Unidbg学习笔记(一):为什么需要用户态模拟器
Unidbg 不是凭空出现的,它是逆向工程领域三十年工具进化的一个必然节点。理解这条脉络,才能知道它解决了什么问题、不能解决什么问题。
逆向分析的两条路径
面对一个未知的二进制程序,逆向工程师只有两条基本路径:
路径一:理解程序 --- 静态分析
不运行程序,直接阅读它的代码。IDA Pro 把机器码翻译成汇编,Ghidra 进一步把汇编翻译成伪 C 代码,JADX 把 DEX 字节码翻译成 Java。你在读代码的过程中推理程序的行为 --- 这是纯粹的思维活动,程序本身没有执行过一条指令。
静态分析的优势是全局视野:你可以看到所有分支、所有路径、所有可能性。但它的致命问题是 信息过载。一个经过混淆的函数可能有上千个基本块,控制流图像一团乱麻。你知道所有路径都存在,但不知道实际执行时走了哪条。
打个比方:静态分析就像拿着一张城市的完整地图,你可以看到所有的街道和岔路口。但如果这张地图有一万条街道,你需要找出某辆车实际走的那条路线 --- 光看地图是不够的。
路径二:观察程序 --- 动态分析
让程序跑起来,在运行过程中观察它的行为。你不需要理解全部代码,只需要关注实际执行到的那条路径。给定一组输入,程序的执行路径是确定的 --- 这把问题从"理解所有可能性"降维为"观察一条确定的轨迹"。
继续上面的比方:动态分析是给那辆车装上 GPS 追踪器。你不需要研究整张地图,只需要看 GPS 记录 --- 它实际走了哪些路口、在哪里拐弯、最终到了哪里。
两条路径各有不可替代的价值。但在实际工作中,尤其是面对加壳、混淆、反调试的 Android Native 代码时,动态分析往往是突破口 --- 先让它跑起来,看到真实的数据流转,再回到静态分析中验证推理。
这篇文章关注的是动态分析这条路径上的工具进化史。这段历史解释了 Unidbg 为什么会被创造出来。
动态分析工具的三次范式转移
第一代:调试器 --- 观察者必须介入执行流
GDB、LLDB、WinDbg --- 这些工具是动态分析的起点。
调试器的工作原理是附加到目标进程 ,通过操作系统提供的调试接口(Linux 上是 ptrace,Windows 上是 Debug API)来控制程序的执行。你可以设断点、单步执行、查看寄存器和内存。
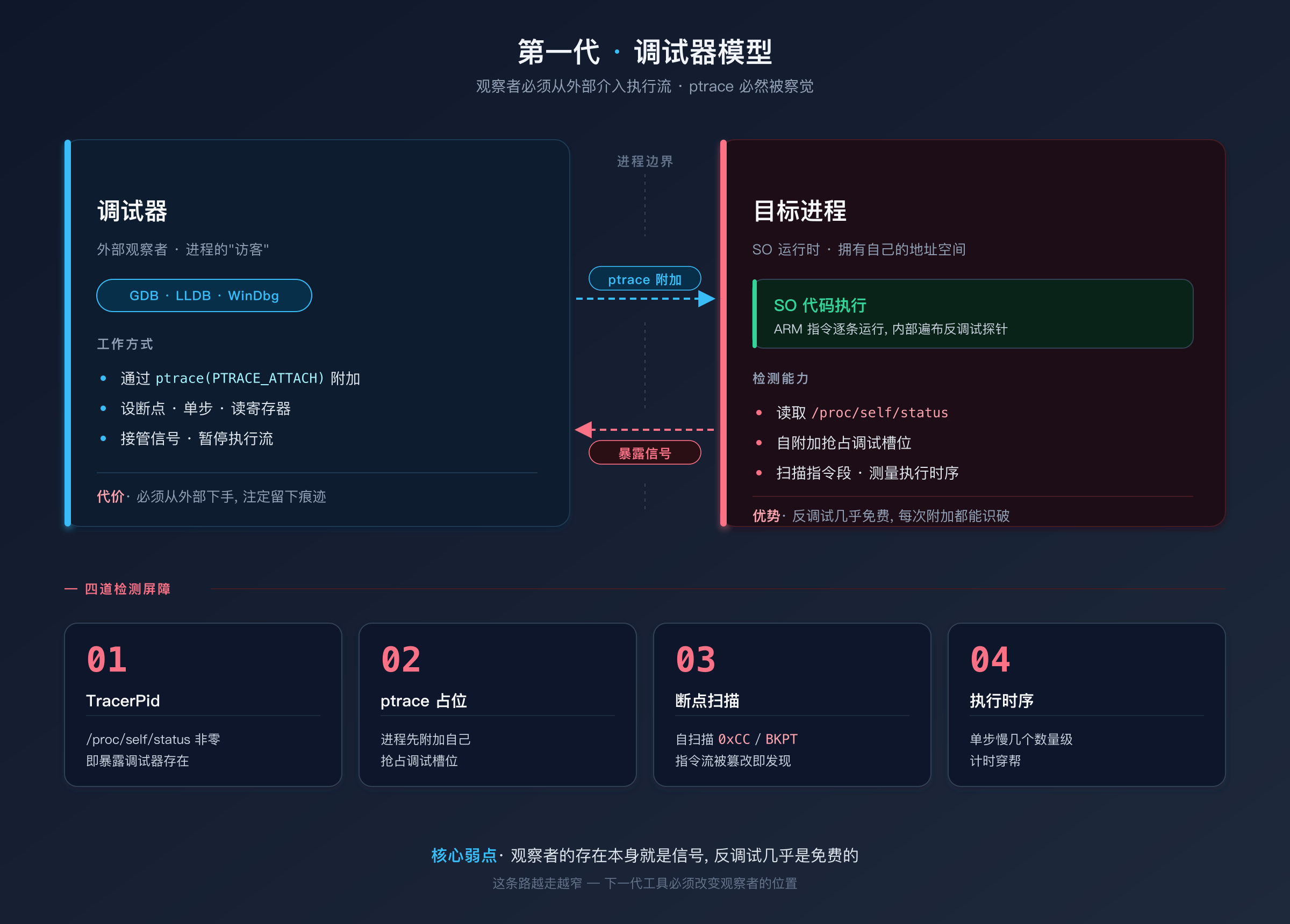
调试器开创了动态分析的可能性,但它有一个结构性的弱点:观察者必须介入执行流 。调试器通过 ptrace 附加到进程上,这个行为本身就可以被检测到。Android 上的反调试手段层出不穷:
- 检测
TracerPid:读取/proc/self/status文件,如果TracerPid字段非零,说明有调试器附加 ptrace占位 :程序启动时自行调用ptrace(PTRACE_TRACEME),抢占调试位,让外部调试器无法再附加- 断点指令扫描 :遍历自身代码段,搜索
0xCC(x86 的INT 3)或 ARM 的BKPT指令,发现则说明被插入了软件断点 - 执行速度检测 :单步执行比正常执行慢几个数量级,通过
clock_gettime等时间函数检测执行耗时异常
调试器和反调试之间的对抗几乎从调试器诞生之日就开始了。这不是一个可以彻底解决的问题 --- 只要观察者需要附加到目标进程,它就必然可以被目标进程察觉。
第二代:Hook 框架 --- 观察者可以驻留在进程内
Frida、Xposed、Substrate --- 这一代工具改变了观察者的位置。
调试器是从进程外部 观察,Hook 框架是把观察逻辑注入到进程内部 。以 Frida 为例,它的做法是把一个 JavaScript 引擎(默认 QuickJS,可切换为 V8)注入到目标进程中,你写的 Hook 脚本直接运行在目标进程的地址空间里。它不需要 ptrace,不会被 TracerPid 检测发现。

Frida 的革命性在于:你可以在不暂停程序的情况下,监控函数调用、修改参数和返回值、甚至主动调用目标函数。这让逆向分析的效率提升了一个量级。
一个典型的 Frida 工作场景:你怀疑某个 SO 函数是签名算法,但不确定它的入参格式和返回值含义。用 Frida 写一段 Hook 脚本,拦截这个函数,打印入参(十六进制 dump)和返回值。App 正常使用的过程中,每次调用签名函数都会被你的脚本记录下来。几分钟内你就能收集到足够的样本来推断参数格式。
但 Hook 框架仍然有一个根本问题:它依赖真实的运行环境。
- 你需要一台 Android 设备(真机或模拟器)
- 你需要把 Frida Server 部署到设备上(需要 root 权限)
- 目标 App 需要能正常启动和运行
- 如果 App 做了 Frida 检测(检查
frida-server默认端口 27042、扫描/proc/self/maps中的 Frida 特征库frida-agent.so),你需要先绕过检测
更重要的是,你仍然不能完全控制执行环境。程序运行在真实的 Android 系统上,操作系统的行为、其他进程的存在、时间的流逝 --- 这些都不在你的控制之下。你是一个潜入者,可以观察和干预,但世界不属于你。
第三代:模拟器 --- 观察者拥有了整个世界
QEMU → Unicorn → Unidbg --- 这一代工具做了一件根本性不同的事情:不再在目标程序的世界里观察它,而是把目标程序拉到你的世界里来运行。
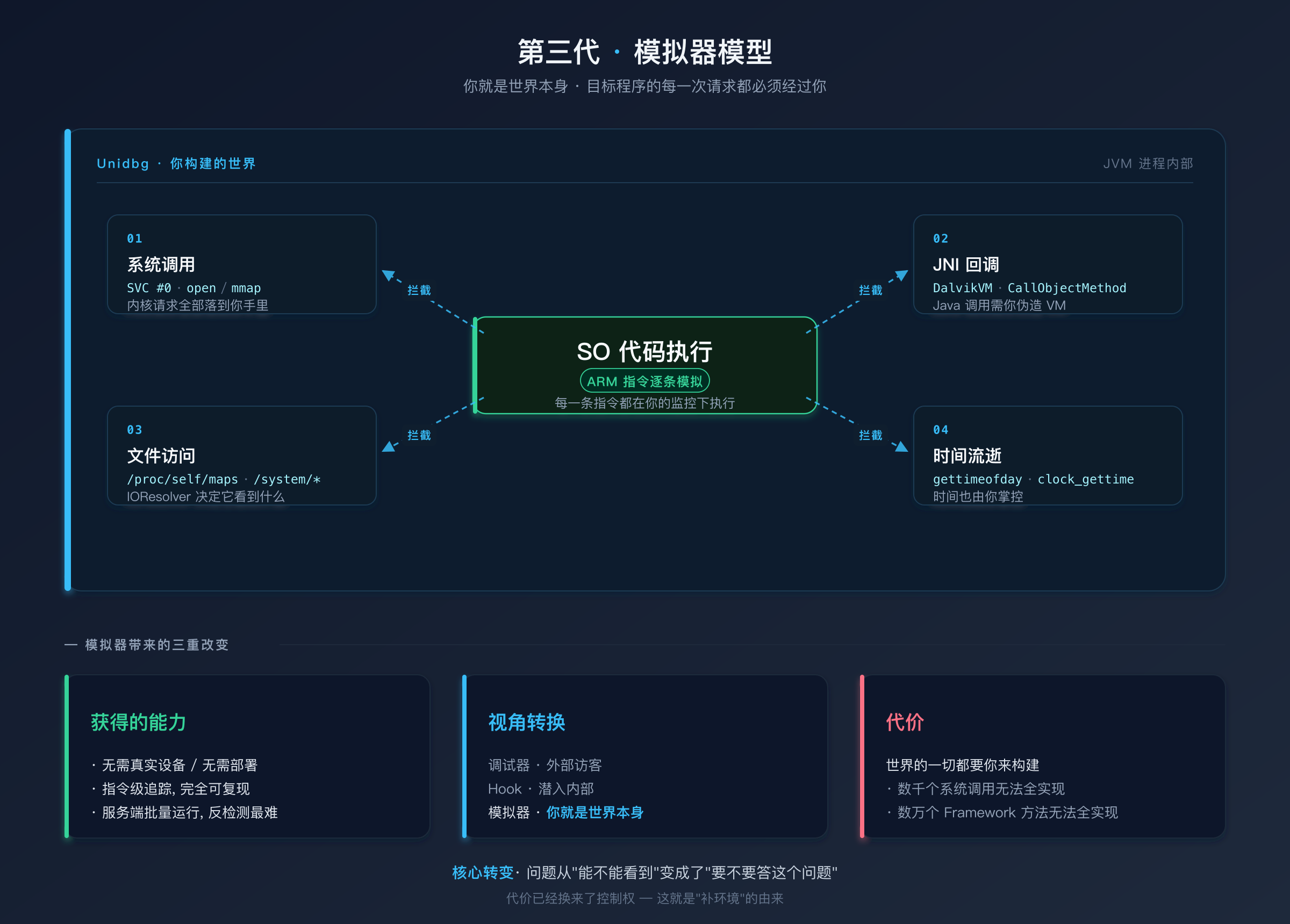
这是一个根本性的范式转移。在调试器和 Hook 框架的模型中,目标程序运行在自己的世界里,你是访客。在模拟器的模型中,你就是世界本身。目标程序的每一次系统调用、每一次 JNI(Java Native Interface,Java 与 Native 代码之间的桥接接口)回调、每一次文件访问,都必须经过你的允许和应答。没有什么可以"偷偷执行"。
这种模型带来了前所未有的控制力:
| 能力 | 调试器 | Hook 框架 | 模拟器 |
|---|---|---|---|
| 需要真实设备 | 是 | 是 | 否 |
| 需要部署到设备 | 是 | 是 | 否 |
| 可被目标程序检测 | 容易 | 有难度 | 最难 |
| 控制所有系统调用 | 否 | 部分 | 是 |
| 控制所有 JNI 回调 | 否 | 部分 | 是 |
| 控制时间流逝 | 否 | 部分 | 是 |
| 指令级追踪 | 慢 | 否 | 快 |
| 在服务端批量运行 | 否 | 困难 | 容易 |
但控制力是有代价的。模拟器拥有世界,也意味着世界的一切都需要你来构建。真实 Android 系统有数千个系统调用、数万个 Framework 方法、完整的文件系统 --- 模拟器不可能全部实现。这就是后面文章要讲的"补环境"的根本原因。
三代工具的进化总结
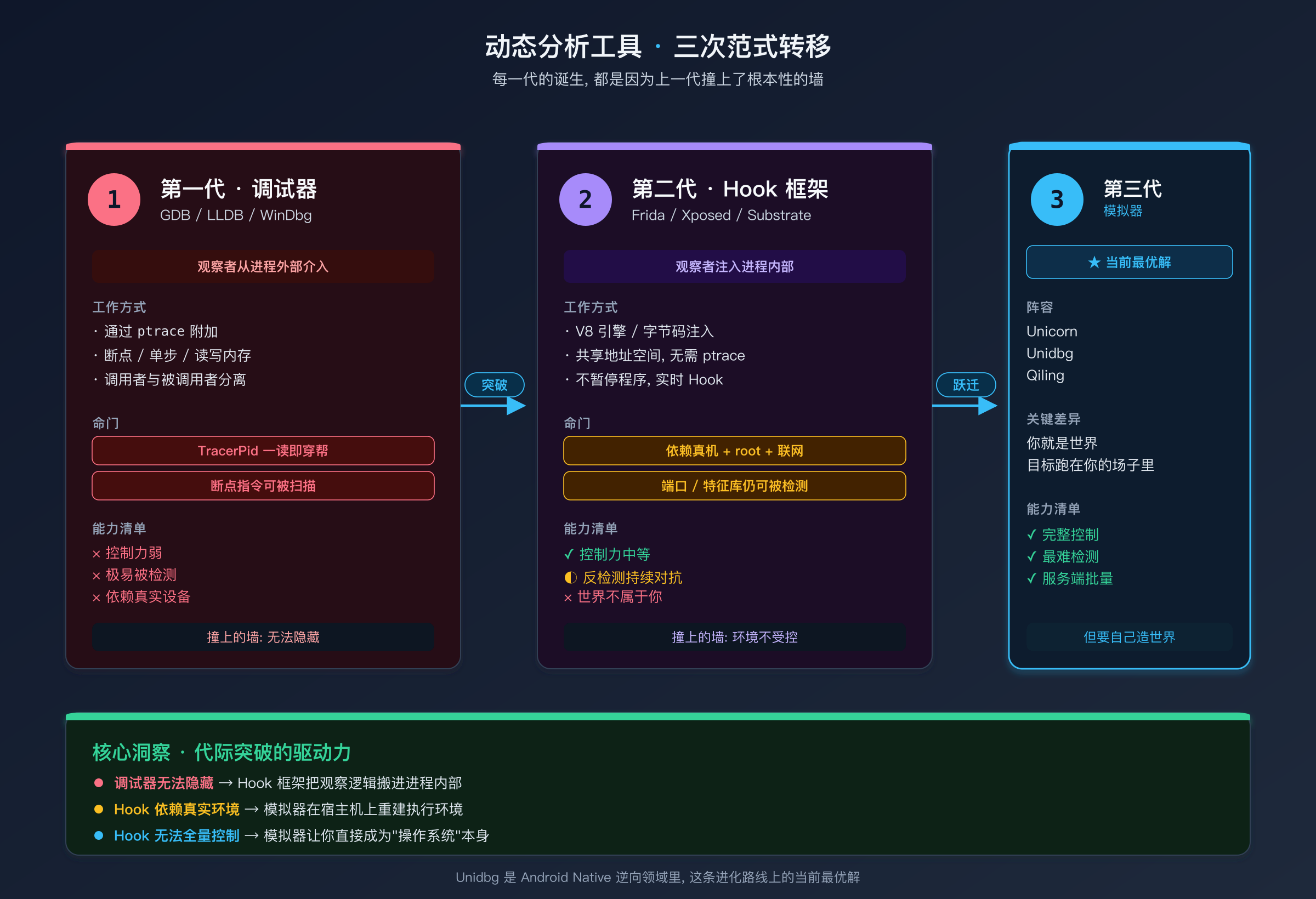
每一代工具的出现,都是因为上一代工具在某些场景下碰到了根本性的墙:
- 调试器无法隐藏自己的存在 → Hook 框架把观察逻辑注入进程内部
- Hook 框架依赖真实设备和运行环境 → 模拟器在你自己的机器上构建执行环境
- Hook 框架无法完全控制执行过程 → 模拟器让你成为"操作系统"本身
从 QEMU 到 Unicorn:切出 CPU 模拟能力
要理解 Unidbg,需要先理解它的地基 --- Unicorn Engine。而要理解 Unicorn,需要先理解 QEMU。
QEMU:全系统模拟
QEMU(Quick EMUlator)是一个完整的系统模拟器,由 Fabrice Bellard 于 2003 年创建。它模拟了 CPU、内存、硬盘、网卡、显卡 --- 整台计算机的一切硬件。你可以在 x86 电脑上运行一个完整的 ARM Linux 系统,包括内核启动、进程管理、网络协议栈。
QEMU 的 CPU 模拟核心叫 TCG(Tiny Code Generator,微型代码生成器)。TCG 是一个二进制翻译器:它把 ARM 指令翻译成宿主机的 x86 指令来执行。这个翻译过程分两步:
ARM 指令 ──> TCG 中间表示(IR)──> x86 指令TCG 以"翻译块(Translation Block,TB)"为单位工作:一次翻译一个基本块的指令,翻译结果被缓存起来,下次执行到同一个基本块时直接复用,避免重复翻译。这种设计被称为 DBT(Dynamic Binary Translation,动态二进制翻译),是 QEMU 能达到可接受执行速度的关键。
但 QEMU 对于逆向分析来说太"重"了。你只想执行一个 SO 文件里的一个函数,不需要启动整个 Linux 内核,不需要初始化网卡驱动,不需要挂载文件系统。你需要的只是 QEMU 的 CPU 模拟能力。
Unicorn:把 CPU 模拟能力"切"出来
2015 年,Nguyen Anh Quynh(也是 Capstone 反汇编引擎的作者)创建了 Unicorn Engine。他做了一件精准的手术:从 QEMU 的庞大代码中,只提取 CPU 模拟(TCG)这一层,封装为一个独立的库。
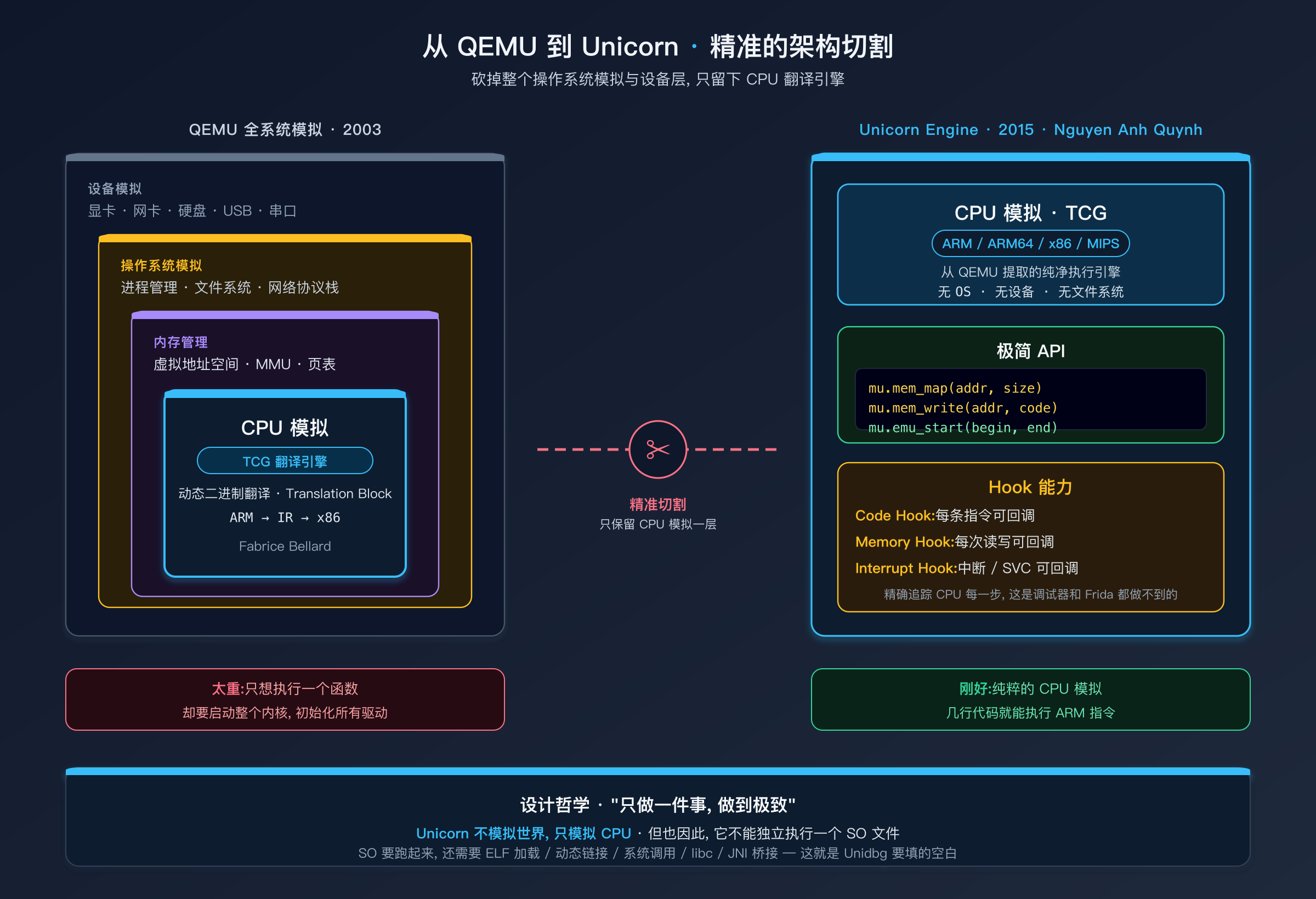
Unicorn 提供了极简的 API:
python
from unicorn import *
from unicorn.arm_const import *
# 创建一个 ARM 模拟器实例,指定架构为 ARM、模式为 Thumb
mu = Uc(UC_ARCH_ARM, UC_MODE_THUMB)
# 在地址 0x1000 处映射一页(4KB)内存,权限为可读可写可执行
mu.mem_map(0x1000, 0x1000)
# 将 ARM 机器码写入映射好的内存
mu.mem_write(0x1000, code)
# 设置 R0 寄存器的初始值(作为函数参数)
mu.reg_write(UC_ARM_REG_R0, 123)
# 从 0x1000 开始执行,到 code 末尾停止
mu.emu_start(0x1000, 0x1000 + len(code))
# 读取 R0 寄存器的值(通常存放函数返回值)
result = mu.reg_read(UC_ARM_REG_R0)这就是 Unicorn 的革命性:你可以在任何平台上,用几行代码,执行一段 ARM 指令。不需要 ARM 设备,不需要操作系统,不需要进程管理。纯粹的 CPU 模拟。
Unicorn 还提供了强大的 Hook 能力:
- Code Hook:每执行一条指令都可以触发回调 --- 相当于在每条指令前后都有一个"探针"
- Memory Hook:每次内存读写都可以触发回调 --- 你可以看到数据的每一次流动
- Interrupt Hook:中断(包括系统调用使用的 SVC 指令)可以触发回调 --- 你可以拦截所有系统调用
这意味着你可以精确追踪 CPU 的每一步操作。这种粒度的监控能力,是调试器和 Hook 框架都无法比拟的。
Unicorn 的局限:只有引擎,没有车
但 Unicorn 只是一个 CPU 模拟器。它能执行 ARM 指令,但不理解这些指令在做什么。
当 SO 代码执行一条 SVC #0 指令(ARM 的系统调用指令,Supervisor Call)时,Unicorn 只知道"发生了一个中断",但不知道这个系统调用是要打开文件还是获取时间。当 SO 代码跳转到 JNI 函数表中的某个地址时,Unicorn 只知道"要执行这个地址的代码",但那个地址上什么代码都没有。
要让一个 Android SO(Shared Object,Linux/Android 的动态链接库,等价于 Windows 的 DLL)文件跑起来,仅有 CPU 模拟是远远不够的。你还需要:
- ELF 加载器 :解析 ELF(Executable and Linkable Format)格式,把 SO 文件的各个段(
.text代码段、.data数据段等)正确加载到内存中 - 动态链接器:处理符号解析和重定位,让 SO 代码中对外部函数的调用能跳转到正确的地址
- 系统调用处理器 :响应
open、read、mmap、clock_gettime等系统调用 - C 运行时库 :提供
malloc、free、printf、strlen等 libc 函数 - JNI 桥接层 :响应
FindClass、GetMethodID、CallObjectMethod等 JNI 调用 - 虚拟文件系统 :响应文件读取请求,包括
/proc/self/maps、/proc/self/status等 procfs 伪文件
这就是 Unidbg 的价值所在。
Unidbg:不是在模拟 CPU,而是在模拟操作系统
Unidbg 由 zhkl0228 创建并持续维护,它在 Unicorn 之上构建了一个最小化但可用的 Android 运行环境。
一个类比可以帮助理解它的定位:
- Unicorn 是发动机 --- 能把燃料转化为动力(把 ARM 指令翻译为 x86 指令执行),但它自己不能上路
- Unidbg 是整辆车 --- 发动机 + 传动系统 + 底盘 + 方向盘 --- 你可以开着它跑了
Unidbg 在 Unicorn 之上添加的每一层,都对应着真实 Android 系统中的一个组件:

关键的一点是:右侧的每一层都是不完整 的。Unidbg 没有实现完整的 Linux 内核,没有完整的 libc,没有完整的 JNI。它实现的是足够让大部分 SO 函数跑起来的最小子集。
这个设计哲学决定了使用 Unidbg 的基本体验:SO 函数第一次跑大概率会报错,报错信息告诉你哪里缺了什么,你补上缺失的部分,再跑,再报错,再补 --- 直到函数正确返回。这就是"补环境"。
"补环境"这个词听起来很技术,但本质很简单:SO 代码在执行过程中会问各种问题("屏幕多高?""现在几点?""这个类存在吗?"),在真机上 Android 系统自动回答这些问题。在 Unidbg 中,大部分问题 Unidbg 自动回答了,少部分需要你来手动回答。"补环境"就是"回答 Unidbg 答不了的问题"。
五个后端引擎:同一个接口,不同的执行方式
Unidbg 的一个重要架构决策是后端可替换 。CPU 模拟层被抽象为一个 Backend 接口,目前有五种实现:
| 后端 | 原理 | 速度 | 分析能力 | 适用场景 |
|---|---|---|---|---|
| Unicorn | 基于 QEMU TCG 的解释执行 | 1x(基准) | 完整 | 兼容性最好 |
| Unicorn2 | Unicorn 改进版,支持多线程调度 | 1.2x | 完整 | 分析(推荐默认) |
| Dynarmic | JIT 编译,ARM 指令编译为本机代码 | 10-100x | 无 | 生产环境 |
| Hypervisor | macOS Hypervisor.framework | 50-200x | 无 | Apple Silicon (M 系列) macOS |
| KVM | Linux 内核虚拟机 | 50-200x | 无 | Linux 生产环境 |
速度差异的根本原因是执行方式不同:
- Unicorn/Unicorn2 是解释执行:每条 ARM 指令都需要翻译为多条 x86 指令,翻译本身有开销。好处是翻译器可以在每条指令前后插入回调
- Dynarmic 是 JIT(Just-In-Time,即时编译)编译:把一段 ARM 代码编译为优化过的本机代码,然后直接执行编译结果。编译一次,执行多次,均摊后开销极低
- Hypervisor/KVM 是硬件虚拟化:利用 CPU 的虚拟化扩展(Intel VT-x、ARM VHE),让 ARM 代码(几乎)直接在硬件上运行,中间没有软件翻译层
速度和分析能力之间存在根本矛盾:
- 解释执行慢,但因为每条指令都经过翻译器,翻译器可以在每条指令执行前后插入回调 --- 所以支持指令级 Hook、内存监控、Trace
- JIT/硬件虚拟化快,但代码直接执行,没有逐指令的翻译步骤,也就没有地方插入回调 --- 所以不支持细粒度监控
这就是为什么不能一个后端通吃:分析和生产是两种根本不同的需求。 分析需要看清每一步(用 Unicorn2),生产只需要跑得快(用 Dynarmic)。理解这一点,你就知道为什么 Unidbg 需要五个后端 --- 不是功能冗余,而是不同场景的最优解完全不同。
同赛道的选手:不同的取舍
Unidbg 不是唯一的用户态模拟器。理解同赛道其他项目的设计取舍,有助于更深刻地理解 Unidbg 的定位。

Qiling Framework
- 语言:Python
- 定位:跨平台二进制分析框架
- 优势 :
- 支持 Windows、Linux、macOS、UEFI 等多种操作系统的二进制文件
- 可以作为 IDA 插件使用(Python 生态的天然优势)
- 社区活跃,文档完善
- 劣势 :
- Android JNI 层的支持远不如 Unidbg 完善
- Python 的执行性能限制了生产环境使用
- 取舍 :选择了广度(跨平台)而非深度(Android JNI)
ExAndroidNativeEmu
- 语言:Python
- 定位:轻量级 Android Native 模拟器
- 优势 :
- 代码量小,容易理解和二次开发
- Python 开发效率高,适合快速验证
- 劣势 :
- 功能不如 Unidbg 完善(支持的系统调用和 JNI 函数更少)
- 没有多后端支持
- 维护不如 Unidbg 活跃
- 取舍 :选择了简洁性,牺牲了功能完整度
AndroidNativeEmu
- 语言:Python
- 定位:ExAndroidNativeEmu 的前身
- 现状:维护较少,大部分用户已转向 ExAndroidNativeEmu 或 Unidbg
Unidbg 的定位
在这个光谱中,Unidbg 选择了深度:
- Java 语言 --- 与 Android 开发生态天然兼容,调用 Android SDK 的类无需额外桥接
- 五种后端引擎 --- 从分析到生产全覆盖
- 最完善的 JNI 桥接 --- 约 230 个 JNIEnv 函数指针实现,覆盖 JNI 规范几乎全部接口
- 最活跃的维护 --- 持续更新系统调用和 JNI 支持
- 生产化能力 --- 通过 Dynarmic/KVM 后端支持高并发签名计算服务
代价是:
- Java 生态限制了与 IDA(Python/IDC 脚本)等基于脚本语言的逆向工具的直接集成
- 学习曲线较陡 --- 需要理解 JNI、系统调用、ELF 加载等多个层面的知识
- 只专注于 Android(和部分 iOS)
回到"为什么"
Unidbg 代表的是动态分析工具进化路线上的当前最优解 --- 在 Android Native 逆向这个特定领域。它不是银弹,也不能替代 Frida(有些场景下真机运行就是最好的方案)。但对于需要脱离设备依赖、需要完全控制执行环境、需要指令级追踪、需要批量化生产的场景,它是目前最成熟的选择。
理解了这条技术脉络,你就不会把 Unidbg 当成一个"黑盒工具"来用。你知道它的 CPU 模拟来自 QEMU/Unicorn,知道它的操作系统模拟是不完整的(所以需要补环境),知道它的后端选择反映了分析与性能的矛盾,知道它在同类工具中选择了深度而非广度。
这些"为什么",比"怎么用"更重要。 因为当你遇到 Unidbg 解决不了的问题时,理解"为什么"能告诉你该换什么工具;而只知道"怎么用"只会让你在错误的方向上越陷越深。