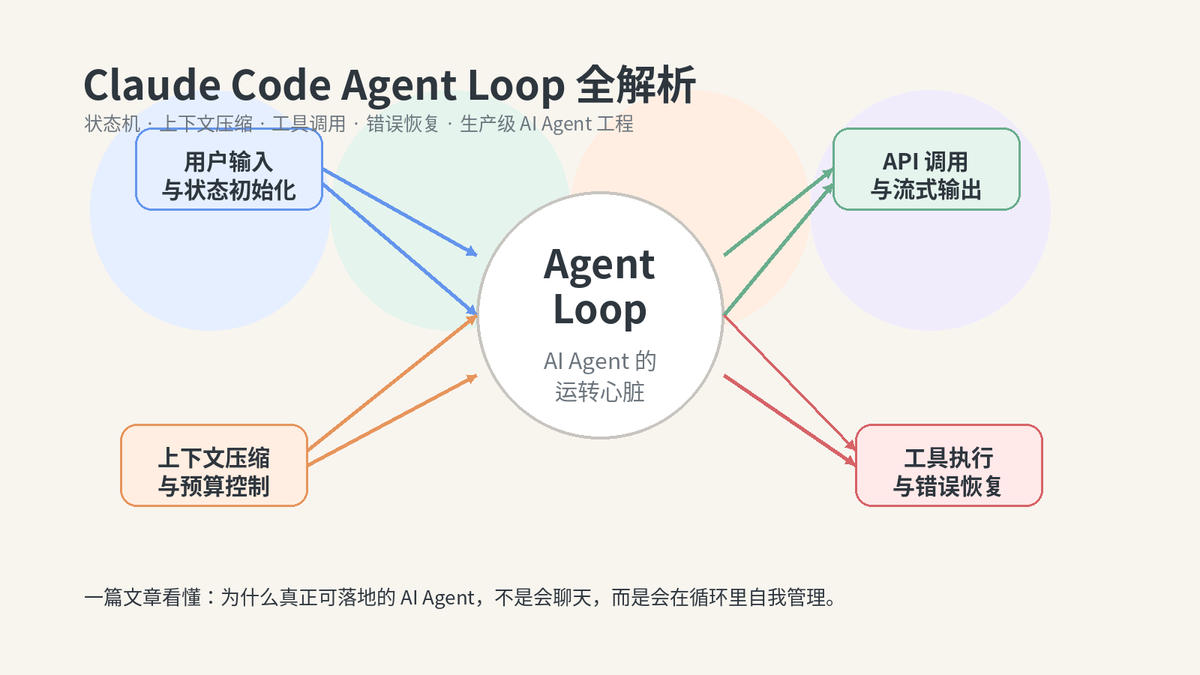
看懂 queryLoop,才真正看懂生产级 AI Agent 是怎么跑起来的。
很多人以为 AI Agent 的核心是模型够不够强、提示词写得好不好、工具够不够多。可真正把系统拉到生产环境后,你会发现最难的根本不是"会回答",而是"能不能在一轮又一轮交互里稳住自己"。
我们聚焦的不是某一个工具,也不是某一个模型参数,而是整个系统最像"心脏"的那部分:Agent Loop。它负责收输入、改状态、压上下文、调模型、跑工具、做恢复、判继续、判终止。你可以把它理解成 AI Agent 的总调度室。
|-------------------------------------------------------------------|
| 一句话先定调:普通聊天系统像"问一句答一句",而 Agent Loop 像"一个边思考、边执行、边修复、边继续推进任务的状态机"。 |
1. 理解 AI Agent 的总开关
如果你只看工具层,你会觉得 Agent 很厉害;如果你只看模型层,你会觉得 Agent 只是把大模型接了更多能力;但只要你往工程实现里再深入一层,就会看到真正决定上限的,是这条循环本身。
因为后面几乎所有关键子系统,最终都要回到这条循环里落地:上下文压缩要在这里触发,API 请求要在这里组装,工具结果要在这里接回,对话是否继续要在这里判断,恢复策略也要在这里执行。没有这条循环,所有模块都只是零件;有了这条循环,它们才像一个系统。
所以,最值得记住的不是一个函数名,而是一个判断标准:真正的 Agent Loop,不只是循环调用模型,而是能够在循环里管理自己。
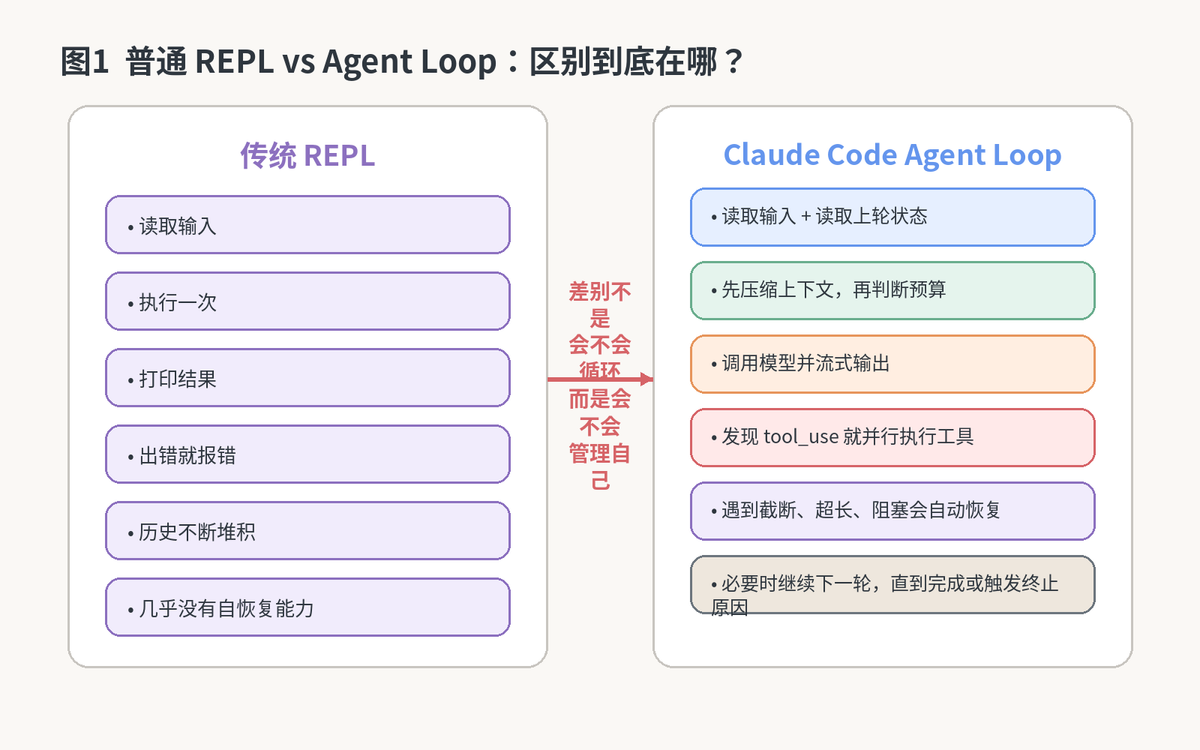
2. Agent Loop 和普通 REPL 到底差在哪
很多人第一次看到 queryLoop,会以为它只是把聊天包装进了 while(true)。表面上确实像,但本质差别非常大。普通 REPL 的前提是"每一轮都是独立的",而 Agent Loop 的前提是"每一轮都会改写下一轮的运行条件"。
• 普通 REPL 读完输入就直接执行;Agent Loop 在执行前先做上下文预算、压缩和标准化。
• 普通 REPL 出错就把错误吐给用户;Agent Loop 会先判断这是不是可恢复错误。
• 普通 REPL 很少关心历史容量;Agent Loop 必须持续管理 token 空间。
• 普通 REPL 没有工具调度;Agent Loop 需要把 tool_use、tool_result、权限检查和结果注入接起来。
• 普通 REPL 的"下一轮"只是再来一次;Agent Loop 的"下一轮"往往已经带着新的状态、新的上下文、新的附件和新的限制。
从工程角度看,Agent Loop 的本质不是"循环",而是"持续演化的运行上下文"。这也是为什么它更像状态机,而不是聊天壳。
3. 状态机总览:queryLoop 到底控制了什么
Claude给出的一个非常重要的视角,就是把 queryLoop 看成一台显式状态机。所谓显式,就是系统不把变化偷偷藏在各个局部变量里,而是通过 State 把跨轮次必须携带的信息都摆到台面上。
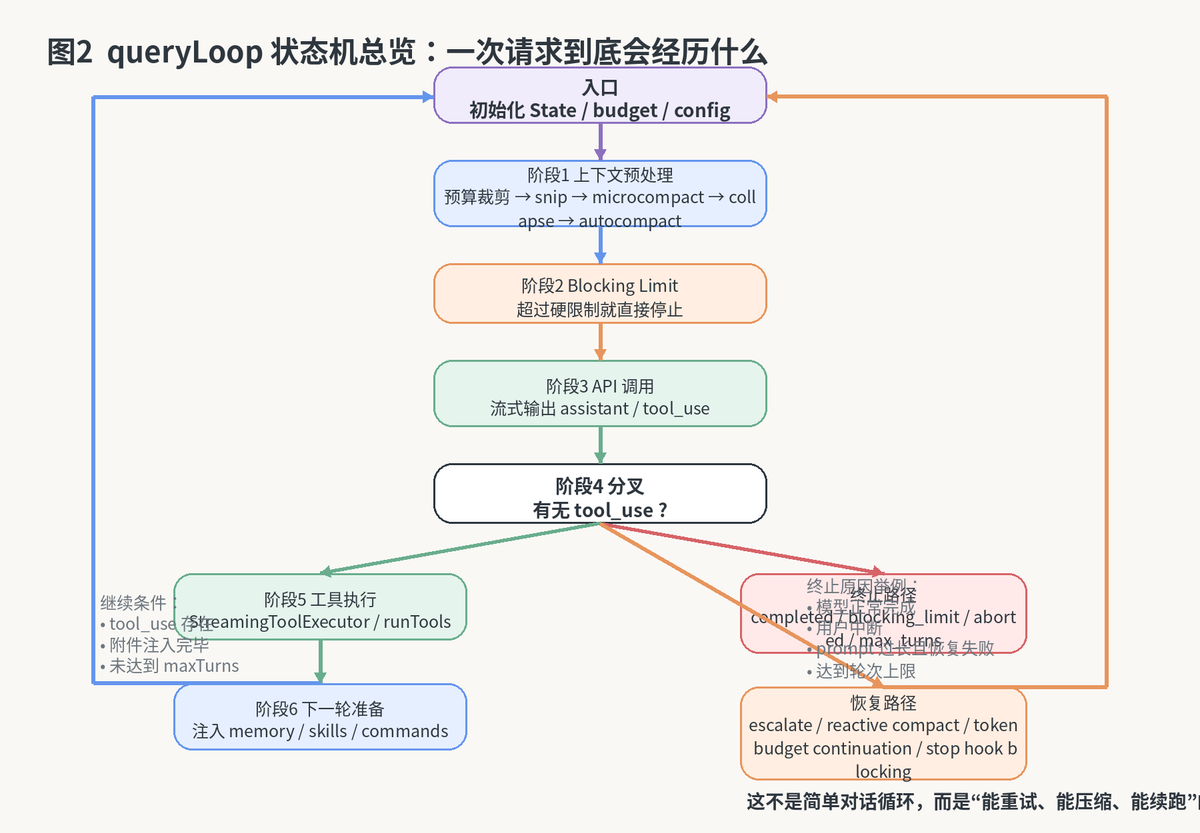
queryLoop 的完整拓扑。先预处理,再调模型,再按"有无 tool_use"分叉,最后进入继续或终止路径。
这一设计非常适合复杂系统。因为一旦路径变多,如果状态不是集中管理,后面一定会出现"某条 continue 路径忘了重置某个字段"的事故。
3.1 State 里的 10 个字段,不是凑数,而是防事故清单
你可以把 State 看成一份"运行中的总账本"。里面每个字段都在看守一种常见风险:消息数组防止上下文丢失,工具上下文防止执行环境断裂,恢复计数防止无限重试,轮次计数防止越跑越远,transition 则让测试和调试能看懂"这轮为什么会继续"。
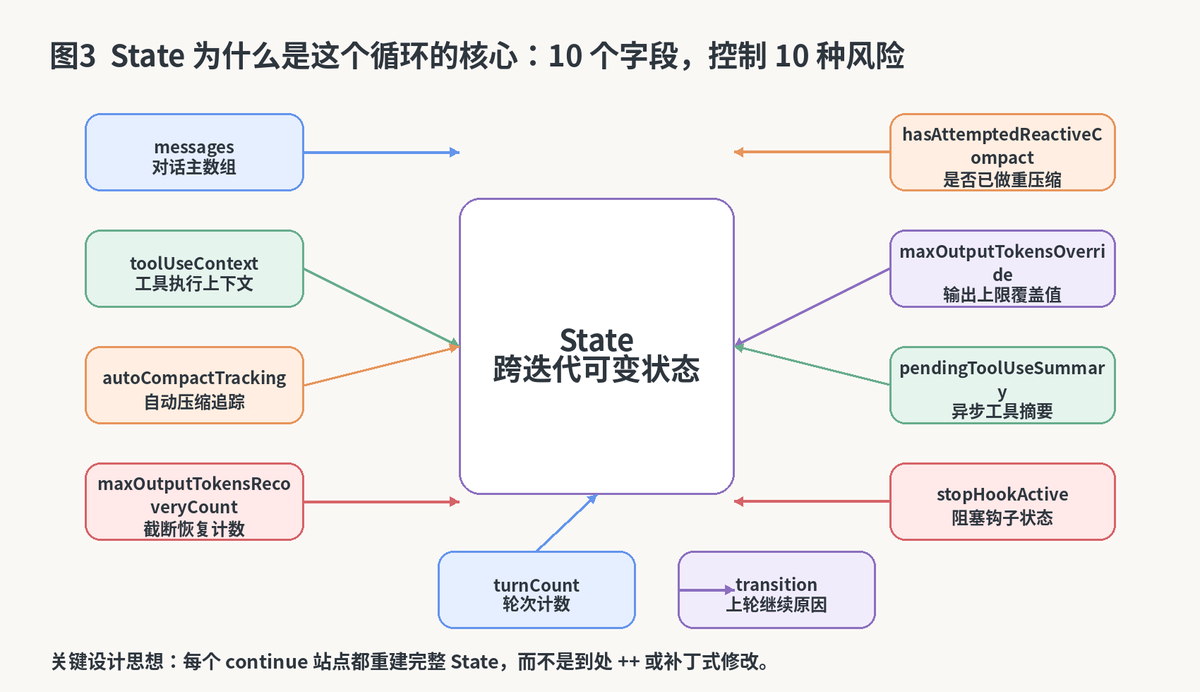
State 把"消息、工具、压缩、恢复、轮次、转移原因"等全部收拢到一处,形成一个跨迭代总控制面板。
特别值得学的一点是:每个 continue 站点都倾向于重建一个完整的新 State,而不是东加一点、西改一点。这种写法看起来啰嗦,实际上对复杂系统极其友好。因为显式重建,等于把"下一轮系统长什么样"一次写清楚了。
3.2 Continue 与 Terminal:为什么这个循环不会失控
要让一个 while(true) 在生产环境里安全运行,最关键的不是能跑,而是知道"什么时候继续"和"什么时候必须停"。Claude把这两类路径拆得非常清楚。
|----------------------------|--------------------|-----------------------------------------------|
| 继续原因 | 触发含义 | 典型动作 |
| next_turn | 模型返回 tool_use | 追加 assistant 与 tool_result,递增 turnCount,进入下一轮 |
| max_output_tokens_escalate | 输出被截断但还没升级过上限 | 把输出上限直接拉高后原样重试 |
| max_output_tokens_recovery | 升级后仍然截断 | 注入继续写的元消息,尝试续写 |
| reactive_compact_retry | prompt 过长 | 先做恢复性压缩后重试 |
| collapse_drain_retry | 有尚未提交的 collapse 结果 | 先把折叠结果排空再重试 |
| stop_hook_blocking | Stop hook 返回阻塞错误 | 把阻塞信息注入消息流,让模型修正 |
| token_budget_continuation | 预算还有余量 | 注入 nudge,鼓励模型继续推进任务 |
|------------------------------------|-----------------------|
| 终止原因 | 什么时候会发生 |
| completed | 模型正常完成,或者可恢复策略全部用完后结束 |
| blocking_limit | token 触到硬限制,无法再继续 |
| prompt_too_long | prompt 过长且恢复手段全部失败 |
| aborted_streaming / aborted_tools | 用户在流式响应或工具阶段中断 |
| model_error | 模型层抛出不可预期异常 |
| stop_hook_prevented / hook_stopped | 钩子明确禁止继续 |
| max_turns | 达到最大轮次限制 |
这两张表合起来其实在回答一个工程问题:怎样让一个复杂循环既有自愈能力,又不会无休止地自愈。
4. 一次完整迭代是怎么发生的
如果把一轮交互拆开看,大致可以分成几段:先预处理上下文,再检查是否已逼近硬限制,接着组装请求并调用模型,然后看模型是否给出 tool_use;有工具就执行工具,没有工具就走终止和恢复判定。
这一拆法非常重要,因为它告诉你:工具执行并不是"模型输出后的附加动作",而是整条主循环里的一个正式阶段。也就是说,工具不是外挂,而是循环的一等公民。
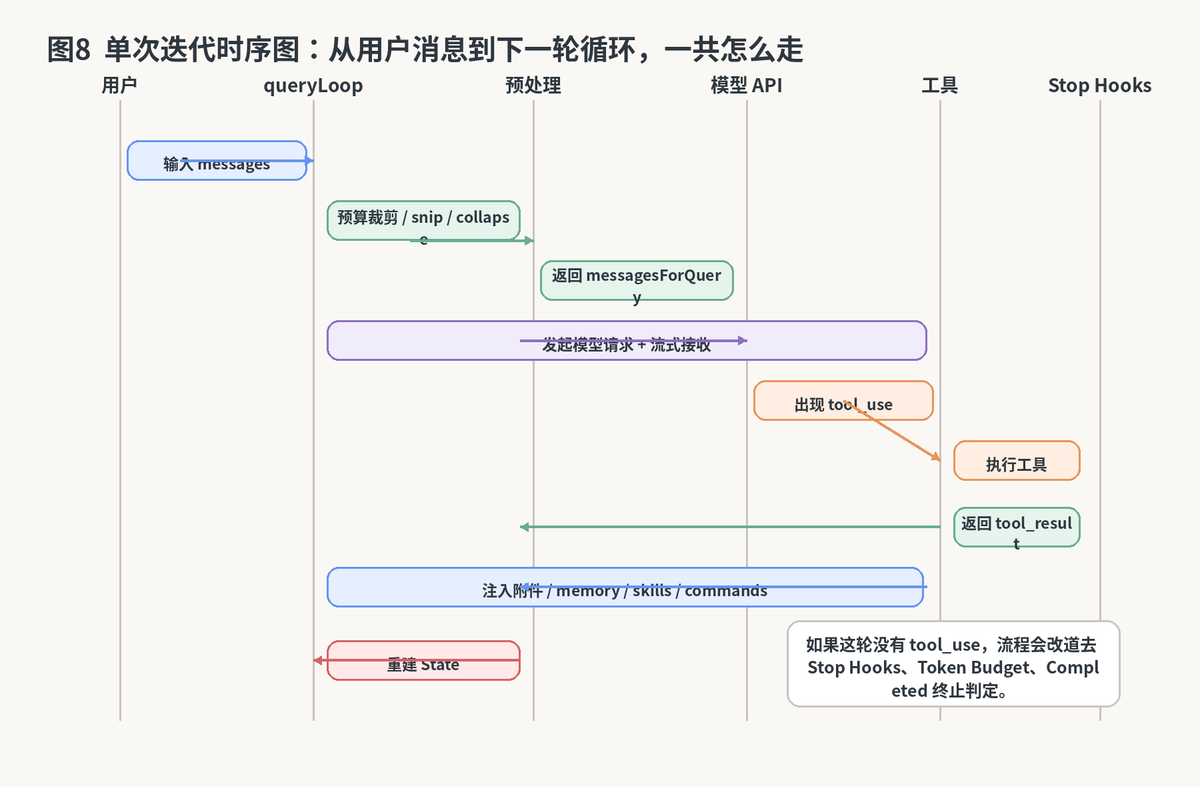
把一轮完整迭代摊开后,你会发现真正的复杂度不在"回答"本身,而在"回答前后还有多少事要做"。
5. 上下文预处理:这套系统为什么不会很快把上下文撑爆
Claude最精彩的部分之一,就是把消息发给模型之前,并不是立刻发送,而是先过一条分层压缩管线。这个顺序不是随便排的,而是非常典型的工程优化思路:先做最便宜、信息损失最小的动作;不够,再升级到更重的动作。

五级压缩阶梯遵循"从轻到重、从局部到全局"的策略。
5.1 第一层:工具结果预算裁剪
系统会先对工具结果做预算限制。这一步看似简单,实际非常关键。因为工具输出往往最容易暴涨:读取大文件、抓长日志、搜索返回多段结果,都可能让消息体瞬间变大。先把这里控住,后面的压缩才不会被过大结果拖垮。
5.2 第二层:History Snip
History Snip 可以理解成"先剪掉一部分旧历史"。它不追求彻底压缩,只追求快速腾一点空间。它释放出来的 token 还会反馈给后续阶段,让后续逻辑知道前面已经腾出了多少余量。
5.3 第三层:Microcompact
Microcompact 更细,目的不是"概括整段历史",而是"把局部肥肉剔掉"。从实战角度说,这种轻量压缩很有价值,因为它比全量摘要更少破坏上下文结构。
5.4 第四层:Context Collapse
这一层最有意思的地方在于,它并不粗暴改写原始消息数组,而更像在读取时临时生成一个折叠视图。通俗点说,原始历史还在,但送给模型看的那一版会被重新投影。这样的好处是:系统既能节省窗口,又不必完全丢掉完整历史。
5.5 第五层:Autocompact
只有前面都不够,系统才会上真正的重量级自动压缩。也正因为它最重,所以它被放到最后。这种排序,背后其实是很成熟的生产经验:信息越宝贵,越要晚一点动刀。
6. API 请求构建:为什么"内部消息"不能直接发给模型
很多初学者容易忽略这一步:系统内部的消息格式,往往比 API 最终接受的格式复杂得多。内部有显示专用消息、进度消息、附件消息、工具块、系统块,甚至还有仅供 UI 使用的虚拟消息。这些都不能原样塞给模型。

内部消息要经过标准化、配对修补和上下文注入,才能变成真正可发送的 API 请求。
这里可以结合官方规则一起理解:在 Claude 的工具调用格式里,tool_result 必须紧跟对应的 tool_use,并且在用户消息的 content 数组里排在最前;否则就可能直接触发请求错误。官方的 token 统计接口也明确支持把 system、tools、images、PDFs 这样的输入一起纳入估算。换句话说,结构不规范,不只是会报错,还会影响预算判断。
这也是为什么标准化并不是"代码洁癖",而是稳定性基础设施。谁先重排附件,谁先剥离虚拟消息,谁来修补 tool_use 与 tool_result 的对应关系,这些动作看起来都不性感,但一旦缺一个,系统就会在边角场景里频繁摔跤。
7. 工具执行阶段:工具不是外挂,而是主循环中的正式阶段
当模型输出里带着 tool_use,系统会进入工具执行阶段。Claude点出了两种执行方式:一种是流式并行执行,模型边输出边把工具塞进执行器;另一种是等所有工具块收集完,再批量统一执行。
• 流式并行的优势是快,能把等待时间切碎,让工具和模型同时推进。
• 批量执行的优势是稳定,适合需要统一调度或一次性整理结果的场景。
• 无论哪种方式,工具结果回来后都还要重新标准化,才能安全接回消息流。
这说明一个重要事实:Agent 的工具调用不是"模型说一句、外部程序帮它办一下"这么简单,而是一条带约束、有配对关系、有预算限制、可插回主循环的正式通道。
8. 为什么这条循环能把等待时间藏起来
真正做过 Agent 产品的人都知道,用户对"正在思考"很宽容,但对"明明在等却什么都没发生"很敏感。Claude很聪明的一点,是它把很多准备动作提前塞进后台并发里。
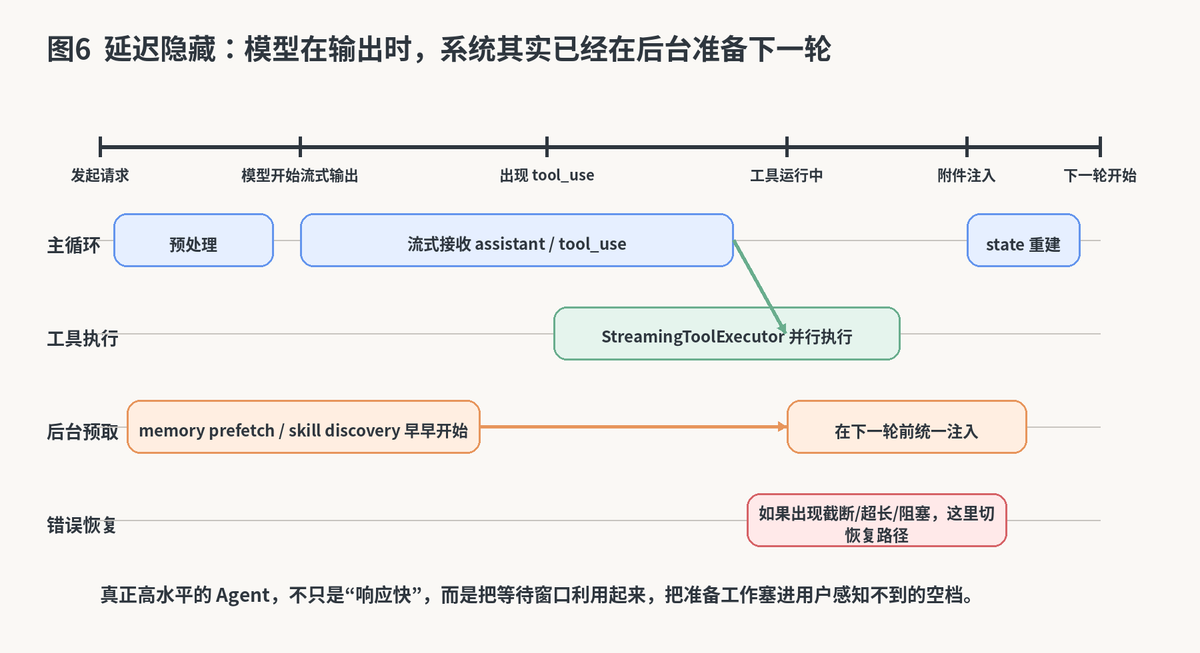
模型流式输出并不是纯等待时间,而是系统在偷偷干活的黄金窗口。
比如 memory prefetch、skill discovery 这类动作,并不是非得等模型完全结束后才做。系统会在入口或中途提前启动它们,等真正轮到附件注入时,这些结果往往已经准备好了。这样一来,用户感觉到的是"系统衔接得很顺",而不是"每一步都在重新加载"。
这背后其实是一种非常成熟的产品思维:把必须做的耗时工作,尽量塞进用户本来就得等待的窗口期里。
9. 错误恢复:为什么它不是出错就停,而是尽量救回来
Claude另外一个非常亮眼的地方,是它把错误恢复写成了一套明确的阶梯,而不是零散 if-else。只要你做过线上系统,就会知道这一点有多重要。因为真正消耗团队精力的,从来不是正常路径,而是边界错误的堆叠。
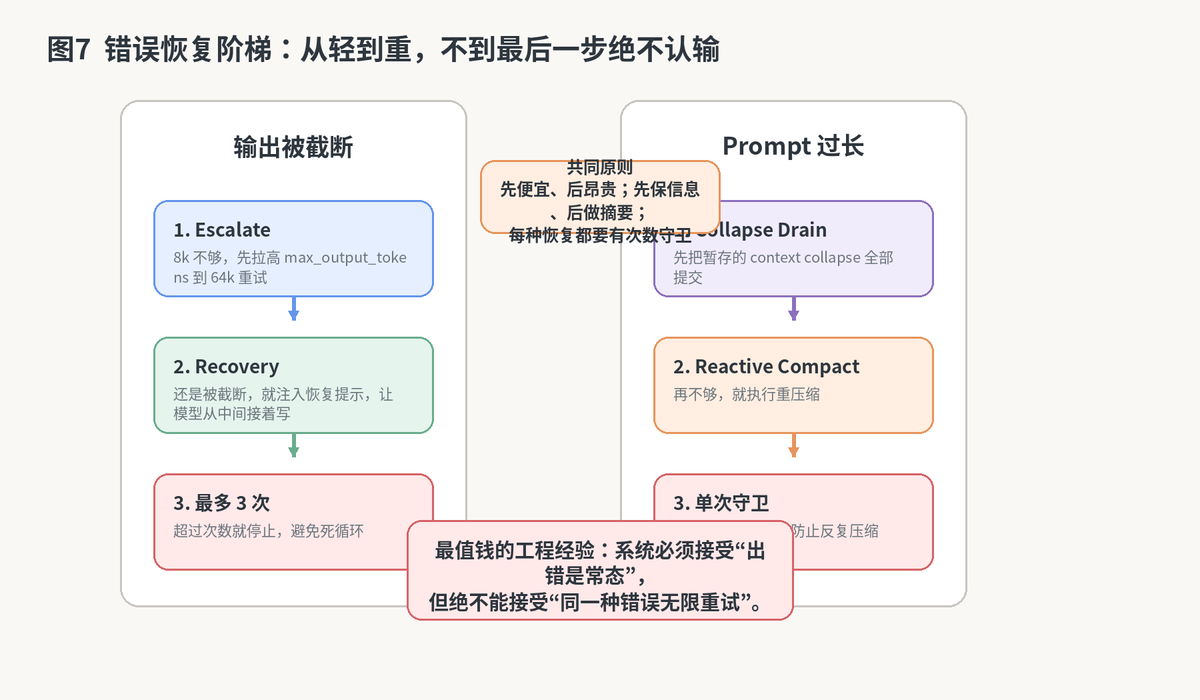
无论是输出截断还是 prompt 过长,恢复策略都遵循先轻后重、先试再停的节奏。
9.1 输出被截断时,先升级上限,再多轮续写
如果模型因为 max_output_tokens 不够而被截断,系统先尝试把输出上限直接拉高。这个动作几乎不改变上下文,也不增加轮次,所以可以理解成最便宜的恢复手段。
如果拉高之后还不够,系统才进入多轮恢复:它会注入一条很克制的元消息,让模型不要道歉、不要复述、直接从断点继续,并且尽量拆成更小的块继续写。这个提示写法其实很专业,因为它专门避免了继续写时最容易浪费 token 的两种行为:客套和重复。
9.2 Prompt 过长时,先排空折叠,再做重压缩
当错误是 prompt 过长时,系统也不会上来就做最重的操作。它会先看看有没有暂存的 context collapse 可以提交;如果这些便宜动作还不够,再去执行 reactive compact。
更关键的是,这里会有单次尝试守卫。也就是说,系统明确知道这类恢复不能无限重来,否则就会进入"压缩失败---重试---再失败"的死亡螺旋。
9.3 Fallback 与中断:该换模型就换,该停就停
如果是模型侧高负载等问题,系统会触发 fallback,在同一轮里切换到备用模型重试,而不是把整个会话打回起点。与此同时,流式输出或工具执行阶段如果收到用户中断,也会立即返回对应终止原因。
这体现了一个成熟系统的边界感:能恢复的尽量恢复,但绝不假装所有事都能恢复。
10. Stop Hooks、Token Budget 和"提前完成"问题
很多人写 Agent 时只盯着"模型说完没",却很少考虑"模型是不是说早了"。Claude在这里补了一刀:如果模型看起来已经完成,但 token 预算其实还没耗尽,系统会做进一步判断,看看它是不是只是提前收手。
如果预算还充足,而且判断还有推进空间,系统会注入 nudge,让模型继续往下做;但如果进入递减回报区,也不会为了把预算花完而硬逼模型继续。这个平衡非常关键,因为"预算还没用完"不等于"继续一定更好"。
Stop Hooks 则扮演另一种守门员角色:当响应触发阻塞条件,系统不会立即失败,而是把阻塞错误重新注入消息流,给模型一次修正机会。你可以把它理解成一个非常工程化的"先拦住,再纠正"。
11. 最值得抄走的 5 个工程模式

11.1 显式状态重建,而不是增量缝补
继续路径越多,越要避免分散修改。最好的做法不是"哪里要改就改哪里",而是在关键继续点直接写出完整下一状态。这样最利于审计,也最利于测试。
11.2 可恢复错误先扣留,别急着抛给上层
如果系统第一时间把错误抛出去,上层组件往往会直接结束会话。可很多错误其实是能被救回来的。所以,把可恢复错误先压住,等恢复失败后再释放,是非常实用的设计。
11.3 恢复策略一定要分层
不要一看到超长就全量摘要,一看到截断就重新开新轮,一看到异常就直接切模型。真正成熟的系统,总是先做损失最小、代价最低的动作。
11.4 任何自动恢复都必须带守卫
while(true) 并不可怕,可怕的是 while(true) + 没有尝试上限。只要系统允许自动重试,就必须有布尔标记、计数器或者 transition reason 来防止无限循环。
11.5 把等待窗口当成免费计算时间
模型流式输出本身就是一段用户已经在等待的时间。如果这时系统还能顺手把内存预取、技能发现、摘要构建等工作做掉,产品体感会好非常多。
12. 如果你要自己做 AI Agent,Claude能直接给你什么
真正吃透后,你会得到一份很有现实价值的工程清单。
• 你的主循环里,是否有独立的 State,而不是散落在函数里的十几个局部变量?
• 你的上下文超长时,是否有分层压缩,而不是直接做大摘要?
• 你的工具结果是否有预算控制和配对修补?
• 你的可恢复错误是否会被立刻暴露,还是会先尝试补救?
• 你的系统是否记录"这轮为什么继续",以便测试和回放?
• 你的等待窗口是否被真正利用起来做后台预取?
只要这里面有一半还没做,你的系统大概率还停留在"能跑 Demo"的阶段;如果大部分都做了,才算真正迈进"可落地 Agent 工程"。
13. 总结:为什么说 queryLoop 才是生产级 AI Agent 的分水岭
最有价值的地方,不是告诉你某个 API 怎么调,而是让你明白:生产级 AI Agent 的核心竞争力,往往不在单次回答质量,而在循环稳定性。一个系统能否长期对话、能否用好工具、能否控制上下文、能否在异常里优雅恢复,最终都要回到这条循环里。
你可以把这条循环想象成一座总控台。用户输入从这里进,模型输出从这里出,工具在这里调度,预算在这里核算,压缩在这里触发,恢复在这里决策,继续与终止也都在这里拍板。谁掌握了这条循环,谁才真正掌握了 Agent。
所以,如果你只想学"怎么接一个模型",这章会显得有点重;但如果你想做"能持续工作、能应对异常、能在线上活得久"的 AI Agent,这一章反而是最值得反复看的底层骨架。
|-----------------------------------------------------|
| 最后用一句最通俗的话收尾:真正厉害的 Agent,不是永远不出错,而是出错以后还能自己把活接着干下去。 |