ddpm和flow matching
1. 核心思想与数学视角的区别
- DDPM (Diffusion Models): 基于加噪与去噪的马尔可夫链 / 随机微分方程 (SDE)
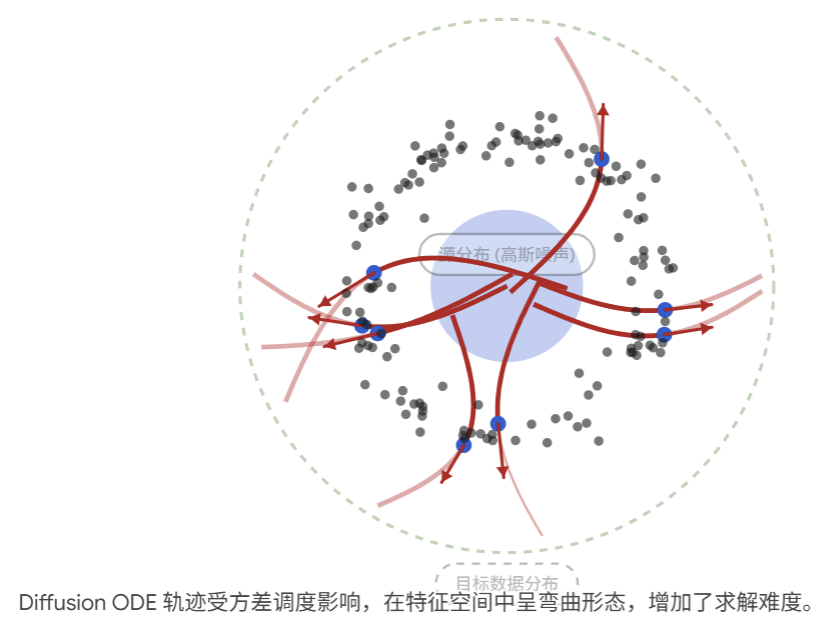
Diffusion 模型的核心在于构造一个破坏数据的过程 。它通过预设的噪声调度策略(如 Linear 或 Cosine),在正向过程中用马尔可夫链或 SDE 将数据逐渐推向高斯分布。模型学习的是这个过程的逆向(即分数函数 Score Function 或去噪方向),由于正向过程的扩散特性,其对应的常微分方程(Probability Flow ODE)的轨迹通常是高度弯曲且复杂的。 - Flow Matching: 基于连续标准化流 (CNF) 的向量场回归
Flow Matching 不再执着于"加噪-去噪"的比喻,而是直接从动态系统和向量场(Vector Fields)的角度出发。它的目标是寻找一个时间依赖的向量场 vt(x)v_t(x)vt(x),使得初始分布(通常是高斯噪声)能够沿着这个向量场流动,精确地演化为目标数据分布。
通过条件流匹配(Conditional Flow Matching, CFM)的数学技巧,模型不需要模拟完整的轨迹,只需在时间 ttt,让网络预测的向量场去拟合构造好的目标向量场即可。其损失函数极其简单明了(即两者的均方误差)。
2. 为什么大家都在转 Flow Matching?
| ddpm | fm |
|---|---|
 |
 |
大家转向 Flow Matching,特别是引入了最优传输(Optimal Transport, OT)的 OT-CFM,主要源于以下几个工程和研究上的巨大红利:
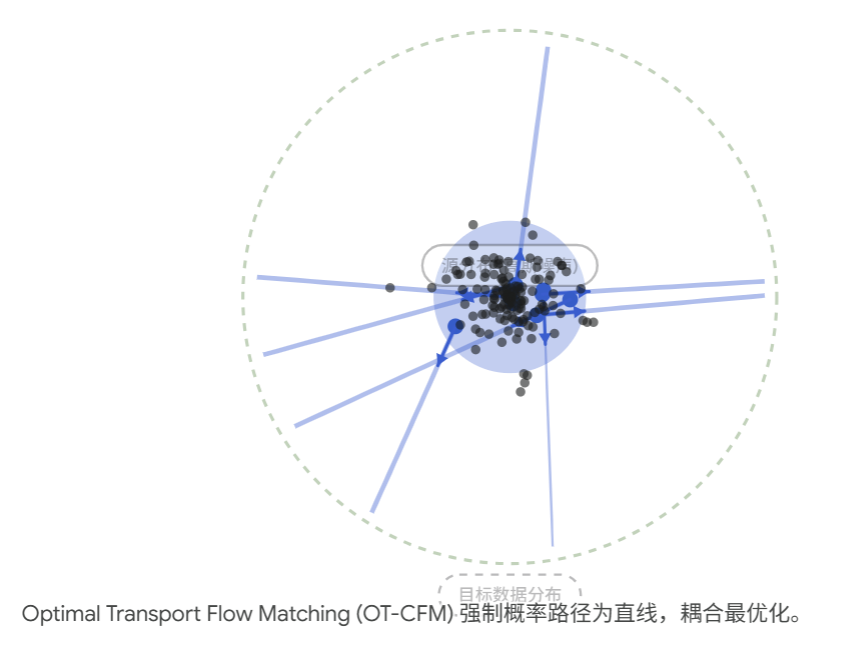
A. 极简的直线轨迹,带来指数级的推理加速 (Inference Efficiency)
在生成阶段,这两类模型都需要使用 ODE 求解器(如 Euler 法、Heun 法、DPM-Solver 等)来积分出最终的样本。
- Diffusion 的痛点: 轨迹弯曲,使得 ODE 求解器在步长较大时容易产生巨大的截断误差。为了保证生成质量,往往需要几十上百步的迭代(NFE 较高)。
- Flow Matching 的优势: 通过 OT-CFM 构造的先验与数据之间的映射是直线(Straight Paths)且 匀速(Constant Velocity)的。即 xt=(1−t)x0+tx1x_t = (1-t) x_0 + t x_1xt=(1−t)x0+tx1。对于这种具有常数导数的直线轨迹,ODE 求解器(哪怕是最简单的欧拉法)只需非常少的步数(比如 4-10 步)就能极其精准地完成积分,极大地加速了生成过程。
B. 打破"噪声到数据"的禁锢:任意分布间的灵活映射
传统 Diffusion 强制一端必须是标准高斯噪声,另一端是数据。但这在很多复杂的生成任务中是不合理的。
Flow Matching 从理论上支持任意两个经验分布之间的直接桥接。在处理跨模态蒸馏或映射任务时(例如将输入的音频/语音特征直接演化为对应的 MIDI 符号,或者驱动高维的 3D 手部动作序列),Flow Matching 可以让模型直接学习从"模态 A 的表征"流向"模态 B 的表征"的动态过程,而不需要将模态 A 彻底破坏成纯噪声再附加上条件去生成模态 B。这种灵活性为构建高效的多模态生成框架(尤其是需要精细对齐的连续信号如 3D 动作生成)打开了巨大的空间。
C. 更平滑的架构扩展性 (Scaling Laws)
Flow Matching 的目标函数本质上是对向量场进行回归,这与 Transformer 架构(尤其是 DiT 结构)的结合更加自然。在扩展模型参数规模(Scaling up)时,相比于 Diffusion 中需要精心调整的 ϵ\epsilonϵ-prediction、vvv-prediction 以及复杂的 SNR 权重设计,Flow Matching 往往表现出更稳定的收敛性和更直接的优化曲面。
总结来说,从 DDPM 到 Flow Matching 的转变,本质上是从依赖特定随机过程的工程妥协 ,走向了直接在流形上构建最优传输路径的数学重构。它使得模型的训练目标更纯粹,推理速度更快,并且极大地释放了在不同模态连续表征之间直接建模的潜力。
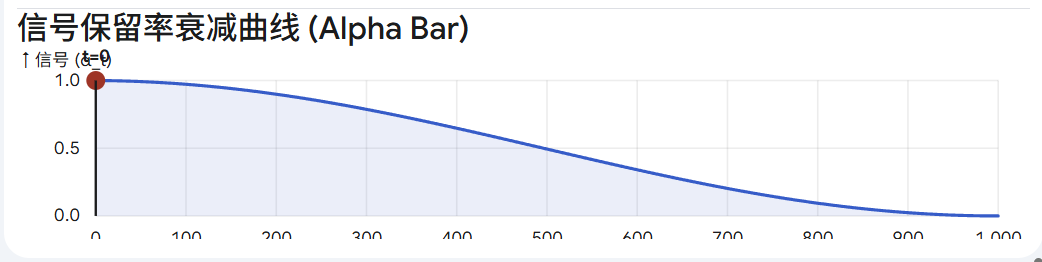
加噪幅度
在实际应用中,研究者们发现了不同的加噪策略会显著影响模型的生成质量:
- 线性表 (Linear Schedule): 最早 DDPM 采用的方法。βt\beta_tβt 随着 ttt 呈线性增长。缺点是到了过程中后期,图像信息已经被破坏得一干二净,剩下的几百步实际上在做无用功。
- 余弦表 (Cosine Schedule): 由 Improved DDPM 提出。它通过余弦函数来控制累积信息的保留率(αˉt\bar{\alpha}_tαˉt),使得信息的衰减更加平滑。这能防止图像在早期就被过度破坏,大大提升了生成质量。
这是一个非常敏锐的观察!很多初学者在看公式时都会产生这个疑惑。
1. βt\beta_tβt 是线性的
在线性策略中,我们规定每一步的噪声方差 βt\beta_tβt 随时间 ttt 线性增长。例如,从 β1=0.0001\beta_1 = 0.0001β1=0.0001 匀速增加到 βT=0.02\beta_T = 0.02βT=0.02。如果把 βt\beta_tβt 画出来,它确实是一条笔直上升的斜线。
2. 单步保留率 αt\alpha_tαt 也是线性的
单步的信号保留率定义为 αt=1−βt\alpha_t = 1 - \beta_tαt=1−βt。既然 βt\beta_tβt 是一条直线,那么 αt\alpha_tαt 自然也就是一条笔直下降的斜线。
3. 为什么 αˉt\bar{\alpha}_tαˉt 变成了曲线?(连乘效应)
我们在右侧图表中看到的"衰减曲线",画的是累积信号保留率 αˉt\bar{\alpha}_tαˉt,它的计算公式是所有历史步骤的连乘:
αˉt=α1×α2×α3×⋯×αt \bar{\alpha}_t = \alpha_1 \times \alpha_2 \times \alpha_3 \times \dots \times \alpha_t αˉt=α1×α2×α3×⋯×αt
这里的关键就在于"连乘"。
- 假设 α1=0.99\alpha_1 = 0.99α1=0.99, α2=0.98\alpha_2 = 0.98α2=0.98, α3=0.97\alpha_3 = 0.97α3=0.97(它们是线性递减的)。
- 累积起来:
- αˉ1=0.99\bar{\alpha}_1 = 0.99αˉ1=0.99
- αˉ2=0.99×0.98≈0.9702\bar{\alpha}_2 = 0.99 \times 0.98 \approx 0.9702αˉ2=0.99×0.98≈0.9702
- αˉ3=0.9702×0.97≈0.941\bar{\alpha}_3 = 0.9702 \times 0.97 \approx 0.941αˉ3=0.9702×0.97≈0.941
- αˉ10\bar{\alpha}_{10}αˉ10 可能就已经跌破 0.50.50.5 了。
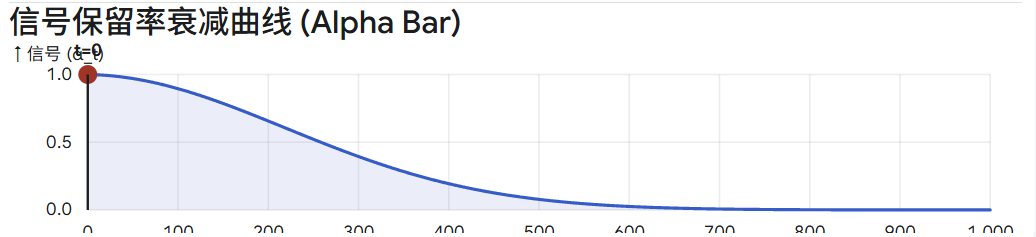
即使单步的保留率下降得很均匀(线性),但因为是在不断叠加打折 ,多个小于 1 的数字连乘会导致结果呈现出类似指数级的"加速崩塌"。这就导致了 αˉt\bar{\alpha}_tαˉt 曲线在前期就会迅速向下滑落,形成一条下凹的陡峭曲线,而不是一条直线。
总结与余弦策略(Cosine)的诞生
正因为"线性 βt\beta_tβt"会导致"非线性的过快衰减",使得图像在中间阶段(比如 t=500t=500t=500 时)信号就几乎掉到 0 了,后面的 500 步全在纯噪声里瞎算,这极大地浪费了模型的容量。
为了解决这个问题,研究人员才发明了余弦策略(Cosine Schedule) 。
余弦策略的思路是反向操作的:
- 它不去管每一步的 βt\beta_tβt 是什么形状。
- 它强行规定 最终的累积曲线 αˉt\bar{\alpha}_tαˉt 必须是一条平缓衰减的余弦曲线。
- 然后再利用公式 βt=1−αˉtαˉt−1\beta_t = 1 - \frac{\bar{\alpha}t}{\bar{\alpha}{t-1}}βt=1−αˉt−1αˉt,反推出每一步应该加多少噪声。