| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文名称 | VLA-R1 |
| 2 | 发表时间/位置 | |
| 3 | Code | VLA-R1: Enhancing Reasoning in Vision-Language-Action Models |
| 4 | 创新点 | |
| 5 | 引用量 |
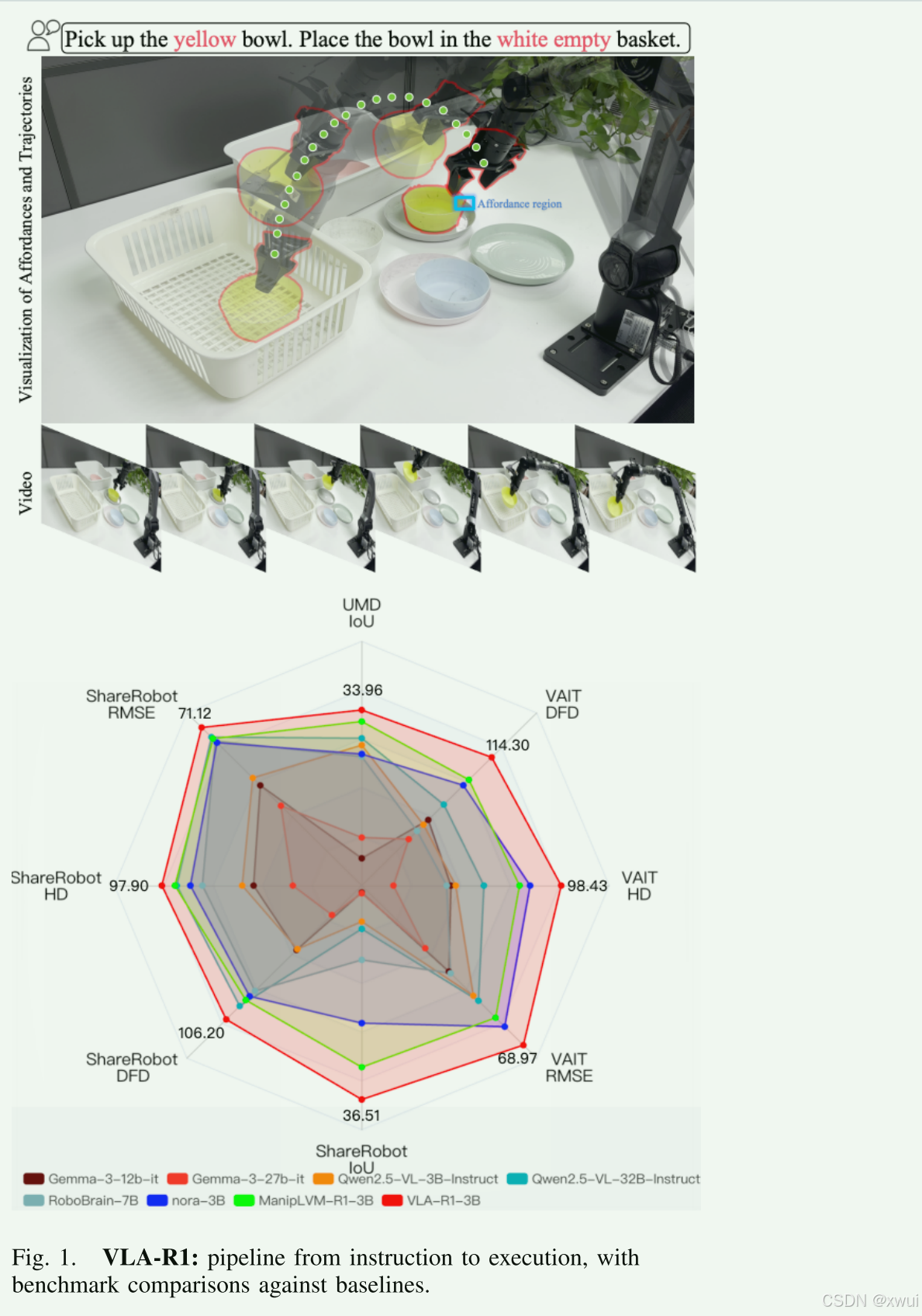
一:提出问题
传统的vla模型工作原理通常是:一张图+一条指令--然后输出一个动作。但是这种传统模型往往存在以下的问题:
-
缺乏"思考过程"(No Step-by-step Reasoning): 遇到复杂场景时,以前的模型是"脑子一热直接动手",没有考虑**可供性(Affordance)*和*几何关系。
- 什么是可供性?比如一个杯子,它的"把手"提供了"可抓握"的属性。如果不去推理"杯子的把手朝向哪里、我的机械爪能不能伸进去(几何关系)",直接去抓,往往会抓空或者碰倒杯子。
-
后训练(Post-training)太弱: 以前的模型训练主要靠"模仿人类"(也就是监督微调 SFT)。但纯模仿上限很低,且一旦遇到没见过的情况就不知所措,缺乏通过"试错和奖励"来提升自身推理逻辑的机制。
本文提出VLA-R1模型。采用了大模型最新的"强化学习+ 思维链"的技术。采用了最新的两个技术方案:
GRPO (Group Relative Policy Optimization) - 群体相对策略优化:
- 这是最近极其火爆的强化学习算法(DeepSeek-R1 的核心算法)。它不需要单独训练一个庞大的评价模型(Critic),而是让模型针对同一个问题生成多个解答方案,在这些方案内部互相比较"谁更好"。这使得机器人在后训练时效率极高。
RLVR (Reinforcement Learning from Verifiable Rewards) - 基于可验证奖励的强化学习:
-
训练机器人最难的是"怎么判断它做得对不对(奖励函数怎么写)"。论文设计了三个客观、可验证的代码级奖励:
-
区域对齐(Region alignment): 机器人想抓的东西,是不是精准对应了画面里的正确区域?(你不能嘴上说抓苹果,手却指着香蕉)。
-
轨迹一致性(Trajectory consistency): 规划的移动路径是否符合物理和逻辑?
-
输出格式化(Output formatting): 输出的动作指令格式必须严格对齐系统要求,不能乱输出乱码。
-
-
只要机器人满足这三个客观条件,就给它发"奖金"(Reward)。这样模型就会拼命为了拿奖金去自我思考(产生很长的内部推理过程),从而真正学会了"谋定而后动"。
最后作者还构建了一个1.3万规模的高质量数据集,区别于以往"图像→→动作"的数据,这个数据集加入了CoT(Chain-of-Thought 思维链) 。它强迫模型在输出动作前,先用语言"碎碎念"一遍:"我要抓这个杯子→→杯子把手在右边→→周围没有障碍物→→我的机械臂应该从右侧靠近..."。这种监督信号与动作轨迹强绑定,是模型学会推理的关键。
为什么要重视指令消歧 :桌子上有两个苹果(一个红一个绿),有三个杯子。如果只依靠过去端到端(End-to-End)直接输出坐标的模型,机器人往往会发生**"模态崩溃"** ------它的机械臂可能指在两个苹果中间的空气中(取了坐标平均值),因为它不知道你到底指哪个。而VLA-R1采用了慢思考的方案。 强迫机器人产生"慢思考(System 2)"。遇到这种情况,VLA-R1必须先生成内部语言:"桌上有红绿两个苹果,指令没说哪个,我需要根据环境(比如最近的那个)做出选择,确定红苹果坐标在X..." 把"想"和"做"分开,这是解决具身智能复杂环境适应性的关键一跃。
可验证奖励(Verifiable Rewards) :在大语言模型(如 ChatGPT)中,RLHF(基于人类反馈的强化学习)很常见,因为人很容易判断一句话回答得好不好。但对于机器人来说,让人类去给机械臂的运动轨迹打分,成本极高且主观 。这篇论文的高明之处在于,它抛弃了人工打分(RLHF),完全采用**客观的数学和物理几何指标(RLVR)**作为强化学习的裁判(Reward)。
为什么用 GIoU(广义交并比)而不是普通的 IoU?
在目标检测中,如果你要抓一个苹果,模型预测的框和真实的框如果完全没有交集 ,传统的 IoU 值为 0。在强化学习中,奖励为 0 意味着"没有梯度",模型不知道该往哪个方向修正。GIoU 的巧妙在于,即使两个框不重合,它也会计算两个框之间的距离。 距离越近,惩罚越小,这样模型就能顺着这个"梯度"慢慢把框移到正确的位置。这对 RL 训练的收敛至关重要。
什么是改进的 Fréchet 距离(弗雷歇距离)?
机械臂的运动是一个连续的轨迹(Trajectory)。如果只算点到点的欧氏距离,无法评估曲线的形状(比如为了避障绕了个弯)。Fréchet 距离在数学上被形象地称为**"遛狗距离"** ------一个人走一条轨迹,狗走另一条轨迹,人狗之间需要的最短狗绳长度。用它来做 Reward,可以极其精准地评估模型规划的动作轨迹与专家轨迹在"形态和走势"上是否高度一致。这是将纯自然语言 RL 算法引入物理世界的绝妙桥梁。
虽然强化学习(RL)很强大,但在冷启动时,如果模型一开始完全随机输出,它永远拿不到奖励,也就学不会。
作者构建的 VLA-CoT-13K 并不是随意的数据集,而是一本带标准解析过程的习题集。
它通过数据引擎强制把"自然语言推导过程"、"视觉目标框(Affordance)"和"物理运动轨迹(Trajectory)"这三种跨模态的信息对齐。让模型在微调阶段(SFT)先学个大概(产生基本的 CoT 能力),然后再用 RLVR 配合 GRPO 在大后方进行疯狂试错和自我进化。
二:解决方案
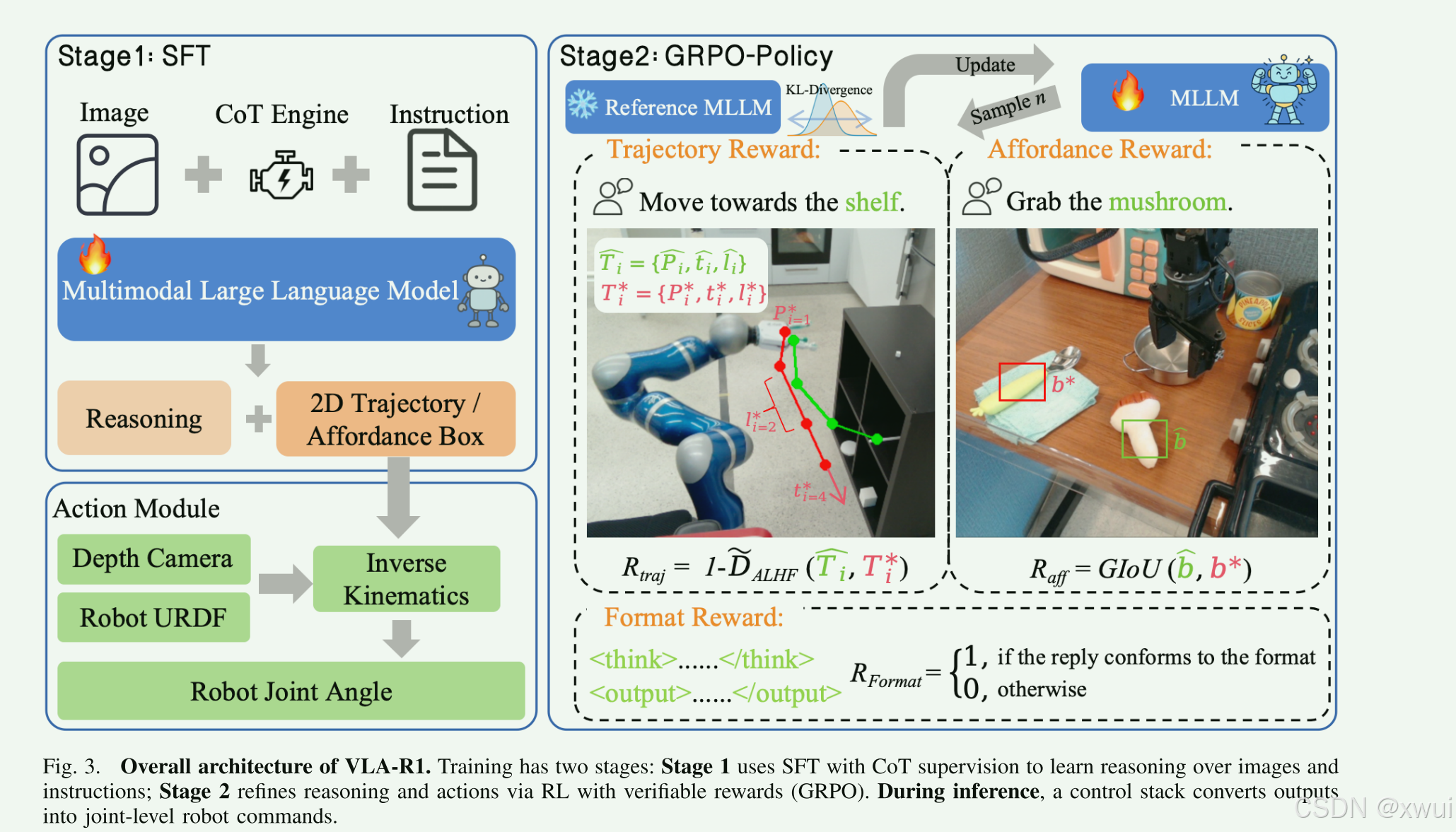
VLA-R1 的整体架构如图 3 所示。给定一张输入图像和一段自然语言指令,VLA-R1 通过视觉-语言主干网络(vision-language backbone)对多模态信息进行编码,随后通过动作解码器(action decoder)生成底层的控制信号。
1.数据合成
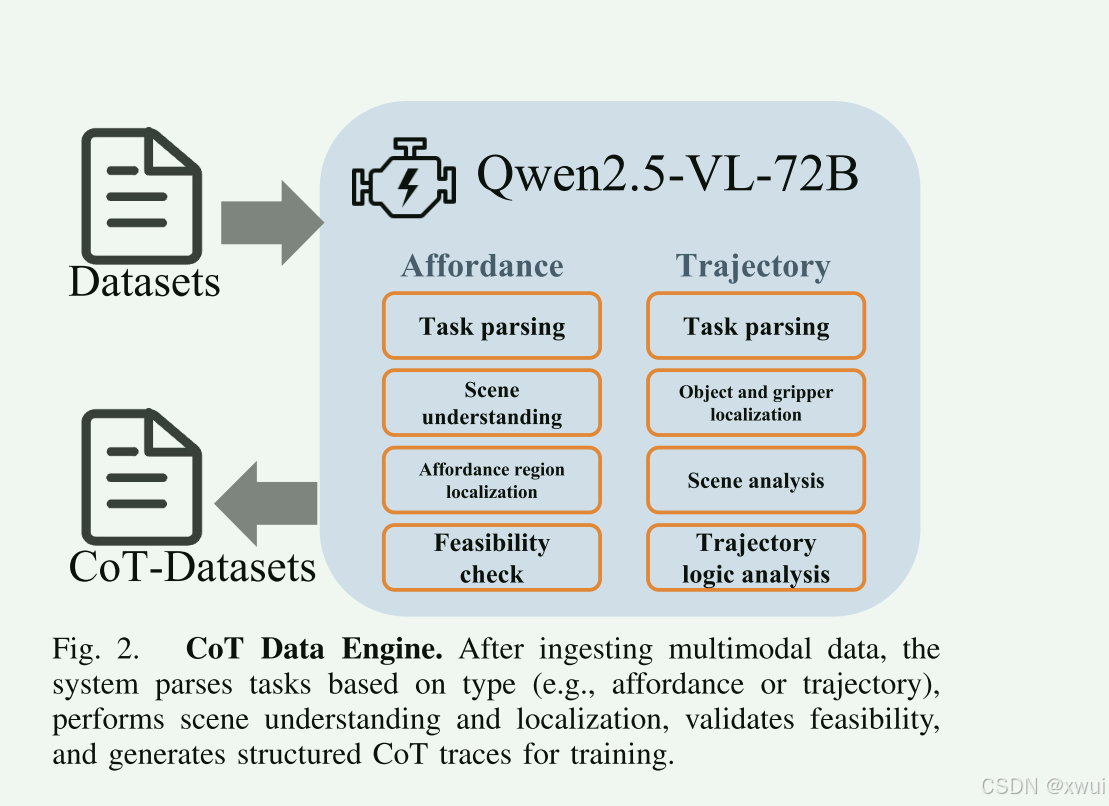

使用大模型 Qwen2.5-VL-72B 构建了一个思维链(CoT)数据集。如表 I 和图 2 所示,我们利用该模型自动为"可供性(affordance)"和"轨迹(trajectory)"任务生成中间推理步骤。我们总共生成了 13,000 条(13K)CoT 标注数据,这些数据作为高质量的监督信号,在感知与动作之间架起了桥梁。这些思维链数据不仅丰富了训练语料库的语义可解释性,还提供了显式的逐步(step-by-step)指导,使得模型能够学习到与任务相一致的推理模式。
2.监督微调Supervised Fine-Tuning
2.1为什么数据用72B模型,训练用3B模型。蒸馏思想的运用。
器人需要在现实世界里实时控制机械臂,控制频率通常要求在 10Hz 甚至更高(即每秒推理10次以上)。如果你把一个 720亿参数(72B)的巨无霸模型塞进机器人脑子里,它可能几秒钟才能憋出一个动作,黄花菜都凉了。作者极其聪明地采用了**"大老师教小徒弟(Knowledge Distillation via Synthetic Data)"**的策略。
-
先让极其聪明的 Qwen2.5-VL-72B(老师) 去看图写详细的"解题步骤"(那 13K 的思维链数据)。
-
然后用这些带解题步骤的标准答案,去训练一个只有 30亿参数(3B)的小模型(徒弟)。3B 的模型在机器人上跑得飞快,又能学到 72B 老师的思维逻辑。这是目前解决具身智能"既要聪明、又要实时"的最优解之一。
2.2 什么是跨时间的信用分配?
想象机器人在煎一个鸡蛋,它做了 100 个动作:拿锅、倒油、打蛋、翻面......如果最后鸡蛋糊了,机器人怎么知道是哪一步做错了?(这就是信用分配难题)。
过去的模型直接输出动作,就像个"黑盒",查不出死因。而 VLA-R1 引入了 <think> 标签,把推理过程白纸黑字写下来了(比如它在倒油前写了:发现锅还没热,但我决定现在倒油)。有了显式的思维链(CoT),无论是监督微调还是后面的强化学习,算法都能极其精准地定位到**"你的脑子是在哪一步短路的"**,从而对症下药地修改模型权重。这大大提高了学习效率。
2.3 为什么原生分辨率和2D RoPE这么重要?
-
原生分辨率(Native input resolution): 以前的视觉模型(如 CLIP)为了省算力,会把所有图片强行缩放裁剪成 224x224 的正方形。对于机器人来说这是致命的!因为缩放会破坏物理世界的几何比例 (原本 10 厘米的杯子被拉伸后可能看起来像 15 厘米),机械臂去抓肯定会抓空。支持"原生分辨率"意味着模型能原汁原味地理解真实的物理空间尺寸。
-
2D RoPE(二维旋转位置编码): 传统的大语言模型处理的是一维文字(从左到右)。但图像是二维的(有上下和左右)。2D RoPE 能让视觉特征不仅保留"这是什么",还能精确保留"这东西在画面的绝对坐标(X, Y)"。这对于需要精准定位(Visual Grounding)和计算动作坐标的机械臂来说,是绝对不可或缺的技术基石。
-
MLP Token 软压缩: 视频流数据太大了,如果不压缩,语言大模型很快会被塞爆。用 MLP 进行软压缩,能在保留核心语义和空间信息的前提下,把视觉数据的体积降下来,让模型能记住更长历史(Long temporal contexts),不会"转个身就忘了前面有什么"。
Reinforcement Learning

整个思路的核心参考了deepseek-r1的思路:
1.为什么用 GRPO 而不是传统的 PPO?(算力账本)
在过去,强化学习微调大模型(包括 ChatGPT 早期)几乎都用 PPO 算法。PPO 的致命弱点是:它需要同时在显存里加载 4 个模型(演员模型、参考模型、评论家 Critic 模型、奖励模型)。对于本身就极其消耗显存的多模态 VLA 模型来说,用 PPO 训练简直是硬件灾难。
-
GRPO 的绝妙之处: 它直接砍掉了 Critic(评论家)模型!
-
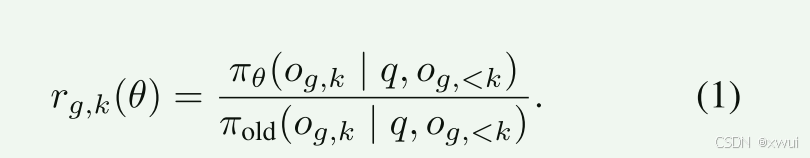
-
它是怎么做到不带 Critic 还能打分的? 看公式 (1) 上面的那句话:"通过组内均值 rˉ 和标准差进行归一化"。简单来说:遇到一个问题,GRPO 会让模型生成 8 个不同的解答(这叫一个 Group)。然后把这 8 个解答送到物理/几何奖励函数里跑一下,得出 8 个分数。这 8 个分数内部"卷(对比)"一下,高于平均分的,就奖励(优势估计 A^>0);低于平均分的,就惩罚(A^<0)。
-
这种"组内相对对比"极大地节省了显存,使得多模态机器人模型也能享受大规模 RL 带来的推理飞跃。
2.ALAF 距离:教机器人像人类一样做平滑运动

在计算机视觉里算差异,大家习惯用欧氏距离(MSE Loss)。但在机器人轨迹规划中,欧氏距离是"灾难性"的。
-
为什么不用欧氏距离? 假设标准轨迹是一条平滑的直线。如果机器人预测的轨迹是"锯齿状(疯狂抖动)"的,但由于这些锯齿点离中轴线很近,欧氏距离算出来会非常小(以为它学得很好)。但如果你把这条带有"高频抖动"的指令发给物理机械臂,电机会因为瞬间频繁变向而被烧毁!
-
弗雷歇距离(Fréchet)的引入: 前面我提到过,这是数学上的"遛狗距离"。它不仅考虑点的位置,必须考虑**保序性(**Φ),即轨迹走势不能倒退。
-
ALAF 的三大惩罚(看公式 3 的大括号):
-
Position(位置): 距离别偏离太远。
-
Angle(角度): 用余弦反函数 arccosarccos计算切向量(方向)。这就杜绝了"锯齿状"轨迹!因为锯齿意味着方向不停剧变,这里的角度惩罚会瞬间爆炸,告诉模型"你不能这样走"。
-
Length ratio(线段长度比): 长度代表着**"速度与加速度"**。如果某一段间距突然变长,说明机器人在这一步加速了。这保证了模型生成的运动在速度上是平滑的、符合物理规律的。
-
-
这个奖励函数写得极其漂亮!它相当于把人类对机器臂"平稳、安全、顺滑"的要求,完美翻译成了强化学习能听懂的数学语言。
3. 为什么需要 Format(格式)奖励?(防作弊机制)
既然有了前面这么高级的物理奖励,为什么还要搞一个简单的格式奖励(格式对就给 1,不对给 0)?
-
在强化学习界有一句名言------"模型比你想象的更聪明,但也更狡猾" 。如果你不规定格式,模型为了快速拿到高分,它可能会跳过 <think> 阶段,或者输出一堆无意义的乱码直接拼凑出动作坐标(这被称为 Reward Hacking 或模型退化)。
-
格式奖励的强制性: 它就像考场上的规定------"必须写解题步骤,只写答案不给分"。这强制约束了模型,必须在输出动作前,把自己的慢思考过程(System 2) 原原本本地写在 <think> 标签里。这正是赋予模型强大泛化和逻辑消歧能力的关键!