目录
- 前言
- [一、lambda 表达式](#一、lambda 表达式)
-
- [1.1 lambda 表达式语法](#1.1 lambda 表达式语法)
- [1.2 捕捉列表](#1.2 捕捉列表)
- [1.3 lambda 的应用](#1.3 lambda 的应用)
- [1.4 lambda 的原理](#1.4 lambda 的原理)
- 二、包装器
-
- [2.1 function](#2.1 function)
- [2.2 function 底层原理](#2.2 function 底层原理)
- [2.3 逆波兰表达式求值](#2.3 逆波兰表达式求值)
- 三、绑定器
-
- [3.1 bind](#3.1 bind)
- [3.2 bind 底层原理](#3.2 bind 底层原理)
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》《笔试算法》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、lambda 表达式
Lambda 表达式是 C++11 引入的核心特性,本质是一个匿名函数对象,它最大的优势是可以定义在函数内部,极大简化了可调用对象的编写,广泛应用于 STL 算法、线程、智能指针等场景。
1.1 lambda 表达式语法
1. 核心语法格式
cpp
[capture-list] (parameters) -> return-type { function-body }
lambda 表达式语法使用层而言没有类型,所以我们一般是用 auto 或者模板参数定义的对象去接收 lambda 对象
2. 基础代码示例
cpp
#include <iostream>
using namespace std;
int main() {
// 完整写法:显式指定返回值类型
auto add1 = [](int x, int y)->int { return x + y; };
cout << add1(1, 2) << endl; // 输出 3
// 简化写法:省略参数列表(无参数)、省略返回值(自动推导)
auto func1 = [] {
cout << "hello bit" << endl;
return 0;
};
func1(); // 输出 hello bit
// 引用传参示例:实现交换
int a = 0, b = 1;
auto swap1 = [](int& x, int& y) {
int tmp = x;
x = y;
y = tmp;
};
swap1(a, b);
cout << a << ":" << b << endl; // 输出 1:0
return 0;
}需要补充一点,尾置返回类型并不是lambda的特权,普通函数也有
1.2 捕捉列表
Lambda 默认只能使用自身参数和函数体内定义的变量,如果要使用外层作用域的变量,必须通过捕捉列表显式或隐式捕获。
1. 三种捕捉方式
(1)显式捕捉:明确指定要捕获的变量
- 值捕捉:x, y,捕获变量的拷贝,Lambda 内部修改的是拷贝,不影响原变量
- 引用捕捉:\&x, \&y,捕获变量的别名,Lambda 内部修改会直接影响原变量
- 混合显式捕捉:x, \&y,x 值捕捉,y 引用捕捉
(2)隐式捕捉:编译器自动捕获用到的变量
- =:所有用到的外层变量都采用值捕捉
- \&:所有用到的外层变量都采用引用捕捉
(3)混合捕捉:隐式 + 显式结合
语法规则:
- 第一个元素必须是 = 或 &,指定默认捕捉方式
- 显式指定的变量必须使用与默认相反的捕捉方式
-
- =, \&x, \&y:默认值捕捉,x 和 y 单独引用捕捉
-
- \&, x, y:默认引用捕捉,x 和 y 单独值捕捉
2. 捕捉的范围限制
- 只能捕捉Lambda 定义位置 之前的普通局部变量
- 静态局部变量和全局变量不需要捕捉,可以直接在 Lambda 内部使用
- 如果 Lambda 定义在全局作用域,捕捉列表必须为空(没有可捕获的局部变量)
3. mutable 修饰符
- 默认情况下,值捕捉的变量是 const 修饰的,Lambda 内部不能修改
- 在参数列表后加 mutable 可以取消 const 限制,允许修改值捕捉的变量
- ⚠️ 注意:修改的仍然是变量的拷贝,不会影响外层原变量
- ⚠️ 强制要求:使用 mutable 后,参数列表 () 不能省略,即使没有参数也要写
cpp
#include <iostream>
using namespace std;
int x = 0; // 全局变量,不需要捕捉
//Lambda表达式可以写到全局,但此时捕捉列表必须为空,因为全局变量不用捕捉就可以用
//此时若捕捉x会报错
//auto func1 = [x]()
//{
// x++;
//};
int main() {
int a = 0, b = 1, c = 2, d = 3;
// 1. 显式捕捉:a 值捕捉,b 引用捕捉
auto func1 = [a, &b] {
// a++; // 错误:值捕捉的变量默认是 const,不能修改
b++; // 正确:引用捕捉可以修改,影响原变量
return a + b;
};
cout << func1() << endl; // 输出 0+2=2
cout << "b=" << b << endl; // 输出 b=2
// 2. 隐式值捕捉:自动捕捉用到的 a、b、c
auto func2 = [=] {
return a + b + c;
};
cout << func2() << endl; // 输出 0+2+2=4
// 3. 隐式引用捕捉:自动捕捉用到的 a、c、d
auto func3 = [&] {
a++;
c++;
d++;
};
func3();
cout << a << " " << b << " " << c << " " << d << endl; // 输出 1 2 3 4
// 4. 混合捕捉:默认引用捕捉,a、b 单独值捕捉
auto func4 = [&, a, b] {
// a++; b++; // 错误:值捕捉默认 const
c++; d++; // 正确:引用捕捉
return a + b + c + d;
};
func4();
cout << a << " " << b << " " << c << " " << d << endl; // 输出 1 2 4 5
// 5. 混合捕捉:默认值捕捉,a、b 单独引用捕捉
auto func5 = [=, &a, &b] {
a++; b++; // 正确:引用捕捉
// c++; d++; // 错误:值捕捉默认 const
return a + b + c + d;
};
func5();
cout << a << " " << b << " " << c << " " << d << endl; // 输出 2 3 4 5
// 6. 静态局部变量:不需要捕捉,直接使用
static int m = 0;
auto func6 = [] {
return x + m; // 全局变量 x 和静态变量 m 都不需要捕捉
};
cout << func6() << endl; // 输出 0+0=0
// 7. mutable 修饰:允许修改值捕捉的变量
auto func7 = [=]() mutable {
a++; b++; c++; d++; // 现在可以修改值捕捉的变量
return a + b + c + d;
};
cout << func7() << endl; // 输出 3+4+5+6=18
cout << a << " " << b << " " << c << " " << d << endl; // 原变量不变:2 3 4 5
return 0;
}下面再说一下 Lambda 在类中的使用
Lambda 在类的非静态成员函数中使用时,有一套特殊的捕捉规则,核心围绕 this 指针展开,这也是最容易出错的地方。
cpp
#include <iostream>
using namespace std;
class A
{
public:
void func()
{
int x = 0, y = 1;
cout << "初始状态:x=" << x << ", y=" << y << ", _a1=" << _a1 << ", _a2=" << _a2 << endl << endl;
// 1. 隐式值捕捉 [=]:自动隐式捕捉 this 指针
auto f1 = [=]
{
_a1++; // 等价于 this->_a1++,修改原对象的成员
return x + y + _a1 + _a2;
};
cout << "f1() 输出:" << f1() << endl;
cout << "调用f1后:_a1=" << _a1 << endl << endl;
// 2. 隐式引用捕捉 [&]:自动隐式捕捉 this 指针
auto f2 = [&]
{
x++; // 修改原局部变量 x
_a1++; // 修改原对象的成员
return x + y + _a1 + _a2;
};
cout << "f2() 输出:" << f2() << endl;
cout << "调用f2后:x=" << x << ", _a1=" << _a1 << endl << endl;
// 3. 错误示例1:只捕捉局部变量,不捕捉 this
// auto f3 = [x]
// {
// return x + _a1 + _a2; // 编译错误!找不到 this 指针
// };
// 4. 错误示例2:直接捕捉成员变量(最常见误区)
// auto f4 = [x, _a1]
// {
// return x + _a1; // 编译错误!_a1 不是当前作用域的局部变量
// };
// 5. 显式捕捉 this(推荐写法):清晰明确
auto f5 = [x, this]
{
_a1++; // 通过 this 指针修改原对象的成员
return x + _a1 + _a2;
};
cout << "f5() 输出:" << f5() << endl;
cout << "调用f5后:_a1=" << _a1 << endl << endl;
}
private:
int _a1 = 0;
int _a2 = 1;
};
int main()
{
A a;
a.func();
return 0;
}1. 核心规则:访问非静态成员变量必须捕捉 this 指针
Lambda 不能直接访问类的成员变量,必须通过捕捉当前对象的 this 指针来间接访问。所有在 Lambda 内部写的 _a1、_a2,编译器都会自动补全为 this->_a1、this->_a2。
2. 两种捕捉 this 的方式
(1)隐式捕捉 this(编译器自动完成)
在类的非静态成员函数中:
- =(隐式值捕捉):会自动隐式捕捉 this 指针
- \&(隐式引用捕捉):会自动隐式捕捉 this 指针
⚠️ 注意:this 是指针,值捕捉和引用捕捉效果完全一样,都能修改原对象的成员。
(2)显式捕捉 this(推荐写法)
直接在捕捉列表中写 this,显式声明要捕捉当前对象的指针。
可以和其他局部变量的捕捉混合使用:x, this、\&x, this
3. 绝对禁止:直接捕捉成员变量
捕捉列表只能捕捉当前函数作用域内的局部变量
成员变量属于对象,不属于成员函数的局部作用域,不能直接写 _a1 捕捉
所有成员变量必须通过 this-> 间接访问
1.3 lambda 的应用
在 Lambda 出现之前,C++ 的可调用对象只有函数指针 和仿函数:
- 函数指针:类型定义复杂,灵活性差
- 仿函数:需要单独定义一个类,代码冗余
Lambda 完美解决了这些问题,让可调用对象的编写变得简洁高效。
最常用场景:STL 算法的自定义比较
以 std::sort 排序为例,对比仿函数和 Lambda 的写法:
cpp
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
using namespace std;
struct Goods {
string _name; // 商品名称
double _price; // 商品价格
int _evaluate; // 商品评分
Goods(const char* str, double price, int evaluate)
: _name(str), _price(price), _evaluate(evaluate)
{}
};
// 传统仿函数写法:需要单独定义类
struct ComparePriceLess {
bool operator()(const Goods& g1, const Goods& g2) {
return g1._price < g2._price;
}
};
struct ComparePriceGreater {
bool operator()(const Goods& g1, const Goods& g2) {
return g1._price > g2._price;
}
};
int main() {
vector<Goods> v = {
{"苹果", 2.1, 5}, {"香蕉", 3, 4},
{"橙子", 2.2, 3}, {"菠萝", 1.5, 4}
};
// 1. 传统仿函数写法
sort(v.begin(), v.end(), ComparePriceLess());
sort(v.begin(), v.end(), ComparePriceGreater());
// 2. Lambda 写法1: 定义一个Lambda对象 + 传参
auto priceLess = [](const Goods& g1, const Goods& g2)
{
return g1._price < g2._price;
};//注意这里的Lambda作为一个语句的结束是有分号的
sort(v.begin(), v.end(), priceLess);
// 2. Lambda 写法2:直接在算法参数中定义,Lambda 表达式本质就是一个对象,无需额外代码
// 按价格升序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price < g2._price;
});//这里的Lambda表达式作为一个实参是没有分号的
// 按价格降序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._price > g2._price;
});
// 按评分升序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate < g2._evaluate;
});
// 按评分降序
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) {
return g1._evaluate > g2._evaluate;
});
return 0;
}1.4 lambda 的原理
lambda 只是C++ 语法糖 ,编译时编译器会自动生成一个独一无二的仿函数类 (重载operator()的类,又称函数对象类);代码里写的 lambda 语法全部映射到这个自动生成的类,汇编层面不存在 "lambda" 特殊指令,运行逻辑和手写仿函数完全一致。
一、Lambda 语法段 ↔ 编译器生成仿函数类
lambda 完整语法:捕捉列表 -> 返回类型 {函数体},每一段语法都对应自动生成类的组件
示例 lambda 代码
cpp
int a = 10, b = 20;
auto func5 = [a, &b](int x) {
++b;
return a + b + x;
};
func5(1);编译器自动生成的等价仿函数类
cpp
// 编译器自定义类名(每个lambda类名唯一,避免类型冲突)
class lambda5 {
public:
// 1. 自动生成构造函数:对应【捕捉列表】
// 参数和捕捉列表变量一一对应,初始化列表给私有成员赋值
lambda5(int a_, int& b_)
: a(a_), b(b_)
{}
// 2. 重载operator():对应【lambda形参、函数体、返回值】
int operator()(int x) const {
++b;
return a + b + x;
}
private:
// 3. 私有成员变量:对应【捕捉列表的变量】
const int a; // 值捕获:拷贝外部变量,默认const不可修改
int& b; // 引用捕获:绑定外部原变量,修改会同步外部
};
// auto func5 = lambda5(a, b); // lambda定义语句等价:实例化仿函数对象
func5(1); // 等价调用:func5.operator()(1)1. 捕捉列表 a, \&b
- 值捕获a:生成const int a私有成员(默认const,无法修改拷贝值);
- 引用捕获&b:生成int& b引用成员,直接关联外部原始变量;
- 编译器自动生成带参构造函数 ,定义
auto func5 = lambda时,会把外部a、b传入构造函数,初始化对象内的成员。
2. 形参列表(int x) + 函数体 + 返回值
全部映射到类里重载的operator()成员函数:
- lambda 形参 =
operator()形参; - lambda 大括号内代码 =
operator()函数体; - lambda 返回值(自动推导 / 显式
->)=operator()返回值。
3. 调用func5(1)
底层等价调用仿函数对象的operator(),即func5.operator()(1)。
4. 空捕获\[\]的 lambda
cpp
auto func1 = []{cout << "hello world";};生成的仿函数类无私有成员、空参构造:
cpp
class lambda_xxx {
public:
void operator()() const { cout << "hello world"; }
};
auto func1 = lambda_xxx(); // 无参构造实例化
func1(); // func1.operator()();二、手写仿函数 vs Lambda 自动生成仿函数
- 手写仿函数代码
cpp
class Rate
{
public:
// 构造函数:接收外部rate,存入私有成员
Rate(double rate) : _rate(rate) {}
// 重载():存储计算逻辑
double operator()(double money, int year)
{
return money * _rate * year;
}
private:
double _rate; // 存储捕获的外部变量
};
// 使用逻辑
double rate = 0.49;
Rate r1(rate); // 实例化,传入外部rate
r1(10000, 2); // 调用operator()执行逻辑- 功能完全等价的 Lambda
cpp
auto r2 = [rate](double money, int year) {
return money * rate * year;
};
// 使用逻辑
r2(10000, 2);- Lambda 等价的自动生成类
cpp
class lambda_1 {
public:
lambda_1(double rate_) : _rate(rate_) {}
double operator()(double money, int year) const {
return money * rate * year;
}
private:
const double _rate; // 值捕获生成const私有成员
};
auto r2 = lambda_1(rate);
r2.operator()(10000, 2);二者唯一区别:手写仿函数需要开发者手动写完整类,lambda 由编译器自动生成整套类代码
感兴趣的兄弟也可以在编译器上打开 lambda 的汇编看一下
二、包装器
std::function 是C++11 引入的可调用对象包装器 ,是定义在 < functional > 头文件中的类模板。它能统一包装所有符合签名的可调用对象(普通函数、函数指针、仿函数、lambda 表达式、静态 / 普通成员函数、bind 表达式),解决了 C++ 中可调用对象类型碎片化、无法统一存储和传递的核心痛点。
2.1 function
为什么必须要有它?
这是 C++ 的历史遗留问题:所有能被()调用的东西,类型都不一样 。
最典型的就是 lambda:哪怕两个 lambda 写得一字不差,它们也是完全不同的独立类型:
cpp
auto add1 = [](int a, int b){ return a+b; };
auto add2 = [](int a, int b){ return a+b; };
// add1 和 add2 类型不同!不能互相赋值,也不能存入同一个容器再加上普通函数、仿函数、成员函数,类型更是千差万别。这就导致一个致命问题:你没法把这些不同类型的可调用对象,放到同一个数组、同一个 map 里统一管理。
比如你想做一个计算器,把 "+-*/" 四个运算存到一个 map 里,没有std::function根本做不到 ------map 的 value 只能是同一个类型。std::function就是来解决这个问题的:它把所有不同类型的可调用对象,都包装成同一个类型的盒子。
一、基本语法与模板原型
1. 模板原型
cpp
// 主模板:仅占位,未定义
template <class T>
class function;
// 实际使用的偏特化版本
template <class Ret, class... Args>
class function<Ret(Args...)>;Ret:被包装可调用对象的返回值类型
Args...:被包装可调用对象的参数类型包(支持可变参数)
2. 定义格式
cpp
std::function<返回值类型(参数类型1, 参数类型2, ...)> 变量名;包装 "接收两个 int,返回 int" 的可调用对象:function<int(int, int)>
包装 "无参数、无返回值" 的可调用对象:function<void()>
二、核心能力:包装所有类型的可调用对象
std::function 可以包装 C++ 中所有符合签名的可调用对象,以下是完整的 6 种场景示例:
cpp
#include <functional>
#include <iostream>
#include <map>
#include <stack>
#include <vector>
using namespace std;
// 1. 普通函数
int f(int a, int b) {
return a + b;
}
// 2. 仿函数类(重载operator()的类)
struct Functor {
int operator()(int a, int b) {
return a + b;
}
};
// 3. 包含静态/普通成员函数的类
class Plus {
public:
Plus(int n = 10) : _n(n) {}
// 静态成员函数
static int plusi(int a, int b) {
return a + b;
}
// 普通成员函数(隐含this指针参数)
double plusd(double a, double b) {
return (a + b) * _n;
}
private:
int _n;
};1. 包装普通函数
cpp
function<int(int, int)> f1 = f;
cout << f1(1, 1) << endl; // 输出2直接将普通函数名赋值给function对象,底层等价于包装函数指针。
2. 包装仿函数对象
cpp
function<int(int, int)> f2 = Functor();
cout << f2(1, 1) << endl; // 输出2仿函数是重载了operator()的类对象,function直接包装该对象,调用时执行其operator()。
3. 包装 lambda 表达式(最常用)
cpp
function<int(int, int)> f3 = [](int a, int b) { return a + b; };
cout << f3(1, 1) << endl; // 输出2这是std::function最核心的使用场景:解决了 lambda 类型唯一、无法存入容器的问题。
4. 包装静态成员函数
cpp
//成员函数要指定类域并且前面加&才能获取地址
function<int(int, int)> f4 = &Plus::plusi;
cout << f4(1, 1) << endl; // 输出2静态成员函数没有隐含的 this 指针 ,签名和普通函数完全一致,包装方式相同。
注意:必须加&取地址符,C++ 不允许静态成员函数隐式转换为函数指针。
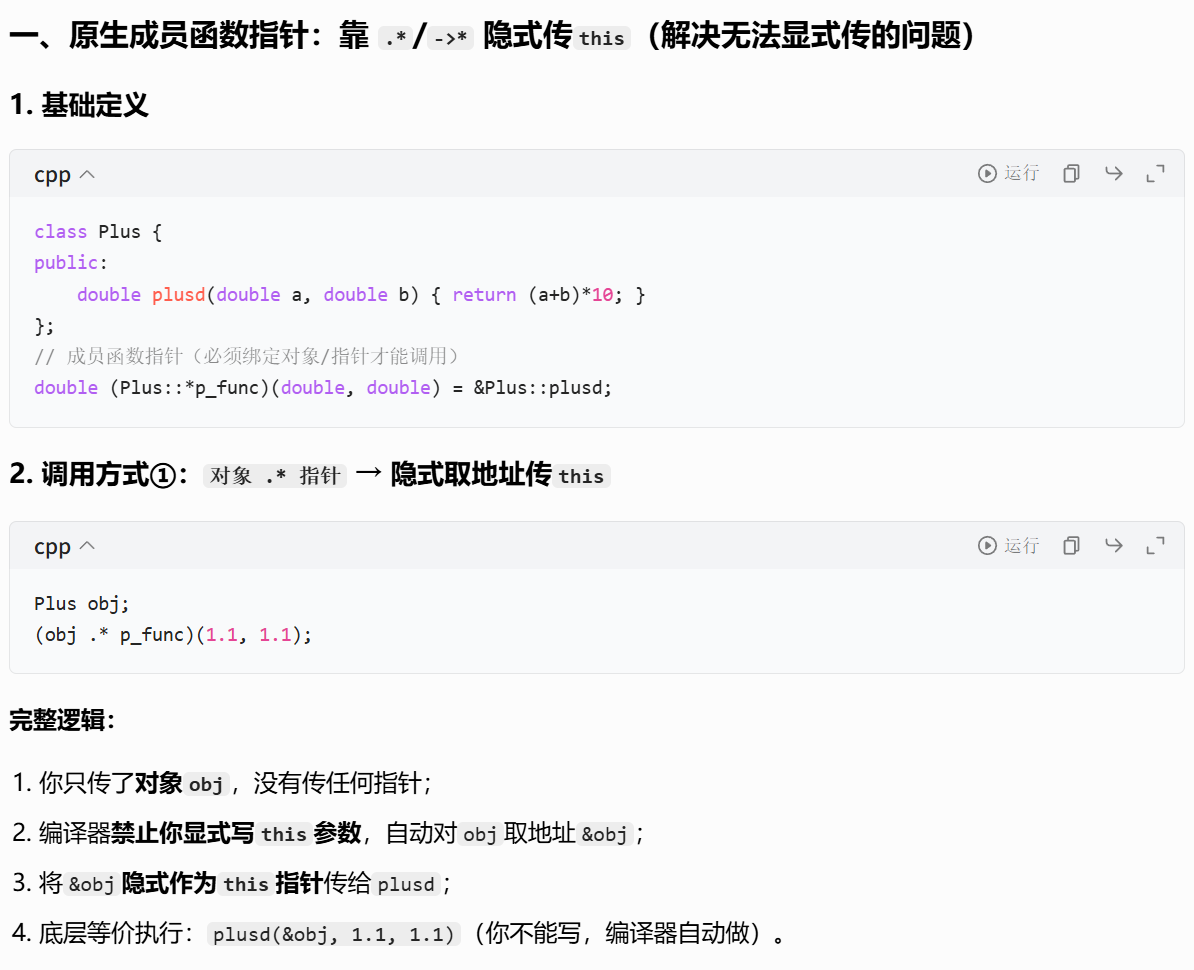
5. 包装普通成员函数(重点难点)
普通成员函数有一个隐含的this指针参数,因此它的实际签名和表面声明不同。例如Plus::plusd的实际签名是:
cpp
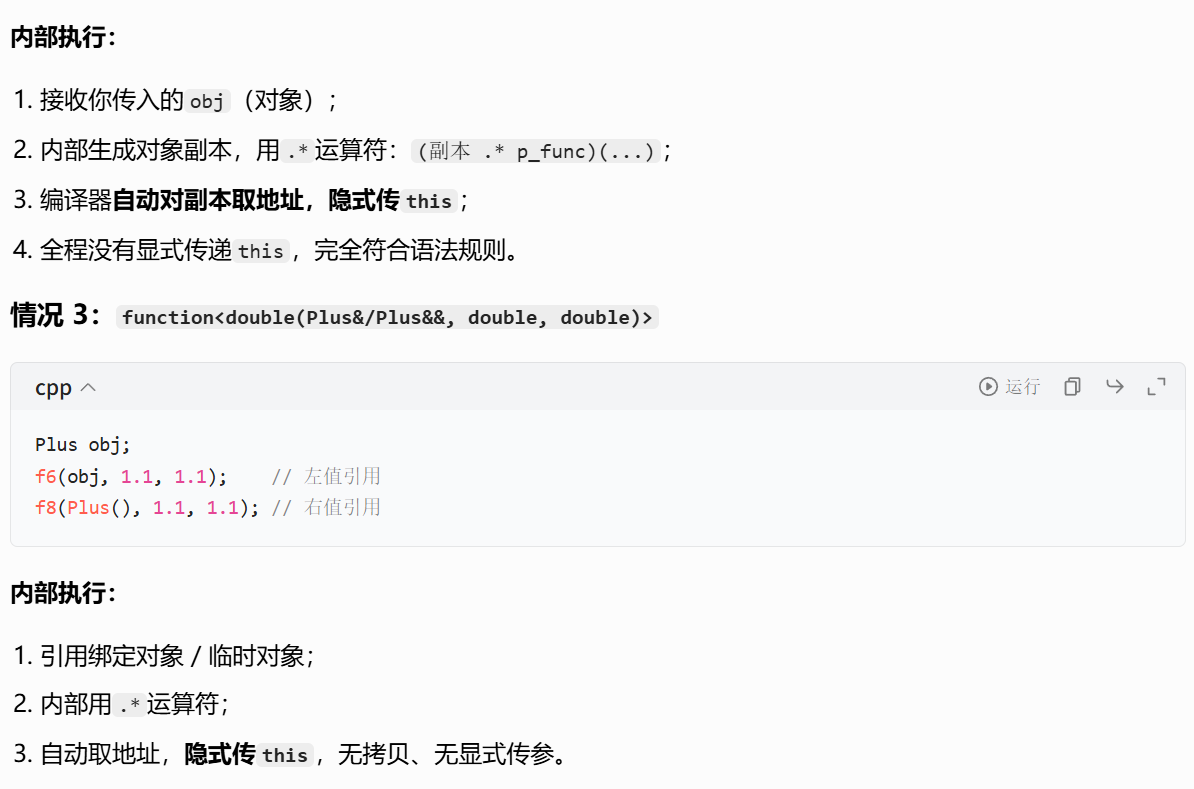
double plusd(Plus* this, double a, double b);因此包装时,function的第一个参数必须是对象的类型(指针、值、右值引用):
方式 1:传对象指针(最常用)
cpp
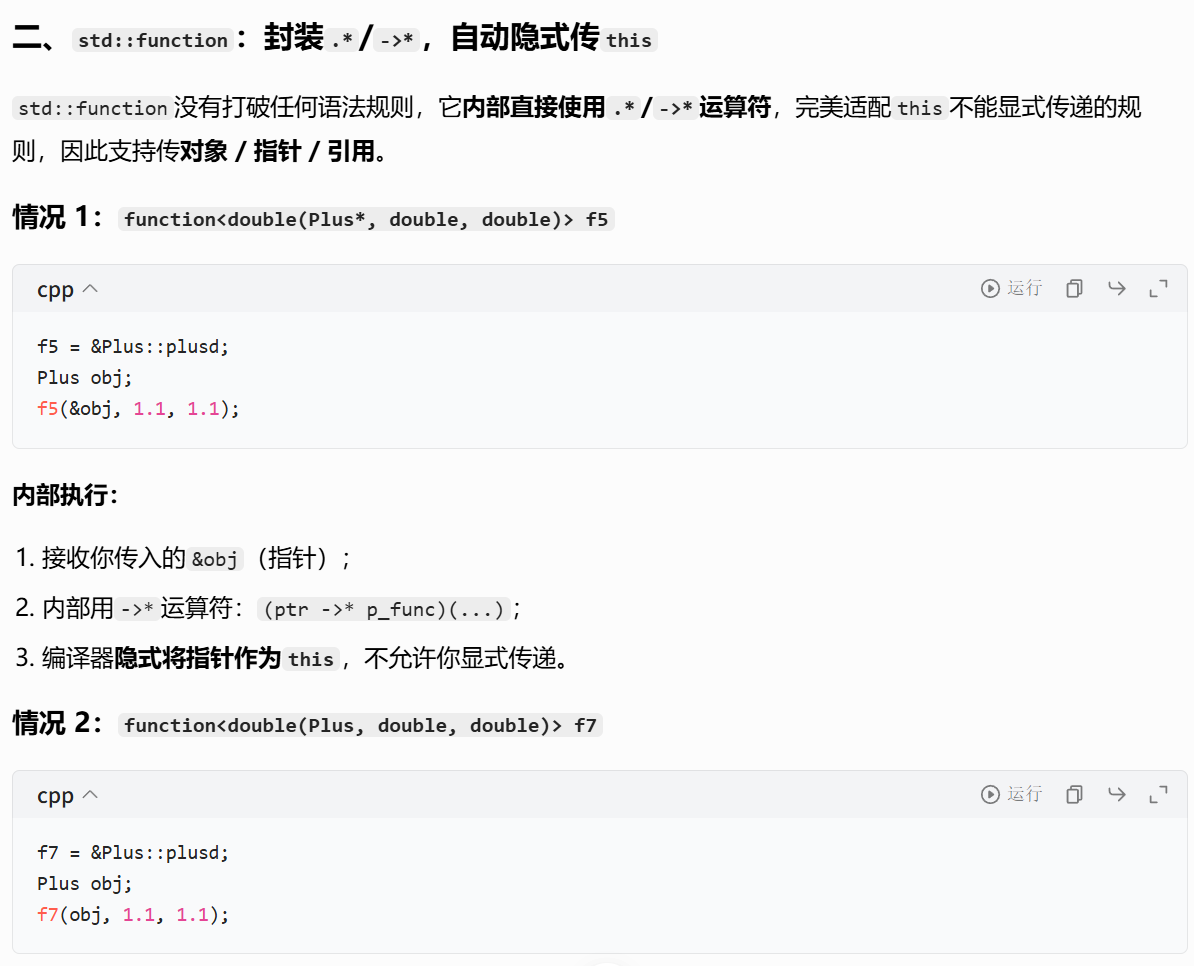
function<double(Plus*, double, double)> f5 = &Plus::plusd;
Plus pd;
cout << f5(&pd, 1.1, 1.1) << endl; // 输出(1.1+1.1)*10=22调用时第一个参数传入对象地址,作为this指针,修改成员会影响原对象。
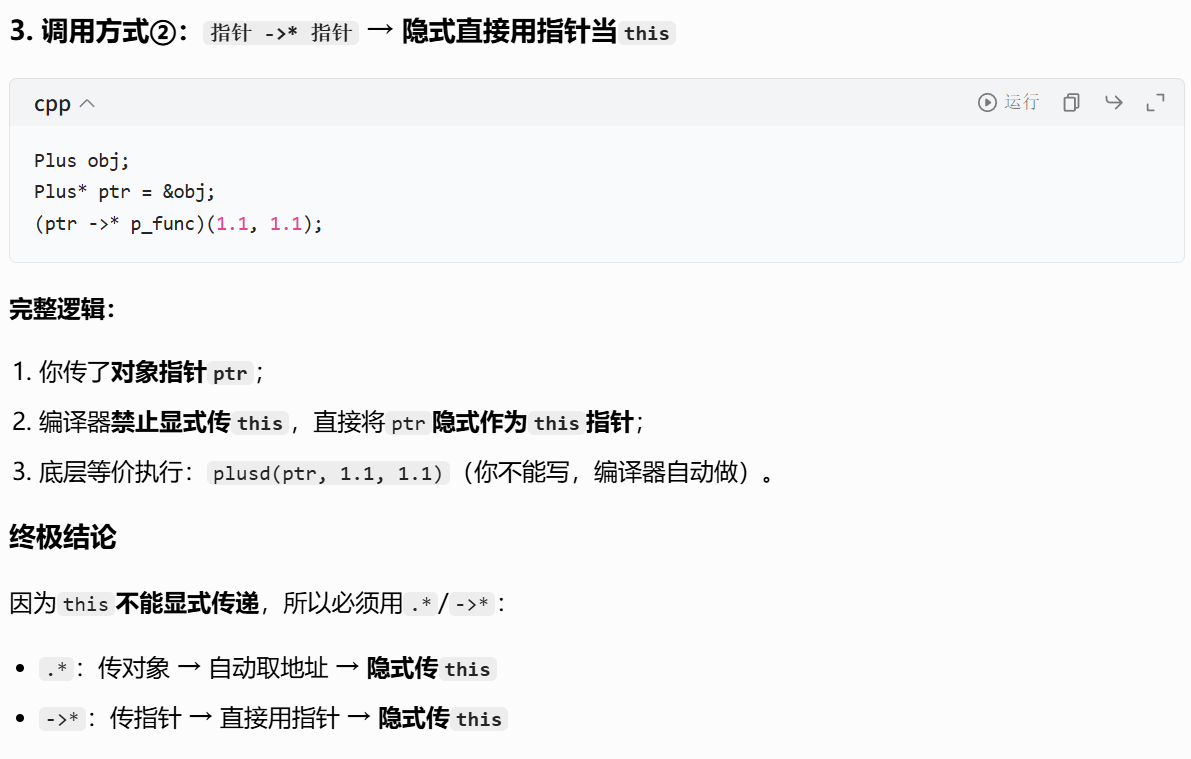
方式 2:传对象值
cpp
function<double(Plus, double, double)> f6 = &Plus::plusd;
cout << f6(pd, 1.1, 1.1) << endl; // 输出22调用时会拷贝传入的对象,修改拷贝对象的成员不会影响原对象。
方式 3:传对象右值引用
cpp
function<double(Plus&&, double, double)> f7 = &Plus::plusd;
cout << f7(move(pd), 1.1, 1.1) << endl; // 输出22
cout << f7(Plus(), 1.1, 1.1) << endl; // 直接传临时对象调用时会移动传入的对象,适合临时对象或不需要保留原对象的场景。
有function之后就可以将这些不同类型的可调用对象存到容器当中
cpp
//可以将这些不同类型的可调用对象存到容器当中
vector<function<int(int, int)>> v;
v.push_back(f);
v.push_back(Functor());
v.push_back([](int a, int b) {return a + b; });
for (auto& f : v)
{
cout << f(1, 1) << endl;
}相信不少兄弟看完懵懵的,我初次见到这个东西也一样,下面我把我当初疑惑的点列出来并给予解答,希望可以为你解惑
std::function<返回值类型(参数类型1, 参数类型2, ...)> 变量名 = ?这个问号必须是什么?
一句话结论:必须是一个符合签名的可调用对象,不是函数名,也不是类名。
"可调用对象" :就是能被()括号调用的东西。C++ 里一共就这 7 种合法的可调用对象,全部都能赋值给std::function:

- 既然plused第一个参数是隐含的 this 指针,像这里
function<double(Plus*, double, double)> f5 = &Plus::plusd;第一个参数传一个Plus*很好理解,为什么传Plus对象也可以?function<double(Plus, double, double)> f6 = &Plus::plusd;


反正我觉得这里C++绕来绕去的非常阴间啊,建议直接记对象传过去会隐式转换为指针就好了
- 下面代码段的写法也是正确的不会报错,原因是临时对象传给值类型参数时,会触发拷贝构造(或移动构造,更高效)生成一个新对象,这个新对象作为成员函数的this指针指向的实例。
cpp
function<double(Plus, double, double)> f7 = &Plus::plusd;
cout << f7(Plus(), 1.1, 1.1) << endl;执行步骤 :
-
Plus()创建临时对象(右值);
-
关键步骤 :临时对象传给值类型参数Plus时,会触发拷贝构造函数 (或 C++11 后的移动构造函数 ,更高效),生成一个新的局部对象 作为函数参数;
-
std::function内部将这个新对象的地址作为this指针,调用plusd;
-
函数执行完,新对象和原临时对象都被销毁。
2.2 function 底层原理
std::function 是一个极其强大的多态包装器。无论是普通函数指针、仿函数(Functor)还是 Lambda 表达式,只要函数签名匹配,都可以被它统一接收和调用。
这种能力,其底层的核心机制被称为类型擦除(Type Erasure)。简单来说,std::function 的底层运作可以归结为以下两个关键步骤:
一、 存储阶段:抹除类型,纯数据托管
当我们将一个可调用对象(例如 Lambda 表达式)赋值给 std::function 时,系统需要将其保存下来。由于不同类型的对象在内存中的大小和结构完全不同,std::function 采取了一种强行剥离的策略:
- 开辟通用空间:std::function 内部维护了一块通用的内存空间。
- 纯数据拷贝 :无论是函数指针还是捕获了大量外部变量的 Lambda 表达式,在底层本质上都是一段内存数据。std::function 会直接将这些对象的底层数据硬拷贝到这块通用空间中。
- 抹除类型信息 :拷贝完成后,std::function 在存储层面彻底遗忘 了该对象原本的类型(比如它是具体哪个 Lambda 类)。此时,这块内存被单纯地视作一团无类型特征的纯数据 (在底层通常表现为
void*指针或字符数组)。
二、 调用阶段:记录代理,执行时动态强转
既然在存储时已经丢失了类型信息,std::function 在被调用时,是如何知道该以何种方式运行这团纯数据 的呢?秘密在于它在赋值时提前准备的专属说明书:
- 生成专属调用函数 :在赋值发生的瞬间(此时编译器依然知晓对象的真实类型),编译器会在后台悄悄生成一个专属调用函数。这个函数内部牢牢记录了该对象原本的真实类型。
- 保存函数指针:std::function 内部除了保存那团"纯数据"外,还会额外保存一个指向上述**"专属调用函数"**的指针。
- 强转与执行 :当我们在代码中实际触发调用(例如执行
f(1, 1))时,std::function 自身并不直接处理,而是将那团无类型的"纯数据"交托给那个"专属调用函数"。 - 还原真相 :由于专属调用函数熟知底层原本的类型,它会果断将这团纯数据强制类型转换回其真实的原始类型(例如强转回原本的 Lambda 类型),随后按照该类型应有的方式执行代码,并返回结果。
2.3 逆波兰表达式求值
这道题目我在之前的文章中写过,当时是使用栈的特性暴力解决的C++ STL 栈与队列完全指南:从容器使用到算法实现,这里我是用封装器来对其进行优化
cpp
class Solution {
public:
int evalRPN(vector<string>& tokens) {
// 1. 核心容器:map 映射 运算符字符串 → 运算逻辑(std::function包装lambda)
map<string, function<int(int, int)>> opFuncMap =
{
{"+", [](int a, int b) {return a + b;}},
{"-", [](int a, int b) {return a - b;}},
{"*", [](int a, int b) {return a * b;}},
{"/", [](int a, int b) {return a / b;}}
};
stack<int> st; // 存储运算数字的栈
// 2. 遍历所有token字符串
for(auto& str : tokens)
{
if(opFuncMap.count(str)) // 判断当前字符串是不是运算符(map中存在该key)
{
// 弹出两个操作数,注意弹出顺序
int right = st.top(); st.pop(); // 先弹栈顶=右操作数
int left = st.top(); st.pop(); // 后弹=左操作数
// 3. 核心调用:取出对应运算符的function对象,传入操作数执行计算
int ret = opFuncMap[str](left, right);
st.push(ret); // 运算结果入栈
}
else
{
// 是数字,字符串转int后入栈
st.push(stoi(str));
}
}
return st.top(); // 栈最后剩余的值就是结果
}
};传统实现方式依靠 switch-case 写分支判断,而这份代码使用 map + std::function + lambda 实现
1. map<string, function<int(int, int)>> opFuncMap 核心映射容器
- map 的key(键):运算符字符串 "+"、"-"、"*"、"/";
- map 的value(值):
std::function<int(int, int)>类型对象; - std::function 内部存储了一个匿名lambda:
lambda 签名:接收两个int、返回一个int,完美匹配四则二元运算;
每个 lambda 对应一种运算符的计算逻辑。
每一个 lambda 都是编译器生成的独有仿函数类 ,类型互不相同,无法直接存入同一个 map ;
std::function 通过类型擦除技术 ,把不同 lambda 统一包装成 function<int(int,int)> 这同一个类型,因此可以全部作为 map 的 value 存储。
2. opFuncMap.count(str) 判断是否为运算符
count() 函数查询 map 中是否存在当前字符串的 key:
- 返回1:当前字符串是运算符,进入运算分支;
- 返回0:当前字符串是数字,直接入栈。
替代了传统写法if(str=="+" || str=="-" || str=="*" || str=="/")冗长的判断。
3. opFuncMap[str](left, right) 执行运算
opFuncMap[str]:根据运算符字符串,从 map 里取出对应的std::function对象;(left, right):调用这个 function 对象,传入左右两个操作数;- 底层执行:function 内部通过多态转发,调用当初存入的 lambda 表达式,完成四则运算并返回结果。
该解法对比传统 switch-case 写法的优势
1. 符合「开闭原则」,扩展运算符极其简单
如果需要新增运算符(例如取模%、幂运算^):
- 本解法:只需要在opFuncMap初始化列表里新增一行键值对
{"%", [](int a,int b){return a%b;}},不需要修改循环主体代码; - switch-case 写法:需要新增case分支,修改循环内的核心逻辑,改动原有代码容易引入 bug。
2. 代码分层清晰,运算逻辑集中管理
所有四则运算的逻辑全部集中写在opFuncMap的初始化处,一眼就能看清所有运算符的计算规则;
传统 switch-case 写法的运算逻辑分散在各个case代码块中,代码碎片化
3. 消除冗长的字符串匹配判断
不需要手写一长串 if(str == "+" || str == "-" ...) 判断语句,直接借助 map 自带的 key 查询功能,代码更简洁、可读性更高。
4. 运算逻辑可复用
map 中存储的function对象可以单独提取、传递给其他函数复用;
switch-case 内的运算逻辑是局部代码,无法单独复用。
要点补充:代码中涉及的隐式类型转换
这段逆波兰表达式代码中,map<string, function<int(int, int)>> opFuncMap 的初始化列表,会触发两次关键的隐式转换:
- 字符串字面量→
string:"+" → string("+")(基础类型隐式转换); - lambda→function:匿名
lambda → function<int(int, int)>(类型擦除转换); - 花括号初始化→pair:
{"+", lambda} → pair<const string, function<int(int, int)>>(核心的 pair 隐式构造)。
std::map 的构造函数接收std::initializer_list<std::pair<const Key, T>>类型参数,即一组键值对的初始化列表
当然该题目容器也可以完全换成哈希表,看自己喜好,哈希表自然最更优的
三、绑定器
3.1 bind
一、基础概念
1. 本质与头文件
std::bind 定义在头文件 < functional > 中,是函数模板 + 函数适配器 :
接收任意可调用对象(普通函数、Lambda、类成员函数、函数对象),处理后返回一个全新的可调用对象(仿函数)。
2. 核心能力
- 固定原函数的部分参数,减少调用新对象时需要传入的参数;
- 调换参数传递顺序,改变实参映射关系。
3. 通用调用语法
cpp
auto 新可调用对象 = bind(原可调用对象, 参数列表);参数列表分两类元素:
- 常量值:直接写死原函数的对应参数,调用新对象时无需传这个值;
- 占位符 _1/_2/_3...:来自命名空间
std::placeholders,代表调用新对象时传入的第 1/2/3 个实参。
4. 两种模板重载
自动推导返回值(日常绝大多数场景使用)
cpp
template <class Fn, class... Args>
auto bind(Fn&& fn, Args&&... args);手动指定返回值(自动推导失败的特殊场景使用)
cpp
template <class Ret, class Fn, class... Args>
auto bind(Fn&& fn, Args&&... args);二、占位符 _n 详解
_1、_2 等占位符存放在 std::placeholders 命名空间:
- _1 = 调用新生成的可调用对象时,传入的第一个实参;
- _2 = 调用新对象时,传入的第二个实参;
- 数字 n 代表新函数的参数位置,和原函数参数顺序无关,因此可以实现参数重排。
使用前需要声明:
cpp
#include <functional>
using std::placeholders::_1;
using std::placeholders::_2;三、五大使用场景
场景 1:调整参数传递顺序
基础原函数:
cpp
int Sub(int a, int b)
{
return (a - b) * 10;
}
cpp
// 1. 占位符顺序和原函数一致,参数正常传递
auto sub1 = bind(Sub, _1, _2);
cout << sub1(10, 5); // sub1(10,5) → Sub(10,5) → (10-5)*10=50
// 2. 交换占位符顺序,调换参数映射关系
auto sub2 = bind(Sub, _2, _1);
cout << sub2(10, 5); // sub2(10,5) → Sub(5,10) → (5-10)*10=-50原理:_2 会接收新调用的第 2 个实参 5,传给原函数第一个形参 a;_1 接收第 1 个实参 10,传给原函数第二个形参 b。
场景 2:固定部分参数(最常用)
通过常量值绑定原函数的某一个参数,调用新对象时只需传入剩余占位符对应的参数:
cpp
// 原函数第一个参数固定为100,新对象只需要传1个参数(_1)
auto sub3 = bind(Sub, 100, _1);
cout << sub3(5); // sub3(5) → Sub(100,5) → 950
// 原函数第二个参数固定为100,新对象只需要传1个参数(_1)
auto sub4 = bind(Sub, _1, 100);
cout << sub4(5); // sub4(5) → Sub(5,100) → -950场景 3:多参数函数的参数固定
三参数原函数 SubX(int a, int b, int c),可以固定任意位置参数:
cpp
// a固定100,新对象传入2个参数给b、c
auto sub5 = bind(SubX, 100, _1, _2);
cout << sub5(5, 1); // SubX(100,5,1)
// b固定100
auto sub6 = bind(SubX, _1, 100, _2);
// c固定100
auto sub7 = bind(SubX, _1, _2, 100);场景 4:绑定类的普通成员函数
类普通成员函数隐含第一个参数是类对象(this 指针),bind 绑定成员函数时必须传入类实例:
cpp
class Plus
{
public:
double plusd(double a, double b)
{
return a + b;
}
};
// bind绑定成员函数:&Plus::plusd(成员函数地址) + Plus()(固定绑定的类实例) + 占位符
function<double(double, double)> f7 = bind(&Plus::plusd, Plus(), _1, _2);
cout << f7(1.1, 1.1); // 等价于 Plus().plusd(1.1,1.1)优势:绑定后无需每次调用都传入类对象,简化调用逻辑。
场景 5:业务实战:基于 Lambda 批量生成专用函数
底层 Lambda func1 接收 3 个参数:利率、本金、存期,计算复利利息:
cpp
auto func1 = [](double rate, double money, int year)->double {
double ret = money;
for (int i = 0; i < year; i++) ret += ret * rate;
return ret - money;
};需求:预设利率、存期,只需要传入本金即可计算利息,用bind快速生成多个专用函数:
cpp
// 固定年利率0.015、存期3年,仅需传入本金(_1)
function<double(double)> func3_1_5 = bind(func1, 0.015, _1, 3);
// 固定年利率0.015、存期5年
function<double(double)> func5_1_5 = bind(func1, 0.015, _1, 5);
// 调用时只传本金100万,自动套用预设利率和年限
cout << func3_1_5(1000000);
cout << func5_1_5(1000000);这样就基于同一个底层逻辑函数,快速生成多组预设参数的专用调用器,避免重复编写大量相似函数 / Lambda。
3.2 bind 底层原理
1. 返回自定义仿函数
bind 会生成一个匿名结构体(仿函数),内部保存三样数据:原函数 / 可调用对象、所有绑定参数(固定值、占位符标识)。
2. 调用仿函数时做参数映射
当你执行 绑定对象(实参1,实参2),仿函数的 operator() 会遍历预存的参数清单:
存的是固定数值:直接拿该值作为原函数参数;
存的是 _1/_2 占位符:从本次传入的实参里提取第 N 个值。
- 凑齐全部参数,调用原函数
映射完成后,把整理好的参数一次性传给底层保存的原函数,返回运算结果。
补充特殊点(成员函数)
绑定类成员函数时,仿函数内部额外存储成员函数指针与类实例,调用时自动把类对象作为成员函数隐含的
结语
