第六章:炼丹师的内功------工程化实践
!info
在第五章中,我们深入解析了卷积神经网络的设计哲学:局部感受野、权重共享、池化操作------这些不只是聪明的工程技巧,而是把"图像天生局部相关、平移等变"这个先验知识,精巧地编码进了网络结构本身。到 2014 年前后,AlexNet 打开了大门,VGGNet 加深了道路,ResNet 解决了退化问题------图像识别的架构蓝图,已经相当清晰。
但有一个问题,被快速带过了:知道"用什么架构",和"真正能训练出一个好用的模型",之间有一条看不见的鸿沟。 这条鸿沟,不在算法理论里,而在工程实践里------它由优化器的选择、学习率的调度、权重的初始化方案、归一化策略,以及运行这一切的硬件基础设施共同构成。
!question
同样一份 VGGNet 的代码,顶级实验室能训练出 92% 准确率的模型,而一个独立研究者按论文复现,可能只得到 85%,甚至根本不收敛。这个差距,到底来自哪里?深度学习的"炼丹",炼的究竟是什么?
6.1、那个无法复现的年代
6.1.1 深度学习的"可复现性危机"
2014 年秋天,在某深度学习论坛上,一位欧洲大学的博士生发了一篇帖子,标题大意是:
为什么我无法复现 AlexNet?
他已经按照 AlexNet 原论文的描述,一丝不苟地搭建了相同的架构:5 个卷积层、3 个全连接层、ReLU 激活函数、数据增强、Dropout。他甚至用了同款 NVIDIA GPU,在同样的 ImageNet 数据集上训练了三周。但他的 Top-5 错误率是 24%,而原论文报告的是 15.3%。
将近 9 个百分点的差距。这不是小误差,这几乎是两个时代的差距。
他能找到的原因有:
- 论文中提到 "SGD with momentum=0.9, weight decay=0.0005",但没提供学习率策略的细节
- 论文中提到 "以小的随机值初始化权重",但没说明具体的分布和方差
- 训练的时长、学习率在哪些 epoch 衰减了多少、批大小是多少------这些细节散落在论文的不同位置,或者没有提供太多细节内容
这不是 AlexNet 特有的问题。2014 年,VGGNet 发布后,牛津大学的作者在技术报告里特别提到:训练最深的 VGG-19 时,他们必须先训练较浅的 VGG-11,用 VGG-11 的参数初始化 VGG-16,再用VGG-16 初始化 VGG-19------这种"阶梯式预热"的技巧,并不在论文摘要里,而放置在论文第 4 页的技术细节里。如果没有细读到,训练 VGG-19 可能就会莫名其妙地失败。
整个深度学习社区在 2013---2016 年间,经历了一场安静的"可复现性危机"。
顶级实验室的论文展示了令人炫目的结果,但这些结果依赖于一套从未被完整公开的工程知识。研究者们有一个隐晦的说法:"SOTA(State of the Art)不只是架构,是架构加秘方。" 秘方,就是那些有效但玄妙的工程细节。
6.1.2 "炼丹":一个隐喻的诞生
中国深度学习社区给这个现象起了一个绝妙的名字:炼丹。
道家炼丹术士有一套精密的操作规程:铅汞的配比、炉火的温度、炼制的时辰、器皿的材质------每一个环节都不能错,但支撑这套规程的"理论基础"是含混不清的。经验丰富的炼丹师知道哪些配方在什么条件下有效,但他们很难用现代科学语言解释"为什么"。
深度学习训练在 2014 年前后,就是这种感觉。
有经验的工程师知道:这个任务用 Adam,那个场景用 SGD with momentum;这种深度的网络要学习率预热,那种结构不需要;BatchNorm 应该加在激活函数之前还是之后------研究界吵了好几年;学习率与批大小的关系满足某个经验规则,但这个规则在大批量时会失效。这些知识是真实的、可重复的,但它们更接近匠人的手艺,而不是可以推导的科学。
"炼丹"这个词,捕捉了那个年代深度学习工程化的本质困境:工具是有效的,但原理是不透明的;结果是可重复的,但路径是难以传授的。
6.1.3 为什么"炼丹"是一个严重的问题
你可能会想,为什无法复现是个"严重问题"?
有几个原因让这个问题比看起来更深刻。
它使科学进步变慢。 如果论文 A 的结果依赖未公开的工程技巧,论文 B 在它之上所做的改进,就无法区分"是改进了架构本身"和"是碰巧找到了更好的技巧"。科学进步应该是可积累的,但当每篇论文都有隐藏变量时,积累就变成了混乱。
它制造了技术壁垒。 顶级实验室的博士生可以通过师生传承学到这套"内功",但没有导师的独立研究者、初入行的工程师、资源有限的学校,就只能从头摸索。这不是公平的竞争。
它阻碍了工业落地。 把一个研究代码变成生产系统,往往意味着要重新找到适合自己数据、规模和硬件的工程配置。没有系统性的知识,每次迁移都是重新炼丹。
这一章,我们要做一件事:把"炼丹"祛魅。
我们会系统梳理深度学习工程化的八个核心维度:优化器、学习率、激活函数、归一化、权重初始化、框架、GPU生态、分布式训练入门。每一个维度,我们都要搞清楚:它为什么存在?它解决了什么问题?它的背后逻辑是什么?
理解了这些,"炼丹"就从玄学变成了工程学。
6.2、优化器的进化:从"往山下走"到"智能导航"
6.2.1 梯度下降的基本直觉
训练神经网络,本质上是在寻找一组参数(权重),让模型在训练数据上的预测误差尽可能小。这个"误差"是一个关于参数的函数,叫做损失函数(Loss Function)。我们的任务,是在这个函数的"地形"里,找到一个尽可能低的谷底。
梯度 (Gradient)告诉我们:从当前位置,哪个方向是最陡的上坡。梯度下降(Gradient Descent)就是反过来走------沿最陡下坡的方向,一步一步向最低点靠近。
直觉上,这很简单。但在一个几百万、几千万参数的深度神经网络里,这个"地形"极其复杂:有无数个局部最低点、有看起来是低点但其实只是宽阔平台的"鞍点"(Saddle Point)、有陡峭的峡谷和宽阔的盆地。朴素的梯度下降,在这样的地形里会遭遇各种问题。
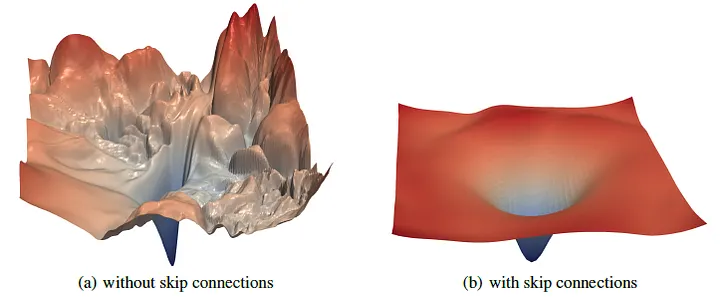
图 6.1:损失景观示意图,(参考 Li et al. 2018 "Visualizing the Loss Landscape of Neural Nets" 的论文图示。)
6.2.2 批量的困境:全批量、纯随机,还是折中?
梯度下降有三个版本,对应"每次用多少数据来计算梯度"的三种策略:
批量梯度下降(Batch Gradient Descent):每次用全部训练数据计算梯度,再更新一次参数。方向最准确,但对于一个有数百万样本的数据集,每更新一步就要过一遍所有数据------代价大得无法接受。
随机梯度下降(Stochastic Gradient Descent, SGD):每次只用一个样本计算梯度,立刻更新。速度极快,但每一步的梯度估计噪声极大------你往往走的方向是"这一个样本说的下坡方向",而全局下坡方向可能完全不同。路径会非常曲折,像醉汉的步伐。
Mini-batch SGD:折中。每次用小批量(通常 32 到 256 个样本)计算梯度,既比纯随机的噪声小,又比全批量快得多。这是现代深度学习的标准训练方式,通常说的"SGD"实际上就是指 这个版本。
Mini-batch SGD 解决了计算效率问题,但自身还有一个深层困难:学习率太敏感。太大:步子太大,在谷底附近来回震荡甚至飞出去。太小:进展极慢,而且容易陷在局部最优出不来。在实践中,"找到一个好的学习率"在 2012 年前后,是一个需要大量经验和运气的任务。
6.2.3 动量:给梯度下降装上"惯性"
1986年,大卫·鲁梅尔哈特(David Rumelhart,1942---2011,神经网络研究先驱,反向传播算法的核心发展者之一)和同事们就已经在使用一种改进------给 SGD 加上"动量"(Momentum)。
动量的直觉很简单:想象一个球在山坡上滚动。一个没有摩擦力的球,不会每次都精确地"沿当前最陡方向走一步",而是会带着之前积累的速度继续往前冲------它的运动方向是当前梯度和历史速度的合力。
带有动量的 SGD 的核心更新规则是:v=β⋅v+(1−β)⋅gradient速度:历史速度 + 当前梯度的加权和parameter=parameter−lr⋅v用速度而不是原始梯度更新参数\begin{align} v&=\beta \cdot v+(1-\beta) \cdot \text{gradient} \qquad &\text{速度:历史速度 + 当前梯度的加权和} \\1.2ex \text{parameter}&=\text{parameter} - \text{lr} \cdot v \qquad &\text{用速度而不是原始梯度更新参数} \end{align}vparameter=β⋅v+(1−β)⋅gradient=parameter−lr⋅v速度:历史速度 + 当前梯度的加权和用速度而不是原始梯度更新参数
参数 βββ(通常取 0.9)控制"惯性有多强"。β=0β=0β=0 退化为普通 SGD;β=0.9β=0.9β=0.9 意味着历史速度贡献90%,当前梯度贡献 10%。
动量的好处很直观:它平滑了梯度噪声 ------单个 mini-batch 的梯度估计可能很嘈杂,但多步动量的累积会把噪声平均掉;它帮助跨越鞍点 ------在平坦的鞍点区域,每一步梯度接近零,但累积的动量能帮助参数"冲过"这片平地;它在一致方向上加速收敛------在梯度方向稳定的区域,动量让参数快速滑行,而不是在两侧震荡。
这是一个好的开始。但动量解决的是梯度方向上的问题,还没有解决"不同参数需要不同学习率"的问题。
6.2.4 AdaGrad:为每个参数量身定制学习率
2011 年,约翰·杜奇 (John Duchi,1985---,斯坦福大学教授,当时是 UC Berkeley 博士生)等人发表了 AdaGrad(Adaptive Gradient Algorithm)。
这个算法的核心洞察是:不同参数应该有不同的学习率。
为什么?想象一个文本模型,需要处理"的"(出现在 99% 的句子里)和"矗立"(出现在 0.01% 的句子里)。对于高频词,梯度信号非常频繁,不需要大步更新;对于低频词,信号稀少,每次看到都应该大步调整。用统一学习率处理这两种情况,必然顾此失彼。
AdaGrad 为每个参数积累其历史梯度的平方和,用这个累积值来缩放当前学习率:Gt+=gradient2累积历史梯度的平方lr_effective=lr/Gt+ϵ历史梯度大 → 当前学习率小parameter−=lr_effective⋅gradient\begin{align} G_{t} &+= \text{gradient}^{2} \qquad &\text{累积历史梯度的平方} \\1.2ex \text{lr\effective} &= \text{lr} / \sqrt{ G{t} + \epsilon } \qquad &\text{历史梯度大 → 当前学习率小} \\1.2ex \text{parameter} &-= \text{lr\_effective} \cdot \text{gradient} \end{align}Gtlr_effectiveparameter+=gradient2=lr/Gt+ϵ −=lr_effective⋅gradient累积历史梯度的平方历史梯度大 → 当前学习率小
高频更新的参数,历史梯度平方累积大,学习率自动缩小;低频更新的参数,学习率保持相对较大。AdaGrad 对稀疏特征(如词嵌入)有很好的效果,但它有一个致命缺陷:学习率单调递减,永不停止 。随着训练进行,所有参数的 GtG_tGt 都在增加,学习率持续缩小,最终趋近于零------模型在还没收敛时就停止了学习。
6.2.5 RMSProp:Hinton 在 PPT 里的临时修补
修复 AdaGrad 的方案,来自一个极其不正式的地方。
2012 年,杰弗里·辛顿 在 Coursera 开了一门在线课程《神经网络的机器学习》。在某一讲的 PPT 幻灯片里,他随手写下了一个 AdaGrad 的改进版本------RMSProp(Root Mean Square Propagation):
Eg2=γ⋅Eg2+(1−γ)⋅gradient2滑动平均代替无限累加lr_effective=lr/Eg2+ϵ\begin{align} Eg\^{2} &= \gamma \cdot Eg\^{2}+ (1- \gamma) \cdot \text{gradient}^{2} \qquad \text{滑动平均代替无限累加} \\1.2ex \text{lr\_effective} &= \text{lr} / \sqrt{ Eg\^{2}+\epsilon} \end{align}Eg2lr_effective=γ⋅Eg2+(1−γ)⋅gradient2滑动平均代替无限累加=lr/Eg2+ϵ
改动只有一处:把"累加所有历史梯度平方"改成"指数滑动平均"------很久以前的梯度信息会被逐渐"遗忘",只保留近期的梯度统计。这样,学习率就不会因为早期大梯度的积累而永久性地衰减到零。
这个算法从未被作为论文正式发表。引用它的论文只能写:Hinton, G.(2012). Lecture 6e of Coursera Neural Networks for Machine Learning course.
这是一个有趣的历史插曲:深度学习最常用的优化算法之一,最初是一位教授在课件里随手写的一个改进想法------没有经过同行评审,没有做充分的实验验证,就这样流传了下来,成为了 Adam 的直接前身。
6.2.6 Adam:动量 + 自适应学习率的结合
2014 年,迪德里克·金玛 (Diederik P. Kingma,1986---,荷兰计算机科学家,当时在阿姆斯特丹大学读博,后加入 OpenAI)和吉米·巴 (Jimmy Ba,多伦多大学博士生)把动量和 RMSProp 的思路系统地结合起来,发表了Adam(Adaptive Moment Estimation)。
Adam 维护两个状态变量:
- mmm(一阶矩,即动量):梯度的指数滑动平均,捕捉梯度的方向趋势
- vvv(二阶矩):梯度平方的指数滑动平均,捕捉梯度的幅度信息
m=β1⋅m+(1−β1)⋅gradient动量更新(β1 通常取 0.9)v=β2⋅v+(1−β2)⋅gradient2二阶矩更新(β2 通常取 0.999)m^=m/(1−β1t)偏差修正(训练初期 m/v 偏小,需要放大)v^=v/(1−β2t)parameter−=lr⋅m^/(v^+ϵ)参数更新(lr 通常取 0.001)\begin{align} m &= \beta_{1} \cdot m + (1-\beta_{1}) \cdot \text{gradient} &\text{动量更新(\\beta_1 通常取 0.9)} \\1.2ex v &= \beta_{2} \cdot v + (1-\beta_{2}) \cdot \text{gradient}^2 &\text{二阶矩更新(\\beta_2 通常取 0.999)} \\1.2ex \hat{m} &= m / (1- \beta_{1}^t) &\text{偏差修正(训练初期 m/v 偏小,需要放大)}\\1.2ex \hat{v} &= v / (1 - \beta_{2}^t) \\1.2ex \text{parameter} &-= \text{lr} \cdot \hat{m} / (\sqrt{ \hat{v} } + \epsilon) &\text{参数更新(lr 通常取 0.001)} \\1.2ex \end{align}mvm^v^parameter=β1⋅m+(1−β1)⋅gradient=β2⋅v+(1−β2)⋅gradient2=m/(1−β1t)=v/(1−β2t)−=lr⋅m^/(v^ +ϵ)动量更新(β1 通常取 0.9)二阶矩更新(β2 通常取 0.999)偏差修正(训练初期 m/v 偏小,需要放大)参数更新(lr 通常取 0.001)
默认参数 β1=0.9,β2=0.999β_1=0.9, β_2=0.999β1=0.9,β2=0.999,在绝大多数任务上,Adam 不需要仔细调学习率也能运转良好。这是它最大的工程价值。一位 2015 年的深度学习工程师形容 Adam 的出现:
"在 Adam 之前,每次开始新项目的第一周都是在调学习率。Adam 发布之后,直接用默认参数跑出来的结果,通常就比我之前花一周调出来的 SGD 好。"
Adam 迅速成为深度学习的标准优化器。但 Adam 并不完美。
2018 年,伊利亚·洛斯齐洛夫 (Ilya Loshchilov)和弗兰克·胡特 (Frank Hutter)指出了一个被忽视的问题:Adam 的权重衰减(Weight Decay,一种防止过拟合的正则化技术)实现是错误的------Adam 用的是 L2 正则化,但 L2 正则化和 Adam 的自适应学习率交互之后,实际效果与真正的"权重衰减"不同。具体来说,自适应学习率会把正则化项也按参数的梯度历史缩放,这破坏了权重衰减本来的含义(直接衰减参数值本身)。
他们提出的 AdamW------修正了这个 bug------在 Transformer 和大语言模型的训练中至关重要。从 BERT 开始,AdamW 成为了 LLM 训练的标准配置,沿用到今天的 GPT-4、LLaMA、DeepSeek 等所有主流大模型。
!important
优化器演化的核心逻辑:每一代优化器都在回答同一个问题------"如何更聪明地利用当前步骤的梯度信息"。动量解决了方向噪声问题,AdaGrad 解决了稀疏参数的学习率问题,RMSProp 修复了单调衰减,Adam 整合了两者优点,AdamW 修复了正则化 bug。这是一条非常清晰的因果进化链。
6.3、学习率的艺术:最敏感的超参数
6.3.1 最重要的超参数
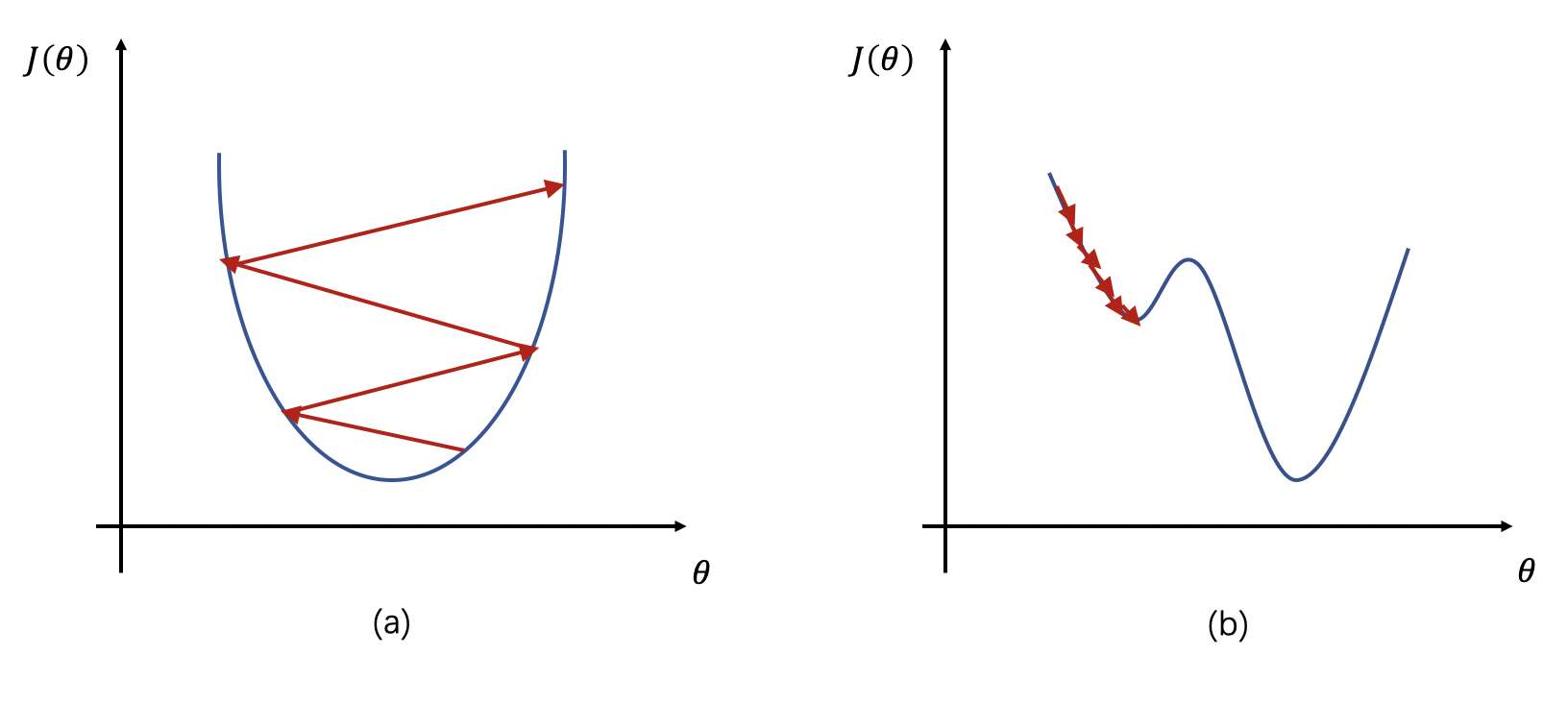
图 6.2:学习率对训练动态的影响,左侧展示学习率太大时损失函数的震荡/发散曲线,右侧展示学习率太小时的极慢收敛曲线。横轴是训练步数,纵轴是损失值。
如果将学习率设置的太大,梯度更新步子太大,会在损失函数的谷底附近来回震荡甚至飞出去------训练不稳定,损失值的曲线会剧烈波动,最终发散。
而如果学习率设置的太小,每步移动极小,收敛极慢;更糟的是,可能卡在一个损失函数的"浅沟"里出不来,这个浅沟不是真正的全局最优点,而只是一个局部最小值的近似。
找到一个"刚好合适"的学习率,在 2013 年之前,真的主要靠经验和运气。通常的做法是"手动二分查找"------先试 0.1,太大就试 0.01,还太大就试 0.001......这是一个繁琐且不可靠的过程。
更深的洞察是:不同训练阶段,最优的学习率是不同的。
训练初期:参数是随机初始化的,距离最优解很远。这时候用大学习率是合理的------步子大,探索范围广,能快速找到大方向。但如果学习率从第一步就很大,初始化引起的梯度方向可能非常不稳定,导致训练崩溃。
训练中期:参数进入了一个"粗略正确"的区域,大学习率能帮助跨越小的局部最优。
训练后期:参数接近最优解,需要用小学习率精细调整,大学习率反而会让参数不断震荡,无法稳定收敛。
这个规律催生了学习率调度(Learning Rate Scheduling)------让学习率随着训练进程动态变化的策略。
6.3.2 学习率预热:冷启动的必要缓冲
学习率预热 (Warm-up)是深度学习工程化里反直觉但极度重要的技术:训练开始时,不要直接用目标学习率,而是从一个极小的值线性增大到目标值,花几百到几千步完成这个过渡。
为什么需要这样做?
当模型刚刚初始化时,参数是随机的,预测输出是混乱的。梯度(损失对参数的导数)在这时候可能极大------因为参数离"合理区域"很远,任何方向的调整都会引起巨大的损失变化。如果此时直接用一个大的学习率,这些巨大的梯度乘以大学习率,会造成极大的参数更新------模型可能在第一个 epoch 就飞出了任何有意义的参数空间。
学习率预热就是一个缓冲带:让模型在最脆弱的初始阶段,用极小的步子走,避免"冷启动震荡"。等到参数进入了一个合理区域,梯度不再那么狂野,再逐步增大学习率,让训练真正提速。
这就像汽车在严冬启动时要先低速暖车------不是发动机不够强,而是在最脆弱的状态下,剧烈的操作反而会造成损坏。
预热策略在 ResNet、BERT、GPT 等几乎所有现代模型的训练中都是标准配置。对于大型语言模型,预热通常持续几千步(占总训练步数的 1---3%),预热结束时学习率才到达目标值。
6.3.3 余弦退火:优雅的衰减
余弦退火(Cosine Annealing)是训练后期学习率衰减的最主流方式之一。
其背后的直觉很简单:学习率按照余弦函数的形状,从目标值平滑地衰减到接近零。
为什么是余弦函数而不是线性衰减?
余弦曲线的特点是:开始衰减时变化缓慢(曲线斜率小),中间阶段变化最快,接近结束时再次放缓(趋近于零时梯度趋于水平)。这个形状在实践中表现出色:训练中期模型仍在探索,不希望学习率下降太快;训练后期需要精细收敛,希望学习率非常平滑地趋近零而不是突然跌落。
"预热 + 余弦退火"的组合,在 2018 年后成为几乎所有大型模型训练的标准方案。
6.3.4 莱斯利·史密斯的反直觉发现
2017 年,美国海军研究实验室的莱斯利·史密斯(Leslie N. Smith)发表了一篇技术报告,提出了两个颇具实践价值的工具。
Learning Rate Finder(学习率寻找器):用极短时间(几分钟到十几分钟),从极小学习率到极大学习率做一次扫描,绘制出"学习率---损失变化率"曲线,曲线下降最陡峭的那个区间,就是最优学习率的大致范围。这个技术把"花一周试学习率"压缩成了"花 10 分钟找学习率"。
Cyclical Learning Rates(CLR,周期性学习率) :更令人惊讶------学习率应该在训练过程中周期性地升高和降低,而不是单调下降。
这与当时的主流认知完全相反。人们普遍认为学习率应该是"从大到小、从快到慢"的单调过程。史密斯的实验发现:通过周期性地让学习率"重新升高",模型有机会逃离当前的局部最优,探索损失函数地形的其他区域,最终往往能找到更好的解。
这个发现体现了深度学习工程化一个典型的规律:正确的解决方案,往往不是你直觉上认为"最合理"的那个。
6.4、激活函数:让梯度流动的闸门
6.4.1 Sigmoid 的黑暗时代
在第三章中讨论反向传播时,我们提到了梯度消失(Vanishing Gradient)------深层网络的梯度在反向传播时,会随着层数增加而指数级缩小,最终让靠近输入的层几乎无法学习。
激活函数,是梯度消失问题的一个重要根源。
在 2010 年代之前,深度学习的标准激活函数是 Sigmoid (σ(x)=1/(1+e(−x))σ(x) = 1/(1+e^{(-x)})σ(x)=1/(1+e(−x)))。Sigmoid 的输出范围是 0 到 1,非常直观。但 Sigmoid 有一个灾难性的数学特性:饱和区梯度接近零。
当输入 xxx 很大(比如 x=10x=10x=10)时,σ(10)≈1σ(10) ≈ 1σ(10)≈1,而 σ′(10)≈0σ'(10) ≈ 0σ′(10)≈0。当 xxx 很负时同样如此。当神经元的输入落在"饱和区"时,梯度几乎为零------即使损失函数的值很高,这个神经元也传不回任何有意义的学习信号。
想象你在用对讲机传递消息,从第 20 层传到第 1 层,要经过 19 个中间人。但每个中间人都把消息音量调低了 90%------收到的消息到最后一个中间人那里,已经弱到几乎听不见。
这就是 Sigmoid 的梯度消失问题。这也是为什么在 ReLU 之前,训练真正深层的神经网络(超过 4---5 层)在实践中极度困难。
6.4.2 ReLU:用线性打破饱和
ReLU (Rectified Linear Unit)的定义极其简单:f(x)=max(0,x)f(x)=\max(0,x)f(x)=max(0,x)负数输出为零,正数原样输出。但它有一个对深层网络至关重要的性质:在正数区间,梯度恒为1。
这意味着,只要神经元的输入是正数,梯度就能完整地反向传播,不会因为经过这一层而衰减。Krizhevsky 等人在 AlexNet 论文里报告:相比 Sigmoid,ReLU 让网络训练速度快了6倍。
然而,ReLU 有自己的问题:"神经元死亡"(Dying ReLU)。
当一个神经元的输入长期为负数时,它的输出恒为零,梯度也恒为零------这个神经元永远不会再被更新,它"死了"。在大学习率下,这个问题尤其严重:一次梯度更新可能把某个权重推到很大的负值,导致这个神经元对几乎所有输入都输出零。如果网络里有大量神经元死亡,有效容量就大幅下降。
Leaky ReLU 是对神经元死亡的直接修复:LeakyReLU(x)={x,x>0αx,x≤0(α∈(0,1), 如 α=0.01) \text{LeakyReLU}(x) = \begin{cases} x, & x > 0 \\ \alpha x, & x \le 0 \quad (\alpha \in (0, 1), \text{ 如 } \alpha = 0.01) \end{cases} LeakyReLU(x)={x,αx,x>0x≤0(α∈(0,1), 如 α=0.01)负区间不再是零,而是一个小斜率 ααα。即使输入是负数,梯度也有一个小的非零值------神经元"活着",只是活动很弱。PReLU (Parametric ReLU)进一步把 ααα 变成可学习的参数,被 2015 年微软 ResNet 团队用于超越人类水平的实验。
6.4.3 GELU:Transformer 时代的标配
随着 Transformer 架构的崛起,研究者开始寻找比 ReLU 更平滑、梯度特性更好的激活函数。
2016 年,丹·亨德里克斯 (Dan Hendrycks)和肯尼斯·吉姆佩尔 (Kevin Gimpel)提出了 GELU (Gaussian Error Linear Unit,高斯误差线性单元)------ReLU 的"软化版本":在零点附近,输出不是硬截断(要么 000 要么 xxx),而是一个平滑的过渡曲线。负值区域有小的非零响应,零点附近有曲率,正值区域近似线性。
GELU 在大多数任务上比 ReLU 有轻微但稳定的性能提升,可能与它更平滑的梯度特性有关,使得优化过程更稳定。GPT 和 BERT 都使用 GELU,它成为了 Transformer 时代事实上的标配激活函数。
6.4.4 SwiGLU:门控激活的大模型时代
2020 年,诺姆·沙泽尔 (Noam Shazeer,1978---,Google Brain 研究员,Transformer 原论文作者之一,后创立 Character.AI)在一篇几乎是随手发到 arXiv 的技术报告里提出了 SwiGLU:
SwiGLU(x,W,V)=Swishβ(xW)⊗(xV)\text{SwiGLU}(x, W, V) = \text{Swish}_\beta(xW) \otimes (xV)SwiGLU(x,W,V)=Swishβ(xW)⊗(xV)
SwiGLU 是一种门控线性单元(Gated Linear Unit,GLU):用两个线性变换的输出,一个做激活,一个做"门"来控制激活的流通量。这种门控机制让网络能更灵活地控制信息流动。
Shazeer 在报告里几乎没有理论分析,只是说"经验上更好"------这是深度学习工程化文化的典型体现:先发现有效,再慢慢理解为什么。LLaMA、Mistral、GPT-4(据推测)、DeepSeek 等几乎所有主流 LLM 都采用了 SwiGLU,成为 Transformer 前馈层的标准配置。
激活函数演化的规律:从 Sigmoid 到 SwiGLU,每一代改进都在解决"梯度流动效率"和"表达能力"之间的权衡------梯度要能流通(不饱和),但也要有非线性(否则深层网络退化为线性变换)。这个双重约束,驱动了三十年的激活函数研究。
6.5、归一化:让深层网络站稳的地基
6.5.1 内部协变量转移:BatchNorm 的动机
2014 年末,在 Google Brain 的一个团队里,谢尔盖·伊奥菲(Sergey Ioffe,Google 高级研究科学家)正在尝试训练一个更深版本的 Inception 网络。
问题是:不稳定。
深层网络训练时有一个持续存在的困扰。哪怕只是微调了某一层的权重,这一层之后所有层的输入分布都会随之改变------因为深层网络是级联系统,第 3 层的输出是第 4 层的输入,第 4 层的输出是第 5 层的输入。当第 3 层的参数更新后,第 4、5、6 层......所有后续层都需要"适应"这个新的输入分布,然后再传递到更后面的层。这个连锁反应使训练极不稳定。
伊奥菲把这个现象命名为 "内部协变量转移"(Internal Covariate Shift,ICS):深层网络训练过程中,每一层的输入分布随着前层参数的更新而持续变化,使每一层都必须不断"追赶"一个移动的目标。
他的解决方案,是 2015 年发表在 ICML 上的批归一化(Batch Normalization,BatchNorm)。
思路很直接:在每一层的输入上,强制施加一个标准化操作 ------计算这个 mini-batch 里所有样本在这一层的激活值的均值和方差,然后把激活值"拉回"均值为 0、方差为 1 的标准分布,再用可学习的参数 γγγ 和 βββ 做缩放和平移:
μ_B = mean(x_i for i in batch)
σ²_B = variance(x_i for i in batch)
x̂_i = (x_i - μ_B) / sqrt(σ²_B + ε) # 标准化
y_i = γ * x̂_i + β # 可学习的缩放和偏移(恢复表达能力)BatchNorm 的效果惊人。伊奥菲和 Hinton 在论文里报告:加了 BatchNorm 之后,同样的 Inception 网络在 ImageNet 上,训练速度快了 14 倍,并且超越了当时最好的模型。
BatchNorm 的好处是多重的:训练稳定性大幅提升 (输入分布被固定,后续层不需要不断适应);学习率可以提高 10 倍 (大梯度不再导致爆炸);对初始化不再那么敏感 (BatchNorm 会把激活值拉回合理范围);有轻微的正则化效果(batch 统计量引入了噪声,类似 Dropout)。
BatchNorm 成为了 2015---2018 年深度学习最重要的工程突破之一。ResNet、DenseNet、MobileNet 等几乎所有图像识别网络,都把 BatchNorm 作为标准组件。
6.5.2 BatchNorm 的局限:批大小的诅咒
但 BatchNorm 有一个局限性:它依赖 batch 维度的统计量。当批大小足够大(128、256)时,一切运转良好。但当批大小很小时(4 或 8),均值和方差的估计非常不稳定------batch 里的样本太少,统计量噪声很大,归一化反而制造了不稳定。
更严重的问题出现在两类场景:
序列数据:在处理文本时,每个位置的序列长度不同,不同位置的特征分布可能完全不同,用 batch 统计量归一化是没有意义的。
小批量训练:在目标检测、语义分割等任务中,由于图像分辨率高,单卡只能放下 2---4 张图。BatchNorm 在这里完全失效。
此外,BatchNorm 还存在一个深层次的问题,它所提供的稳定性实际上是以巨大的代价换来的。如果我们仔细思考这里发生的事情,就会发现这里存有某种极其奇怪且不自然的现象。
过去的情况是,我们有一个单独的样本输入到神经网络中,然后计算其激活值,这是一个确定性的过程,因此我们会得到这个样本的某些逻辑值。后来,由于考虑训练效率,我们开始批量处理样本,但这些样本最初是独立并行处理的。但现在,由于 BatchNorm 的引入,我们在神经网络的前向传播和反向传播过程中,会将这些样本在数学上耦合在一起。因此,现在任何一个输入样本的隐藏层激活值和逻辑输出,不仅取决于该样本及其输入,还受到同一批次中所有其他样本的影响。
你可能会认为这是一个错误或不受欢迎的现象,但奇怪的是,这实际上在神经网络训练中被证明是有益的,而且这是一个附加效应。原因在于,我们可以将其视为一种正则化手段。具体来说,输入数据经过处理后得到隐藏层结果,而其他样本的存在会使其产生轻微波动。这种机制实际上是在对每个输入样本进行"填充扩展",同时引入少量熵值。由于这种填充效应,它本质上构成了一种数据增强形式,相当于对输入数据进行小幅扩充和扰动。这使得神经网络更难对这些具体样本产生过拟合。通过引入这些噪声,样本数据得到扩展,从而实现了对神经网络的正则化效果。
这就是为什么它具有二阶效应,这本质上是一种正则化手段,这也使得我们更难摆脱 BatchNorm 的使用。因为基本上没有人喜欢 BatchNorm 的这一特性------在数学计算和前向传播过程中,批次中的样本是相互耦合的。这会导致各种奇怪的结果,还会引发大量错误等等。正因如此,人们一直在尝试弃用 BatchNorm,转而采用其他不会耦合批次样本的归一化技术,例如层归一化、实例归一化、组归一化等等。
简单来说,BatchNorm 是最早被引入的归一化层类型。它的效果非常好,并且恰好具有这种正则化效应。它稳定了训练过程,尽管人们一直试图移除它并转向其他归一化技术,但一直难以实现,因为它效果非常好。而它效果如此出色的部分原因,再次归功于这种正则化效应,以及它在控制激活值和其分布方面的高效性。
这就是 BatchNorm 的简要故事。
6.5.3 LayerNorm:Transformer 的选择
2016 年,吉米·巴 (Jimmy Ba,也是 Adam 论文的合作者)等人发表了 LayerNorm(Layer Normalization,层归一化)。
LayerNorm 的改变只有一点,但很关键:从跨 batch 计算统计量,改为在单个样本的特征维度上计算统计量。这也是解决 BatchNorm 跨样本耦合的最直接的一种思路。
μ = mean(x_j for j in features) # 对单个样本的所有特征求均值
σ² = variance(x_j for j in features)
x̂_j = (x_j - μ) / sqrt(σ² + ε) # 在特征维度上标准化
y_j = γ * x̂_j + β这样,归一化不再依赖 batch 里有多少样本------即使 batch 里只有一个样本,统计量也是完整的。LayerNorm 是 Transformer 的标配。 从 2017 年的原始 Transformer,到 BERT、GPT 系列、LLaMA,所有基于 Transformer 的模型都使用 LayerNorm(或其变体)而弃用了 BatchNorm。
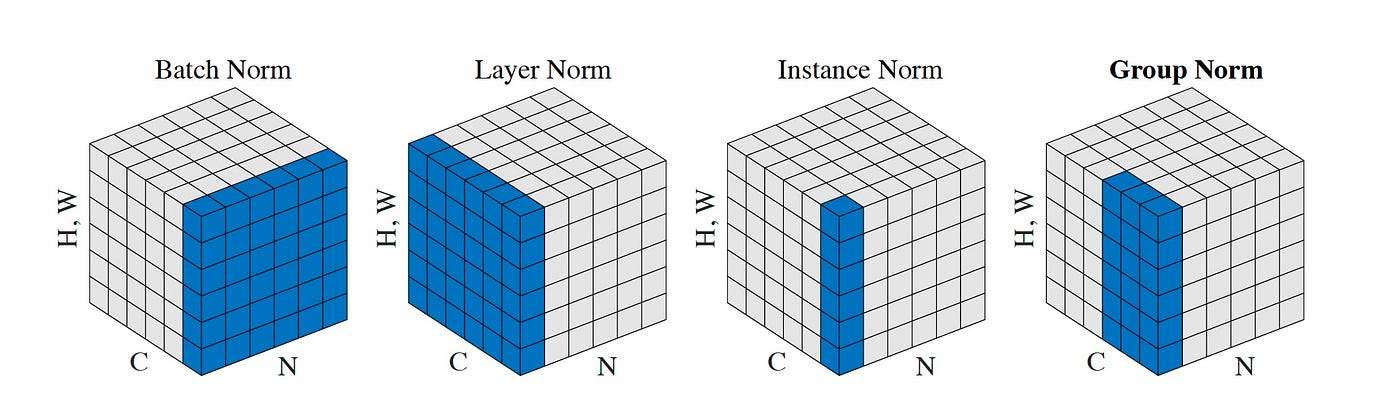
图 6.3:常见的各类归一化维度示意图
6.5.4 RMSNorm: 减少计算量,保留效果
2019年,研究者们发现 LayerNorm 里有一个计算步骤可能是多余的:减均值的操作。
RMSNorm(Root Mean Square Layer Normalization)在此基础上去掉了均值计算步骤,只保留方差归一化:
RMS(x) = sqrt(mean(x_j² for j in features))
x̂_j = x_j / RMS(x)
y_j = γ * x̂_j # 无偏移项 β实验结果显示:RMSNorm 在大多数任务上与 LayerNorm 性能相当,但计算速度更快(省了一次均值计算)。LLaMA、Mistral、DeepSeek 等后来的开源 LLM,都选择了用 RMSNorm 替代 LayerNorm。在训练几千亿 token 的 LLM 时,每一层节省几毫秒,乘以数万亿次的前向传播,积累起来是相当可观的时间节省。
6.6、权重初始化:从随机噪声到有效起点
6.6.1 初始化为零的灾难
神经网络的参数在训练开始前需要初始化。一个最直觉的想法:将参数全部初始化为零。
这是个灾难。原因是对称性(Symmetry):如果同一层的所有神经元初始化为相同的值,它们接收相同的输入,计算相同的激活,输出相同的梯度------每个神经元会做完全一样的更新,永远保持相同。整个层,实际上只有一个神经元在工作。
这叫做对称性破坏问题------初始化必须引入随机性,打破对称,让不同神经元从不同的初始点出发,学习不同的特征。
那我们是否可以使用较小的随机数进行初始化呢?例如从 N(0,0.01)\mathcal{N}(0, 0.01)N(0,0.01) 中采样?
对于浅层网络,这的确可以工作。但对于深层网络,如果方差太小,每层的激活值都会缩小,经过很多层之后趋近于零------神经元实际上处于"休眠"状态,梯度同样会消失。
那我们如果用较大的随机数进行初始化呢?比如从 N(0,1)\mathcal{N}(0, 1)N(0,1) 中采样?
这会导致激活值指数级增大,经过多层后爆炸------对 Sigmoid 等饱和激活函数,大激活值会直接落入饱和区,梯度为零。
6.6.2 Xavier 初始化
2010 年,泽维尔·格洛特 (Xavier Glorot,后加入 DeepMind)和约书亚·本吉奥发表了一篇重要论文,系统研究了初始化对深层网络训练的影响。
他们的推导思路是:让信号在前向传播和反向传播中,都保持相对稳定的方差。
如果初始化方差太小:信号在前向传播中衰减,最终层激活为零。如果初始化方差太大:信号爆炸,激活进入饱和区。对于使用 tanh 或 Sigmoid 激活函数的层,他们推导出最优的初始化方差:Var(W)=2n_in+n_out\text{Var}(W)=\frac{2}{\sqrt{ \text{n\_{in}} + \text{n\_out} }}Var(W)=n_in+n_out 2其中 'n_in' 是该层输入神经元数,'n_out' 是输出神经元数。这就是 Xavier初始化(也叫 Glorot 初始化)。
Xavier 初始化解决了 tanh/Sigmoid 网络的训练稳定性问题,让训练真正深层的网络成为可能。
6.6.3 Kaiming 初始化:补偿激活函数的"冷却效应"
2015年,微软亚洲研究院的何恺明在论文《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》中发现了一个关键问题:Xavier 初始化对 ReLU 及其变体激活函数效果不理想。
问题的数学根源
使用 ReLU 时,负值被硬截断为零,这改变了信号传播的统计特性。
考虑一个简单的计算:输入 x∼N(0,1)x \sim \mathcal{N}(0, 1)x∼N(0,1),权重 W∼N(0,σW2)W \sim \mathcal{N}(0, \sigma_W^2)W∼N(0,σW2),输出 y=x⋅Wy = x \cdot Wy=x⋅W。
- 未经激活时:Var(y)=Var(x)⋅Var(W)=1⋅σW2=σW2\text{Var}(y) = \text{Var}(x) \cdot \text{Var}(W) = 1 \cdot \sigma_W^2 = \sigma_W^2Var(y)=Var(x)⋅Var(W)=1⋅σW2=σW2
- 应用 ReLU 后:ReLU 将所有负值映射为零,实际上输出方差缩小了一半(因为负半轴的贡献消失了)
如果不修正这个因子,信号在经过多层 ReLU 后会不断衰减------这是梯度消失的另一个根源。
何恺明的修正方案是,为了补偿这个"冷却效应",初始化方差应该加倍:
Var(W)=2nin\text{Var}(W) = \frac{2}{n_{\text{in}}}Var(W)=nin2
或写成标准差的形式:
σW=2nin\sigma_W = \sqrt{\frac{2}{n_{\text{in}}}}σW=nin2
这个因子 2 的来源,就是对 ReLU 半激活特性的补偿。He 初始化(或 Kaiming 初始化)由此得名。
验证与理解
为了理解这个公式,我们可以用一组具体的数值进行实验:
假设一层网络有 nin=10n_{\text{in}}=10nin=10 个输入神经元。随机初始化输入 x∈R1000×10x \in \mathbb{R}^{1000 \times 10}x∈R1000×10(1000 个样本,每个 10 维):
python
x = torch.randn(1000, 10) # mean≈0, std≈1
W = torch.randn(10, 200) # 未做缩放
y = x @ W # 输出
print(f"输入std: {x.std():.3f}") # 1.0025 ≈ 1.0
print(f"输出std: {y.std():.3f}") # 3.1336 ≈ √10 ≈ 3.16输出的标准差为 nin=10≈3.16\sqrt{n_{\text{in}}} = \sqrt{10} \approx 3.16nin =10 ≈3.16,这来自方差的可加性:
Var(y)=∑k=1ninVar(xkWk)=nin⋅1⋅1=10\text{Var}(y) = \sum_{k=1}^{n_{\text{in}}} \text{Var}(x_k W_k) = n_{\text{in}} \cdot 1 \cdot 1 = 10Var(y)=k=1∑ninVar(xkWk)=nin⋅1⋅1=10
如果应用 ReLU,方差缩小到 5(因为负半轴消失)。为了恢复到方差 10,权重初始化时方差需要翻倍:
python
W = torch.randn(10, 200) * (2 / 10) ** 0.5 # √(2/10) ≈ 0.447
y_relu = torch.relu(x @ W)
print(f"ReLU后的输出std: {y_relu.std():.3f}") # 结果在 0.8 左右实测结果,在经过 Kaiming 权重初始化,并应用 ReLU 激活函数,输出的标准差在 0.8 左右,相对接近于 1。需要注意的是,He 初始化的目的并不是让输出 std 精确为 1,而是通过补偿激活函数的方差衰减,使得梯度能在深层网络中有效反向传播。
(选读)为什么没有恢复到 1
为什么恢复后的标准差为 0.8,而不是 1,这其实来自 ReLU 的截尾分布特性。当对正态分布应用 ReLU 时,并不是简单地"把一半方差去掉",而是变成了 截尾正态分布(truncated normal)。对于 y∼N(0,σ2)y \sim \mathcal{N}(0, \sigma^2)y∼N(0,σ2),应用 ReLU 后: EReLU(y)≈0.399σ;VarReLU(y)≈0.341σ2E\\text{ReLU}(y) \approx 0.399\sigma; \qquad \text{Var}\\text{ReLU}(y) \approx 0.341 \sigma^2EReLU(y)≈0.399σ;VarReLU(y)≈0.341σ2
因此方差的缩放因子实际上是 0.341 而不是 0.5,而如果我们采用 0.341\sqrt{ 0.341 }0.341 权重进行补偿,则
python
未经 ReLU 前: y_std ≈ √10 × 0.447 ≈ 1.414
应用 ReLU 后: y_relu_std ≈ 1.414 × √0.341 ≈ 0.826 ✓这正好符合截尾分布的理论。
我们再次强调,He 初始化的真正目的不在于让输出 std 恰好为 1,而在于使梯度在反向传播中能有效流动,避免梯度爆炸和消失,使得深层网络可训练。
6.6.4 现代激活函数:从 GeLU 到 SwiGLU
然而,到了 2016 年后,随着 Transformer 的崛起,研究者们逐渐采用 GeLU、SwiGLU等现代激活函数,那又应该如何初始化呢?
如果我们看 PyTorch 官方文档,其中的 torch.nn.init.calculate_gain() 函数只内置了少数激活函数的增益系数:
| 激活函数 | gain值 | 说明 |
|---|---|---|
| linear / identity | 1.0 | 无非线性 |
| sigmoid | 1.0 | |
| tanh | 5/3 ≈ 1.667 | |
| relu | √2 ≈ 1.414 | 补偿一半神经元失活 |
| leaky_relu | √(2/(1+slope²)) | 取决于负斜率 |
| selu | 3/4 | SELU的特殊缩放性质 |
GeLU、SiLU(Swish)、SwiGLU 等,都没有被包含。为什么官方文档里没有这些?
GeLU(高斯误差线性单元)的定义是:
GELU(x)=x⋅Φ(x)\text{GELU}(x) = x \cdot \Phi(x)GELU(x)=x⋅Φ(x)
其中 Φ(x)\Phi(x)Φ(x) 是标准正态分布的累积分布函数(CDF)。
不像 ReLU 的 max(0,x)\max(0, x)max(0,x) 有简洁的数学形式,GELU 的方差缩放系数依赖于输入的分布,没有简洁的解析解 。实验上,GeLU 的有效增益约为 2\sqrt{2}2 (与 ReLU 接近),因为在正半轴,GeLU 近似线性行为。
SwiGLU 为何更复杂?
SwiGLU 的结构是:
SwiGLU(x,W1,W2)=SiLU(xW1)⊗(xW2)\text{SwiGLU}(x, W_1, W_2) = \text{SiLU}(xW_1) \otimes (xW_2)SwiGLU(x,W1,W2)=SiLU(xW1)⊗(xW2)
这不是单一的激活函数,而是一个门控线性单元:
- 第一项 SiLU(xW1)\text{SiLU}(xW_1)SiLU(xW1) 做激活
- 第二项 xW2xW_2xW2 做"门控",两项逐元素相乘
传统的 Kaiming 初始化假设"独立的层"------激活只依赖该层的输入。但 SwiGLU 有两个权重矩阵相互作用 ,打破了这个假设。因此,SwiGLU 从根本上不适用经典的 Kaiming 增益公式,Kaiming 初始化方法主要适用于 ReLU 及其变体激活函数等。
6.6.5 现代 LLM 的实践方案:经验优于理论
既然理论给不出简洁答案,那现代 LLM 训练采取了什么实践方法?
对于 GeLU/SiLU
最常见的做法是:指定 ReLU 的增益来初始化,因为 GeLU 和 SiLU 在正区间的表现接近 ReLU:
python
import torch.nn as nn
# 方法1:用 kaiming_normal_ 指定 nonlinearity='relu'
nn.init.kaiming_normal_(weight, nonlinearity='relu')
# 等价于:std = √(2 / fan_in)
# 方法2:直接用固定的 std,这是 GPT-2 风格的做法
nn.init.normal_(weight, mean=0.0, std=0.02)第一种方法更有理论依据;第二种方法更简单,并且在大规模实验中被验证有效。
对于 SwiGLU
SwiGLU 的初始化通常是:
python
# 三个线性投影分别初始化
gate_proj = nn.Linear(d_in, d_hidden) # W_1
up_proj = nn.Linear(d_in, d_hidden) # W_2
down_proj = nn.Linear(d_hidden, d_out) # 投影回输出维度
init_std = 0.02 # 或根据 fan_in 计算
nn.init.normal_(gate_proj.weight, std=init_std)
nn.init.normal_(up_proj.weight, std=init_std)
# 残差连接末端的权重需要特殊缩放
# (这在第9章会详细讨论,这里只提及)
nn.init.normal_(down_proj.weight, std=init_std / math.sqrt(2 * num_layers))关键是:SwiGLU 不使用 Kaiming 增益,而是用统一的 std 配合残差缩放。
这也体现了深度学习工程化的一个典型模式:理论给出了初步的理解框架(方差传播、梯度流动),工程实践则在这个框架基础上,根据经验不断微调,最终形成一套"虽然不完全遵循理论,但在实践中被验证有效"的方案。
6.7、框架:从手工求导到自动微分的时代
6.7.1 在框架出现之前
在 2007 年,如果你想训练一个神经网络,那么就需要你手动推导反向传播公式,然后用 Fortran 或 C 语言手写每一层的梯度计算代码,然后实现矩阵乘法,然后处理数值精度问题......整个过程可能需要数周时间,而且每改一次架构,就要重新推导一遍。
这不只是低效,它实际上限制了研究者可以探索的网络类型。越简单的架构越好推导,越复杂的架构越难以手算梯度------这制造了一个隐性偏见,让研究者倾向于选择梯度易于计算的网络,而不是可能效果更好但更复杂的网络。
6.7.2 Theano:计算图的先驱
2008 年,蒙特利尔大学的约书亚·本吉奥 实验室发布了 Theano------第一个真正意义上的深度学习框架。
Theano 的核心创新是符号计算图 (Symbolic Computation Graph):用 Theano 的 API 定义"操作"(矩阵乘法、加法、激活函数),Theano 自动构建计算图,表示这些操作之间的依赖关系,并自动推导反向传播所需的所有梯度公式------这是自动微分(Automatic Differentiation)的早期实现。Theano 还支持将计算图编译到 GPU 上运行,在 CUDA 出现后提供了 GPU 加速。
对于 Hinton、Bengio 等蒙特利尔学派的研究者,Theano 是赋能者:它让研究者能专注于架构设计,而不是梯度计算的繁琐实现。
但 Theano 有一个让工程师非常头疼的设计特点:静态计算图。你必须先"定义"整个计算图,编译后才能运行------调试极度困难,因为 Python 的调试器无法进入图的内部;错误信息晦涩,往往只有编译错误而不是运行时的直觉信息。
6.7.3 Caffe 与 TensorFlow:静态图时代的两个极端
2014 年,加州大学伯克利分校的贾扬清 (Yangqing Jia,1985---,中国计算机科学家)发布了Caffe------专为卷积神经网络设计的框架,用配置文件定义网络结构,在计算机视觉社区迅速流行,一度是 ImageNet 竞赛的主流框架。
2015 年 11 月,Google 发布了TensorFlow 1.x 。TensorFlow 的设计哲学强调生产部署能力:静态计算图可以序列化、传输到不同平台、用 Google 的分布式基础设施扩展到数百台机器。这让 TensorFlow 迅速成为企业的首选。
但 TensorFlow 1.x 对研究者来说,体验非常糟糕。
问题还是静态图:必须先构建计算图,然后开一个"会话"(Session),把数据喂给会话运行。图和执行是分离的。大家写的 Python 代码不是直接可执行的代码,而是在"描述一个将来会被执行的图"。
这意味着:我们无法在网络训练的中间用 print() 打印一个张量的值看看发生了什么;也无法用 Python 调试器单步进入网络内部;错误可能在图被执行时才出现,而不是在你写出错误代码的地方。
一位早期 TensorFlow 用户有一个形象的比喻:
"用 TensorFlow 1.x 调试网络,就像在一个不能打断点、不能单步执行的环境里写代码。你只能在程序外面猜测里面发生了什么。"
6.7.4 PyTorch:研究者的反叛
2016 年 9 月,Facebook AI Research(FAIR)发布了 PyTorch。
PyTorch 做了一个表面简单、实则根本性的设计决定:动态计算图 (Dynamic Computation Graph),也叫 "按需执行"(Eager Execution)。
动态计算图意味着:代码在执行时才构建计算图。当我们写 y = x @ W + b,Python 立刻执行这个矩阵乘法,并记录梯度。可以在任意点插入 print(y),看到实际的张量值。也可以用 Python 的 if 语句、for 循环、try/except------所有 Python 语言的控制流都自然地工作,计算图会随着代码的动态执行而动态构建。
PyTorch 让深度学习变回了"写普通 Python 代码"的感觉。
早期用户的反应,几乎是一致的惊喜:
"第一次用 PyTorch 的时候,我脑子里有一种感觉:'就这?它就是普通 Python。'然后我意识到,这正是它了不起的地方。"
PyTorch 从一发布开始,就在研究界获得了极高的接受度。2018 年的统计显示:NeurIPS 和 ICML 上接受的论文中,PyTorch 代码仓库的数量第一次超过了 TensorFlow。这个趋势在 2019---2020 年迅速扩大。
Google 的反应 :2019 年,TensorFlow 发布 2.0 版本,核心改变就是把 eager execution 设为默认------这是在向 PyTorch 的设计理念靠拢。同时,Google 强力推广 Keras(高层 API)来降低 TF 的使用门槛。但时机已晚:研究生态已经大量向 PyTorch 迁移,论文代码、开源模型、教程资源都以 PyTorch 为主。TensorFlow 在工业生产部署场景(尤其是 Google 内部产品线、移动端 TFLite)保持了重要地位,但在研究社区,PyTorch 的统治地位在 2020 年后已经确立。
JAX 的出现 :与此同时,Google 研究团队推出了JAX------一个函数式自动微分库,支持对任意 Python 函数做自动微分,并有极其强大的即时编译(JIT)和硬件抽象(可以无缝运行在 GPU 和 TPU 上)。DeepMind 大量使用 JAX,AlphaFold 2 就是用 JAX 写的。但 JAX 的函数式范式对习惯命令式编程的用户不友好,目前仍是研究前沿的小众工具。
6.7.5 PyTorch 为什么赢了:生态飞轮
PyTorch 的胜出,不只是技术选择的胜利,更是社区飞轮的胜利:
- 研究者发现 PyTorch 好用 → 论文代码用 PyTorch 发布
- 新研究者学习这些代码 → 学会了 PyTorch → 他们的论文也用 PyTorch
- 招聘市场发现大量简历上写"熟悉 PyTorch" → 企业开始要求候选人懂 PyTorch
- 工业级 PyTorch 工具链(TorchServe、TorchScript、ONNX)发展成熟 → 更多企业选择 PyTorch
- 回到步骤 1
在这个飞轮形成之后,TensorFlow 即使在技术上做出改进,也很难打破惯性。这不是 TensorFlow 的失败,而是先发优势在开发者生态里的强大作用------是深度学习框架战争里最清晰的"赢家通吃"案例。
6.8、硅基矩阵机:GPU 如何成为 AI 的底层基础设施
6.8.1 游戏显卡的意外转型
1999 年,Nvidia 发布了第一款被命名为"GPU"(Graphics Processing Unit,图形处理单元)的芯片------这个名字是 Nvidia 市场部门创造的,指那些专门处理图形渲染的芯片。GPU 的设计出发点完全是游戏:让《雷神之锤》的画面更流畅,让 3D 图形能实时渲染。
Nvidia 工程师在设计 GPU 时,做了一个关键的架构决策:用大量并行的小型计算单元,而不是少数强大的计算单元。这是因为游戏渲染的本质是"对每个像素做相同的操作"------并行性极高,但每个操作不需要很复杂的逻辑。
深度学习的核心操作是什么?矩阵乘法。
前向传播:输入 × 权重矩阵 = 输出激活值。
反向传播:梯度 × 权重转置矩阵 = 传回的梯度。
矩阵乘法,天然地适合大规模并行计算:每个输出元素的计算都是独立的内积,可以同时进行。CPU 受限于它的少数强大核心;GPU 则可以同时启动数千个小型运算,把矩阵乘法速度提高 10---100 倍。
这个"意外的适配",是深度学习历史上最重要的工程机缘之一。没有 GPU,AlexNet 可能要训练几个月,深度学习的实用化会推迟多年。
6.8.2 CUDA:把 GPU 变成通用计算平台
2006 年,Nvidia 做了一个改变 AI 历史走向的战略决定:发布 CUDA(Compute Unified Device Architecture,统一计算设备架构)------一套允许开发者用 C 语言直接为 GPU 编程的 API。
在 CUDA 之前,用 GPU 做非图形计算,需要把计算"伪装"成图形渲染问题------非常迂回、繁琐。CUDA 让程序员能直接写 GPU 代码,而不需要懂图形学。
2007 年,吴恩达的团队率先用 CUDA 加速了神经网络训练,报告了 70 倍的加速比。但 CUDA 真正被全世界看到,是 2012 年的 AlexNet------Krizhevsky 等人使用两块 GTX 580 GPU(每块 3GB 显存)并行训练,论文发表后,GPU 训练神经网络的效果被全世界看到了,Nvidia 的股价开始了一轮长达十年的长牛。
6.8.3 cuDNN:专为深度学习优化的底层库
Nvidia 看到了这个商机,并迅速跟进。
2014 年,Nvidia 发布了 cuDNN(CUDA Deep Neural Network library)------专门为深度学习操作优化的 CUDA 库:卷积、池化、归一化、激活函数,每一个操作都经过 Nvidia 工程师的手工优化,充分利用 GPU 的硬件特性(内存访问模式、指令流水线)。
实测效果:使用 cuDNN 的神经网络,比直接用普通 CUDA 代码快 3---10 倍 。Theano、Caffe、TensorFlow、PyTorch,所有主流深度学习框架在底层都调用 cuDNN。这意味着:一旦选择了 GPU 训练,就自动绑定了 Nvidia 的生态。
6.8.4 GPU 性能的世代跃迁
从 2012 年到今天,GPU 的计算性能以惊人的速度增长:
| GPU型号 | 发布年份 | FP32性能 | BF16/FP16峰值 | 显存容量 |
|---|---|---|---|---|
| GTX 680(AlexNet时代) | 2012 | 3.1 TFLOPS | --- | 2GB |
| Tesla P100 | 2016 | 9.3 TFLOPS | 18.7 TFLOPS FP16 | 16GB |
| Tesla V100 | 2017 | 14 TFLOPS | 112 TFLOPS Tensor Core | 16/32GB |
| A100 | 2020 | 19.5 TFLOPS | 312 TFLOPS BF16 | 40/80GB |
| H100 | 2022 | 60 TFLOPS | 1979 TFLOPS BF16 | 80GB |
| H200 | 2024 | 67 TFLOPS | 1979+ TFLOPS | 141GB |
从 GTX 680 到 H100,FP32 算力提高了近 20 倍,但 BF16/Tensor Core 性能的增长幅度远超这个数字------这不是偶然,是 Nvidia 有意识地为深度学习训练专门优化的结果。
2017 年,V100 首次引入了 Tensor Core------专门用于矩阵乘法的硬件加速单元,可以将 4×4 矩阵乘法在一个时钟周期内完成。这让深度学习的核心操作(矩阵乘法)获得了专用硬件的加速,BF16 的计算性能因此出现了数量级的跃升。
为了让大家更直观的感受到这些不同时代的显卡,到底有多大的差距,我们将用一组具体例子让大家来感受这些数字。
2012年,Hinton 团队用两块 GTX 580(比 GTX 680 还弱一代)训练 AlexNet,在 ImageNet 上跑了整整 5~6 天。那么现在用同样的任务,不同 GPU 需要多久?
| GPU | 大致训练时间 | 时代感 |
|---|---|---|
| GTX 680(2012) | ~5 天 | 周末出去玩,回来还没跑完 |
| P100(2016) | ~10 小时 | 睡一觉 |
| V100(2017) | ~1 小时 | 午饭时间 |
| A100(2020) | ~8 分钟 | 泡一杯咖啡 |
| H100(2022) | ~2 分钟 | 还没喝完第一口 |
GPT-3 有 1750 亿参数,官方训练消耗了约 3640 PetaFLOP·天 (即每秒 101510^{15}1015 次浮点运算,持续 3640 天的总量)。
| GPU | 单卡理论最快需要多久 |
|---|---|
| GTX 680 | 约 3200 年 |
| V100(FP16) | 约 82 天 |
| A100(BF16) | 约 34 天 |
| H100(BF16) | 约 5 天 |
实际 OpenAI 用了上万张 V100,并行跑了约 34 天。H100 集群现在可以在一周内完成。
Tensor Core 的意义 :Transformer 里最核心的操作是大矩阵乘法,比如 4096×4096×4096×40964096 \\times 4096 \times 4096 \\times 40964096×4096×4096×4096,这样一次乘法需要约 137 GFLOPs(1370 亿次浮点运算)。
| GPU | 完成这一次矩阵乘法耗时 |
|---|---|
| GTX 680(无 Tensor Core) | ~44 毫秒 |
| V100(Tensor Core,FP16) | ~1.2 毫秒 |
| A100(Tensor Core,BF16) | ~0.44 毫秒 |
| H100(Tensor Core,BF16) | ~0.07 毫秒 |
Transformer 的一次前向传播里,这样的矩阵乘法要执行数百次。GTX 680 每次前向传播需要几秒,H100 只需要几十毫秒------这是实时推理和"喝杯水"的差距。
这就是为什么 2017 年 V100 + Tensor Core 是 GPU 发展史上真正的分水岭:不只是快了几倍,而是让"训练大模型"这件事从理论上可行变成了工程上可行。
6.8.5 为什么 GPU 没有被专用 AI 芯片取代
自 2016 年前后,各大公司和创业公司都开始开发专用 AI 芯片:Google 的TPU、Graphcore 的 IPU、Cerebras 的晶圆级芯片、寒武纪的 MLU......理论上,专用芯片针对深度学习的操作模式做了专门优化,应该比通用 GPU 更高效。
为什么 GPU 仍然主导着深度学习训练?
答案是生态护城河。Nvidia 的 CUDA 生态,经过超过 15 年的积累,包含了:cuDNN/cuBLAS/NCCL等深度优化的数值计算库;几乎所有开源深度学习代码都是为 CUDA 写的;完善的调试工具链(Nsight Compute/Systems);以及全球数十万熟悉 CUDA 的深度学习工程师。
专用芯片在某些特定场景(推理部署、特定网络架构)可以击败 GPU,但对于研究和通用训练,GPU 的 CUDA 生态提供了难以复制的惯性------换到新芯片意味着移植大量代码、重新培训工程师、失去大量第三方工具。
Google 的 TPU 是个例外,但它主要在 Google 内部使用,对外通过 Cloud 提供服务,并不影响整个行业的 GPU 主导地位。
6.9、走向规模化:分布式训练的第一步
6.9.1 单卡的天花板
2016 年,如果你想训练一个有 1 亿参数的模型,你会遇到一个硬性约束:显存。
一个 FP32(32 位浮点数)参数占 4 字节,1 亿参数需要 400MB 显存。听起来不多------但训练一个模型消耗的显存远不只是参数本身:
- 梯度:和参数一样大
- 优化器状态 (Adam 维护两个状态 mmm 和 vvv):是参数的两倍
- 中间激活值(反向传播需要保存前向传播的激活):取决于批大小和网络深度
实际上,一个 1 亿参数的模型用 Adam 训练,完整显存需求约为参数量的 16倍------大约 6.4 GB。2016 年最好的研究级 GPU 只有 16GB 或 32GB。当模型增大到 10 亿参数,单卡完全无法容纳。
从单卡到多卡,从单机到多机,是深度学习工程化最重要的扩展方向之一。 这里介绍最基础的两种技术;完整的分布式训练体系(模型并行、流水线并行、ZeRO 优化器)将在第十一章"规模定律"中详细讨论。
6.9.2 数据并行:最简单的多卡方案
数据并行(Data Parallelism)的思路极其简单:
- 把同一个模型复制到每一块 GPU 上
- 把每个 mini-batch 的数据分成 N 份,一份给一块 GPU
- 每块 GPU 独立计算前向传播和反向传播,得到自己那份数据的梯度
- 聚合(All-Reduce):把所有 GPU 的梯度加总,并广播给所有 GPU
- 每块 GPU 用聚合后的梯度,做相同的参数更新
python
# PyTorch数据并行(极简示例)
model = MyModel()
model = torch.nn.DataParallel(model) # 一行代码,模型自动分发到所有GPUNvidia 专门开发了 NCCL(NVIDIA Collective Communications Library)来高效实现 All-Reduce,利用 NVLink 等硬件互联来最大化通信带宽。
6.9.3 梯度累积:以时间换空间
当模型太大,单次 mini-batch 根本放不进显存时,梯度累积(Gradient Accumulation)提供了一个单卡的近似解:
python
accumulation_steps = 8 # 等效批大小 = 真实批大小 × 8
optimizer.zero_grad()
for i, (inputs, targets) in enumerate(dataloader):
outputs = model(inputs)
loss = criterion(outputs, targets) / accumulation_steps
loss.backward() # 梯度在内存里累积,不清零
if (i+1) % accumulation_steps == 0:
optimizer.step() # 累积了 N 步梯度后,才做一次参数更新
optimizer.zero_grad()梯度累积的效果等价于批大小扩大了 N 倍,但显存消耗只是单步的量。代价:训练速度下降(没有真正的并行),但在 GPU 显存极端紧张时是可行的选择。
6.9.4 混合精度训练:显存消耗减半,速度翻倍
在模型训练阶段上,模型计算精度主要分为:
- FP32(32位浮点):最高精度,最慢,显存最大
- FP16(16位浮点):精度低,速度快,显存小,但数值不稳定(溢出/下溢问题)
- BF16(Brain Float 16,Google Brain开发):牺牲小数位精度,保留更大的数值范围,比 FP16 更稳定
混合精度训练(Mixed Precision Training)的方案,由 Nvidia 在 2018 年的论文里系统提出:
- 计算用低精度(FP16 或 BF16):矩阵乘法等计算密集型操作用半精度,速度是 FP32 的 2---8 倍
- 存储主权重用 FP32:模型参数的"主副本"用 FP32 保存,保证精度不损失
- 梯度缩放(Loss Scaling):FP16 的数值范围小,很小的梯度会下溢为零;通过放大损失使梯度保持在有效范围内
python
# PyTorch 混合精度训练(torch.cuda.amp)
scaler = torch.cuda.amp.GradScaler() # 梯度缩放器
with torch.cuda.amp.autocast(): # 自动混合精度上下文
output = model(input)
loss = criterion(output, target)
scaler.scale(loss).backward() # 缩放梯度,防止 FP16 下溢
scaler.step(optimizer)
scaler.update()混合精度训练的效果:显存减少约 30---50%,训练速度提升 1.5---3 倍(取决于 GPU 型号和操作比例)。从 BERT 预训练开始,混合精度训练成为大规模模型训练的标准配置,沿用至今。
6.10、工程化的边界:炼丹为何依然存在
6.10.1 工具不能解决的问题
我们在这一章里,系统梳理了深度学习工程化的八个核心维度。这些知识在一定程度上可以帮助工程师少走很多弯路------但不能帮他们走出所有的弯路。
"炼丹"这个词时至今日依然在使用,不是因为社区没有进步,而是因为有一些根本性的困难,工程工具无法消解。
第一个困难:超参数的维度爆炸。
每引入一个新技术,就增加了一组需要调整的超参数:
- Adam:学习率、β1β_1β1、β2β_2β2、εεε、权重衰减系数
- 学习率调度:预热步数、最大学习率、余弦周期数
- BatchNorm/LayerNorm:γγγ、βββ 的初始化
- Dropout:drop rate,应该加在哪些层
这些超参数之间还有交互效应:批大小改变时,学习率通常需要相应调整("线性缩放规则"------批大小翻倍,学习率也翻倍,Facebook 2017 年的发现);Adam 和 L2 正则化有已知的相互干扰(AdamW的动机);BatchNorm 和 Dropout 同时使用会产生意想不到的干扰。在一个有数十个超参数、相互之间有复杂交互的系统里,即使有系统性的搜索策略,完整的超参数空间也是无法穷举的。
第二个困难:技术的迁移性不稳定。
一套在 ResNet 上完美工作的配置,迁移到 Transformer 时可能需要从头调整------不同的架构、不同的数据模态、不同的训练规模,对工程配置的需求可能完全不同。
BatchNorm 在 CNN 上效果极好,在 Transformer 上几乎无法使用;SGD with momentum 在视觉任务上有时比 Adam 更好,在语言任务上很少成为首选;Dropout 在小模型上有效防止过拟合,在预训练大模型上效果存疑。没有任何一套配置对所有问题都是最优的。
第三个困难:理论理解滞后于工程实践。
我们知道 Adam 比 SGD 在大多数任务上收敛更快------但对于"为什么 Adam 找到的解在泛化能力上有时不如 SGD",理论解释仍然不完整。我们知道 BatchNorm 能稳定训练------但对于它的"轻微正则化效果"的机制,理论界至今没有完全达成共识。
这不是无知,这是科学前沿的正常状态:工程实践往往领先于理论解释。但它意味着,工程师在遇到边界情况时,无法依赖完整的理论框架来推理,只能回到实验------回到"炼丹"。
6.10.2 自动机器学习的尝试与局限
那有没有办法让机器来完成"炼丹",自动找到最优的超参数配置呢?
这个方向叫做AutoML(Automated Machine Learning),在 2017---2020 年间吸引了大量研究和投资。
Google 提出了 Neural Architecture Search(NAS)------用神经网络来设计神经网络的架构。他们用强化学习搜索到了 EfficientNet 系列,在 ImageNet 上超过了人类手工设计的架构。
但 AutoML 有根本性的计算代价问题:搜索最优架构需要训练和评估成千上万个候选模型------计算成本是手工设计的几百倍甚至几千倍。对于大型模型,这个代价完全无法承受。
更深的问题是:AutoML 可以自动化"给定数据集,找最优架构"这个任务,但无法自动化"定义什么是正确的任务"和"数据集是否正确"这些更根本的决策。工程化的技术层面可以部分自动化,但工程判断和问题定义,至今仍然是人的工作。
6.10.3 工程化积累的真正价值
让我们回到本章的起点:那个无法复现 AlexNet 的博士生。
他面对的问题,本质上是知识的不透明性------有效的工程知识被锁在少数实验室的经验里,没有系统化的整理和传播。
2012-2024年,这个问题在很大程度上被解决了。
不是因为"炼丹"消失了,而是因为:Adam 成为了大多数任务的合理默认值;PyTorch 的调试友好性让工程师能更快理解"为什么模型不收敛";混合精度训练被集成进框架,不再需要手动实现;学习率Finder 把"试学习率"的时间压缩到分钟级;大量开源代码库(HuggingFace Transformers、fast.ai)把好的工程实践直接封装进 API。
这不是消除了不确定性,而是把 "已知的最佳实践"的覆盖范围大幅扩展了。留下的"炼丹空间",是还没有系统化的边界地带------而这些边界,往往也是下一代研究的前沿。
!important
本章的核心 insight:深度学习的成功,一半靠算法创新(正确的架构、正确的数学),一半靠工程基础设施(正确的优化器、正确的调度、正确的工具链)。这两部分是不可分割的。一套好的工程工具链,可以让研究者能花更多时间在真正重要的问题上,而不是在基础调试上。深度学习从"少数人的炼丹玄学"变成"多数人可掌握的工程实践",工程化的积累功不可没。
6.11、知识自检
读完本章,你应该能做到:
- 解释为什么 Adam 比普通 SGD 在大多数深度学习任务上更快收敛,以及 Adam 的 mmm 和 vvv 两个状态量各自追踪什么信息
- 描述"学习率太大"和"学习率太小"分别会导致训练出现什么具体现象,以及为什么学习率预热是必要的
- 用一个具体类比解释 ReLU 的梯度流动优势,以及"神经元死亡"问题是什么,Leaky ReLU 如何修复它
- 解释 BatchNorm 解决了什么问题("内部协变量转移"的含义),以及它为什么在序列任务和小批量场景下失效
- 说明 LayerNorm 和 BatchNorm 在归一化维度上的根本区别,以及为什么 Transformer 选择LayerNorm
- 用"对称性破坏"解释为什么全零初始化会失败,以及 He 初始化和 Xavier 初始化各自针对什么激活函数
- 说出 PyTorch 和 TensorFlow 的核心设计差异(动态图 vs 静态图),以及这个差异如何影响研究者的开发体验
- 解释为什么 GPU 天然适合矩阵乘法,CUDA 和 cuDNN 分别解决了什么问题
- 描述混合精度训练的基本逻辑(低精度计算+高精度主权重),以及它能带来多大的性能收益
- 解释数据并行和梯度累积各自解决了什么问题,以及它们的代价是什么
6.12、常见误解
❌ "Adam 是最好的优化器,SGD 已经没用了"
✅ 实际上:Adam 对大多数任务是更好的默认选项,但 SGD 在某些情况下仍然有优势。一些视觉任务(如 ImageNet 分类)上,精心调过的 SGD + Momentum 能达到比 Adam 更好的最终精度,但训练时间更长。Adam 的优势是训练早期收敛更快、对学习率不那么敏感。AdamW(修正了权重衰减的变体)是 LLM 训练的标准选择。
❌ "BatchNorm 解决了梯度消失问题"✅ 实际上:BatchNorm 解决的核心问题是"内部协变量转移"------每层输入分布随训练不断变化,它的直接作用是让训练更稳定、允许更大学习率。梯度消失问题主要由 ReLU 等激活函数解决,另外由残差连接(ResNet)从结构上提供了梯度高速路。BatchNorm、ReLU、残差连接,三者各自解决不同的训练困难,经常配合使用。
❌ "混合精度训练会导致模型精度下降"✅ 实际上:正确实现的混合精度训练(FP16计算 + FP32主权重 + 梯度缩放)在绝大多数任务上,精度损失可以忽略不计(通常在 0.1% 以内)。精度损失发生的情况,往往是没有正确实现梯度缩放(导致梯度下溢),或者在极端情况下 FP16 数值范围不够(此时用 BF16 可以缓解)。
❌ "TensorFlow 失败了,被 PyTorch 完全取代了"✅ 实际上:TensorFlow 在工业生产部署(尤其是 Google 体系内的产品线、移动端 TFLite、服务端 TFServing)仍然占有重要地位。TensorFlow 的"失败"是在研究社区的话语权上,而不是在整个行业的实际使用上。更准确的说法是:研究社区大幅偏向 PyTorch,但生产部署 TensorFlow 仍然广泛使用。
❌ "调参就是玄学,没有任何规律可言"✅ 实际上:调参有大量经过验证的经验规律------学习率与批大小的线性缩放关系、优化器选择的领域经验(视觉vs语言)、学习率 Finder 帮助快速定位学习率范围、预热策略对大模型的重要性。"炼丹"的真正玄学部分,存在于超参数之间的复杂交互和边界情况;对于大多数标准任务,有明确的"好的默认值"可以遵循。
本章关键词
| 词汇 | 简明定义 |
|---|---|
| 随机梯度下降(SGD) | 每次用小批量数据计算梯度并更新参数的优化算法基础 |
| 动量(Momentum) | 给梯度下降添加"惯性",让参数更新方向在时间上平滑 |
| AdaGrad | 为每个参数维护独立学习率的自适应优化算法 |
| RMSProp | 用梯度平方的滑动平均修复AdaGrad学习率单调递减的问题 |
| Adam | 结合动量和自适应学习率的优化器,深度学习的主流默认选择 |
| AdamW | 修正了权重衰减实现的Adam变体,LLM训练的标准配置 |
| 学习率预热(Warm-up) | 训练开始时将学习率从小值线性增大到目标值,防止冷启动不稳定 |
| 余弦退火(Cosine Annealing) | 按余弦曲线平滑衰减学习率的调度策略 |
| ReLU | max(0, x),正区间梯度恒为1,是深度学习的主流激活函数 |
| GELU | 平滑版ReLU,Transformer时代的标准激活函数 |
| SwiGLU | 门控线性激活单元,LLaMA等LLM前馈层的标准配置 |
| 批归一化(BatchNorm) | 对mini-batch内的激活值做标准化,稳定训练,允许更大学习率 |
| 层归一化(LayerNorm) | 在单样本的特征维度上做归一化,Transformer的标准选择 |
| RMSNorm | 去掉均值计算的LayerNorm变体,LLaMA等LLM的标准配置 |
| Xavier初始化 | 基于网络宽度的方差控制初始化,适合tanh/sigmoid激活函数 |
| He初始化 | 修正了ReLU半激活特性的初始化方案,现代深度网络的默认选择 |
| 自动微分(Autograd) | 由框架自动计算任意可微函数的梯度,无需手工推导 |
| 动态计算图 | 在代码执行时动态构建计算图,PyTorch的核心设计,便于调试 |
| CUDA | Nvidia的GPU通用计算编程框架,深度学习GPU加速的基础 |
| cuDNN | Nvidia专为深度学习操作优化的底层CUDA库 |
| Tensor Core | Nvidia GPU中专门用于矩阵乘法的硬件加速单元(V100起) |
| 数据并行 | 把数据分发到多块GPU,每块GPU持有完整模型,梯度聚合后统一更新 |
| 梯度累积 | 多步不清零梯度,模拟更大批大小的单卡显存节省技术 |
| 混合精度训练 | 低精度(FP16/BF16)计算 + 高精度(FP32)主权重存储,显存与速度的平衡 |
延伸阅读
- 必读:Kingma, D.P., & Ba, J.(2014). "Adam: A Method for Stochastic Optimization." arXiv:1412.6980. Adam 优化器的原始论文,清晰且有大量实验数据
- 必读:Ioffe, S., & Szegedy, C.(2015). "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift." ICML 2015. BatchNorm 的原始论文,理解为什么现代深度网络需要归一化
- 推荐:He, K. 等(2015). "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification." ICCV 2015. 提出 PReLU 和 He 初始化,包含大量对激活函数和初始化的深入分析
- 推荐:Smith, L.N.(2017). "Cyclical Learning Rates for Training Neural Networks." arXiv:1506.01186. 学习率寻找器和周期性学习率,非常实用且易读
- 推荐:Micikevicius, P. 等(2018). "Mixed Precision Training." ICLR 2018. 混合精度训练的系统性论述,包含 FP16 溢出问题的完整分析
- 深入:Loshchilov, I., & Hutter, F.(2019). "Decoupled Weight Decay Regularization." ICLR 2019. AdamW 论文,解释 L2 正则化和权重衰减在自适应优化器中的区别
- 深入:Li, H. 等(2018). "Visualizing the Loss Landscape of Neural Nets." NeurIPS 2018. 通过可视化损失函数地形,直观理解不同架构选择和优化器的影响
!tip
下一章预告:工程工具箱建好了,深度网络能高效训练了。但所有这些,处理的都是有固定大小输入的数据------图像是 W×HW×HW×H 的像素矩阵,可以一口气喂给网络。语言则完全不同:一句话可以有 5 个词,也可以有 500 个词;词与词之间的关系是有顺序的;一段话的意思,可能依赖于很多词以前出现的主语。图像的"局部性",在语言中并不适用。如何让机器学会处理"有顺序、可变长、长程依赖"的序列数据?这个问题催生了一整个神经网络家族------以及一个让研究者头疼了三十年的技术难题。