在AI项目落地与技术选型中,很多研发和架构师都会面临一个难题:业务场景是否需要上超大参数通用基座模型?是不是模型参数越大、投入越高,项目效果就越好?结合当下主流的GLM-5、GLM-OCR、PaddleOCR-VL-1.5模型资源与成本数据,从算力、研发周期、落地成本三个维度,剖析通用模型与垂直微调模型的技术选型逻辑。
现阶段超大参数通用基座模型,以GLM-5(744B MoE)为代表,属于重算力、重资金、重人力的底层基础设施级项目。其完整预训练与RLHF优化周期长达3-6个月,需要百人级算法、工程、数据团队协同开发。
成本层面极具门槛,万卡集群长时间运行带来3000万-5000万元算力成本,叠加2000万-3000万元人力成本、500万-800万元数据标注成本,整体投入高达5500万-8800万元。该类模型支持全场景通用任务,但算力冗余极高、推理成本昂贵,仅适合大厂搭建AI基础生态,中小企业业务落地完全没必要过度投入。
针对文档识别、票据解析、扫描件处理等高频垂直场景,轻量化微调模型成为工业级落地首选,代表模型为GLM-OCR与PaddleOCR-VL-1.5,核心优势是低算力、短周期、低成本、高适配。
0.9B参数的GLM-OCR,基于成熟基座微调迭代,开发周期仅1-2周。算力成本压缩至10万-20万元,人力成本100万-150万元,分摊基座成本后整体投入约2200万元。相较于通用大模型,成本降幅超70%,且针对OCR场景专项优化,推理速度、识别准确率远超通用模型,规避了通用模型场景适配差、算力浪费的问题。
PaddleOCR-VL-1.5的落地性价比更具优势,综合总成本仅1800万元左右。依托合成数据替代传统人工标注,大幅降低数据成本,2-3周即可完成全流程开发部署,小团队就能实现项目落地,完美适配政企文档、商务票据、档案扫描等轻量化业务场景。
从技术架构角度分析,两类模型的核心差异在于资源利用率。通用模型从零构建全场景能力,存在大量算力与参数冗余;垂直微调模型复用成熟基座能力,聚焦细分场景,剔除无效算力消耗,实现成本与性能的最优平衡。
对于企业技术团队而言,AI落地的核心是场景适配与投入产出比 。盲目堆砌大参数、高算力的通用模型,只会造成资源浪费、项目成本超标、落地效率低下。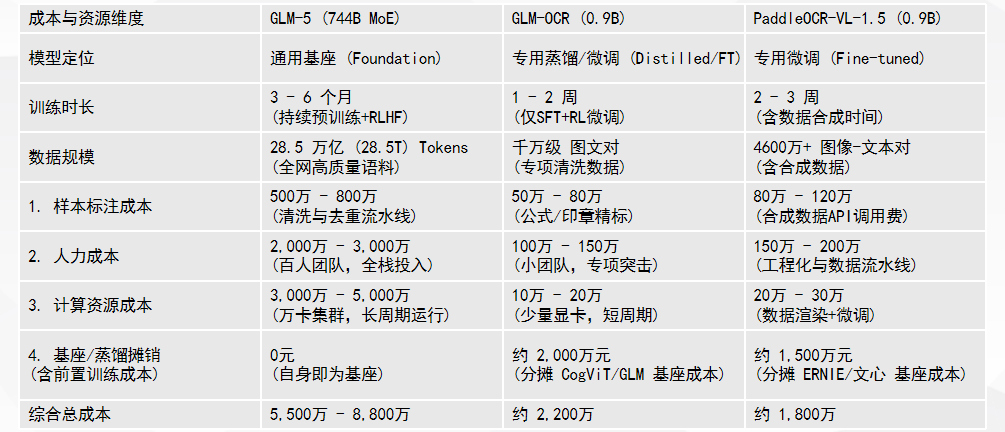
当下AI产业已告别盲目堆参数的内卷阶段,轻量化、场景化、高性价比的垂直模型,才是中小企业、行业项目落地的主流方向。精准匹配业务场景,合理控制算力与研发成本,才是靠谱的AI技术选型方案。