LLM-as-Judge 踩坑实录
LLM-as-Judge 用起来很简单,但要让它"评得准、判得稳"却不容易。这篇文章系统梳理我们在实际项目中遇到的 6 类常见陷阱------每一个坑,我们都替你踩过了。
一、一个令人不安的发现
我们团队用 GPT-4 对一个客服机器人的 500 条回答做了成对比较评测。结果还不错------新模型比旧模型赢了 62% 的比较。
但当我们把同一个比较对中的 A/B 顺序调换,重新评测了一遍,结果变成了 51%。12 个百分点的差异,仅仅因为顺序不同。
这不是个例。过去一年,大量研究揭示了 LLM-as-Judge 的各类系统性偏见。这篇文章的目标是:帮你识别这些坑,并给出可操作的应对方案。
二、六大陷阱全景
陷阱 1:位置偏见------排在前面就先赢一半
这是最著名也最普遍的 LLM-as-Judge 偏见。当 Judge LLM 做成对比较时,它系统性地偏好 第一个出现的回答。
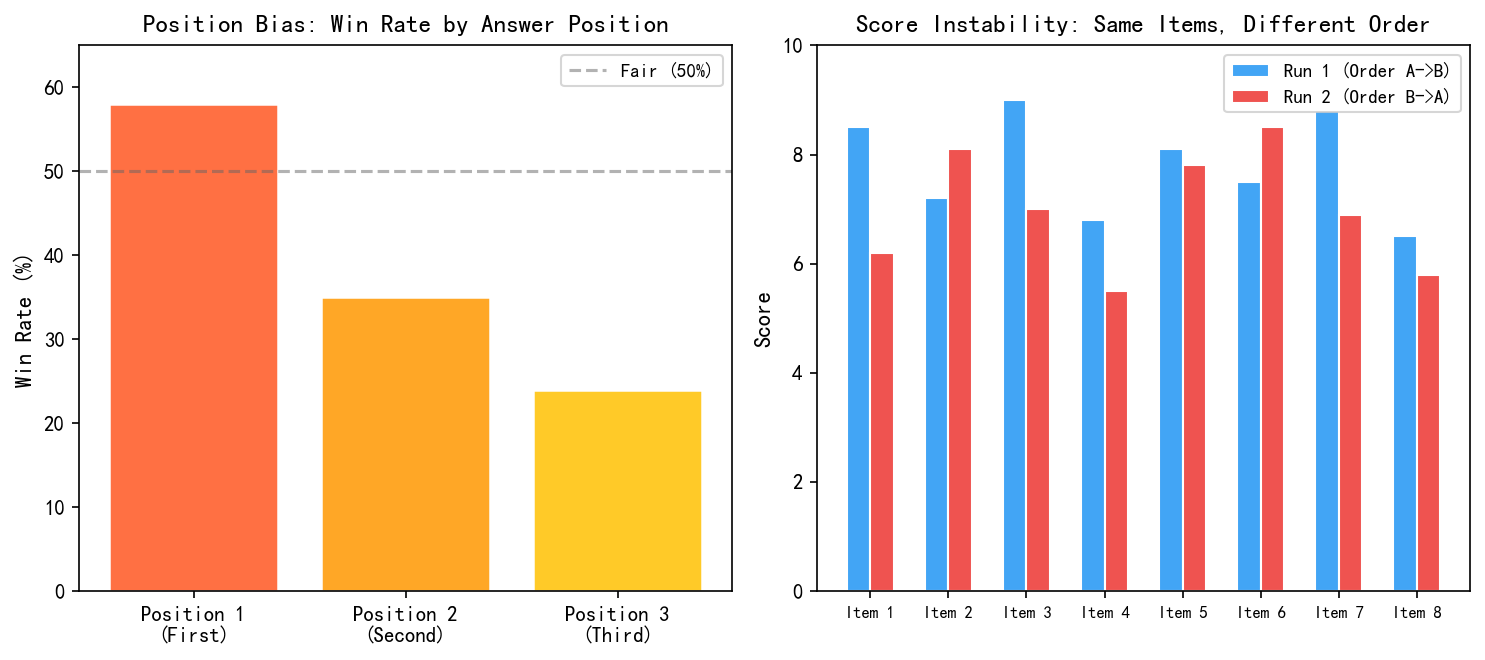
左侧图表展示了一个典型实验的结果:同一个回答,放在 Position 1 时胜率 58%,放在 Position 3 时降到 24%。
为什么? 一种解释是 LLM 的自回归生成特性------它从左到右处理文本,前面的信息天然获得了更多"注意力"。另一种解释是评测 prompt 通常先描述 A 再描述 B,给 Judge 造成了隐式顺序引导。
应对方案:
python
def debiased_pairwise_compare(question: str, answer_a: str,
answer_b: str, model: str = "gpt-4o") -> dict:
"""消除位置偏见的成对比较------两个方向都评一遍"""
# 正向比较(A 在前,B 在后)
result_ab = pairwise_compare(question, answer_a, answer_b, model)
# 反向比较(B 在前,A 在后)
result_ba = pairwise_compare(question, answer_b, answer_a, model)
# 如果两次结果不一致,标记为 tie
if result_ab["winner"] != result_ba["winner"]:
return {
"winner": "tie",
"confidence": "low",
"forward_result": result_ab,
"backward_result": result_ba,
"note": "Position bias detected --- results inconsistent after swapping"
}
return {
"winner": result_ab["winner"],
"confidence": "high",
"forward_result": result_ab,
"backward_result": result_ba
}核心思路:每次比较做两遍(A-B 和 B-A),一致才算数,不一致标为平局。这样虽然评测成本翻倍,但大幅减少了位置偏见的影响。如果你的预算紧张,至少要做 10-20% 的方向校验。
陷阱 2:冗长偏见------字数多就是好吗?
Judge LLM 有一种"看到长回答就觉得好"的倾向,尤其当回答表面看起来"有模有样"时。
我们做了一个对照实验:对同一个问题,让模型生成一个 50 词的精准回答和一个 200 词但内容重复的回答。结果 GPT-4 Judge 在 73% 的情况下选择了更长的回答------尽管它包含大量水分。
应对方案:在评测 prompt 中明确要求 Judge 忽略长度,或使用长度归一化。
请在评分时遵守以下原则:
1. 简洁不等于不完整。一个回答"短而准"应该比"长而空"得分更高。
2. 评估信息密度而非字数。如果一个回答可以用 50 字说清楚而没有遗漏,它应该得到满分。
3. 如果发现回答中存在重复表述或废话,请扣分。另一个更结构化的方案是 Rubric-Based 评分:为每个评测维度定义明确的量规,减少长度对分数的污染。
python
RUBRIC_EXAMPLE = """
评分量规(Clarity 维度):
10 分:表达极其清晰,无歧义,结构精良,一读就懂。
7 分:意思可以理解,但有些句子需要读两遍。
5 分:部分内容令人困惑,结构松散。
3 分:大部分难以理解。
1 分:完全无法理解。
注意:分数只取决于表达的清晰程度,与回答的字数无关。
"""陷阱 3:自我增强偏见------GPT-4 偏好 GPT-4 的风格
多个研究发现:当 Judge LLM 自己是 GPT-4 时,它倾向于给 GPT-4 系列模型生成的回答打更高分。这不是"作弊",而是一种风格偏好------每个模型都有自己独特的措辞方式、结构和思维链条,Judge LLM 觉得"更像自己的"回答看起来更自然、更正确。
这个问题的棘手之处在于:你很难区分"Judge 确实公正地评判了质量"和"Judge 只是在奖励自己偏好的风格"。
应对方案:
- 多 Judge 交叉验证:用不同家族的模型(GPT-4、Claude、Gemini)各当一次 Judge,取平均分
- 风格归一化:在评测前对回答做格式统一处理,减少表面风格差异
python
def multi_judge_evaluate(question: str, answer: str) -> dict:
"""用多个 Judge 模型交叉评估"""
judges = ["gpt-4o", "claude-3-opus-20240229", "gemini-1.5-pro"]
all_scores = {}
for judge_model in judges:
try:
result = evaluate(question, answer, model=judge_model)
all_scores[judge_model] = result
except Exception as e:
all_scores[judge_model] = {"error": str(e)}
# 计算均值和标准差
overalls = [s["overall"] for s in all_scores.values()
if "overall" in s]
return {
"judge_scores": all_scores,
"mean": sum(overalls) / len(overalls) if overalls else 0,
"std": (sum((x - sum(overalls)/len(overalls))**2
for x in overalls) / len(overalls))**0.5
if overalls else 0,
"consensus": "high" if len(set(round(o) for o in overalls)) <= 1
else "medium" if len(overalls) > 1
else "low"
}陷阱 4:评分分布偏差------Judge 有点"手松"
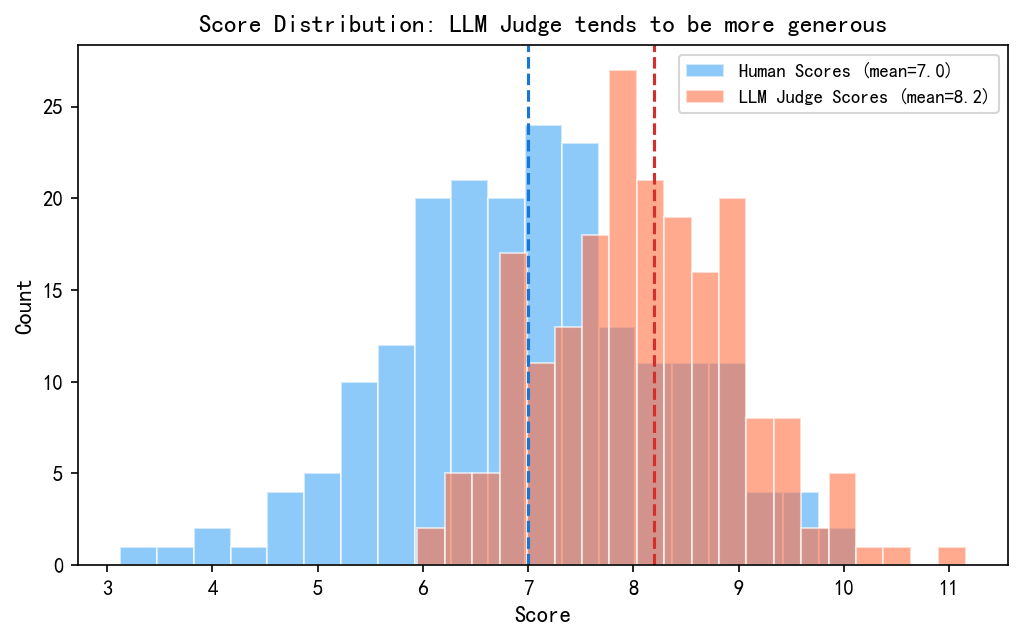
从上图可以清楚看到:LLM Judge 给出的分数分布(红色)整体上比人工评分(蓝色)偏右------平均值高出约 1.2 分。这意味着如果你直接用 LLM 的绝对分数做阈值判断(比如"低于 7 分就打回"),可能会漏掉不少实际上不合格的回答。
为什么 Judge 会给更高分? 一个假说是:LLM 训练数据中包含大量"鼓励性语言",它在做评判时会不自觉地"客气"。另一个原因是:大多数公开发布的模型回答本身质量就不错,Judge 形成了"大多数回答都在 7 分以上"的先验。
应对方案------分数校准:
python
def calibrate_scores(llm_scores: list[float],
human_scores: list[float]) -> callable:
"""用线性回归做分数校准,将 LLM 分数映射到人工分数尺度"""
from sklearn.linear_model import LinearRegression
import numpy as np
X = np.array(llm_scores).reshape(-1, 1)
y = np.array(human_scores)
model = LinearRegression()
model.fit(X, y)
def calibrate(llm_score: float) -> float:
return float(model.predict([[llm_score]])[0])
print(f"校准公式: human_score = {model.coef_[0]:.3f} * llm_score "
f"+ {model.intercept_:.3f}")
return calibrate
# 使用示例:用 50 条人工标注数据拟合校准函数
# calibrate = calibrate_scores(llm_scores_50, human_scores_50)
# calibrated_score = calibrate(new_llm_score)具体做法:取 50-100 条数据同时做 LLM 评测和人工评测,用线性回归拟合一个校准函数,然后将所有 LLM 分数映射到人工尺度。经验表明,50 条校准数据通常就够用了。
陷阱 5:提示词敏感性------改几个字,结果天差地别
同一个 Judge 模型,对同一条回答的评测结果,可能因为 prompt 的微小变化而显著不同。我们测试了 3 种 prompt 变体:
| Prompt 变体 | 平均分 | 与人工相关性 |
|---|---|---|
| "请给这个回答打分(1-10)" | 8.1 | 0.62 |
| "请严格按以下标准给这个回答打分(1-10)" | 7.4 | 0.71 |
| "你是一个严格的评测员。请用以下 Rubric 打分(1-10)" | 6.9 | 0.83 |
三种 prompt 的平均分差了 1.2 分,与人工相关性从 0.62 到 0.83。你的评测 prompt 就是你的评测质量标准------它直接决定了 Judge 的行为。
应对方案:
- 固化 prompt:评测 prompt 应该被版本化管理,任何修改都要重新做验证
- 用几条"锚定样本"测试 prompt 变化:准备 10 条已知"标准答案"的评测样本,每次改 prompt 后先跑一遍,看分数是否合理
python
ANCHOR_SAMPLES = [
{
"question": "1 + 1 = ?",
"answer": "2",
"expected_score_range": (9, 10),
"label": "trivial_correct"
},
{
"question": "1 + 1 = ?",
"answer": "根据量子力学原理,1+1 可能在 1.98 到 2.02 之间浮动......",
"expected_score_range": (1, 3),
"label": "obvious_overkill"
},
{
"question": "太阳系有几颗行星?",
"answer": "9 颗,包括冥王星。",
"expected_score_range": (1, 5),
"label": "outdated_fact"
}
]
def validate_judge_prompt(judge_prompt: str, model: str = "gpt-4o") -> dict:
"""用锚定样本验证评测 prompt 的合理性"""
results = []
for sample in ANCHOR_SAMPLES:
score = evaluate(sample["question"], sample["answer"], model)
low, high = sample["expected_score_range"]
passed = low <= score["overall"] <= high
results.append({
"label": sample["label"],
"score": score["overall"],
"expected": f"{low}-{high}",
"passed": passed
})
pass_rate = sum(1 for r in results if r["passed"]) / len(results)
print(f"锚定样本通过率: {pass_rate:.0%}")
return {"pass_rate": pass_rate, "details": results}陷阱 6:多轮对话中的上下文污染
这是最容易被忽视的坑。当你用同一个 Judge LLM 的 session 连续评估多条数据时,前面的评测可能会影响后面的评判------这就是"上下文污染"。
例如:你连续评测了 5 条质量很差的回答,Judge 的"锚点"被拉低了。接下来评测一条质量中等的回答时,Judge 可能打出虚高的分数------它在潜意识中和前面的差回答做对比,而不是和绝对标准做对比。
应对方案:每条评测都使用独立的上下文(每次都新建 conversation),或至少每 N 条清空一次上下文。
python
def batch_evaluate(questions: list[str], answers: list[str]) -> list[dict]:
"""逐条评测,每条使用独立的上下文"""
results = []
for q, a in zip(questions, answers):
# 每次都创建新的 API 调用,无上下文污染
result = evaluate(q, a)
results.append(result)
return results注意:这意味着不能用 Assistant 模式的一条长对话来做批量评测------那正是上下文污染的来源。
三、偏见缓解方案汇总
| 偏见 | 缓解方案 | 成本增加 | 效果 |
|---|---|---|---|
| 位置偏见 | 双向比较(swap test) | 2x | 显著 |
| 冗长偏见 | Rubric 评分 + prompt 约束 | 0 | 中等 |
| 自我增强 | 多 Judge 交叉验证 | 2-3x | 显著 |
| 评分分布偏差 | 线性校准(50 条人工数据) | 一次性 | 显著 |
| Prompt 敏感性 | 锚定样本验证 + prompt 版本管理 | 低 | 显著 |
| 上下文污染 | 独立上下文评测 | 0 | 显著 |
一个经验法则:如果你在做模型选型的最终决策,至少要用前 3 种策略的组合;日常迭代的快速评测,位置偏见的双向比较是最低限度的投入。
四、如何发现你自己的评测系统中潜伏的偏见?
最终,每个 LLM-as-Judge 系统都有自己独特的偏见组合------取决于你用的 Judge 模型、评测 prompt、评测领域和数据类型。
我建议做一次 "偏见审计":
python
class BiasAudit:
"""LLM-as-Judge 偏见审计工具"""
def __init__(self, judge_model: str = "gpt-4o"):
self.judge_model = judge_model
self.results = {}
def audit_position_bias(self, questions: list[str],
answers_a: list[str],
answers_b: list[str]) -> dict:
"""审计位置偏见"""
forward_wins_a = 0
backward_wins_a = 0
for q, a, b in zip(questions, answers_a, answers_b):
# A 在前
r1 = pairwise_compare(q, a, b, self.judge_model)
if r1["winner"] == "A":
forward_wins_a += 1
# B 在前(A 在后)
r2 = pairwise_compare(q, b, a, self.judge_model)
if r2["winner"] == "B":
backward_wins_a += 1 # A 是 B,所以 winner=B 表示 A 赢了
n = len(questions)
bias_score = (forward_wins_a - backward_wins_a) / n
return {
"forward_win_rate_a": f"{forward_wins_a/n:.1%}",
"backward_win_rate_a": f"{backward_wins_a/n:.1%}",
"position_bias": f"{bias_score:.1%}",
"severity": "high" if abs(bias_score) > 0.15
else "medium" if abs(bias_score) > 0.08
else "low"
}
def audit_length_bias(self, questions: list[str]) -> dict:
"""审计冗长偏见"""
# 生成短精确版和长重复版的回答对
# 比较 Judge 对两者的偏好
pass # 完整实现在配套代码中
def run_full_audit(self) -> dict:
"""运行完整的偏见审计"""
# 整合各项审计结果
pass总结
LLM-as-Judge 不是"有偏见所以不能用",而是"知道它有什么偏见,然后用工程手段来对冲"。核心要点:
- 位置偏见最普遍,双向比较是最低成本的解决方案
- 冗长偏见最隐蔽,需要从 prompt 层面明确约束
- 评分分布偏差最容易被忽略,50 条人工校准数据就能大幅改善
- 多 Judge 交叉验证是提升可靠性的终极手段,但成本也最高
- 做好偏见审计------你不测量偏见,偏见就在默默地测量你的模型