目录
1、堆排序
我们在之前的建堆实现过程中,需要我们先定义一个结构体来定义一个堆,让后在进行堆的push和pop,会很麻烦,而直接建堆是在数组上直接将无序的数组进行建堆,这样我们就抛开了堆的数据结构这个思想,只需要用堆结构中的向上调整建堆和向下调整建堆。我们在写直接建堆之前先把向上建堆和向下建堆的代码先复习一遍。
堆排序的过程:1.先使无序的数组变成堆 。
2.让后交换首尾节点里的值,接着再对堆进行调整。
1.1Swap交换值

1.2向上调整建堆
思想:向上调整的过程就是让孩子节点不断的和父亲节点比较,使无序的数组变成堆,让后如果孩子节点比父亲节点大,就交换两个节点里的值,让后再更新下标,再进行重复一轮的比较

1.2.1向上调整的时间复杂度(N*logN)
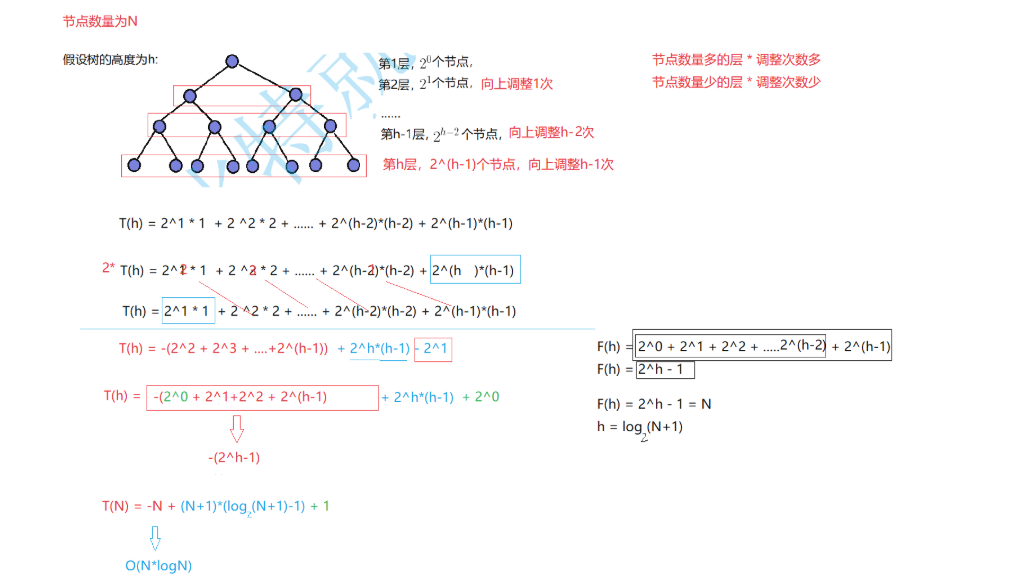
思想:向上调整建堆是从第二个节点开始向上进行调整的,假设一共有N个节点,高度为h,则存在关系式:N=2^h-1;而每层的节点数和向上调整的高度的乘积是等比×等差,每一层的和就是他们的时间复杂度。经下图的分析可得T(h)=(h-2)2^(h-1)+1;将N与h的关系代入得T=(1/2)(log^(N+1)-2)(N+1)+1约等于N*logN,具体推导过程如下图。
1.3向下调整建堆(从根节点开始向下调整建队)
从根节点开始向下调整建堆的前提是必须先保障左右子树是堆
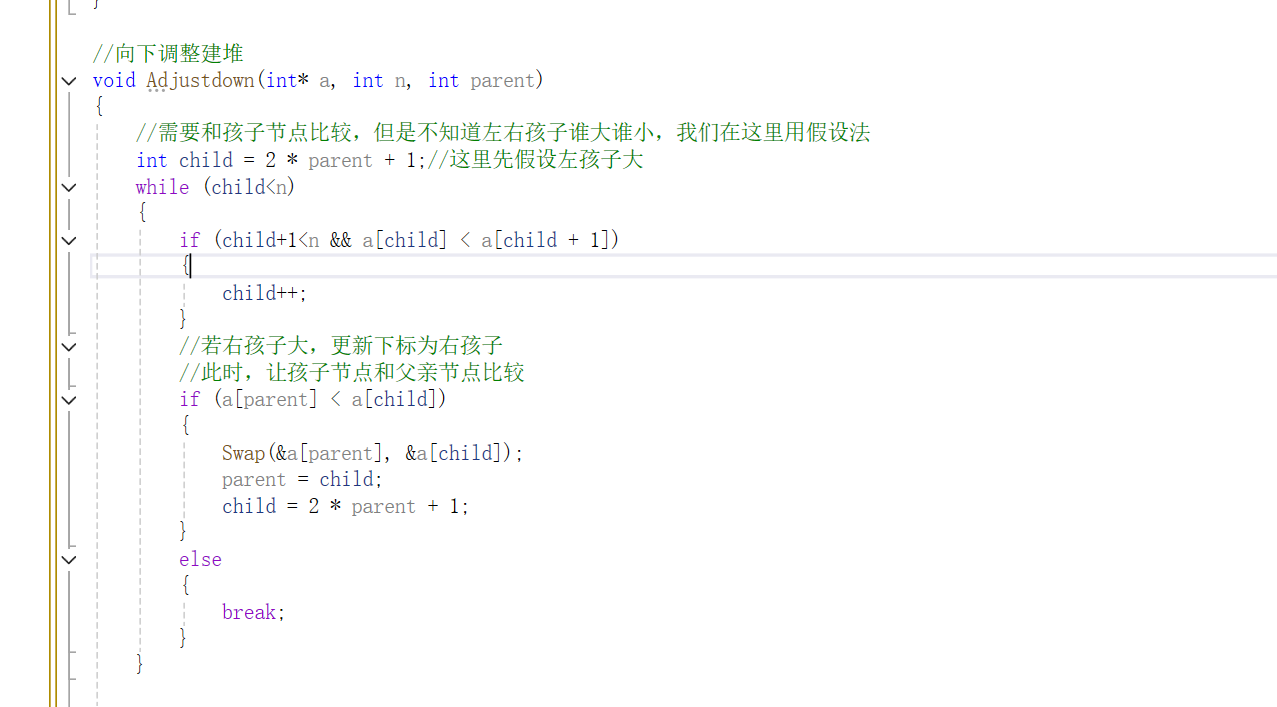
这里有一个易错点,就是这个假设左孩子的时候,需要注意比较的时候右孩子存在不存在,如果没有考虑这个条件,会导致非法访问右孩子的下标。(child+1<n)
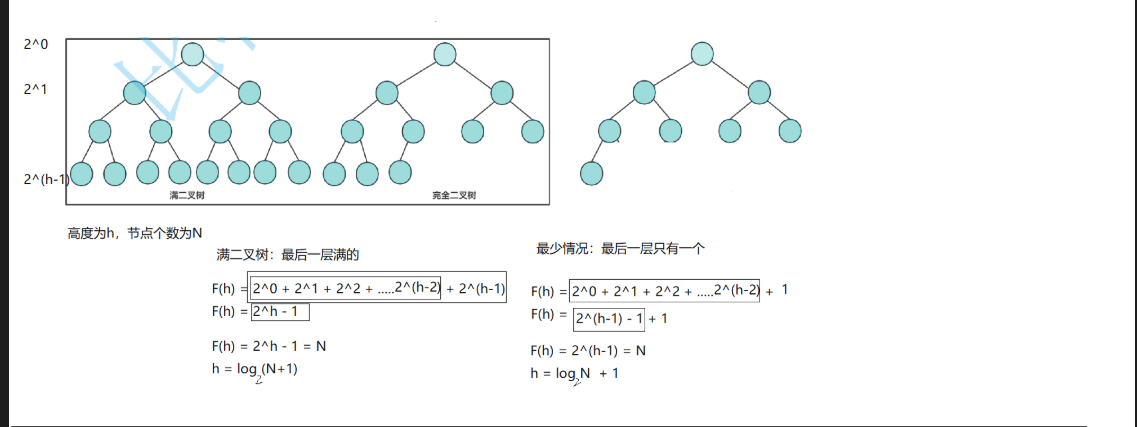
对于下面的图我们分两种情况,左图是满二叉树,右图是完全二叉树
(1)满二叉数的N和h的关系是h=log(N+1),
(2)完全二叉树的N和h的关系是h=logN+1;
但是它们的关系都可以简化为h=logN;
接下来我们来推到 一下从根节点向下进行调整堆的时间复杂度,此时,我们以最坏的情况来看,这个堆除了最后一层叶子节点不用调整外,其他的非叶子节点都需要进行调整,而最后一层的节点约等于N/2;相当于总结点的一半,此时,我们从第一层开始向下进行调整,则我们这里会写下一个h的关系式:T=2^0*(h-1)+2^1*(h-2)+.......+2^(h-2)*1,化简之后为T=2^h-h-1,将h与N的关系代入得
T=N-log(N+1)约等于N,所以它得时间复杂度是O(N)???
注意注意,这个答案是错误的,
那为什么在算法领域,大家依然强调从根节点开始遍历效率低,甚至有时会说是 O(N log N) 呢?
常数项与系数的差异:
虽然都是 O(N),但标准建堆的精确公式推导出来是 N - \log N - 1,而刚才从根节点遍历推导出来的是 2N - \log N - 2(注意:刚才推导中的 2^h 在标准建堆的推导中对应的是 2^{h-1} 量级,系数差了整整一倍)。在海量数据下,从根节点遍历的实际运行时间大约是标准建堆的 2倍。
算法前提的破坏(核心原因):
向下调整(siftDown)的硬性前提是"左右子树必须已经是堆"。从根节点开始遍历时,这个前提完全不成立。这种"盲目下沉"在逻辑上是错误的,它无法保证把当前节点放到最终的正确位置,往往需要后续反复的、额外的调整才能修正。
O(N log N) 说法的来源:
在算法教学中,为了警示大家不要破坏 siftDown 的前提,通常会将这种"暴力遍历"的复杂度,类比为向上调整建堆(siftUp)的复杂度。向上调整建堆(从第2个元素开始不断向上冒泡)的复杂度是严格的 O(N log N)。
总结一下:
你的纠正非常精准,根节点的代价确实是 h-1。即使把这个修正代入,从根节点遍历的数学代价依然是 O(N)(系数约为2)。但由于它违背了算法的核心前提,且实际效率只有标准建堆(系数约为1)的一半,所以从最后一个非叶子节点开始的自底向上建堆,才是唯一正确且最高效的标准做法。
1.4向下调整建堆(从最后一个非叶子节点开始向下调整建堆)
为了更好的优化建堆,我们一般采用自下而上的方式进行建堆,这样避免还得考虑左右子树必须是堆的前提,而上面的根节点还需要先考虑左右子树是堆的情况。

从最后一个非叶子节点开始向下调整建堆只是改变了parent节点的下标,上面从根节点向下调整建堆的下标是从根节点开始的,而这里的从非叶子节点的下标是从最后一个父亲节点开始的,所以只需要改变一下起始的下标就行了,其他都没变。
1.4.1逆向向下调整的时间复杂度(N)
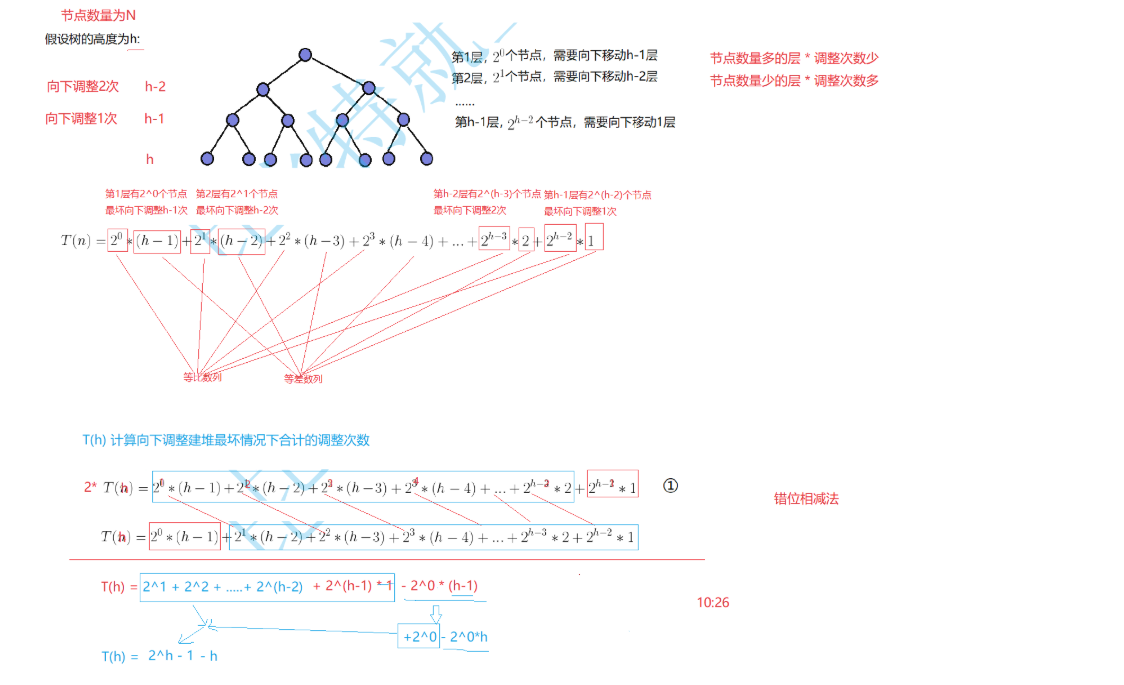

逆向向下调整建堆除了最后一层的叶子节点之外,所有的非叶子节点都需要进行调整,所以上面的等差*等比的和就是总的实现复杂度,可以看出上面计算所得T(h)=2^h-1-h,又因为h与N的关系N=2^h-1,将这个式子带入到总的时间复杂度当中得:T(h)=N-log(N+1)约等于N,所以这种方法的向下调整建堆的复杂度是O(N)
2堆排序的实现过程
2.1堆排序的实现过程(向上调整建堆)(N*logN)
原则:(升序建大堆,降序建小堆)

这个就是先给定一个无序的数组,让后先建大堆,让后交换,再接着调整堆,此时需要注意的是向下调整建堆的元素个数需要--;
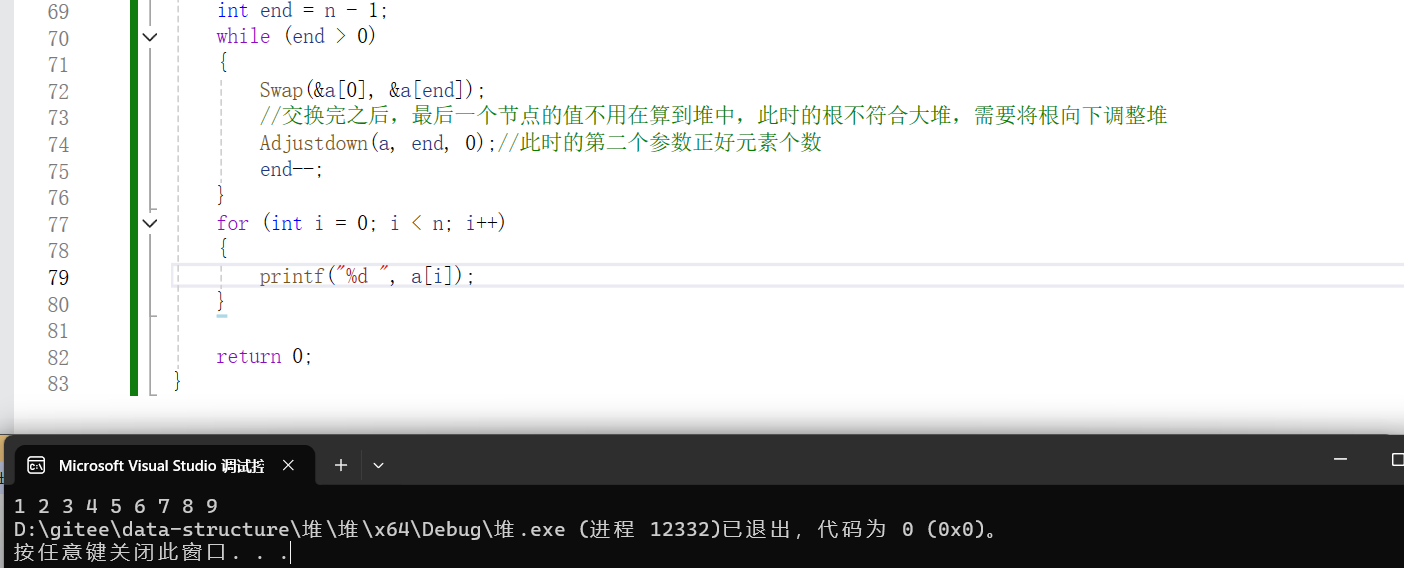
上面就是采用建大堆得到的是升序的过程,但是这种建堆的复杂度较高,(1)向上调整建堆的复杂度是O(N*logN),(2)交换+调整堆的复杂度是O(N*logN),而堆排序由这两部组成,总的时间复杂度是O(N*logN)。
2.2堆排序的实现过程(向下调整建堆)(N)
我们一般用向下调整建堆一般以自下而上的建堆方法,也就是从最后一个非叶子节点开始自上而下调整建堆,这样在建堆的这一步的复杂度就能得到大大的改善。具体的代码实现和向上调整建堆实现堆排序的代码没有太大的差距,只不过是在建堆这部分有点不同,具体代码如下:
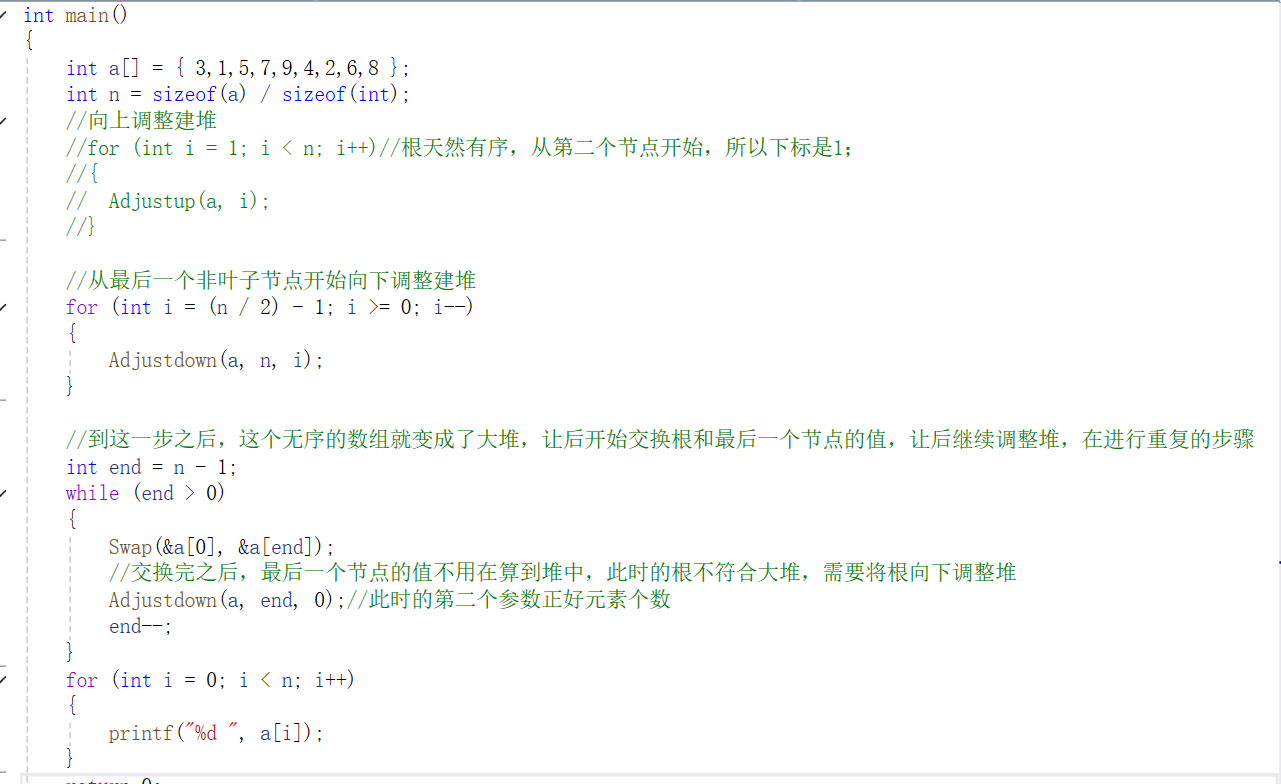 在上面的代码截图当中可以看出就只是在建堆这个部分改变了,其他的交换和重新调整堆,都没有改变,而它的复杂度是:(1)向上调整建堆的复杂度是O(N),(2)交换+调整堆的复杂度是O(N*logN),而堆排序由这两部组成和,总的时间复杂度是O(N)。
在上面的代码截图当中可以看出就只是在建堆这个部分改变了,其他的交换和重新调整堆,都没有改变,而它的复杂度是:(1)向上调整建堆的复杂度是O(N),(2)交换+调整堆的复杂度是O(N*logN),而堆排序由这两部组成和,总的时间复杂度是O(N)。