在 SaaS 和 AI 时代,多租户架构已经成为数据库必须面对的核心场景之一。如何在保证租户间数据隔离的同时,最大化硬件资源利用率、降低运维成本,是每个数据库团队都需要回答的问题。PolarDB PostgreSQL 分布式版(以下简称 PolarDB-PG 分布式版)为此提供了一套成熟、灵活、兼容社区版 Citus 的解决方案。
PolarDB-PG 分布式版架构概览
PolarDB-PG 分布式版采用计算-存储分离的双层架构,由协调节点(CN)负责查询逻辑与元数据管控,数据节点(DN)负责物理分片的存储与计算。底层 PolarStore 共享存储池配合多副本同步机制,既保证了高可用,又实现了按需计费------费用仅按单副本计算。
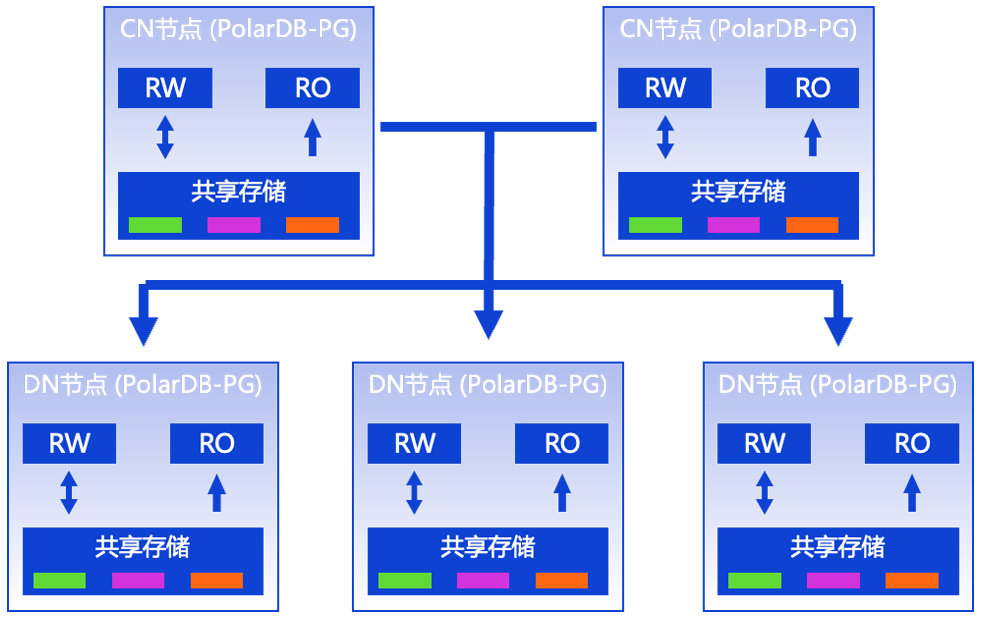
PolarDB-PG 分布式架构:由 CN 和 DN 节点两层构成,每个节点对应一个集中式实例
在分布式表管理方面,PolarDB-PG 分布式版完全兼容 Citus 生态,包括 create_distributed_table、create_reference_table、polar_cluster_move_shard_placement 等核心函数,使用 Citus 的用户可以零成本迁移。同时,产品也保留了完整的 PostgreSQL 生态兼容性,各类 ORM、图形化管理工具和驱动均可直接使用。
多租户架构的两种经典模式
多租户场景下,数据拆分策略直接决定了系统的扩展性、隔离性和运维复杂度。PolarDB-PG 分布式版支持两种主流的拆分模式:
模式一:垂直拆分------每个租户一个 Schema
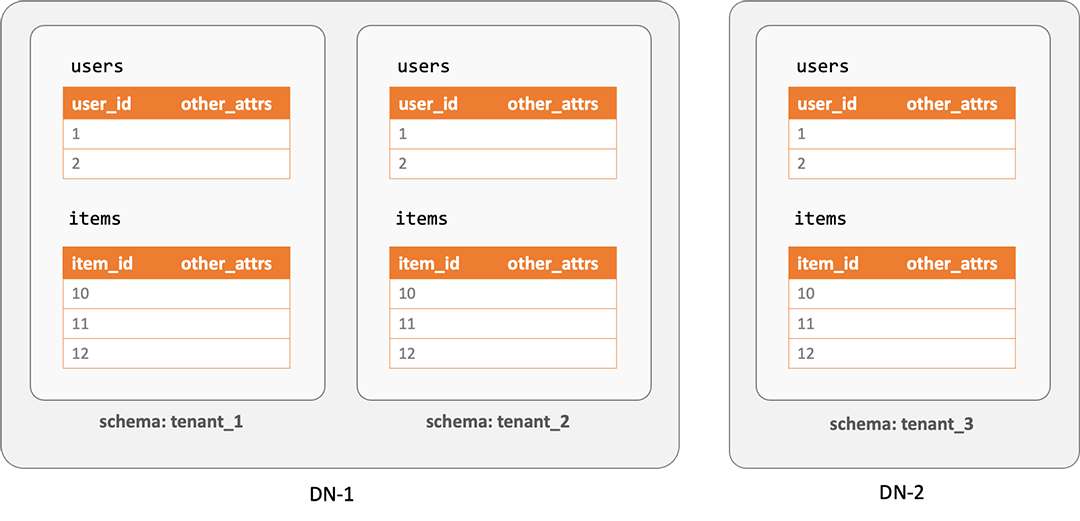
按 Schema 进行垂直拆分,图中有 3 个租户/Schema,分布在 2 个数据节点上
垂直拆分的核心思路是为每个租户分配独立的 Schema,并将不同租户的 Schema 映射到不同的数据节点上。典型适用场景包括:
- 租户数量几十到上百个(通常少于 200 个);
- 不同租户的表结构存在差异,例如可选特性、定制特性等;
- 需要较强的应用层隔离,租户间完全解耦。
PolarDB-PG 分布式版通过内置的 polar_cluster_schema_distribute 功能将 Schema 分布到各个 DN。配合 search_path 的配置,应用连接时可以透明地访问指定租户的数据,无需在业务代码中显式指定 Schema。
-- 将特定 Schema 迁移到目标节点
SELECT polar_cluster_schema_move('tenant_001_schema', 'dn-node-ip', 5432);方案的核心优势包括:
- 表级隔离:每个租户拥有独立的 Schema,表结构、索引、权限完全隔离;
- 独占资源:可以将高负载租户的 Schema 迁移到专用 DN 节点,彻底消除资源争抢;
- 在线迁移:Schema 迁移过程在线进行,不阻塞业务的读写操作。
应用通过 search_path 指定租户后,查询请求会被精确路由到单个 DN 节点,避免了广播查询带来的网络开销,性能接近单机 PostgreSQL。同时,又能享受分布式集群带来的运维优势,通过租户迁移有效利用硬件资源。
实际客户场景中,我们有多个企业级 SaaS 头部客户都采用了这样的多租户实践,行业横跨互联网、餐饮、游戏、企业 ERP 等。
模式二:水平拆分------租户 ID 作为分区键
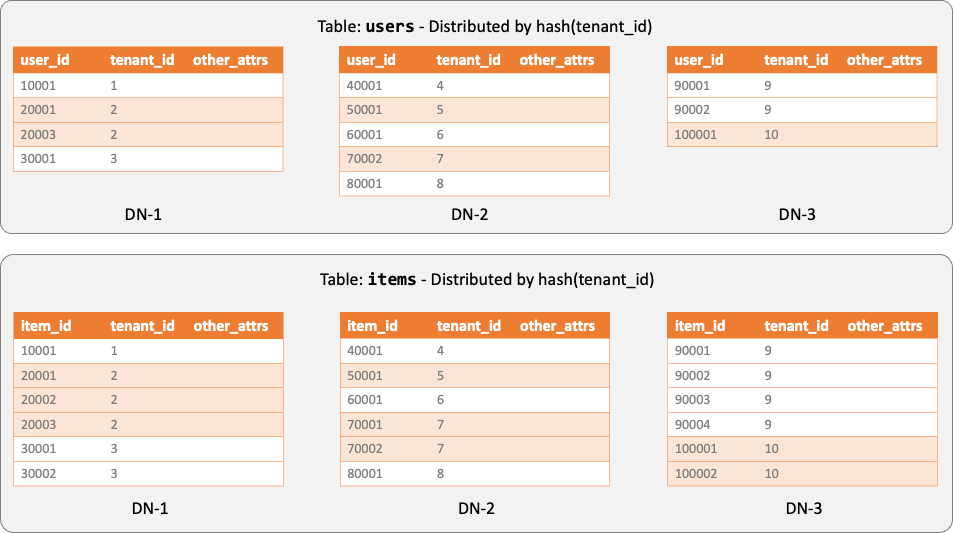
按租户 ID 进行水平拆分,其中 users 和 items 都是分布式表、且都按照 tenant_id 进行分区
水平拆分将所有租户的数据放在同一张分布表中,以租户 ID(tenant_id)作为分布键(distribution key),通过哈希算法将不同租户的行分散到各个 DN 节点。适用场景包括:
- 租户数量庞大(万级至百万级);
- 所有租户的表结构完全相同;
- 追求极致的资源利用率和弹性伸缩能力。
PolarDB-PG 中通过 create_distributed_table 功能将一张表创建成分布式表:
-- 创建表并以 tenant_id 作为分布键
CREATE TABLE orders (
tenant_id bigint NOT NULL,
order_id bigint NOT NULL,
amount decimal(10,2),
created_at timestamp DEFAULT now(),
PRIMARY KEY (tenant_id, order_id)
);
-- 按 tenant_id 进行分布式打散
SELECT create_distributed_table('orders', 'tenant_id');方案的核心优势包括:
- 弹性扩展:新租户加入时,数据自动通过哈希路由到合适的 DN,无需执行 DDL 创建新表;
- 亲和性优化:通过 colocate(亲和组)机制,同一租户的多张表会被分布到相同的节点上,确保跨表 JOIN 时数据同节点存储,避免跨节点网络传输;
- 复制表辅助:租户共享的公共数据(如配置表、字典表)可设为复制表(reference table),每个 DN 保存完整副本,与分布表关联时无需跨节点通信。
查询时,当 WHERE 条件中包含 tenant_id 的等值条件时,优化器自动进行分片剪枝,将查询精确定位到存储该租户数据的分片,性能与单机查询一致。
-- 将特定租户隔离到独立分片
SELECT isolate_tenant_to_new_shard('orders', '10001', 'CASCADE');
-- 将该分片迁移到目标节点
SELECT polar_cluster_move_shard_placement(...);对于负载特别高的租户,PolarDB-PG 分布式版还提供了 isolate_tenant_to_new_shard 功能,可以将特定租户的数据从共享分片中独立出来,并迁移到专用 DN 节点。这使得即使采用水平拆分的架构,也能对重点租户提供垂直隔离级别的资源保障。
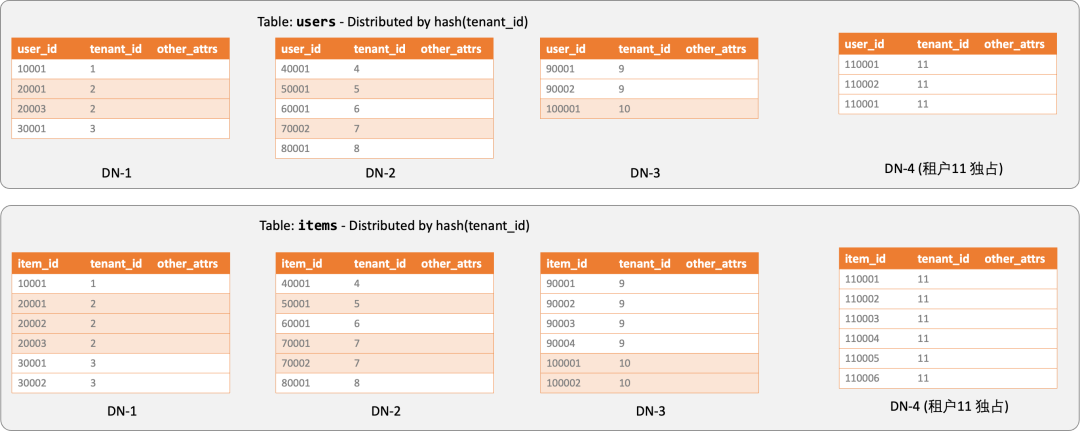
将热点租户 tenant 11 单独拆分到独立的 DN 上
实践中,钉钉的多个业务都采用了这样的多租户实践,这也非常契合钉钉的业务属性------大到上万人的大型企业或组织,小到 OPC(One-Person Company)或个人账号,都能享用到完整的钉钉办公套件。
两种模式对比
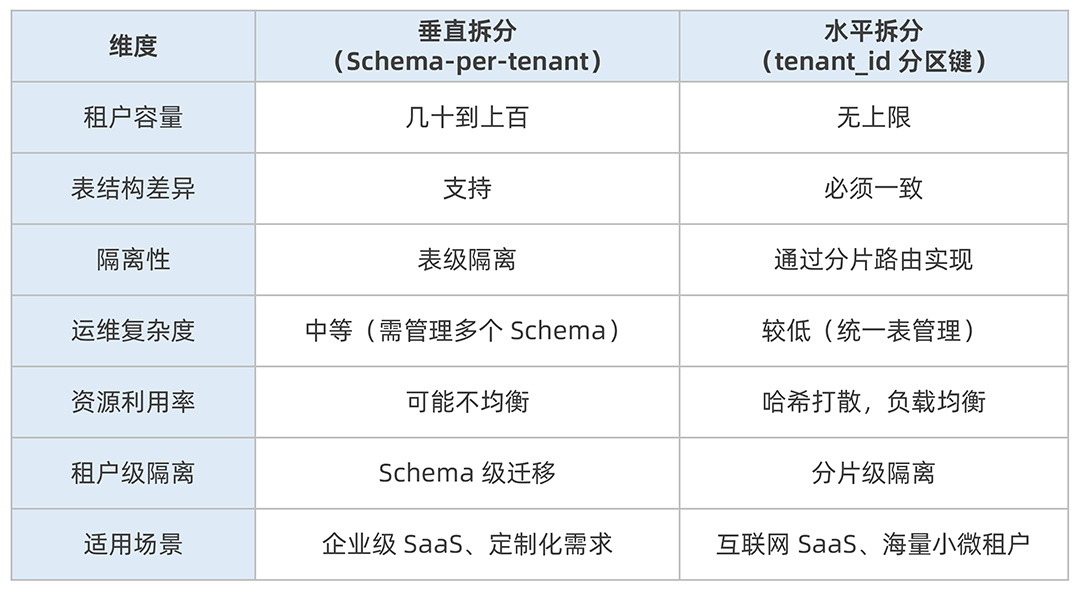
在实际业务中,两种模式也可以结合使用------对于大部分中小租户采用水平拆分,对于有定制化需求或高 SLA 要求的重点客户采用垂直拆分。
分布式能力的关键特性
▶︎ 事务一致性
PolarDB-PG 分布式版基于两阶段提交协议(2PC)和全局时间戳机制保证跨节点分布式事务的原子性。在默认的 Read Committed 隔离级别下,应用可正常使用 INSERT、UPDATE、DELETE 等操作。开启全局一致性事务之后,跨节点的读请求也具备快照一致性。
▶︎ 并行数据重分布
数据重分布是分布式集群运维中最"重"的操作之一。针对数据重分布持续时间久的问题,PolarDB-PG 分布式版支持并行节点间拷贝数据,能够充分利用集群 IO 带宽,在业务给定的时间窗口内尽快完成数据重分布操作,确保不影响业务高峰期的正常流量。
▶︎ 列存加速分析查询
PolarDB-PG 分布式版内置列存分析引擎,对分析查询可带来最高 60 倍的性能提升。列存数据通过异步同步机制与行存保持近实时一致,不影响在线写入。该引擎天然适配多租户环境,无论是按租户 ID 水平拆分还是按 Schema 垂直拆分,均可加速跨租户的全局统计和分析。
▶︎ CDC 数据变更同步
通过配置 CDC(Change Data Capture),PolarDB-PG 分布式版可将数据变更实时流式输出到下游系统(如 Kafka、Elasticsearch 等)。分布式表的 CDC 需要消费者连接每个 DN 节点获取变更事件,复制表仅需连接主 CN 节点。配合 Flink CDC、Debezium 等工具,可轻松实现多租户数据的实时同步和分析。
▶︎ 连接池
在 PostgreSQL 数据库中,常常会发生连接数爆满的问题,导致无法新建连接,甚至导致内存占用过高,触发 OOM 导致实例崩溃。PolarDB-PG 分布式支持智能代理和连接池功能,可以支持更多的连接数,并做到自动负载均衡,无需担心连接数问题和 OOM 问题。
▶︎ 全文检索和向量检索
PolarDB-PG 分布式支持全文检索和向量检索功能,用于满足业务上常见的检索需求。PolarDB-PG 的全文检索支持 BM25、多语言分词、同近义词、拼音等特性,并且支持丰富的查询类型,优化了 jieba 内存占用;向量检索支持向量量化、索引构建、查询召回、高维向量等方面的优化。这些功能特性可以和分布式无缝组合使用,并且可以随着计算节点的增加线性扩展。
总结
PolarDB PostgreSQL 分布式版为多租户场景提供了两种成熟的数据拆分策略:垂直拆分适合租户数量有限、表结构可能存在差异的企业 SaaS 场景;水平拆分适合海量互联网租户、表结构统一的场景,通过分布键实现数据的自动打散和弹性伸缩。两者均支持租户级资源隔离,且可以混合使用。
借助完整的 Citus 兼容性、灵活的查询优化、列存分析加速以及 CDC 实时同步等能力,PolarDB-PG 分布式版已经成为 SaaS 企业构建多租户数据库服务的理想选择。