第一步:SRN-DeblurNet介绍
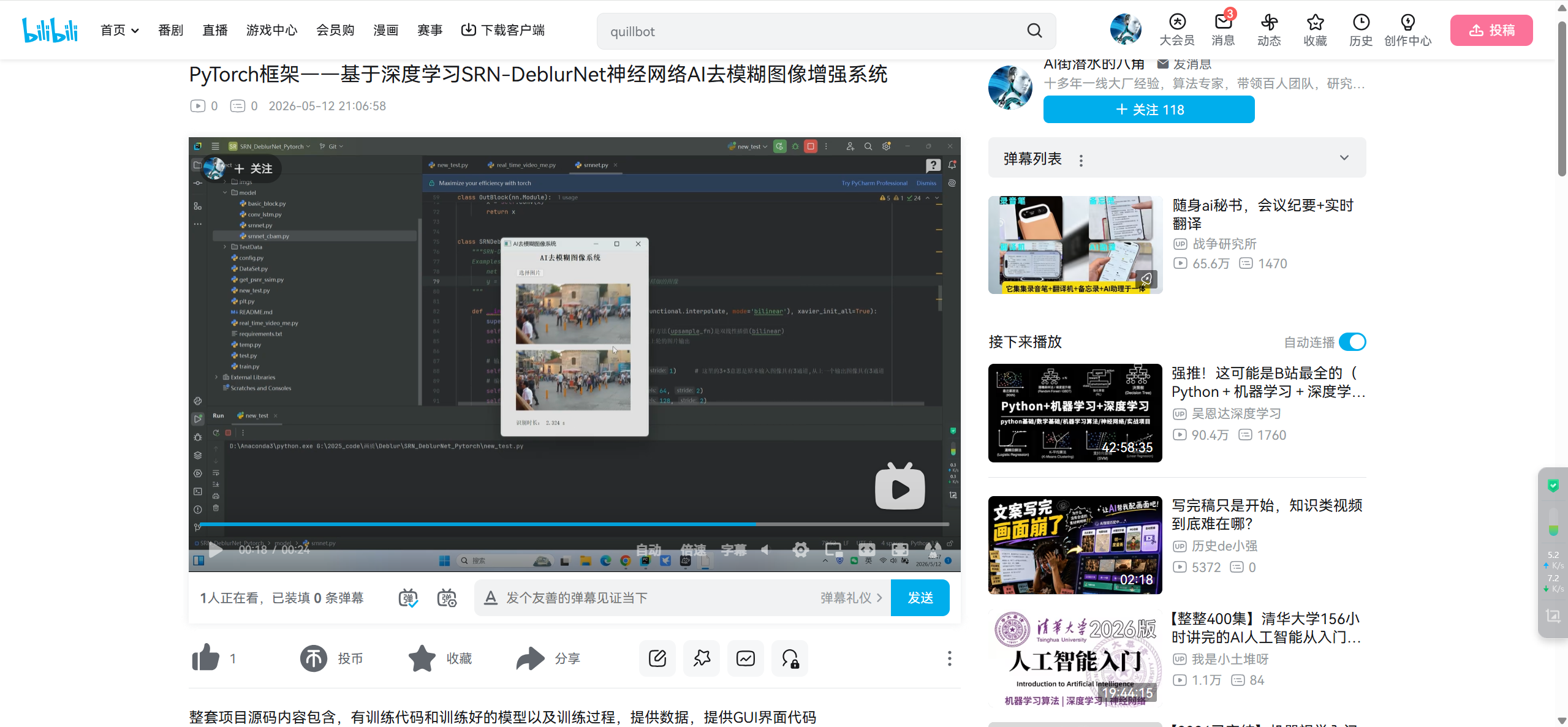
本文介绍的 SRN-DeblurNet(CVPR2018)方法便是一种基于深度学习的盲去模糊方法,它沿用了去模糊领域广泛应用的从粗到细(coarse-to-fine)的方案,提出了一个新的用于去模糊任务的尺度循环网络(Scale-recurrent Network),采用尺度训练方法,使用了编码器-解码器,ResBlock 网络等,该方法有两大突出特点:
SRN-DeblurNet 是第一篇将循环神经网络 RNN(Recurrent Neural Network)引入去模糊任务,而此前基于深度学习的去模糊领域通常使用 CNN(卷积神经网络),该文章的引用已达 1090 次(Google scholar),在基于深度学习的去模糊领域中具有开创性的意义。
SRN-DeblurNet 相比于同期其它的基于深度学习的方法,它的网络结构更简单,参数数量更少,训练更高效、容易;而且该网络的去模糊效果在相关邻域其它论文中得到了一致的认可。
第二步:SRN-DeblurNet网络结构
第三步:模型代码展示
python
class SRNDeblurNet(nn.Module):
"""SRN-DeblurNet主体网络
Examples:
net = SRNDeblurNet()
y = net( x1 , x2 , x3)#x3是最粗糙的图像,而x1是最精细的图像
"""
def __init__(self, upsample_fn=partial(torch.nn.functional.interpolate, mode='bilinear'), xavier_init_all=True):
super(type(self), self).__init__()
self.upsample_fn = upsample_fn # 下采样方法(upsample_fn)是双线性插值(bilinear)
self.input_padding = None # 记录上轮的图片输出
# 输入块
self.inblock = EBlock(3 + 3, 32, 1) # 这里的3+3意思是原本输入图像具有3通道,从上一个输出图像具有3通道
# 编码块(通道c倍增,高h宽w减半)
self.eblock1 = EBlock(32, 64, 2)
self.eblock2 = EBlock(64, 128, 2)
# convlstm单层
self.convlstm = CLSTM_cell(128, 128, 5)
# 解码块(通道c倍减,高h宽w翻倍)
self.dblock1 = DBlock(128, 64, 2, 1)
self.dblock2 = DBlock(64, 32, 2, 1)
# 输出块
self.outblock = OutBlock(32)
# 初始化参数
if xavier_init_all:
for name, m in self.named_modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
torch.nn.init.xavier_normal_(m.weight)
def forward_step(self, x, hidden_state):
"""单步forward
Args:
x: (b,c,h,w),其中c是6通道(3通道+3通道)
Returns:
d3: (b,c,h,w),其中c是3通道
h,c: (b,c,h,w),其中c为128通道
"""
# 输入块+编码块(通道6(3+3)->32->64->128,h和w在两层编码块变为h/4,w/4)
e32 = self.inblock(x)
e64 = self.eblock1(e32)
e128 = self.eblock2(e64)
# convlstm
h, c = self.convlstm(e128, hidden_state) # 返回convlstm的h和c隐状态,其形状与e128相同
# 解码块+输出块(通道128->64->32->3,h/4和w/4在两层解码块变为h和w)
d64 = self.dblock1(h)
d32 = self.dblock2(d64 + e64) # 含残差块
d3 = self.outblock(d32 + e32) # 含残差块
return d3, h, c
def forward(self, b1, b2, b3):
"""三次不同规模的forward
Arg:
b1, b2, b3: 原规模,1/2规模,1/4规模的图片
Return:
i1, i2, i3: 经过网络后的原规模,1/2规模,1/4规模的图片
"""
# input_padding是第一次用于填充1/4规模的输入图片
if self.input_padding is None or self.input_padding.shape != b3.shape:
self.input_padding = torch.zeros_like(b3)
# 初始化h,c隐状态(B=b1.shape[0],C=128,H=1/16原H,W=1/16原W)
# 为什么这里是1/16?因为第一次进入的b3本身就是1/4规模的图片,经过两层编码块后,h和w会2次减半
h, c = self.convlstm.init_hidden(b1.shape[0], (b1.shape[-2]//16, b1.shape[-1]//16))
# 第一轮迭代(1/4规模),将b3和input_padding拼接输入
i3, h, c = self.forward_step(torch.cat([b3, self.input_padding], 1), (h, c))
# 下一次的h和w隐状态形状:高H=1/8原H,宽W=1/8原W,需要上采样
c = self.upsample_fn(c, scale_factor=2)
h = self.upsample_fn(h, scale_factor=2)
# 第二轮迭代(1/2规模),将b2和i3上采样2倍后拼接输入
i2, h, c = self.forward_step(torch.cat([b2, self.upsample_fn(i3, scale_factor=2)], 1), (h, c))
# 下一次的h和w隐状态形状:高H=1/4原H,宽W=1/4原W,需要上采样
c = self.upsample_fn(c, scale_factor=2)
h = self.upsample_fn(h, scale_factor=2)
# 第三轮迭代(原规模)
i1, h, c = self.forward_step(torch.cat([b1, self.upsample_fn(i2, scale_factor=2)], 1), (h, c))
return i1, i2, i3第四步:训练过程
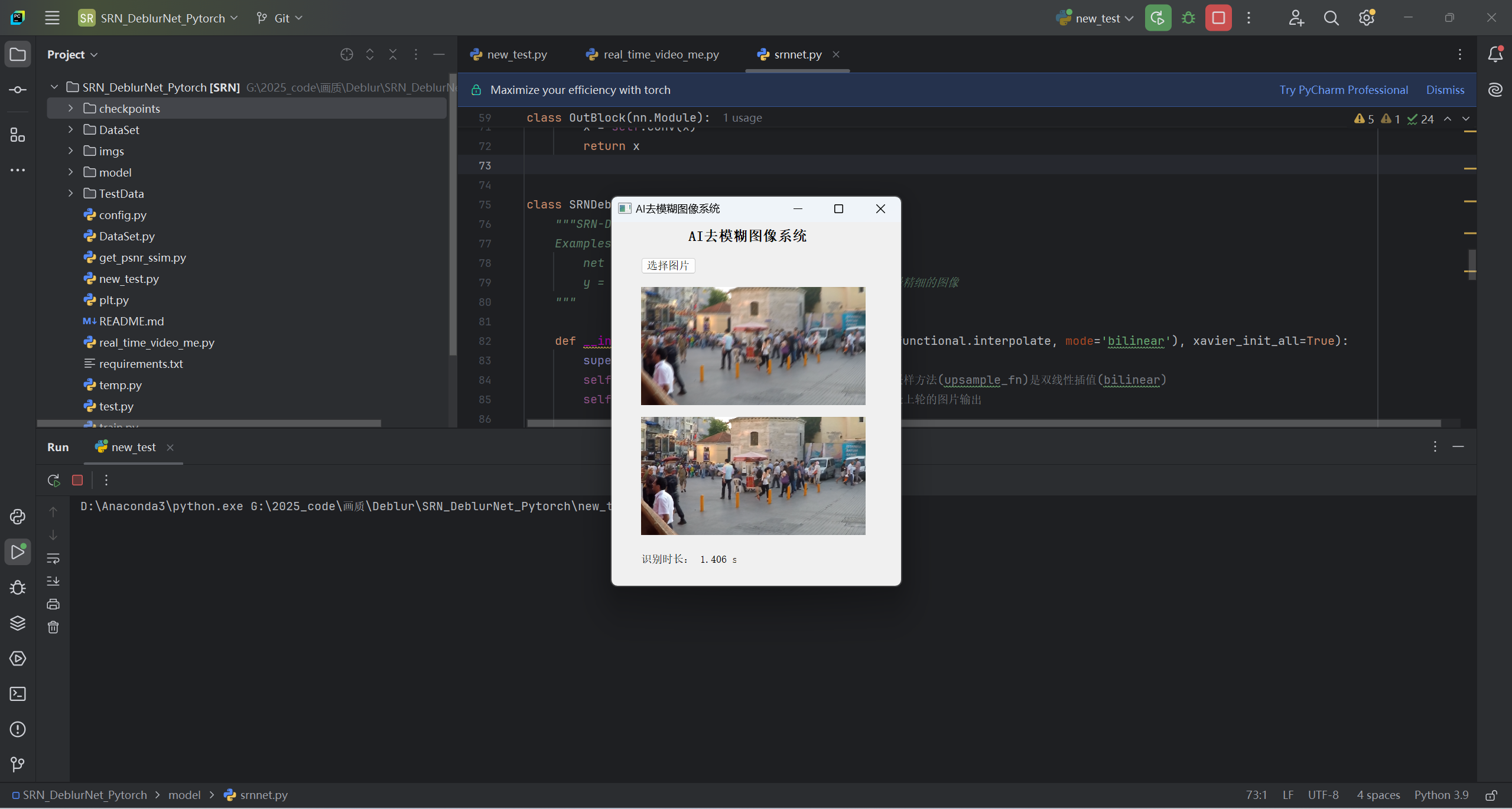
第五步:运行


第六步:整个工程的内容
项目完整文件下载请见演示与介绍视频的简介处给出:➷➷➷
https://www.bilibili.com/video/BV13n5u6DE9q/