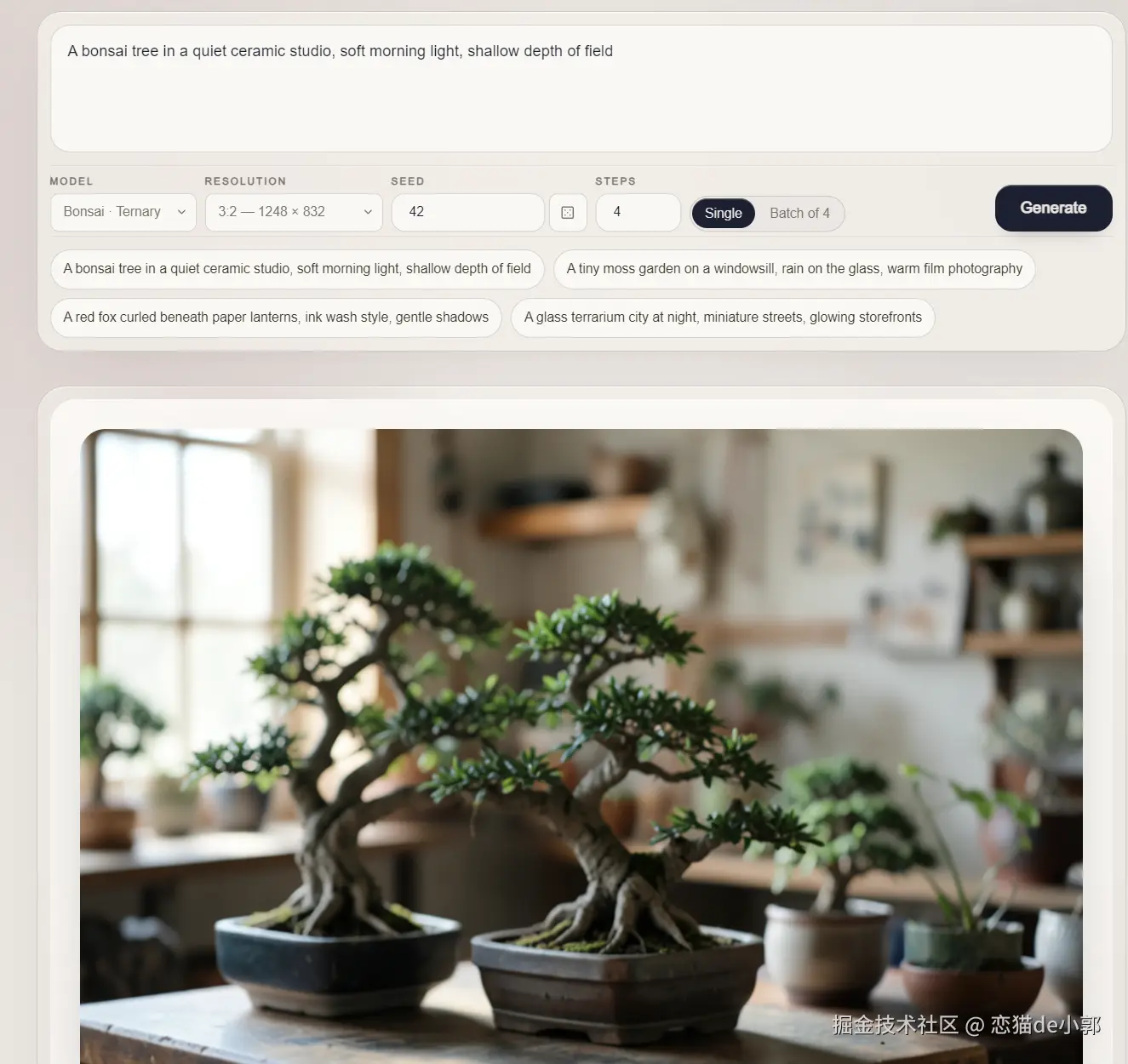
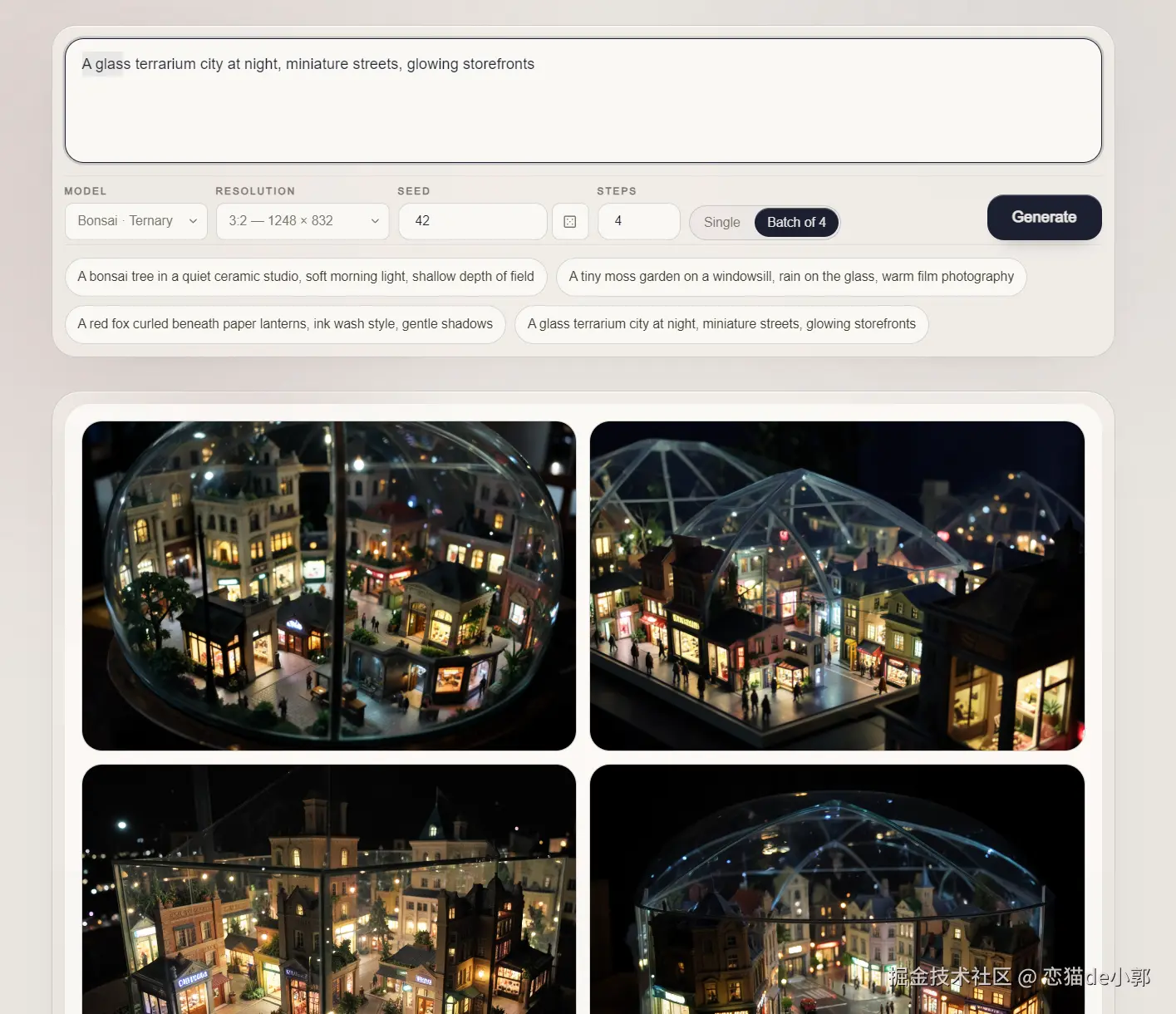
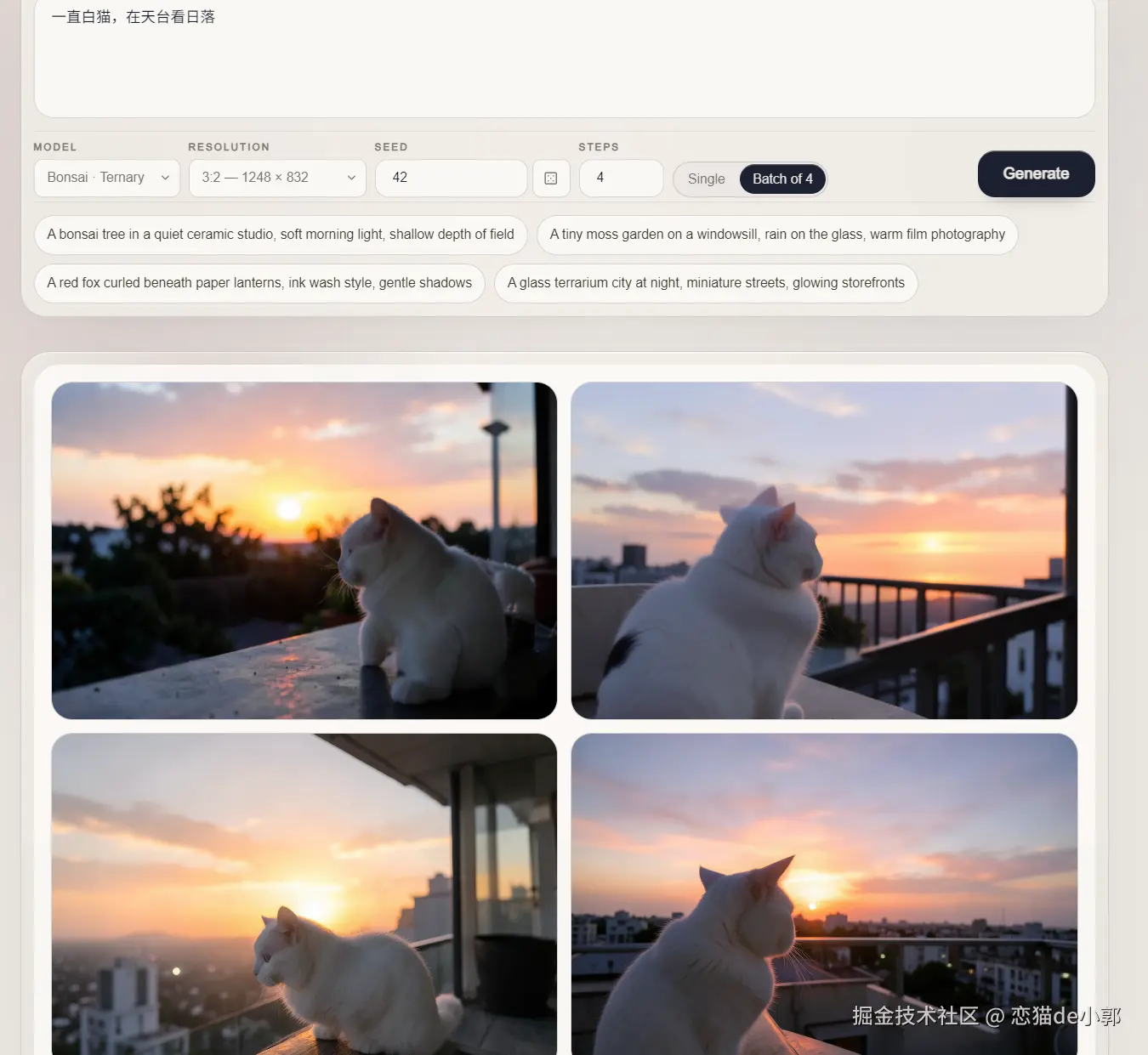
如下图所示,这些都是通过 Ternary Bonsai Image 4B 模型在手机上本地的你信吗?这就是今天要聊的一个图像生成模型,同时 Bonsai Image 4B 也是参数类别中首个可以直接在 iPhone 上运行的图像模型 。

实际上,Bonsai Image 就是把 FLUX.2 Klein 4B 的 diffusion transformer,压到 1-bit / ternary 低比特权重,让它能在 iPhone 上跑的图像生成模型:
保留 FLUX.2 Klein 4B 的架构,把 diffusion transformer 权重改成二值或三值表示,从而把显存/内存占用压下来。
对比上面的 Ternary Bonsai Image 4B ,下面这些是 1-bit Bonsai Image 4B 生成的,是的,Bonsai Image 4B 有两个版本:

- 1-bit Bonsai Image 4B : 权重只有
{−1, +1}两种状态,再配合 FP16 group-wise scaling factor,官方说有效精度大概 1.125 bits/weight,核心是极限压缩,适合内存压力最大、模型大小敏感的场景 - Ternary Bonsai Image 4B : 权重是
{−1, 0, +1}三种状态,同样带 FP16 group-wise scaling factor,官方说有效精度大概 1.71 bits/weight,多了一个 0 状态,画质和 prompt fidelity 更接近原模型。
| Model | Diffusion Transformer | Reduction vs FP16 |
|---|---|---|
| FLUX.2 Klein 4B | 7.75 GB | 1.0x |
| 1-bit Bonsai Image 4B | 0.93 GB | 8.3x |
| Ternary Bonsai Image 4B | 1.21 GB | 6.4x |
4B 参数级别的图像 DiT,本来 FP16 diffusion transformer 要 7.75GB,现在被压到 0.93GB / 1.21GB 级别 ,当然,需要注意的是,它压的是 diffusion transformer 主体,不是整个 pipeline 都只有 1GB,官方说加上压缩 text encoder 和 FP16 VAE 后,Apple Silicon 部署包体是 3.42GB / 3.88GB,而原始 full precision FLUX.2 Klein 4B pipeline 是 15.97GB。
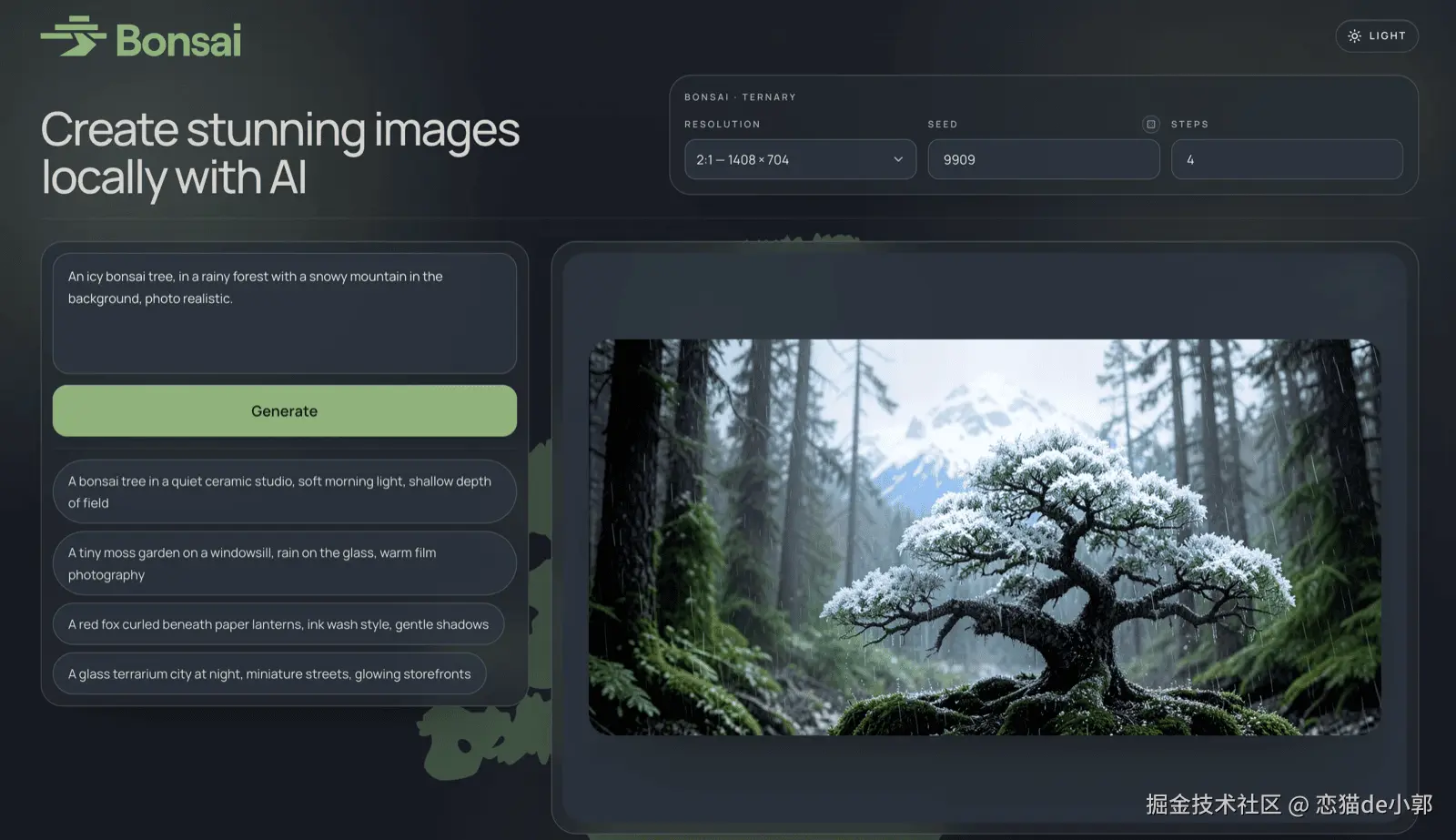
官方 demo 里默认 512×512 作为 fast preview,也给了 1024×1024、1248×832、832×1248、1408×704 等建议尺寸,要求尺寸是 32 的倍数:
目前官方提供的运行路径大概有几类:
- Apple Silicon / iPhone / iPad / Mac :在 Apple 设备上走 MLX low-bit 路径,支持 Apple Silicon iPhone、iPad、Mac
- CUDA GPU :Linux / Windows NVIDIA GPU 上走 Gemlite low-bit GEMM + HQQ / Triton Windows ,官方说 Windows 可以原生跑,不需要 WSL2
- CLI / 本地 Web Studio / iOS App : GitHub demo 支持 CLI 生成,也可以启动 FastAPI backend + Next.js frontend 的本地 studio,App Store 上也已经有 Bonsai Studio
PrismML 用三个互补的基准测试评估了 Bonsai Image 4B ,最终结果如下所示:
- GenEval 用于评估对象组成和属性绑定
- HPSv3 用于评估人类偏好和美学质量
- DPG-Bench 用于评估密集提示跟踪和语义忠实度

| Model | Diffusion Transformer Footprint (GB) | GenEval | HPSv3 | DPG-Bench | Size reduction relative to FLUX.2 Klein 4B | Performance relative to FLUX.2 Klein 4B |
|---|---|---|---|---|---|---|
| 1-bit Bonsai Image 4B | 0.93 | 0.671 | 11.15 | 0.822 | 8.3x | 88% |
| Ternary Bonsai Image 4B | 1.21 | 0.723 | 12.22 | 0.851 | 6.4x | 95% |
| FLUX.2 Klein 4B | 7.75 | 0.819 | 12.84 | 0.853 | 1x | 100% |
| SDXL | 5.14 | 0.3 | 10.05 | 0.74 | 1.5x | 67% |
| BK-SDM-Small | 0.98 | 0.297 | 3.05 | 0.559 | 7.9x | 42% |
| Stable Diffusion 1.5 | 1.72 | 0.396 | 4.2 | 0.601 | 4.5x | 51% |
| PixArt-Σ XL 2 | 1.2 | 0.541 | 11.93 | 0.769 | 6.4x | 83% |
具体结果为:
- Ternary Bonsai Image 4B 体积 1.21 GB,在 GenEval、HPSv3 和 DPG-Bench 测试里,保持了 FLUX.2 Klein 4B 95% 的精度,同时将扩散变换器的体积缩小了 6.4 倍。
- 1-bit Bonsai Image 4B 的 diffusion transformer 大小降低到 1 GB 以下,减少了 8.3 倍,同时在相同的三个评估保留了 FLUX.2 Klein 4B 的 88% 的准确度
这里 1-bit 是权重二值化,ternary 是三值化,理论上乘法可以大幅简化,内存带宽也大幅下降,但图像 diffusion transformer 对画质非常敏感,所以它保留了一小部分 FP16 projection layers,官方说约 5% precision-sensitive supporting tensors 仍保留 FP16,因此最终不是理论 16x,而是 8.3x / 6.4x 的整体 transformer footprint 压缩。
另外,文生图是多步 denoising,不是文本 LLM 那种 token 一个个吐,所以每一步都要调用 transformer,transformer 体积直接影响内存占用、带宽压力和速度,这里 Bonsai Image 4B 优化的就是 diffusion 推理里最频繁执行的部分。
但是如果只是把权重压成 1-bit,但没有 MLX / Gemlite 这种 low-bit kernel,实际运行时可能还要 unpack 成 FP16,那就只是省了硬盘空间,不一定省运行内存和速度。
所以官方这次同时提供 MLX 版本、Gemlite 版本、unpacked 版本、demo repo、iOS App,这说明它是模型 + kernel + deployment stack 一起做。

最后,官方也提供了对应的参考数据:
- 内存占用 : 512×512 生成时,binary / ternary 的 mean-active memory 分别是 1.5GB / 1.96GB,而原始 FLUX.2 Klein 4B 是 11.74GB;1024×1024 时,binary / ternary 是 1.95GB / 2.38GB,原始模型是 14.39GB
- 速度 : iPhone 17 Pro Max 生成 512×512 大约 9.4 秒,Mac M4 Pro 大约 6 秒
- 质量: Ternary 版本 benchmark 接近 FLUX.2 Klein 4B;1-bit 是 footprint 优先,画质和 prompt 跟随弱一些,容易丢细节
当然,他的核心是压缩模型,所以最多也就是用在一些头像、普通插画,简单草稿,风格化图片等场景,肯定是别想指望他能有个 banana 和 image2 那样的效果,那是拍马都追不上的。
所以,Bonsai Image 4B 的核心就是「本地甚至手机能跑的 AI 画图模型」,同时提供两个方案,其中 1-bit 更小更省,Ternary 更稳,它们还是 4B,只是参数被压缩存储,把原本很吃内存的 4B 图像生成 DiT 模型,用 1-bit / Ternary 的极低比特权重量化压到手机可运行,同时还保留大部分原模型画质和语义能力,这就是他的价值。
至少放 OpenClaw 或者 Hermes 里,作为一个本地多模态补充就还是可以的。
这是我本地自己生成的,效果还过得去,速度也还不错,用来说一个本地补充还是可以的: