一、模块概述
工具类模块是整个项目的基础设施层,为上层模块(数据库、会话、在线管理、房间、匹配、服务器)提供通用的底层能力。本模块包含两个头文件:
| 文件 | 功能说明 |
|---|---|
logger.hpp |
日志宏模块 --- 提供分级日志输出(INFO/DEBUG/ERROR) |
util.hpp |
工具类集合 --- MySQL操作、JSON处理、字符串分割、文件读取 |
模块依赖关系:
logger.hpp(最底层,无外部依赖)
↓
util.hpp(依赖 logger.hpp,同时引入 MySQL、JsonCpp、WebSocket++ 等第三方库)
↓
db.hpp / session.hpp / online.hpp(上层业务模块依赖 util.hpp)二、日志宏模块 --- logger.hpp
日志模块是项目中最底层的模块,没有任何外部依赖 ,仅使用 C 标准库的
stdio.h和time.h。它通过预处理器宏实现,在编译时展开,零运行时开销。
2.1 为什么使用宏而不是函数?
- 零开销 :宏在编译期展开,没有函数调用的压栈/跳转开销
- 获取源码位置 :宏可以直接使用
__FILE__和__LINE__预定义宏,自动记录日志的文件名和行号;而函数无法获取调用者的源码位置 - 可变参数 :使用
__VA_ARGS__实现类似printf的格式化输出
2.2 完整源码
cpp
//日志宏实现模块
//防止头文件被重复包含
#ifndef __M_LOGGER_H__
#define __M_LOGGER_H__
//引入需要头文件
#include <stdio.h>
#include <time.h>
//日志等级 普通 调试 错误
#define INF 0
#define DBG 1
#define ERR 2
// 默认打印 INF 及以上等级
#define DEFAULT_LOG_LEVEL INF
// 辅助宏:数字等级 → 字符串 INF/DBG/ERR
#define LEVEL_STRING(level) (level == INF ? "INF" : level == DBG ? "DBG" : "ERR")
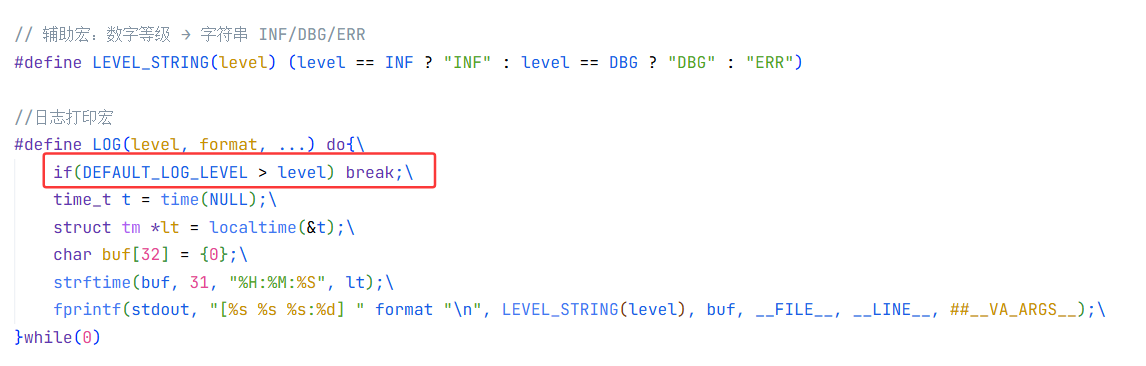
//日志打印宏
#define LOG(level, format, ...) do{\
if(DEFAULT_LOG_LEVEL > level) break;\
time_t t = time(NULL);\
struct tm *lt = localtime(&t);\
char buf[32] = {0};\
strftime(buf, 31, "%H:%M:%S", lt);\
fprintf(stdout, "[%s %s %s:%d] " format "\n", LEVEL_STRING(level), buf, __FILE__, __LINE__, ##__VA_ARGS__);\
}while(0)
#define ILOG(format, ...) LOG(INF, format, ##__VA_ARGS__)
#define DLOG(format, ...) LOG(DBG, format, ##__VA_ARGS__)
#define ELOG(format, ...) LOG(ERR, format, ##__VA_ARGS__)
#endif2.3 逐段解析
2.3.1 头文件保护
cpp
#ifndef __M_LOGGER_H__
#define __M_LOGGER_H__
// ... 头文件内容
#endif使用 #ifndef / #define / #endif 防止头文件被重复包含。这是 C/C++ 中最经典的头文件保护方式,确保即便多个源文件间接包含了 logger.hpp,其中的定义也只会被编译一次。
2.3.2 日志等级定义
cpp
#define INF 0 // 普通信息
#define DBG 1 // 调试信息
#define ERR 2 // 错误信息
#define DEFAULT_LOG_LEVEL INF // 默认只打印 INF 及以上等级定义三个日志等级,数值越大越严重。DEFAULT_LOG_LEVEL 我设为 INF(0)
实际控制逻辑在
LOG宏中:if(DEFAULT_LOG_LEVEL > level) break;。当DEFAULT_LOG_LEVEL为INF(0)时,DBG(1)的日志因为0 > 1为false不会 break,所以DBG 也会被打印。即打印打印 INF 及以上等级。但这取决于
DEFAULT_LOG_LEVEL的设置:如果想屏蔽调试日志,将DEFAULT_LOG_LEVEL设为INF(0);如果想只看错误日志,设为ERR(2)。当前默认配置下INF和DBG和ERR都会打印。
2.3.3 LEVEL_STRING 辅助宏
cpp
#define LEVEL_STRING(level) (level == INF ? "INF" : level == DBG ? "DBG" : "ERR")将数字等级转换为字符串标识,用于日志输出时显示可读的等级名称。使用嵌套的三目运算符实现简洁的条件判断。
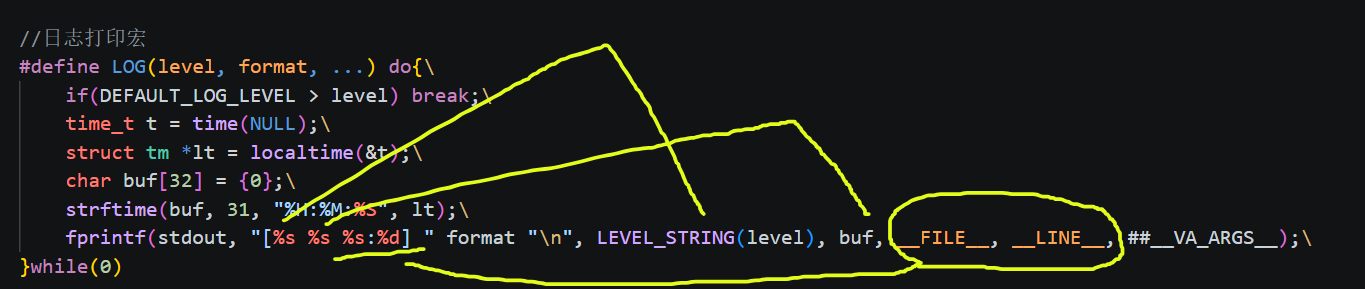
2.3.4 LOG 核心宏
cpp
#define LOG(level, format, ...) do{\
if(DEFAULT_LOG_LEVEL > level) break;\
time_t t = time(NULL);\
struct tm *lt = localtime(&t);\
char buf[32] = {0};\
strftime(buf, 31, "%H:%M:%S", lt);\
fprintf(stdout, "[%s %s %s:%d] " format "\n", LEVEL_STRING(level), buf, __FILE__, __LINE__, ##__VA_ARGS__);\
}while(0)逐行解析:
-
do{...}while(0):将宏体包裹在do-while(0)中,使其在if-else等上下文中使用时行为与普通语句一致,避免分号相关的问题。 -
if(DEFAULT_LOG_LEVEL > level) break;:等级过滤。如果当前日志等级低于设定的默认等级则跳过。break在do-while(0)中等价于跳过后续代码。 -
时间获取:
time(NULL)--- 获取当前时间戳(秒级)localtime(&t)--- 将时间戳转为本地时间的tm结构体strftime(buf, 31, "%H:%M:%S", lt)--- 格式化为时:分:秒的字符串,然后把字符串存放在buf中- (开辟的buf为32,这里允许最大写入字符为31,因为留了一个给'\0')
因为是宏定义,所有的内容必须在同一行,所以为了我在每一句最后都加上了
\。
-
格式化输出:
fprintf(stdout, "[%s %s %s:%d] " format "\n", ...)输出格式为:
[等级 时间 文件名:行号] 用户消息%s--- 等级字符串(INF/DBG/ERR)%s--- 时间字符串(HH:MM:SS)%s:%d--- 源文件名:行号(__FILE__和__LINE__)format--- 用户传入的格式字符串##__VA_ARGS__--- 可变参数,##的作用是当没有额外参数时自动去掉前面的逗号
2.3.5 便捷宏
cpp
#define ILOG(format, ...) LOG(INF, format, ##__VA_ARGS__) // 信息日志
#define DLOG(format, ...) LOG(DBG, format, ##__VA_ARGS__) // 调试日志
#define ELOG(format, ...) LOG(ERR, format, ##__VA_ARGS__) // 错误日志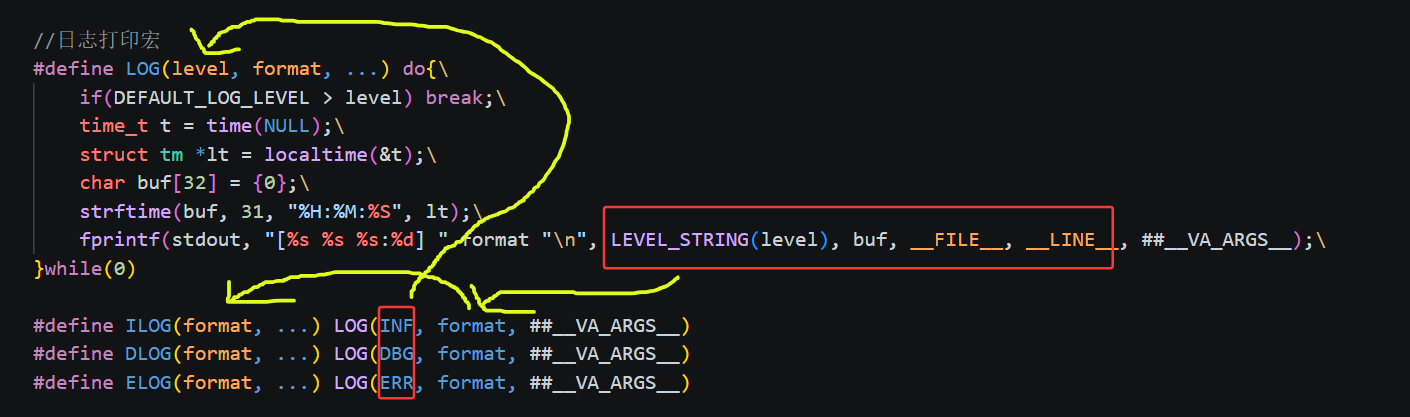
为三个等级各提供一个便捷宏,使用时无需手写等级参数:
cpp
ILOG("用户登录成功, id=%d", uid); // [INF 14:30:25 server.hpp:42] 用户登录成功, id=1001
ELOG("mysql init failed"); // [ERR 14:30:26 util.hpp:43] mysql init failed2.4 日志输出示例
运行服务器后,终端输出效果如下:
[INF 20:15:03 server.hpp:120] 服务器启动成功,端口: 8888
[INF 20:15:10 server.hpp:85] 用户注册成功: player1
[ERR 20:15:12 util.hpp:43] mysql init failed
[INF 20:15:15 matcher.hpp:60] 匹配成功: player1 vs player2三、工具类集合 --- util.hpp
util.hpp 是项目的核心工具文件,封装了四个工具类和一个关键类型定义,为上层模块提供数据库操作、JSON 处理、字符串分割和文件读取能力。
3.1 文件头与依赖引入
cpp
//工具类实现模块
//头文件保护
#ifndef __M_UTIL_H__
#define __M_UTIL_H__
//必要头文件
#include "logger.hpp"
#include <iostream>
#include <mysql/mysql.h>
#include <string>
#include <sstream>
#include <fstream>
#include <memory>
#include <vector>
#include <jsoncpp/json/json.h>
#include <websocketpp/server.hpp> //引入 WebSocket 服务器的核心功能
#include <websocketpp/config/asio_no_tls.hpp> //引入【非加密、异步】WebSocket 配置
typedef websocketpp::server<websocketpp::config::asio> wsserver_t;依赖说明
| 头文件 | 来源 | 用途 |
|---|---|---|
"logger.hpp" |
项目内 | 日志输出(ELOG/ILOG) |
<mysql/mysql.h> |
MySQL C API | MySQL 数据库连接与操作 |
<jsoncpp/json/json.h> |
JsonCpp | JSON 序列化与反序列化 |
<websocketpp/server.hpp> |
WebSocket++ | WebSocket 服务器核心功能 |
<websocketpp/config/asio_no_tls.hpp> |
WebSocket++ | 非加密异步 IO 配置 |
<fstream> |
C++ STL | 文件输入流(文件读取) |
<sstream> |
C++ STL | 字符串流(JSON 序列化输出) |
<memory> |
C++ STL | 智能指针 unique_ptr |
<vector> |
C++ STL | 动态数组(字符串分割结果存储) |
wsserver_t 类型定义
cpp
typedef websocketpp::server<websocketpp::config::asio> wsserver_t;这是整个项目最关键的类型定义之一。
- 它将 WebSocket++ 的服务器模板实例化简化为
wsserver_t,后续所有模块(server.hpp、room.hpp、online.hpp、session.hpp)都使用这个类型来引用 WebSocket 服务器。选择asio_no_tls配置意味着使用异步非加密连接,适合开发测试环境。
3.2 MySQL 工具类 --- mysql_util
mysql_util 封装了 MySQL C API 的三个核心操作:创建连接 、执行语句 、关闭连接。所有方法均为静态方法,无需实例化即可使用。
3.2.1 类结构总览
cpp
class mysql_util{
public:
static MYSQL *mysql_create(
const std::string &host,
const std::string &username,
const std::string &password,
const std::string &dbname,
uint16_t port = 3306);
static bool mysql_exec(MYSQL *mysql, const std::string &sql);
static void mysql_destroy(MYSQL* mysql);
};3.2.2 创建并初始化连接 --- mysql_create
cpp
static MYSQL *mysql_create(
const std::string &host, //主机地址
const std::string &username, //用户名
const std::string &password, //用户密码
const std::string &dbname, //需要连接的数据库名
uint16_t port = 3306 /*默认端口*/)
{
//1. 初始化句柄
MYSQL *mysql = mysql_init(NULL);
if(mysql == NULL)
{
ELOG("mysql init failed");
return NULL;
}
//2. 连接服务器 MYSQL *mysql_real_connect(mysql, host, user, pass, dbname, port, unix_socket, flag);
if(mysql_real_connect(mysql, host.c_str(), username.c_str(), password.c_str(), dbname.c_str(), port, NULL, 0) == NULL)
{
ELOG("connect mysql server failed:%s", mysql_error(mysql));
mysql_close(mysql);
return NULL;
}
//3. 设置客户端字符集
if(mysql_set_character_set(mysql, "utf8") != 0)
{
ELOG("set client character failed:%s", mysql_error(mysql));
mysql_close(mysql);
return NULL;
}
return mysql;
}分步解析:
第一步 --- 初始化 MySQL 句柄:
cpp
MYSQL *mysql = mysql_init(NULL);mysql_init(NULL)分配并初始化一个MYSQL结构体,返回其指针- 传入
NULL表示让 MySQL 库自行分配内存 - 如果内存不足,返回
NULL,此时打印错误日志并返回
第二步 --- 连接 MySQL 服务器:
cpp
mysql_real_connect(mysql, host.c_str(), username.c_str(), password.c_str(), dbname.c_str(), port, NULL, 0)mysql_real_connect 的参数说明:
| 参数 | 传入值 | 说明 |
|---|---|---|
mysql |
初始化后的句柄 | 连接句柄 |
host |
服务器地址 | 如 "127.0.0.1" |
user |
用户名 | 如 "root" |
passwd |
密码 | 明文密码字符串 |
db |
数据库名 | 如 "gobang |
port |
端口号 | 默认 3306 |
unix_socket |
NULL |
不使用 Unix 套接字 |
client_flag |
0 |
无特殊标志位 |
- 连接失败时返回
NULL,通过mysql_error(mysql)获取具体错误信息 - 失败时需要调用
mysql_close(mysql)释放第一步中分配的句柄,避免内存泄漏
第三步 --- 设置客户端字符集:
cpp
mysql_set_character_set(mysql, "utf8")- 将客户端连接的字符集设置为
utf8,确保中文用户名、聊天消息等能正确存取 - 返回
0表示成功,非0表示失败 - 失败同样需要
mysql_close释放资源
返回值: 成功返回有效的 MYSQL* 句柄指针,失败返回 NULL。
3.2.3 执行 SQL 语句 --- mysql_exec
cpp
static bool mysql_exec(MYSQL *mysql, const std::string &sql)
{
int ret = mysql_query(mysql, sql.c_str());
if(ret != 0)
{
ELOG("%s", sql.c_str());
ELOG("mysql query failed:%s",mysql_error(mysql));
return false;
}
return true;
}解析:
mysql_query(mysql, sql.c_str())执行一条 SQL 语句- 参数
sql使用const std::string &引用传递,避免拷贝 - 调用
sql.c_str()转换为 C 风格字符串传给 MySQL C API - 返回
0表示执行成功,非0表示失败
- 参数
- 执行失败时,先打印出问题的 SQL 语句(方便排查),再打印 MySQL 返回的错误信息
- 返回
true/false表示执行结果
使用场景(上层模块 db.hpp 中的实际调用):
cpp
// 用户注册
char sql[4096] = {0};
sprintf(sql, "insert into user values(null, '%s', '%s', 1000, 0, 0)",
username.c_str(), password.c_str());
return mysql_util::mysql_exec(_mysql, sql);
// 用户登录验证
sprintf(sql, "select id, username, score, total_count, win_count from user where username='%s' and password='%s'",
username.c_str(), password.c_str());3.2.4 销毁关闭连接 --- mysql_destroy
cpp
static void mysql_destroy(MYSQL* mysql)
{
if(mysql != NULL)
{
mysql_close(mysql);
}
return;
}解析:
- 先检查指针非空,再调用
mysql_close释放连接 - 空指针保护防止对
NULL调用mysql_close导致未定义行为 - 在项目析构函数中使用:
cpp
// db.hpp 中的使用
~user_table() {
mysql_util::mysql_destroy(_mysql);
}3.3 JSON 工具类 --- json_util
json_util 封装了 JsonCpp 库的序列化与反序列化操作,项目中所有的客户端-服务端通信数据都通过 JSON 格式传输,因此这个类被大量使用。
3.3.1 类结构总览
cpp
class json_util{
public:
static bool serialize(const Json::Value &root, std::string &str);
static bool unserialize(const std::string &str, Json::Value &root);
};3.3.2 序列化 --- serialize(JSON对象 → 字符串)
cpp
static bool serialize(const Json::Value &root, std::string &str) //把一个 JSON 数据(root) → 变成一段字符串(放到str里)
{
//实例化一个StreamWriteBuilder工厂类对象
Json::StreamWriterBuilder swb;
swb["emitUTF8"] = true;
//通过StreamWriterBuilder工厂类对象生产一个StreamWriter对象,使用智能指针(工厂生成写入器)
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());
/*步骤1:工厂创建写入器,返回原始指针
Json::StreamWriter* raw_ptr = swb.newStreamWriter();
步骤2:用原始指针构造智能指针
std::unique_ptr<Json::StreamWriter> sw(raw_ptr);
等价于
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter()); */
std::stringstream ss; //用写入器将 JSON 对象 写入流 stringstream
int ret = sw->write(root, &ss);
if(ret != 0)
{
ELOG("Json serialize failed!");
return false;
}
str = ss.str(); //从 stringstream 对象 ss 中提取出内部的字符串,并赋值给 str。
return true;
}分步解析:
第一步 --- 创建工厂对象并配置:
cpp
Json::StreamWriterBuilder swb;
swb["emitUTF8"] = true;StreamWriterBuilder是 JsonCpp 提供的工厂模式类,用于创建 JSON 写入器swb["emitUTF8"] = true是关键配置:让写入器直接输出 UTF-8 编码,不做转义。如果不设置,中文字符会被转义为\uXXXX格式,导致中文用户名等无法正确显示
第二步 --- 工厂生产写入器(智能指针管理):
cpp
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());这里使用了两步合一的写法,等价于:
cpp
// 步骤1:工厂创建写入器,返回原始指针
Json::StreamWriter* raw_ptr = swb.newStreamWriter();
// 步骤2:用原始指针构造智能指针
std::unique_ptr<Json::StreamWriter> sw(raw_ptr);newStreamWriter()返回一个通过new分配的StreamWriter原始指针- 用
std::unique_ptr包装后,当sw离开作用域时会自动delete,防止内存泄漏 - 这是 C++11 RAII(资源获取即初始化)思想的典型应用
第三步 --- 将 JSON 写入字符串流:
cpp
std::stringstream ss;
int ret = sw->write(root, &ss);std::stringstream是 C++ 的字符串流,可以像操作流一样操作字符串sw->write(root, &ss)将Json::Value对象root序列化后写入流ss- 返回
0表示成功
第四步 --- 提取结果字符串:
cpp
str = ss.str();
return true;ss.str()从字符串流中提取出完整的字符串内容- 赋值给输出参数
str,返回true表示成功
使用示例(server.hpp 中的实际调用):
cpp
Json::Value resp;
resp["result"] = true;
resp["reason"] = "注册成功";
std::string body;
json_util::serialize(resp, body);
// body 此时的内容: {"result":true,"reason":"注册成功"}3.3.3 反序列化 --- unserialize(字符串 → JSON对象)
cpp
static bool unserialize(const std::string &str, Json::Value &root)
{
//实例化一个CharReadBuilder工厂类对象
Json::CharReaderBuilder crb;
//使用CharReadBuilder工厂类生产一个CharReader对象
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());
//定义一个Json::Value对象储存解析后的数据
std::string err;
bool ret = cr->parse(str.c_str(), str.c_str() + str.size(), &root, &err);
if (ret == false)
{
ELOG("json unserialize failed: %s", err.c_str());
return false;
}
return true;
}分步解析:
第一步 --- 创建工厂并生产读取器:
cpp
Json::CharReaderBuilder crb;
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());- 与序列化类似,使用工厂模式 创建
CharReader对象 - 同样用
unique_ptr管理内存,自动释放
第二步 --- 解析 JSON 字符串:
cpp
std::string err;
bool ret = cr->parse(str.c_str(), str.c_str() + str.size(), &root, &err);parse 的四个参数:
| 参数 | 说明 |
|---|---|
str.c_str() |
JSON 字符串的起始地址 |
str.c_str() + str.size() |
JSON 字符串的结束地址(起始 + 长度 = 末尾后一位) |
&root |
输出参数,解析后的 JSON 数据存入此对象 |
&err |
输出参数,解析失败时的错误信息 |
- 使用
[begin, end)左闭右开区间指定要解析的字符串范围 str.c_str()返回字符串首地址,str.c_str() + str.size()返回末尾地址- 解析成功返回
true,失败返回false并在err中写入错误描述
使用示例(server.hpp 中的实际调用):
cpp
// 从 HTTP 请求体中解析注册信息
std::string body = "{\"username\":\"player1\",\"password\":\"123456\"}";
Json::Value root;
json_util::unserialize(body, root);
std::string username = root["username"].asString(); // "player1"
std::string password = root["password"].asString(); // "123456"3.4 字符串分割工具类 --- string_util
string_util 提供了一个通用的字符串分割方法,主要用于 HTTP 请求中 Cookie 字段的解析。
3.4.1 完整源码
cpp
class string_util{
public:
static int split(const std::string &src, //字符串
const std::string &sep, //分隔符
std::vector<std::string> &res) //结果
{
size_t pos, idx = 0; //pos查找到分隔符位置,idx查找起始位置
while(idx < src.size())
{
pos = src.find(sep,idx); //find(要找的内容,从哪里找)
if(pos == std::string::npos)
{
//没找到,把从 idx 到字符串末尾的所有内容,直接放进结果
res.push_back(src.substr(idx));
break;
}
if(pos == idx)
{
//分隔符和当前位置重合
idx += sep.size();
continue;
}
//正常分割
res.push_back(src.substr(idx, pos - idx));
idx = pos + sep.size();
}
return res.size();
}
};3.4.2 逐行解析
函数签名:
cpp
static int split(const std::string &src, const std::string &sep, std::vector<std::string> &res)| 参数 | 类型 | 说明 |
|---|---|---|
src |
const std::string & |
待分割的源字符串 |
sep |
const std::string & |
分隔符 |
res |
std::vector<std::string> & |
输出参数,分割结果 |
| 返回值 | int |
分割后的子串数量 |
核心逻辑:
使用 idx 记录当前查找的起始位置,循环查找分隔符 sep:
-
找不到分隔符(
pos == npos):说明剩余部分是一个完整的子串,直接加入结果,退出循环 -
分隔符和当前位置重合(
pos == idx) :说明出现了连续的分隔符(如"a,,b"中的两个逗号),跳过空串,将idx后移 -
正常情况 :提取从
idx到pos之间的子串加入结果,然后更新idx到分隔符之后
3.4.3 执行流程图解
以分割 HTTP Cookie 为例:
输入: src = "SSID=ABC123; username=player1", sep = "; "
步骤1: idx=0, find("; ", 0) → pos=10
找到分隔符,正常分割 → res.push_back("SSID=ABC123")
idx = 10 + 2 = 12
步骤2: idx=12, find("; ", 12) → pos=npos
没找到,剩余部分直接加入 → res.push_back("username=player1")
break
结果: res = ["SSID=ABC123", "username=player1"]
返回: 2连续分隔符的处理:
输入: src = "a;;b", sep = ";"
步骤1: idx=0, find(";", 0) → pos=1
正常分割 → res.push_back("a")
idx = 1 + 1 = 2
步骤2: idx=2, find(";", 2) → pos=2
pos == idx,跳过 → idx = 2 + 1 = 3
步骤3: idx=3, find(";", 3) → pos=npos
没找到 → res.push_back("b")
结果: res = ["a", "b"](跳过了空串)3.4.4 实际使用场景
在 server.hpp 中解析 HTTP 请求的 Cookie 头:
cpp
// Cookie: SSID=abc123; other=value
std::string cookie_header = req->get_header("Cookie");
std::vector<std::string> cookie_arr;
string_util::split(cookie_header, "; ", cookie_arr);
// cookie_arr = ["SSID=abc123", "other=value"]
for (auto &s : cookie_arr) {
std::vector<std::string> kv;
string_util::split(s, "=", kv);
// kv[0] = "SSID", kv[1] = "abc123"
}3.5 文件读取工具类 --- file_util
file_util 封装了一次性读取整个文件内容到字符串的操作,主要用于 HTTP 静态文件服务(读取 HTML、CSS、JS、图片等文件返回给浏览器)。
3.5.1 完整源码
cpp
class file_util{
public:
static bool read(const std::string &filename, std::string &body) //读取文件到body中
{
//打开文件
std::ifstream ifs(filename, std::ios::binary); //以二进制的方式打开文件
if(ifs.is_open() == false)
{
ELOG("%s file open failed!", filename.c_str());
return false;
}
//获取文件大小
size_t fsize = 0;
ifs.seekg(0, std::ios::end); //文件指针移动到末尾
fsize = ifs.tellg(); //获取当前指针的位置,因为已经在末尾,所以读取的整个文件大小
ifs.seekg(0, std::ios::beg); //把文件指针移回开头,准备读取
body.resize(fsize); //分配空间
//将文件所有数据读取出来;
// 且C++11 及以后版本中,std::string 的内部数据是连续存储的,
// 并且 &body[0] 可以获取指向内部字符数组的指针。
ifs.read(&body[0], fsize); //read(目标地址, 读取字节数)
if(ifs.good() == false)
{
ELOG("read %s file content failed!", filename.c_str());
ifs.close();
return false;
}
//关闭文件
return true;
}
};3.5.2 逐行解析
第一步 --- 以二进制方式打开文件:
cpp
std::ifstream ifs(filename, std::ios::binary);- 使用
std::ios::binary标志以二进制模式打开文件 - 二进制模式至关重要:如果用文本模式,Windows 系统会自动将
\r\n转换为\n,导致读取的文件大小与实际不符,图片等二进制文件会损坏 ifs.is_open()检查文件是否成功打开
第二步 --- 通过文件指针操作获取文件大小:
cpp
size_t fsize = 0;
ifs.seekg(0, std::ios::end); // 将文件指针移动到末尾
fsize = ifs.tellg(); // 获取当前指针位置(即文件大小)
ifs.seekg(0, std::ios::beg); // 将文件指针移回开头,准备读取
body.resize(fsize); // 预先分配足够的空间这是一个经典的获取文件大小的技巧:
seekg(0, std::ios::end)--- seek get pointer,将读取指针移到文件末尾tellg()--- 返回当前读取指针的位置(相对于文件开头的字节数),此时就是文件总大小seekg(0, std::ios::beg)--- 将读取指针移回文件开头body.resize(fsize)--- 预先为字符串分配足够的内存空间,避免读取过程中反复扩容
第三步 --- 一次性读取全部文件内容:
cpp
ifs.read(&body[0], fsize);ifs.read(目标地址, 读取字节数)从文件流中读取指定字节数的数据到目标地址&body[0]获取std::string内部字符数组的起始地址。C++11 标准保证std::string内部数据连续存储,且&body[0]可以获取到可写的字符数组指针(注意:body.c_str()返回的是const char*,不能用于写入)- 由于已经
resize(fsize),字符串有足够的空间容纳文件内容
第四步 --- 错误检查与返回:
cpp
if(ifs.good() == false)
{
ELOG("read %s file content failed!", filename.c_str());
ifs.close();
return false;
}
return true;ifs.good()检查流的状态是否正常(没有发生错误)- 读取失败时打印错误日志并关闭文件
- 成功时返回
true(文件会在ifs析构时自动关闭)
3.5.3 实际使用场景
在 server.hpp 中处理 HTTP 静态文件请求:
cpp
// 浏览器请求: GET /login.html
std::string body;
file_util::read("wwwroot/login.html", body);
// body 内容就是 login.html 的全部 HTML 代码
// 然后将 body 作为 HTTP 响应体返回给浏览器
// 浏览器请求: GET /css/common.css
file_util::read("wwwroot/css/common.css", body);
// 返回 CSS 文件内容
// 浏览器请求: GET /image/cat.jpg
file_util::read("wwwroot/image/cat.jpg", body);
// 二进制模式保证图片文件不会损坏四、模块协作关系
工具类模块作为基础设施层,被上层所有业务模块使用:
┌──────────────────────────────┐
│ server.hpp │
│ HTTP路由 + WebSocket管理 │
└──────────┬───────────────────┘
│ 使用 json_util 序列化响应
│ 使用 string_util 解析Cookie
│ 使用 file_util 读取静态文件
┌───────────────────┼───────────────────┐
│ │ │
┌──────▼──────┐ ┌───────▼──────┐ ┌────────▼───────┐
│ db.hpp │ │ session.hpp │ │ matcher.hpp │
│ 用户表操作 │ │ 会话管理 │ │ 匹配系统 │
└──────┬──────┘ └───────┬──────┘ └───────┬────────┘
│ │ │
│ mysql_util │ json_util │ json_util
│ json_util │ string_util │
│ │ │
└──────────────────┼───────────────────┘
│
┌─────────▼─────────┐
│ util.hpp │
│ mysql_util │
│ json_util │
│ string_util │
│ file_util │
│ wsserver_t │
└─────────┬─────────┘
│
┌─────────▼─────────┐
│ logger.hpp │
│ ILOG/DLOG/ELOG │
└───────────────────┘各工具类的使用统计
| 工具类 | 使用者 | 具体用途 |
|---|---|---|
mysql_util |
db.hpp |
创建/销毁 MySQL 连接,执行增删改查 SQL |
json_util |
db.hpp, server.hpp, room.hpp, matcher.hpp |
序列化响应数据、反序列化请求体 |
string_util |
server.hpp, session.hpp |
解析 HTTP Cookie 头、分割键值对 |
file_util |
server.hpp |
读取 HTML/CSS/JS/图片等静态文件 |
wsserver_t |
server.hpp, room.hpp, online.hpp, session.hpp |
WebSocket 服务器的类型别名 |
logger.hpp |
所有模块 | 各模块的运行日志与错误日志 |
五、设计总结
5.1 设计特点
-
全部使用静态方法 :四个工具类的所有方法都是
static,无需创建对象即可调用,符合工具类的无状态设计理念 -
统一的错误处理模式 :所有方法失败时都通过
ELOG记录详细错误信息,并返回false/NULL让调用者感知失败 -
资源安全的销毁设计 :
mysql_destroy做了空指针检查;json_util使用unique_ptr自动管理内存;file_util依赖 RAII 自动关闭文件流 -
二进制安全的文件读取 :使用
std::ios::binary模式,确保图片等二进制文件不会被文本模式损坏 -
UTF-8 原生支持 :MySQL 连接设置
utf8字符集,JSON 序列化开启emitUTF8,确保中文数据完整传输
5.2 头文件组织原则
logger.hpp → 无依赖,定义日志宏
util.hpp → 依赖 logger.hpp,定义工具类 + wsserver_t依赖方向始终是单向的:util.hpp → logger.hpp。上层模块只需 #include "util.hpp" 即可同时获得日志和全部工具能力。