介绍
你可能已经试过 AI 代码生成。也许你用 Claude 或 ChatGPT 写过一个函数,立刻就能用。这很棒------但那只是开始。
现在想象这样一个场景:一个 AI Agent 为你管理整个 Feature 开发------从代码设计、到实现、到测试、再到 Code Review------都不需要你去敲键盘,你只需要在关键决策点点头确认。 这听起来像魔法吗?
不是。这是两个世界的碰撞 :你已经知道如何写出好代码,但你还没有学到如何 驾驭(Harness) 一个能自主行动的 AI 系统。这两者的差距,比从"零样本提示"到"精心调教提示词"的距离大得多。
在这次演讲里,我们不会只讲"怎么写更好的 prompt"------那只是起点。我们要走过四个递进的层级:
- 提示词工程:怎么说才能让 AI 理解你的意图
- 上下文工程:怎么给 AI 看到对的信息、避免噪音
- 驾驭工程(Harness Engineering):怎么建一套系统让 AI 真的能在生产环境里工作
无论你是在做 Android 框架开发、还是搭建平台工程,这些层级都直接关系到:你的 AI Agent 能不能从"有趣的实验"变成"真正可信赖的生产工具"。
这不是理论。我们会看具体案例,讨论实际的陷阱,并给出你今天就能用上的策略。
演进路线:从 Prompt 到 Context 再到 Harness
这几年,整个技术路线走得非常清晰。三个阶段的升级:
2022-2023 年:Prompt Engineering 时代
- 关心的问题:怎么写一条好的 Prompt?
- 工程单位:一句话
- 防的是什么:模型猜错意图
- 时间尺度:秒
2025 年:Context Engineering 时代
- 关心的问题:模型看到什么?
- 工程单位:一个上下文窗口
- 防的是什么:信息缺失、上下文腐烂
- 时间尺度:分钟 ~ 小时
2026 年:Harness Engineering 时代(现在)
- 关心的问题:系统如何运行?
- 工程单位:一整套运行时
- 防的是什么:Agent 跑偏、跑飞、没人察觉
- 时间尺度:天 ~ 月 ~ 长期
关键点是:每一层都包含上一层,三层不是竞争关系,而是层层包裹。
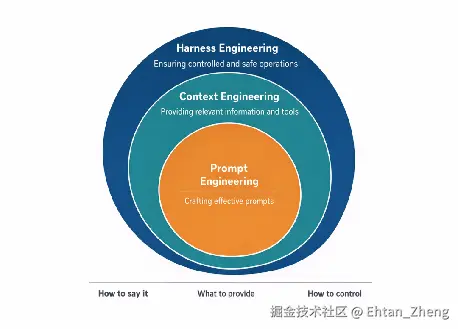
你不会"用 Harness 取代 Prompt"------你只是把工程的边界从"一句话"扩到"一个窗口",再扩到"一整个系统"。
一个简单的口号能抓住 Harness 的姿态:
第一部分:提示词工程基础
什么是提示词工程
提示词工程(Prompt Engineering)是通过精心设计和结构化输入提示,优化大型语言模型(LLM)输出质量的学科。这个领域在过去两年内迅速发展,从最初的"试错"演进为系统化的方法论。
从根本上讲,LLM 是基于大规模文本数据训练的概率模型,它们对输入的结构和语义线索具有可预测的反应模式。虽然这些模型在数学意义上不"理解"自然语言,但通过精心设计提示词的形式、内容和上下文,我们可以显著提高输出的准确性、相关性和可用性。
关键洞察在于:生产级的提示词工程从不依赖单一技术,而是通过组合多种互补的方法,每种方法解决问题域的不同维度。
六大技术家族框架
近期的系统性综述(Schulhoff et al., The Prompt Report, 2024)将超过 50 种已知的提示词优化技术归纳为六个主要家族。这种分类框架的价值在于,它揭示了提示词设计的深层结构,而不仅仅是技术的罗列。
为了阐述这个框架,本节将以一个具体的工程场景为例:实现一个完整的用户注册功能,包括以下需求:
- UI 层:邮箱、密码、确认密码三个输入字段
- 校验层:实时输入校验、提交前全量校验
- 接口层:调用
POST /register接口 - 状态管理:处理加载中(Loading)、错误(Error)和成功(Success)三种状态
家族 1:上下文学习(In-Context Learning)
原理与问题
在模型没有特定域知识时,即使是明确的任务描述也可能导致风格不匹配、框架选择不当或模式偏离的结果。上下文学习通过在提示词中嵌入参考示例和角色定义,帮助模型对齐输出的风格和质量标准。
这个家族包含三个递进的层级:
-
零样本学习(Zero-shot):完全依赖模型的预训练知识。例如:"实现一个用户注册页面的 Kotlin 代码"。这种方法的优点是简洁,缺点是模型必须猜测你的架构、命名规范和设计风格。
-
少样本学习(Few-shot) :提供 2-5 个具体的代码示例作为参考。例如:"以下是我们项目中现有的
LoginScreen和ForgotPasswordScreen的实现,请按照相同的模式实现RegisterScreen:相同的 MVVM 分层、相同的 state holder 写法、相同的错误处理 UI。"这个方法大幅提高了输出与项目风格的匹配度。 -
角色提示词(Role Prompting):在提示中明确定义模型的角色和专业背景。例如:"你是一位有 10 年经验的 Android 开发工程师,深入了解 Jetpack Compose、Coroutines 和响应式编程。你在架构设计中偏好 MVVM 分层和不可变状态。"这层添加有助于激活模型更专业的词汇和思维模式。
实践指导
最有效的做法是将这三层叠加使用。一个典型的提示词应该同时包含:明确的角色定义、2-3 个代码示例、具体的风格要求。研究表明,带有角色锚定的少样本提示词是最具通用性的起点,能以相对较少的 token 成本产生高质量输出。
家族 2:思维生成(Thought Generation)
原理与问题
当模型直接从输入跳到输出时,复杂的多步推理任务容易出现逻辑缺陷。思维生成技术要求模型在给出最终答案之前,显式地展示其推理过程。这样做的好处是双重的:一方面提高了准确性(特别是在需要多步骤逻辑的任务中),另一方面使输出可被验证和调整。
这个家族包含两个主要变体:
-
思维链(Chain-of-Thought, CoT):线性、分步的推理过程。例如,对于注册功能:
- 第一步:分析需求。注册需要哪些字段?每个字段的校验规则是什么?
- 第二步:设计数据流。UI 的 state 模型如何组织?事件类型如何定义?
- 第三步:识别边界情况。可能的失败场景有哪些(邮箱已注册、密码强度不够、网络超时、两次密码不一致等)?
- 第四步:实现。基于前面的分析,逐步编写代码。
研究发现,CoT 能将复杂推理任务的准确率提升 30-40%。
-
思维树(Tree-of-Thought, ToT):分支式的并行探索。对于注册功能,可能需要权衡多种技术选择:
- 方案 A:提交时校验(简单,但用户体验差)
- 方案 B:实时校验(好的用户体验,但逻辑复杂)
- 方案 C:混合方案:实时提示,提交时严格校验
ToT 让模型并行探索这些方案并比较优劣,最后给出推荐。
实践指导
在日常工作中,应默认使用 CoT。只有当存在多个技术方案需要深入权衡时,才需要启用 ToT 的分支探索模式。显式推理的代价是更多的 token 消耗,但在关键决策点,这个成本是值得的。
家族 3:分解与流程化(Decomposition & Orchestration)
原理与问题
某些任务的复杂性超出单个提示词能够有效处理的范围。此时,将任务分解为多个子任务,并通过顺序链接的提示词完成,是一种更稳健的策略。这个方法的核心是:每个阶段的输出不仅是最终产物,更是下一阶段的输入。
对于注册功能,可以分解为以下五个阶段:
perl
阶段 1 阶段 2 阶段 3 阶段 4 阶段 5
读取 PRD → 设计架构 → 实现 UI → 实现业务逻辑 → 处理状态与错误
列出字段 设计 state 写 Composable 连接 ViewModel 补全加载/错误/
校验规则 模型 和 state 和 Repository 成功 UI
失败场景清单 定义事件类型 holder 调用关键优势:可检视性(Inspectability)
每一个中间产物都可以独立审视和修正。例如,在第二阶段发现遗漏了"密码确认字段不一致"的校验规则,可以及时回溯第一阶段的需求清单,而不会导致后续阶段的返工。这样的可追溯性对于复杂项目至关重要。
实践指导
提示词链的设计应该遵循"单一职责原则":每个阶段专注于一个清晰的输出目标。建议在阶段之间保存中间结果,便于调试和版本控制。
家族 4:接地与上下文检索(Grounding & RAG)
原理与问题
模型的训练数据是固定的,它无法获取你的最新代码库、API 文档或项目规范。不做接地的结果是,模型只能基于通用的框架知识生成代码,导致:
- DI 配置的假设与你的项目不符
- 使用了不存在的工具类或常量
- 组件命名风格与设计系统不匹配
接地(Grounding)的核心策略是:在生成之前,从你的真实系统中检索相关的代码片段、文档和规范,并将其注入提示词中。
RAG 流程示例
对于注册功能的实现,应该在提示词中包含:
- 现有的
LoginScreen.kt源代码(作为代码风格参考) AuthRepository接口定义(展示数据访问层的设计)POST /register的 OpenAPI 文档或 Swagger 描述- 设计系统中的
EmailField和PasswordField组件定义 - 项目的公用校验工具类(如
EmailValidator,PasswordValidator) - 1-2 个已有的 ViewModel 单元测试
然后提示模型:"基于以下项目上下文,实现 RegisterScreen。UI 部分参照 LoginScreen 的实现模式,状态管理参照 LoginViewModel 的写法,API 调用参照 AuthRepository 的接口签名。在你的实现中,请明确指出每一处参照的源文件。"
实际效果对比
| 场景 | 结果 |
|---|---|
| 有接地 | 生成的代码可以直接在项目中编译通过,UI 风格与现有界面保持一致,能够通过代码审查 |
| 无接地 | 代码通常是泛泛而谈的"使用 Jetpack Compose 加 MVVM",充满了对项目架构的错误假设 |
成本考量
RAG 会增加 token 消耗,但这个成本通常能被后续工作流中减少的 bug 修复和迭代循环所抵消。
家族 5:输出塑形(Output Shaping)
原理与问题
模型的自然输出是文本形式:可能是散文描述、代码片段、或长篇幅的说明。这种格式在人类阅读时可以接受,但当需要将输出自动化传递给下游工具时(如代码生成、依赖注入、配置生成等),就需要结构化的格式。
输出塑形(Output Shaping)通过在提示词中明确指定输出格式和数据结构,强制模型返回机器可读的结果。
结构化输出示例
对于代码生成任务,可以要求模型输出 JSON 格式:
json
{
"analysis": {
"fields": [
{"name": "email", "type": "String", "validation": "non-empty, valid email format"},
{"name": "password", "type": "String", "validation": "min 8 chars, uppercase, number, special"}
],
"state_model": "...",
"error_scenarios": [...]
},
"files_to_create": [
{
"path": "app/presentation/screens/RegisterScreen.kt",
"content": "...",
"purpose": "..."
}
],
"files_to_modify": [
{
"path": "app/navigation/NavGraph.kt",
"diff": "...",
"reason": "Add RegisterScreen route"
}
],
"new_dependencies": [],
"validation_rules": [...]
}清单效应(Checklist Effect)
结构化输出还起到强制清单的作用。例如,将 new_dependencies 设为必填字段,模型就必须显式地审视是否引入了新依赖,而不是悄悄在 build.gradle 中添加库。这种显式化大幅降低了隐藏风险。
实践指导
使用 JSON Schema 或 TypeScript 类型定义来描述期望的输出格式。这比自然语言描述更精确,也更容易被模型理解。
家族 6:自我批判与护栏(Self-Critique & Guardrails)
原理与问题
即使前五个家族都应用得当,模型生成的代码仍然可能包含逻辑错误、遗漏的边界情况或安全隐患。自我批判(Self-Critique)和护栏(Guardrails)是最后的质量闭合环节。
-
护栏:明确的硬性约束。这些是模型在任何情况下都不应逾越的边界。例如:
- "不要引入任何新的网络库。项目已经使用 Retrofit,必须复用现有的
AuthRepository。" - "不要在日志或任何明文存储中保存密码。使用 Android Keystore。"
- "所有 UI 状态变更必须通过 ViewModel,不允许在 Composable 中直接修改状态。"
- "不要引入任何新的网络库。项目已经使用 Retrofit,必须复用现有的
-
自我批判:要求模型在提交输出前进行自我检查。例如:
- "检查清单:是否所有的输入字段都有相应的校验?"
- "密码强度规则是否与 LoginScreen 的规则一致?"
- "是否处理了所有可能的失败场景(邮箱已注册、密码强度不足、网络超时、服务器返回 429 等)?"
- "UI 中是否为所有网络请求提供了加载状态提示?"
- "用户在请求进行中点击返回按钮,应该如何处理?"
高级技术
文献中还有相关的进阶变体:
- Self-Consistency:对同一个提示词采样多条推理路径,然后通过多数投票选出最可靠的答案。
- Reflexion:执行完自我批判后,再让模型根据批判结果改进自己的输出。
这些方法的共同思路是:通过引入独立的验证工序,来检查和改进上一工序的产物。
技术的组合与实践
为什么不能只用一种技术
单一技术能够解决特定维度的问题,但现实中的任务往往是多维的。例如:
- 少样本学习可以解决"代码风格不匹配",但解决不了"模型漏掉关键的校验逻辑"
- 思维链提高了逻辑准确性,但无法补充模型对你的代码库的无知
- RAG 提供真实上下文,但如果模型没有显式推理,仍然容易遗漏细节
一个完整的工作流示例
生产级提示词工程的典型组合如下,按照应用顺序:
-
建立基础(家族 1):带角色锚定和少样本示例的初始提示词 "你是一位资深 Android 工程师,擅长 Jetpack Compose 和 MVVM。 请参照以下现有代码实现 RegisterScreen..."
-
显式推理(家族 2):引入 CoT "首先,分析注册的所有需求。其次,设计 state 模型。 其次,列出所有失败场景。最后,实现代码。"
-
精细化上下文(家族 4):注入项目的真实代码和规范 "这是我们项目的 AuthRepository 接口、API 文档和设计系统。 请严格遵循这些现有的模式..."
-
规范化输出(家族 5):指定结构化格式 "请用以下 JSON 格式返回结果:files_to_create、files_to_modify、 new_dependencies、validation_rules"
-
质量检查(家族 6):加入护栏和自我批判 "检查以下护栏:【列表】。生成代码前,请自我审查:【检查清单】"
-
流程编排(家族 3):如果单个提示词超过处理能力,分解为多阶段 第一个提示词:仅读取 PRD,输出需求清单和 state 设计 第二个提示词:基于第一个的输出,实现 Composable ...
关键要点:这些技术的组合不是线性的,而是相互强化的。在实际应用中,应该根据任务的具体特点,灵活选择要应用的技术及其顺序。
提示词工程的局限性与展望
尽管上述技术框架非常有效,但提示词工程仍然有几个根本性的局限,这些局限指向系统设计演进的必要性。
局限一:无状态性(Stateless)
每一次提示词调用都是独立的,模型无法从前一轮对话中学习或积累上下文。这意味着:
- 如果模型在第一次尝试中犯了错误,在第二次提示时必须重新解释整个上下文
- 无法基于多轮对话的对话历史来优化策略
- 模型无法形成对特定项目的"长期记忆"
局限二:无法自我迭代(Non-Agentic)
提示词是单向的:模型生成答案,但无法观察答案在真实环境中是否有效。例如:
- 生成的代码能否编译通过?模型看不到编译错误
- 代码在运行时是否会崩溃?模型无法执行和测试
- 输出是否满足了隐含的需求?模型无法主动验证
这意味着提示词工程可以回答问题,但不能解决问题。它生成了代码,但不能保证代码可用。
局限三:难以保持一致性(Consistency across scale)
当任务跨越多个步骤和多次提示词调用时,维持输出的一致性变得困难。例如:
- 第一个提示词定义的 state 模型,第二个提示词的实现可能不一致
- 跨多个文件的命名规范容易产生偏差
- 业务逻辑的决定可能在后续步骤中被遗忘或误解
局限四:无法访问实时信息和私有系统
模型无法:
- 查询实时的 API 文档或最新的项目配置
- 访问项目的私有代码仓库(除非通过 RAG 主动提供)
- 获取部署环境的实时状态或诊断信息
结论:从提示词工程到系统工程
提示词工程是与 AI 协作的第一步,但它的局限性明确指向了下一阶段的进化方向。当任务变得更复杂、风险变得更高时,我们需要从"如何提出更好的问题"转变为"如何构建能够智能地观察、反馈和自我改进的系统"。
这个转变催生了新的概念和架构:代理(Agents)、工具使用(Tool Use)、反馈循环(Feedback Loops)和验证机制(Validation)。这些是第二、第三部分的核心主题。
简而言之,提示词工程的边界,就是系统工程的起点。
第二部分:上下文工程
什么是上下文工程?
Andrej Karpathy 给出了如今整个行业都在沿用的定义:
"上下文工程,是为下一步精心填充上下文窗口的微妙艺术与科学。"
一个简单的心智模型:
| 硬件类比 | LLM 对应物 |
|---|---|
| CPU | 模型本身 |
| RAM | 上下文窗口 |
| 操作系统 | 决定"什么进 RAM、什么出 RAM"的 Agent |
CPU 的速度你改不了,但你可以决定此刻 RAM 里放着什么。这就是上下文工程的全部。
- 提示词工程问的是:"我该敲哪句话?"
- 上下文工程问的是:"模型在这一步应该看到什么------又不该看到什么?"
为什么重要:三个绕不开的问题
常见的误区。 你可能会这样想:
"我想做一个智能客服,回答用户关于公司产品的问题。我有一个几百页的产品手册。我的模型有 200K 的上下文窗口。那我是不是可以直接把整个手册丢给模型,让它自己去理解,而不用担心什么都遗漏呢?"
这个直觉看起来合理------但在实际使用中会撞上三个真实的问题,而上下文工程正是同时解决这三个问题的学科。
先做一次"尺度感"校准。 1 个 token 大约相当于 0.75 个英文单词,或 1.5 个汉字。也就是说,200K 的窗口大致等于一本中长篇小说;Gemini 2.5 Pro 的 100 万 token 窗口,相当于七本小说。听上去很大方------直到你让一个 Agent 跑上一小时,亲眼看着它被填满。
2026 年主流模型的 context window 对比:
| 模型 | Context Window | 相当于 |
|---|---|---|
| Gemini 2.5 Pro | 100 万 token | 7 本书 |
| Claude 4 | 20 万 token | 1-2 本书 |
| GPT-4o | 12.8 万 token | 短篇小说 |
| Deepseek V3 | 12.8 万 token | 短篇小说 |
| 开源小模型 | 数万 token | 一份手册都装不下 |
看上去后面的模型窗口也不小------直到你实际用一个 Agent 跑起来。
| # | 问题 | 具体症状 |
|---|---|---|
| 1 | 窗口上限 | 哪怕 100 万 token 的窗口,长程 Agent 也会塞满------工具输出、文件内容、历史轮次堆得很快 |
| 2 | 质量退化(上下文腐烂) | 不加筛选的输入→模型混淆重点→回答含糊其辞。输入越杂乱,模型的理解就越差 |
| 3 | 成本 | 每一个输入 token 在每一轮都计费。"以防万一"把所有东西都加载进来,账单可能多出 10 倍以上 |
问题 2 是真正的杀手------上下文腐烂。 Chroma 在 2025 年测试了 18 个前沿模型,每一个都随着输入变长而退化:
- 200K 窗口的模型 → 在约 5 万 token 处就能测到明显的退化
- 信息放在长上下文的中段 → 召回率掉 15--20 个百分点
- 所有被测模型的中段准确率下降 30% 以上
原因是结构性的。注意力机制按 n² 增长------token 越多,模型的"注意力预算"就被摊得越薄。
一个反直觉的发现:模型在随机打乱 的文档上反而比在逻辑清晰组织 的文档上表现更好。逻辑结构创造了大量看起来都像答案的"似是而非的干扰项"。一个组织良好的代码库,对 LLM 反倒可能比一个随机排列的代码库更难搜索------因为每样东西看上去都可能是答案。
问题 3------成本------常被忽视,但在生产中咬得更狠。 一个长程 Agent 如果每一轮都把同一份 5 万 token 的代码库摘要重新加载一次,跑 40 轮就要为两百万 input token 付费。同一个 Agent 如果只持有文件路径、用到时再懒加载,可能总共只花 10 万 token。同样的答案,账单差 20 倍。
结论:你不能 只是把东西塞进窗口。你必须主动管理它------既为了质量 ,也为了成本。
上下文工程的四个操作
LangChain 提出了一个简洁的框架,能干净地映射到真实 Agent 的工作方式。对上下文,你能做的事一共只有四件:
| 操作 | 含义 | 一句话类比 |
|---|---|---|
| Write(写出) | 把上下文存到窗口外面 | 在纸上做笔记 |
| Select(选入) | 只把需要的拉进窗口 | 打开正确的那个文件 |
| Compress(压缩) | 留下精华,丢掉冗余 | 把会议写成纪要 |
| Isolate(隔离) | 把上下文分散到多个窗口 | 把活儿分给队友 |
一个好的 Agent,在每一步都在使用这四种操作。下面以 Claude Code 为具体例子,逐个走一遍。
1. Write(写出)------ 把上下文存到窗口外面
核心思路。 上下文窗口又小又贵。任何"以后还要用、但此刻不需要"的东西,都该放在别的地方------磁盘、记忆文件、待办列表。
两种形式:
- 草稿(Scratchpads)------当前任务的临时笔记(待办列表、计划文件)
- 记忆(Memory)------跨会话保留的知识(用户偏好、项目惯例)
Claude Code 怎么做:
| Claude Code 在做什么 | 所用工具 | 为什么 |
|---|---|---|
| 任务开始时写一份待办列表 | TaskCreate |
计划留在窗口外,每一步不必从头推理 |
| 跨会话保存用户偏好 | Write → ~/.claude/.../memory/user_*.md |
"用户偏好 Jetpack Compose + StateFlow"------再也不会问第二次 |
| 保存项目惯例 | Write → 仓库根目录的 CLAUDE.md |
项目里每次新会话都自动加载 |
| 上下文到 95% 时自动压缩 | 内置摘要机制 | 旧轮次被写成摘要,腾出窗口空间 |
| 把决策记录在 commit 里 | Bash git commit |
git log 成为下一次会话能读到的持久记忆 |
举个具体例子。 你告诉 Claude Code:"我们用 MVVM 和 Hilt。" 它把这一条写进 CLAUDE.md。六个月后,新的会话里你提出一个新需求------Claude 已经知道你的技术栈了,你一个字都不用再说。
2. Select(选入)------ 只把需要的拉进来
核心思路。 即时检索 胜过预加载。先持有轻量级指针(文件路径、ID),只有真正用到的那一刻才加载完整内容。
一个比喻。 与其把图书馆的全部书籍都摆在读者面前,不如让一个聪明的图书管理员------知道你要查什么、清楚每部书在哪里、能精准地只把你需要的那几页递给你。这就是 Select 的全部。
Select 分两种:
| 模式 | 何时加载 | 例子 |
|---|---|---|
| 静态(Static) | 每次都加载,与具体查询无关 | CLAUDE.md、.cursor/rules、系统提示词------项目的"宪法",每个会话都需要 |
| 动态(Dynamic) | 仅在与这次查询相关时加载 | Glob/Grep/Read/WebSearch------根据实际需求精准拉取 |
静态选入像"团队员工手册"------每个人入职第一天都要读,不用每次都考虑。动态选入则是聪明图书管理员的日常工作。
动态要选的对象:
- 对的记忆文件(当前场景适用哪些偏好?)
- 对的代码文件(这次改动涉及哪些文件?)
- 对的工具(这一步该调用哪个工具?)
- 对的知识(我需要哪些外部信息?)
Claude Code 怎么做:
| Claude Code 在做什么 | 所用工具 | 为什么 |
|---|---|---|
| 会话开始时自动加载项目惯例 | CLAUDE.md |
始终相关的程序性记忆,加载一次即可 |
| 按文件名找相关文件 | Glob ------ 例如 **/*ViewModel.kt |
廉价的"发现"动作,发生在昂贵的"读取"之前 |
| 按内容搜代码 | Grep ------ 例如 viewModels\(\) |
找到使用模式,不必读遍每一个文件 |
| 真正用到时才读某个文件 | Read ------ 例如 Read("TodoViewModel.kt") |
完整内容惰性加载,而不是一次性拉进来 |
| 按需获取外部文档 | WebSearch、WebFetch |
只有相关时才拉 2026 年最新的 Jetpack Compose 文档 |
| 在合适时机选用合适能力 | Skill 工具 |
专用能力仅在匹配的任务上才加载 |
举个具体例子。 你说:"给 TodoRepository 加一个离线缓存。" Claude 不会 通读你的整个仓库。它先用 Glob "**/Repository.kt" 了解仓库里 Repository 的整体结构,再用 Grep "Room\|Cache" 找已有的缓存模式,最后只 Read 真正相关的两三个文件。哪怕代码库有上百万行------窗口依然保持精简。
3. Compress(压缩)------ 留下精华,丢掉冗余
核心思路。 有些上下文必须留在窗口里,但你不需要它的每一个字。把它压到只剩"承重部分"。
两种常见做法:
- 摘要(Summarization)------把长历史改写成短简报
- 修剪(Trimming)------按启发式规则丢掉较旧或低价值的消息
Claude Code 怎么做:
| Claude Code 在做什么 | 工具 / 机制 | 为什么 |
|---|---|---|
| 上下文到约 95% 时自动压缩对话 | 内置递归摘要 | 对话可以一直跑下去,窗口不至于崩溃 |
| Sub-Agent 只返回 1--2K token 的摘要,而不是完整记录 | Agent 工具返回简短报告 |
协调者保持精简,深度探索发生在别处 |
Bash 输出过大时自动截断 |
输出在 3 万字符处截断 | 防止一条命令撑爆窗口 |
Glob/Grep 返回的是路径/行号,而不是文件内容 |
工具的返回形态本身就是设计 | 发现是廉价的;完整读取是可选的 |
长文件读取支持 offset + limit |
局部读取 | 一万行的文件,只把相关那一段放进上下文 |
举个具体例子:Claude Code 的 auto compact。
你已经调试了 90 分钟。Claude 执行了 50 条 Bash 命令,读取了 20 个文件,输出了一堆日志。窗口使用率到了 95%。
此时 Claude 自动触发 auto compact:80 轮对话被浓缩为一份 2K token 的摘要:
"已确认 ViewModel 被持有;排除了 Activity 泄漏;怀疑 Hilt 作用域不匹配;下一步检查 TodoFragment"
窗口使用率从 95% 降回 30%。后续工作从这份简报继续,而不是背着原始的 80 轮对话------同样的调试能力,但窗口被释放出来了,成本也降低了。
4. Isolate(隔离)------ 把上下文分散到多个窗口
核心思路。 有时答案不是"更小的上下文"------而是"更多个上下文 "。让每个聚焦的子任务拥有自己的干净窗口。探索发生在用完即弃的上下文里,只有结论回流到主线。
最经典的范式是 Lead Agent → Sub-Agent 架构(由 Anthropic 的 Multi-Agent researcher 项目推广开来):
vbnet
Lead Agent(总指挥)
├─ Sub-Agent A(PDF 搜索)------ 拥有自己的窗口、自己的工具、自己的历史
├─ Sub-Agent B(网页搜索)------ 拥有自己的窗口、自己的工具、自己的历史
└─ Sub-Agent C(代码分析)------ 拥有自己的窗口、自己的工具、自己的历史
│
└─→ 每个 Sub-Agent 并行运行,互不污染
└─→ 完成后返回"1K token 的摘要"给 Lead Agent
└─→ Lead Agent 综合三份摘要,产出最终答案这样做的好处是:每个子任务拥有一个干净的、聚焦的上下文,没有其他任务的历史干扰。Lead Agent 始终只看到 Sub-Agent 们的最终报告。
三种隔离模式:
(a) Sub-agents(子 Agent) ------把聚焦的工作派给一个拥有独立窗口的 Sub-Agent。(即上面讲过的 Lead Agent → Sub-Agent。)
(b) 环境隔离(Environment isolation) ------把大块数据彻底 留在 LLM 之外。数据待在沙箱、文件或数据库里;LLM 只看到对这些数据操作之后的结果,永远看不到原始的大块内容。
例子:分析一个 50 MB 的销售 CSV。 ❌ 错误做法: 把整张 CSV 粘进 prompt------窗口当场被撑爆,账单也很贵,而且模型对中间的数字本来就会记错。 ✅ 正确做法: CSV 留在磁盘上。Agent 写一小段 Python------
df.groupby('region').sum()------放进沙箱(E2B、Pyodide,或干脆一个子进程)跑一下,只把 10 行的结果表带回上下文 。LLM 从头到尾没见过这 50 MB,它只看到了答案。在 Android 场景里同理:堆转储、trace 文件、构建日志这些庞大的二进制文件都待在磁盘上,由分析工具处理,回到模型的只是"被持有最多的前 5 个类"或"最慢的 3 个方法"。
(c) 状态隔离(State isolation) ------你 Agent 内部 的状态(你代码里维护的数据结构),大于 你交给 LLM 看到的那份视图 。有些字段由你计算、被你用于路由或控制流,但从不暴露给模型。
- 按作用域拆分:将信息划分为:系统提示词(System)、短期记忆(Short-term)、长期记忆(Long-term)、工具反馈(Tool Output)。
- 动态挂载/按需加载:只有当Agent需要用"工具"时,才把工具返回的信息放入提示词。
- 修剪历史 (Auto-compact):当对话太长时,将之前的对话总结为"状态快照"而不是保存所有对话原句
例子:一个客服 Agent。 你的内部状态可能包含:
customer_id、conversation_history、sentiment_score、fraud_risk_score、account_balance、escalation_count。但 LLM 在每一轮并不需要 看到全部。LLM 起草回复时,你只暴露conversation_history + customer_first_name。sentiment_score由你的代码计算并用于路由 ------一旦低于 0.3 你就升级到人工,但你不告诉 LLM 这个数字 。fraud_risk_score由一层守门员(guardrail)在响应发出前读取,但永远不进 prompt。核心原则:你的系统跟踪的状态 ≠ LLM 看到的状态 。把路由/控制流字段藏起来,能让模型专注于对话本身,也避免它"对着"那些本来是给你 看、而不是给它看的数字进行推理。
Claude Code 怎么做:
| Claude Code 在做什么 | 所用工具 | 为什么 |
|---|---|---|
| 把调研派给 Sub-Agent | Agent(如 Explore、general-purpose) |
Sub-Agent 读了 20 个文件;主 Agent 只收到 500 token 的摘要 |
| 并行工作时使用 worktree | Agent(isolation: "worktree") |
每个分支拥有自己独立的工作副本 |
| 计划模式让工作保持只读 | EnterPlanMode / ExitPlanMode |
规划上下文与执行上下文相互分离 |
| 大块数据留在磁盘,不进窗口 | Read/Write 文件 |
500 行的文件躺在磁盘上,只有需要的切片才进入上下文 |
| 用专门角色的 Agent 处理专门任务 | Sub-Agent 类型(Explore、Plan、code-reviewer 等) | 每个都有独立的系统提示词与工具集,与主线隔离 |
举个具体例子。 你问:"诊断我们的应用为什么会在第 10 次 Activity 切换之后崩溃。" Claude 不会试图在一个窗口里硬解。它并行派出三个 Sub-Agent:
- Sub-Agent A 探索
Activity生命周期相关代码 → 返回"怀疑 TodoFragment 持有了 ViewModel" - Sub-Agent B 读取最近的崩溃日志 → 返回"所有崩溃都包含
OutOfMemoryError" - Sub-Agent C 调研 Hilt 作用域配置 → 返回"有 3 处使用了 ActivityRetainedScope"
每个 Sub-Agent 都读了几十个文件。主 Agent 的窗口里只看到三段简短摘要------并据此综合出最终答案。
上下文的四种失败模式
Agent出问题时,原因通常就是下面这四种之一(Drew Breunig 的分类)。叫得出名字,调试就更快:
| 失败模式 | 发生了什么 | 如何修复 |
|---|---|---|
| 中毒(Poisoning) | 一个幻觉混进上下文,并被反复强化 | 写入前先验证;不要把未核实的输出写进记忆 |
| 分心(Distraction) | 上下文太多,信号被噪音淹没 | 压缩或隔离;激进地修剪 |
| 混淆(Confusion) | 看似相关、实则无关的信息影响了答案 | 选得更挑剔;不要"以防万一"地预加载 |
| 冲突(Clash) | 上下文内部互相矛盾 | 在写入时就解决,而不是读取时 |
大多数"模型今天怎么变笨了"的抱怨,最终都会落到这四种之一------而不是模型本身的问题。
端到端示例:在 Android 中构建一个 Todo 功能
下面是 Claude Code 处理这条真实请求时的会话流,看四种操作如何协同工作:
"加一个功能:创建待办,并把它们显示在列表里。"
csharp
收到用户请求
│
▼
[SELECT] CLAUDE.md 自动加载 → "MVVM、Compose、StateFlow、Hilt"
│
▼
[WRITE] TaskCreate → 计划存到窗口外
• 寻找现有模式
• 增加数据层
• 增加 ViewModel
• 增加 UI
│
▼
[ISOLATE] 派出 Agent(Explore) →
Sub-Agent 在自己窗口里读了 12 个文件,
返回:"Repository 模式 + LazyColumn + StateFlow"
│ (约 800 token 回流)
▼
[SELECT] Glob "**/*Repository.kt" → 3 条路径
Read("TodoRepository.kt") → 只读相关的 40 行
│
▼
[WRITE] Write TodoViewModel.kt
Write TodoListScreen.kt
Edit MainActivity.kt
│
▼
[WRITE] Bash git commit "feat: add todo creation and display"
TaskUpdate → completed
│
▼
[COMPRESS] 若对话过长 → 自动压缩较旧的轮次
│
▼
[WRITE] 记忆更新:"本项目的列表使用 LazyColumn + StateFlow"
→ 下一个功能自动复用这一模式注意有些事情没有发生:
- Claude 没有通读整个代码库(Select 让上下文保持很小)
- Claude 没有把每一轮历史都背着走(Compress 和 Write 把它们移到了窗口外)
- Claude 没有在一个窗口里硬解所有事情(Isolate 派出了 Sub-Agent)
- Claude 没有在下次会话里忘记你的约定(Write 把它们存住了)
这就是上下文工程。不是某句"魔法咒语",而是 Write、Select、Compress、Isolate 这一套循环------在每一步都被纪律性地执行。
Agent 兴起与 Context Engineering 的关联
上下文工程之所以在 2024-2025 成为热点话题,背后有一个重要的推动力:Agent 的兴起。
一个 Agent 不是单轮的提示-回答,而是长程的、反复迭代的、不断积累上下文的系统。每执行一次工具,就会有一个工具执行结果堆进窗口。跑 5 分钟也许没事,跑 50 分钟呢?跑了一周、自主合并了 200 个 PR 之后呢?
Context 的管理效果,会直接影响到 Agent 的执行结果。
一个 Agent 在"信息充分、上下文整洁"的环境里,可能表现卓越。同一个 Agent,被塞进杂乱无章的上下文里,表现可能直线下降。这是为什么 Context Engineering 的技术突然变得至关重要------因为它决定了 Agent 能不能从"有趣的实验"活下来,变成"可以在生产环境里长期运行"的系统。
但,仅有好的 Context Engineering 还不够。
第三部分:Harness Engineering(驾驭工程)
让我们从一个问题开始:
如果我告诉你,同一个模型,靠更换 Harness,性能能从 52.8% 跳到 66.5%,你会觉得不可思议吗?
这不是理论数据,这是 LangChain 在 Terminal Bench 2.0 真实跑出来的结果。他们什么都没改------没换更强的模型,没改 Prompt,只改了 Harness------就把排名从 Top 30 跳到 Top 5。
这说明什么?
说明真正拉开差距的,不是模型本身,而是模型周围的那套系统。
什么是 Harness
我用一个隐喻,你一听就懂。
模型就是一匹马。 力气很大,跑得很快,但它自己其实不知道该往哪跑。
工程师就是骑手。 我们的工作是给方向。
Harness(马具)就是缰绳、马鞍、嚼子。 它的工作是把这匹马的原始力量,导向有用的工作。
所以:
Agent = Model + Harness
模型提供智能 ;Harness 让智能真的有用。
Harness 就是把一个原始模型变成一个能用的 Agent 所需的"全部其他东西"------文件系统、Git、代码执行、沙盒、记忆、工具、循环、约束、反馈。
有句话抓住了 Harness 的本质:"如果你不是模型本身,那你就是 Harness 的一部分。"
这意味着什么?真正的竞争力不在模型有多聪明,而在于 Harness 有多完善。
为什么 Harness 现在变成了主战场
第一个原因:天花板效应
模型的基座已经足够强了。但大家发现了什么?
单纯依赖更牛的模型,其实解决不了业务里的复杂问题。
模型只是引擎。如果没有好的底盘和传动系统------也就是 Harness------这个引擎的能力根本释放不出来。
就好比你有一个顶尖的厨师,你把他扔进一个乱七八糟、没火又没灶的厨房。他也是施展不开的。
第二个原因:裸模型的内在缺陷
即使是 GPT-4.5 这样的顶级模型,如果没有 Harness 约束,也会出现两个问题:
一个叫"焦虑症"------模型试图一口气干完所有工作,结果导致上下文耗尽,卡住了。
一个叫"自满症"------模型看到一点进展,就自以为是地宣布"搞定了!"然后停下来,完全不去验证。
这不是模型傻,这是架构级的缺陷。你靠写 Prompt 救不了这个------必须靠 Harness 层面的流程控制。
第三个原因:连锁失败的数学逻辑
我给你念一个数据。
假设一个 Agent 的任务链条有 20 步。看起来每一步的成功率都很高,都是 95%。
那你们算一下:0.95 的 20 次方是多少?
只有 36%。
这就是为什么很多团队反馈说:"我们的模型 95% 的时间都在正常工作,但一到真实的任务上,还是有明显的失败率。"
因为这种连锁失败不是靠模型变聪明解决的。必须靠 Harness 里的中间检查点和回滚机制,来强制地打破这个概率链。
第四个原因:竞争壁垒转移
现在的 GPT、Claude、Gemini,核心能力越来越接近。他们开始有点商品化的意思。
当大家用的模型都差不多时,谁的系统设计稳?谁的 Harness 质量高?谁就有护城河。
所以,四个原因汇聚到一点:模型是引擎,Harness 是整车设计。再强的引擎,也得有好的底盘才能跑起来好。
Human Steer, Agent Execute(人类掌舵,Agent 执行)。
人类不是去替 Agent 做决定,而是去搭建那套让 Agent 的决定保持在轨道上的系统。这正是 Harness 的工作。
Harness 的六大组件
我们从一个问题开始:一个"裸模型"到底有什么根本性的缺陷?
答案是四个:
第一个缺陷:无记忆 每次对话都从零开始,不能跨会话积累知识。一个 Agent 5 小时前做过的决定,下一个会话它完全忘了。
第二个缺陷:无行动 只能生成文本,不能执行代码、修改文件、看到结果。就像一个盲人,知道该怎么做,但看不到结果。
第三个缺陷:知识截止 训练数据有时间界限。模型对 2026 年发布的最新库、最新 API,一无所知。
第四个缺陷:无环境 没有受控的运行时、没有约束、没有质量关卡。就像没有红绿灯、没有安全帽的工地。
Harness 就是为了补齐这四个缺陷而存在的。
把这四个缺陷和对应的解决方案展开,就得到了一套成熟 Agent Harness 的六大组件:
| # | 组件 | 解决缺陷 | 具体工具 |
|---|---|---|---|
| 1 | 文件系统 + Git | 无记忆 | Read/Write/Edit + Bash git ... |
| 2 | Bash + 沙箱 | 无行动 | Bash 工具 + EnterWorktree |
| 3 | 记忆系统 | 无记忆 | CLAUDE.md、~/.claude/.../memory/ |
| 4 | 网络搜索 + MCP | 知识截止 | WebSearch、WebFetch、MCP 服务器 |
| 5 | 上下文工程 | 无环境 | 自动压缩、Skill、Read offset/limit |
| 6 | 编排 + Hooks | 无环境 | Agent()、TaskCreate、PreToolUse/PostToolUse Hooks |
六大组件实战速览
每个组件都有对应的 Claude Code 工具和实践方案。快速对照表如下:
1️⃣ 文件系统 + Git
解决的缺陷: 无记忆
核心职责: 把一切临时的、稍后需要的信息写出来,不要塞进上下文窗口。
一个 Agent 在一个会话里生成的计划、笔记、中间产物、决策日志 ,如果都硬要放在上下文里,很快就会撑爆窗口。文件系统的角色就是:永久化存储。
三个关键用途:
- 计划与待办 :Agent 用
TaskCreate把任务清单写出去,不必背着走 - 项目约定 :
CLAUDE.md、AGENTS.md记录技术栈、模块边界、规范------新会话自动加载 - 版本与回滚 :Git 让每次改动都有迹可循。
git log成为下一个会话能读到的历史
Git 的额外价值: 它不仅是版本控制,更是一个时间机器 。Agent 5 小时前做过什么决定?为什么那样做?git log 和 commit message 里都有。
Claude Code 实践方案:
| 操作 | Claude Code 工具 | 具体用法 |
|---|---|---|
| 计划存储 | TaskCreate() |
在会话开始时创建任务列表,计划不进窗口 |
| 项目约定 | Write + 根目录 CLAUDE.md |
写入技术栈、架构约定、禁止项;新会话自动加载 |
| 跨会话记忆 | Write + ~/.claude/.../memory/ |
保存用户偏好、项目惯例,下次会话自动注入 |
| 版本追踪 | Bash git commit |
每个重要改动都 commit;commit message 记录"为什么" |
| 历史回溯 | Bash git log / git show |
需要回顾决策时,直接查 git 历史而不是问用户 |
具体场景:
markdown
第一个会话:
1. TaskCreate → 把计划写成待办列表
2. Write CLAUDE.md → "项目用 MVVM、不用新的网络库"
3. 工作完成后 → git commit "feat: xxx. 为什么: xxx"
第二个会话(两周后):
1. CLAUDE.md 自动加载 → Claude 已经知道技术栈
2. git log 可查阅 → 上次会话的所有决策都在 commit message 里
3. Memory 文件自动加载 → 用户偏好已记录
→ 新会话从"继续"而不是"重新开始"2️⃣ Bash + 沙箱 ------ 行动能力与自我验证闭环
解决的缺陷: 无行动
核心职责: 让 Agent 不仅能说出 应该做什么,还能真的做 ,并看到结果、能改。
一个文本模型如果只能生成代码但看不到运行结果,本质上是盲人 。Bash + 沙箱让 Agent 形成一个自我修正的闭环:
写代码 → 跑 Bash → 看输出 →
❌ 错了?读错误信息 → 修改 → 重新跑
✅ 对了?继续下一步两个关键概念:
- Bash 工具:执行任意命令,编译、测试、部署、分析都靠它
- 沙箱隔离 :用
EnterWorktree把 Agent 的工作隔离到临时目录,不会污染主分支。同时隔离资源------内存、网络、文件访问都有边界
为什么这很关键: 如果没有沙箱,一个失控的 rm -rf / 可能真的会删掉整个系统。沙箱让 Agent 在"安全的操练场"里失败、学习、重试。
Claude Code 实践方案:
| 操作 | Claude Code 工具 | 具体用法 |
|---|---|---|
| 执行命令 | Bash 工具 |
编译、测试、分析代码;Bash 返回 stdout/stderr,Agent 读结果后修改 |
| 沙箱隔离 | EnterWorktree() |
创建临时工作副本,所有改动不影响主分支,完成后 ExitWorktree() 清理 |
| 权限控制 | Permission 模式 | 用户可设定"哪些命令需要审批"(如 git push、rm 等) |
| 输出截断 | 自动机制 | Bash 输出超过 30K 字符自动截断,避免窗口爆炸 |
| 错误处理 | Bash 返回码 | Agent 读 stderr 和返回码,自动判断成功/失败,决定重试或改进 |
具体场景:
markdown
任务:修复一个 Android 构建失败
第一轮:
1. Agent 运行 `./gradlew :module:test`
2. 看到测试失败,读错误日志
3. 修改源代码
4. 重新运行 test → 通过 ✅
沙箱的作用:
• 如果 Agent 误写了 `rm -rf src/`,只删掉临时副本,主项目安全
• Agent 可以放心尝试激进的重构,因为可以随时 `ExitWorktree(action: "remove")`
• 不同的分支隔离 → 多个 Agent 可以同时在不同 worktree 里工作,互不干扰自我修正闭环的威力:
erlang
Agent 不仅能"写出代码",更能"验证代码":
写 → 编译 → ❌ 编译失败?读错误 → 修改 → 重新编译 → ✅ 通过
相比之下,没有 Bash 的 Agent(例如传统 ChatGPT)只能:
写 → 用户说"不对" → 重新写 → 用户说"还是不对"...
Bash 让 Agent 自动形成**闭环反馈**。3️⃣ 记忆系统(AGENTS.md / CLAUDE.md) ------ 跨会话的知识积累
解决的缺陷: 无记忆
核心职责: 不改模型权重,用文档形式动态注入知识。
每个新会话,Agent 都从零开始。但你的项目有约定、惯例、最佳实践 ------这些不应该每次都重新说一遍。记忆系统的答案是:写成 Markdown,每次自动加载。
三层记忆体系:
| 层级 | 内容 | 生命周期 | 例子 |
|---|---|---|---|
| 项目级 | CLAUDE.md |
长期(项目级别) | 技术栈:MVVM、Compose、StateFlow;禁止依赖:不引入新网络库 |
| 用户级 | ~/.claude/.../memory/user_*.md |
长期(跨项目) | "用户偏好 Jetpack Compose"、"倾向于函数式风格" |
| 会话级 | TaskCreate、压缩摘要 |
短期(单个会话) | "已排除 Activity 泄漏;下一步检查 Hilt" |
为什么这比提示词好: 一个好的 prompt 写一次;一个好的记忆文档可以被复用、被继承、被升级。项目收藏了最佳实践,新来的 Agent(或新人)自动受益。
Claude Code 实践方案:
| 层级 | Claude Code 工具 | 具体用法 | 自动加载时机 |
|---|---|---|---|
| 项目级 | Write → 根目录 CLAUDE.md |
写入技术约定、架构边界、禁止项 | 每个会话开始自动加载 |
| 用户级 | Write → ~/.claude/.../memory/user_*.md |
记录用户偏好、编码风格、常见决策 | 跨项目自动加载 |
| 会话级 | TaskCreate / 压缩摘要 |
当前会话的中间发现、已排除的假设 | 会话内持续可见 |
具体写法示例(CLAUDE.md):
markdown
# 项目技术栈
- **UI 框架**:Jetpack Compose(不用 XML)
- **状态管理**:StateFlow + ViewModel
- **依赖注入**:Hilt(不引入新的 DI 框架)
- **网络库**:Retrofit + OkHttp(已有,不要新增)
# 架构规则
- **禁止反向依赖**:ui/ 不能依赖 vm/;vm/ 不能依赖 repo/
- **单元测试**:所有 public 函数必须有测试
- **错误处理**:Repository 返回 Result<T>;ViewModel 转换为 UiState
# 常见决策
- **为什么用 StateFlow 而不是 LiveData**:支持多观察者、更易测试
- **为什么用 ViewModel 而不是在 Composable 里直接修改 state**:关注点分离、会话期间状态保留具体使用场景:
sql
第一个会话:
User: "加一个用户列表功能"
Claude Code:
1. 自动加载 CLAUDE.md
2. 看到"StateFlow + ViewModel"的约定
3. 自动按这个架构实现
4. 写完代码 → git commit
"feat: add user list screen
Architecture:
- UserListScreen: Composable UI
- UserListViewModel: manages state via StateFlow
- UserRepository: data layer with caching
Follows CLAUDE.md conventions for architecture"
第二个会话(一周后,新人加入):
New Engineer: "加一个用户搜索功能"
Claude Code:
1. CLAUDE.md 自动加载 → "我知道这个项目的约定"
2. 之前会话的 git commit 在 → 可以看到上次决策的原因
3. Memory 文件加载 → 知道这个用户的编码偏好
→ 新 Agent(或新人)从"继承最佳实践"开始,不用重复讨论架构记忆文件的进化(越来越聪明):
objectivec
初始 CLAUDE.md(3 行):
"MVVM, StateFlow, Hilt"
一个月后(补充经验):
"MVVM, StateFlow, Hilt
禁止 LiveData, 禁止引入新网络库
Repository 返回 Result<T>"
三个月后(累积决策):
[完整的架构文档,包含所有已做过决策的记录]
这个文件成了"项目的开发手册"------新人进来读这个,
比 100 次口头解释都管用。4️⃣ 网络搜索 + MCP ------ 突破知识截止与感知外部世界
解决的缺陷: 知识截止
核心职责: 让 Agent 感知当下的世界,不被训练数据的截止日期限制。
一个模型的训练数据有时间界限。但你的项目在现在运行------有新的库版本、有新的 API、有新的最佳实践。Agent 需要访问这些实时信息。
两条不同的路线:
-
Web Search:爬取公开互联网
- 用途:最新的文档、StackOverflow 答案、GitHub 讨论
- 例子:
WebSearch("React 18.3 hook best practices 2026")
-
MCP(Model Context Protocol):接入内部系统
- 用途:你公司内部的 CRM、内部 Wiki、监控系统、私有 API
- 例子:
MCP get-customer {id}可能直接查询你们的数据库 - 关键优势:LLM 永远无法训练到你的内部数据。MCP 让 Agent 用标准化协议访问它们
为什么要分开两个: Web Search 是"我需要公开信息";MCP 是"我需要这个公司特有的信息"。同一套接口标准,但数据来源完全不同。
Claude Code 实践方案:
| 需求 | Claude Code 工具 | 具体用法 | 何时触发 |
|---|---|---|---|
| 最新文档 | WebSearch() |
搜索最新的库文档、API、最佳实践 | Agent 判断需要当前信息时主动调用 |
| StackOverflow | WebSearch() |
找解决方案、看常见错误 | 遇到陌生错误时 |
| 内部数据 | MCP 服务器(需配置) | 查询内部 Wiki、CRM、监控系统、私有 API | 需要公司内部信息时 |
| 缓存机制 | 自动(WebFetch) | 15 分钟内重复访问同一 URL 会用缓存 | 降低成本、加快速度 |
具体使用场景:
arduino
场景 1:最新库文档查询(Web Search)
Task: 用 Jetpack Compose 的 Navigation 实现页面跳转
Claude Code:
1. CLAUDE.md 说"用 Compose"
2. 但 Claude 的训练数据是 2025 年 1 月
3. 最新的 Navigation API 可能已更新
4. 主动 WebSearch("Jetpack Compose Navigation 2026 latest")
5. 找到最新文档 → 按最新 API 实现
好处:不会用过时的 API;代码从一开始就是"新"的
场景 2:公司内部 API 查询(MCP)
Task: 查询当前用户的订阅状态
如果有 MCP 服务器配置(指向公司的用户服务):
Claude Code:
1. 判断需要用户数据
2. 调用 MCP:`get-user-subscription {user_id}`
3. 实时查询公司数据库
4. 获得真实数据 → 写出正确的业务逻辑
好处:不用手工告诉 Claude "订阅有哪些状态"
Agent 直接从系统真相查询MCP 的配置示例(概念):
json
// 项目根目录 claude_mcp.json(概念示例)
{
"servers": {
"user-service": {
"command": "python",
"args": ["./mcp_server_user.py"],
"env": {
"DB_HOST": "internal-db.company.com",
"DB_CREDS": "from-vault"
}
},
"internal-wiki": {
"command": "node",
"args": ["./mcp_server_wiki.js"],
"url": "https://wiki.internal.company.com"
}
}
}
// 这样配置后,Claude Code 自动获得这些 MCP 工具
// Agent 可以直接:
// WebFetch 公司 Wiki
// 查询用户数据库
// 读取内部监控数据与 RAG 的对比:
arduino
RAG(传统做法):
你说:"用户有三种状态:active, suspended, cancelled"
Agent 记住这个信息,写代码时参考
→ 如果规则改了,你要重新告诉 Agent
MCP(新做法):
配置一次 MCP 服务器
Agent 每次都直接查询最新的用户状态定义
→ 规则改了自动生效,Agent 无需更新
MCP 的优势:系统即真相,不用同步信息5️⃣ 上下文工程 ------ 信息质量管理
解决的缺陷: 无环境(信息环境不受控)
核心职责: 这是我们在 Part 2 讲过的四个操作:Write、Select、Compress、Isolate。
在 Harness 的语境里,上下文工程的角色是:在长程运行中,确保 Agent 看到的信息始终是精简的、相关的、有质量的。
具体机制:
- Write:计划、决策写到文件,不进窗口
- Select:只按需加载相关的代码、文档、记忆
- Compress:当窗口到 95% 时,自动把旧的对话轮次压缩成简报
- Isolate:复杂任务派给 Sub-Agent,主 Agent 只看摘要
一个关键数据点: 一个 Agent 跑 8 小时,如果没有上下文工程,可能只能利用其中最后的 2 小时 的对话历史(因为前面的被噪音淹没了)。有上下文工程,它能有效利用整个 8 小时。
Claude Code 实践方案:
| 操作 | Claude Code 工具 | 具体用法 | 何时触发 |
|---|---|---|---|
| Write | TaskCreate / Write 文件 |
计划、笔记、阶段产物写到文件,不进窗口 | 会话开始 / 任何时刻有"以后还要用"的信息 |
| Select | Glob / Grep / Read / WebSearch |
只加载相关的代码、文档、记忆 | Agent 需要特定信息时 |
| Compress | 自动(95% 时触发) | 旧对话轮次压缩成摘要 | 窗口使用率达到 95% |
| Isolate | Agent() 派发 Sub-Agent |
复杂任务分派给专门的 Sub-Agent | Agent 判断任务太复杂 / 需要并行 |
具体使用场景:
erlang
长程任务:修复一个复杂的内存泄漏(需要 4-6 小时的调试)
会话流程:
├─ 【0:00】开始
│ ├─ TaskCreate → 计划:收集信息、分析堆转储、对比两个版本...
│ └─ CLAUDE.md 自动加载
│
├─ 【1:30】收集信息阶段
│ ├─ Grep "ViewModel" 找相关代码
│ ├─ Read 三个重点文件(其他文件暂不加载)
│ └─ WebSearch 最新的 Hilt 内存泄漏问题
│ └─ 窗口占用:35%
│
├─ 【2:45】发现可疑点
│ ├─ 写笔记到临时文件:"怀疑 TodoViewModel 被 Activity 强持有"
│ ├─ Bash 运行堆转储工具
│ └─ 窗口占用:42%
│
├─ 【3:15】对比版本
│ ├─ Bash git diff v1.0 → 看改了什么
│ ├─ 堆转储显示对象数量差异
│ └─ 窗口占用:55%
│
├─ 【4:00】进行修改
│ ├─ Write 修复代码
│ ├─ Bash 编译 + 测试
│ ├─ 发现还有问题,继续改
│ └─ 窗口占用:78%
│
├─ 【4:45】窗口即将满(95%)
│ ├─ 【Compress 自动触发】
│ ├─ 旧的 80 轮对话 → 压缩成 2K token 摘要:
│ │ "已排除:Activity 泄漏、Service 泄漏
│ │ 确认:ViewModel 被 Listener 持有
│ │ 已改:移除 Listener 注册 + 改 WeakReference
│ │ 状态:还有内存增长,需要检查 Coroutine 泄漏"
│ │
│ ├─ 窗口占用降回:38%
│ └─ 后续工作继续从这份摘要继续
│
└─ 【5:30】完成
└─ git commit "fix: resolve memory leak in TodoViewModel"
内容完整,无遗漏(即使进行了压缩)四个操作的协同:
scss
没有上下文工程:
[写代码] → [跑测试] → [改代码] → ... (一直都在增加历史)
→ 到 4 小时时,窗口满了,前面 2 小时的信息被挤出
→ 到 5 小时时,发现问题,想回顾早期的假设,但早期信息已丢失
→ 只能向用户问:"我们之前排除了什么?"
有上下文工程:
[计划存文件] → 清楚当前目标
[只加载需要的代码] → 不读无关文件
[自动压缩] → 历史被浓缩成摘要,但关键信息保留
[需要时派出 Sub-Agent] → 复杂分析不在主线,有独立窗口
→ 到 5 小时时,所有关键信息都还在(以摘要形式),可以高效继续6️⃣ 编排 + Hooks ------ 系统控制与质量关卡
解决的缺陷: 无环境(无约束、无反馈机制)
核心职责: 协调多个 Agent,并在模型的输出上加上确定性的验证。
编排(Orchestration):
- Lead Agent 分派任务给多个 Sub-Agent
- Sub-Agent 并行或串联执行
- Lead Agent 汇聚结果
例子:一个 Agent 需要同时读代码、读文档、搜网络。与其一个 Agent 做三件事,不如三个 Sub-Agent 各做一件,再由 Lead 汇聚。
Hooks(钩子):
- PreToolUse :工具调用前 的守门员
- 参数合法吗?
git commit前检查 lint 是否通过 - 这个操作被允许吗?禁止 Agent
rm -rf
- 参数合法吗?
- PostToolUse :工具调用后 的质量检查
- 输出格式正确吗?JSON 真的是有效 JSON 吗?
- 内容符合约束吗?文件不能包含硬编码密钥
为什么这很重要: LLM 是概率模型,有时会"幻觉"。Hooks 是你的防线 ------不是信任 Agent,而是验证 Agent 的每一步。
Claude Code 实践方案:
| 操作 | Claude Code 工具 | 具体用法 | 场景 |
|---|---|---|---|
| 多任务编排 | Agent(subagent_type="...") |
Lead Agent 派出多个 Sub-Agent | 需要并行:代码分析 + 文档搜索 + 网络搜索 |
| 任务流程 | TaskCreate / TaskUpdate |
记录任务状态,设定依赖关系 | 多步骤任务,需要严格顺序 |
| PreToolUse Hook | 用户权限配置 | 工具调用前拦截;检查参数合法性、权限 | git push 前审批、禁止 rm -rf |
| PostToolUse Hook | 验证脚本(自定义或内置) | 工具调用后验证输出;检查格式、安全性 | 文件写入前检查密钥、JSON 格式检查 |
具体使用场景:
vbnet
场景 1:并行编排(多 Sub-Agent)
任务:"诊断为什么新版本的 APK 比上版本大了 50MB"
Lead Agent 的决策:
└─ 这个任务涉及多个方向,适合并行
└─ 派出三个 Sub-Agent:
├─ Sub-Agent A(代码分析)
│ └─ 搜索最近的 gradle 配置改动
│ └─ 查看是否新增了重库
│ └─ 返回摘要:"新增了 exoplayer,拉入了 3 个传递依赖"
│
├─ Sub-Agent B(资源分析)
│ └─ 扫描 res/ 下的新增资源
│ └─ 对比两个版本的图片、音视频
│ └─ 返回摘要:"新增了 20MB 高清贴图"
│
└─ Sub-Agent C(方法数分析)
└─ 运行 DEX 分析工具
└─ 对比两版本的类和方法数
└─ 返回摘要:"新增了 8000 个方法(来自 exoplayer)"
Lead Agent 汇聚:
"APK 增长来自三部分:
- exoplayer(3MB 库 + 8000 个方法)
- 新增贴图(20MB)
- 其他依赖(27MB)
建议:1. 用 ProGuard 去掉 exoplayer 未用的部分
2. 压缩贴图
3. 考虑动态下发"
好处:
• 三个 Sub-Agent 并行,总时间 = 最长的单个任务(而不是三个相加)
• 每个 Agent 窗口干净,不受其他分析的干扰
• 最终答案综合了多个角度场景 2:Hooks 质量关卡
javascript
配置示例(在项目设置中):
PreToolUse Hooks:
├─ 规则 1:git commit 前必须通过 lint
│ └─ 拦截 Agent 的 `git commit` 调用
│ └─ 先跑 `./gradlew lint`
│ └─ 如果失败,打回给 Agent:"修复 lint 错误再 commit"
│
├─ 规则 2:禁止危险命令
│ └─ 检测 `rm -rf` / `git reset --hard` / `git push --force`
│ └─ 要求用户显式确认
│
└─ 规则 3:文件写入检查
└─ 禁止写入 `/etc/` / `/root/` 等系统路径
└─ 禁止写入敏感文件(`credentials.json`, `.env` 含密钥)
PostToolUse Hooks:
├─ 规则 1:JSON 格式检查
│ └─ 如果 Agent 输出 JSON,验证是否有效
│ └─ 无效则拦截,要求 Agent 修正
│
├─ 规则 2:代码合规检查
│ └─ 生成的代码跑过 SAST(静态分析)
│ └─ 检测硬编码密钥、SQL 注入风险等
│ └─ 有问题则拦截,返回错误给 Agent
│
└─ 规则 3:测试覆盖率
└─ 新增代码必须有单测
└─ 测试覆盖率 < 80% 则失败
效果示例:
Agent 写完代码,运行 `git commit`
│
▼ [PreToolUse Hook]
"lint 检查中..."
│
├─ ❌ 有问题:"在 line 42 有未使用的导入"
│ └─ Agent 读到错误 → 修改代码 → 重新 git commit
│
├─ ✅ 通过 → 继续
│
▼ [真正执行 git commit]
完成后 [PostToolUse Hook]
"代码合规检查中..."
│
├─ ❌ SAST 发现风险:"硬编码 API key"
│ └─ Agent 读到错误 → 改成从环境变量读 → 重新 commit
│
└─ ✅ 通过 → 提交成功
关键点:
• Agent 不是"被信任的",而是"被验证的"
• 每一步都有确定性的检查,不依赖 Agent 的自觉性
• Hook 失败时,Agent 会自己读错误、自己修正
• 这就是把"概率性模型"变成"可生产系统"的方式编排 vs 单 Agent 的对比:
vbnet
单 Agent 的问题:
"诊断 APK 增长"
→ 一个 Agent 需要:分析代码 + 分析资源 + 分析方法数 + 综合
→ 四件事都在一个窗口里
→ 对话变得又臭又长,容易混乱
多 Agent 编排的优势:
├─ Sub-Agent-A 只关注代码改动(窗口小、聚焦、快)
├─ Sub-Agent-B 只关注资源改动(窗口小、聚焦、快)
├─ Sub-Agent-C 只关注方法数改动(窗口小、聚焦、快)
└─ Lead Agent 综合(输入是三份摘要,很清晰)
总耗时 ≈ 最长的单个分析,不是三个分析的总和
输出质量更高(因为每个 Agent 可以深入)各组件之间的协同关系
这六个组件不是孤立的。一个实际的 Agent 运行时:
css
[任务来临]
│
▼
[System Prompt] ← 定义 Agent 的角色和约束
│
▼
[记忆系统加载] ← 自动加载项目约定(CLAUDE.md)和用户偏好
│
▼
[编排] ← Lead Agent 决定是否派出 Sub-Agent
│
├─→ [网络搜索 + MCP] ← 如果需要外部信息
│
├─→ [上下文选择] ← 只加载相关的代码、文档
│
└─→ [Agent 思考并调用工具]
│
▼
[PreToolUse Hook] ← 工具调用前验证
│
▼
[Bash 执行] ← 在沙箱里运行,文件系统记录结果
│
▼
[PostToolUse Hook] ← 工具调用后验证
│
▼
[上下文压缩] ← 如果窗口接近上限,压缩历史
│
▼
[文件系统记录] ← Git commit,或者写入任务记录每个层级都在为整个系统服务。缺一不可。
其中有几行特别值得拎出来看:
- 文件系统是 Harness 的"内存条之外的硬盘"。 Agent 自己装不下的一切------计划、笔记、阶段产物------都靠它兜底。没有文件系统的 Agent,本质上只能"过目即忘"。
- Bash + 沙箱是行动闭环。 它给 Agent 的不只是"能执行代码"这件事,更重要的是**"跑了之后能看到结果、能据此修正"**------这才是 Agent 之所以是 Agent 的根本。
- 网络搜索 + MCP 解决的是同一个问题------"知识截止" ------但目标不同:Web Search 抓公开互联网 ,MCP 抓你公司内部那些 LLM 永远训练不到的东西(CRM、内部 Wiki、监控系统)。
- Hooks 是 Harness 工程里最被低估的一件武器。
LLM 本质上是概率模型------给同样的输入,不同时刻可能产生不同的输出。但生产环境不容许"运气好的时候就对,运气差的时候就错"。Hooks 的作用就是:在模型的概率性输出上面,套一层确定性的质量关卡。
具体方式:
- PreToolUse Hook:工具调用前检查------该参数是否合法?这个操作是否被禁止?
- PostToolUse Hook:工具调用后验证------输出是否符合安全约束?是否满足格式要求?
例子:
- "凡是
git commit都先跑一遍 lint,Lint 失败则拒绝 commit" - "凡是
Write文件都检查------这个路径是否在允许列表里?内容是否包含硬编码密钥?"
这就是把**"概率性 Agent"驯化成"可上生产 Agent"的关键扳手**。
还有一个常被忘掉的「第零号组件」------ System Prompt。
它不是六大组件之一,但它是把这六者串起来的神经系统:
- 定义 Agent 的角色:它是什么、它该做什么
- 设置行为边界:能做什么、不能做什么
- 编码安全约束:隐私、安全、合规限制
- 指定优先级:六个组件出现冲突时该如何取舍
一段好的系统提示词,本身就是这套 Harness 的宪法。它决定了所有其他组件如何协同运作。
这六类组件共同的特征是:它们都不是模型本身的能力,而是模型周围的脚手架。
一个更深的观察:这六个组件本身是分层的、互相依赖的:
- 底层:文件系统(最基础的原语------持久化存储)
- 行动层:Bash + 沙箱(给模型行动的能力,以及自我验证的闭环)
- 记忆层:记忆系统(跨会话的知识积累)
- 感知层:网络搜索 + MCP(感知外部世界)
- 优化层:上下文工程(管理这些信息的质量)
- 控制层:编排 + Hooks(确保行动不越界)
这不仅仅是六个独立的组件,而是一个有机系统。去掉任何一层,整个 Agent 都会失效。把这套脚手架搭好,一个 Sonnet 也能干出 Opus 的活;脚手架烂,再好的模型也跑不远。
在 Android 场景下,Harness 长什么样?
把上面所有抽象的东西拉回到一个真实场景。假设我们用 Claude Code 维护一个 Android 框架模块,一个有 Harness 的工作流大概长这样:
bash
┌─────────────────────── Guides(前馈,行动前)───────────────────────┐
│ │
│ • CLAUDE.md 项目约定:MVVM、Compose、StateFlow、Hilt │
│ • AGENTS.md 模块边界:ui/ → vm/ → repo/,禁止反向依赖 │
│ • skills/*.md 团队 how-to:如何写 ViewModel 单测 │
│ • Bootstrap 会话开始时 `./gradlew :module:dependencies` │
│ │
└────────────────────────────────────────────────────────────────────┘
│
▼
┌───────────── Agent 工作 ─────────────┐
│ │
│ Model + 六大组件 │
│ - 文件系统/Git │
│ - Bash 执行 │
│ - 沙盒(worktree) │
│ - 记忆/搜索 │
│ - 上下文管理(自动压缩) │
│ - 长程执行(TaskCreate 规划) │
│ │
└───────────────────────────────────────┘
│
▼
┌──────────────────── Sensors(反馈,行动后)────────────────────┐
│ │
│ • ./gradlew assembleDebug 编译通过吗? │
│ • ./gradlew lint 代码风格符合? │
│ • ./gradlew :module:test 新写的测试是否通过? │
│ • ArchUnit 模块边界没被打破? │
│ • code-reviewer Sub-Agent 有没有过度工程? │
│ • Plan 模式 / 人类审批 高风险变更是否经过人类点头? │
│ │
└────────────────────────────────────────────────────────────────┘
│
▼
commit + 进入下一轮注意这里的关键点:
- Agent 不是"被信任的"------它每写一段代码,都会被一组 Sensor 检查。
- Sensor 是闭环的 ------
./gradlew test不通过,Agent 会自己读到错误、自己改、再跑一次,直到通过。 - 人类不在中间循环里 ------但人类定义了这条流水线该跑成什么样(哪些 Guides、哪些 Sensors、什么时候要审批)。
这就是"Human Steer, Agent Execute"在工程上的样子。
核心总结:Prompt / Context / Harness
很简单,三个层级对应三个不同的场景:
当你的 Agent 只跑 5 分钟、写一个函数 → Prompt 工程就够用了。一句话说清楚,模型理解,完成。
当你的 Agent 要跑 50 分钟、读 30 个文件 → 你需要 Context 工程。信息量大了,需要精心管理上下文,确保信息既完整又不混乱。
当你的 Agent 要在生产环境里自主改你公司的代码库 → 你需要 Harness 工程。不能出错、不能走偏、不能让人看不见。需要整套系统的设计。
用一张表把三者的关系锁死:
| 层 | 你工程的对象 | 你在防什么风险 |
|---|---|---|
| Prompt | 单条指令 | 表达不清,模型猜错意图 |
| Context | 上下文窗口 | 信息缺失或上下文腐烂 |
| Harness | 整个运行系统 | Agent 跑偏、跑飞、没人察觉 |
最后一个结论,也是最重要的:
更好的模型解决了"上限问题"------让 Agent 有潜力做成事。
更好的 Harness 解决了"是否能上生产"的问题------让 Agent 真的做成事。
第四部分:下一跃迁------从 Harness 到 Ecosystem
演进的尽头并不在 Harness
回头看这条已经走过的演进线,每一次跃迁都不是因为"模型不够聪明",而是因为上一层撞到了一堵自己解决不了的墙:
| 阶段 | 那时大家以为足够了 | 撞到的墙 | 触发下一跃迁 |
|---|---|---|---|
| Prompt | 只要把指令写对,模型就能解决一切 | 信息密度有限、知识截止、不能行动 | → Context |
| Context | 只要信息环境够好,模型就能做对事 | 信息再丰富也只是"被喂",单 Agent 单回合、没有行动闭环 | → Harness |
| Harness | 把约束、反馈、循环都搭好,就能上生产 | 每个团队都在重造同一套脚手架;Agent 之间互不联通;信任边界硬编码在项目里 | → ? |
Harness Engineering 解决了"一个团队怎么把 Agent 送进自家生产"------但当每个团队都要自己造一遍 ,当一家公司的 Agent 完全无法给另一家公司用,当每条工具协议都要从零谈一遍------下一次跃迁的需求就开始酝酿了。
下一跃迁的雏形:Ecosystem Engineering(生态工程)
如果 Harness Engineering 关心的是"单个 Agent 系统的运行时",下一跃迁关心的就是"Agent 之间的生态"------一个跨项目、跨组织、可互操作、有标准协议、有信任机制的更大网络。可以用四组对比把这次跃迁的轮廓勾出来:
| 维度 | Harness Engineering | Ecosystem Engineering |
|---|---|---|
| 工程对象 | 单项目内的 Agent 运行时 | 跨项目、跨组织的 Agent 生态 |
| 协作范围 | 一个团队里 N 个 Sub-Agent | 跨团队 / 跨公司的 Agent 互操作 |
| 安全模型 | 项目内中心化护栏 | 去中心化的信任机制(能力声明、可验证审计) |
| 编排方式 | 人工设计的编排流水线 | 自组织的 Agent 网络------Agent 自己找 Agent |
| 类比 | 一座剧院(导演调度全班人马) | 一座城市(剧院、街区、交通规则、市民) |
一个有用的参照系:Docker 之于应用部署,相当于 Harness 之于 Agent 创建。 Docker 没让你的应用变聪明,但它让世界上任何 应用都能被相同的方式打包、分发、运行------并由此催生了 Kubernetes 这个跨集群编排层。Ecosystem Engineering 大概率会走同样的路:当"造一个 Agent"被标准化之后,下一个问题必然是"几百万个 Agent 之间怎么协作"。
三个正在发生的信号
这不是纯粹的未来主义------三条线已经在 2026 年发生:
信号一:Agent 的商品化与市场化。 MCP 公开服务器注册表从 1,200 涨到 9,400+;各家平台开始出现 "Agent Store"------内部 Agent 像应用商店里的 App 一样可被检索、被订阅、被组合。当 Agent 变成可买可卖的商品,Agent 之间的协议就比"单个 Agent 多聪明"更重要。
信号二:自适应 Harness(Harness 自我进化)。 Anthropic 的 Skills 系统是一个早期样板:Agent 在使用过程中会学习并保留 项目特定的 how-to,下一次自动加载更合适的子集;类似地,自演化的 system prompt (Agent 会写回它自己的 prompt)已经在多个开源项目里出现。Harness 不再是"工程师一次性配置好",而是Harness 自己学会怎么变得更适合这个团队。
信号三:人--AI 协作范式正在被重画。 工程师的工作正在从"写代码 → AI 审 → 改 → 再审",迁移到"定义目标 → Harness 自动执行 → 人在关键节点点头 → 交付 "。人不是被替代了,是角色被上移了------从"执行层"上移到"架构师 + 监工"。
演进的全景:四次跃迁与一个隐喻
把整条演进线放进一个隐喻里,可能比任何技术清单都更说明问题------剧院的演变:
| 阶段 | 工程角色 | 隐喻 |
|---|---|---|
| Prompt Engineering | 编剧(Screenwriter) | 写好这一幕台词 |
| Context Engineering | 舞美设计师(Stage Designer) | 给演员一个对的舞台 |
| Harness Engineering | 剧院建筑师(Theater Architect) | 建一座能持续演出的剧院 |
| Ecosystem Engineering | 城市规划师(City Planner) | 让所有剧院、街区、市民流转起来 |
每一次跃迁,工程的单位 都在变大:一句话 → 一个窗口 → 一个运行时 → 一整个城市 。每一次跃迁,工程师距离"敲代码"都越来越远------但对最终系统的影响力却越来越大。
全文一句话总结
把四个部分压成一句话:
从 Prompt 到 Context 到 Harness 再到 Ecosystem------每一次跃迁,都不是为了让模型变得更聪明,而是为了让"聪明"在更大的系统里、更长的时间尺度上、被更多人放心地共同使用。