、身高、温度这类变量,可以考虑高斯朴素贝叶斯。它默认每个特征在各类别下近似服从高斯分布。
7.2 MultinomialNB:文本分类最经典
如果你的特征是词频、计数、词袋表示,那么多项式朴素贝叶斯是最经典的选择。它在文本分类领域出现非常多,也是很多人最熟悉的朴素贝叶斯版本。
7.3 BernoulliNB:只关心"有没有"
如果你只在乎某个特征是否出现,而不在乎出现了几次,那么伯努利朴素贝叶斯更合适。比如一个词有没有出现,某个标签是否被触发。
7.4 ComplementNB:类别不平衡时更稳
当类别很不平衡时,补集朴素贝叶斯往往是一个值得试的版本。它通过使用'非本类'的统计信息来修正估计,在不平衡文本数据上常常更稳一些。

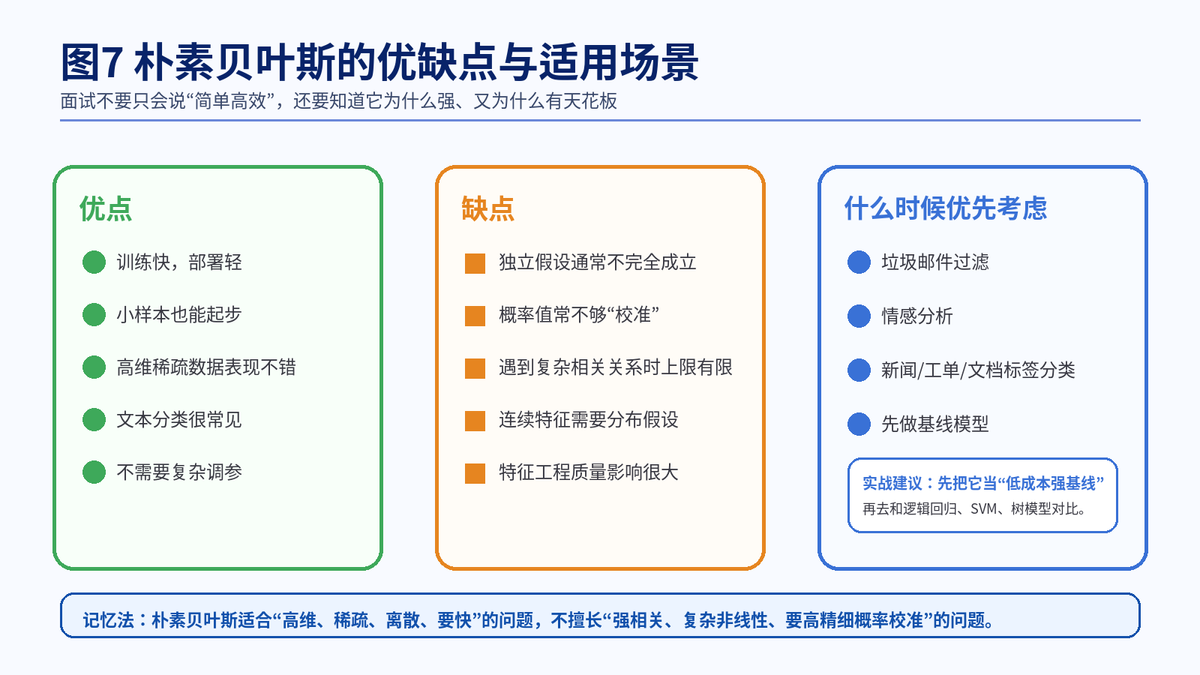
8. 朴素贝叶斯的优点和局限
8.1 它为什么这么受欢迎
训练速度快,部署成本低。
对高维稀疏数据友好,尤其是文本问题。
样本不多时也能快速起步。
作为基线模型非常强,便于和其他模型做对比。
8.2 它的天花板在哪里
条件独立假设往往不完全成立。
当特征之间强相关时,模型表达能力有限。
它给出的概率常常不够"校准",数值未必特别可信。
面对复杂非线性关系时,往往不如更强的判别式模型。
8.3 实战中应该怎么用
很实用的一种思路是:先用朴素贝叶斯打一个低成本基线,快速看清数据是否有可分性;如果效果已经够用,直接上线也未尝不可;如果还不够,再和逻辑回归、线性 SVM、树模型等做进一步比较。
9. 面试时怎么把这道题答得既通俗又专业
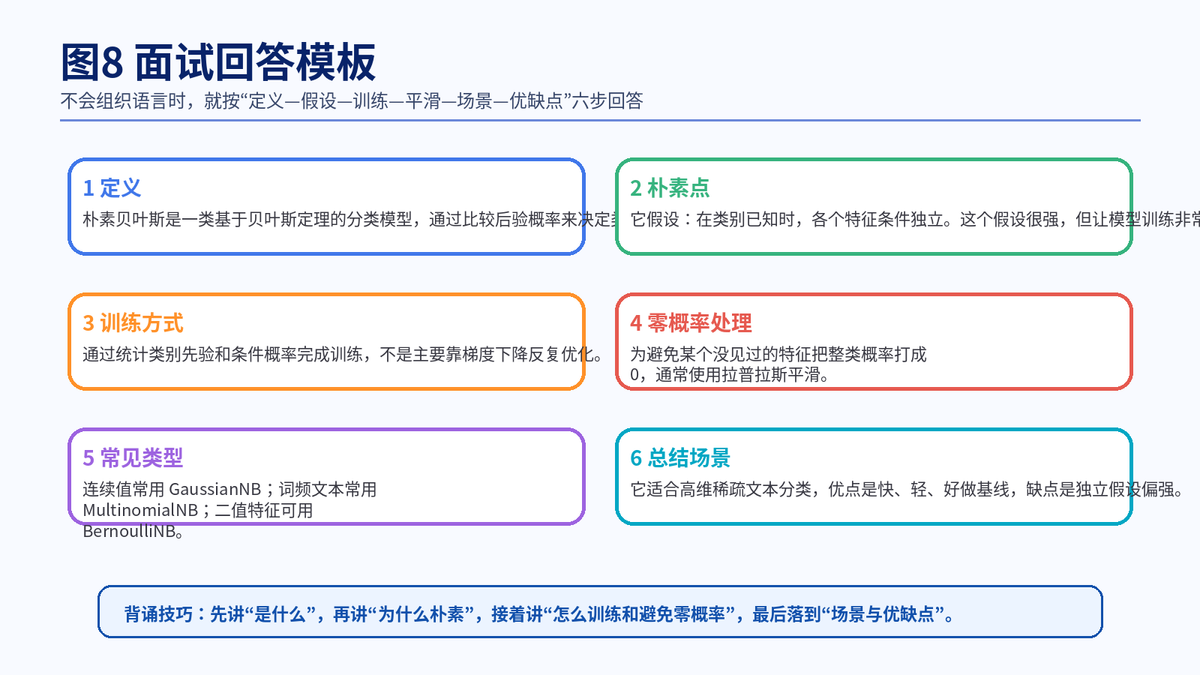
9.1 推荐答题结构
你可以直接按下面这条线回答:先说它是什么;再说为什么叫'朴素';接着讲训练就是统计先验和条件概率;然后补一句零概率要用拉普拉斯平滑;最后落到常见类型、优缺点和适用场景。
9.2 一段可直接复述的话术
朴素贝叶斯是一类基于贝叶斯定理的分类模型,核心是比较样本属于各个类别的后验概率。它之所以叫'朴素',是因为假设在类别已知的条件下,各个特征相互独立。训练时主要是统计类别先验和条件概率,不是主要靠梯度下降。为了避免某个没见过的特征把整类概率打成 0,通常会用拉普拉斯平滑。它特别适合高维稀疏文本分类,优点是快、轻、好做基线,缺点是独立假设偏强。
10. 总结
朴素贝叶斯最值得掌握的,不是某一条公式,而是背后的三层思想:第一,分类可以用概率比较来做;第二,复杂问题可以通过合理假设拆开;第三,统计估计要考虑数据稀疏和零概率问题。
如果你把这三层吃透了,面试里无论对方是问定义、问训练、问平滑、问类型,还是问适用场景,你都能顺着同一条主线讲清楚。
一句话收尾:朴素贝叶斯不是最复杂的模型,但它是最能体现机器学习'概率思维 + 工程取舍'的经典模型之一。